
ChatBook
主要提供一站式的AI服务, 包含基础AI对话, AI角色代理, AI客服, AI知识库, AI生成思维导图, AI生成PPTX等功能.
Stars: 78
ChatBook provides a one-stop AI service, including basic AI dialogue, AI role agents, AI customer service, AI knowledge base, AI mind map generation, and AI PPTX generation. Users can define AI workflows freely to handle more complex business scenarios. The backend uses serverless functions with data stored in the ./data directory. The tool allows administrators to manage knowledge bases, configure keys, and review user registrations. Normal users can directly use AI models and knowledge bases after registration. The technology stack includes LLM models like Langchain, Pinecone, OpenAi, Gemini, Baidu Wenxin, Node Express for backend, and React, NextJS, MUI for frontend.
README:
主要提供一站式的AI服务, 包含基础AI对话, AI角色代理, AI客服, AI知识库, AI生成思维导图, AI生成PPTX等功能; 可自由定义AI工作流程, 从而可以应对更加复杂的业务场景.
主要功能:
1 基础AI对话: 无需每个用户去开通各通AI模型的会员,由单位开通一次,即可给单位内用户使用.
2 AI角色代理: Ai的角色代理,可以设置不同的角色进行专业的问答服务.
3 AI客服: 智能化的AI客户服务,连接企业自身知识库,进行专业问答,同时提供表单收集数据功能.
4 AI知识库: 使用企业自己数据进行投喂,然后进行问答.
5 AI生成思维导图: 提供AI生成思维导图的功能.
6 AI生成PPTX: 提供AI生成PPTX的功能.
git clone https://github.com/chatbookai/ChatBook.git
启动前端项目:
cd ChatBook
npm install
npm run dev
然后访问 http://127.0.0.1:3000
启动后端项目:
使用另外一个CMD窗口,进入到ChatBook目录的express目录下面,因为是前后端在一个仓库,但是两个项目,需要额外再执行一次npm install,命令如下:
cd ChatBook\express
npm install
npm run express
后端API就可以访问了, http://127.0.0.1:1988
后端使用serverless function, 数据目录是在安装目录的./data下面.
管理员:
1 设置OPENAI KEY或是其它模型的KEY,管理知识库,并且给每个知识库配置KEY等信息
2 管理普通用户信息
3 自行注册的用户,需要管理员审核以后,就可以使用AI对话模型和知识库模型
4 新用户可以自己注册,或是由管理员建立
普通用户:
1 可以直接使用AI对话模型和知识库模型
2 自行注册
默认管理员
用户名: [email protected]
密码: 123456aA
默认普通用户
用户名: [email protected]
密码: 123456aA
1 LLM: Langchain, Pinecone, OpenAi, Gemini, Baidu Wenxin, 后续会持续集成其它模型
2 后端: Node Express
3 前端: React, NextJS, MUI
QQ群: 186411255
- 本项目发行协议: [AGPL-3.0 License]
- 开源商用: 无需联系,可以直接使用,需要在您官网页面底部增加您的开源库的URL(根据开源协议你需要公开你的源代码),GPL协议授权你可以修改代码,并共享你修改以后的代码,但没有授权你可以修改版权信息,所以版权信息不能修改.
- 闭源商用: 需要联系,额外取得商业授权,根据商业授权协议的内容,来决定你是否可以合法的修改版权信息.
- 商业授权: 价格:36000元人民币,或5000美元.
- 宣传推广: 如果你愿意推广和宣传本项目,推广和宣传的形式包括但不限于点赞(STAR),推特,短视频,文章文案等,根据不同的宣传渠道和效果会获得不同的积分收益,你可以使用积分来抵扣官方网站的会员费,或是做为商业版本授权的折扣(最多可抵扣50%),还有一些其它的收益方式,正在讨论中,到时候会有一个专门的业务系统来管理和统计这些数据.
- 技术服务: 可选项目,每年支付一次,主要用于软件二次开发商做二次开发的时候的技术咨询和服务,其它业务场景则不需要支付此费用,具体请咨询.
