
supabase-mcp
Connect Supabase to your AI assistants
Stars: 299
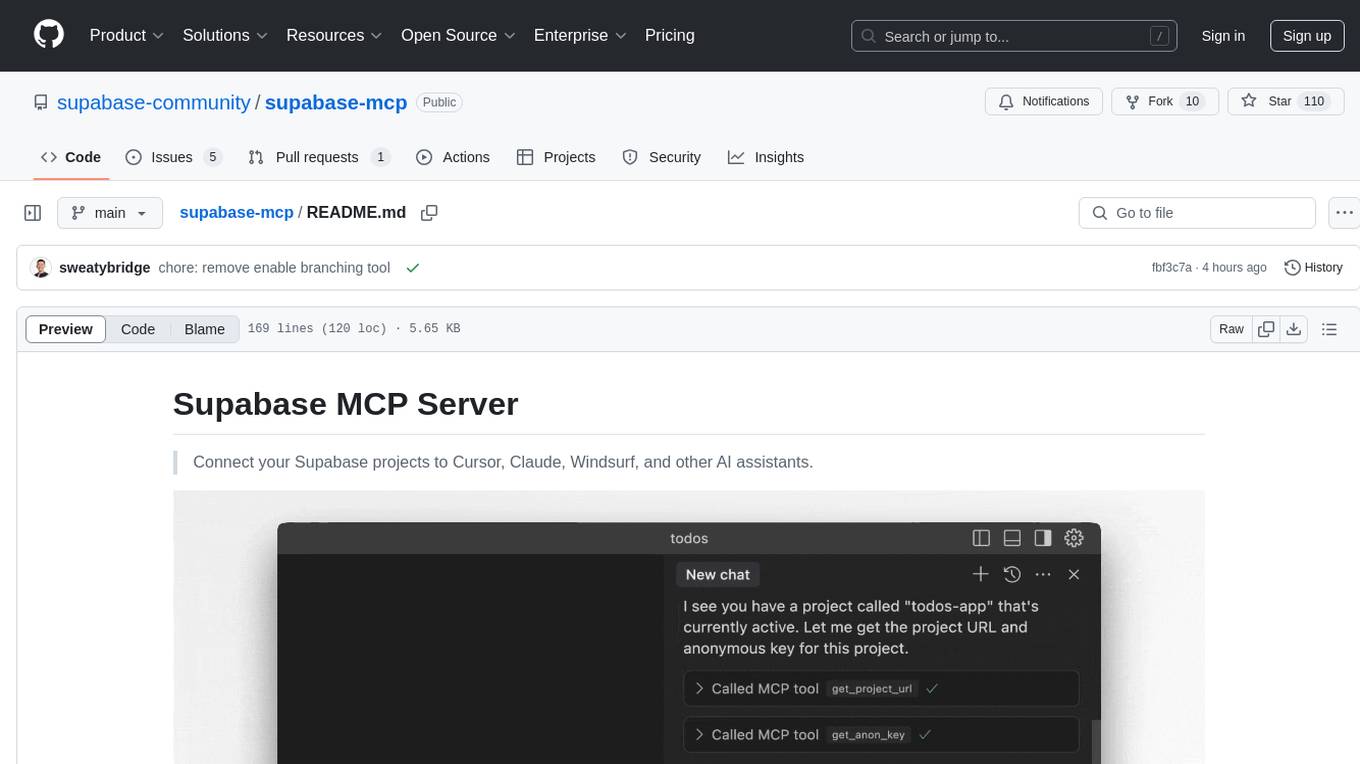
Supabase MCP Server standardizes how Large Language Models (LLMs) interact with Supabase, enabling AI assistants to manage tables, fetch config, and query data. It provides tools for project management, database operations, project configuration, branching (experimental), and development tools. The server is pre-1.0, so expect some breaking changes between versions.
README:
Connect your Supabase projects to Cursor, Claude, Windsurf, and other AI assistants.
The Model Context Protocol (MCP) standardizes how Large Language Models (LLMs) talk to external services like Supabase. It connects AI assistants directly with your Supabase project and allows them to perform tasks like managing tables, fetching config, and querying data. See the full list of tools.
