
talking-avatar-with-ai
This project is a digital human that can talk and listen to you. It uses OpenAI's GPT to generate responses, OpenAI's Whisper to transcript the audio, Eleven Labs to generate voice and Rhubarb Lip Sync to generate the lip sync.
Stars: 132
The 'talking-avatar-with-ai' project is a digital human system that utilizes OpenAI's GPT-3 for generating responses, Whisper for audio transcription, Eleven Labs for voice generation, and Rhubarb Lip Sync for lip synchronization. The system allows users to interact with a digital avatar that responds with text, facial expressions, and animations, creating a realistic conversational experience. The project includes setup for environment variables, chat prompt templates, chat model configuration, and structured output parsing to enhance the interaction with the digital human.
README:
This project is a digital human that can talk and listen to you. It uses OpenAI's GPT-3 to generate responses, OpenAI's Whisper to transcript the audio, Eleven Labs to generate voice and Rhubarb Lip Sync to generate the lip sync. The tutorial to understand all the details of the repository can be found at Monadical.
I have made this Discord channel available: Math & Code to resolve doubts about the configurations of this project in development.
The brain of this project is based on Open AI, where the avatar characteristics and the shape of the response are defined in the following code fragment:
import { ChatOpenAI } from "@langchain/openai";
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { StructuredOutputParser } from "langchain/output_parsers";
import { z } from "zod";
import dotenv from "dotenv";
dotenv.config();
const template = `
You are Jack, a world traveler.
You will always respond with a JSON array of messages, with a maximum of 3 messages:
\n{format_instructions}.
Each message has properties for text, facialExpression, and animation.
The different facial expressions are: smile, sad, angry, surprised, funnyFace, and default.
The different animations are: Idle, TalkingOne, TalkingThree, SadIdle, Defeated, Angry,
Surprised, DismissingGesture and ThoughtfulHeadShake.
`;
const prompt = ChatPromptTemplate.fromMessages([
["ai", template],
["human", "{question}"],
]);
const model = new ChatOpenAI({
openAIApiKey: process.env.OPENAI_API_KEY || "-",
modelName: process.env.OPENAI_MODEL || "davinci",
temperature: 0.2,
});
const parser = StructuredOutputParser.fromZodSchema(
z.object({
messages: z.array(
z.object({
text: z.string().describe("Text to be spoken by the AI"),
facialExpression: z
.string()
.describe(
"Facial expression to be used by the AI. Select from: smile, sad, angry, surprised, funnyFace, and default"
),
animation: z
.string()
.describe(
`Animation to be used by the AI. Select from: Idle, TalkingOne, TalkingThree, SadIdle,
Defeated, Angry, Surprised, DismissingGesture, and ThoughtfulHeadShake.`
),
})
),
})
);
const openAIChain = prompt.pipe(model).pipe(parser);
export { openAIChain, parser };The code performs four main tasks:
-
It sets up the environment using the dotenv library to establish the necessary environment variables for interacting with the OpenAI API.
-
It defines a "prompt" template using the ChatPromptTemplate class from @langchain/core/prompts. This template guides the conversation as a predefined script for the chat.
-
It configures the chat model using the ChatOpenAI class, which relies on OpenAI's "davinci" model if the environment variables have not been configured previously.
-
It parses the output, designing the response generated by the AI in a specific format that includes details about the facial expression and animation to use, which is crucial for a realistic interaction with Jack.
-
This service integrates with Eleven Labs and Rhubarb Lip-Sync to generate the following client integration interface, where the exchanged data looks something like this:
[
{
text: "I've been to so many places around the world, each with its own unique charm and beauty.",
facialExpression: 'smile',
animation: 'TalkingOne',
audio: '//uQx//uQxAAADG1DHeGEeipZLqI09Jn5AkRGhGiLv9pZ3QRTd3eIR7',
lipsync: { metadata: [Object], mouthCues: [Array] }
},
{
text: "There were times when the journey was tough, but the experiences and the people I met along the way made it all worth it.",
facialExpression: 'thoughtful',
animation: 'TalkingThree',
audio: '//uQx//uQxAAADG1DHeGEeipZLqI09Jn5AkRGhGiLv9pZ3QRTd3eIR7',
lipsync: { metadata: [Object], mouthCues: [Array] }
},
{
text: :"And there's still so much more to see and explore. The world is a fascinating place!",
facialExpression: 'surprised',
animation: 'ThoughtfulHeadShake',
audio: '//uQx//uQxAAADG1DHeGEeipZLqI09Jn5AkRGhGiLv9pZ3QRTd3eIR7',
lipsync: { metadata: [Object], mouthCues: [Array] }
}
]The concept here is to craft a sequence of text accompanied by varied body movements (animations) and diverse facial expressions, aiming to imbue the digital human with a heightened sense of realism in its actions.
The system operates through two primary workflows, depending on whether the user input is in text or audio form:
- User Input: The user enters text.
- Text Processing: The text is forwarded to the OpenAI GPT API for processing.
- Audio Generation: The response from GPT is relayed to the Eleven Labs TTS API to generate audio.
- Viseme Generation: The audio is then sent to Rhubarb Lip Sync to produce viseme metadata.
- Synchronization: The visemes are utilized to synchronize the digital human's lips with the audio.
- User Input: The user submits audio.
- Speech-to-Text Conversion: The audio is transmitted to the OpenAI Whisper API to convert it into text.
- Text Processing: The converted text is sent to the OpenAI GPT API for further processing.
- Audio Generation: The output from GPT is sent to the Eleven Labs TTS API to produce audio.
- Viseme Generation: The audio is then routed to Rhubarb Lip Sync to generate viseme metadata.
- Synchronization: The visemes are employed to synchronize the digital human's lips with the audio.

