Best AI tools for< Serve Model >
20 - AI tool Sites
Empower
Empower is a serverless fine-tuned LLM hosting platform that offers a developer platform for fine-tuned LLMs. It provides prebuilt task-specific base models with GPT4 level response quality, enabling users to save up to 80% on LLM bills with just 5 lines of code change. Empower allows users to own their models, offers cost-effective serving with no compromise on performance, and charges on a per-token basis. The platform is designed to be user-friendly, efficient, and cost-effective for deploying and serving fine-tuned LLMs.

vLLM
vLLM is a fast and easy-to-use library for LLM inference and serving. It offers state-of-the-art serving throughput, efficient management of attention key and value memory, continuous batching of incoming requests, fast model execution with CUDA/HIP graph, and various decoding algorithms. The tool is flexible with seamless integration with popular HuggingFace models, high-throughput serving, tensor parallelism support, and streaming outputs. It supports NVIDIA GPUs and AMD GPUs, Prefix caching, and Multi-lora. vLLM is designed to provide fast and efficient LLM serving for everyone.
Backend.AI
Backend.AI is an enterprise-scale cluster backend for AI frameworks that offers scalability, GPU virtualization, HPC optimization, and DGX-Ready software products. It provides a fast and efficient way to build, train, and serve AI models of any type and size, with flexible infrastructure options. Backend.AI aims to optimize backend resources, reduce costs, and simplify deployment for AI developers and researchers. The platform integrates seamlessly with existing tools and offers fractional GPU usage and pay-as-you-play model to maximize resource utilization.
Meteron AI
Meteron AI is an all-in-one AI toolset that helps developers build AI-powered products faster and easier. It provides a simple, yet powerful metering mechanism, elastic scaling, unlimited storage, and works with any model. With Meteron, developers can focus on building AI products instead of worrying about the underlying infrastructure.
BentoML
BentoML is a platform for software engineers to build, ship, and scale AI products. It provides a unified AI application framework that makes it easy to manage and version models, create service APIs, and build and run AI applications anywhere. BentoML is used by over 1000 organizations and has a global community of over 3000 members.
Baseten
Baseten is a machine learning infrastructure that provides a unified platform for data scientists and engineers to build, train, and deploy machine learning models. It offers a range of features to simplify the ML lifecycle, including data preparation, model training, and deployment. Baseten also provides a marketplace of pre-built models and components that can be used to accelerate the development of ML applications.
Anyscale
Anyscale is a company that provides a scalable compute platform for AI and Python applications. Their platform includes a serverless API for serving and fine-tuning open LLMs, a private cloud solution for data privacy and governance, and an open source framework for training, batch, and real-time workloads. Anyscale's platform is used by companies such as OpenAI, Uber, and Spotify to power their AI workloads.
Seldon
Seldon is an MLOps platform that helps enterprises deploy, monitor, and manage machine learning models at scale. It provides a range of features to help organizations accelerate model deployment, optimize infrastructure resource allocation, and manage models and risk. Seldon is trusted by the world's leading MLOps teams and has been used to install and manage over 10 million ML models. With Seldon, organizations can reduce deployment time from months to minutes, increase efficiency, and reduce infrastructure and cloud costs.
Predibase
Predibase is a platform for fine-tuning and serving Large Language Models (LLMs). It provides a cost-effective and efficient way to train and deploy LLMs for a variety of tasks, including classification, information extraction, customer sentiment analysis, customer support, code generation, and named entity recognition. Predibase is built on proven open-source technology, including LoRAX, Ludwig, and Horovod.
EnterpriseAI
EnterpriseAI is an advanced computing platform that focuses on the intersection of high-performance computing (HPC) and artificial intelligence (AI). The platform provides in-depth coverage of the latest developments, trends, and innovations in the AI-enabled computing landscape. EnterpriseAI offers insights into various sectors such as financial services, government, healthcare, life sciences, energy, manufacturing, retail, and academia. The platform covers a wide range of topics including AI applications, security, data storage, networking, and edge/IoT technologies.

