
verifiers
Verifiers for LLM Reinforcement Learning
Stars: 2918

Verifiers is a library of modular components for creating RL environments and training LLM agents. It includes an async GRPO implementation built around the `transformers` Trainer, is supported by `prime-rl` for large-scale FSDP training, and can easily be integrated into any RL framework which exposes an OpenAI-compatible inference client. The library provides tools for creating and evaluating RL environments, training LLM agents, and leveraging OpenAI-compatible models for various tasks. Verifiers aims to be a reliable toolkit for building on top of, minimizing fork proliferation in the RL infrastructure ecosystem.
README:
Verifiers is a library of modular components for creating RL environments and training LLM agents. Environments built with Verifiers can be used directly as LLM evaluations, synthetic data pipelines, or agent harnesses for any OpenAI-compatible model endpoint, in addition to RL training. Verifiers includes an async GRPO implementation built around the transformers Trainer, is supported by prime-rl for large-scale FSDP training, and can easily be integrated into any RL framework which exposes an OpenAI-compatible inference client.
Full documentation is available here.
We recommend using verifiers with along uv for dependency management in your own project:
curl -LsSf https://astral.sh/uv/install.sh | sh
uv init # create a fresh project
source .venv/bin/activateFor local (CPU) development and evaluation with API models, do:
uv add verifiers # uv add 'verifiers[dev]' for Jupyter + testing supportFor training on GPUs with vf.GRPOTrainer, do:
uv add 'verifiers[all]' && uv pip install flash-attn --no-build-isolationTo use the latest main branch, do:
uv add verifiers @ git+https://github.com/willccbb/verifiers.gitTo use with prime-rl, see here.
To install verifiers from source for core library development, do:
git clone https://github.com/willccbb/verifiers.git
cd verifiers
uv sync --all-extras && uv pip install flash-attn --no-build-isolation
uv run pre-commit installIn general, we recommend that you build and train Environments with verifiers, not in verifiers. If you find yourself needing to clone and modify the core library in order to implement key functionality for your project, we'd love for you to open an issue so that we can try and streamline the development experience. Our aim is for verifiers to be a reliable toolkit to build on top of, and to minimize the "fork proliferation" which often pervades the RL infrastructure ecosystem.
Environments in Verifiers are installable Python modules which can specify dependencies in a pyproject.toml, and which expose a load_environment function for instantiation by downstream applications (e.g. trainers). See environments/ for examples.
To initialize a blank Environment module template, do:
vf-init vf-environment-name # -p /path/to/environments (defaults to "./environments")To an install an Environment module into your project, do:
vf-install vf-environment-name # -p /path/to/environments (defaults to "./environments") To install an Environment module from this repo's environments folder, do:
vf-install vf-math-python --from-repo # -b branch_or_commit (defaults to "main")Once an Environment module is installed, you can create an instance of the Environment using load_environment, passing any necessary args:
import verifiers as vf
vf_env = vf.load_environment("vf-environment-name", **env_args)To run a quick evaluation of your Environment with an API-based model, do:
vf-eval vf-environment-name # vf-eval -h for config options; defaults to gpt-4.1-mini, 5 prompts, 3 rollouts for eachThe core elements of Environments in are:
- Datasets: a Hugging Face
Datasetwith apromptcolumn for inputs, and optionallyanswer (str)orinfo (dict)columns for evaluation (both can be omitted for environments that evaluate based solely on completion quality) - Rollout logic: interactions between models and the environment (e.g.
env_response+is_completedfor anyMultiTurnEnv) - Rubrics: an encapsulation for one or more reward functions
- Parsers: optional; an encapsulation for reusable parsing logic
We support both /v1/chat/completions-style and /v1/completions-style inference via OpenAI clients, though we generally recommend /v1/chat/completions-style inference for the vast majority of applications. Both the included GRPOTrainer as well as prime-rl support the full set of SamplingParams exposed by vLLM (via their OpenAI-compatible server interface), and leveraging this will often be the appropriate way to implement rollout strategies requiring finer-grained control, such as interrupting and resuming generations for interleaved tool use, or enforcing reasoning budgets.
