
llmfit
94 models. 30 providers. One command to find what runs on your hardware.
Stars: 157
llmfit is a terminal tool designed to optimize LLM models for your system's RAM, CPU, and GPU. It detects your hardware, scores models based on quality, speed, fit, and context, and recommends models that will run well on your machine. It supports multi-GPU setups, MoE architectures, dynamic quantization selection, and speed estimation. The tool provides an interactive TUI and a classic CLI mode for ease of use. It includes a database of 94 models from 30 providers sourced from the HuggingFace API, with memory requirements computed from parameter counts across a quantization hierarchy. llmfit uses multi-dimensional scoring to rank models and estimates speed based on backend-specific constants. It also offers dynamic quantization selection to fit models to available memory efficiently.
README:
94 models. 30 providers. One command to find what runs on your hardware.
A terminal tool that right-sizes LLM models to your system's RAM, CPU, and GPU. Detects your hardware, scores each model across quality, speed, fit, and context dimensions, and tells you which ones will actually run well on your machine.
Ships with an interactive TUI (default) and a classic CLI mode. Supports multi-GPU setups, MoE architectures, dynamic quantization selection, and speed estimation.
curl -fsSL https://llmfit.axjns.dev/install.sh | shDownloads the latest release binary from GitHub and installs it to /usr/local/bin (or ~/.local/bin)
Or
brew tap AlexsJones/llmfit
brew install llmfit
Example of a medium performance home laptop

