
google-cloud-gcp-openai-api
🌴 Drop-in replacement REST API for Vertex AI (PaLM 2, Codey, Gemini) that is compatible with the OpenAI API specifications
Stars: 67
This project provides a drop-in replacement REST API for Google Cloud Vertex AI (PaLM 2, Codey, Gemini) that is compatible with the OpenAI API specifications. It aims to make Google Cloud Platform Vertex AI more accessible by translating OpenAI API calls to Vertex AI. The software is developed in Python and based on FastAPI and LangChain, designed to be simple and customizable for individual needs. It includes step-by-step guides for deployment, supports various OpenAI API services, and offers configuration through environment variables. Additionally, it provides examples for running locally and usage instructions consistent with the OpenAI API format.
README:
This project is a drop-in replacement REST API for Vertex AI (PaLM 2, Codey, Gemini) that is compatible with the OpenAI API specifications.
Examples:
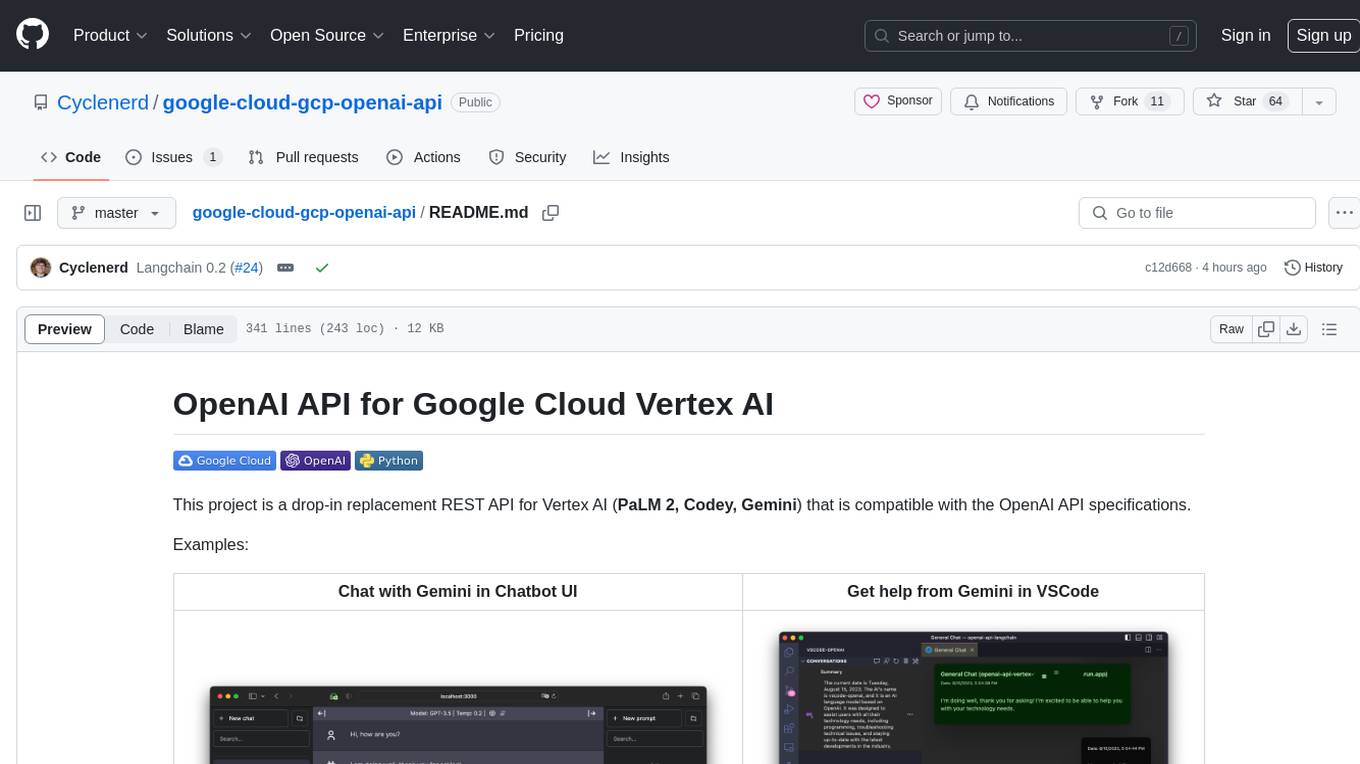
| Chat with Gemini in Chatbot UI | Get help from Gemini in VSCode |
|---|---|
 |
 |
This project is inspired by the idea of LocalAI but with the focus on making Google Cloud Platform Vertex AI PaLM more accessible to anyone.
A Google Cloud Run service is installed that translates the OpenAI API calls to Vertex AI (PaLM 2, Codey, Gemini).