LiteLLM
LiteLLM is a platform that simplifies model access, spend tracking, and fallbacks across 100+ LLMs. It provides a gateway to manage model access and offers features like logging, budget tracking, pass-through endpoints, and self-serve key management. LiteLLM is open-source and compatible with the OpenAI format, allowing users to access various LLMs seamlessly.
Tecton
Tecton is an AI data platform that helps build smarter AI applications by simplifying feature engineering, generating training data, serving real-time data, and enhancing AI models with context-rich prompts. It automates data pipelines, improves model accuracy, and lowers production costs, enabling faster deployment of AI models. Tecton abstracts away data complexity, provides a developer-friendly experience, and allows users to create features from any source. Trusted by top engineering teams, Tecton streamlines ML delivery processes, improves customer interactions, and automates release processes through CI/CD pipelines.
ASI Platform - Prescience
The ASI Platform, specifically the Prescience Platform, is an industry-proven AI tool designed for mission-critical operations. It offers data fusion, domain modeling, prediction, optimization, communications, and replay functionalities to help organizations anticipate and act with confidence in their operations. The platform enables seamless integration of data sources, provides predictive situational awareness, supports collaboration across operations, and allows for comprehensive retrospective analysis.
AiPlus
AiPlus is an AI tool designed to serve as a cost-efficient model gateway. It offers users a platform to access and utilize various AI models for their projects and tasks. With AiPlus, users can easily integrate AI capabilities into their applications without the need for extensive development or resources. The tool aims to streamline the process of leveraging AI technology, making it accessible to a wider audience.
Radicalbit
Radicalbit is an MLOps and AI Observability platform that helps businesses deploy, serve, observe, and explain their AI models. It provides a range of features to help data teams maintain full control over the entire data lifecycle, including real-time data exploration, outlier and drift detection, and model monitoring in production. Radicalbit can be seamlessly integrated into any ML stack, whether SaaS or on-prem, and can be used to run AI applications in minutes.
Humley
Humley is a Conversational AI platform that allows users to build and launch AI assistants in under an hour. The platform provides a no-code environment for creating self-serve experiences and managing AI outputs. Humley aims to revolutionize customer experiences and boost efficiencies by making Conversational AI accessible and safe for all users. With features like Knowledge Search, Build Flows, Integrate with Systems, Capture Feedback, and Multi-Channel Support, Humley Studio offers a comprehensive toolkit for creating engaging conversational experiences. The platform empowers businesses to deliver exceptional customer service, streamline access to AI models, and improve operational efficiencies.
Modal
Modal is a high-performance cloud platform designed for developers, AI data, and ML teams. It offers a serverless environment for running generative AI models, large-scale batch jobs, job queues, and more. With Modal, users can bring their own code and leverage the platform's optimized container file system for fast cold boots and seamless autoscaling. The platform is engineered for large-scale workloads, allowing users to scale to hundreds of GPUs, pay only for what they use, and deploy functions to the cloud in seconds without the need for YAML or Dockerfiles. Modal also provides features for job scheduling, web endpoints, observability, and security compliance.
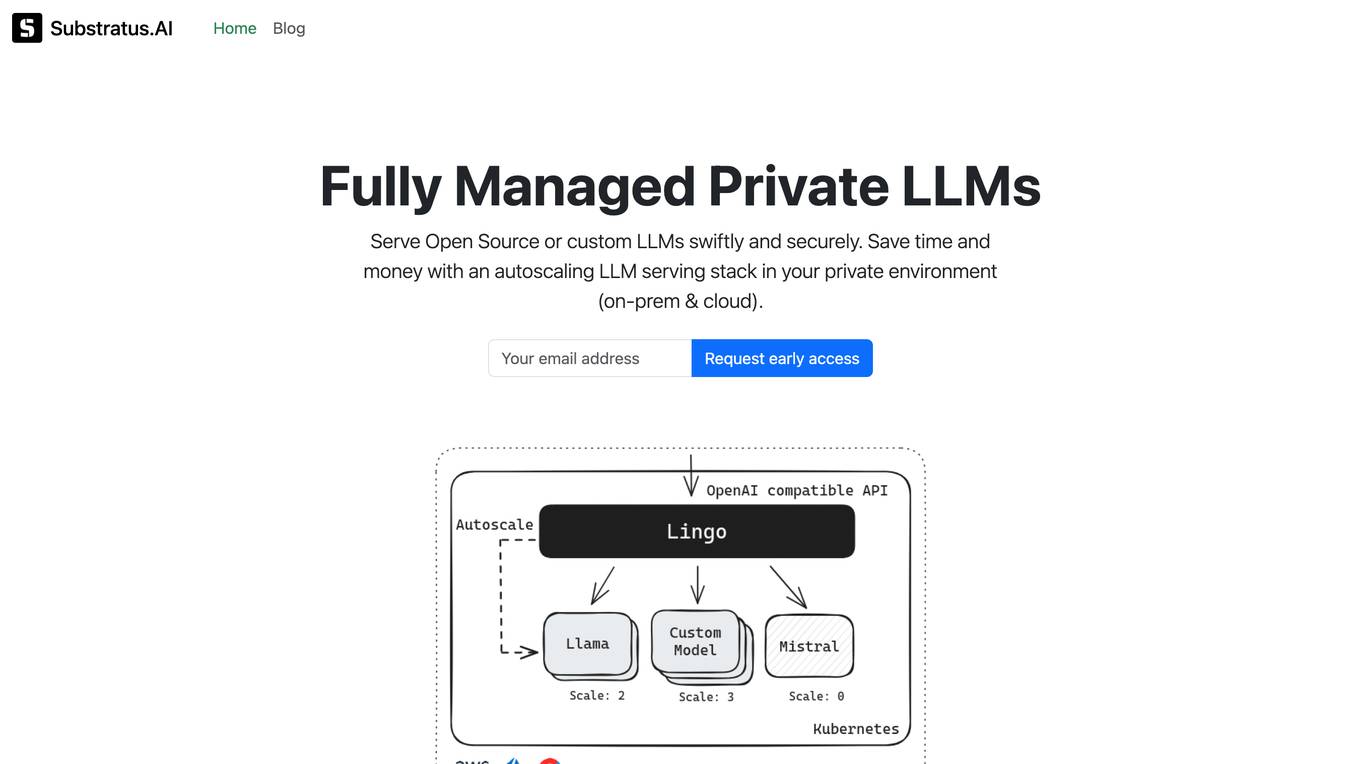
Substratus.AI
Substratus.AI is a fully managed private LLMs platform that allows users to serve LLMs (Llama and Mistral) in their own cloud account. It enables users to keep control of their data while reducing OpenAI costs by up to 10x. With Substratus.AI, users can utilize LLMs in production in hours instead of weeks, making it a convenient and efficient solution for AI model deployment.