- 额外说明: 本系统指的是计算机软件代码,系统里面带的模板并不是开源项目的一部分.虽然系统会自带四套模板供大家免费使用,但更多模板需要购买模板的授权.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ChatBook
Similar Open Source Tools
ChatBook
ChatBook provides a one-stop AI service, including basic AI dialogue, AI role agents, AI customer service, AI knowledge base, AI mind map generation, and AI PPTX generation. Users can define AI workflows freely to handle more complex business scenarios. The backend uses serverless functions with data stored in the ./data directory. The tool allows administrators to manage knowledge bases, configure keys, and review user registrations. Normal users can directly use AI models and knowledge bases after registration. The technology stack includes LLM models like Langchain, Pinecone, OpenAi, Gemini, Baidu Wenxin, Node Express for backend, and React, NextJS, MUI for frontend.
myscaledb
MyScaleDB is a SQL vector database designed for scalable AI applications, enabling developers to efficiently manage and process massive volumes of data using familiar SQL. It offers fast and efficient vector search, filtered search, and SQL-vector join queries. MyScaleDB is fully SQL-compatible and production-ready for AI applications, providing unmatched performance and scalability through cutting-edge OLAP architecture and advanced vector algorithms. Built on top of ClickHouse, it combines structured and vectorized data management for high accuracy and speed in filtered searches.
MyScaleDB
MyScaleDB is a SQL vector database optimized for AI applications, enabling developers to manage and process massive volumes of data efficiently. It offers fast and powerful vector search, filtered search, and SQL-vector join queries, making it fully SQL-compatible. MyScaleDB provides unmatched performance and scalability by leveraging cutting-edge OLAP database architecture and advanced vector algorithms. It is production-ready for AI applications, supporting structured data, text, vector, JSON, geospatial, and time-series data. MyScale Cloud offers fully-managed MyScaleDB with premium features on billion-scale data, making it cost-effective and simpler to use compared to specialized vector databases. Built on top of ClickHouse, MyScaleDB combines structured and vector search efficiently, ensuring high accuracy and performance in filtered search operations.
Nexior
Nexior allows users to deploy their own AI application site in minutes, offering services like GPT, Midjourney, ChatDoc, QrArt, etc. Users can use the platform without any development experience, AI account purchases, API support concerns, or payment system configurations. It supports various features such as GPT 3.5/4.0, Midjourney modes, unlimited document uploads, artistic QR code generation, payment and referral systems, and user system support. Nexior is open source, free under the MIT license, and easy to configure and deploy.
