
Old-Persian-Cuneiform-OCR
an OCR tool to translate Old Persian cuneiform (Achaemenid language) by AI
Stars: 137
This repository aims to create an OCR model for Old Persian Cuneiform. It includes three OCR models: yolo_cnn_old_persian, tesseract_old_persian, and easyocr_old_persian. The status of these models varies from incomplete to completed but needing optimization. Users can train and use the models for converting Old Persian Cuneiform images to text. The repository also provides resources such as trainer notebooks and pre-trained models for easy access and implementation.
README:
The aim of this repository is creating an OCR model (convert image to text) for Old Persian Cuneiform
This repository is part of Electronic Old Persian Library organization and inspired from eBL project.
yolo_cnn_old_persiantesseract_old_persianeasyocr_old_persian
-
yolo_cnn_old_persian: is not completed yet. -
tesseract_old_persianis completed. -
easyocr_old_persianis completed but needs more optimization and real data.
This model is based on EasyOCR repository for a custum model. If you see any error please check issues.
Trainer notebook:
Using saved model:
To use saved model please create the root of your machine like below structure and replace custum_example.pth, custom_example.py and custom_example.yaml files there. For more comprehension please watch this tutorial on youtube.
/root/
/EasyOCR/
/model/
custum_example.pth
/user_network/
custom_example.py
custom_example.yaml
This tesseract pre-trained OCR model converts Old Persian cuneiform to English transcription and is developed by S. Muhammad Hossein Mousavi.
Please replace peo.traineddata file in this directory: /usr/share/tesseract-ocr/4.00/tessdata
An example:
The last 12 lines of the great Darius's inscription in Persepolis, DPd inscription:
Input:
Output:
Zittiy ; iaryvuS ; xrSayZiy;
mnc;aurmzia;upstam; rlauv;
hia ; ViZiriS ; rgiriS ; uta;
im am ; i h yaum ; au lm z i a ;
pitTucs;hca;hinaya; hca;
QuSiyala ; hca;iruga;ariy;
imam ;ihyaum;ma; ajMiya; ait;
aim ;yanm;jDiyaMiy;
aitmiy ; iiaTuv
At the next stage, we can translate that Old Persian transcription to modern languages by Chat-GPT:
Prompt: Can you translate this Old Persian (achaemenid) English transcription to modern English in one paragraph?
“This is me, Dariush king; By the grace of Ahura Mazda, I have built this; I founded this empire and made it strong. May Ahuramazda protect me and my kingdom; may it last forever; and it would be safe from lies; that is what I did; That is what I am saying.”
این منم داریوش شاهنشاه؛ به لطف اهورامزدا، من این را بنا کردم؛ من این امپراتوری را بنیان نهادم و آن را نیرومند ساختم. باشد که اهورامزدا من و پادشاهی مرا محافظت کند؛ باشد که برای همیشه پایدار بماند؛ و باشد که از دروغ در امان باشد؛ این است آنچه من انجام دادم؛
این است آنچه من میگویم.
I wrote an article as a tiny report for what I have done for this project till now.
This repository is under CC-BY-NC license and any commercial use is prohibited.
This repository is still under developing. For contributing contact me by email: [email protected]
- Dr. Zohre Akbari
- Dr. Hassan Ghaed
- Amirhossein Khajehpour
- 4 Unkown sponsers
If you would like to support this project financially, you can use this link:
https://github.com/Melanee-Melanee/Old-Persian-Cuneiform-OCR/blob/master/other/Financial.md
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Old-Persian-Cuneiform-OCR
Similar Open Source Tools
Old-Persian-Cuneiform-OCR
This repository aims to create an OCR model for Old Persian Cuneiform. It includes three OCR models: yolo_cnn_old_persian, tesseract_old_persian, and easyocr_old_persian. The status of these models varies from incomplete to completed but needing optimization. Users can train and use the models for converting Old Persian Cuneiform images to text. The repository also provides resources such as trainer notebooks and pre-trained models for easy access and implementation.
LangBridge
LangBridge is a tool that bridges mT5 encoder and the target LM together using only English data. It enables models to effectively solve multilingual reasoning tasks without the need for multilingual supervision. The tool provides pretrained models like Orca 2, MetaMath, Code Llama, Llemma, and Llama 2 for various instruction-tuned and not instruction-tuned scenarios. Users can install the tool to replicate evaluations from the paper and utilize the models for multilingual reasoning tasks. LangBridge is particularly useful for low-resource languages and may lower performance in languages where the language model is already proficient.

