
ComfyUI-TopazVideoAI
None
Stars: 91

ComfyUI-TopazVideoAI is a tool designed to facilitate the usage of TopazVideoAI for creating short AI-generated videos. Users can connect this node between video output and video save to enhance the quality of videos. The tool requires a licensed installation of TopazVideoAI and provides instructions for setting up environment variables and paths. It is recommended to use upscale factors of 2 or 4 to avoid errors. The tool encodes and decodes videos as image batches, which may result in longer processing times compared to the TopazVideoAI GUI. Common errors include 'No such filter: 'tvai_up'' which can be resolved by ensuring the correct ffmpeg path and removing conflicting ffmpeg installations.
README:
Requirements: Licensed installation of TopazVideoAI
Installation: git clone this project to custom_nodes folder
git clone https://github.com/sh570655308/ComfyUI-TopazVideoAI.git
First, set up environment variables Open Topaz Video AI UI, log in to your account, press Ctrl+Shift+T to open the command window, and it will automatically set the model directory in environment variables Then add Topaz's installation directory to the PATH. This step is for setting up FFmpeg. If you have previously set other paths, please remove them Close the GUI, open shell terminal
cd "C:\Program Files\Topaz Labs LLC\Topaz Video AI"
.\login
The path may vary when you have custom installation path Then close the shell terminal, now you can use this node normally
Usage:
Simply connect this nodes between video output and video save
Notification:
Use 2 or 4 for upscale factor, others may cause error now
Model selection is not ready yet, now only works with default
This node is designed for short AI generated videos. I didn't test it with long video, because comfyui transfer video as image batch, the node will encode and decode which cost longer time than TopazVideoAI GUI.
Common errors: No such filter: 'tvai_up' Make sure the ffmpeg path is correct and unique - you must use the ffmpeg that comes with TopazVideoAI. Remember to remove ffmpeg from other paths and from the ComfyUI environment.
要求: 已安装的 TopazVideoAI,要登录账户
安装: 将此项目克隆到 custom_nodes 文件夹
git clone https://github.com/sh570655308/ComfyUI-TopazVideoAI.git
使用: 首先要设置环境变量
打开topaz video ai的应用程序,登录账号,快捷键ctrl+shift+T打开命令窗口,会自动设置模型目录到环境变量。
如果自动设置模型目录失败,则需要手动设置,在用户环境配置中添加TVAI_MODEL_DATA_DIR 和TVAI_MODEL_DIR,数值为模型对应的目录
然后在path中添加topaz的安装目录,这一步是设置ffmpeg,如果之前有设置过其他路径的ffmpeg请删除
设置完成后关闭gui,打开shell终端输入:
cd "C:\Program Files\Topaz Labs LLC\Topaz Video AI"
.\login
之后就可以正常使用了
注意事项:
放大倍数请使用2或4,其他数值目前可能导致错误
模型选择功能尚未就绪,目前仅支持默认设置
此节点专为AI生成的短视频设计。由于ComfyUI以图像批次方式传输视频,节点需要进行编码和解码,因此相比TopazVideoAI图形界面处理时间更长,故未对长视频进行测试。
常见错误: No such filter: 'tvai_up’ 确保ffmpeg的path路径正确,必须用TopazVideoAI自带的ffmpeg。记得删除其他路径的ffmpeg以及comfyui环境中的ffmpeg。
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ComfyUI-TopazVideoAI
Similar Open Source Tools
ComfyUI-TopazVideoAI
ComfyUI-TopazVideoAI is a tool designed to facilitate the usage of TopazVideoAI for creating short AI-generated videos. Users can connect this node between video output and video save to enhance the quality of videos. The tool requires a licensed installation of TopazVideoAI and provides instructions for setting up environment variables and paths. It is recommended to use upscale factors of 2 or 4 to avoid errors. The tool encodes and decodes videos as image batches, which may result in longer processing times compared to the TopazVideoAI GUI. Common errors include 'No such filter: 'tvai_up'' which can be resolved by ensuring the correct ffmpeg path and removing conflicting ffmpeg installations.

