
APIMyLlama
API up your Ollama Server.
Stars: 79
APIMyLlama is a server application that provides an interface to interact with the Ollama API, a powerful AI tool to run LLMs. It allows users to easily distribute API keys to create amazing things. The tool offers commands to generate, list, remove, add, change, activate, deactivate, and manage API keys, as well as functionalities to work with webhooks, set rate limits, and get detailed information about API keys. Users can install APIMyLlama packages with NPM, PIP, Jitpack Repo+Gradle or Maven, or from the Crates Repository. The tool supports Node.JS, Python, Java, and Rust for generating responses from the API. Additionally, it provides built-in health checking commands for monitoring API health status.
README:

APIMyLlama is a server application that provides an interface to interact with the Ollama API, a powerful AI tool to run LLMs. It allows users to run this alongside Ollama to easily distrubute API keys to create amazing things.
We now have a Ko-fi open if you would like to help and donate to the project. We love to keep it free and open source when possible and donating helps a lot.
If you already have Ollama setup with the 'ollama serve' command and your desired model. You can skip this. If not i'll show you how to set it up. First install Ollama for your desired operating system. Once installed open a terminal instance and run the command below.
ollama pull llama3If done correctly you should now have the Meta's Llama3 LLM installed. You can use any model with the API but for this example we will use this model. Now you are gonna run this command after the install is complete.
ollama serveNow you have an Ollama server setup. Time for the next step.
Install Node.JS on your server. Then clone the git repository.
git clone https://github.com/Gimer-Studios/APIMyLlama.git
cd APIMyLlama
npm install
node APIMyLlama.jsAfter cloning go into the APIMyLlama directory and install all the needed dependencies by running the 'npm install' command. Then run the APIMyLlama.js file. On startup it will ask what port you want to use.
PS C:\Users\EXAMPLE\Documents\APIMyLlama> node APIMyLlama.js
APIMyLlama V2 is being started. Thanks for choosing Gimer Studios.
Connected to the apiKeys.db database.
Enter the port number for the API server: 3000
Port number saved to port.conf: 3000
Enter the URL for the Ollama server (URL that your Ollama server is running on. By default it is "http://localhost:11434" so if you didnt change anything it should be that.): <URL_FOR_OLLAMA_SERVER
Enter the desired port you would like to use with the APIMyLlama server. This port can NOT be the same as Ollama or any other application running on your server. After you choose your port you will NEED to port foward this port if you are gonna use the API Key system OUTSIDE of your network. Then it will ask you to enter the URL for your Ollama server. This is the URL Ollama is running on. If you are running APIMyLlama on the same system as you are running Ollama on. You will put 'http://localhost:11434' If you changed the port you can put your port instead of '11434'. If you are running Ollama on a different server/device (This also applies to virtualized machines). You will need to get the IP of the device and then put it like this 'http://<YOUR_SERVER_IP>:11434'. If you changed the port then you can put your port here instead of '11434'. This last thing applies to running Ollama and APIMyLlama on 2 different systems. If you are doing this. You will NEED to run Ollama to listen on ALL interfaces. You can do this on Windows or Linux like shown below.
Let Ollama Listen on all interfaces (Only applies if you are using 2 different systems for the APIMyLlama server and Ollama.)
Windows: For Windows you can set a System Environment Variable. The variable and the value are listed below.
Variable: OLLAMA_HOST
Value: 0.0.0.0
Linux: For Linux you can edit the service file for Ollama. Open /etc/systemd/system/ollama.service and add the following line inside the [Service] section
Environment="OLLAMA_HOST=0.0.0.0"
On Linux you can also just run the command below to listen on all interfaces if that is easier for you. However you will need to run Ollama with this command everytime you start it up if you want to use APIMyLlama.
OLLAMA_HOST=0.0.0.0 ollama serve
These are the commands you can use in the APIMyLlama application
generatekeyThis command will generate a key using Cryptography and save it to the local database.
listkeyThis command will list all API Keys in the database.
removekey <API_KEY>This command will remove any key from the database.
addkey <API_KEY>You can add custom keys if wanted. (DO with CAUTION as it may be unsafe)