The primary constraint we impose on rollout logic is that token sequences must be increasing, i.e. once a token has been added to a model's context in a rollout, it must remain as the rollout progresses. Note that this causes issues with some popular reasoning models such as the Qwen3 and DeepSeek-R1-Distill series; see Footguns for guidance on adapting these models to support multi-turn rollouts.
For tasks requiring only a single response from a model for each prompt, you can use SingleTurnEnv directly by specifying a Dataset and a Rubric. Rubrics are sets of reward functions, which can be either sync or async.
from datasets import load_dataset
import verifiers as vf
dataset = load_dataset("my-account/my-dataset", split="train")
def reward_A(prompt, completion, info) -> float:
# reward fn, e.g. correctness
...
def reward_B(parser, completion) -> float:
# auxiliary reward fn, e.g. format
...
async def metric(completion) -> float:
# non-reward metric, e.g. proper noun count
...
rubric = vf.Rubric(funcs=[reward_A, reward_B, metric], weights=[1.0, 0.5, 0.0])
vf_env = SingleTurnEnv(
dataset=dataset,
rubric=rubric
)
results = vf_env.evaluate(client=OpenAI(), model="gpt-4.1-mini", num_examples=100, rollouts_per_example=1)
vf_env.make_dataset(results) # HF dataset formatDatasets should be formatted with columns for:
-
'prompt' (List[ChatMessage])OR'question' (str)fields-
ChatMessage= e.g.{'role': 'user', 'content': '...'} - if
questionis set instead ofprompt, you can also passsystem_prompt (str)and/orfew_shot (List[ChatMessage])
-
-
answer (str)AND/ORinfo (dict)(both optional, can be omitted entirely) -
task (str): optional, used byEnvGroupandRubricGroupfor orchestrating composition of Environments and Rubrics
The following named attributes available for use by reward functions in your Rubric:
-
prompt: sequence of input messages -
completion: sequence of messages generated during rollout by model and Environment -
answer: primary answer column, optional (defaults to empty string if omitted) -
state: can be modified during rollout to accumulate any metadata (state['responses']includes full OpenAI response objects by default) -
info: auxiliary info needed for reward computation (e.g. test cases), optional (defaults to empty dict if omitted) -
task: tag for task type (used byEnvGroupandRubricGroup) -
parser: the parser object declared. Note:vf.Parser().get_format_reward_func()is a no-op (always 1.0); usevf.ThinkParseror a custom parser if you want a real format adherence reward.
Note: Some environments can fully evaluate using only prompt, completion, and state without requiring ground truth answer or info data. Examples include format compliance checking, completion quality assessment, or length-based rewards.
For tasks involving LLM judges, you may wish to use vf.JudgeRubric() for managing requests to auxiliary models.
Note on concurrency: environment APIs accept max_concurrent to control parallel rollouts. The vf-eval CLI currently exposes --max-concurrent-requests; ensure this maps to your environment’s concurrency as expected.
vf-eval also supports specifying sampling_args as a JSON object, which is sent to the vLLM inference engine:
vf-eval vf-environment-name --sampling-args '{"reasoning_effort": "low"}'Use vf-eval -s to save outputs as dataset-formatted JSON, and view all locally-saved eval results with vf-tui.
For many applications involving tool use, you can use ToolEnv to leverage models' native tool/function-calling capabilities in an agentic loop. Tools can be specified as generic Python functions (with type hints and docstrings), which will then be passed in JSON schema form to each inference request.
import verifiers as vf
vf_env = vf.ToolEnv(
dataset= ... # HF Dataset with 'prompt'/'question' and optionally 'answer'/'info' columns
rubric= ... # Rubric object; vf.ToolRubric() can be optionally used for counting tool invocations in each rollout
tools=[search_tool, read_article_tool, python_tool], # python functions with type hints + docstrings
max_turns=10
)In cases where your tools require heavy computational resources, we recommend hosting your tools as standalone servers (e.g. MCP servers) and creating lightweight wrapper functions to pass to ToolEnv. Parallel tool call support is enabled by default.
For training, or self-hosted endpoints, you'll want to enable auto tool choice in vLLM with the appropriate parser. If your model does not support native tool calling, you may find the XMLParser abstraction useful for rolling your own tool call parsing on top of MultiTurnEnv; see environments/xml_tool_env for an example.
Both SingleTurnEnv and ToolEnv are instances of MultiTurnEnv, which exposes an interface for writing custom Environment interaction protocols. The two methods you must override are
from typing import Tuple
import verifiers as vf
from verifiers.types import Messages, State
class YourMultiTurnEnv(vf.MultiTurnEnv):
def __init__(self,
dataset: Dataset,
rubric: Rubric,
max_turns: int,
**kwargs):
async def is_completed(self, messages: Messages, state: State, **kwargs) -> bool:
# return whether or not a rollout is completed
async def env_response(self, messages: Messages, state: State, **kwargs) -> Tuple[Messages, State]:
# return new environment message(s) + updated stateIf your application requires more fine-grained control than is allowed by MultiTurnEnv, you may want to inherit from the base Environment functionality directly and override the rollout method.
The included trainer (vf.GRPOTrainer) supports running GRPO-style RL training via Accelerate/DeepSpeed, and uses vLLM for inference. It supports both full-parameter finetuning, and is optimized for efficiently training dense transformer models on 2-16 GPUs.
# install environment
vf-install vf-wordle (-p /path/to/environments | --from-repo)
# quick eval
vf-eval vf-wordle -m (model_name in configs/endpoints.py) -n NUM_EXAMPLES -r ROLLOUTS_PER_EXAMPLE
# inference (shell 0)
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5 vf-vllm --model willcb/Qwen3-1.7B-Wordle \
--data-parallel-size 7 --enforce-eager --disable-log-requests
# training (shell 1)
CUDA_VISIBLE_DEVICES=6,7 accelerate launch --num-processes 2 \
--config-file configs/zero3.yaml examples/grpo/train_wordle.py --size 1.7BAlternatively, you can train environments with the external prime-rl project (FSDP-first orchestration). See the prime-rl README for installation and examples. For example:
# orchestrator config (prime-rl)
[environment]
id = "vf-math-python" # or your environment ID# run (prime-rl)
uv run rl \
--trainer @ configs/your_exp/train.toml \
--orchestrator @ configs/your_exp/orch.toml \
--inference @ configs/your_exp/infer.toml- Ensure your
wandbandhuggingface-clilogins are set up (or setreport_to=Noneintraining_args). You should also have something set as yourOPENAI_API_KEYin your environment (can be a dummy key for vLLM). - If using high max concurrency, increase the number of allowed open sockets (e.g.
ulimit -n 4096) - On some setups, inter-GPU communication can hang or crash during vLLM weight syncing. This can usually be alleviated by setting (or unsetting)
NCCL_P2P_DISABLE=1in your environment (or potentiallyNCCL_CUMEM_ENABLE=1). Try this as your first step if you experience NCCL-related issues. - If problems persist, please open an issue.
GRPOTrainer is optimized for setups with at least 2 GPUs, scaling up to multiple nodes. 2-GPU setups with sufficient memory to enable small-scale experimentation can be rented for <$1/hr.
If you do not require LoRA support, you may want to use the prime-rl trainer, which natively supports Environments created using verifiers, is more optimized for performance and scalability via FSDP, includes a broader set of configuration options and user experience features, and has more battle-tested defaults. Both trainers support asynchronous rollouts, and use a one-step off-policy delay by default for overlapping training and inference. See the prime-rl docs for usage instructions.
See the full docs for more information.
Verifiers warmly welcomes community contributions! Please open an issue or PR if you encounter bugs or other pain points during your development, or start a discussion for more open-ended questions.
Please note that the core verifiers/ library is intended to be a relatively lightweight set of reusable components rather than an exhaustive catalog of RL environments. For applications of verifiers (e.g. "an Environment for XYZ task"), you are welcome to submit a PR for a self-contained module that lives within environments/ if it serves as a canonical example of a new pattern. Stay tuned for more info shortly about our plans for supporting community Environment contributions 🙂
If you use this code in your research, please cite:
@misc{brown_verifiers_2025,
author = {William Brown},
title = {{Verifiers}: Reinforcement Learning with LLMs in Verifiable Environments},
howpublished = {\url{https://github.com/willccbb/verifiers}},
note = {Commit abcdefg • accessed DD Mon YYYY},
year = {2025}
}- A community Environments hub for crowdsourcing, sharing, and discovering new RL environments built with
verifiers - Default patterns for hosted resources such as code sandboxes, auxiliary models, and MCP servers
- Multimodal input support
- Non-increasing token sequences via REINFORCE
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for verifiers
Similar Open Source Tools
verifiers
Verifiers is a library of modular components for creating RL environments and training LLM agents. It includes an async GRPO implementation built around the `transformers` Trainer, is supported by `prime-rl` for large-scale FSDP training, and can easily be integrated into any RL framework which exposes an OpenAI-compatible inference client. The library provides tools for creating and evaluating RL environments, training LLM agents, and leveraging OpenAI-compatible models for various tasks. Verifiers aims to be a reliable toolkit for building on top of, minimizing fork proliferation in the RL infrastructure ecosystem.

