
Agentless
Agentless🐱: an agentless approach to automatically solve software development problems
Stars: 301
Agentless is an open-source tool designed for automatically solving software development problems. It follows a two-phase process of localization and repair to identify faults in specific files, classes, and functions, and generate candidate patches for fixing issues. The tool is aimed at simplifying the software development process by automating issue resolution and patch generation.
README:

😽News | 🐈Setup | 🙀Localization | 😼Repair | 🧶Comparison | 🐈⬛Artifacts | 📝Citation | 😻Acknowledgement
- July 1st, 2024: We just released OpenAutoCoder-Agentless 1.0! Agentless currently is the best open-source approach on SWE-bench lite with 82 fixes (27.3%) and costing on average $0.34 per issue.
Agentless is an agentless approach to automatically solve software development problems. To solve each issue, Agentless follows a simple two phase process: localization and repair.
- 🙀 Localization: Agentless employs a hierarchical process to first localize the fault to specific files, then to relevant classes or functions, and finally to fine-grained edit locations
- 😼 Repair : Agentless takes the edit locations and generates multiple candidate patches in a simple diff format, performs test filtering, and re-ranks all remaining patches to selects one to submit
First create the environment
git clone https://github.com/OpenAutoCoder/Agentless.git
cd Agentless
conda create -n agentless python=3.11
conda activate agentless
pip install -r requirements.txt
export PYTHONPATH=$PYTHONPATH:$(pwd)⏬ Developer Setup
# for contribution, please install the pre-commit hook.
pre-commit install # this allows a more standardized code styleThen export your OpenAI API key
export OPENAI_API_KEY={key_here}Now you are ready to run Agentless on the problems in SWE-bench! We now go through a step-by-step example of how to run Agentless.
[!NOTE]
To reproduce the full SWE-bench lite experiments and follow our exact setup as described in the paper. Please see this README
[!TIP]
For localization, you can use
--target_idto specific a particular bug you want to target.For example
--target_id=django__django-11039
In localization, the goal is find the locations in source code where we need to edit to fix the issues. Agentless uses a 3-stage localization step to first localize to specific files, then to relevant code elements, and finally to fine-grained edit locations.
[!TIP]
Since for each issue in the benchmark we need to checkout the repository and process the files, you might want to save some time by downloading the preprocessed data here: swebench_lite_repo_structure.zip
After downloading, please unzip and export the location as such
export PROJECT_FILE_LOC={folder which you saved}
Run the following command to generate the edit locations:
mkdir results # where we will save our results
python agentless/fl/localize.py --file_level --related_level --fine_grain_line_level \
--output_folder results/location --top_n 3 \
--compress \
--context_window=10 This will save all the localized locations in results/location/loc_outputs.jsonl with the logs saved in results/location/localize.log
⏬ Structure of `loc_outputs.jsonl` :: click to expand ::
-
instance_id: task ID of the issue -
found_files: list of files localized by the model -
additional_artifact_loc_file: raw output of the model during file-level localization -
file_traj: trajectory of the model during file-level localization (e.g., # of tokens) -
found_related_locs: list of relevant code elements localized by the model -
additional_artifact_loc_related: raw output of the model during relevant-code-level localization -
related_loc_traj: trajectory of the model during relevant-code-level localization -
found_edit_locs: list of edit locations localized by the model -
additional_artifact_loc_edit_location: raw output of the model during edit-location-level localization -
edit_loc_traj: trajectory of the model during edit-location-level localization
🙀 Individual localization steps :: click to perform the individual localization step ::
We first start by localization to specific files
mkdir results # where we will save our results
python agentless/fl/localize.py --file_level --output_folder results/file_levelThis command saves the file-level localization in results/file_level/loc_outputs.jsonl, you can also check results/file_level/localize.log for detailed logs
Next, we localize to related elements within each of the files we localize