ultimate-rvc
Ultimate RVC is an extension of AiCoverGen, offering new features and improvements for generating audio content using RVC. It is designed for users looking to integrate singing functionality into AI assistants/chatbots/vtubers, create character voices for songs or books, and train voice models. The tool provides easy setup, voice conversion enhancements, TTS functionality, voice model training suite, caching system, UI improvements, and support for custom configurations. It is available for local and Google Colab use, with a PyPI package for easy access. The tool also offers CLI usage and customization through environment variables.
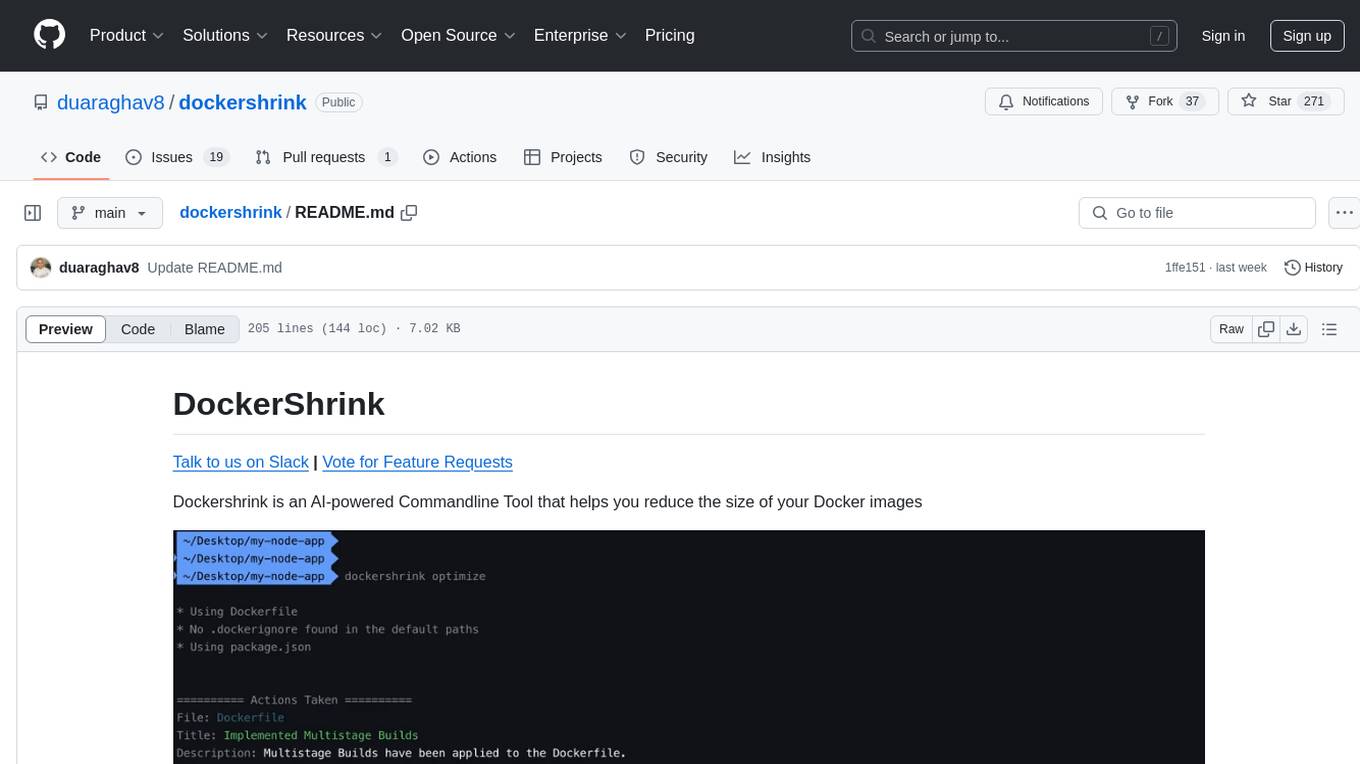
dockershrink
Dockershrink is an AI-powered Commandline Tool designed to help reduce the size of Docker images. It combines traditional Rule-based analysis with Generative AI techniques to optimize Image configurations. The tool supports NodeJS applications and aims to save costs on storage, data transfer, and build times while increasing developer productivity. By automatically applying advanced optimization techniques, Dockershrink simplifies the process for engineers and organizations, resulting in significant savings and efficiency improvements.