changeport <SERVER_PORT>You can change the servers port in realtime without having to restart the application.
changeollamaurl <YOUR_OLLAMA_SERVER_URL>You can change the Ollama Server url if you have a custom one set. By default it is "http://localhost:11434".
addwebhook <YOUR_WEBHOOK>You can add webhooks for alerts when a new request is made. EX. Discord Webhook
listwebhooksThis command will list all the webhooks you have attached to your system.
deletewebhook <ID_OF_WEBHOOK_IN_DATABASE>This command can be used to remove a webhook in your system. You can get the ID of the webhook using the 'listwebhooks' command.
ratelimit <API_KEY> <RATE_LIMIT>This command allows you to change the ratelimit on a key. By default it is 10. The rate limit is by minute. So for example the default allows 10 requests to the API per minute.
deactivatekey <API_KEY>Allows you to deactivate an API key. This will make the key useless untill it is activated.
activatekey <API_KEY>Activates a API key that has been deactivated in the past.
addkeydescription <API_KEY>This command lets you add a description to a key to help you decipher what key does what.
listkeydescription <API_KEY>This command lists the description of that key if it has a description.
generatekeys <number>Quickly generate multiple new API keys.
regeneratekey <API_KEY>Regenerate any specified API key without affecting other details.
activateallkeysActivate all your API keys with a single command.
deactivateallkeysDeactivate all your API keys with a single command.
getkeyinfo <API_KEY>Retrieve detailed information about a specific API key.
listactivekeysEasily list all active API keys.
listinactivekeysEasily list all inactive API keys.
Install APIMyLlama packages with NPM (Node.JS), PIP (Python), Jitpack Repo+Gradle or Maven (Java), or from the Crates Repository (Rust)
NPM Install (Node.JS)
cd PROJECT_NAME
npm install apimyllama-node-packagePIP Install (Python)
cd PROJECT_NAME
pip install apimyllamaJitpack+Gradle Repository <build.gradle> (Java IF YOUR USING GRADLE)
dependencyResolutionManagement {
repositoriesMode.set(RepositoriesMode.FAIL_ON_PROJECT_REPOS)
repositories {
mavenCentral()
maven { url 'https://www.jitpack.io' }
}
}Jitpack+Gradle Dependency <build.gradle> (Java IF YOUR USING GRADLE)
dependencies {
implementation 'com.github.Gimer-Studios:APIMyLlama-Java-Package:V2.0.5'
}Jitpack+Maven Repository <pom.xml> (Java IF YOUR USING MAVEN)
<repositories>
<repository>
<id>jitpack.io</id>
<url>https://www.jitpack.io</url>
</repository>
</repositories>Jitpack+Maven Dependency <pom.xml> (Java IF YOUR USING MAVEN)
<dependency>
<groupId>com.github.Gimer-Studios</groupId>
<artifactId>APIMyLlama-Java-Package</artifactId>
<version>V2.0.5</version>
</dependency>Crate Repository <Cargo.toml> (Rust)
[dependencies]
apimyllama = "2.0.7"
tokio = { version = "1", features = ["full"] }Node.JS example:
const apiMyLlamaNodePackage = require('apimyllama-node-package');
// Intialize Parameters
const apikey = 'API_KEY';
const prompt = 'Hello!';
const model = 'llama3';
const ip = 'SERVER_IP';
const port = 'SERVER_PORT';
const stream = false;
apiMyLlamaNodePackage.generate(apikey, prompt, model, ip, port, stream)
.then(response => console.log(response))
.catch(error => console.error(error));Python example:
import requests
from apimyllama import ApiMyLlama
def main():
ip = "SERVER_IP"
port = "PORT_NUMBER"
apikey = "API_KEY"
prompt = "Hello"
model = "llama3"
api = ApiMyLlama(ip, port)
try:
result = api.generate(apikey, prompt, model)
print("API Response:", result)
except requests.RequestException as e:
print("An error occurred:", e)
if __name__ == "__main__":
main()Java Example:
import com.gimerstudios.apimyllama.ApiMyLlama;
import java.io.IOException;
public class TestAPIMyLlama {
public static void main(String[] args) {
String serverIp = "SERVER_IP";
int serverPort = SERVER_PORT;
String apiKey = "API_KEY";
String prompt = "Hello!";
String model = "llama3";
boolean stream = false;
ApiMyLlama apiMyLlama = new ApiMyLlama(serverIp, serverPort);
try {
String response = apiMyLlama.generate(apiKey, prompt, model, stream);
System.out.println("Generate Response: " + response);
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
}Rust Example:
use apimyllama::ApiMyLlama;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let server_ip = "127.0.0.1".to_string();
let server_port = 3000;
let api_key = "api";
let api = ApiMyLlama::new(server_ip, server_port);
let prompt = "Hello!";
let model = "llama3";
match api.generate(api_key, prompt, model, false).await {
Ok(response) => {
println!("Response: {}", response.response);
println!("Model: {}", response.model);
println!("Created At: {}", response.created_at);
println!("Done: {}", response.done);
println!("Done Reason: {}", response.done_reason);