python agentless/fl/localize.py --related_level \
--output_folder results/related_level \
--start_file results/file_level/loc_outputs.jsonl \
--top_n 3 --compressHere the --start_file refers to the previous file-level localization. --top_n argument indicates the number of files we want to consider.
Similar to the previous stage, this command saves the related-element localization in results/related_level/loc_outputs.jsonl, with logs in results/related_level/localize.log
Finally, we take the related elements from the previous step and localize to the edit locations we want the LLM to generate patches for
python agentless/fl/localize.py --fine_grain_line_level \
--output_folder results/edit_location \
--start_file results/related_level/loc_outputs.jsonl \
--top_n 3 --context_window=10 Here the --start_file refers to the previous related-element localization. --context_window indicates the amount of lines before and after we provide to the LLM.
The final edit locations Agentless will perform repair on is saved in results/edit_location/loc_outputs.jsonl, with logs in results/edit_location/localize.log
For the last localization step of localizing to edit locations, we can also perform sampling to obtain multiple sets of edit locations.
python agentless/fl/localize.py --fine_grain_line_level \
--output_folder results/edit_location_samples \
--start_file results/related_level/loc_outputs.jsonl \
--top_n 3 --context_window=10 --temperature 0.8 \
--num_samples 4This command will sample with temperature 0.8 and generate 4 edit location sets. We can then merge them together to form a bigger list of edit locations.
Run the following command to merge:
python agentless/fl/localize.py --merge \
--output_folder results/edit_location_samples_merged \
--start_file results/edit_location_samples/loc_outputs.jsonl \
--num_samples 4This will perform pair-wise merging of samples (i.e., sample 0 and 1 will be merged and sample 2 and 3 will be merged). Furthermore it will also merge all samples together.
The merged location files can be found in results/edit_location_samples_merged/loc_merged_{st_id}-{en_id}_outputs.jsonl where st_id and en_id indicates the samples that are being merged. The location file with all samples merged together can be found as results/edit_location_samples_merged/loc_all_merged_outputs.jsonl. Furthermore, we also include the location of each individual sample for completeness within the folder.
Using the edit locations (i.e., found_edit_locs) from before, we now perform repair.
Agentless generates multiple patches per issue (controllable via parameters) and then perform majority voting to select the final patch for submission
Run the following command to generate the patches:
python agentless/repair/repair.py --loc_file results/location/loc_outputs.jsonl \
--output_folder results/repair \
--loc_interval --top_n=3 --context_window=10 \
--max_samples 10 --cot --diff_format \
--gen_and_process This command generates 10 samples (1 greedy and 9 via temperature sampling) as defined --max_samples 10. The --context_window indicates the amount of code lines before and after each localized edit location we provide to the model for repair. The repair results is saved in results/repair/output.jsonl, which contains the raw output of each sample as well as the any trajectory information (e.g., number of tokens). The complete logs are also saved in results/repair/repair.log
[!NOTE]
We also perform post-processing to generate the complete git-diff patch for each repair samples.
You can find the individual patch in
results/repair/output_{i}_processed.jsonlwhereiis the sample number.
Finally, we perform majority voting to select the final patch to solve each issue. Run the following command:
python agentless/repair/rerank.py --patch_folder results/repair --num_samples 10 --deduplicate --plausibleIn this case, we use --num_samples 10 to pick from the 10 samples we generated previously, --deduplicate to apply normalization to each patch for better voting, and --plausible to select patches that can pass the previous regression tests (warning: this feature is not yet implemented)
This command will produced the all_preds.jsonl that contains the final selected patch for each instance_id which you can then directly use your favorite way of testing SWE-bench for evaluation!
Below shows the comparison graph between Agentless and the best open-source agent-based approaches on SWE-bench lite