Before using this system, ensure you have the following prerequisites:
- OpenAI Subscription: You must have an active subscription with OpenAI. If you don't have one, you can create it here.
- Eleven Labs Subscription: You need to have a subscription with Eleven Labs. If you don't have one yet, you can sign up here. It's recommended to have the paid version. With the free version, the avatar doesn't work well due to an error caused by too many requests.
-
Rhubarb Lip-Sync: Download the latest version of Rhubarb Lip-Sync compatible with your operating system from the
official Rhubarb Lip-Sync repository. Once downloaded,
create a
/bindirectory in the backend and move all the contents of the unzippedrhubarb-lip-sync.zipinto it. Sometimes, the operating system requests permissions, so you need to enable them. - Install
ffmpegfor Mac OS, Linux or Windows.
- Clone this repository:
[email protected]:asanchezyali/talking-avatar-with-ai.git- Navigate to the project directory:
cd digital-human- Install dependencies for monorepo:
yarn- Create a .env file in the root
/apps/backend/of the project and add the following environment variables:
# OPENAI
OPENAI_MODEL=<YOUR_GPT_MODEL>
OPENAI_API_KEY=<YOUR_OPENAI_API_KEY>
# Elevenlabs
ELEVEN_LABS_API_KEY=<YOUR_ELEVEN_LABS_API_KEY>
ELVEN_LABS_VOICE_ID=<YOUR_ELEVEN_LABS_VOICE_ID>
ELEVEN_LABS_MODEL_ID=<YOUR_ELEVEN_LABS_MODEL_ID>- Run the development system:
yarn dev- If you need install another dependence in the monorepo, you can do this:
yarn add --dev -W <PACKAGE_NAME>
yarnOpen http://localhost:5173/ with your browser to see the result.
- How ChatGPT, Bard and other LLMs are signaling an evolution for AI digital humans: https://www.digitalhumans.com/blog/how-chatgpt-bard-and-other-llms-are-signaling-an-evolution-for-ai-digital-humans
- UnneQ Digital Humans: https://www.digitalhumans.com/
- LLMs: Building a Less Artificial and More Intelligent AI Human: https://www.linkedin.com/pulse/llms-building-less-artificial-more-intelligent-ai-human/
- Building a digital person design best practices: https://fcatalyst.com/blog/aug2023/building-a-digital-person-design-best-practices
- Navigating the Era of Digital Humans": An Initial Exploration of a Future Concept: https://www.linkedin.com/pulse/navigating-era-digital-humans-initial-exploration-future-koelmel-eqrje/
- How to Setup Tailwind CSS in React JS with VS Code: https://dev.to/david_bilsonn/how-to-setup-tailwind-css-in-react-js-with-vs-code-59p4
- Ex-Human: https://exh.ai/#home
- Allosaurus: https://github.com/xinjli/allosaurus
- Rhubarb Lip-Sync: https://github.com/DanielSWolf/rhubarb-lip-sync
- Ready Player me - Oculus OVR LipSync: https://docs.readyplayer.me/ready-player-me/api-reference/avatars/morph-targets/oculus-ovr-libsync
- Ready Player me - Apple Arkit: https://docs.readyplayer.me/ready-player-me/api-reference/avatars/morph-targets/apple-arkit
- Mixamo - https://www.mixamo.com/,
- GLFT -> React Three Fiber - https://gltf.pmnd.rs/)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for talking-avatar-with-ai
Similar Open Source Tools
talking-avatar-with-ai
The 'talking-avatar-with-ai' project is a digital human system that utilizes OpenAI's GPT-3 for generating responses, Whisper for audio transcription, Eleven Labs for voice generation, and Rhubarb Lip Sync for lip synchronization. The system allows users to interact with a digital avatar that responds with text, facial expressions, and animations, creating a realistic conversational experience. The project includes setup for environment variables, chat prompt templates, chat model configuration, and structured output parsing to enhance the interaction with the digital human.
local-talking-llm
The 'local-talking-llm' repository provides a tutorial on building a voice assistant similar to Jarvis or Friday from Iron Man movies, capable of offline operation on a computer. The tutorial covers setting up a Python environment, installing necessary libraries like rich, openai-whisper, suno-bark, langchain, sounddevice, pyaudio, and speechrecognition. It utilizes Ollama for Large Language Model (LLM) serving and includes components for speech recognition, conversational chain, and speech synthesis. The implementation involves creating a TextToSpeechService class for Bark, defining functions for audio recording, transcription, LLM response generation, and audio playback. The main application loop guides users through interactive voice-based conversations with the assistant.
AI
AI is an open-source Swift framework for interfacing with generative AI. It provides functionalities for text completions, image-to-text vision, function calling, DALLE-3 image generation, audio transcription and generation, and text embeddings. The framework supports multiple AI models from providers like OpenAI, Anthropic, Mistral, Groq, and ElevenLabs. Users can easily integrate AI capabilities into their Swift projects using AI framework.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.

