
stars
Count GitHub Stars ⭐
Stars: 74
Ultralytics Analytics & Star Tracking is a tool to track GitHub stars, contributors, and PyPI downloads for Ultralytics projects. It provides real-time analytics updated daily, including total stars, forks, issues, pull requests, contributors, and public repositories. Users can access the analytics API for GitHub and PyPI downloads. The tool also offers historical star tracking for GitHub repositories, allowing users to analyze star growth over time. With a REST API and Python usage examples, users can easily retrieve and display analytics data. The repository structure includes scripts for unified analytics fetching, historical star tracking, and shared utilities. Contributions to the open-source community are encouraged, and the tool is available under AGPL-3.0 License for collaboration and an Enterprise License for commercial applications.
README:
![]()
Track GitHub stars, contributors, and PyPI downloads for Ultralytics projects.
![]()



![]()
Real-time analytics updated daily at 02:07 UTC via GitHub Actions.
https://raw.githubusercontent.com/ultralytics/stars/main/data/github.json
Fields:
-
total_stars: Total stars across all public repos -
total_forks: Total forks across all public repos -
total_issues: Total issues across all public repos (all-time) -
total_pull_requests: Total pull requests across all public repos (all-time) -
total_contributors: Sum of contributors across all repos (may include duplicates) -
public_repos: Number of public repositories -
timestamp: Last update time (ISO 8601) -
repos: Array with per-reponame,stars,forks,issues,pull_requests, andcontributors
https://raw.githubusercontent.com/ultralytics/stars/main/data/pypi.json
Packages tracked:
-
ultralytics- Main YOLO11 package -
ultralytics-actions- GitHub Actions -
ultralytics-thop- PyTorch ops profiling -
hub-sdk- Ultralytics HUB SDK -
mkdocs-ultralytics-plugin- Documentation plugin -
ultralytics-autoimport- Auto-import utilities
Fields:
-
total_downloads: Combined all-time downloads across all packages -
total_last_month: Combined downloads across all packages (last 30 days) -
timestamp: Last update time (ISO 8601) -
packages: Array with per-packagelast_day,last_week,last_month, andtotaldownloads
REST API:
curl https://raw.githubusercontent.com/ultralytics/stars/main/data/github.json
curl https://raw.githubusercontent.com/ultralytics/stars/main/data/pypi.jsonPython:
import requests
stars = requests.get("https://raw.githubusercontent.com/ultralytics/stars/main/data/github.json").json()
downloads = requests.get("https://raw.githubusercontent.com/ultralytics/stars/main/data/pypi.json").json()
print(f"Total stars: {stars['total_stars']:,}")
print(f"Total forks: {stars['total_forks']:,}")
print(f"Total issues: {stars['total_issues']:,}")
print(f"Total PRs: {stars['total_pull_requests']:,}")
print(f"Total contributors: {stars['total_contributors']:,}")
print(f"PyPI downloads (total): {downloads['total_downloads']:,}")
print(f"PyPI downloads (30d): {downloads['total_last_month']:,}")stars/
├── fetch_stats.py # Unified analytics fetcher (GitHub + PyPI)
├── count_stars.py # Historical star tracking script
├── utils.py # Shared utilities
├── data/
│ ├── github.json # GitHub analytics (updated daily)
│ ├── pypi.json # PyPI analytics (updated daily)
│ ├── google_analytics.json # Google Analytics (updated daily)
│ ├── reddit.json # Reddit stats (updated daily)
│ └── summary.json # Combined summary (updated daily)
└── .github/workflows/
├── analytics.yml # Daily analytics update
└── format.yml # Code formatting
Track star growth over time for any GitHub repositories using count_stars.py.
pip install -r requirements.txtpython count_stars.py --token YOUR_GITHUB_TOKEN --days 30 --saveArguments:
-
--token: GitHub Personal Access Token (create one) -
--days: Number of trailing days to analyze (default: 30) -
--save: Save user information to CSV (optional)
Tracked repositories are defined in count_stars.py and include:
- Ultralytics projects (ultralytics, yolov5, yolov3)
- YOLO variants (yolov6, yolov7, YOLOX)
- FAANG repos (detectron2, segment-anything, deepmind-research)
- ML frameworks (PyTorch Lightning, fastai, ray)
- And 30+ more popular CV/ML repositories
Edit the REPOS list in count_stars.py to customize tracked repositories.
Counting stars for last 30.0 days from 08 October 2025
ultralytics/ultralytics 1572 stars (52.4/day) : 6%|▌ | 1572/46959 [00:16<04:15, 94.53it/s]
ultralytics/yolov5 391 stars (13.0/day) : 2%|▏ | 391/55572 [00:04<03:56, 85.86it/s]
...
Contributions are the lifeblood of the open-source community, and we greatly appreciate your input! Whether it's bug fixes, feature suggestions, or documentation improvements, every contribution helps.
Please see our Contributing Guide for detailed instructions on how to get involved. We also encourage you to fill out our Survey to share your feedback. Thank you 🙏 to everyone who contributes!