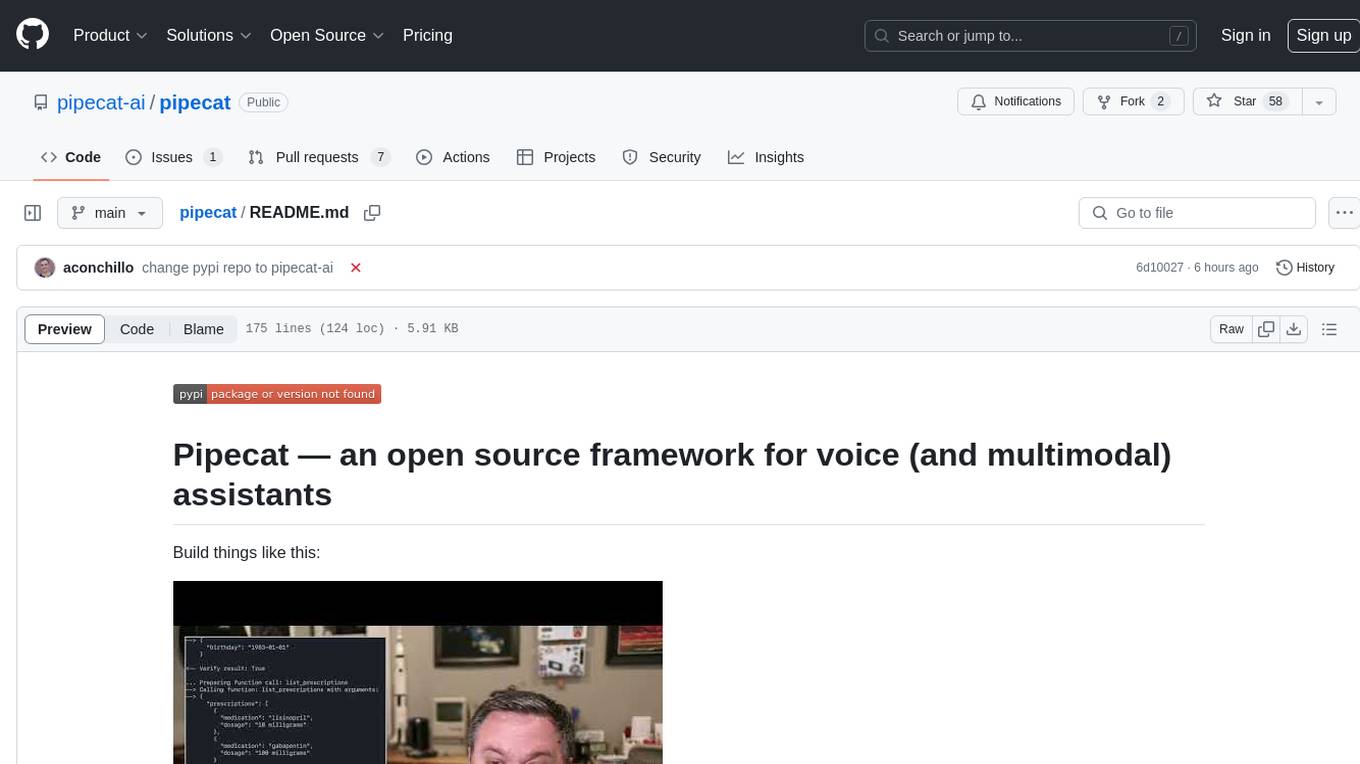
pipecat
Pipecat is an open-source framework designed for building generative AI voice bots and multimodal assistants. It provides code building blocks for interacting with AI services, creating low-latency data pipelines, and transporting audio, video, and events over the Internet. Pipecat supports various AI services like speech-to-text, text-to-speech, image generation, and vision models. Users can implement new services and contribute to the framework. Pipecat aims to simplify the development of applications like personal coaches, meeting assistants, customer support bots, and more by providing a complete framework for integrating AI services.
bagofwords
Bag of words is an open-source AI platform that helps data teams deploy and manage chat-with-your-data agents in a controlled, reliable, and self-learning environment. It enables users to create charts, tables, and dashboards by chatting with their data, capture AI decisions and user feedback, automatically improve AI quality, integrate with various data sources and APIs, and ensure governance and integrations. The platform supports self-hosting in VPC via VMs, Docker/Compose, or Kubernetes, and offers additional integrations for AI Analyst in Slack, Excel, Google Sheets, and more. Users can start in minutes and scale to org-wide analytics.
arcadia
Arcadia is an all-in-one enterprise-grade LLMOps platform that provides a unified interface for developers and operators to build, debug, deploy, and manage AI agents. It supports various LLMs, embedding models, reranking models, and more. Built on langchaingo (golang) for better performance and maintainability. The platform follows the operator pattern that extends Kubernetes APIs, ensuring secure and efficient operations.
cheat-sheet-pdf
The Cheat-Sheet Collection for DevOps, Engineers, IT professionals, and more is a curated list of cheat sheets for various tools and technologies commonly used in the software development and IT industry. It includes cheat sheets for Nginx, Docker, Ansible, Python, Go (Golang), Git, Regular Expressions (Regex), PowerShell, VIM, Jenkins, CI/CD, Kubernetes, Linux, Redis, Slack, Puppet, Google Cloud Developer, AI, Neural Networks, Machine Learning, Deep Learning & Data Science, PostgreSQL, Ajax, AWS, Infrastructure as Code (IaC), System Design, and Cyber Security.