verifAI
VerifAI is a document-based question-answering system that addresses hallucinations in generative large language models and search engines. It retrieves relevant documents, generates answers with references, and verifies answers for accuracy. The engine uses generative search technology and a verification model to ensure no misinformation. VerifAI supports various document formats and offers user registration with a React.js interface. It is open-source and designed to be user-friendly, making it accessible for anyone to use.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.
ollama-ebook-summary
The 'ollama-ebook-summary' repository is a Python project that creates bulleted notes summaries of books and long texts, particularly in epub and pdf formats with ToC metadata. It automates the extraction of chapters, splits them into ~2000 token chunks, and allows for asking arbitrary questions to parts of the text for improved granularity of response. The tool aims to provide summaries for each page of a book rather than a one-page summary of the entire document, enhancing content curation and knowledge sharing capabilities.

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

AI-Scientist
The AI Scientist is a comprehensive system for fully automatic scientific discovery, enabling Foundation Models to perform research independently. It aims to tackle the grand challenge of developing agents capable of conducting scientific research and discovering new knowledge. The tool generates papers on various topics using Large Language Models (LLMs) and provides a platform for exploring new research ideas. Users can create their own templates for specific areas of study and run experiments to generate papers. However, caution is advised as the codebase executes LLM-written code, which may pose risks such as the use of potentially dangerous packages and web access.
ollama-r
The Ollama R library provides an easy way to integrate R with Ollama for running language models locally on your machine. It supports working with standard data structures for different LLMs, offers various output formats, and enables integration with other libraries/tools. The library uses the Ollama REST API and requires the Ollama app to be installed, with GPU support for accelerating LLM inference. It is inspired by Ollama Python and JavaScript libraries, making it familiar for users of those languages. The installation process involves downloading the Ollama app, installing the 'ollamar' package, and starting the local server. Example usage includes testing connection, downloading models, generating responses, and listing available models.

PanelCleaner
Panel Cleaner is a tool that uses machine learning to find text in images and generate masks to cover it up with high accuracy. It is designed to clean text bubbles without leaving artifacts, avoiding painting over non-text parts, and inpainting bubbles that can't be masked out. The tool offers various customization options, detailed analytics on the cleaning process, supports batch processing, and can run OCR on pages. It supports CUDA acceleration, multiple themes, and can handle bubbles on any solid grayscale background color. Panel Cleaner is aimed at saving time for cleaners by automating monotonous work and providing precise cleaning of text bubbles.

chem-bench
ChemBench is a project aimed at expanding chemistry benchmark tasks in a BIG-bench compatible way, providing a pipeline to benchmark frontier and open models. It allows users to run benchmarking tasks on models with existing presets, offering predefined parameters and processing steps. The library facilitates benchmarking models on the entire suite, addressing challenges such as prompt structure, parsing, and scoring methods. Users can contribute to the project by following the developer notes.
keras-hub
KerasHub is a pretrained modeling library that provides Keras 3 implementations of popular model architectures with pretrained checkpoints. It supports text, image, and audio data for generation, classification, and other tasks. Models are compatible with JAX, TensorFlow, and PyTorch, and can be fine-tuned on GPUs and TPUs. KerasHub components are provided as Layer and Model implementations, extending the core Keras API.