Ultralytics provides two licensing options to accommodate different use cases:
- AGPL-3.0 License: Ideal for students and enthusiasts, this OSI-approved open-source license promotes collaboration and knowledge sharing. See the LICENSE file for details.
- Enterprise License: Designed for commercial applications, this license allows for the integration of Ultralytics software and AI models into commercial products and services. For more information, visit Ultralytics Licensing.
If you encounter bugs, have feature requests, or wish to contribute, please visit GitHub Issues. For broader discussions and questions about Ultralytics projects, join our vibrant community on Discord!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for stars
Similar Open Source Tools
stars
Ultralytics Analytics & Star Tracking is a tool to track GitHub stars, contributors, and PyPI downloads for Ultralytics projects. It provides real-time analytics updated daily, including total stars, forks, issues, pull requests, contributors, and public repositories. Users can access the analytics API for GitHub and PyPI downloads. The tool also offers historical star tracking for GitHub repositories, allowing users to analyze star growth over time. With a REST API and Python usage examples, users can easily retrieve and display analytics data. The repository structure includes scripts for unified analytics fetching, historical star tracking, and shared utilities. Contributions to the open-source community are encouraged, and the tool is available under AGPL-3.0 License for collaboration and an Enterprise License for commercial applications.
local-deep-research
Local Deep Research is a powerful AI-powered research assistant that performs deep, iterative analysis using multiple LLMs and web searches. It can be run locally for privacy or configured to use cloud-based LLMs for enhanced capabilities. The tool offers advanced research capabilities, flexible LLM support, rich output options, privacy-focused operation, enhanced search integration, and academic & scientific integration. It also provides a web interface, command line interface, and supports multiple LLM providers and search engines. Users can configure AI models, search engines, and research parameters for customized research experiences.
L3AGI
L3AGI is an open-source tool that enables AI Assistants to collaborate together as effectively as human teams. It provides a robust set of functionalities that empower users to design, supervise, and execute both autonomous AI Assistants and Teams of Assistants. Key features include the ability to create and manage Teams of AI Assistants, design and oversee standalone AI Assistants, equip AI Assistants with the ability to retain and recall information, connect AI Assistants to an array of data sources for efficient information retrieval and processing, and employ curated sets of tools for specific tasks. L3AGI also offers a user-friendly interface, APIs for integration with other systems, and a vibrant community for support and collaboration.

GraphGen
GraphGen is a framework for synthetic data generation guided by knowledge graphs. It enhances supervised fine-tuning for large language models (LLMs) by generating synthetic data based on a fine-grained knowledge graph. The tool identifies knowledge gaps in LLMs, prioritizes generating QA pairs targeting high-value knowledge, incorporates multi-hop neighborhood sampling, and employs style-controlled generation to diversify QA data. Users can use LLaMA-Factory and xtuner for fine-tuning LLMs after data generation.

wzry_ai
This is an open-source project for playing the game King of Glory with an artificial intelligence model. The first phase of the project has been completed, and future upgrades will be built upon this foundation. The second phase of the project has started, and progress is expected to proceed according to plan. For any questions, feel free to join the QQ exchange group: 687853827. The project aims to learn artificial intelligence and strictly prohibits cheating. Detailed installation instructions are available in the doc/README.md file. Environment installation video: (bilibili) Welcome to follow, like, tip, comment, and provide your suggestions.

