
WenShape
WenShape文枢(原NOVIX写作):深度上下文感知的智能体小说创作系统
Stars: 188

WenShape is a context engineering system for creating long novels. It addresses the challenge of narrative consistency over thousands of words by using an orchestrated writing process, dynamic fact tracking, and precise token budget management. All project data is stored in YAML/Markdown/JSONL text format, naturally supporting Git version control.
README:
文枢 WenShape 是一个面向长篇小说创作的 上下文工程(Context Engineering) 系统。它的核心问题是:当叙事跨越数万字时,LLM 会不可避免地遗忘早期设定、产生前后矛盾。文枢通过编排式写作流程、动态事实追踪和精确的 Token 预算管理来应对这一挑战。
所有项目数据以 YAML / Markdown / JSONL 纯文本存储,天然支持 Git 版本控制。
系统由一个 Orchestrator(编排器)驱动完整的写作会话。编排器按阶段调度不同的专用模块,每个模块使用独立的系统提示词,可配置不同的 LLM 提供商和生成温度。
一个完整的写作会话实际执行以下流程:
flowchart LR
A[用户发起写作请求] --> B[阶段 1:场景准备(Archivist)]
B --> C[阶段 2:上下文构建(Context Engine)]
C --> D[阶段 3:草稿生成(Writer)]
D --> E[阶段 4:修订循环(Editor / Writer)]
E --> F[阶段 5:收尾分析(Archivist)]| 阶段 | 目标 | 关键产物 |
|---|---|---|
| 1 场景准备 | 为“这一章要写什么”建立可检索的结构化入口 | Scene Brief(角色/设定卡、事实、摘要、时间线) |
| 2 上下文构建 | 在有限 Token 预算内把“最相关的信息”组织进上下文 | 记忆包(Working Memory + Evidence 命中 + Gap/Questions) |
| 3 草稿生成 | 以流式方式生成初稿,并显式标记待确认项 | 草稿正文(含 [TO_CONFIRM]) |
| 4 修订循环 | 以最小改动完成修改,避免波及无关内容 | Patch 操作(replace/insert/delete)+ Diff 预览 |
| 5 收尾分析 | 将本章沉淀为可检索资产,为后续章节复用 | 章节摘要 + Canon(事实/时间线/状态) |
说明:Archivist / Writer / Editor 并非自主决策的独立智能体,而是由编排器按需调度的专用模块。它们各自维护独立的系统提示词和 LLM 配置,但执行顺序和调用时机由编排器决定。
上下文引擎负责在每次 LLM 调用前,在有限的 Token 预算内选出最相关的信息。
预算分配策略(默认 128K Token):
| 分配对象 | 比例 | 说明 |
|---|---|---|
| 系统规则 | 5% | 行为约束和提示词 |
| 角色/世界观卡片 | 15% | 当前场景相关的设定卡片 |
| 动态事实表 | 10% | 累积的关键剧情事实 |
| 历史摘要 | 20% | 已完成章节的压缩摘要 |
| 当前草稿 | 30% | 正在创作的章节内容 |
| 输出预留 | 20% | 保留给模型生成 |
选择引擎采用两层策略:
- 确定性选择:风格卡、场景简要等必选项,确保写作风格一致
- 检索式选择:对候选卡片(每类最多 50 个)进行 BM25 + 词重叠混合评分,返回 Top-K 最相关项
系统在每次章节确认后执行收尾分析:通过 LLM 调用提取新产生的事实条目(角色状态变化、地点转移、物品获取等),写入 JSONL 格式的事实表。同时使用启发式规则(基于动作动词、特定后缀、出现频率阈值)检测可能的新角色和世界观设定,以提议形式呈现给用户确认。
后续章节生成时,事实表参与上下文选择引擎的评分排序,确保长篇叙事的一致性。
内置 Wiki 爬取和结构化提取能力,支持从萌娘百科、Fandom、Wikipedia 等站点批量导入角色和世界观信息,自动解析 Infobox 和正文内容,生成可编辑的设定卡片。
frontend/ (React 18 + Vite + TypeScript)
├── pages/ 页面组件(项目列表、写作会话、系统设置)
├── components/ide/ IDE 式三段布局(ActivityBar + SidePanel + Editor)
├── context/ 全局状态管理(IDEContext, Reducer 模式)
