
Building-a-Small-LLM-from-Scratch
该系列的目的是让读者可以在基础的pytorch上,不依赖任何其他现成的外部库,从零开始理解并实现一个大语言模型的所有组成部分,以及训练微调代码,因此读者仅需python,pytorch和最基础深度学习背景知识即可。
Stars: 197
This tutorial provides a comprehensive guide on building a small Large Language Model (LLM) from scratch using PyTorch. The author shares insights and experiences gained from working on LLM projects in the industry, aiming to help beginners understand the fundamental components of LLMs and training fine-tuning codes. The tutorial covers topics such as model structure overview, attention modules, optimization techniques, normalization layers, tokenizers, pretraining, and fine-tuning with dialogue data. It also addresses specific industry-related challenges and explores cutting-edge model concepts like DeepSeek network structure, causal attention, dynamic-to-static tensor conversion for ONNX inference, and performance optimizations for NPU chips. The series emphasizes hands-on practice with small models to enable local execution and plans to expand into multimodal language models and tensor parallel multi-card deployment.
README:
-- Build a small LLM from scratch: a tutorial --

申明:本教程的所有内容(文字,图片,代码等)可以用于非盈利目的个人使用和分享。但如果用于盈利目的,包括但不限于卖课,公众号,视频号等需要经由作者的批准。谢谢理解。
进入工业界两年,一回头发现和在学校相比,时间似乎溜走地更悄无声息了。没有论文来总结自己每个阶段的思考和成果,似乎我的价值只存在于这六七人小团队的梦呓呢喃中,一旦离开了屈指可数的小圈子,自己这两年的所有足迹便被一个响指抹平了。本着知识就应该被分享的开源精神和一点无法被公司满足的小虚荣心,我决定写一个系列分享一下自己这两年从事大语言模型的一些理解和思考。从23年7月开始到24年底,我在公司主要做了两个和大语言模型相关的项目。其一是从23年7月开始为期半年的和中国移动合作的端侧小模型项目,在这项目中我们算法团队四个人从零开始参考GPT2和ChatGLM,训练了一个0.34B的中文语言模型(出于端侧芯片算力和我们自身训练资源和时间的考量,我们在项目要求时限内仅能训练GPT2-medium参数量的小模型),并在自建的家庭对话垂域数据上进行微调,最后通过ONNX部署在移动端的安卓智慧屏,这个项目参展了2023年中国移动全球合作伙伴大会,到24年初我们又更新了一版1B的模型进一步优化了聊天效果。第二个项目是24年5月开始的对公司内某个图文多模态大模型进行算力优化的项目,我们参考了一些开源的论文,通过对网络结构和推理逻辑的调整在量化模型的基础上进一步提升了30%的推理速度。在这两个项目中,虽然训练规模有限,但我也算是完整地了解并实践了大语言模型和图文多模态大模型的网络结构设计和训练流程,抛开那些无法分享的公司项目细节,我打算整理一份比较基础的,从零开始实现大语言模型的教程,让新入门的同学们可以更快的了解必要的知识,少走弯路。当然同时也可以作为一个记录我思考的笔记本,供该领域的从业者们参考和交流,也请大家检验下我自己的认知和理解是否存在偏差。
-
该系列的目的是让读者可以在基础的pytorch上,不依赖任何其他现成的外部库,从零开始理解并实现一个大语言模型的所有组成部分,以及训练微调代码,因此读者仅需python,pytorch,numpy和最基础深度学习背景知识即可。
-
为了让读者能够亲手实践,我们希望能从小模型开始,让大家尽可能可以自己在本地跑起来
-
后续也考虑拓展到图文多模态大语言模型。
-
考虑到国内外网上已经有大量现成的大语言模型教程和代码,本系列除了单纯的梳理知识点外,也记录了自己在实践中的思考和做项目时遇到的具体业界问题。
-
还有一些最新热点模型的知识点,比如deepseek的网络结构和正常的大语言模型有什么区别,为什么生成式语言模型一定要因果注意力(causal attention),pytorch的动态长度推理怎么转换为需要静态张量形状的ONNX推理格式,如何简单有效地加速首轮问答响应时间,RMSNorm归一化层在只支持FP16计算的NPU芯片上怎么解决值域越界,tokenizer分词器词表裁剪等。
本系列目前计划将内容分为如下章节:
- 大语言模型结构概览
- 注意力模块与KV Cache
- DeepSeekV3的注意力优化
- 旋转位置编码 (待更新)
- 前馈网络 (待更新)
- 归一化层 (待更新)
- tokenizer分词器 (待更新)
- 文本预训练 (待更新)
- 对话数据微调 (待更新)
- LoRA高效微调 (待更新)
- 视觉Transformer网络 (?待定)
- 图文多模态网络 (?待定)
- 张量并行多卡部署 (?待定)
具体章节名称和数量在实际撰写时可能进行调整。
@misc{tang2025all,
title = {Building a Small LLM from Scratch: a tutorial},
author = {Tang, Kaihua and Zhang, Huaizheng},
year = {2025},
note = {\url{https://github.com/KaihuaTang/Building-a-Small-LLM-from-Scratch}},
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Building-a-Small-LLM-from-Scratch
Similar Open Source Tools
Building-a-Small-LLM-from-Scratch
This tutorial provides a comprehensive guide on building a small Large Language Model (LLM) from scratch using PyTorch. The author shares insights and experiences gained from working on LLM projects in the industry, aiming to help beginners understand the fundamental components of LLMs and training fine-tuning codes. The tutorial covers topics such as model structure overview, attention modules, optimization techniques, normalization layers, tokenizers, pretraining, and fine-tuning with dialogue data. It also addresses specific industry-related challenges and explores cutting-edge model concepts like DeepSeek network structure, causal attention, dynamic-to-static tensor conversion for ONNX inference, and performance optimizations for NPU chips. The series emphasizes hands-on practice with small models to enable local execution and plans to expand into multimodal language models and tensor parallel multi-card deployment.