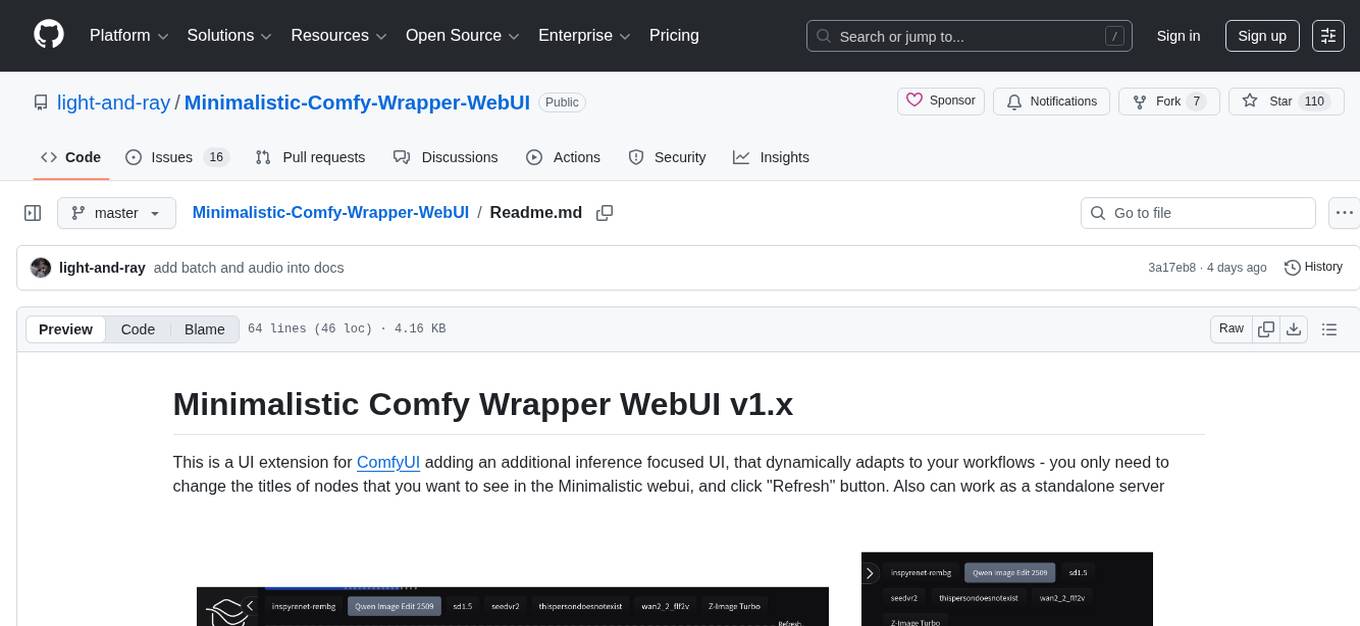
Minimalistic-Comfy-Wrapper-WebUI
Minimalistic Comfy Wrapper WebUI is a user interface extension for ComfyUI that provides an additional inference-focused UI. It dynamically adapts to workflows, allowing users to change node titles and refresh the UI. The tool ensures stability by storing data in the browser's local storage, supports working with the same workflows in Comfy and the webui, offers better queues management, prompt presets, batch support, a minimalist image editor, and mobile-friendly UI. Users can install it from the ComfyUI manager and customize node titles for input and output nodes. The tool is designed for users who prefer a simpler interface for inference tasks and want to work with ComfyUI workflows from a different perspective.