├── hooks/ 自定义 Hooks(WebSocket 事件追踪、防抖请求)
└── api.ts 统一 API 层(Axios, 12 个模块, WebSocket 重连)
backend/ (FastAPI + Pydantic v2)
├── agents/ 专用模块(Archivist / Writer / Editor / Extractor)
│ ├── base.py 基类:统一 LLM 调用、Token 追踪、消息构建
│ ├── writer.py 撰稿人:研究循环 + 流式生成
│ ├── editor.py 编辑:Patch 生成 + 选区编辑 + 回退策略
│ ├── archivist.py 档案员:场景简要 + 事实检测 + 设定评分
│ └── extractor.py 提取器:Wiki → 结构化卡片
├── orchestrator/ 编排器
│ ├── orchestrator.py 写作会话全流程协调
│ ├── _context_mixin 上下文和记忆包准备
│ └── _analysis_mixin 章节分析和事实表更新
├── context_engine/ 上下文引擎
│ ├── select_engine 两层选择策略(确定性 + 检索式)
│ ├── budget_manager Token 预算分配与追踪
│ └── smart_compressor 历史对话智能压缩
├── llm_gateway/ LLM 网关
│ ├── gateway.py 统一接口:重试、流式、成本追踪
│ └── providers/ 9 个提供商适配(OpenAI / Anthropic / DeepSeek / Qwen / Kimi / GLM / Gemini / Grok / Custom)
├── routers/ REST API(15 个路由模块)
├── services/ 业务逻辑层
├── storage/ 文件系统存储(YAML / Markdown / JSONL)
└── data/ 项目数据目录(Git-Native)
data/{project_id}/
├── project.yaml 项目元数据
├── cards/ 设定卡片(角色、世界观、文风)
│ ├── character_001.yaml
│ └── worldview_001.yaml
├── canon/ 动态事实表
│ └── facts.jsonl
├── drafts/ 章节草稿
│ ├── .chapter_order
│ ├── chapter_001.md
│ └── chapter_002.md
└── sessions/ 会话历史
└── session_001.jsonl
| 层 | 技术 |
|---|---|
| 前端 | React 18, Vite 5, TypeScript, TailwindCSS v3, SWR, Framer Motion, Lucide React |
| 后端 | FastAPI, Pydantic v2, Uvicorn, WebSocket, aiofiles |
| LLM | OpenAI SDK, Anthropic SDK(支持 9 个提供商动态切换) |
| 存储 | 文件系统(YAML / Markdown / JSONL),Git-Native 设计 |
| 打包 | PyInstaller(单目录模式,含前端构建产物) |
无需安装 Python 或 Node.js,开箱即用。
- 前往 Releases 下载最新版本
WenShape_vX.X.X.zip - 解压到任意目录
- 双击运行
WenShape.exe,浏览器自动打开 - 在 设置 → 智能体配置 中填入 API Key(支持 OpenAI / Anthropic / DeepSeek 等,也可选 Mock 模式体验)
- 创建项目,开始写作
环境要求:Python 3.10+, Node.js 18+
# 克隆仓库
git clone https://github.com/unitagain/WenShape.git
cd WenShape-main
# Windows 一键启动
start.bat
# macOS / Linux
./start.sh启动脚本自动完成依赖安装、端口检测(默认后端 8000,前端 3000,冲突时自动递增)和服务启动。
手动启动:
# 终端 1 — 后端
cd backend
pip install -r requirements.txt
python -m app.main
# 终端 2 — 前端
cd frontend
npm install
npm run dev访问地址以启动日志输出为准。后端提供 Swagger 文档:http://localhost:8000/docs
复制 backend/.env.example 为 backend/.env,填入 API Key:
OPENAI_API_KEY=sk-...
ANTHROPIC_API_KEY=sk-ant-...