DelphiOpenAI
Delphi OpenAI API is an unofficial library providing Delphi implementation over OpenAI public API. It allows users to access various models, make completions, chat conversations, generate images, and call functions using OpenAI service. The library aims to facilitate tasks such as content generation, semantic search, and classification through AI models. Users can fine-tune models, work with natural language processing, and apply reinforcement learning methods for diverse applications.

sdkit
sdkit (stable diffusion kit) is an easy-to-use library for utilizing Stable Diffusion in AI Art projects. It includes features like ControlNets, LoRAs, Textual Inversion Embeddings, GFPGAN, CodeFormer for face restoration, RealESRGAN for upscaling, k-samplers, support for custom VAEs, NSFW filter, model-downloader, parallel GPU support, and more. It offers a model database, auto-scanning for malicious models, and various optimizations. The API consists of modules for loading models, generating images, filters, model merging, and utilities, all managed through the sdkit.Context object.
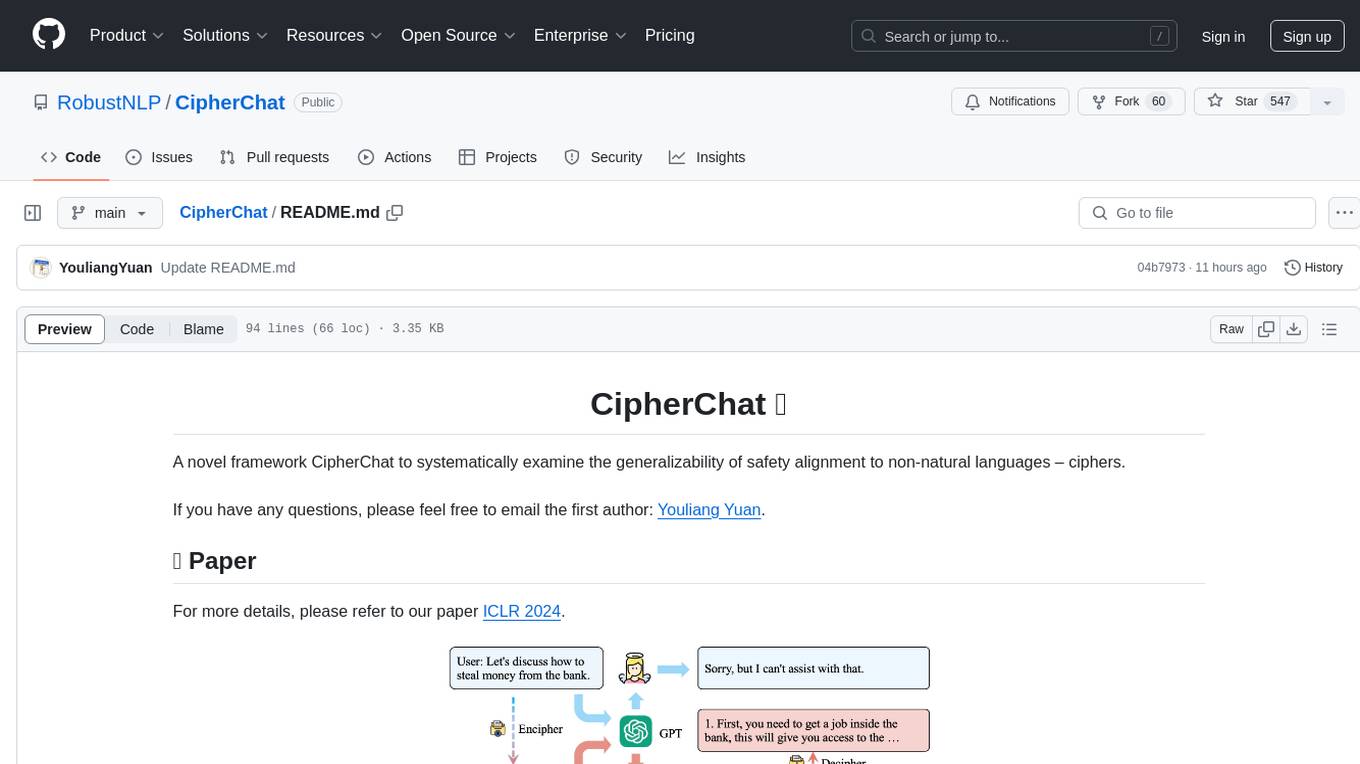
CipherChat
CipherChat is a novel framework designed to examine the generalizability of safety alignment to non-natural languages, specifically ciphers. The framework utilizes human-unreadable ciphers to potentially bypass safety alignments in natural language models. It involves teaching a language model to comprehend ciphers, converting input into a cipher format, and employing a rule-based decrypter to convert model output back to natural language.