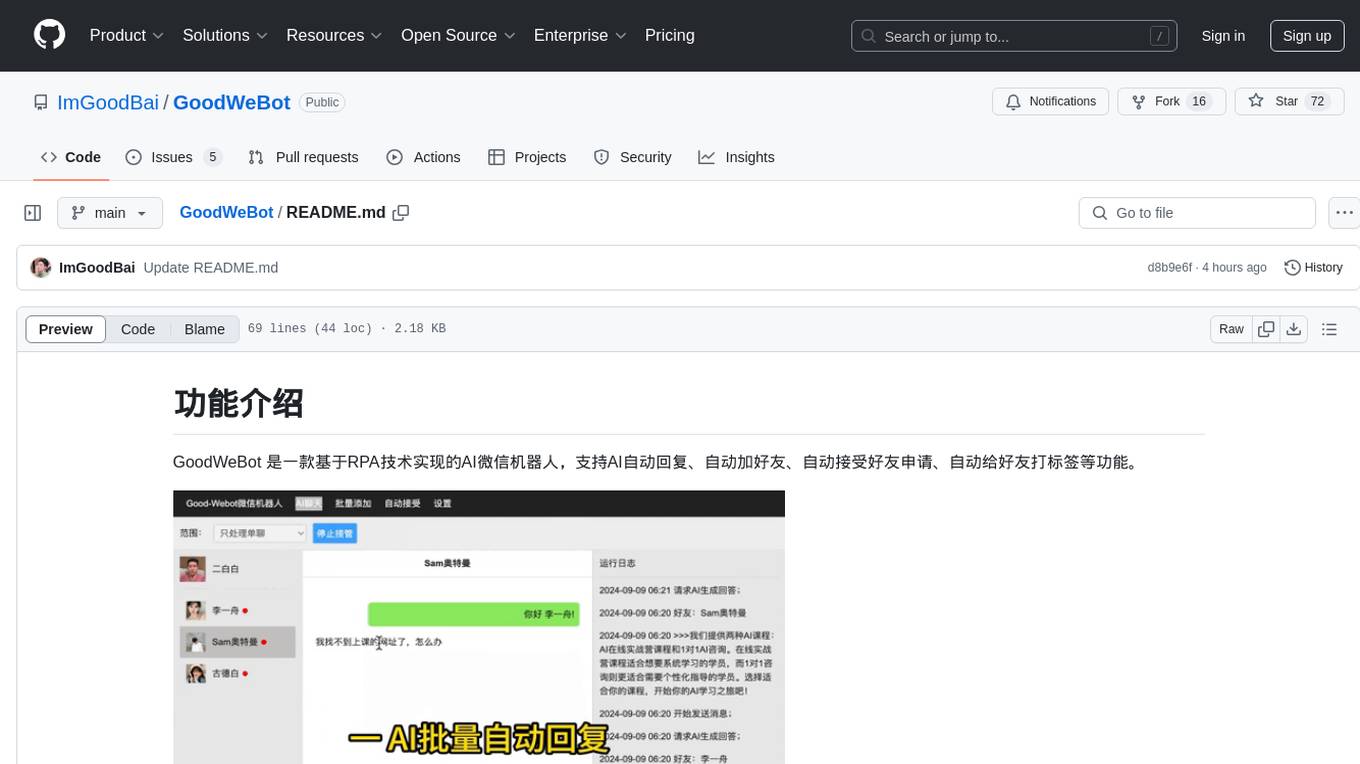
GoodWeBot
GoodWeBot is an AI WeChat robot based on RPA technology, supporting AI automatic replies, automatic friend adding, automatic friend request acceptance, automatic friend tagging, and more. It is fully compliant with RPA technology, easy to use with one-click download and run without installation, and integrates with mainstream AI services like coze. The tool is free to use and provides features like AI chat support, contact synchronization, group messaging, and coze API testing. Users should comply with GPL 3.0 open-source license and use the tool for technical research and learning purposes only, following local laws and regulations. The tool should not be used for any illegal or infringing activities, and users are responsible for the consequences of their usage.
flowdeer-dist
FlowDeer Tree is an AI tool designed for managing complex workflows and facilitating deep thoughts. It provides features such as displaying thinking chains, assigning tasks to AI members, utilizing task conclusions as context, copying and importing AI members in JSON format, adjusting node sequences, calling external APIs as plugins, and customizing default task splitting, execution, summarization, and output rewriting prompts. The tool aims to streamline workflow processes and enhance productivity by leveraging artificial intelligence capabilities.

lightllm
LightLLM is a Python-based LLM (Large Language Model) inference and serving framework known for its lightweight design, scalability, and high-speed performance. It offers features like tri-process asynchronous collaboration, Nopad for efficient attention operations, dynamic batch scheduling, FlashAttention integration, tensor parallelism, Token Attention for zero memory waste, and Int8KV Cache. The tool supports various models like BLOOM, LLaMA, StarCoder, Qwen-7b, ChatGLM2-6b, Baichuan-7b, Baichuan2-7b, Baichuan2-13b, InternLM-7b, Yi-34b, Qwen-VL, Llava-7b, Mixtral, Stablelm, and MiniCPM. Users can deploy and query models using the provided server launch commands and interact with multimodal models like QWen-VL and Llava using specific queries and images.

ChatChat
Chat Chat is a unified chat and search to AI platform with a simple and easy-to-use interface. It supports major AI providers such as Anthropic, OpenAI, Cohere, and Google Gemini, and is easy to self-host. Chat Chat can be used for a variety of tasks, including searching for information, getting help with writing, and translating languages.