LightLLM
LightLLM is a lightweight library for linear and logistic regression models. It provides a simple and efficient way to train and deploy machine learning models for regression tasks. The library is designed to be easy to use and integrate into existing projects, making it suitable for both beginners and experienced data scientists. With LightLLM, users can quickly build and evaluate regression models using a variety of algorithms and hyperparameters. The library also supports feature engineering and model interpretation, allowing users to gain insights from their data and make informed decisions based on the model predictions.

FuseAI
FuseAI is a repository that focuses on knowledge fusion of large language models. It includes FuseChat, a state-of-the-art 7B LLM on MT-Bench, and FuseLLM, which surpasses Llama-2-7B by fusing three open-source foundation LLMs. The repository provides tech reports, releases, and datasets for FuseChat and FuseLLM, showcasing their performance and advancements in the field of chat models and large language models.

AutoPatent
AutoPatent is a multi-agent framework designed for automatic patent generation. It challenges large language models to generate full-length patents based on initial drafts. The framework leverages planner, writer, and examiner agents along with PGTree and RRAG to craft lengthy, intricate, and high-quality patent documents. It introduces a new metric, IRR (Inverse Repetition Rate), to measure sentence repetition within patents. The tool aims to streamline the patent generation process by automating the creation of detailed and specialized patent documents.
Awesome-local-LLM
Awesome-local-LLM is a curated list of platforms, tools, practices, and resources that help run Large Language Models (LLMs) locally. It includes sections on inference platforms, engines, user interfaces, specific models for general purpose, coding, vision, audio, and miscellaneous tasks. The repository also covers tools for coding agents, agent frameworks, retrieval-augmented generation, computer use, browser automation, memory management, testing, evaluation, research, training, and fine-tuning. Additionally, there are tutorials on models, prompt engineering, context engineering, inference, agents, retrieval-augmented generation, and miscellaneous topics, along with a section on communities for LLM enthusiasts.