println!("Context: {:?}", response.context);
println!("Total Duration: {}", response.total_duration);
println!("Load Duration: {}", response.load_duration);
println!("Prompt Eval Duration: {}", response.prompt_eval_duration);
println!("Eval Count: {}", response.eval_count);
println!("Eval Duration: {}", response.eval_duration);
}
Err(e) => println!("Text generation failed: {}", e),
}
Ok(())
}The packages have built in health checking command (AS OF V2) If you already have the Node.js or Python packages installed then you can just copy and paste the code below to test.
Node.JS example:
const apiMyLlamaNodePackage = require('apimyllama-node-package');
// Intialize Parameters
const apikey = 'API_KEY';
const ip = 'SERVER_IP';
const port = 'SERVER_PORT';
apiMyLlamaNodePackage.getHealth(apikey, ip, port)
.then(response => console.log('Health Check Response:', response))
.catch(error => console.error('Error:', error));Python example:
import requests
from apimyllama import ApiMyLlama
ip = 'YOUR_SERVER_IP'
port = 'YOUR_SERVER_PORT'
apikey = 'YOUR_API_KEY'
api = ApiMyLlama(ip, port)
try:
health = api.get_health(apikey)
print("Health Check Response:", health)
except requests.RequestException as error:
print("Error:", error)Java example:
import com.gimerstudios.apimyllama.ApiMyLlama;
import java.io.IOException;
import java.util.Map;
public class TestAPIMyLlama {
public static void main(String[] args) {
String serverIp = "SERVER_IP";
int serverPort = SERVER_PORT;
String apiKey = "API_KEY";
ApiMyLlama apiMyLlama = new ApiMyLlama(serverIp, serverPort);
try {
Map<String, Object> healthStatus = apiMyLlama.getHealth(apiKey);
System.out.println("Health Status: " + healthStatus);
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
}Rust Example:
use apimyllama::ApiMyLlama;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let server_ip = "127.0.0.1".to_string();
let server_port = 3000;
let api_key = "api";
let api = ApiMyLlama::new(server_ip, server_port);
match api.get_health(api_key).await {
Ok(response) => {
println!("API Health Status: {}", response.status);
println!("Timestamp: {}", response.timestamp);
}
Err(e) => println!("Health check failed: {}", e),
}
Ok(())
}ApiMyLlama(ip, port)
ip: IP address of the APIMyLlama server.
port: Port number on which the APIMyLlama server is running.
api.generate(apiKey, prompt, model, stream)
api.get_health(apikey)
apiKey: API key for accessing the Ollama API.
prompt: Text prompt to generate a response.
model: Machine learning model to use for text generation.
stream: Boolean indicating whether to stream the response.
If there are any issues please make a Github Issue Report. To get quicker support join our discord server. -Discord Server If there are any feature requests you may request them in the discord server. PLEASE NOTE this project is still in EARLY BETA.
We now have a Ko-fi open if you would like to help and donate to the project. We love to keep it free and open source when possible and donating helps a lot.
You most likely forgot to run the 'npm install' command after cloning the repository.
You probably didn't port foward. And if you did your router may have not intialized the changes yet or applied them.
3. Ollama Serve command error "Error: listen tcp 127.0.0.1:11434: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted."
If you get this error just close the Ollama app through the system tray on Windows. And if your on Linux just use systemctl to stop the Ollama process. Once done you can try running the ollama serve command again.
If you have a custom port set for your Ollama server this is a simple fix. Just run the 'changeollamaurl <YOUR_OLLAMA_SERVER_URL>' and change it to the url your Ollama server is running on. By default it is "http://localhost:11434" but if you changed it you will need to do this. You can also fix this problem through changing the port in the ollamaURL.conf file.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for APIMyLlama
Similar Open Source Tools
APIMyLlama
APIMyLlama is a server application that provides an interface to interact with the Ollama API, a powerful AI tool to run LLMs. It allows users to easily distribute API keys to create amazing things. The tool offers commands to generate, list, remove, add, change, activate, deactivate, and manage API keys, as well as functionalities to work with webhooks, set rate limits, and get detailed information about API keys. Users can install APIMyLlama packages with NPM, PIP, Jitpack Repo+Gradle or Maven, or from the Crates Repository. The tool supports Node.JS, Python, Java, and Rust for generating responses from the API. Additionally, it provides built-in health checking commands for monitoring API health status.