Supported OpenAI API services:
| OpenAI | API | Supported |
|---|---|---|
| List models | /v1/models |
✅ |
| Chat Completions | /v1/chat/completions |
✅ |
| Completions (Legacy) | /v1/completions |
❌ |
| Embeddings | /v1/embeddings |
❌ |
The software is developed in Python and based on FastAPI and LangChain.
Everything is designed to be very simple, so you can easily adjust the source code to your individual needs.
A Jupyter notebook Vertex_AI_Chat.ipynb with step-by-step instructions is prepared.
It will help you to deploy the API backend and Chatbot UI frontend as Google Cloud Run service.
Requirements:
Your user (the one used for deployment) must have proper permissions in the project. For a fast and hassle-free deployemnt the "Owner" role is recommended.
In addition, the default compute service account ([PROJECT_NR][email protected])
must have the role "Role Vertex AI User" (roles/aiplatform.user).
Authenticate:
gcloud auth loginSet default project:
gcloud config set project [PROJECT_ID]Run the following script to create a container image and deploy that container as a public API (which allows unauthenticated calls) in Google Cloud Run:
bash deploy.shNote: You can change the generated fake OpenAI API key and Google Cloud region with environment variables:
export OPENAI_API_KEY="sk-XYZ" export GOOGLE_CLOUD_LOCATION="europe-west1" bash deploy.sh
The software was tested on GNU/Linux and macOS with Python 3.11 and 3.12.3 (3.12.4 currently not working).
If you want to use the software under Windows, you must set the environment variables with set instead of export.
You should also create a virtual environment with the version of Python you want to use, and activate it before proceeding.
You also need the Google Cloud CLI.
The Google Cloud CLI includes the gcloud command-line tool.
Initiate a Python virtual environment and install requirements:
python3 -m venv .venv && \
source .venv/bin/activate && \
pip install -r requirements.txtAuthenticate:
gcloud auth application-default loginSet default project:
gcloud auth application-default set-quota-project [PROJECT_ID]Run with default model:
export DEBUG="True"
export OPENAI_API_KEY="sk-XYZ"
uvicorn vertex:app --reloadExample for Windows:
set DEBUG=True
set OPENAI_API_KEY=sk-XYZ
uvicorn vertex:app --reloadRun with Gemini gemini-pro model:
export DEBUG="True"
export OPENAI_API_KEY="sk-XYZ"
export MODEL_NAME="gemini-pro"
uvicorn vertex:app --reloadRun with Codey codechat-bison-32k model:
export DEBUG="True"
export OPENAI_API_KEY="sk-XYZ"
export MODEL_NAME="codechat-bison-32k"
export MAX_OUTPUT_TOKENS="16000"
uvicorn vertex:app --reloadThe application will now be running on your local computer. You can access it by opening a web browser and navigating to the following address:
http://localhost:8000/
HTTP request and response formats are consistent with the OpenAI API.
For example, to generate a chat completion, you can send a POST request to the /v1/chat/completions endpoint with the instruction as the request body:
curl --location 'http://[ENDPOINT]/v1/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer [API-KEY]' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "Say this is a test!"
}
]
}'Response:
{
"id": "cmpl-efccdeb3d2a6cfe144fdde11",
"created": 1691577522,
"object": "chat.completion",
"model": "gpt-3.5-turbo",
"usage": {
"prompt_tokens": 0,
"completion_tokens": 0,
"total_tokens": 0
},
"choices": [
{
"message": {
"role": "assistant",
"content": "Sure, this is a test."
},
"finish_reason": "stop",
"index": 0
}
]
}
Download export for Bruno API client: bruno-export.json
The configuration of the software can be done with environment variables.