cl-waffe2
cl-waffe2 is an experimental deep learning framework in Common Lisp, providing fast, systematic, and customizable matrix operations, reverse mode tape-based Automatic Differentiation, and neural network model building and training features accelerated by a JIT Compiler. It offers abstraction layers, extensibility, inlining, graph-level optimization, visualization, debugging, systematic nodes, and symbolic differentiation. Users can easily write extensions and optimize their networks without overheads. The framework is designed to eliminate barriers between users and developers, allowing for easy customization and extension.
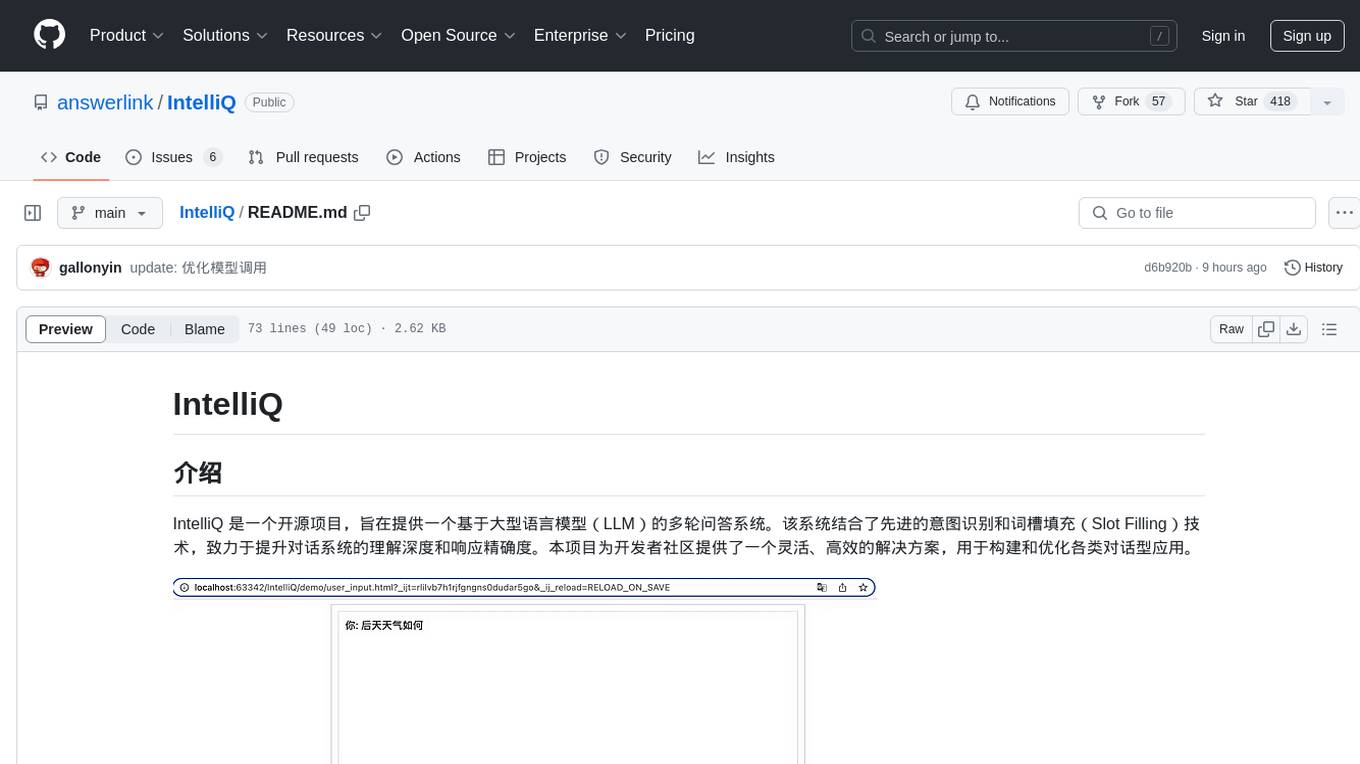
IntelliQ
IntelliQ is an open-source project aimed at providing a multi-turn question-answering system based on a large language model (LLM). The system combines advanced intent recognition and slot filling technology to enhance the depth of understanding and accuracy of responses in conversation systems. It offers a flexible and efficient solution for developers to build and optimize various conversational applications. The system features multi-turn dialogue management, intent recognition, slot filling, interface slot technology for real-time data retrieval and processing, adaptive learning for improving response accuracy and speed, and easy integration with detailed API documentation supporting multiple programming languages and platforms.