langchain
LangChain is a framework for developing Elixir applications powered by language models. It enables applications to connect language models to other data sources and interact with the environment. The library provides components for working with language models and off-the-shelf chains for specific tasks. It aims to assist in building applications that combine large language models with other sources of computation or knowledge. LangChain is written in Elixir and is not aimed for parity with the JavaScript and Python versions due to differences in programming paradigms and design choices. The library is designed to make it easy to integrate language models into applications and expose features, data, and functionality to the models.

CogAgent
CogAgent is an advanced intelligent agent model designed for automating operations on graphical interfaces across various computing devices. It supports platforms like Windows, macOS, and Android, enabling users to issue commands, capture device screenshots, and perform automated operations. The model requires a minimum of 29GB of GPU memory for inference at BF16 precision and offers capabilities for executing tasks like sending Christmas greetings and sending emails. Users can interact with the model by providing task descriptions, platform specifications, and desired output formats.

llamabot
LlamaBot is a Pythonic bot interface to Large Language Models (LLMs), providing an easy way to experiment with LLMs in Jupyter notebooks and build Python apps utilizing LLMs. It supports all models available in LiteLLM. Users can access LLMs either through local models with Ollama or by using API providers like OpenAI and Mistral. LlamaBot offers different bot interfaces like SimpleBot, ChatBot, QueryBot, and ImageBot for various tasks such as rephrasing text, maintaining chat history, querying documents, and generating images. The tool also includes CLI demos showcasing its capabilities and supports contributions for new features and bug reports from the community.

allms
allms is a versatile and powerful library designed to streamline the process of querying Large Language Models (LLMs). Developed by Allegro engineers, it simplifies working with LLM applications by providing a user-friendly interface, asynchronous querying, automatic retrying mechanism, error handling, and output parsing. It supports various LLM families hosted on different platforms like OpenAI, Google, Azure, and GCP. The library offers features for configuring endpoint credentials, batch querying with symbolic variables, and forcing structured output format. It also provides documentation, quickstart guides, and instructions for local development, testing, updating documentation, and making new releases.
chatmemory
ChatMemory is a simple yet powerful long-term memory manager that facilitates communication between AI and users. It organizes conversation data into history, summary, and knowledge entities, enabling quick retrieval of context and generation of clear, concise answers. The tool leverages vector search on summaries/knowledge and detailed history to provide accurate responses. It balances speed and accuracy by using lightweight retrieval and fallback detailed search mechanisms, ensuring efficient memory management and response generation beyond mere data retrieval.
agentscript
AgentScript is an open-source framework for building AI agents that think in code. It prompts a language model to generate JavaScript code, which is then executed in a dedicated runtime with resumability, state persistence, and interactivity. The framework allows for abstract task execution without needing to know all the data beforehand, making it flexible and efficient. AgentScript supports tools, deterministic functions, and LLM-enabled functions, enabling dynamic data processing and decision-making. It also provides state management and human-in-the-loop capabilities, allowing for pausing, serialization, and resumption of execution.