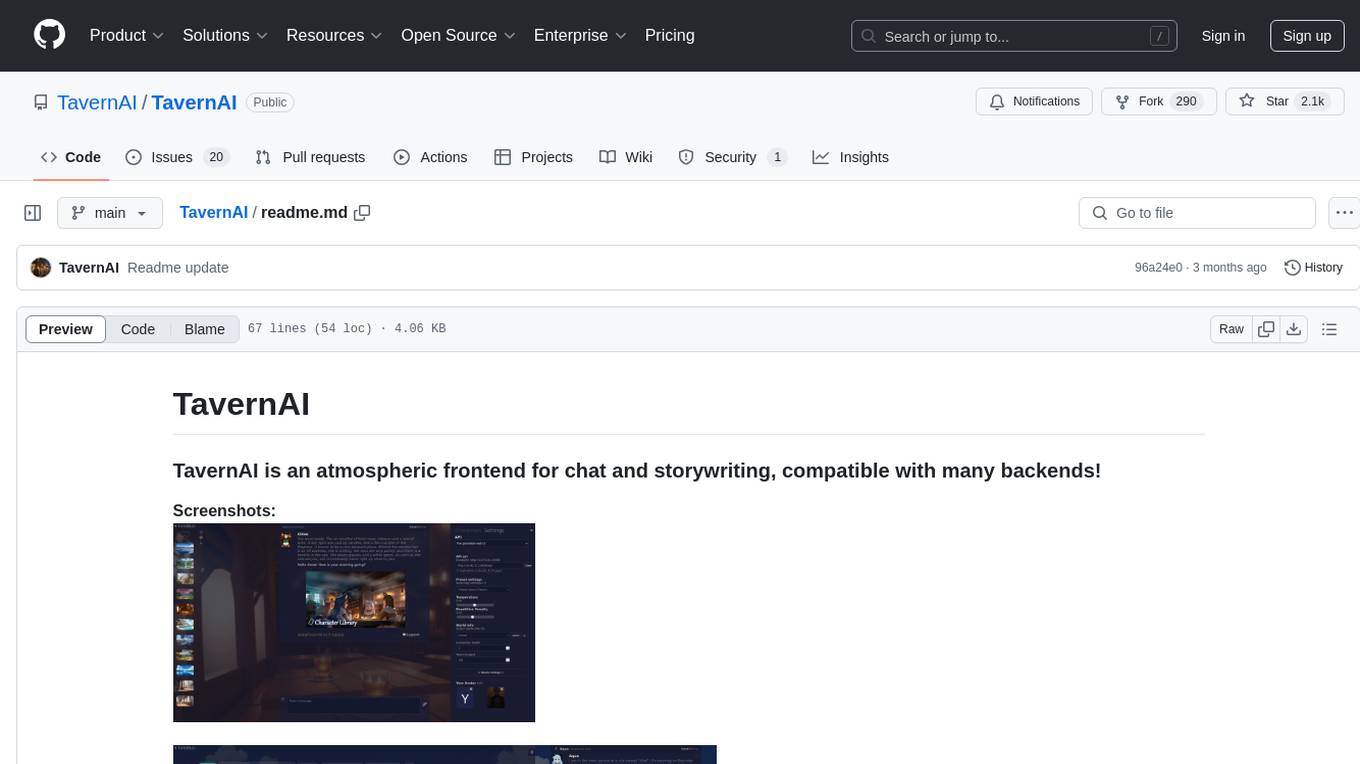
TavernAI
TavernAI is an atmospheric frontend tool for chat and storywriting, compatible with various backends. It offers features like character creation, online character database, group chat, story mode, world info, message swiping, configurable settings, interface themes, backgrounds, message editing, GPT-4.5, and Claude picture recognition. The tool supports backends like Kobold series, Oobabooga's Text Generation Web UI, OpenAI, NovelAI, and Claude. Users can easily install TavernAI on different operating systems and start using it for interactive storytelling and chat experiences.
AiEditor
AiEditor is a next-generation rich text editor for AI, based on Web Component and supporting various front-end frameworks. It offers two themes, light and dark, along with flexible configuration for developing text editing applications. The editor includes features for basic text formatting, enhancements like undo/redo and format painter, support for attachments like images and videos, code-related functionalities, table manipulation, Markdown support, AI-related features such as continuation and optimization, and more. Planned improvements include collaboration, automated testing, AI picture insertion and drawing, enhanced paste features, WORD and PDF export, Notion-like operations, and integration with ChatGPT.