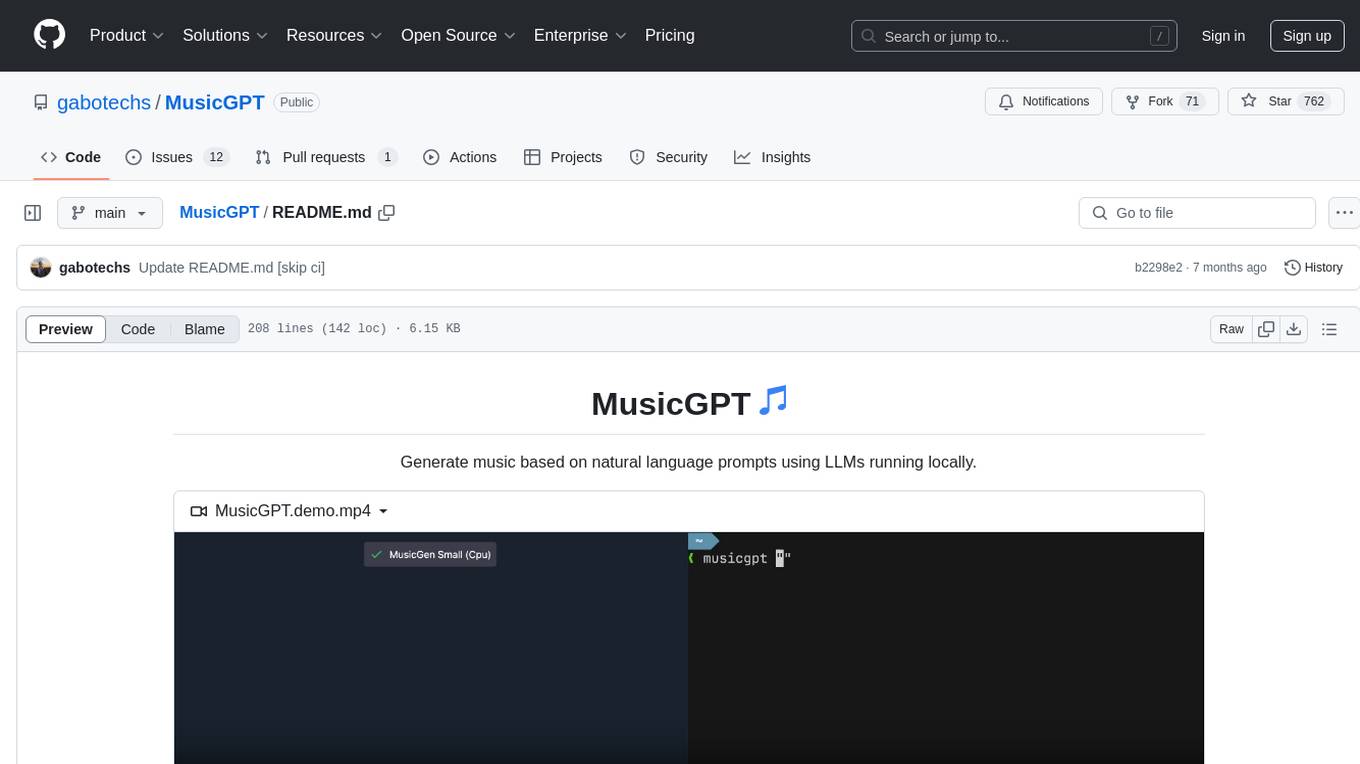
MusicGPT
MusicGPT is an application that allows running the latest music generation AI models locally in a performant way, supporting different music generation models transparently to the user. It can be interacted with through UI mode or CLI mode, generating music based on natural language prompts. The tool requires access to storage to save downloaded models and generated audios along with metadata. It is licensed under MIT License for the code and CC-BY-NC-4.0 License for the AI model weights.