DEEPSEEK_API_KEY=...可在 backend/config.yaml 中为不同模块指定 LLM 提供商和参数:
agents:
archivist:
provider: openai # 档案员:精确性优先
temperature: 0.3
writer:
provider: anthropic # 撰稿人:创意性优先
temperature: 0.7
editor:
provider: anthropic
temperature: 0.5欢迎任何形式的贡献——Bug 报告、功能建议、代码提交、文档改进、国际化翻译、UI/UX 优化。
- Fork 本仓库
- 创建功能分支:
git checkout -b feature/your-feature - 提交变更:
git commit -m "feat: description" - 推送并创建 Pull Request
- 标题格式:
feat|fix|docs|refactor: 简要描述 - 确保代码可正常运行(后端无语法错误,前端
npm run build通过) - 涉及 UI 变更请附截图
本项目采用 PolyForm Noncommercial License 1.0.0。
- 允许:个人非商业使用、学习、研究、修改
- 禁止:任何形式的商业用途(包括企业内部使用)
商业授权请联系:[email protected]
如果你正在使用文枢创作,欢迎把体验与反馈告诉我们。
你的一条 Issue、一次 PR,甚至一句建议,都可能让它变得更好。
如果这个项目对你有帮助,点一个 Star 也是很大的鼓励。
Let the story unfold.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for WenShape
Similar Open Source Tools
WenShape
WenShape is a context engineering system for creating long novels. It addresses the challenge of narrative consistency over thousands of words by using an orchestrated writing process, dynamic fact tracking, and precise token budget management. All project data is stored in YAML/Markdown/JSONL text format, naturally supporting Git version control.
banana-slides
Banana-slides is a native AI-powered PPT generation application based on the nano banana pro model. It supports generating complete PPT presentations from ideas, outlines, and page descriptions. The app automatically extracts attachment charts, uploads any materials, and allows verbal modifications, aiming to truly 'Vibe PPT'. It lowers the threshold for creating PPTs, enabling everyone to quickly create visually appealing and professional presentations.

ai-toolbox
AI Toolbox is a cross-platform desktop application designed to efficiently manage various AI programming assistant configurations. It supports Windows, macOS, and Linux. The tool provides visual management of OpenCode, Oh-My-OpenCode, Slim plugin configurations, Claude Code API supplier configurations, Codex CLI configurations, MCP server management, Skills management, WSL synchronization, AI supplier management, system tray for quick configuration switching, data backup, theme switching, multilingual support, and automatic update checks.
tradecat
TradeCat is a comprehensive data analysis and trading platform designed for cryptocurrency, stock, and macroeconomic data. It offers a wide range of features including multi-market data collection, technical indicator modules, AI analysis, signal detection engine, Telegram bot integration, and more. The platform utilizes technologies like Python, TimescaleDB, TA-Lib, Pandas, NumPy, and various APIs to provide users with valuable insights and tools for trading decisions. With a modular architecture and detailed documentation, TradeCat aims to empower users in making informed trading decisions across different markets.
torch-rechub
Torch-RecHub is a lightweight, efficient, and user-friendly PyTorch recommendation system framework. It provides easy-to-use solutions for industrial-level recommendation systems, with features such as generative recommendation models, modular design for adding new models and datasets, PyTorch-based implementation for GPU acceleration, a rich library of 30+ classic and cutting-edge recommendation algorithms, standardized data loading, training, and evaluation processes, easy configuration through files or command-line parameters, reproducibility of experimental results, ONNX model export for production deployment, cross-engine data processing with PySpark support, and experiment visualization and tracking with integrated tools like WandB, SwanLab, and TensorBoardX.
Y2A-Auto
Y2A-Auto is an automation tool that transfers YouTube videos to AcFun. It automates the entire process from downloading, translating subtitles, content moderation, intelligent tagging, to partition recommendation and upload. It also includes a web management interface and YouTube monitoring feature. The tool supports features such as downloading videos and covers using yt-dlp, AI translation and embedding of subtitles, AI generation of titles/descriptions/tags, content moderation using Aliyun Green, uploading to AcFun, task management, manual review, and forced upload. It also offers settings for automatic mode, concurrency, proxies, subtitles, login protection, brute force lock, YouTube monitoring, channel/trend capturing, scheduled tasks, history records, optional GPU/hardware acceleration, and Docker deployment or local execution.
adnify
Adnify is an advanced code editor with ultimate visual experience and deep integration of AI Agent. It goes beyond traditional IDEs, featuring Cyberpunk glass morphism design style and a powerful AI Agent supporting full automation from code generation to file operations.
Lim-Code
LimCode is a powerful VS Code AI programming assistant that supports multiple AI models, intelligent tool invocation, and modular architecture. It features support for various AI channels, a smart tool system for code manipulation, MCP protocol support for external tool extension, intelligent context management, session management, and more. Users can install LimCode from the plugin store or via VSIX, or build it from the source code. The tool offers a rich set of features for AI programming and code manipulation within the VS Code environment.

resume-design
Resume-design is an open-source and free resume design and template download website, built with Vue3 + TypeScript + Vite + Element-plus + pinia. It provides two design tools for creating beautiful resumes and a complete backend management system. The project has released two frontend versions and will integrate with a backend system in the future. Users can learn frontend by downloading the released versions or learn design tools by pulling the latest frontend code.