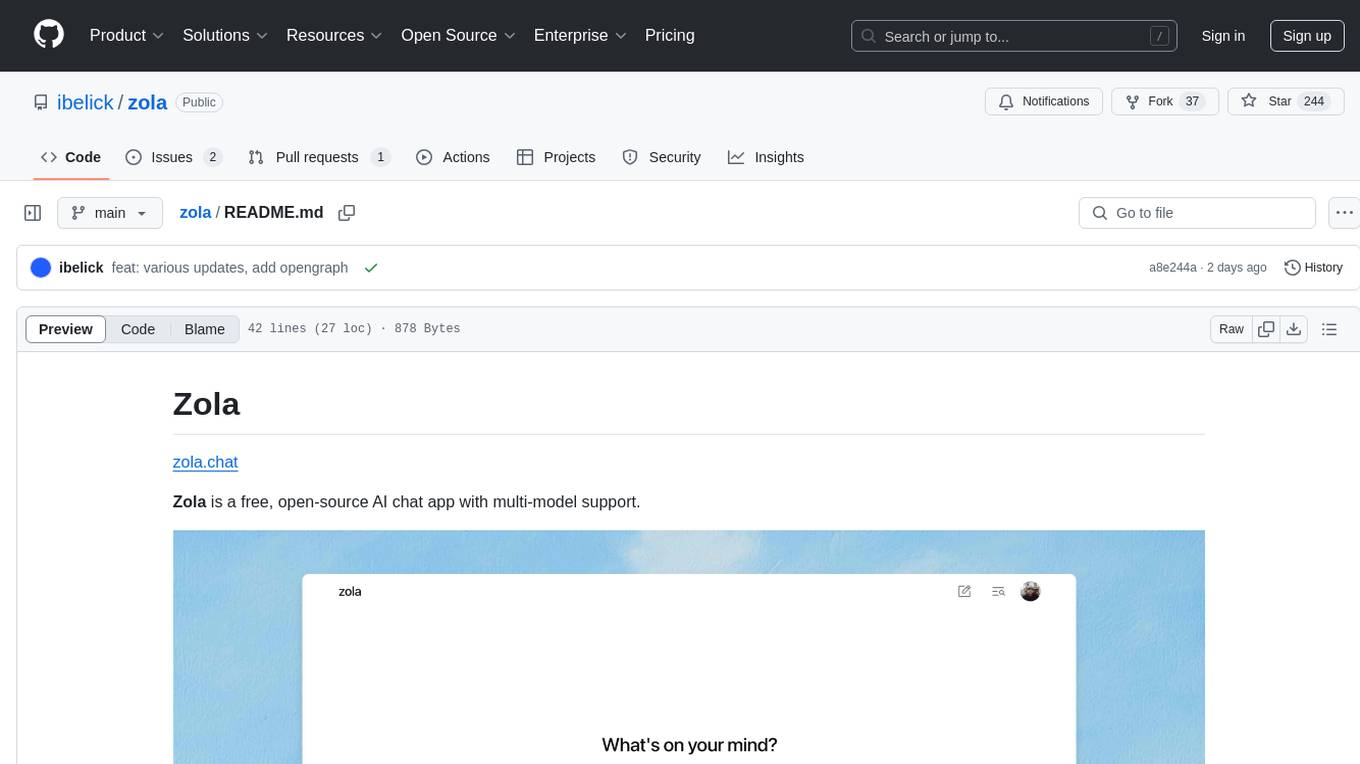
zola
Zola is a free, open-source AI chat app with multi-model support. It features light and dark mode, prompt suggestions, file uploads, and a mobile-friendly layout. Built with prompt-kit, shadcn/ui, motion-primitives, vercel ai sdk, and supabase. Coming next are more model support, search, agent mode, and memory. Beta release with evolving codebase.
chatAir
ChatAir is a native client for ChatGPT and Gemini, designed to provide a smoother and faster chat experience than ChatGPT. It is developed natively on Android, offering efficient performance and a seamless user experience. ChatAir supports OpenAI/Gemini API calls and allows customization of server addresses. It also features Markdown support, code highlighting, customizable settings for prompts, model, temperature, history, and reply length limit, dark mode, customized themes, and image recognition function for quick and accurate image information retrieval.