lollms
LoLLMs Server is a text generation server based on large language models. It provides a Flask-based API for generating text using various pre-trained language models. This server is designed to be easy to install and use, allowing developers to integrate powerful text generation capabilities into their applications.
lollms_legacy
Lord of Large Language Models (LoLLMs) Server is a text generation server based on large language models. It provides a Flask-based API for generating text using various pre-trained language models. This server is designed to be easy to install and use, allowing developers to integrate powerful text generation capabilities into their applications. The tool supports multiple personalities for generating text with different styles and tones, real-time text generation with WebSocket-based communication, RESTful API for listing personalities and adding new personalities, easy integration with various applications and frameworks, sending files to personalities, running on multiple nodes to provide a generation service to many outputs at once, and keeping data local even in the remote version.

suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.

neocodeium
NeoCodeium is a free AI completion plugin powered by Codeium, designed for Neovim users. It aims to provide a smoother experience by eliminating flickering suggestions and allowing for repeatable completions using the `.` key. The plugin offers performance improvements through cache techniques, displays suggestion count labels, and supports Lua scripting. Users can customize keymaps, manage suggestions, and interact with the AI chat feature. NeoCodeium enhances code completion in Neovim, making it a valuable tool for developers seeking efficient coding assistance.

langserve
LangServe helps developers deploy `LangChain` runnables and chains as a REST API. This library is integrated with FastAPI and uses pydantic for data validation. In addition, it provides a client that can be used to call into runnables deployed on a server. A JavaScript client is available in LangChain.js.
agent-mimir
Agent Mimir is a command line and Discord chat client 'agent' manager for LLM's like Chat-GPT that provides the models with access to tooling and a framework with which accomplish multi-step tasks. It is easy to configure your own agent with a custom personality or profession as well as enabling access to all tools that are compatible with LangchainJS. Agent Mimir is based on LangchainJS, every tool or LLM that works on Langchain should also work with Mimir. The tasking system is based on Auto-GPT and BabyAGI where the agent needs to come up with a plan, iterate over its steps and review as it completes the task.
shortest
Shortest is an AI-powered natural language end-to-end testing framework built on Playwright. It provides a seamless testing experience by allowing users to write tests in natural language and execute them using Anthropic Claude API. The framework also offers GitHub integration with 2FA support, making it suitable for testing web applications with complex authentication flows. Shortest simplifies the testing process by enabling users to run tests locally or in CI/CD pipelines, ensuring the reliability and efficiency of web applications.