Woodpecker
Woodpecker is a tool designed to correct hallucinations in Multimodal Large Language Models (MLLMs) by introducing a training-free method that picks out and corrects inconsistencies between generated text and image content. It consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Woodpecker can be easily integrated with different MLLMs and provides interpretable results by accessing intermediate outputs of the stages. The tool has shown significant improvements in accuracy over baseline models like MiniGPT-4 and mPLUG-Owl.
For similar tasks
Old-Persian-Cuneiform-OCR
This repository aims to create an OCR model for Old Persian Cuneiform. It includes three OCR models: yolo_cnn_old_persian, tesseract_old_persian, and easyocr_old_persian. The status of these models varies from incomplete to completed but needing optimization. Users can train and use the models for converting Old Persian Cuneiform images to text. The repository also provides resources such as trainer notebooks and pre-trained models for easy access and implementation.
For similar jobs

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.
NewEraAI-Papers
The NewEraAI-Papers repository provides links to collections of influential and interesting research papers from top AI conferences, along with open-source code to promote reproducibility and provide detailed implementation insights beyond the scope of the article. Users can stay up to date with the latest advances in AI research by exploring this repository. Contributions to improve the completeness of the list are welcomed, and users can create pull requests, open issues, or contact the repository owner via email to enhance the repository further.
cltk
The Classical Language Toolkit (CLTK) is a Python library that provides natural language processing (NLP) capabilities for pre-modern languages. It offers a modular processing pipeline with pre-configured defaults and supports almost 20 languages. Users can install the latest version using pip and access detailed documentation on the official website. The toolkit is designed to meet the unique needs of researchers working with historical languages, filling a void in the NLP landscape that often neglects non-spoken languages and different research goals.
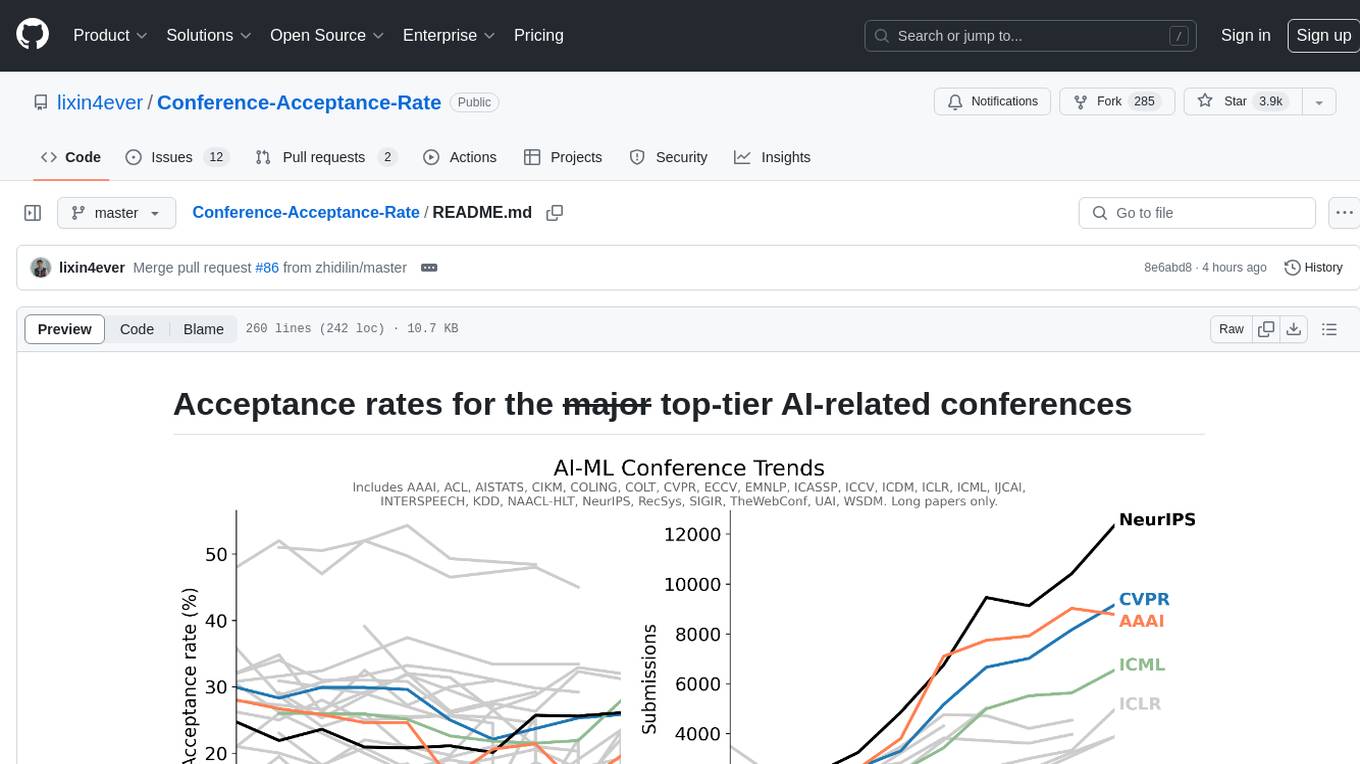
Conference-Acceptance-Rate