Genesis
Genesis is a physics platform designed for general purpose Robotics/Embodied AI/Physical AI applications. It includes a universal physics engine, a lightweight, ultra-fast, pythonic, and user-friendly robotics simulation platform, a powerful and fast photo-realistic rendering system, and a generative data engine that transforms user-prompted natural language description into various modalities of data. It aims to lower the barrier to using physics simulations, unify state-of-the-art physics solvers, and minimize human effort in collecting and generating data for robotics and other domains.
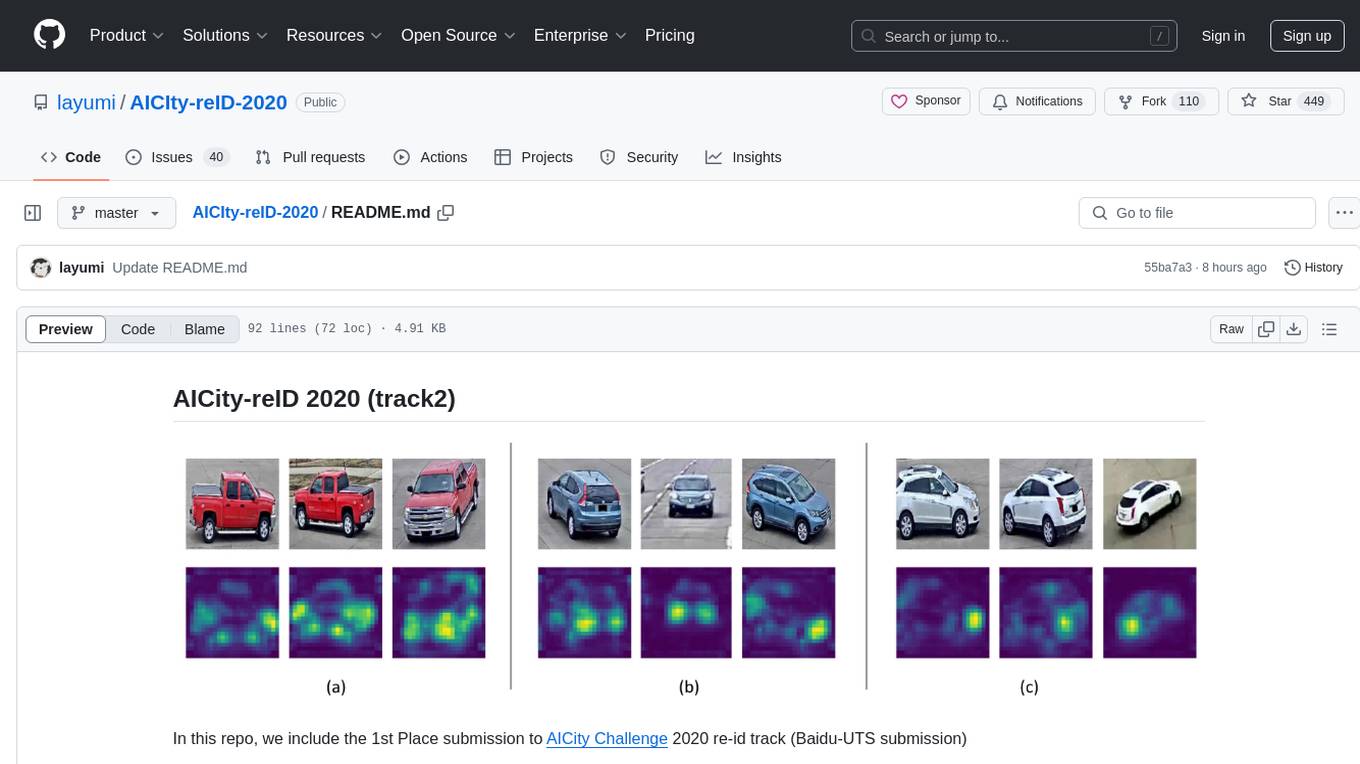
AICIty-reID-2020
AICIty-reID 2020 is a repository containing the 1st Place submission to AICity Challenge 2020 re-id track by Baidu-UTS. It includes models trained on Paddlepaddle and Pytorch, with performance metrics and trained models provided. Users can extract features, perform camera and direction prediction, and access related repositories for drone-based building re-id, vehicle re-ID, person re-ID baseline, and person/vehicle generation. Citations are also provided for research purposes.