py-vectara-agentic
The `vectara-agentic` Python library is designed for developing powerful AI assistants using Vectara and Agentic-RAG. It supports various agent types, includes pre-built tools for domains like finance and legal, and enables easy creation of custom AI assistants and agents. The library provides tools for summarizing text, rephrasing text, legal tasks like summarizing legal text and critiquing as a judge, financial tasks like analyzing balance sheets and income statements, and database tools for inspecting and querying databases. It also supports observability via LlamaIndex and Arize Phoenix integration.

Hurley-AI
Hurley AI is a next-gen framework for developing intelligent agents through Retrieval-Augmented Generation. It enables easy creation of custom AI assistants and agents, supports various agent types, and includes pre-built tools for domains like finance and legal. Hurley AI integrates with LLM inference services and provides observability with Arize Phoenix. Users can create Hurley RAG tools with a single line of code and customize agents with specific instructions. The tool also offers various helper functions to connect with Hurley RAG and search tools, along with pre-built tools for tasks like summarizing text, rephrasing text, understanding memecoins, and querying databases.
llm-ollama
LLM-ollama is a plugin that provides access to models running on an Ollama server. It allows users to query the Ollama server for a list of models, register them with LLM, and use them for prompting, chatting, and embedding. The plugin supports image attachments, embeddings, JSON schemas, async models, model aliases, and model options. Users can interact with Ollama models through the plugin in a seamless and efficient manner.

HuggingFaceGuidedTourForMac
HuggingFaceGuidedTourForMac is a guided tour on how to install optimized pytorch and optionally Apple's new MLX, JAX, and TensorFlow on Apple Silicon Macs. The repository provides steps to install homebrew, pytorch with MPS support, MLX, JAX, TensorFlow, and Jupyter lab. It also includes instructions on running large language models using HuggingFace transformers. The repository aims to help users set up their Macs for deep learning experiments with optimized performance.

hash
HASH is a self-building, open-source database which grows, structures and checks itself. With it, we're creating a platform for decision-making, which helps you integrate, understand and use data in a variety of different ways.