AI-CloudOps
AI+CloudOps is a cloud-native operations management platform designed for enterprises. It aims to integrate artificial intelligence technology with cloud-native practices to significantly improve the efficiency and level of operations work. The platform offers features such as AIOps for monitoring data analysis and alerts, multi-dimensional permission management, visual CMDB for resource management, efficient ticketing system, deep integration with Prometheus for real-time monitoring, and unified Kubernetes management for cluster optimization.
LunaBox
LunaBox is a lightweight, fast, and feature-rich tool for managing and tracking visual novels, with the ability to customize game categories, automatically track playtime, generate personalized reports through AI analysis, import data from other platforms, backup data locally or on cloud services, and ensure privacy and security by storing sensitive data locally. The tool supports multi-dimensional statistics, offers a variety of customization options, and provides a user-friendly interface for easy navigation and usage.
topsha
LocalTopSH is an AI Agent Framework designed for companies and developers who require 100% on-premise AI agents with data privacy. It supports various OpenAI-compatible LLM backends and offers production-ready security features. The framework allows simple deployment using Docker compose and ensures that data stays within the user's network, providing full control and compliance. With cost-effective scaling options and compatibility in regions with restrictions, LocalTopSH is a versatile solution for deploying AI agents on self-hosted infrastructure.
ai_quant_trade
The ai_quant_trade repository is a comprehensive platform for stock AI trading, offering learning, simulation, and live trading capabilities. It includes features such as factor mining, traditional strategies, machine learning, deep learning, reinforcement learning, graph networks, and high-frequency trading. The repository provides tools for monitoring stocks, stock recommendations, and deployment tools for live trading. It also features new functionalities like sentiment analysis using StructBERT, reinforcement learning for multi-stock trading with a 53% annual return, automatic factor mining with 5000 factors, customized stock monitoring software, and local deep reinforcement learning strategies.

ClawRouter
ClawRouter is a tool designed to route every request to the cheapest model that can handle it, offering a wallet-based system with 30+ models available without the need for API keys. It provides 100% local routing with 14-dimension weighted scoring, zero external calls for routing decisions, and supports various models from providers like OpenAI, Anthropic, Google, DeepSeek, xAI, and Moonshot. Users can pay per request with USDC on Base, benefiting from an open-source, MIT-licensed, fully inspectable routing logic. The tool is optimized for agent swarm and multi-step workflows, offering cost-efficient solutions for parallel web research, multi-agent orchestration, and long-running automation tasks.
99AI
99AI is a commercializable AI web application based on NineAI 2.4.2 (no authorization, no backdoors, no piracy, integrated front-end and back-end integration packages, supports Docker rapid deployment). The uncompiled source code is temporarily closed. Compared with the stable version, the development version is faster.
AIxVuln
AIxVuln is an automated vulnerability discovery and verification system based on large models (LLM) + function calling + Docker sandbox. The system manages 'projects' through a web UI/desktop client, automatically organizing multiple 'digital humans' for environment setup, code auditing, vulnerability verification, and report generation. It utilizes an isolated Docker environment for dependency installation, service startup, PoC verification, and evidence collection, ultimately producing downloadable vulnerability reports. The system has already discovered dozens of vulnerabilities in real open-source projects.
For similar tasks
WenShape
WenShape is a context engineering system for creating long novels. It addresses the challenge of narrative consistency over thousands of words by using an orchestrated writing process, dynamic fact tracking, and precise token budget management. All project data is stored in YAML/Markdown/JSONL text format, naturally supporting Git version control.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

agnai
Agnaistic is an AI roleplay chat tool that allows users to interact with personalized characters using their favorite AI services. It supports multiple AI services, persona schema formats, and features such as group conversations, user authentication, and memory/lore books. Agnaistic can be self-hosted or run using Docker, and it provides a range of customization options through its settings.json file. The tool is designed to be user-friendly and accessible, making it suitable for both casual users and developers.