simpleAI
SimpleAI is a self-hosted alternative to the not-so-open AI API, focused on replicating main endpoints for LLM such as text completion, chat, edits, and embeddings. It allows quick experimentation with different models, creating benchmarks, and handling specific use cases without relying on external services. Users can integrate and declare models through gRPC, query endpoints using Swagger UI or API, and resolve common issues like CORS with FastAPI middleware. The project is open for contributions and welcomes PRs, issues, documentation, and more.
fish-ai
fish-ai is a tool that adds AI functionality to Fish shell. It can be integrated with various AI providers like OpenAI, Azure OpenAI, Google, Hugging Face, Mistral, or a self-hosted LLM. Users can transform comments into commands, autocomplete commands, and suggest fixes. The tool allows customization through configuration files and supports switching between contexts. Data privacy is maintained by redacting sensitive information before submission to the AI models. Development features include debug logging, testing, and creating releases.

llm-vscode
llm-vscode is an extension designed for all things LLM, utilizing llm-ls as its backend. It offers features such as code completion with 'ghost-text' suggestions, the ability to choose models for code generation via HTTP requests, ensuring prompt size fits within the context window, and code attribution checks. Users can configure the backend, suggestion behavior, keybindings, llm-ls settings, and tokenization options. Additionally, the extension supports testing models like Code Llama 13B, Phind/Phind-CodeLlama-34B-v2, and WizardLM/WizardCoder-Python-34B-V1.0. Development involves cloning llm-ls, building it, and setting up the llm-vscode extension for use.

generative-ai
The 'Generative AI' repository provides a C# library for interacting with Google's Generative AI models, specifically the Gemini models. It allows users to access and integrate the Gemini API into .NET applications, supporting functionalities such as listing available models, generating content, creating tuned models, working with large files, starting chat sessions, and more. The repository also includes helper classes and enums for Gemini API aspects. Authentication methods include API key, OAuth, and various authentication modes for Google AI and Vertex AI. The package offers features for both Google AI Studio and Google Cloud Vertex AI, with detailed instructions on installation, usage, and troubleshooting.

consult-llm-mcp
Consult LLM MCP is an MCP server that enables users to consult powerful AI models like GPT-5.2, Gemini 3.0 Pro, and DeepSeek Reasoner for complex problem-solving. It supports multi-turn conversations, direct queries with optional file context, git changes inclusion for code review, comprehensive logging with cost estimation, and various CLI modes for Gemini and Codex. The tool is designed to simplify the process of querying AI models for assistance in resolving coding issues and improving code quality.
perplexity-ai
Perplexity is a module that utilizes emailnator to generate new accounts, providing users with 5 pro queries per account creation. It enables the creation of new Gmail accounts with emailnator, ensuring unlimited pro queries. The tool requires specific Python libraries for installation and offers both a web interface and an API for different usage scenarios. Users can interact with the tool to perform various tasks such as account creation, query searches, and utilizing different modes for research purposes. Perplexity also supports asynchronous operations and provides guidance on obtaining cookies for account usage and account generation from emailnator.

chat-ui
A chat interface using open source models, eg OpenAssistant or Llama. It is a SvelteKit app and it powers the HuggingChat app on hf.co/chat.