The following variables with default values exist:
| Variable | Default | Description |
|---|---|---|
| DEBUG | False | Show debug messages that help during development. |
| GOOGLE_CLOUD_LOCATION | us-central1 | Google Cloud Platform region for API calls. |
| GOOGLE_CLOUD_PROJECT_ID | [DEFAULT_AUTH_PROJECT] | Identifier for your project. If not specified, the project of authentication is used. |
| HOST | 0.0.0.0 | Bind socket to this host. |
| MAX_OUTPUT_TOKENS | 512 | Token limit determines the maximum amount of text output from one prompt. Can be overridden by the end user as required by the OpenAI API specification. |
| MODEL_NAME | chat-bison | One of the foundation models that are available in Vertex AI. |
| OPENAI_API_KEY | sk-[RANDOM_HEX] | Self-generated fake OpenAI API key used for authentication against the application. |
| PORT | 8000 | Bind socket to this port. |
| TEMPERATURE | 0.2 | Sampling temperature, it controls the degree of randomness in token selection. Can be overridden by the end user as required by the OpenAI API specification. |
| TOP_K | 40 | How the model selects tokens for output, the next token is selected from. |
| TOP_P | 0.8 | Tokens are selected from most probable to least until the sum of their. Can be overridden by the end user as required by the OpenAI API specification. |
If your application uses client libraries provided by OpenAI,
you only need to modify the OPENAI_API_BASE environment variable to match your Google Cloud Run endpoint URL:
export OPENAI_API_BASE="https://openai-api-vertex-XYZ.a.run.app/v1"
python your_openai_app.pyWhen deploying the Chatbot UI application, the following environment variables must be set:
| Variable | Value |
|---|---|
| OPENAI_API_KEY | API key generated during deployment |
| OPENAI_API_HOST | Google Cloud Run URL |

Run the following script to create a container image from the GitHub source code and deploy that container as a public website (which allows unauthenticated calls) in Google Cloud Run:
export OPENAI_API_KEY="sk-XYZ"
export OPENAI_API_HOST="https://openai-api-vertex-XYZ.a.run.app"
bash chatbot-ui.shSet the following Chatbox settings:
| Setting | Value |
|---|---|
| AI Provider | OpenAI API |
| OpenAI API Key | API key generated during deployment |
| API Host | Google Cloud Run URL |

The VSCode-OpenAI extension is a powerful and versatile tool designed to integrate OpenAI features seamlessly into your code editor.
To activate the setup, you have two options:
- either use the command "vscode-openai.configuration.show.quickpick" or
- access it through the vscode-openai Status Bar located at the bottom left corner of VSCode.