You can download the complete artifacts of Agentless in our v0.1.0 release:
- 🐈⬛ agentless_logs: raw logs and trajectory information
- 🐈⬛ swebench_lite_repo_structure: preprocessed structure information for each SWE-Bench-lite problem
- 🐈⬛ 20240630_agentless_gpt4o: evaluated run of Agentless used in our paper
@article{agentless,
author = {Xia, Chunqiu Steven and Deng, Yinlin and Dunn, Soren and Zhang, Lingming},
title = {Agentless: Demystifying LLM-based Software Engineering Agents},
year = {2024},
journal = {arXiv preprint},
}[!NOTE]
The first two authors contributed equally to this work, with author order determined via Nigiri
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Agentless
Similar Open Source Tools
Agentless
Agentless is an open-source tool designed for automatically solving software development problems. It follows a two-phase process of localization and repair to identify faults in specific files, classes, and functions, and generate candidate patches for fixing issues. The tool is aimed at simplifying the software development process by automating issue resolution and patch generation.
cover-agent
CodiumAI Cover Agent is a tool designed to help increase code coverage by automatically generating qualified tests to enhance existing test suites. It utilizes Generative AI to streamline development workflows and is part of a suite of utilities aimed at automating the creation of unit tests for software projects. The system includes components like Test Runner, Coverage Parser, Prompt Builder, and AI Caller to simplify and expedite the testing process, ensuring high-quality software development. Cover Agent can be run via a terminal and is planned to be integrated into popular CI platforms. The tool outputs debug files locally, such as generated_prompt.md, run.log, and test_results.html, providing detailed information on generated tests and their status. It supports multiple LLMs and allows users to specify the model to use for test generation.

generative-models
Generative Models by Stability AI is a repository that provides various generative models for research purposes. It includes models like Stable Video 4D (SV4D) for video synthesis, Stable Video 3D (SV3D) for multi-view synthesis, SDXL-Turbo for text-to-image generation, and more. The repository focuses on modularity and implements a config-driven approach for building and combining submodules. It supports training with PyTorch Lightning and offers inference demos for different models. Users can access pre-trained models like SDXL-base-1.0 and SDXL-refiner-1.0 under a CreativeML Open RAIL++-M license. The codebase also includes tools for invisible watermark detection in generated images.

LayerSkip
LayerSkip is an implementation enabling early exit inference and self-speculative decoding. It provides a code base for running models trained using the LayerSkip recipe, offering speedup through self-speculative decoding. The tool integrates with Hugging Face transformers and provides checkpoints for various LLMs. Users can generate tokens, benchmark on datasets, evaluate tasks, and sweep over hyperparameters to optimize inference speed. The tool also includes correctness verification scripts and Docker setup instructions. Additionally, other implementations like gpt-fast and Native HuggingFace are available. Training implementation is a work-in-progress, and contributions are welcome under the CC BY-NC license.

ML-Bench
ML-Bench is a tool designed to evaluate large language models and agents for machine learning tasks on repository-level code. It provides functionalities for data preparation, environment setup, usage, API calling, open source model fine-tuning, and inference. Users can clone the repository, load datasets, run ML-LLM-Bench, prepare data, fine-tune models, and perform inference tasks. The tool aims to facilitate the evaluation of language models and agents in the context of machine learning tasks on code repositories.

lhotse
Lhotse is a Python library designed to make speech and audio data preparation flexible and accessible. It aims to attract a wider community to speech processing tasks by providing a Python-centric design and an expressive command-line interface. Lhotse offers standard data preparation recipes, PyTorch Dataset classes for speech tasks, and efficient data preparation for model training with audio cuts. It supports data augmentation, feature extraction, and feature-space cut mixing. The tool extends Kaldi's data preparation recipes with seamless PyTorch integration, human-readable text manifests, and convenient Python classes.

sage
Sage is a tool that allows users to chat with any codebase, providing a chat interface for code understanding and integration. It simplifies the process of learning how a codebase works by offering heavily documented answers sourced directly from the code. Users can set up Sage locally or on the cloud with minimal effort. The tool is designed to be easily customizable, allowing users to swap components of the pipeline and improve the algorithms powering code understanding and generation.