Example of models with Mixture-of-Experts architectures

cargo install llmfitbrew tap AlexsJones/llmfit
brew install llmfitcurl -fsSL https://llmfit.axjns.dev/install.sh | shDownloads the latest release binary from GitHub and installs it to /usr/local/bin (or ~/.local/bin).
git clone https://github.com/AlexsJones/llmfit.git
cd llmfit
cargo build --release
# binary is at target/release/llmfitllmfitLaunches the interactive terminal UI. Your system specs (CPU, RAM, GPU name, VRAM, backend) are shown at the top. Models are listed in a scrollable table sorted by composite score. Each row shows the model's score, estimated tok/s, best quantization for your hardware, run mode, memory usage, and use-case category.
| Key | Action |
|---|---|
Up / Down or j / k
|
Navigate models |
/ |
Enter search mode (partial match on name, provider, params, use case) |
Esc or Enter
|
Exit search mode |
Ctrl-U |
Clear search |
f |
Cycle fit filter: All, Runnable, Perfect, Good, Marginal |
1-9
|
Toggle provider visibility |
Enter |
Toggle detail view for selected model |
PgUp / PgDn
|
Scroll by 10 |
g / G
|
Jump to top / bottom |
q |
Quit |
Use --cli or any subcommand to get classic table output:
# Table of all models ranked by fit
llmfit --cli
# Only perfectly fitting models, top 5
llmfit fit --perfect -n 5
# Show detected system specs
llmfit system
# List all models in the database
llmfit list
# Search by name, provider, or size
llmfit search "llama 8b"
# Detailed view of a single model
llmfit info "Mistral-7B"-
Hardware detection -- Reads total/available RAM via
sysinfo, counts CPU cores, and probes for GPUs:-
NVIDIA -- Multi-GPU support via
nvidia-smi. Aggregates VRAM across all detected GPUs. Falls back to VRAM estimation from GPU model name if reporting fails. -
AMD -- Detected via
rocm-smi. -
Intel Arc -- Discrete VRAM via sysfs, integrated via
lspci. -
Apple Silicon -- Unified memory via
system_profiler. VRAM = system RAM. - Backend detection -- Automatically identifies the acceleration backend (CUDA, Metal, ROCm, SYCL, CPU ARM, CPU x86) for speed estimation.
-
NVIDIA -- Multi-GPU support via
-
Model database -- 94 models sourced from the HuggingFace API, stored in
data/hf_models.jsonand embedded at compile time. Memory requirements are computed from parameter counts across a quantization hierarchy (Q8_0 through Q2_K). VRAM is the primary constraint for GPU inference; system RAM is the fallback for CPU-only execution.MoE support -- Models with Mixture-of-Experts architectures (Mixtral, DeepSeek-V2/V3) are detected automatically. Only a subset of experts is active per token, so the effective VRAM requirement is much lower than total parameter count suggests. For example, Mixtral 8x7B has 46.7B total parameters but only activates ~12.9B per token, reducing VRAM from 23.9 GB to ~6.6 GB with expert offloading.
-
Dynamic quantization -- Instead of assuming a fixed quantization, llmfit tries the best quality quantization that fits your hardware. It walks a hierarchy from Q8_0 (best quality) down to Q2_K (most compressed), picking the highest quality that fits in available memory. If nothing fits at full context, it tries again at half context.
-
Multi-dimensional scoring -- Each model is scored across four dimensions (0–100 each):
Dimension What it measures Quality Parameter count, model family reputation, quantization penalty, task alignment Speed Estimated tokens/sec based on backend, params, and quantization Fit Memory utilization efficiency (sweet spot: 50–80% of available memory) Context Context window capability vs target for the use case Dimensions are combined into a weighted composite score. Weights vary by use-case category (General, Coding, Reasoning, Chat, Multimodal, Embedding). For example, Chat weights Speed higher (0.35) while Reasoning weights Quality higher (0.55). Models are ranked by composite score, with unrunnable models (Too Tight) always at the bottom.
-
Speed estimation -- Estimated tokens per second using backend-specific constants:
Backend Speed constant CUDA 220 Metal 160 ROCm 180 SYCL 100 CPU (ARM) 90 CPU (x86) 70 Formula:
K / params_b × quant_speed_multiplier, with penalties for CPU offload (0.5×), CPU-only (0.3×), and MoE expert switching (0.8×). -
Fit analysis -- Each model is evaluated for memory compatibility:
Run modes:
- GPU -- Model fits in VRAM. Fast inference.
- MoE -- Mixture-of-Experts with expert offloading. Active experts in VRAM, inactive in RAM.
- CPU+GPU -- VRAM insufficient, spills to system RAM with partial GPU offload.
- CPU -- No GPU. Model loaded entirely into system RAM.
Fit levels:
- Perfect -- Recommended memory met on GPU. Requires GPU acceleration.
- Good -- Fits with headroom. Best achievable for MoE offload or CPU+GPU.
- Marginal -- Tight fit, or CPU-only (CPU-only always caps here).
- Too Tight -- Not enough VRAM or system RAM anywhere.
The model list is generated by scripts/scrape_hf_models.py, a standalone Python script (stdlib only, no pip dependencies) that queries the HuggingFace REST API. 94 models across 30 providers including Meta Llama, Mistral, Qwen, Google Gemma, Microsoft Phi, DeepSeek, IBM Granite, Allen Institute OLMo, xAI Grok, Cohere, BigCode, 01.ai, Upstage, TII Falcon, HuggingFace, Zhipu GLM, Moonshot Kimi, Baidu ERNIE, and more. The scraper automatically detects MoE architectures via model config (num_local_experts, num_experts_per_tok) and known architecture mappings.