You will need Node.js installed on your machine. You can check this by running:
node -vIf you don't have Node.js installed, you can download it from nodejs.org.
First, go to your Supabase settings and create a personal access token. Give it a name that describes its purpose, like "Cursor MCP Server".
This will be used to authenticate the MCP server with your Supabase account. Make sure to copy the token, as you won't be able to see it again.
Next, configure your MCP client (such as Cursor) to use this server. Most MCP clients store the configuration as JSON in the following format:
{
"mcpServers": {
"supabase": {
"command": "npx",
"args": [
"-y",
"@supabase/mcp-server-supabase@latest",
"--access-token",
"<personal-access-token>"
]
}
}
}Replace <personal-access-token> with the token you created in step 1. If you are on Windows, you will need to prefix this command.
If your MCP client doesn't accept JSON, the direct CLI command is:
npx -y @supabase/mcp-server-supabase@latest --access-token=<personal-access-token>Note: Do not run this command directly - this is meant to be executed by your MCP client in order to start the server.
npxautomatically downloads the latest version of the MCP server fromnpmand runs it in a single command.
On Windows, you will need to prefix the command with cmd /c:
{
"mcpServers": {
"supabase": {
"command": "cmd",
"args": [
"/c",
"npx",
"-y",
"@supabase/mcp-server-supabase@latest",
"--access-token",
"<personal-access-token>"
]
}
}
}or with wsl if you are running Node.js inside WSL:
{
"mcpServers": {
"supabase": {
"command": "wsl",
"args": [
"npx",
"-y",
"@supabase/mcp-server-supabase@latest",
"--access-token",
"<personal-access-token>"
]
}
}
}Make sure Node.js is available in your system PATH environment variable. If you are running Node.js natively on Windows, you can set this by running the following commands in your terminal.
-
Get the path to
npm:npm config get prefix
-
Add the directory to your PATH:
setx PATH "%PATH%;<path-to-dir>" -
Restart your MCP client.
Note: This server is pre-1.0, so expect some breaking changes between versions. Since LLMs will automatically adapt to the tools available, this shouldn't affect most users.
The following Supabase tools are available to the LLM:
-
list_projects: Lists all Supabase projects for the user. -
get_project: Gets details for a project. -
create_project: Creates a new Supabase project. -
pause_project: Pauses a project. -
restore_project: Restores a project. -
list_organizations: Lists all organizations that the user is a member of. -
get_organization: Gets details for an organization.
-
list_tables: Lists all tables within the specified schemas. -
list_extensions: Lists all extensions in the database. -
list_migrations: Lists all migrations in the database. -
apply_migration: Applies a SQL migration to the database. SQL passed to this tool will be tracked within the database, so LLMs should use this for DDL operations (schema changes). -
execute_sql: Executes raw SQL in the database. LLMs should use this for regular queries that don't change the schema. -
get_logs: Gets logs for a Supabase project by service type (api, postgres, edge functions, auth, storage, realtime). LLMs can use this to help with debugging and monitoring service performance.
-
get_project_url: Gets the API URL for a project. -
get_anon_key: Gets the anonymous API key for a project.
-
create_branch: Creates a development branch with migrations from production branch. -
list_branches: Lists all development branches. -
delete_branch: Deletes a development branch. -
merge_branch: Merges migrations and edge functions from a development branch to production. -
reset_branch: Resets migrations of a development branch to a prior version. -
rebase_branch: Rebases development branch on production to handle migration drift.
-
generate_typescript_types: Generates TypeScript types based on the database schema. LLMs can save this to a file and use it in their code.
The PostgREST MCP server allows you to connect your own users to your app via REST API. See more details on its project README.
- Model Context Protocol: Learn more about MCP and its capabilities.