co-llm
Co-LLM (Collaborative Language Models) is a tool for learning to decode collaboratively with multiple language models. It provides a method for data processing, training, and inference using a collaborative approach. The tool involves steps such as formatting/tokenization, scoring logits, initializing Z vector, deferral training, and generating results using multiple models. Co-LLM supports training with different collaboration pairs and provides baseline training scripts for various models. In inference, it uses 'vllm' services to orchestrate models and generate results through API-like services. The tool is inspired by allenai/open-instruct and aims to improve decoding performance through collaborative learning.
nextjs-openai-doc-search
This starter project is designed to process `.mdx` files in the `pages` directory to use as custom context within OpenAI Text Completion prompts. It involves building a custom ChatGPT style doc search powered by Next.js, OpenAI, and Supabase. The project includes steps for pre-processing knowledge base, storing embeddings in Postgres, performing vector similarity search, and injecting content into OpenAI GPT-3 text completion prompt.
SpeziLLM
The Spezi LLM Swift Package includes modules that help integrate LLM-related functionality in applications. It provides tools for local LLM execution, usage of remote OpenAI-based LLMs, and LLMs running on Fog node resources within the local network. The package contains targets like SpeziLLM, SpeziLLMLocal, SpeziLLMLocalDownload, SpeziLLMOpenAI, and SpeziLLMFog for different LLM functionalities. Users can configure and interact with local LLMs, OpenAI LLMs, and Fog LLMs using the provided APIs and platforms within the Spezi ecosystem.

chatgpt-cli
ChatGPT CLI provides a powerful command-line interface for seamless interaction with ChatGPT models via OpenAI and Azure. It features streaming capabilities, extensive configuration options, and supports various modes like streaming, query, and interactive mode. Users can manage thread-based context, sliding window history, and provide custom context from any source. The CLI also offers model and thread listing, advanced configuration options, and supports GPT-4, GPT-3.5-turbo, and Perplexity's models. Installation is available via Homebrew or direct download, and users can configure settings through default values, a config.yaml file, or environment variables.

paxml
Pax is a framework to configure and run machine learning experiments on top of Jax.

debug-gym
debug-gym is a text-based interactive debugging framework designed for debugging Python programs. It provides an environment where agents can interact with code repositories, use various tools like pdb and grep to investigate and fix bugs, and propose code patches. The framework supports different LLM backends such as OpenAI, Azure OpenAI, and Anthropic. Users can customize tools, manage environment states, and run agents to debug code effectively. debug-gym is modular, extensible, and suitable for interactive debugging tasks in a text-based environment.
web-codegen-scorer
Web Codegen Scorer is a tool designed to evaluate the quality of web code generated by Large Language Models (LLMs). It allows users to make evidence-based decisions related to AI-generated code by iterating on system prompts, comparing code quality from different models, and monitoring code quality over time. The tool focuses specifically on web code and offers various features such as configuring evaluations, specifying system instructions, using built-in checks for code quality, automatically repairing issues, and viewing results with an intuitive report viewer UI.
sql-eval
This repository contains the code that Defog uses for the evaluation of generated SQL. It's based off the schema from the Spider, but with a new set of hand-selected questions and queries grouped by query category. The testing procedure involves generating a SQL query, running both the 'gold' query and the generated query on their respective database to obtain dataframes with the results, comparing the dataframes using an 'exact' and a 'subset' match, logging these alongside other metrics of interest, and aggregating the results for reporting. The repository provides comprehensive instructions for installing dependencies, starting a Postgres instance, importing data into Postgres, importing data into Snowflake, using private data, implementing a query generator, and running the test with different runners.

blinkid-android
The BlinkID Android SDK is a comprehensive solution for implementing secure document scanning and extraction. It offers powerful capabilities for extracting data from a wide range of identification documents. The SDK provides features for integrating document scanning into Android apps, including camera requirements, SDK resource pre-bundling, customizing the UX, changing default strings and localization, troubleshooting integration difficulties, and using the SDK through various methods. It also offers options for completely custom UX with low-level API integration. The SDK size is optimized for different processor architectures, and API documentation is available for reference. For any questions or support, users can contact the Microblink team at help.microblink.com.
For similar tasks
Agentless
Agentless is an open-source tool designed for automatically solving software development problems. It follows a two-phase process of localization and repair to identify faults in specific files, classes, and functions, and generate candidate patches for fixing issues. The tool is aimed at simplifying the software development process by automating issue resolution and patch generation.