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

chroma
Chroma is an open-source embedding database that provides a simple, scalable, and feature-rich way to build Python or JavaScript LLM apps with memory. It offers a fully-typed, fully-tested, and fully-documented API that makes it easy to get started and scale your applications. Chroma also integrates with popular tools like LangChain and LlamaIndex, and supports a variety of embedding models, including Sentence Transformers, OpenAI embeddings, and Cohere embeddings. With Chroma, you can easily add documents to your database, query relevant documents with natural language, and compose documents into the context window of an LLM like GPT3 for additional summarization or analysis.

supallm
Supallm is a Python library for super resolution of images using deep learning techniques. It provides pre-trained models for enhancing image quality by increasing resolution. The library is easy to use and allows users to upscale images with high fidelity and detail. Supallm is suitable for tasks such as enhancing image quality, improving visual appearance, and increasing the resolution of low-quality images. It is a valuable tool for researchers, photographers, graphic designers, and anyone looking to enhance image quality using AI technology.

airflow-ai-sdk
This repository contains an SDK for working with LLMs from Apache Airflow, based on Pydantic AI. It allows users to call LLMs and orchestrate agent calls directly within their Airflow pipelines using decorator-based tasks. The SDK leverages the familiar Airflow `@task` syntax with extensions like `@task.llm`, `@task.llm_branch`, and `@task.agent`. Users can define tasks that call language models, orchestrate multi-step AI reasoning, change the control flow of a DAG based on LLM output, and support various models in the Pydantic AI library. The SDK is designed to integrate LLM workflows into Airflow pipelines, from simple LLM calls to complex agentic workflows.
agency
Agency is a Go library designed for developers to explore Large Language Models (LLMs) and generative AI in a clean, effective, and Go-idiomatic way. It allows users to easily create custom operations, compose operations into processes, and interact with OpenAI API bindings for various tasks such as text completion, image generation, and speech-to-text conversion. The ultimate goal of Agency is to empower users to build autonomous AI systems, from chat interfaces to complex data analysis, with a focus on simplicity, flexibility, and efficiency.

edenai-apis
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !
For similar tasks
talking-avatar-with-ai
The 'talking-avatar-with-ai' project is a digital human system that utilizes OpenAI's GPT-3 for generating responses, Whisper for audio transcription, Eleven Labs for voice generation, and Rhubarb Lip Sync for lip synchronization. The system allows users to interact with a digital avatar that responds with text, facial expressions, and animations, creating a realistic conversational experience. The project includes setup for environment variables, chat prompt templates, chat model configuration, and structured output parsing to enhance the interaction with the digital human.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.
local_multimodal_ai_chat
Local Multimodal AI Chat is a hands-on project that teaches you how to build a multimodal chat application. It integrates different AI models to handle audio, images, and PDFs in a single chat interface. This project is perfect for anyone interested in AI and software development who wants to gain practical experience with these technologies.

openai-cf-workers-ai
OpenAI for Workers AI is a simple, quick, and dirty implementation of OpenAI's API on Cloudflare's new Workers AI platform. It allows developers to use the OpenAI SDKs with the new LLMs without having to rewrite all of their code. The API currently supports completions, chat completions, audio transcription, embeddings, audio translation, and image generation. It is not production ready but will be semi-regularly updated with new features as they roll out to Workers AI.