LeanCopilot
Lean Copilot is a tool that enables the use of large language models (LLMs) in Lean for proof automation. It provides features such as suggesting tactics/premises, searching for proofs, and running inference of LLMs. Users can utilize built-in models from LeanDojo or bring their own models to run locally or on the cloud. The tool supports platforms like Linux, macOS, and Windows WSL, with optional CUDA and cuDNN for GPU acceleration. Advanced users can customize behavior using Tactic APIs and Model APIs. Lean Copilot also allows users to bring their own models through ExternalGenerator or ExternalEncoder. The tool comes with caveats such as occasional crashes and issues with premise selection and proof search. Users can get in touch through GitHub Discussions for questions, bug reports, feature requests, and suggestions. The tool is designed to enhance theorem proving in Lean using LLMs.
kvpress
This repository implements multiple key-value cache pruning methods and benchmarks using transformers, aiming to simplify the development of new methods for researchers and developers in the field of long-context language models. It provides a set of 'presses' that compress the cache during the pre-filling phase, with each press having a compression ratio attribute. The repository includes various training-free presses, special presses, and supports KV cache quantization. Users can contribute new presses and evaluate the performance of different presses on long-context datasets.
Autono
A highly robust autonomous agent framework based on the ReAct paradigm, designed for adaptive decision making and multi-agent collaboration. It dynamically generates next actions during agent execution, enhancing robustness. Features a timely abandonment strategy and memory transfer mechanism for multi-agent collaboration. The framework allows developers to balance conservative and exploratory tendencies in agent execution strategies, improving adaptability and task execution efficiency in complex environments. Supports external tool integration, modular design, and MCP protocol compatibility for flexible action space expansion. Multi-agent collaboration mechanism enables agents to focus on specific task components, improving execution efficiency and quality.

garak
Garak is a free tool that checks if a Large Language Model (LLM) can be made to fail in a way that is undesirable. It probes for hallucination, data leakage, prompt injection, misinformation, toxicity generation, jailbreaks, and many other weaknesses. Garak's a free tool. We love developing it and are always interested in adding functionality to support applications.

LayerSkip
LayerSkip is an implementation enabling early exit inference and self-speculative decoding. It provides a code base for running models trained using the LayerSkip recipe, offering speedup through self-speculative decoding. The tool integrates with Hugging Face transformers and provides checkpoints for various LLMs. Users can generate tokens, benchmark on datasets, evaluate tasks, and sweep over hyperparameters to optimize inference speed. The tool also includes correctness verification scripts and Docker setup instructions. Additionally, other implementations like gpt-fast and Native HuggingFace are available. Training implementation is a work-in-progress, and contributions are welcome under the CC BY-NC license.
turnkeyml
TurnkeyML is a tools framework that integrates models, toolchains, and hardware backends to simplify the evaluation and actuation of deep learning models. It supports use cases like exporting ONNX files, performance validation, functional coverage measurement, stress testing, and model insights analysis. The framework consists of analysis, build, runtime, reporting tools, and a models corpus, seamlessly integrated to provide comprehensive functionality with simple commands. Extensible through plugins, it offers support for various export and optimization tools and AI runtimes. The project is actively seeking collaborators and is licensed under Apache 2.0.

paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and includes a process of embedding docs, queries, searching for top passages, creating summaries, using an LLM to re-score and select relevant summaries, putting summaries into prompt, and generating answers. The tool can be used to answer specific questions related to scientific research by leveraging citations and relevant passages from documents.

generative-models
Generative Models by Stability AI is a repository that provides various generative models for research purposes. It includes models like Stable Video 4D (SV4D) for video synthesis, Stable Video 3D (SV3D) for multi-view synthesis, SDXL-Turbo for text-to-image generation, and more. The repository focuses on modularity and implements a config-driven approach for building and combining submodules. It supports training with PyTorch Lightning and offers inference demos for different models. Users can access pre-trained models like SDXL-base-1.0 and SDXL-refiner-1.0 under a CreativeML Open RAIL++-M license. The codebase also includes tools for invisible watermark detection in generated images.

garak
Garak is a vulnerability scanner designed for LLMs (Large Language Models) that checks for various weaknesses such as hallucination, data leakage, prompt injection, misinformation, toxicity generation, and jailbreaks. It combines static, dynamic, and adaptive probes to explore vulnerabilities in LLMs. Garak is a free tool developed for red-teaming and assessment purposes, focusing on making LLMs or dialog systems fail. It supports various LLM models and can be used to assess their security and robustness.
ice-score
ICE-Score is a tool designed to instruct large language models to evaluate code. It provides a minimum viable product (MVP) for evaluating generated code snippets using inputs such as problem, output, task, aspect, and model. Users can also evaluate with reference code and enable zero-shot chain-of-thought evaluation. The tool is built on codegen-metrics and code-bert-score repositories and includes datasets like CoNaLa and HumanEval. ICE-Score has been accepted to EACL 2024.
For similar tasks
verifiers
Verifiers is a library of modular components for creating RL environments and training LLM agents. It includes an async GRPO implementation built around the `transformers` Trainer, is supported by `prime-rl` for large-scale FSDP training, and can easily be integrated into any RL framework which exposes an OpenAI-compatible inference client. The library provides tools for creating and evaluating RL environments, training LLM agents, and leveraging OpenAI-compatible models for various tasks. Verifiers aims to be a reliable toolkit for building on top of, minimizing fork proliferation in the RL infrastructure ecosystem.
For similar jobs