Select openai.com and enter the Google Cloud Run URL with /v1 during setup.
When deploying the Discord Bot application, the following environment variables must be set:
| Variable | Value |
|---|---|
| OPENAI_API_KEY | API key generated during deployment |
| OPENAI_API_BASE | Google Cloud Run URL with /v1
|
When deploying the ChatGPT in Slack application, the following environment variables must be set:
| Variable | Value |
|---|---|
| OPENAI_API_KEY | API key generated during deployment |
| OPENAI_API_BASE | Google Cloud Run URL with /v1
|
When deploying the ChatGPT Telegram Bot application, the following environment variables must be set:
| Variable | Value |
|---|---|
| OPENAI_API_KEY | API key generated during deployment |
| OPENAI_API_BASE | Google Cloud Run URL with /v1
|
Have a patch that will benefit this project? Awesome! Follow these steps to have it accepted.
- Please read how to contribute.
- Fork this Git repository and make your changes.
- Create a Pull Request.
- Incorporate review feedback to your changes.
- Accepted!
All files in this repository are under the Apache License, Version 2.0 unless noted otherwise.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for google-cloud-gcp-openai-api
Similar Open Source Tools
google-cloud-gcp-openai-api
This project provides a drop-in replacement REST API for Google Cloud Vertex AI (PaLM 2, Codey, Gemini) that is compatible with the OpenAI API specifications. It aims to make Google Cloud Platform Vertex AI more accessible by translating OpenAI API calls to Vertex AI. The software is developed in Python and based on FastAPI and LangChain, designed to be simple and customizable for individual needs. It includes step-by-step guides for deployment, supports various OpenAI API services, and offers configuration through environment variables. Additionally, it provides examples for running locally and usage instructions consistent with the OpenAI API format.
llm-gateway
llm-gateway is a gateway tool designed for interacting with third-party LLM providers such as OpenAI, Cohere, etc. It tracks data exchanged with these providers in a postgres database, applies PII scrubbing heuristics, and ensures safe communication with OpenAI's services. The tool supports various models from different providers and offers API and Python usage examples. Developers can set up the tool using Poetry, Pyenv, npm, and yarn for dependency management. The project also includes Docker setup for backend and frontend development.

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern

cake
cake is a pure Rust implementation of the llama3 LLM distributed inference based on Candle. The project aims to enable running large models on consumer hardware clusters of iOS, macOS, Linux, and Windows devices by sharding transformer blocks. It allows running inferences on models that wouldn't fit in a single device's GPU memory by batching contiguous transformer blocks on the same worker to minimize latency. The tool provides a way to optimize memory and disk space by splitting the model into smaller bundles for workers, ensuring they only have the necessary data. cake supports various OS, architectures, and accelerations, with different statuses for each configuration.
pr-pilot
PR Pilot is an AI-powered tool designed to assist users in their daily workflow by delegating routine work to AI with confidence and predictability. It integrates seamlessly with popular development tools and allows users to interact with it through a Command-Line Interface, Python SDK, REST API, and Smart Workflows. Users can automate tasks such as generating PR titles and descriptions, summarizing and posting issues, and formatting README files. The tool aims to save time and enhance productivity by providing AI-powered solutions for common development tasks.

runpod-worker-comfy
runpod-worker-comfy is a serverless API tool that allows users to run any ComfyUI workflow to generate an image. Users can provide input images as base64-encoded strings, and the generated image can be returned as a base64-encoded string or uploaded to AWS S3. The tool is built on Ubuntu + NVIDIA CUDA and provides features like built-in checkpoints and VAE models. Users can configure environment variables to upload images to AWS S3 and interact with the RunPod API to generate images. The tool also supports local testing and deployment to Docker hub using Github Actions.

moatless-tools
Moatless Tools is a hobby project focused on experimenting with using Large Language Models (LLMs) to edit code in large existing codebases. The project aims to build tools that insert the right context into prompts and handle responses effectively. It utilizes an agentic loop functioning as a finite state machine to transition between states like Search, Identify, PlanToCode, ClarifyChange, and EditCode for code editing tasks.
ai-dial-core
AI DIAL Core is an HTTP Proxy that provides a unified API to different chat completion and embedding models, assistants, and applications. It is written in Java 17 and built on Eclipse Vert.x. The core functionality includes handling static and dynamic settings, deployment on Kubernetes using Helm charts, and storing user data in Blob Storage and Redis. It supports various identity providers, storage providers like AWS S3, Google Cloud Storage, and Azure Blob Store, and features like AI DIAL Addons, Interceptors, Assistants, Applications, and Models with customizable parameters and configurations.