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

sourcegraph
Sourcegraph is a code search and navigation tool that helps developers read, write, and fix code in large, complex codebases. It provides features such as code search across all repositories and branches, code intelligence for navigation and refactoring, and the ability to fix and refactor code across multiple repositories at once.
anterion
Anterion is an open-source AI software engineer that extends the capabilities of `SWE-agent` to plan and execute open-ended engineering tasks, with a frontend inspired by `OpenDevin`. It is designed to help users fix bugs and prototype ideas with ease. Anterion is equipped with easy deployment and a user-friendly interface, making it accessible to users of all skill levels.
devika
Devika is an advanced AI software engineer that can understand high-level human instructions, break them down into steps, research relevant information, and write code to achieve the given objective. Devika utilizes large language models, planning and reasoning algorithms, and web browsing abilities to intelligently develop software. Devika aims to revolutionize the way we build software by providing an AI pair programmer who can take on complex coding tasks with minimal human guidance. Whether you need to create a new feature, fix a bug, or develop an entire project from scratch, Devika is here to assist you.
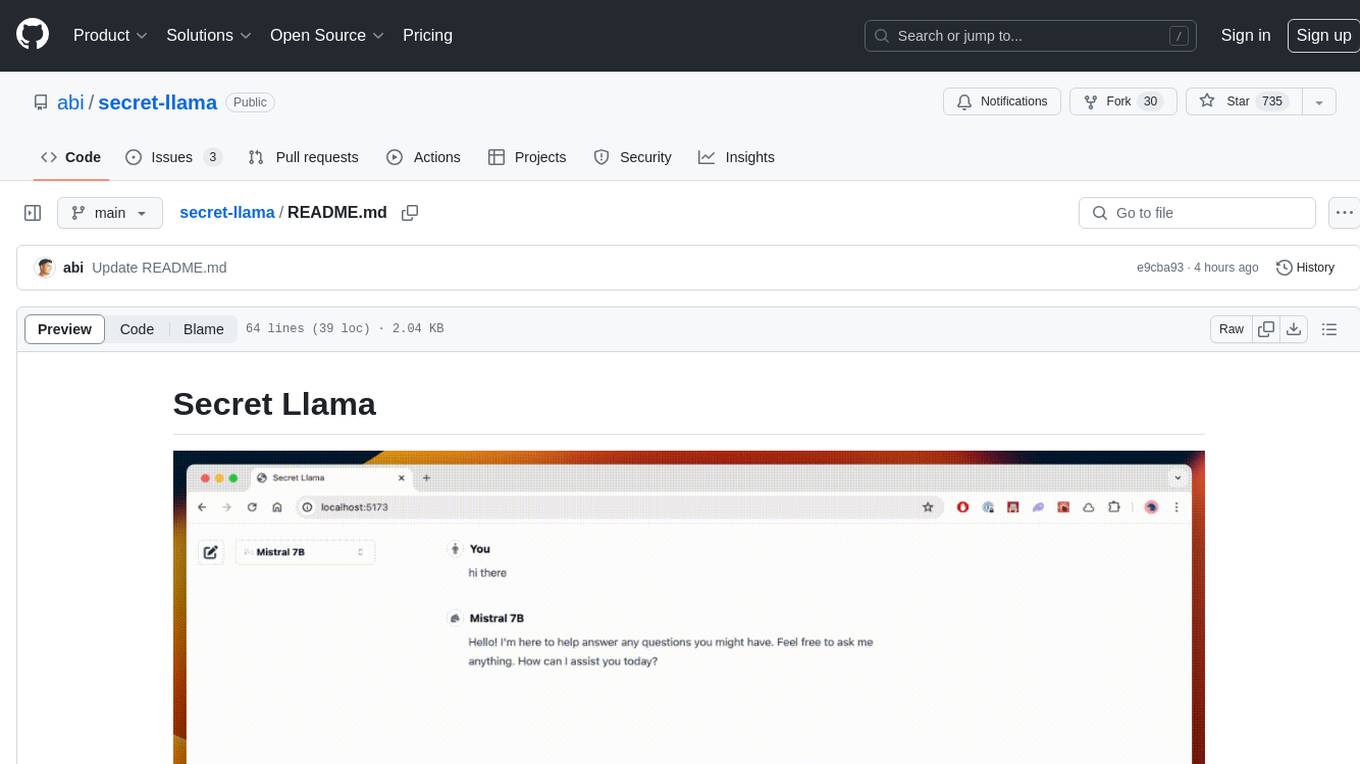
secret-llama