LitServe
LitServe is a high-throughput serving engine designed for deploying AI models at scale. It generates an API endpoint for models, handles batching, streaming, and autoscaling across CPU/GPUs. LitServe is built for enterprise scale with a focus on minimal, hackable code-base without bloat. It supports various model types like LLMs, vision, time-series, and works with frameworks like PyTorch, JAX, Tensorflow, and more. The tool allows users to focus on model performance rather than serving boilerplate, providing full control and flexibility.
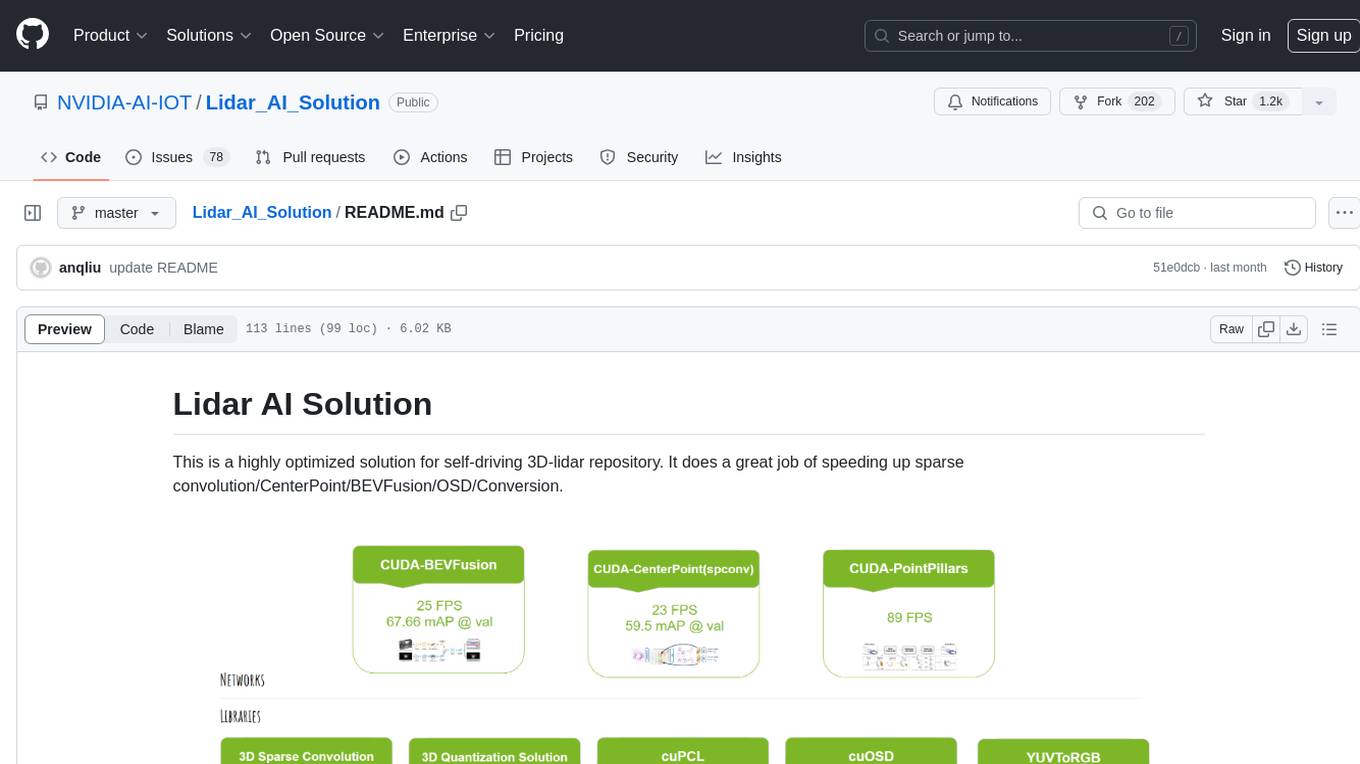
Lidar_AI_Solution
Lidar AI Solution is a highly optimized repository for self-driving 3D lidar, providing solutions for sparse convolution, BEVFusion, CenterPoint, OSD, and Conversion. It includes CUDA and TensorRT implementations for various tasks such as 3D sparse convolution, BEVFusion, CenterPoint, PointPillars, V2XFusion, cuOSD, cuPCL, and YUV to RGB conversion. The repository offers easy-to-use solutions, high accuracy, low memory usage, and quantization options for different tasks related to self-driving technology.