Mapperatorinator
Mapperatorinator is a multi-model framework that uses spectrogram inputs to generate fully featured osu! beatmaps for all gamemodes and assist modding beatmaps. The project aims to automatically generate rankable quality osu! beatmaps from any song with a high degree of customizability. The tool is built upon osuT5 and osu-diffusion, utilizing GPU compute and instances on vast.ai for development. Users can responsibly use AI in their beatmaps with this tool, ensuring disclosure of AI usage. Installation instructions include cloning the repository, creating a virtual environment, and installing dependencies. The tool offers a Web GUI for user-friendly experience and a Command-Line Inference option for advanced configurations. Additionally, an Interactive CLI script is available for terminal-based workflow with guided setup. The tool provides generation tips and features MaiMod, an AI-driven modding tool for osu! beatmaps. Mapperatorinator tokenizes beatmaps, utilizes a model architecture based on HF Transformers Whisper model, and offers multitask training format for conditional generation. The tool ensures seamless long generation, refines coordinates with diffusion, and performs post-processing for improved beatmap quality. Super timing generator enhances timing accuracy, and LoRA fine-tuning allows adaptation to specific styles or gamemodes. The project acknowledges credits and related works in the osu! community.
vigenair
ViGenAiR is a tool that harnesses the power of Generative AI models on Google Cloud Platform to automatically transform long-form Video Ads into shorter variants, targeting different audiences. It generates video, image, and text assets for Demand Gen and YouTube video campaigns. Users can steer the model towards generating desired videos, conduct A/B testing, and benefit from various creative features. The tool offers benefits like diverse inventory, compelling video ads, creative excellence, user control, and performance insights. ViGenAiR works by analyzing video content, splitting it into coherent segments, and generating variants following Google's best practices for effective ads.

jaison-core
J.A.I.son is a Python project designed for generating responses using various components and applications. It requires specific plugins like STT, T2T, TTSG, and TTSC to function properly. Users can customize responses, voice, and configurations. The project provides a Discord bot, Twitch events and chat integration, and VTube Studio Animation Hotkeyer. It also offers features for managing conversation history, training AI models, and monitoring conversations.