Gemini-API
Gemini-API is a reverse-engineered asynchronous Python wrapper for Google Gemini web app (formerly Bard). It provides features like persistent cookies, ImageFx support, extension support, classified outputs, official flavor, and asynchronous operation. The tool allows users to generate contents from text or images, have conversations across multiple turns, retrieve images in response, generate images with ImageFx, save images to local files, use Gemini extensions, check and switch reply candidates, and control log level.
For similar tasks
APIMyLlama
APIMyLlama is a server application that provides an interface to interact with the Ollama API, a powerful AI tool to run LLMs. It allows users to easily distribute API keys to create amazing things. The tool offers commands to generate, list, remove, add, change, activate, deactivate, and manage API keys, as well as functionalities to work with webhooks, set rate limits, and get detailed information about API keys. Users can install APIMyLlama packages with NPM, PIP, Jitpack Repo+Gradle or Maven, or from the Crates Repository. The tool supports Node.JS, Python, Java, and Rust for generating responses from the API. Additionally, it provides built-in health checking commands for monitoring API health status.
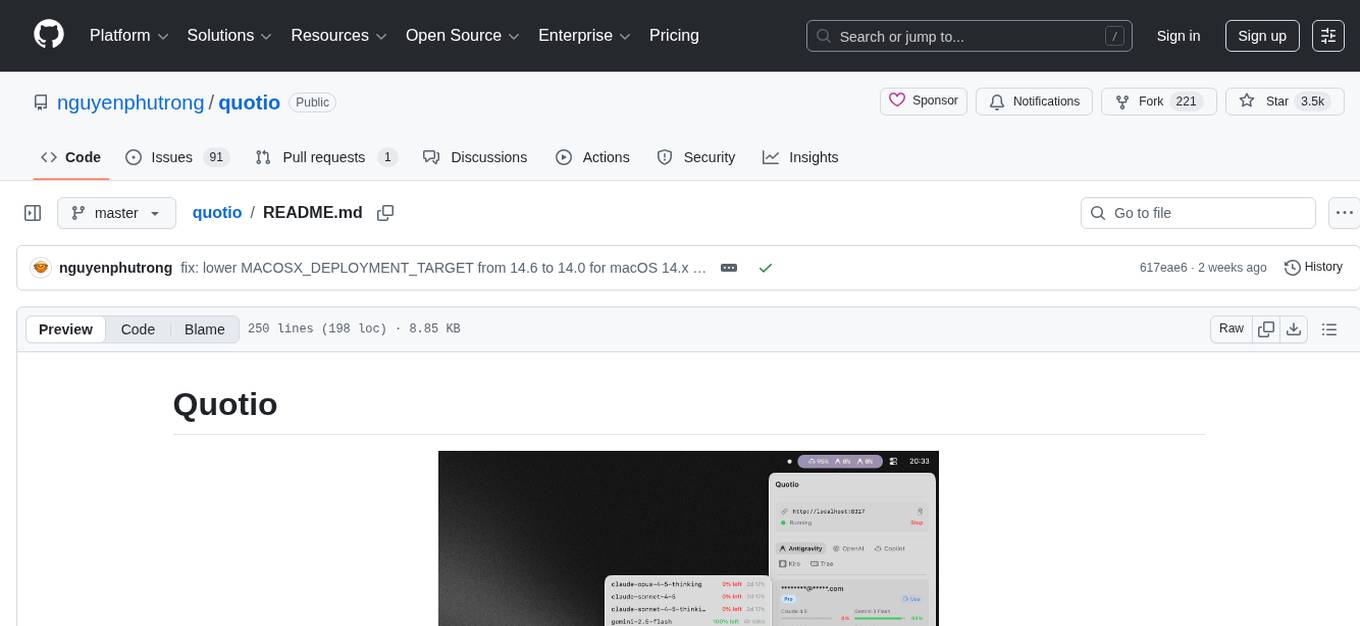
quotio
Quotio is a native macOS application designed as the ultimate command center for managing CLIProxyAPI, a local proxy server that powers AI coding agents. It allows users to connect multiple AI accounts, track quotas, configure CLI tools, and monitor request traffic in real-time. With features like multi-provider support, standalone quota mode, one-click agent configuration, real-time dashboard, smart quota management, API key management, menu bar integration, notifications, auto-update, and multilingual support, Quotio offers a comprehensive solution for AI coding assistants on macOS.
LinJun
LinJun is a native desktop application for managing CLIProxyAPIPlus, a local proxy server that powers AI coding agents. It helps manage multiple AI accounts, track quotas, and configure CLI tools across macOS, Windows, and Linux. The tool offers features like expanded provider support, quota and model visibility, provider-aware model filtering, large log performance, one-click agent configuration, live dashboard monitoring, smart routing, API key management, system tray integration, and multilingual support. It supports various AI providers and compatible CLI agents, and provides installation instructions, usage guidelines, screenshots, settings customization, architecture overview, tech stack details, token storage information, FAQs, contribution guidelines, and license details.
chatgpt-web-sea
ChatGPT Web Sea is an open-source project based on ChatGPT-web for secondary development. It supports all models that comply with the OpenAI interface standard, allows for model selection, configuration, and extension, and is compatible with OneAPI. The tool includes a Chinese ChatGPT tuning guide, supports file uploads, and provides model configuration options. Users can interact with the tool through a web interface, configure models, and perform tasks such as model selection, API key management, and chat interface setup. The project also offers Docker deployment options and instructions for manual packaging.