generative-ai-sagemaker-cdk-demo
This repository showcases how to deploy generative AI models from Amazon SageMaker JumpStart using the AWS CDK. Generative AI is a type of AI that can create new content and ideas, such as conversations, stories, images, videos, and music. The repository provides a detailed guide on deploying image and text generative AI models, utilizing pre-trained models from SageMaker JumpStart. The web application is built on Streamlit and hosted on Amazon ECS with Fargate. It interacts with the SageMaker model endpoints through Lambda functions and Amazon API Gateway. The repository also includes instructions on setting up the AWS CDK application, deploying the stacks, using the models, and viewing the deployed resources on the AWS Management Console.

cake
cake is a pure Rust implementation of the llama3 LLM distributed inference based on Candle. The project aims to enable running large models on consumer hardware clusters of iOS, macOS, Linux, and Windows devices by sharding transformer blocks. It allows running inferences on models that wouldn't fit in a single device's GPU memory by batching contiguous transformer blocks on the same worker to minimize latency. The tool provides a way to optimize memory and disk space by splitting the model into smaller bundles for workers, ensuring they only have the necessary data. cake supports various OS, architectures, and accelerations, with different statuses for each configuration.

Awesome-Robotics-3D
Awesome-Robotics-3D is a curated list of 3D Vision papers related to Robotics domain, focusing on large models like LLMs/VLMs. It includes papers on Policy Learning, Pretraining, VLM and LLM, Representations, and Simulations, Datasets, and Benchmarks. The repository is maintained by Zubair Irshad and welcomes contributions and suggestions for adding papers. It serves as a valuable resource for researchers and practitioners in the field of Robotics and Computer Vision.

tensorzero
TensorZero is an open-source platform that helps LLM applications graduate from API wrappers into defensible AI products. It enables a data & learning flywheel for LLMs by unifying inference, observability, optimization, and experimentation. The platform includes a high-performance model gateway, structured schema-based inference, observability, experimentation, and data warehouse for analytics. TensorZero Recipes optimize prompts and models, and the platform supports experimentation features and GitOps orchestration for deployment.

vector-inference
This repository provides an easy-to-use solution for running inference servers on Slurm-managed computing clusters using vLLM. All scripts in this repository run natively on the Vector Institute cluster environment. Users can deploy models as Slurm jobs, check server status and performance metrics, and shut down models. The repository also supports launching custom models with specific configurations. Additionally, users can send inference requests and set up an SSH tunnel to run inference from a local device.

rhesis
Rhesis is a comprehensive test management platform designed for Gen AI teams, offering tools to create, manage, and execute test cases for generative AI applications. It ensures the robustness, reliability, and compliance of AI systems through features like test set management, automated test generation, edge case discovery, compliance validation, integration capabilities, and performance tracking. The platform is open source, emphasizing community-driven development, transparency, extensible architecture, and democratizing AI safety. It includes components such as backend services, frontend applications, SDK for developers, worker services, chatbot applications, and Polyphemus for uncensored LLM service. Rhesis enables users to address challenges unique to testing generative AI applications, such as non-deterministic outputs, hallucinations, edge cases, ethical concerns, and compliance requirements.