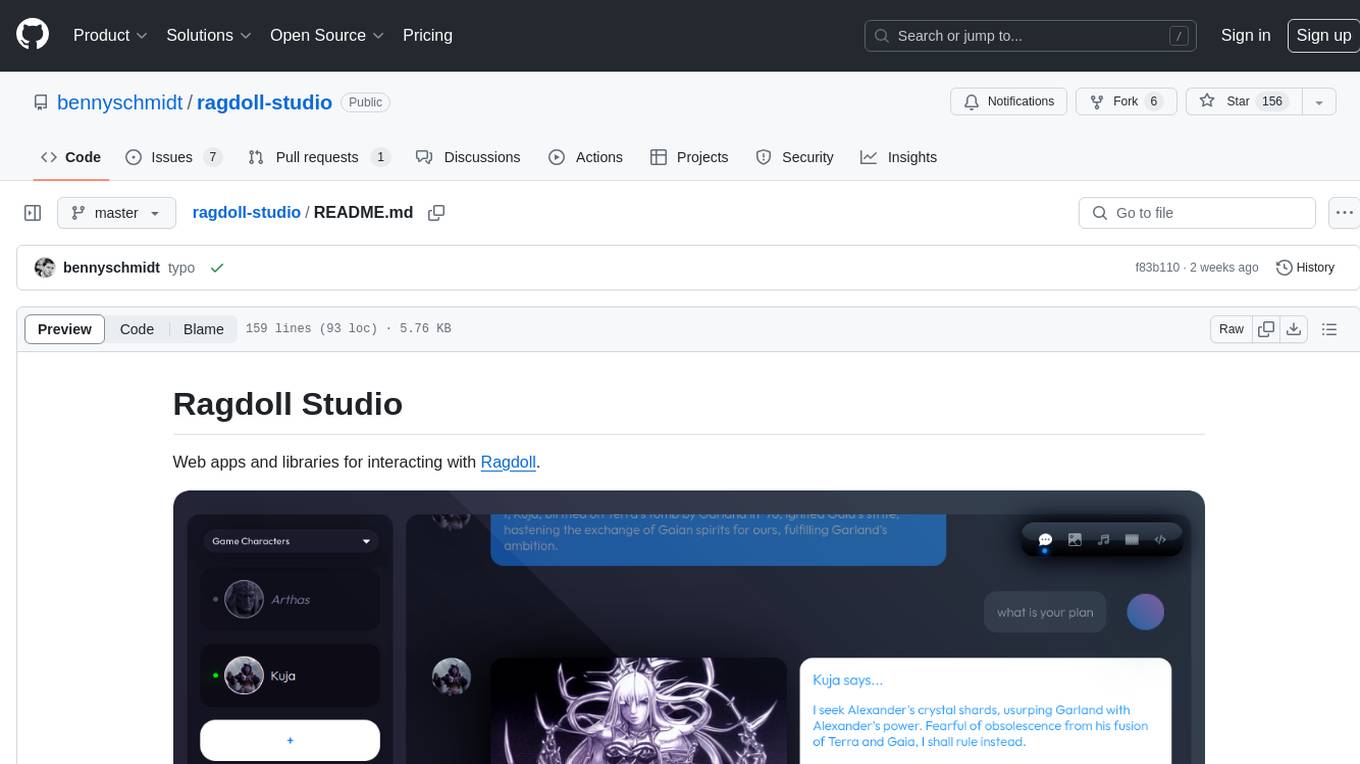
ragdoll-studio
Ragdoll Studio is a platform offering web apps and libraries for interacting with Ragdoll, enabling users to go beyond fine-tuning and create flawless creative deliverables, rich multimedia, and engaging experiences. It provides various modes such as Story Mode for creating and chatting with characters, Vector Mode for producing vector art, Raster Mode for producing raster art, Video Mode for producing videos, Audio Mode for producing audio, and 3D Mode for producing 3D objects. Users can export their content in various formats and share their creations on the community site. The platform consists of a Ragdoll API and a front-end React application for seamless usage.
LLMUnity
LLM for Unity enables seamless integration of Large Language Models (LLMs) within the Unity engine, allowing users to create intelligent characters for immersive player interactions. The tool supports major LLM models, runs locally without internet access, offers fast inference on CPU and GPU, and is easy to set up with a single line of code. It is free for both personal and commercial use, tested on Unity 2021 LTS, 2022 LTS, and 2023. Users can build multiple AI characters efficiently, use remote servers for processing, and customize model settings for text generation.