aiotieba
Aiotieba is an asynchronous Python library for interacting with the Tieba API. It provides a comprehensive set of features for working with Tieba, including support for authentication, thread and post management, and image and file uploading. Aiotieba is well-documented and easy to use, making it a great choice for developers who want to build applications that interact with Tieba.
gitmesh
GitMesh is an AI-powered Git collaboration network designed to address contributor dropout in open source projects. It offers real-time branch-level insights, intelligent contributor-task matching, and automated workflows. The platform transforms complex codebases into clear contribution journeys, fostering engagement through gamified rewards and integration with open source support programs. GitMesh's mascot, Meshy/Mesh Wolf, symbolizes agility, resilience, and teamwork, reflecting the platform's ethos of efficiency and power through collaboration.
intlayer
Intlayer is an open-source, flexible i18n toolkit with AI-powered translation and CMS capabilities. It is a modern i18n solution for web and mobile apps, framework-agnostic, and includes features like per-locale content files, TypeScript autocompletion, tree-shakable dictionaries, and CI/CD integration. With Intlayer, internationalization becomes faster, cleaner, and smarter, offering benefits such as cross-framework support, JavaScript-powered content management, simplified setup, enhanced routing, AI-powered translation, and more.
ollama4j
Ollama4j is a Java library that serves as a wrapper or binding for the Ollama server. It facilitates communication with the Ollama server and provides models for deployment. The tool requires Java 11 or higher and can be installed locally or via Docker. Users can integrate Ollama4j into Maven projects by adding the specified dependency. The tool offers API specifications and supports various development tasks such as building, running unit tests, and integration tests. Releases are automated through GitHub Actions CI workflow. Areas of improvement include adhering to Java naming conventions, updating deprecated code, implementing logging, using lombok, and enhancing request body creation. Contributions to the project are encouraged, whether reporting bugs, suggesting enhancements, or contributing code.
llm4s
LLM4S provides a simple, robust, and scalable framework for building Large Language Models (LLM) applications in Scala. It aims to leverage Scala's type safety, functional programming, JVM ecosystem, concurrency, and performance advantages to create reliable and maintainable AI-powered applications. The framework supports multi-provider integration, execution environments, error handling, Model Context Protocol (MCP) support, agent frameworks, multimodal generation, and Retrieval-Augmented Generation (RAG) workflows. It also offers observability features like detailed trace logging, monitoring, and analytics for debugging and performance insights.
vnc-lm
vnc-lm is a Discord bot designed for messaging with language models. Users can configure model parameters, branch conversations, and edit prompts to enhance responses. The bot supports various providers like OpenAI, Huggingface, and Cloudflare Workers AI. It integrates with ollama and LiteLLM, allowing users to access a wide range of language model APIs through a single interface. Users can manage models, switch between models, split long messages, and create conversation branches. LiteLLM integration enables support for OpenAI-compatible APIs and local LLM services. The bot requires Docker for installation and can be configured through environment variables. Troubleshooting tips are provided for common issues like context window problems, Discord API errors, and LiteLLM issues.

OSA
OSA (Open-Source-Advisor) is a tool designed to improve the quality of scientific open source projects by automating the generation of README files, documentation, CI/CD scripts, and providing advice and recommendations for repositories. It supports various LLMs accessible via API, local servers, or osa_bot hosted on ITMO servers. OSA is currently under development with features like README file generation, documentation generation, automatic implementation of changes, LLM integration, and GitHub Action Workflow generation. It requires Python 3.10 or higher and tokens for GitHub/GitLab/Gitverse and LLM API key. Users can install OSA using PyPi or build from source, and run it using CLI commands or Docker containers.
readme-ai
README-AI is a developer tool that auto-generates README.md files using a combination of data extraction and generative AI. It streamlines documentation creation and maintenance, enhancing developer productivity. This project aims to enable all skill levels, across all domains, to better understand, use, and contribute to open-source software. It offers flexible README generation, supports multiple large language models (LLMs), provides customizable output options, works with various programming languages and project types, and includes an offline mode for generating boilerplate README files without external API calls.