For similar tasks
ChatBook
ChatBook provides a one-stop AI service, including basic AI dialogue, AI role agents, AI customer service, AI knowledge base, AI mind map generation, and AI PPTX generation. Users can define AI workflows freely to handle more complex business scenarios. The backend uses serverless functions with data stored in the ./data directory. The tool allows administrators to manage knowledge bases, configure keys, and review user registrations. Normal users can directly use AI models and knowledge bases after registration. The technology stack includes LLM models like Langchain, Pinecone, OpenAi, Gemini, Baidu Wenxin, Node Express for backend, and React, NextJS, MUI for frontend.
awesome-langchain-zh
The awesome-langchain-zh repository is a collection of resources related to LangChain, a framework for building AI applications using large language models (LLMs). The repository includes sections on the LangChain framework itself, other language ports of LangChain, tools for low-code development, services, agents, templates, platforms, open-source projects related to knowledge management and chatbots, as well as learning resources such as notebooks, videos, and articles. It also covers other LLM frameworks and provides additional resources for exploring and working with LLMs. The repository serves as a comprehensive guide for developers and AI enthusiasts interested in leveraging LangChain and LLMs for various applications.

empower-functions
Empower Functions is a family of large language models (LLMs) that provide GPT-4 level capabilities for real-world 'tool using' use cases. These models offer compatibility support to be used as drop-in replacements, enabling interactions with external APIs by recognizing when a function needs to be called and generating JSON containing necessary arguments based on user inputs. This capability is crucial for building conversational agents and applications that convert natural language into API calls, facilitating tasks such as weather inquiries, data extraction, and interactions with knowledge bases. The models can handle multi-turn conversations, choose between tools or standard dialogue, ask for clarification on missing parameters, integrate responses with tool outputs in a streaming fashion, and efficiently execute multiple functions either in parallel or sequentially with dependencies.

wenda
Wenda is a platform for large-scale language model invocation designed to efficiently generate content for specific environments, considering the limitations of personal and small business computing resources, as well as knowledge security and privacy issues. The platform integrates capabilities such as knowledge base integration, multiple large language models for offline deployment, auto scripts for additional functionality, and other practical capabilities like conversation history management and multi-user simultaneous usage.
rag-chat
The `@upstash/rag-chat` package simplifies the development of retrieval-augmented generation (RAG) chat applications by providing Next.js compatibility with streaming support, built-in vector store, optional Redis compatibility for fast chat history management, rate limiting, and disableRag option. Users can easily set up the environment variables and initialize RAGChat to interact with AI models, manage knowledge base, chat history, and enable debugging features. Advanced configuration options allow customization of RAGChat instance with built-in rate limiting, observability via Helicone, and integration with Next.js route handlers and Vercel AI SDK. The package supports OpenAI models, Upstash-hosted models, and custom providers like TogetherAi and Replicate.
KB-Builder
KB Builder is an open-source knowledge base generation system based on the LLM large language model. It utilizes the RAG (Retrieval-Augmented Generation) data generation enhancement method to provide users with the ability to enhance knowledge generation and quickly build knowledge bases based on RAG. It aims to be the central hub for knowledge construction in enterprises, offering platform-based intelligent dialogue services and document knowledge base management functionality. Users can upload docx, pdf, txt, and md format documents and generate high-quality knowledge base question-answer pairs by invoking large models through the 'Parse Document' feature.
refly
Refly.AI is an open-source AI-native creation engine that empowers users to transform ideas into production-ready content. It features a free-form canvas interface with multi-threaded conversations, knowledge base integration, contextual memory, intelligent search, WYSIWYG AI editor, and more. Users can leverage AI-powered capabilities, context memory, knowledge base integration, quotes, and AI document editing to enhance their content creation process. Refly offers both cloud and self-hosting options, making it suitable for individuals, enterprises, and organizations. The tool is designed to facilitate human-AI collaboration and streamline content creation workflows.
magic
Magic is an open-source all-in-one AI productivity platform designed to help enterprises quickly build and deploy AI applications, aiming for a 100x increase in productivity. It consists of various AI products and infrastructure tools, such as Super Magic, Magic IM, Magic Flow, and more. Super Magic is a general-purpose AI Agent for complex task scenarios, while Magic Flow is a visual AI workflow orchestration system. Magic IM is an enterprise-grade AI Agent conversation system for internal knowledge management. Teamshare OS is a collaborative office platform integrating AI capabilities. The platform provides cloud services, enterprise solutions, and a self-hosted community edition for users to leverage its features.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.