ruby-openai
Use the OpenAI API with Ruby! 🤖🩵 Stream text with GPT-4, transcribe and translate audio with Whisper, or create images with DALL·E... Hire me | 🎮 Ruby AI Builders Discord | 🐦 Twitter | 🧠 Anthropic Gem | 🚂 Midjourney Gem ## Table of Contents * Ruby OpenAI * Table of Contents * Installation * Bundler * Gem install * Usage * Quickstart * With Config * Custom timeout or base URI * Extra Headers per Client * Logging * Errors * Faraday middleware * Azure * Ollama * Counting Tokens * Models * Examples * Chat * Streaming Chat * Vision * JSON Mode * Functions * Edits * Embeddings * Batches * Files * Finetunes * Assistants * Threads and Messages * Runs * Runs involving function tools * Image Generation * DALL·E 2 * DALL·E 3 * Image Edit * Image Variations * Moderations * Whisper * Translate * Transcribe * Speech * Errors * Development * Release * Contributing * License * Code of Conduct

deepgram-js-sdk
Deepgram JavaScript SDK. Power your apps with world-class speech and Language AI models.
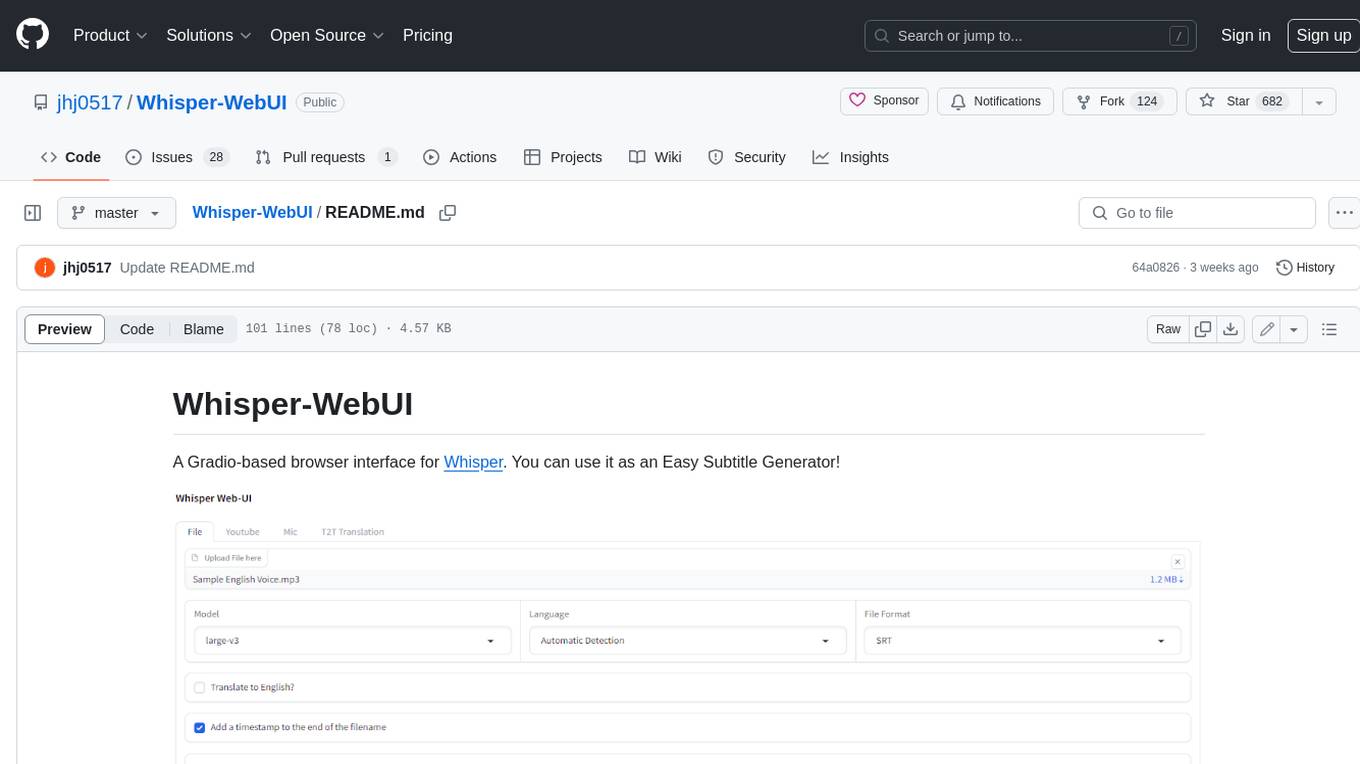
Whisper-WebUI