Entirely-in-browser, fully private LLM chatbot supporting Llama 3, Mistral and other open source models. Fully private = No conversation data ever leaves your computer. Runs in the browser = No server needed and no install needed! Works offline. Easy-to-use interface on par with ChatGPT, but for open source LLMs. System requirements include a modern browser with WebGPU support. Supported models include TinyLlama-1.1B-Chat-v0.4-q4f32_1-1k, Llama-3-8B-Instruct-q4f16_1, Phi1.5-q4f16_1-1k, and Mistral-7B-Instruct-v0.2-q4f16_1. Looking for contributors to improve the interface, support more models, speed up initial model loading time, and fix bugs.
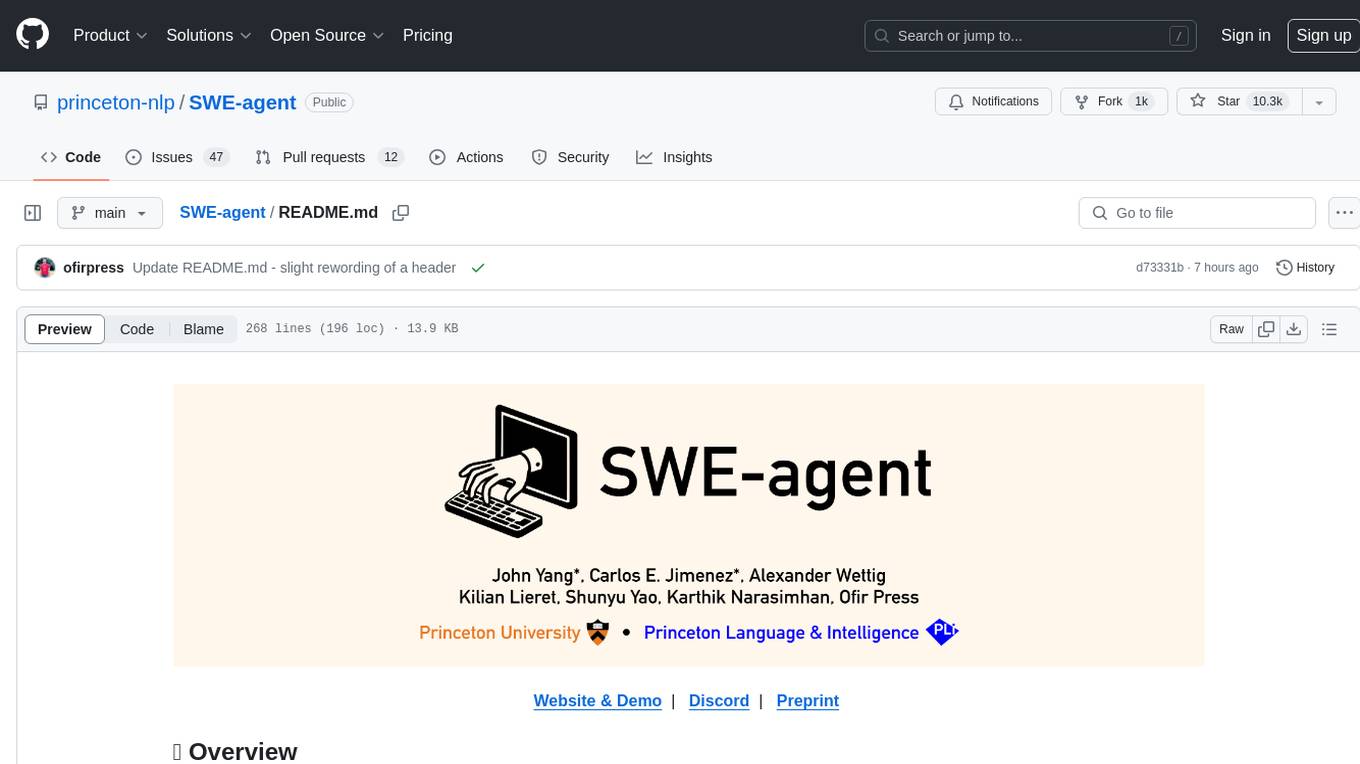
SWE-agent
SWE-agent is a tool that turns language models (e.g. GPT-4) into software engineering agents capable of fixing bugs and issues in real GitHub repositories. It achieves state-of-the-art performance on the full test set by resolving 12.29% of issues. The tool is built and maintained by researchers from Princeton University. SWE-agent provides a command line tool and a graphical web interface for developers to interact with. It introduces an Agent-Computer Interface (ACI) to facilitate browsing, viewing, editing, and executing code files within repositories. The tool includes features such as a linter for syntax checking, a specialized file viewer, and a full-directory string searching command to enhance the agent's capabilities. SWE-agent aims to improve prompt engineering and ACI design to enhance the performance of language models in software engineering tasks.