farfalle
Farfalle is an open-source AI-powered search engine that allows users to run their own local LLM or utilize the cloud. It provides a tech stack including Next.js for frontend, FastAPI for backend, Tavily for search API, Logfire for logging, and Redis for rate limiting. Users can get started by setting up prerequisites like Docker and Ollama, and obtaining API keys for Tavily, OpenAI, and Groq. The tool supports models like llama3, mistral, and gemma. Users can clone the repository, set environment variables, run containers using Docker Compose, and deploy the backend and frontend using services like Render and Vercel.
ComfyUI-Tara-LLM-Integration
Tara is a powerful node for ComfyUI that integrates Large Language Models (LLMs) to enhance and automate workflow processes. With Tara, you can create complex, intelligent workflows that refine and generate content, manage API keys, and seamlessly integrate various LLMs into your projects. It comprises nodes for handling OpenAI-compatible APIs, saving and loading API keys, composing multiple texts, and using predefined templates for OpenAI and Groq. Tara supports OpenAI and Grok models with plans to expand support to together.ai and Replicate. Users can install Tara via Git URL or ComfyUI Manager and utilize it for tasks like input guidance, saving and loading API keys, and generating text suitable for chaining in workflows.

conversational-agent-langchain
This repository contains a Rest-Backend for a Conversational Agent that allows embedding documents, semantic search, QA based on documents, and document processing with Large Language Models. It uses Aleph Alpha and OpenAI Large Language Models to generate responses to user queries, includes a vector database, and provides a REST API built with FastAPI. The project also features semantic search, secret management for API keys, installation instructions, and development guidelines for both backend and frontend components.

ChatGPT-Next-Web-Pro
ChatGPT-Next-Web-Pro is a tool that provides an enhanced version of ChatGPT-Next-Web with additional features and functionalities. It offers complete ChatGPT-Next-Web functionality, file uploading and storage capabilities, drawing and video support, multi-modal support, reverse model support, knowledge base integration, translation, customizations, and more. The tool can be deployed with or without a backend, allowing users to interact with AI models, manage accounts, create models, manage API keys, handle orders, manage memberships, and more. It supports various cloud services like Aliyun OSS, Tencent COS, and Minio for file storage, and integrates with external APIs like Azure, Google Gemini Pro, and Luma. The tool also provides options for customizing website titles, subtitles, icons, and plugin buttons, and offers features like voice input, file uploading, real-time token count display, and more.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.