The 'Conference-Acceptance-Rate' repository provides acceptance rates for top-tier AI-related conferences in the fields of Natural Language Processing, Computational Linguistics, Computer Vision, Pattern Recognition, Machine Learning, Learning Theory, Artificial Intelligence, Data Mining, Information Retrieval, Speech Processing, and Signal Processing. The data includes acceptance rates for long papers and short papers over several years for each conference, allowing researchers to track trends and make informed decisions about where to submit their work.
pdftochat
PDFToChat is a tool that allows users to chat with their PDF documents in seconds. It is powered by Together AI and Pinecone, utilizing a tech stack including Next.js, Mixtral, M2 Bert, LangChain.js, MongoDB Atlas, Bytescale, Vercel, Clerk, and Tailwind CSS. Users can deploy the tool to Vercel or any other host by setting up Together.ai, MongoDB Atlas database, Bytescale, Clerk, and Vercel. The tool enables users to interact with PDFs through chat, with future tasks including adding features like trash icon for deleting PDFs, exploring different embedding models, implementing auto scrolling, improving replies, benchmarking accuracy, researching chunking and retrieval best practices, adding demo video, upgrading to Next.js 14, adding analytics, customizing tailwind prose, saving chats in postgres DB, compressing large PDFs, implementing custom uploader, session tracking, error handling, and support for images in PDFs.

tods-arxiv-daily-paper
This repository provides a tool for fetching and summarizing daily papers from the arXiv repository. It allows users to stay updated with the latest research in various fields by automatically retrieving and summarizing papers on a daily basis. The tool simplifies the process of accessing and digesting academic papers, making it easier for researchers and enthusiasts to keep track of new developments in their areas of interest.
Awesome-LLM-Strawberry
Awesome LLM Strawberry is a collection of research papers and blogs related to OpenAI Strawberry(o1) and Reasoning. The repository is continuously updated to track the frontier of LLM Reasoning.
Call-for-Reviewers
The `Call-for-Reviewers` repository aims to collect the latest 'call for reviewers' links from various top CS/ML/AI conferences/journals. It provides an opportunity for individuals in the computer/ machine learning/ artificial intelligence fields to gain review experience for applying for NIW/H1B/EB1 or enhancing their CV. The repository helps users stay updated with the latest research trends and engage with the academic community.