Model categories span general purpose, coding (CodeLlama, StarCoder2, WizardCoder, Qwen2.5-Coder, Qwen3-Coder), reasoning (DeepSeek-R1, Orca-2), multimodal/vision (Llama 3.2 Vision, Llama 4 Scout/Maverick, Qwen2.5-VL), chat, enterprise (IBM Granite), and embedding (nomic-embed, bge).
See MODELS.md for the full list.
To refresh the model database:
# Automated update (recommended)
make update-models
# Or run the script directly
./scripts/update_models.sh
# Or manually
python3 scripts/scrape_hf_models.py
cargo build --releaseThe scraper writes data/hf_models.json, which is baked into the binary via include_str!. The automated update script backs up existing data, validates JSON output, and rebuilds the binary.
src/
main.rs -- CLI argument parsing, entrypoint, TUI launch
hardware.rs -- System RAM/CPU/GPU detection (multi-GPU, backend identification)
models.rs -- Model database, quantization hierarchy, dynamic quant selection
fit.rs -- Multi-dimensional scoring (Q/S/F/C), speed estimation, MoE offloading
display.rs -- Classic CLI table rendering (tabled crate)
tui_app.rs -- TUI application state, filters, navigation
tui_ui.rs -- TUI rendering (ratatui)
tui_events.rs -- TUI keyboard event handling (crossterm)
data/
hf_models.json -- Model database (94 models)
scripts/
scrape_hf_models.py -- HuggingFace API scraper
update_models.sh -- Automated database update script
Makefile -- Build and maintenance commands
The Cargo.toml already includes the required metadata (description, license, repository). To publish:
# Dry run first to catch issues
cargo publish --dry-run
# Publish for real (requires a crates.io API token)
cargo login
cargo publishBefore publishing, make sure:
- The version in
Cargo.tomlis correct (bump with each release). - A
LICENSEfile exists in the repo root. Create one if missing:
# For MIT license:
curl -sL https://opensource.org/license/MIT -o LICENSE
# Or write your own. The Cargo.toml declares license = "MIT".-
data/hf_models.jsonis committed. It is embedded at compile time and must be present in the published crate. - The
excludelist inCargo.tomlkeepstarget/,scripts/, anddemo.gifout of the published crate to keep the download small.
To publish updates:
# Bump version
# Edit Cargo.toml: version = "0.2.0"
cargo publish| Crate | Purpose |
|---|---|
clap |
CLI argument parsing with derive macros |
sysinfo |
Cross-platform RAM and CPU detection |
serde / serde_json
|
JSON deserialization for model database |
tabled |
CLI table formatting |
colored |
CLI colored output |
ratatui |
Terminal UI framework |
crossterm |
Terminal input/output backend for ratatui |
-
Linux -- Full support. GPU detection via
nvidia-smi(NVIDIA),rocm-smi(AMD), and sysfs/lspci(Intel Arc). -
macOS (Apple Silicon) -- Full support. Detects unified memory via
system_profiler. VRAM = system RAM (shared pool). Models run via Metal GPU acceleration. -
macOS (Intel) -- RAM and CPU detection works. Discrete GPU detection if
nvidia-smiavailable. -
Windows -- RAM and CPU detection works. NVIDIA GPU detection via
nvidia-smiif installed.
| Vendor | Detection method | VRAM reporting |
|---|---|---|
| NVIDIA | nvidia-smi |
Exact dedicated VRAM |
| AMD | rocm-smi |
Detected (VRAM may be unknown) |
| Intel Arc (discrete) | sysfs (mem_info_vram_total) |
Exact dedicated VRAM |
| Intel Arc (integrated) | lspci |
Shared system memory |
| Apple Silicon | system_profiler |
Unified memory (= system RAM) |
Contributions are welcome, especially new models.
- Add the model's HuggingFace repo ID (e.g.,
meta-llama/Llama-3.1-8B) to theTARGET_MODELSlist inscripts/scrape_hf_models.py. - If the model is gated (requires HuggingFace authentication to access metadata), add a fallback entry to the
FALLBACKSlist in the same script with the parameter count and context length. - Run the automated update script:
make update-models # or: ./scripts/update_models.sh - Verify the updated model list:
./target/release/llmfit list - Update MODELS.md by running:
python3 << 'EOF' < scripts/...(see commit history for the generator script) - Open a pull request.
See MODELS.md for the current list and AGENTS.md for architecture details.
If you're looking for a different approach, check out llm-checker -- a Node.js CLI tool with Ollama integration that can pull and benchmark models directly. It takes a more hands-on approach by actually running models on your hardware via Ollama, rather than estimating from specs. Good if you already have Ollama installed and want to test real-world performance. Note that it doesn't support MoE (Mixture-of-Experts) architectures -- all models are treated as dense, so memory estimates for models like Mixtral or DeepSeek-V3 will reflect total parameter count rather than the smaller active subset.
MIT
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llmfit
Similar Open Source Tools
llmfit
llmfit is a terminal tool designed to optimize LLM models for your system's RAM, CPU, and GPU. It detects your hardware, scores models based on quality, speed, fit, and context, and recommends models that will run well on your machine. It supports multi-GPU setups, MoE architectures, dynamic quantization selection, and speed estimation. The tool provides an interactive TUI and a classic CLI mode for ease of use. It includes a database of 94 models from 30 providers sourced from the HuggingFace API, with memory requirements computed from parameter counts across a quantization hierarchy. llmfit uses multi-dimensional scoring to rank models and estimates speed based on backend-specific constants. It also offers dynamic quantization selection to fit models to available memory efficiently.