mLoRA
mLoRA (Multi-LoRA Fine-Tune) is an open-source framework for efficient fine-tuning of multiple Large Language Models (LLMs) using LoRA and its variants. It allows concurrent fine-tuning of multiple LoRA adapters with a shared base model, efficient pipeline parallelism algorithm, support for various LoRA variant algorithms, and reinforcement learning preference alignment algorithms. mLoRA helps save computational and memory resources when training multiple adapters simultaneously, achieving high performance on consumer hardware.
call-center-ai
Call Center AI is an AI-powered call center solution leveraging Azure and OpenAI GPT. It allows for AI agent-initiated phone calls or direct calls to the bot from a configured phone number. The bot is customizable for various industries like insurance, IT support, and customer service, with features such as accessing claim information, conversation history, language change, SMS sending, and more. The project is a proof of concept showcasing the integration of Azure Communication Services, Azure Cognitive Services, and Azure OpenAI for an automated call center solution.

text-embeddings-inference
Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for popular models like FlagEmbedding, Ember, GTE, and E5. It implements features such as no model graph compilation step, Metal support for local execution on Macs, small docker images with fast boot times, token-based dynamic batching, optimized transformers code for inference using Flash Attention, Candle, and cuBLASLt, Safetensors weight loading, and production-ready features like distributed tracing with Open Telemetry and Prometheus metrics.