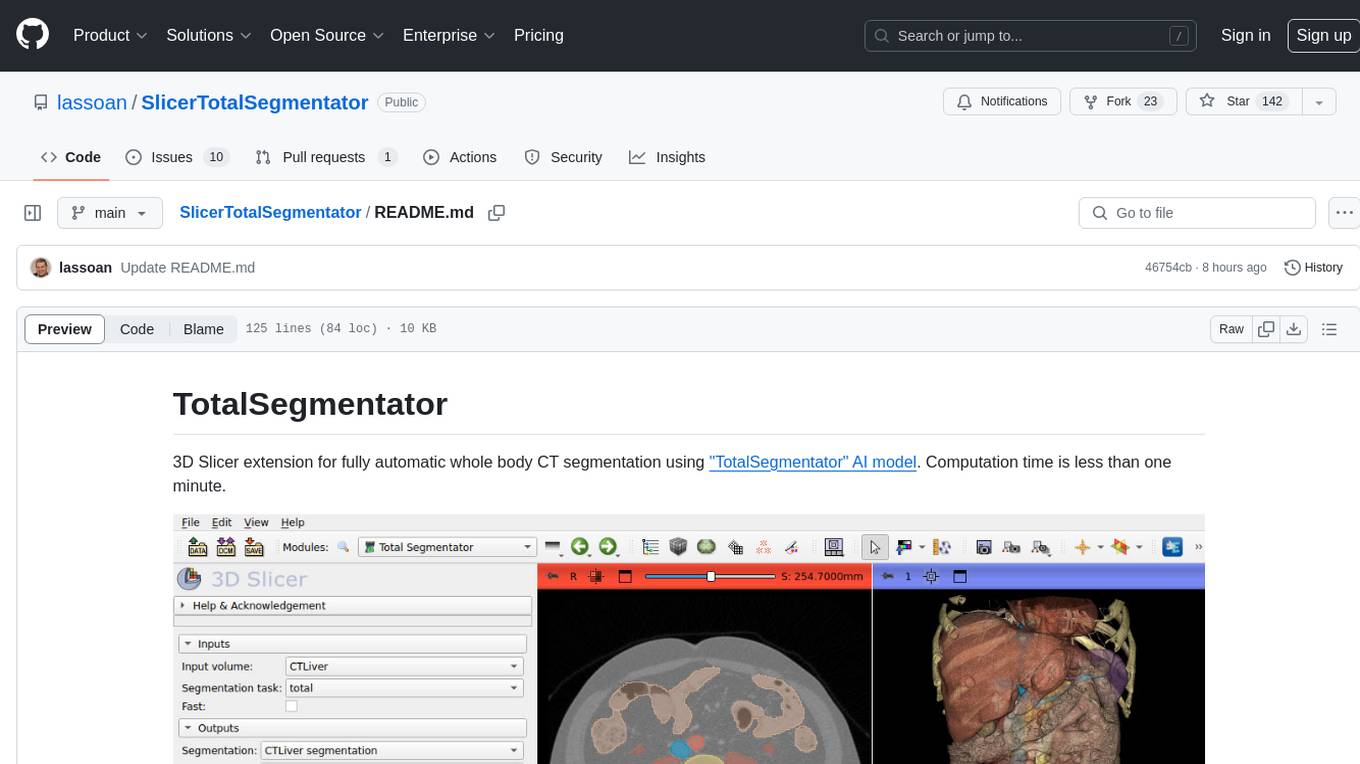
SlicerTotalSegmentator
TotalSegmentator is a 3D Slicer extension designed for fully automatic whole body CT segmentation using the 'TotalSegmentator' AI model. The computation time is less than one minute, making it efficient for research purposes. Users can set up GPU acceleration for faster segmentation. The tool provides a user-friendly interface for loading CT images, creating segmentations, and displaying results in 3D. Troubleshooting steps are available for common issues such as failed computation, GPU errors, and inaccurate segmentations. Contributions to the extension are welcome, following 3D Slicer contribution guidelines.
vector_companion
Vector Companion is an AI tool designed to act as a virtual companion on your computer. It consists of two personalities, Axiom and Axis, who can engage in conversations based on what is happening on the screen. The tool can transcribe audio output and user microphone input, take screenshots, and read text via OCR to create lifelike interactions. It requires specific prerequisites to run on Windows and uses VB Cable to capture audio. Users can interact with Axiom and Axis by running the main script after installation and configuration.

sdk
Vikit.ai SDK is a software development kit that enables easy development of video generators using generative AI and other AI models. It serves as a langchain to orchestrate AI models and video editing tools. The SDK allows users to create videos from text prompts with background music and voice-over narration. It also supports generating composite videos from multiple text prompts. The tool requires Python 3.8+, specific dependencies, and tools like FFMPEG and ImageMagick for certain functionalities. Users can contribute to the project by following the contribution guidelines and standards provided.
ChatGPT-Telegram-Bot
The ChatGPT Telegram Bot is a powerful Telegram bot that utilizes various GPT models, including GPT3.5, GPT4, GPT4 Turbo, GPT4 Vision, DALL·E 3, Groq Mixtral-8x7b/LLaMA2-70b, and Claude2.1/Claude3 opus/sonnet API. It enables users to engage in efficient conversations and information searches on Telegram. The bot supports multiple AI models, online search with DuckDuckGo and Google, user-friendly interface, efficient message processing, document interaction, Markdown rendering, and convenient deployment options like Zeabur, Replit, and Docker. Users can set environment variables for configuration and deployment. The bot also provides Q&A functionality, supports model switching, and can be deployed in group chats with whitelisting. The project is open source under GPLv3 license.