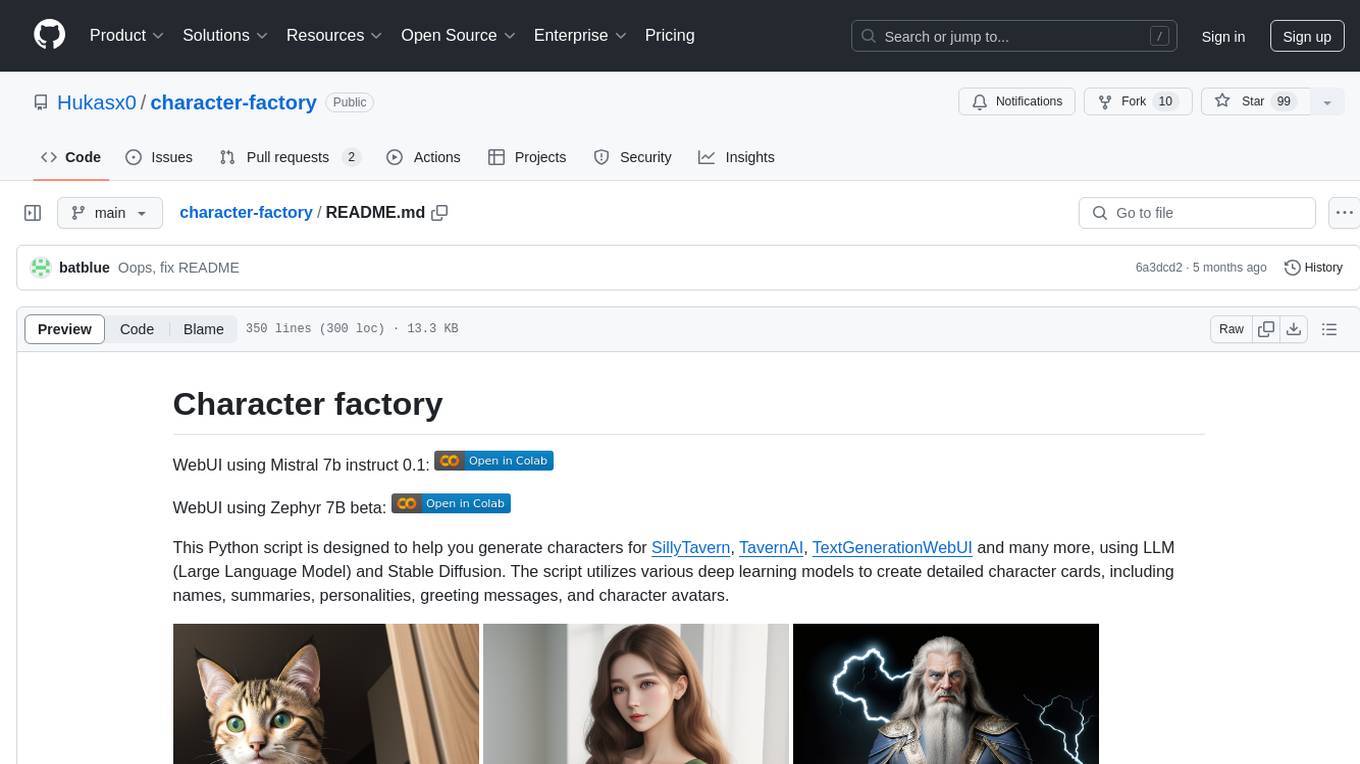
character-factory
Character Factory is a Python script designed to generate detailed character cards for SillyTavern, TavernAI, TextGenerationWebUI, and more using Large Language Model (LLM) and Stable Diffusion. It streamlines character generation by leveraging deep learning models to create names, summaries, personalities, greeting messages, and avatars for characters. The tool provides an easy way to create unique and imaginative characters for storytelling, chatting, and other purposes.
ai-anime-art-generator
AI Anime Art Generator is an AI-driven cutting-edge tool for anime arts creation. Perfect for beginners to easily create stunning anime art without any prior experience. It allows users to create detailed character designs, custom avatars for social media, and explore new artistic styles and ideas. Built on Next.js, TailwindCSS, Google Analytics, Vercel, Replicate, CloudFlare R2, and Clerk.
TavernAI
TavernAI is an atmospheric frontend tool for chat and storywriting, compatible with various backends. It offers features like character creation, online character database, group chat, story mode, world info, message swiping, configurable settings, interface themes, backgrounds, message editing, GPT-4.5, and Claude picture recognition. The tool supports backends like Kobold series, Oobabooga's Text Generation Web UI, OpenAI, NovelAI, and Claude. Users can easily install TavernAI on different operating systems and start using it for interactive storytelling and chat experiences.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.
SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.