vision-parse
Vision Parse is a tool that leverages Vision Language Models to parse PDF documents into beautifully formatted markdown content. It offers smart content extraction, content formatting, multi-LLM support, PDF document support, and local model hosting using Ollama. Users can easily convert PDFs to markdown with high precision and preserve document hierarchy and styling. The tool supports multiple Vision LLM providers like OpenAI, LLama, and Gemini for accuracy and speed, making document processing efficient and effortless.
LEADS
LEADS is a lightweight embedded assisted driving system designed to simplify the development of instrumentation, control, and analysis systems for racing cars. It is written in Python and C/C++ with impressive performance. The system is customizable and provides abstract layers for component rearrangement. It supports hardware components like Raspberry Pi and Arduino, and can adapt to various hardware types. LEADS offers a modular structure with a focus on flexibility and lightweight design. It includes robust safety features, modern GUI design with dark mode support, high performance on different platforms, and powerful ESC systems for traction control and braking. The system also supports real-time data sharing, live video streaming, and AI-enhanced data analysis for driver training. LEADS VeC Remote Analyst enables transparency between the driver and pit crew, allowing real-time data sharing and analysis. The system is designed to be user-friendly, adaptable, and efficient for racing car development.
tuui
TUUI is a desktop MCP client designed for accelerating AI adoption through the Model Context Protocol (MCP) and enabling cross-vendor LLM API orchestration. It is an LLM chat desktop application based on MCP, created using AI-generated components with strict syntax checks and naming conventions. The tool integrates AI tools via MCP, orchestrates LLM APIs, supports automated application testing, TypeScript, multilingual, layout management, global state management, and offers quick support through the GitHub community and official documentation.
AgentPoison
AgentPoison is a repository that provides the official PyTorch implementation of the paper 'AgentPoison: Red-teaming LLM Agents via Memory or Knowledge Base Backdoor Poisoning'. It offers tools for red-teaming LLM agents by poisoning memory or knowledge bases. The repository includes trigger optimization algorithms, agent experiments, and evaluation scripts for Agent-Driver, ReAct-StrategyQA, and EHRAgent. Users can fine-tune motion planners, inject queries with triggers, and evaluate red-teaming performance. The codebase supports multiple RAG embedders and provides a unified dataset access for all three agents.
ai-gateway
LangDB AI Gateway is an open-source enterprise AI gateway built in Rust. It provides a unified interface to all LLMs using the OpenAI API format, focusing on high performance, enterprise readiness, and data control. The gateway offers features like comprehensive usage analytics, cost tracking, rate limiting, data ownership, and detailed logging. It supports various LLM providers and provides OpenAI-compatible endpoints for chat completions, model listing, embeddings generation, and image generation. Users can configure advanced settings, such as rate limiting, cost control, dynamic model routing, and observability with OpenTelemetry tracing. The gateway can be run with Docker Compose and integrated with MCP tools for server communication.
For similar tasks
google-cloud-gcp-openai-api
This project provides a drop-in replacement REST API for Google Cloud Vertex AI (PaLM 2, Codey, Gemini) that is compatible with the OpenAI API specifications. It aims to make Google Cloud Platform Vertex AI more accessible by translating OpenAI API calls to Vertex AI. The software is developed in Python and based on FastAPI and LangChain, designed to be simple and customizable for individual needs. It includes step-by-step guides for deployment, supports various OpenAI API services, and offers configuration through environment variables. Additionally, it provides examples for running locally and usage instructions consistent with the OpenAI API format.
com.openai.unity
com.openai.unity is an OpenAI package for Unity that allows users to interact with OpenAI's API through RESTful requests. It is independently developed and not an official library affiliated with OpenAI. Users can fine-tune models, create assistants, chat completions, and more. The package requires Unity 2021.3 LTS or higher and can be installed via Unity Package Manager or Git URL. Various features like authentication, Azure OpenAI integration, model management, thread creation, chat completions, audio processing, image generation, file management, fine-tuning, batch processing, embeddings, and content moderation are available.
100x-LLM
This repository contains code snippets and examples from the 100x Applied AI cohort lectures. It includes implementations of LLM Workflows, RAG (Retrieval Augmented Generation), Agentic Patterns, Chat Completions with various providers, Function Calling, and more. The repository structure consists of core components like LLM Workflows, RAG Implementations, Agentic Patterns, Chat Completions, Function Calling, Hugging Face Integration, and additional components for various agent implementations, presentation generation, Notion API integration, FastAPI-based endpoints, authentication implementations, and LangChain usage examples.
node-llama-cpp
node-llama-cpp is a tool that allows users to run AI models locally on their machines. It provides pre-built bindings with the option to build from source using cmake. Users can interact with text generation models, chat with models using a chat wrapper, and force models to generate output in a parseable format like JSON. The tool supports Metal and CUDA, offers CLI functionality for chatting with models without coding, and ensures up-to-date compatibility with the latest version of llama.cpp. Installation includes pre-built binaries for macOS, Linux, and Windows, with the option to build from source if binaries are not available for the platform.
llm-term
LLM-Term is a Rust-based CLI tool that generates and executes terminal commands using OpenAI's language models or local Ollama models. It offers configurable model and token limits, works on both PowerShell and Unix-like shells, and provides a seamless user experience for generating commands based on prompts. Users can easily set up the tool, customize configurations, and leverage different models for command generation.