chaiNNer
ChaiNNer is a node-based image processing GUI aimed at making chaining image processing tasks easy and customizable. It gives users a high level of control over their processing pipeline and allows them to perform complex tasks by connecting nodes together. ChaiNNer is cross-platform, supporting Windows, MacOS, and Linux. It features an intuitive drag-and-drop interface, making it easy to create and modify processing chains. Additionally, ChaiNNer offers a wide range of nodes for various image processing tasks, including upscaling, denoising, sharpening, and color correction. It also supports batch processing, allowing users to process multiple images or videos at once.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.

GlaDOS
This project aims to create a real-life version of GLaDOS, an aware, interactive, and embodied AI entity. It involves training a voice generator, developing a 'Personality Core,' implementing a memory system, providing vision capabilities, creating 3D-printable parts, and designing an animatronics system. The software architecture focuses on low-latency voice interactions, utilizing a circular buffer for data recording, text streaming for quick transcription, and a text-to-speech system. The project also emphasizes minimal dependencies for running on constrained hardware. The hardware system includes servo- and stepper-motors, 3D-printable parts for GLaDOS's body, animations for expression, and a vision system for tracking and interaction. Installation instructions cover setting up the TTS engine, required Python packages, compiling llama.cpp, installing an inference backend, and voice recognition setup. GLaDOS can be run using 'python glados.py' and tested using 'demo.ipynb'.
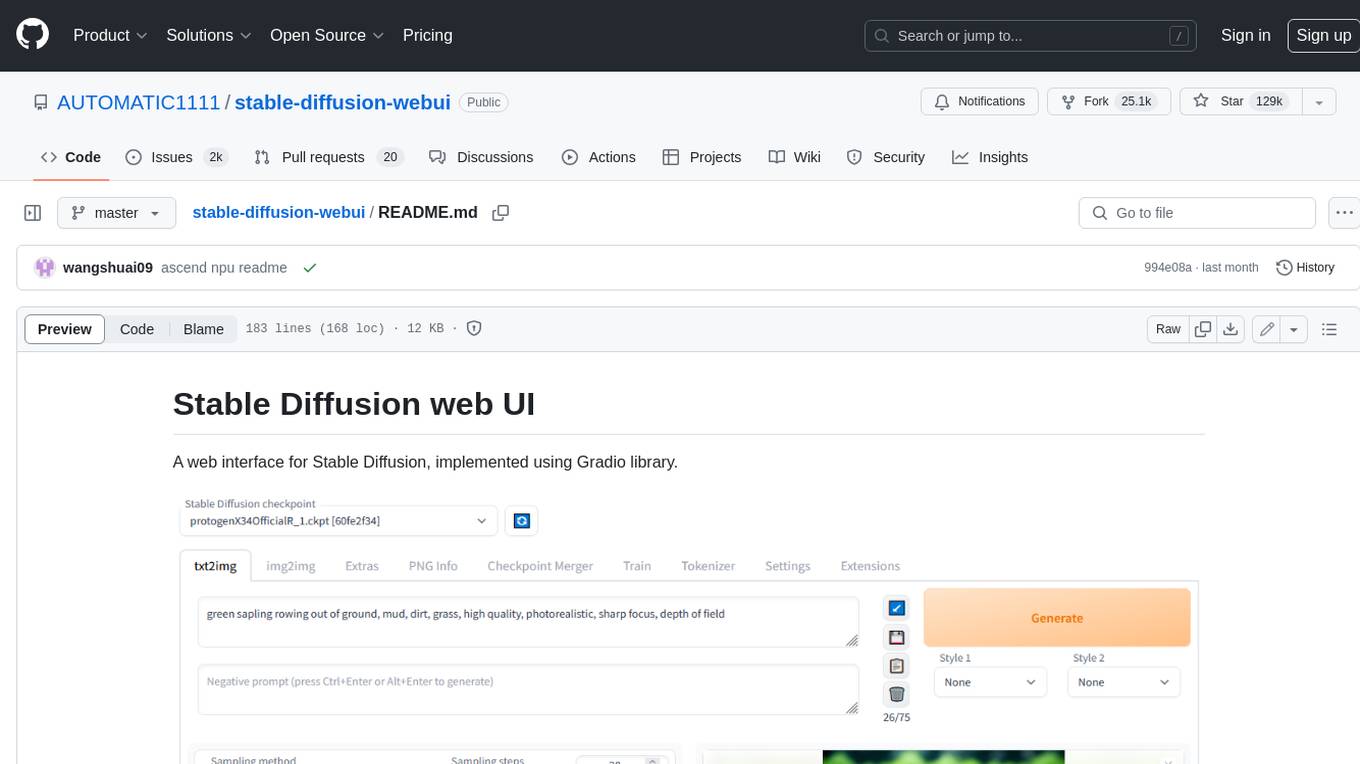
stable-diffusion-webui
Stable Diffusion web UI is a web interface for Stable Diffusion, implemented using Gradio library. It provides a user-friendly interface to access the powerful image generation capabilities of Stable Diffusion. With Stable Diffusion web UI, users can easily generate images from text prompts, edit and refine images using inpainting and outpainting, and explore different artistic styles and techniques. The web UI also includes a range of advanced features such as textual inversion, hypernetworks, and embeddings, allowing users to customize and fine-tune the image generation process. Whether you're an artist, designer, or simply curious about the possibilities of AI-generated art, Stable Diffusion web UI is a valuable tool that empowers you to create stunning and unique images.
For similar tasks
ComfyUI-TopazVideoAI