This project is licensed under Apache 2.0. See the LICENSE file for details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for supabase-mcp
Similar Open Source Tools
supabase-mcp
Supabase MCP Server standardizes how Large Language Models (LLMs) interact with Supabase, enabling AI assistants to manage tables, fetch config, and query data. It provides tools for project management, database operations, project configuration, branching (experimental), and development tools. The server is pre-1.0, so expect some breaking changes between versions.
MCPJungle
MCPJungle is a self-hosted MCP Gateway for private AI agents, serving as a registry for Model Context Protocol Servers. Developers use it to manage servers and tools centrally, while clients discover and consume tools from a single 'Gateway' MCP Server. Suitable for developers using MCP Clients like Claude & Cursor, building production-grade AI Agents, and organizations managing client-server interactions. The tool allows quick start, installation, usage, server and client setup, connection to Claude and Cursor, enabling/disabling tools, managing tool groups, authentication, enterprise features like access control and OpenTelemetry metrics. Limitations include lack of long-running connections to servers and no support for OAuth flow. Contributions are welcome.
notebook-intelligence
Notebook Intelligence (NBI) is an AI coding assistant and extensible AI framework for JupyterLab. It greatly boosts the productivity of JupyterLab users with AI assistance by providing features such as code generation with inline chat, auto-complete, and chat interface. NBI supports various LLM Providers and AI Models, including local models from Ollama. Users can configure model provider and model options, remember GitHub Copilot login, and save configuration files. NBI seamlessly integrates with Model Context Protocol (MCP) servers, supporting both Standard Input/Output (stdio) and Server-Sent Events (SSE) transports. Users can easily add MCP servers to NBI, auto-approve tools, set environment variables, and group servers based on functionality. Additionally, NBI allows access to built-in tools from an MCP participant, enhancing the user experience and productivity.

bedrock-claude-chat
This repository is a sample chatbot using the Anthropic company's LLM Claude, one of the foundational models provided by Amazon Bedrock for generative AI. It allows users to have basic conversations with the chatbot, personalize it with their own instructions and external knowledge, and analyze usage for each user/bot on the administrator dashboard. The chatbot supports various languages, including English, Japanese, Korean, Chinese, French, German, and Spanish. Deployment is straightforward and can be done via the command line or by using AWS CDK. The architecture is built on AWS managed services, eliminating the need for infrastructure management and ensuring scalability, reliability, and security.

chat-mcp
A Cross-Platform Interface for Large Language Models (LLMs) utilizing the Model Context Protocol (MCP) to connect and interact with various LLMs. The desktop app, built on Electron, ensures compatibility across Linux, macOS, and Windows. It simplifies understanding MCP principles, facilitates testing of multiple servers and LLMs, and supports dynamic LLM configuration and multi-client management. The UI can be extracted for web use, ensuring consistency across web and desktop versions.

lexido
Lexido is an innovative assistant for the Linux command line, designed to boost your productivity and efficiency. Powered by Gemini Pro 1.0 and utilizing the free API, Lexido offers smart suggestions for commands based on your prompts and importantly your current environment. Whether you're installing software, managing files, or configuring system settings, Lexido streamlines the process, making it faster and more intuitive.

langserve
LangServe helps developers deploy `LangChain` runnables and chains as a REST API. This library is integrated with FastAPI and uses pydantic for data validation. In addition, it provides a client that can be used to call into runnables deployed on a server. A JavaScript client is available in LangChain.js.
bot-on-anything
The 'bot-on-anything' repository allows developers to integrate various AI models into messaging applications, enabling the creation of intelligent chatbots. By configuring the connections between models and applications, developers can easily switch between multiple channels within a project. The architecture is highly scalable, allowing the reuse of algorithmic capabilities for each new application and model integration. Supported models include ChatGPT, GPT-3.0, New Bing, and Google Bard, while supported applications range from terminals and web platforms to messaging apps like WeChat, Telegram, QQ, and more. The repository provides detailed instructions for setting up the environment, configuring the models and channels, and running the chatbot for various tasks across different messaging platforms.