ai-analyst
AI Analyst by E2B is an AI-powered code and data analysis tool built with Next.js and the E2B SDK. It allows users to analyze data with Meta's Llama 3.1, upload CSV files, and create interactive charts. The tool is powered by E2B Sandbox, Vercel's AI SDK, Next.js, and echarts library for interactive charts. Supported LLM providers include TogetherAI and Fireworks, with various chart types available for visualization.
DeepClaude
DeepClaude is an open-source project inspired by the DeepSeek R1 model, aiming to provide the best results in various tasks by combining different models. It supports OpenAI-compatible input and output formats, integrates with DeepSeek and Claude APIs, and offers special support for other OpenAI-compatible models. Users can run the project locally or deploy it on a server to access a powerful language model service. The project also provides guidance on obtaining necessary APIs and running the project, including using Docker for deployment.
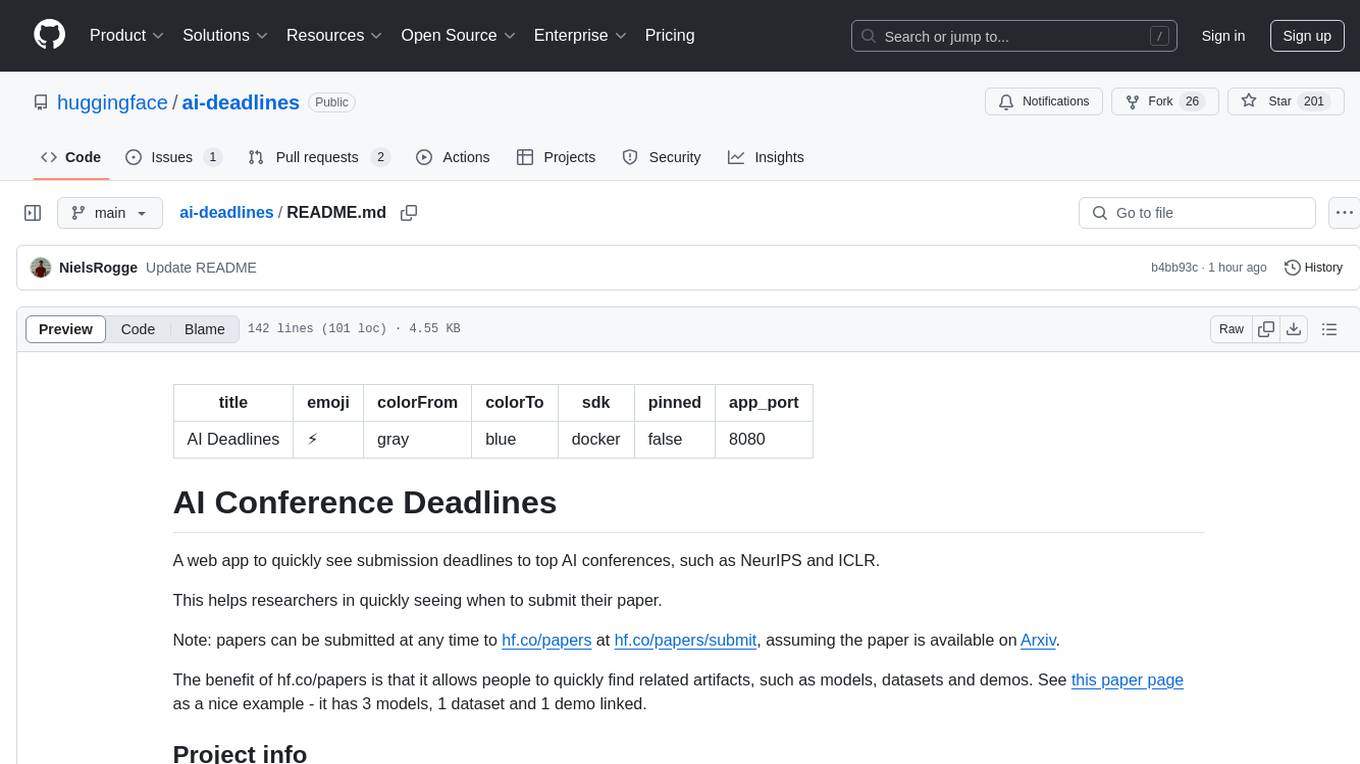
ai-deadlines
AI Deadlines is a web app that displays submission deadlines for top AI conferences like NeurIPS and ICLR. It helps researchers know when to submit their papers. The data is fetched from a GitHub repository and updated automatically using a CRON job. The project is based on an existing repository and features a new UI. Users can contribute by updating conference deadlines in the provided YAML file. The app can be run locally with Node.js and npm or deployed using Docker. It is built with Vite, TypeScript, React, shadcn-ui, and Tailwind CSS. The project is licensed under MIT.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.