FlexFlow
FlexFlow Serve is an open-source compiler and distributed system for **low latency**, **high performance** LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.
litserve
LitServe is a high-throughput serving engine for deploying AI models at scale. It generates an API endpoint for a model, handles batching, streaming, autoscaling across CPU/GPUs, and more. Built for enterprise scale, it supports every framework like PyTorch, JAX, Tensorflow, and more. LitServe is designed to let users focus on model performance, not the serving boilerplate. It is like PyTorch Lightning for model serving but with broader framework support and scalability.

WordLlama
WordLlama is a fast, lightweight NLP toolkit optimized for CPU hardware. It recycles components from large language models to create efficient word representations. It offers features like Matryoshka Representations, low resource requirements, binarization, and numpy-only inference. The tool is suitable for tasks like semantic matching, fuzzy deduplication, ranking, and clustering, making it a good option for NLP-lite tasks and exploratory analysis.

exllamav2
ExLlamaV2 is an inference library designed for running local LLMs on modern consumer GPUs. The library supports paged attention via Flash Attention 2.5.7+, offers a new dynamic generator with features like dynamic batching, smart prompt caching, and K/V cache deduplication. It also provides an API for local or remote inference using TabbyAPI, with extended features like HF model downloading and support for HF Jinja2 chat templates. ExLlamaV2 aims to optimize performance and speed across different GPU models, with potential future optimizations and variations in speeds. The tool can be integrated with TabbyAPI for OpenAI-style web API compatibility and supports a standalone web UI called ExUI for single-user interaction with chat and notebook modes. ExLlamaV2 also offers support for text-generation-webui and lollms-webui through specific loaders and bindings.

exllamav2
ExLlamaV2 is an inference library for running local LLMs on modern consumer GPUs. It is a faster, better, and more versatile codebase than its predecessor, ExLlamaV1, with support for a new quant format called EXL2. EXL2 is based on the same optimization method as GPTQ and supports 2, 3, 4, 5, 6, and 8-bit quantization. It allows for mixing quantization levels within a model to achieve any average bitrate between 2 and 8 bits per weight. ExLlamaV2 can be installed from source, from a release with prebuilt extension, or from PyPI. It supports integration with TabbyAPI, ExUI, text-generation-webui, and lollms-webui. Key features of ExLlamaV2 include: - Faster and better kernels - Cleaner and more versatile codebase - Support for EXL2 quantization format - Integration with various web UIs and APIs - Community support on Discord