AceCoder
AceCoder is a tool that introduces a fully automated pipeline for synthesizing large-scale reliable tests used for reward model training and reinforcement learning in the coding scenario. It curates datasets, trains reward models, and performs RL training to improve coding abilities of language models. The tool aims to unlock the potential of RL training for code generation models and push the boundaries of LLM's coding abilities.

SLAM-LLM
SLAM-LLM is a deep learning toolkit for training custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports various tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). Users can easily extend to new models and tasks, utilize mixed precision training for faster training with less GPU memory, and perform multi-GPU training with data and model parallelism. Configuration is flexible based on Hydra and dataclass, allowing different configuration methods.

AgentCPM
AgentCPM is a series of open-source LLM agents jointly developed by THUNLP, Renmin University of China, ModelBest, and the OpenBMB community. It addresses challenges faced by agents in real-world applications such as limited long-horizon capability, autonomy, and generalization. The team focuses on building deep research capabilities for agents, releasing AgentCPM-Explore, a deep-search LLM agent, and AgentCPM-Report, a deep-research LLM agent. AgentCPM-Explore is the first open-source agent model with 4B parameters to appear on widely used long-horizon agent benchmarks. AgentCPM-Report is built on the 8B-parameter base model MiniCPM4.1, autonomously generating long-form reports with extreme performance and minimal footprint, designed for high-privacy scenarios with offline and agile local deployment.

DataDreamer
DataDreamer is a powerful open-source Python library designed for prompting, synthetic data generation, and training workflows. It is simple, efficient, and research-grade, allowing users to create prompting workflows, generate synthetic datasets, and train models with ease. The library is built for researchers, by researchers, focusing on correctness, best practices, and reproducibility. It offers features like aggressive caching, resumability, support for bleeding-edge techniques, and easy sharing of datasets and models. DataDreamer enables users to run multi-step prompting workflows, generate synthetic datasets for various tasks, and train models by aligning, fine-tuning, instruction-tuning, and distilling them using existing or synthetic data.

lerobot
LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.
qgate-model
QGate-Model is a machine learning meta-model with synthetic data, designed for MLOps and feature store. It is independent of machine learning solutions, with definitions in JSON and data in CSV/parquet formats. This meta-model is useful for comparing capabilities and functions of machine learning solutions, independently testing new versions of machine learning solutions, and conducting various types of tests (unit, sanity, smoke, system, regression, function, acceptance, performance, shadow, etc.). It can also be used for external test coverage when internal test coverage is not available or weak.
awesome-production-llm
This repository is a curated list of open-source libraries for production large language models. It includes tools for data preprocessing, training/finetuning, evaluation/benchmarking, serving/inference, application/RAG, testing/monitoring, and guardrails/security. The repository also provides a new category called LLM Cookbook/Examples for showcasing examples and guides on using various LLM APIs.
For similar tasks
Building-a-Small-LLM-from-Scratch
This tutorial provides a comprehensive guide on building a small Large Language Model (LLM) from scratch using PyTorch. The author shares insights and experiences gained from working on LLM projects in the industry, aiming to help beginners understand the fundamental components of LLMs and training fine-tuning codes. The tutorial covers topics such as model structure overview, attention modules, optimization techniques, normalization layers, tokenizers, pretraining, and fine-tuning with dialogue data. It also addresses specific industry-related challenges and explores cutting-edge model concepts like DeepSeek network structure, causal attention, dynamic-to-static tensor conversion for ONNX inference, and performance optimizations for NPU chips. The series emphasizes hands-on practice with small models to enable local execution and plans to expand into multimodal language models and tensor parallel multi-card deployment.