Intuz
Intuz is an AI, IoT, Mobile & Web Development Services Company that empowers businesses with AI-enabled solutions. They have delivered over 1700 successful projects to enterprise, SMEs, and Fortune 500 clients globally. Intuz offers services such as AI development, IoT solutions, mobile app development, web applications, and enterprise app development. They serve various industries with use-case specific AI and IoT services, including Consumer Electronics, EV & Green Energy, Smart Manufacturing, Fleet Management & Supply Chain, and Smart Factory & Plants.
Dappier
Dappier is a platform that enables publishers and AI developers to monetize their content by creating branded AI agents and syndicating trusted, rights-cleared data. Users can easily connect their data sources, transform content for AI interaction, and launch custom AI agents for natural search and content recommendations. The platform offers a self-serve fine-tuning platform and a marketplace for syndicating content to AI developers, enabling users to generate new revenue streams. Dappier prioritizes data security and privacy, ensuring that training data is never shared with external parties.
2 - Open Source AI Tools

vllm
vLLM is a fast and easy-to-use library for LLM inference and serving. It is designed to be efficient, flexible, and easy to use. vLLM can be used to serve a variety of LLM models, including Hugging Face models. It supports a variety of decoding algorithms, including parallel sampling, beam search, and more. vLLM also supports tensor parallelism for distributed inference and streaming outputs. It is open-source and available on GitHub.
lightning-lab
Lightning Lab is a public template for artificial intelligence and machine learning research projects using Lightning AI's PyTorch Lightning. It provides a structured project layout with modules for command line interface, experiment utilities, Lightning Module and Trainer, data acquisition and preprocessing, model serving APIs, project configurations, training checkpoints, technical documentation, logs, notebooks for data analysis, requirements management, testing, and packaging. The template simplifies the setup of deep learning projects and offers extras for different domains like vision, text, audio, reinforcement learning, and forecasting.
20 - OpenAI Gpts
Create A Business Model Canvas For Your Business
Let's get started by telling me about your business: What do you offer? Who do you serve? ------------------------------------------------------- Need help Prompt Engineering? Reach out on LinkedIn: StephenHnilica
Il King del Fantacalcio - Esperto di Serie A
Analisi dettagliate e statistiche per il fantacalcio. Strategie, formazioni vincenti, e suggerimenti di mercato per la Serie A. Perfetto per chi cerca il podio nel proprio campionato. Aggiornamenti continui sui giocatori, performance e infortuni. Tutto quello che serve per la tua squadra ideale


Buildwell AI - UK Construction Regs Assistant
Provides Construction Support relating to Planning Permission, Building Regulations, Party Wall Act and Fire Safety in the UK. Obtain instant Guidance for your Construction Project.
World Animals Flight Attendant Uniform
Enjoy the world of anthropomorphic animals and enjoy a banquet in flight attendant uniforms
SQL Server assistant
Expert in SQL Server for database management, optimization, and troubleshooting.
Baci's AI Server
An AI waiter for Baci Bistro & Bar, knowledgeable about the menu and ready to assist.
Software expert
Server admin expert in cPanel, Softaculous, WHM, WordPress, and Elementor Pro.
アダチさん13号(SQLServer篇)
安達孝一さんがSE時代に蓄積してきた、SQL Serverのナレッジやノウハウ等 (SQL Server 2000/2005/2008/2012) について、ご質問頂けます。また、対話内容を基に、ChatGPT(GPT-4)向けの、汎用的な質問文例も作成できます。





CraftGPT
Your expert Minecraft server Java plugin assistant. Whether you're learning the ropes or are an experienced developer, I'm here to help you with Java concepts, coding examples, and any queries you have about Minecraft plugin development.
Gourmet GPT
As a high-class server, I describe dishes with luxury and elegance. Just upload your picture!

Bun Nook Kit App Builder
Expert in BNK server setup, typesafe routes, htmlody, and creating SQLite schemas with BNK.