pgvecto.rs
pgvecto.rs is a Postgres extension written in Rust that provides vector similarity search functions. It offers ultra-low-latency, high-precision vector search capabilities, including sparse vector search and full-text search. With complete SQL support, async indexing, and easy data management, it simplifies data handling. The extension supports various data types like FP16/INT8, binary vectors, and Matryoshka embeddings. It ensures system performance with production-ready features, high availability, and resource efficiency. Security and permissions are managed through easy access control. The tool allows users to create tables with vector columns, insert vector data, and calculate distances between vectors using different operators. It also supports half-precision floating-point numbers for better performance and memory usage optimization.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.
llm-leaderboard
Nejumi Leaderboard 3 is a comprehensive evaluation platform for large language models, assessing general language capabilities and alignment aspects. The evaluation framework includes metrics for language processing, translation, summarization, information extraction, reasoning, mathematical reasoning, entity extraction, knowledge/question answering, English, semantic analysis, syntactic analysis, alignment, ethics/moral, toxicity, bias, truthfulness, and robustness. The repository provides an implementation guide for environment setup, dataset preparation, configuration, model configurations, and chat template creation. Users can run evaluation processes using specified configuration files and log results to the Weights & Biases project.
thinc
Thinc is a lightweight deep learning library that offers an elegant, type-checked, functional-programming API for composing models, with support for layers defined in other frameworks such as PyTorch, TensorFlow and MXNet. You can use Thinc as an interface layer, a standalone toolkit or a flexible way to develop new models.
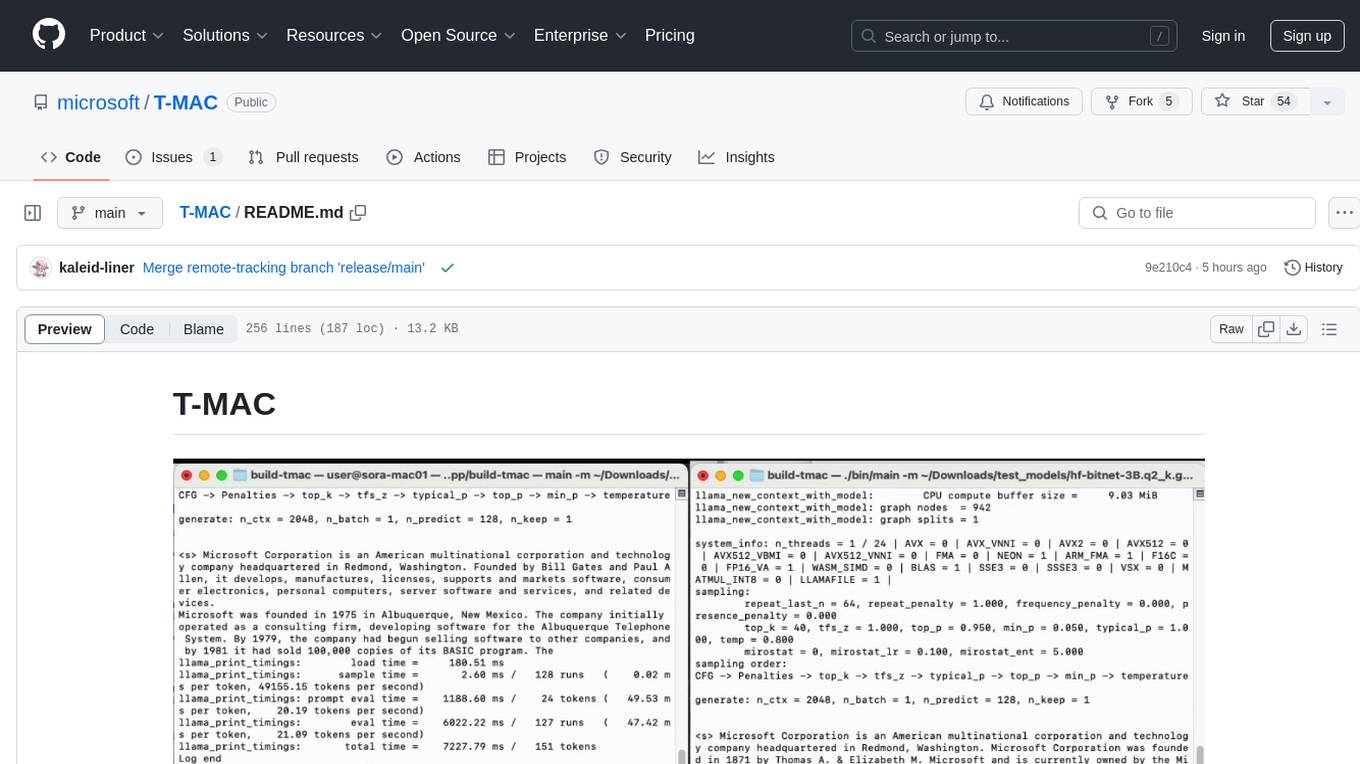
T-MAC
T-MAC is a kernel library that directly supports mixed-precision matrix multiplication without the need for dequantization by utilizing lookup tables. It aims to boost low-bit LLM inference on CPUs by offering support for various low-bit models. T-MAC achieves significant speedup compared to SOTA CPU low-bit framework (llama.cpp) and can even perform well on lower-end devices like Raspberry Pi 5. The tool demonstrates superior performance over existing low-bit GEMM kernels on CPU, reduces power consumption, and provides energy savings. It achieves comparable performance to CUDA GPU on certain tasks while delivering considerable power and energy savings. T-MAC's method involves using lookup tables to support mpGEMM and employs key techniques like precomputing partial sums, shift and accumulate operations, and utilizing tbl/pshuf instructions for fast table lookup.