bia-bob
BIA `bob` is a Jupyter-based assistant for interacting with data using large language models to generate Python code. It can utilize OpenAI's chatGPT, Google's Gemini, Helmholtz' blablador, and Ollama. Users need respective accounts to access these services. Bob can assist in code generation, bug fixing, code documentation, GPU-acceleration, and offers a no-code custom Jupyter Kernel. It provides example notebooks for various tasks like bio-image analysis, model selection, and bug fixing. Installation is recommended via conda/mamba environment. Custom endpoints like blablador and ollama can be used. Google Cloud AI API integration is also supported. The tool is extensible for Python libraries to enhance Bob's functionality.
For similar jobs

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

nvidia_gpu_exporter
Nvidia GPU exporter for prometheus, using `nvidia-smi` binary to gather metrics.

tracecat
Tracecat is an open-source automation platform for security teams. It's designed to be simple but powerful, with a focus on AI features and a practitioner-obsessed UI/UX. Tracecat can be used to automate a variety of tasks, including phishing email investigation, evidence collection, and remediation plan generation.

openinference
OpenInference is a set of conventions and plugins that complement OpenTelemetry to enable tracing of AI applications. It provides a way to capture and analyze the performance and behavior of AI models, including their interactions with other components of the application. OpenInference is designed to be language-agnostic and can be used with any OpenTelemetry-compatible backend. It includes a set of instrumentations for popular machine learning SDKs and frameworks, making it easy to add tracing to your AI applications.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

kong
Kong, or Kong API Gateway, is a cloud-native, platform-agnostic, scalable API Gateway distinguished for its high performance and extensibility via plugins. It also provides advanced AI capabilities with multi-LLM support. By providing functionality for proxying, routing, load balancing, health checking, authentication (and more), Kong serves as the central layer for orchestrating microservices or conventional API traffic with ease. Kong runs natively on Kubernetes thanks to its official Kubernetes Ingress Controller.