evalplus
EvalPlus is a rigorous evaluation framework for LLM4Code, providing HumanEval+ and MBPP+ tests to evaluate large language models on code generation tasks. It offers precise evaluation and ranking, coding rigorousness analysis, and pre-generated code samples. Users can use EvalPlus to generate code solutions, post-process code, and evaluate code quality. The tool includes tools for code generation and test input generation using various backends.
smriti-ai
Smriti AI is an intelligent learning assistant that helps users organize, understand, and retain study materials. It transforms passive content into active learning tools by capturing resources, converting them into summaries and quizzes, providing spaced revision with reminders, tracking progress, and offering a multimodal interface. Suitable for students, self-learners, professionals, educators, and coaching institutes.
browser4
Browser4 is a lightning-fast, coroutine-safe browser designed for AI integration with large language models. It offers ultra-fast automation, deep web understanding, and powerful data extraction APIs. Users can automate the browser, extract data at scale, and perform tasks like summarizing products, extracting product details, and finding specific links. The tool is developer-friendly, supports AI-powered automation, and provides advanced features like X-SQL for precise data extraction. It also offers RPA capabilities, browser control, and complex data extraction with X-SQL. Browser4 is suitable for web scraping, data extraction, automation, and AI integration tasks.
For similar tasks
stars
Ultralytics Analytics & Star Tracking is a tool to track GitHub stars, contributors, and PyPI downloads for Ultralytics projects. It provides real-time analytics updated daily, including total stars, forks, issues, pull requests, contributors, and public repositories. Users can access the analytics API for GitHub and PyPI downloads. The tool also offers historical star tracking for GitHub repositories, allowing users to analyze star growth over time. With a REST API and Python usage examples, users can easily retrieve and display analytics data. The repository structure includes scripts for unified analytics fetching, historical star tracking, and shared utilities. Contributions to the open-source community are encouraged, and the tool is available under AGPL-3.0 License for collaboration and an Enterprise License for commercial applications.

only_train_once
Only Train Once (OTO) is an automatic, architecture-agnostic DNN training and compression framework that allows users to train a general DNN from scratch or a pretrained checkpoint to achieve high performance and slimmer architecture simultaneously in a one-shot manner without fine-tuning. The framework includes features for automatic structured pruning and erasing operators, as well as hybrid structured sparse optimizers for efficient model compression. OTO provides tools for pruning zero-invariant group partitioning, constructing pruned models, and visualizing pruning and erasing dependency graphs. It supports the HESSO optimizer and offers a sanity check for compliance testing on various DNNs. The repository also includes publications, installation instructions, quick start guides, and a roadmap for future enhancements and collaborations.

ChaKt-KMP
ChaKt is a multiplatform app built using Kotlin and Compose Multiplatform to demonstrate the use of Generative AI SDK for Kotlin Multiplatform to generate content using Google's Generative AI models. It features a simple chat based user interface and experience to interact with AI. The app supports mobile, desktop, and web platforms, and is built with Kotlin Multiplatform, Kotlin Coroutines, Compose Multiplatform, Generative AI SDK, Calf - File picker, and BuildKonfig. Users can contribute to the project by following the guidelines in CONTRIBUTING.md. The app is licensed under the MIT License.