mflux
MFLUX is a line-by-line port of the FLUX implementation in the Huggingface Diffusers library to Apple MLX. It aims to run powerful FLUX models from Black Forest Labs locally on Mac machines. The codebase is minimal and explicit, prioritizing readability over generality and performance. Models are implemented from scratch in MLX, with tokenizers from the Huggingface Transformers library. Dependencies include Numpy and Pillow for image post-processing. Installation can be done using `uv tool` or classic virtual environment setup. Command-line arguments allow for image generation with specified models, prompts, and optional parameters. Quantization options for speed and memory reduction are available. LoRA adapters can be loaded for fine-tuning image generation. Controlnet support provides more control over image generation with reference images. Current limitations include generating images one by one, lack of support for negative prompts, and some LoRA adapters not working.

DeepPavlov
DeepPavlov is an open-source conversational AI library built on PyTorch. It is designed for the development of production-ready chatbots and complex conversational systems, as well as for research in the area of NLP and dialog systems. The library offers a wide range of models for tasks such as Named Entity Recognition, Intent/Sentence Classification, Question Answering, Sentence Similarity/Ranking, Syntactic Parsing, and more. DeepPavlov also provides embeddings like BERT, ELMo, and FastText for various languages, along with AutoML capabilities and integrations with REST API, Socket API, and Amazon AWS.

litdata
LitData is a tool designed for blazingly fast, distributed streaming of training data from any cloud storage. It allows users to transform and optimize data in cloud storage environments efficiently and intuitively, supporting various data types like images, text, video, audio, geo-spatial, and multimodal data. LitData integrates smoothly with frameworks such as LitGPT and PyTorch, enabling seamless streaming of data to multiple machines. Key features include multi-GPU/multi-node support, easy data mixing, pause & resume functionality, support for profiling, memory footprint reduction, cache size configuration, and on-prem optimizations. The tool also provides benchmarks for measuring streaming speed and conversion efficiency, along with runnable templates for different data types. LitData enables infinite cloud data processing by utilizing the Lightning.ai platform to scale data processing with optimized machines.

LLamaSharp
LLamaSharp is a cross-platform library to run 🦙LLaMA/LLaVA model (and others) on your local device. Based on llama.cpp, inference with LLamaSharp is efficient on both CPU and GPU. With the higher-level APIs and RAG support, it's convenient to deploy LLM (Large Language Model) in your application with LLamaSharp.
rag-chatbot
The RAG ChatBot project combines Lama.cpp, Chroma, and Streamlit to build a Conversation-aware Chatbot and a Retrieval-augmented generation (RAG) ChatBot. The RAG Chatbot works by taking a collection of Markdown files as input and provides answers based on the context provided by those files. It utilizes a Memory Builder component to load Markdown pages, divide them into sections, calculate embeddings, and save them in an embedding database. The chatbot retrieves relevant sections from the database, rewrites questions for optimal retrieval, and generates answers using a local language model. It also remembers previous interactions for more accurate responses. Various strategies are implemented to deal with context overflows, including creating and refining context, hierarchical summarization, and async hierarchical summarization.
For similar tasks
solo-server
Solo Server is a lightweight server designed for managing hardware-aware inference. It provides seamless setup through a simple CLI and HTTP servers, an open model registry for pulling models from platforms like Ollama and Hugging Face, cross-platform compatibility for effortless deployment of AI models on hardware, and a configurable framework that auto-detects hardware components (CPU, GPU, RAM) and sets optimal configurations.
llmfit
llmfit is a terminal tool designed to optimize LLM models for your system's RAM, CPU, and GPU. It detects your hardware, scores models based on quality, speed, fit, and context, and recommends models that will run well on your machine. It supports multi-GPU setups, MoE architectures, dynamic quantization selection, and speed estimation. The tool provides an interactive TUI and a classic CLI mode for ease of use. It includes a database of 94 models from 30 providers sourced from the HuggingFace API, with memory requirements computed from parameter counts across a quantization hierarchy. llmfit uses multi-dimensional scoring to rank models and estimates speed based on backend-specific constants. It also offers dynamic quantization selection to fit models to available memory efficiently.