ComfyUI-TopazVideoAI is a tool designed to facilitate the usage of TopazVideoAI for creating short AI-generated videos. Users can connect this node between video output and video save to enhance the quality of videos. The tool requires a licensed installation of TopazVideoAI and provides instructions for setting up environment variables and paths. It is recommended to use upscale factors of 2 or 4 to avoid errors. The tool encodes and decodes videos as image batches, which may result in longer processing times compared to the TopazVideoAI GUI. Common errors include 'No such filter: 'tvai_up'' which can be resolved by ensuring the correct ffmpeg path and removing conflicting ffmpeg installations.
facefusion-docker
FaceFusion Docker is an industry leading face manipulation platform that provides a seamless way to manipulate faces in images and videos. The repository offers Docker containers for CPU, CUDA, TensorRT, and ROCm environments, allowing users to easily set up and run the platform. Users can access different containers through specific ports to browse and interact with the face manipulation features. The platform is designed to be user-friendly and efficient for various face manipulation tasks.
Topaz-Video-AI
Topaz-Video-AI is a software tool designed to enhance video quality and provide various editing features. Users can utilize this tool to improve the visual appeal of their videos by applying filters, adjusting colors, and enhancing details. The software offers a user-friendly interface and a range of customization options to cater to different editing needs. Despite potential triggers from antivirus programs, Topaz-Video-AI is safe to use and has been tested by numerous users. By following the provided instructions, users can easily download, install, and run the software to enhance their video content.
AI-B-roll
AI-B-roll is a tool designed to generate broll for videos using AI. Users can automatically add AI b-roll to their videos with the provided API. The tool aims to streamline the process of creating engaging video content by leveraging artificial intelligence technology. It offers a convenient solution for video creators looking to enhance their projects with visually appealing footage.
Upscaler
Holloway's Upscaler is a consolidation of various compiled open-source AI image/video upscaling products for a CLI-friendly image and video upscaling program. It provides low-cost AI upscaling software that can run locally on a laptop, programmable for albums and videos, reliable for large video files, and works without GUI overheads. The repository supports hardware testing on various systems and provides important notes on GPU compatibility, video types, and image decoding bugs. Dependencies include ffmpeg and ffprobe for video processing. The user manual covers installation, setup pathing, calling for help, upscaling images and videos, and contributing back to the project. Benchmarks are provided for performance evaluation on different hardware setups.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.