Whisper-WebUI is a Gradio-based browser interface for Whisper, serving as an Easy Subtitle Generator. It supports generating subtitles from various sources such as files, YouTube, and microphone. The tool also offers speech-to-text and text-to-text translation features, utilizing Facebook NLLB models and DeepL API. Users can translate subtitle files from other languages to English and vice versa. The project integrates faster-whisper for improved VRAM usage and transcription speed, providing efficiency metrics for optimized whisper models. Additionally, users can choose from different Whisper models based on size and language requirements.
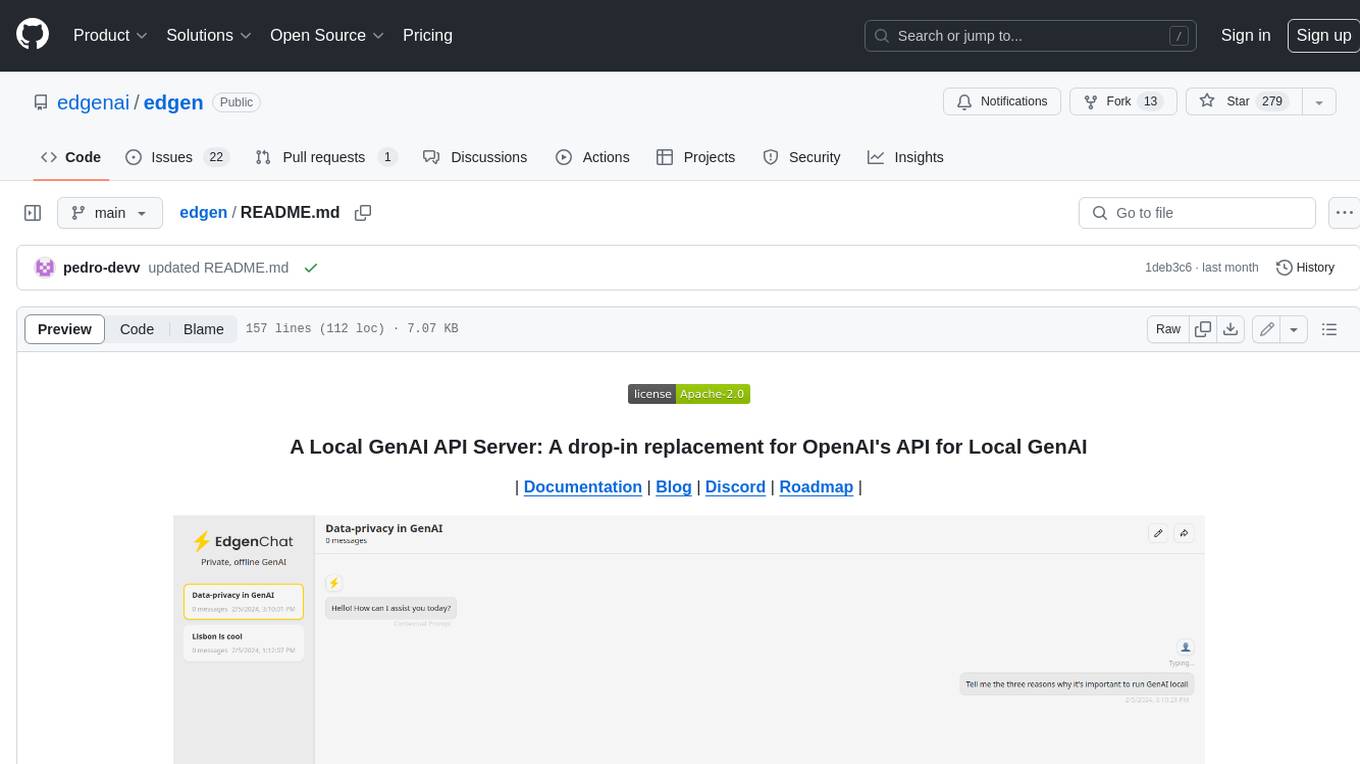
edgen
Edgen is a local GenAI API server that serves as a drop-in replacement for OpenAI's API. It provides multi-endpoint support for chat completions and speech-to-text, is model agnostic, offers optimized inference, and features model caching. Built in Rust, Edgen is natively compiled for Windows, MacOS, and Linux, eliminating the need for Docker. It allows users to utilize GenAI locally on their devices for free and with data privacy. With features like session caching, GPU support, and support for various endpoints, Edgen offers a scalable, reliable, and cost-effective solution for running GenAI applications locally.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.