ck
Collective Mind (CM) is a collection of portable, extensible, technology-agnostic and ready-to-use automation recipes with a human-friendly interface (aka CM scripts) to unify and automate all the manual steps required to compose, run, benchmark and optimize complex ML/AI applications on any platform with any software and hardware: see online catalog and source code. CM scripts require Python 3.7+ with minimal dependencies and are continuously extended by the community and MLCommons members to run natively on Ubuntu, MacOS, Windows, RHEL, Debian, Amazon Linux and any other operating system, in a cloud or inside automatically generated containers while keeping backward compatibility - please don't hesitate to report encountered issues here and contact us via public Discord Server to help this collaborative engineering effort! CM scripts were originally developed based on the following requirements from the MLCommons members to help them automatically compose and optimize complex MLPerf benchmarks, applications and systems across diverse and continuously changing models, data sets, software and hardware from Nvidia, Intel, AMD, Google, Qualcomm, Amazon and other vendors: * must work out of the box with the default options and without the need to edit some paths, environment variables and configuration files; * must be non-intrusive, easy to debug and must reuse existing user scripts and automation tools (such as cmake, make, ML workflows, python poetry and containers) rather than substituting them; * must have a very simple and human-friendly command line with a Python API and minimal dependencies; * must require minimal or zero learning curve by using plain Python, native scripts, environment variables and simple JSON/YAML descriptions instead of inventing new workflow languages; * must have the same interface to run all automations natively, in a cloud or inside containers. CM scripts were successfully validated by MLCommons to modularize MLPerf inference benchmarks and help the community automate more than 95% of all performance and power submissions in the v3.1 round across more than 120 system configurations (models, frameworks, hardware) while reducing development and maintenance costs.

aimet
AIMET is a library that provides advanced model quantization and compression techniques for trained neural network models. It provides features that have been proven to improve run-time performance of deep learning neural network models with lower compute and memory requirements and minimal impact to task accuracy. AIMET is designed to work with PyTorch, TensorFlow and ONNX models. We also host the AIMET Model Zoo - a collection of popular neural network models optimized for 8-bit inference. We also provide recipes for users to quantize floating point models using AIMET.

byteir
The ByteIR Project is a ByteDance model compilation solution. ByteIR includes compiler, runtime, and frontends, and provides an end-to-end model compilation solution. Although all ByteIR components (compiler/runtime/frontends) are together to provide an end-to-end solution, and all under the same umbrella of this repository, each component technically can perform independently. The name, ByteIR, comes from a legacy purpose internally. The ByteIR project is NOT an IR spec definition project. Instead, in most scenarios, ByteIR directly uses several upstream MLIR dialects and Google Mhlo. Most of ByteIR compiler passes are compatible with the selected upstream MLIR dialects and Google Mhlo.

hqq
HQQ is a fast and accurate model quantizer that skips the need for calibration data. It's super simple to implement (just a few lines of code for the optimizer). It can crunch through quantizing the Llama2-70B model in only 4 minutes! 🚀
effort
Effort is an example implementation of the bucketMul algorithm, which allows for real-time adjustment of the number of calculations performed during inference of an LLM model. At 50% effort, it performs as fast as regular matrix multiplications on Apple Silicon chips; at 25% effort, it is twice as fast while still retaining most of the quality. Additionally, users have the option to skip loading the least important weights.
neural-compressor
Intel® Neural Compressor is an open-source Python library that supports popular model compression techniques such as quantization, pruning (sparsity), distillation, and neural architecture search on mainstream frameworks such as TensorFlow, PyTorch, ONNX Runtime, and MXNet. It provides key features, typical examples, and open collaborations, including support for a wide range of Intel hardware, validation of popular LLMs, and collaboration with cloud marketplaces, software platforms, and open AI ecosystems.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.