dash-infer
DashInfer is a C++ runtime tool designed to deliver production-level implementations highly optimized for various hardware architectures, including x86 and ARMv9. It supports Continuous Batching and NUMA-Aware capabilities for CPU, and can fully utilize modern server-grade CPUs to host large language models (LLMs) up to 14B in size. With lightweight architecture, high precision, support for mainstream open-source LLMs, post-training quantization, optimized computation kernels, NUMA-aware design, and multi-language API interfaces, DashInfer provides a versatile solution for efficient inference tasks. It supports x86 CPUs with AVX2 instruction set and ARMv9 CPUs with SVE instruction set, along with various data types like FP32, BF16, and InstantQuant. DashInfer also offers single-NUMA and multi-NUMA architectures for model inference, with detailed performance tests and inference accuracy evaluations available. The tool is supported on mainstream Linux server operating systems and provides documentation and examples for easy integration and usage.

marlin
Marlin is a highly optimized FP16xINT4 matmul kernel designed for large language model (LLM) inference, offering close to ideal speedups up to batchsizes of 16-32 tokens. It is suitable for larger-scale serving, speculative decoding, and advanced multi-inference schemes like CoT-Majority. Marlin achieves optimal performance by utilizing various techniques and optimizations to fully leverage GPU resources, ensuring efficient computation and memory management.
ModelCache
Codefuse-ModelCache is a semantic cache for large language models (LLMs) that aims to optimize services by introducing a caching mechanism. It helps reduce the cost of inference deployment, improve model performance and efficiency, and provide scalable services for large models. The project facilitates sharing and exchanging technologies related to large model semantic cache through open-source collaboration.
seemore
seemore is a vision language model developed in Pytorch, implementing components like image encoder, vision-language projector, and decoder language model. The model is built from scratch, including attention mechanisms and patch creation. It is designed for readability and hackability, with the intention to be improved upon. The implementation is based on public publications and borrows attention mechanism from makemore by Andrej Kapathy. The code was developed on Databricks using a single A100 for compute, and MLFlow is used for tracking metrics. The tool aims to provide a simplistic version of vision language models like Grok 1.5/GPT-4 Vision, suitable for experimentation and learning.

create-million-parameter-llm-from-scratch
The 'create-million-parameter-llm-from-scratch' repository provides a detailed guide on creating a Large Language Model (LLM) with 2.3 million parameters from scratch. The blog replicates the LLaMA approach, incorporating concepts like RMSNorm for pre-normalization, SwiGLU activation function, and Rotary Embeddings. The model is trained on a basic dataset to demonstrate the ease of creating a million-parameter LLM without the need for a high-end GPU.
glossAPI
The glossAPI project aims to develop a Greek language model as open-source software, with code licensed under EUPL and data under Creative Commons BY-SA. The project focuses on collecting and evaluating open text sources in Greek, with efforts to prioritize and gather textual data sets. The project encourages contributions through the CONTRIBUTING.md file and provides resources in the wiki for viewing and modifying recorded sources. It also welcomes ideas and corrections through issue submissions. The project emphasizes the importance of open standards, ethically secured data, privacy protection, and addressing digital divides in the context of artificial intelligence and advanced language technologies.
LLM101n
LLM101n is a course focused on building a Storyteller AI Large Language Model (LLM) from scratch in Python, C, and CUDA. The course covers various topics such as language modeling, machine learning, attention mechanisms, tokenization, optimization, device usage, precision training, distributed optimization, datasets, inference, finetuning, deployment, and multimodal applications. Participants will gain a deep understanding of AI, LLMs, and deep learning through hands-on projects and practical examples.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.