crawl4ai
Crawl4AI is a powerful and free web crawling service that extracts valuable data from websites and provides LLM-friendly output formats. It supports crawling multiple URLs simultaneously, replaces media tags with ALT, and is completely free to use and open-source. Users can integrate Crawl4AI into Python projects as a library or run it as a standalone local server. The tool allows users to crawl and extract data from specified URLs using different providers and models, with options to include raw HTML content, force fresh crawls, and extract meaningful text blocks. Configuration settings can be adjusted in the `crawler/config.py` file to customize providers, API keys, chunk processing, and word thresholds. Contributions to Crawl4AI are welcome from the open-source community to enhance its value for AI enthusiasts and developers.
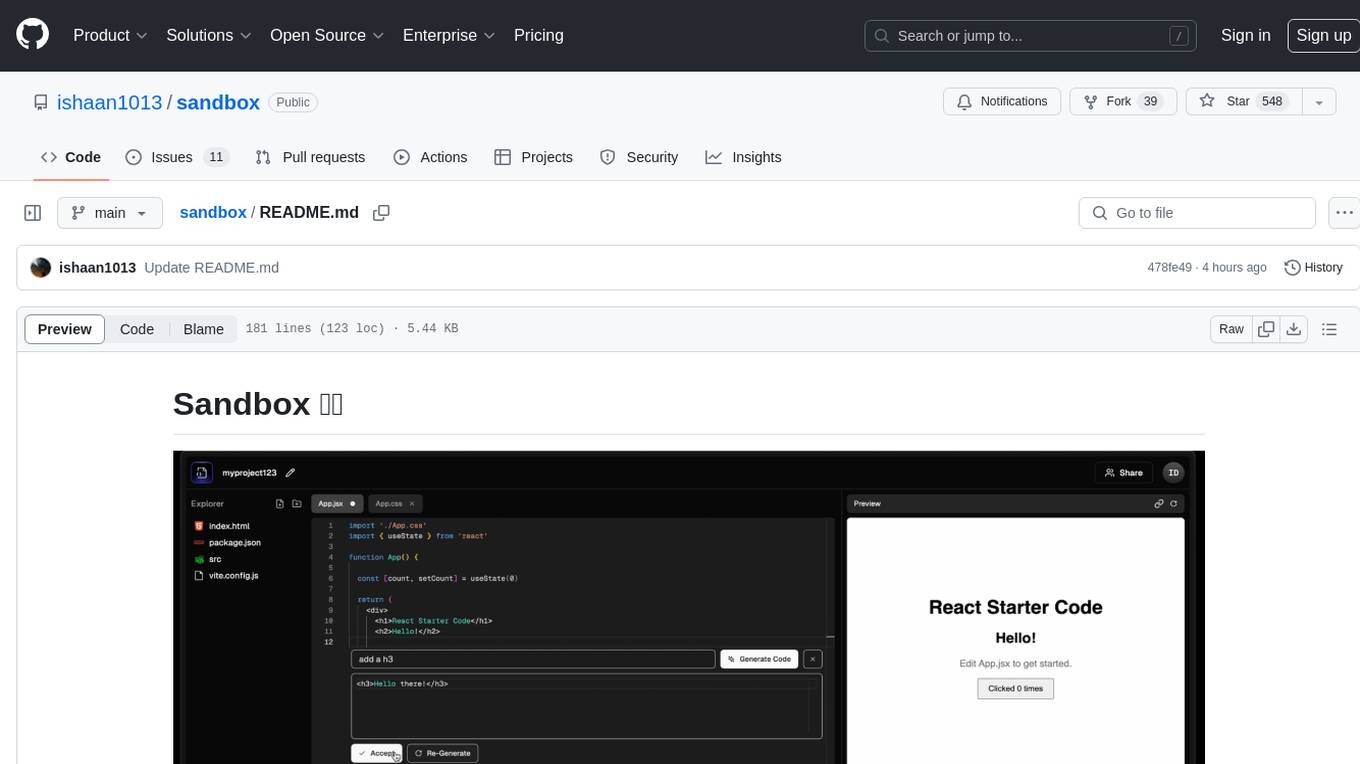
sandbox
Sandbox is an open-source cloud-based code editing environment with custom AI code autocompletion and real-time collaboration. It consists of a frontend built with Next.js, TailwindCSS, Shadcn UI, Clerk, Monaco, and Liveblocks, and a backend with Express, Socket.io, Cloudflare Workers, D1 database, R2 storage, Workers AI, and Drizzle ORM. The backend includes microservices for database, storage, and AI functionalities. Users can run the project locally by setting up environment variables and deploying the containers. Contributions are welcome following the commit convention and structure provided in the repository.
void
Void is an open-source Cursor alternative, providing a full source code for users to build and develop. It is a fork of the vscode repository, offering a waitlist for the official release. Users can contribute by checking the Project board and following the guidelines in CONTRIBUTING.md. Support is available through Discord or email.

aphrodite-engine
Aphrodite is an inference engine optimized for serving HuggingFace-compatible models at scale. It leverages vLLM's Paged Attention technology to deliver high-performance model inference for multiple concurrent users. The engine supports continuous batching, efficient key/value management, optimized CUDA kernels, quantization support, distributed inference, and modern samplers. It can be easily installed and launched, with Docker support for deployment. Aphrodite requires Linux or Windows OS, Python 3.8 to 3.12, and CUDA >= 11. It is designed to utilize 90% of GPU VRAM but offers options to limit memory usage. Contributors are welcome to enhance the engine.
cua
Cua is a tool for creating and running high-performance macOS and Linux virtual machines on Apple Silicon, with built-in support for AI agents. It provides libraries like Lume for running VMs with near-native performance, Computer for interacting with sandboxes, and Agent for running agentic workflows. Users can refer to the documentation for onboarding, explore demos showcasing AI-Gradio and GitHub issue fixing, and utilize accessory libraries like Core, PyLume, Computer Server, and SOM. Contributions are welcome, and the tool is open-sourced under the MIT License.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.