cursor-tools
cursor-tools is a CLI tool designed to enhance AI agents with advanced skills, such as web search, repository context, documentation generation, GitHub integration, Xcode tools, and browser automation. It provides features like Perplexity for web search, Gemini 2.0 for codebase context, and Stagehand for browser operations. The tool requires API keys for Perplexity AI and Google Gemini, and supports global installation for system-wide access. It offers various commands for different tasks and integrates with Cursor Composer for AI agent usage.
odoo-expert
RAG-Powered Odoo Documentation Assistant is a comprehensive documentation processing and chat system that converts Odoo's documentation to a searchable knowledge base with an AI-powered chat interface. It supports multiple Odoo versions (16.0, 17.0, 18.0) and provides semantic search capabilities powered by OpenAI embeddings. The tool automates the conversion of RST to Markdown, offers real-time semantic search, context-aware AI-powered chat responses, and multi-version support. It includes a Streamlit-based web UI, REST API for programmatic access, and a CLI for document processing and chat. The system operates through a pipeline of data processing steps and an interface layer for UI and API access to the knowledge base.

promptwright
Promptwright is a Python library designed for generating large synthetic datasets using a local LLM and various LLM service providers. It offers flexible interfaces for generating prompt-led synthetic datasets. The library supports multiple providers, configurable instructions and prompts, YAML configuration for tasks, command line interface for running tasks, push to Hugging Face Hub for dataset upload, and system message control. Users can define generation tasks using YAML configuration or Python code. Promptwright integrates with LiteLLM to interface with LLM providers and supports automatic dataset upload to Hugging Face Hub.
raycast_api_proxy
The Raycast AI Proxy is a tool that acts as a proxy for the Raycast AI application, allowing users to utilize the application without subscribing. It intercepts and forwards Raycast requests to various AI APIs, then reformats the responses for Raycast. The tool supports multiple AI providers and allows for custom model configurations. Users can generate self-signed certificates, add them to the system keychain, and modify DNS settings to redirect requests to the proxy. The tool is designed to work with providers like OpenAI, Azure OpenAI, Google, and more, enabling tasks such as AI chat completions, translations, and image generation.
promptwright
Promptwright is a Python library designed for generating large synthetic datasets using local LLM and various LLM service providers. It offers flexible interfaces for generating prompt-led synthetic datasets. The library supports multiple providers, configurable instructions and prompts, YAML configuration, command line interface, push to Hugging Face Hub, and system message control. Users can define generation tasks using YAML configuration files or programmatically using Python code. Promptwright integrates with LiteLLM for LLM providers and supports automatic dataset upload to Hugging Face Hub. The library is not responsible for the content generated by models and advises users to review the data before using it in production environments.
agent-mimir
Agent Mimir is a command line and Discord chat client 'agent' manager for LLM's like Chat-GPT that provides the models with access to tooling and a framework with which accomplish multi-step tasks. It is easy to configure your own agent with a custom personality or profession as well as enabling access to all tools that are compatible with LangchainJS. Agent Mimir is based on LangchainJS, every tool or LLM that works on Langchain should also work with Mimir. The tasking system is based on Auto-GPT and BabyAGI where the agent needs to come up with a plan, iterate over its steps and review as it completes the task.

magic-cli
Magic CLI is a command line utility that leverages Large Language Models (LLMs) to enhance command line efficiency. It is inspired by projects like Amazon Q and GitHub Copilot for CLI. The tool allows users to suggest commands, search across command history, and generate commands for specific tasks using local or remote LLM providers. Magic CLI also provides configuration options for LLM selection and response generation. The project is still in early development, so users should expect breaking changes and bugs.
tiledesk-dashboard
Tiledesk is an open-source live chat platform with integrated chatbots written in Node.js and Express. It is designed to be a multi-channel platform for web, Android, and iOS, and it can be used to increase sales or provide post-sales customer service. Tiledesk's chatbot technology allows for automation of conversations, and it also provides APIs and webhooks for connecting external applications. Additionally, it offers a marketplace for apps and features such as CRM, ticketing, and data export.
For similar tasks
supabase-mcp
Supabase MCP Server standardizes how Large Language Models (LLMs) interact with Supabase, enabling AI assistants to manage tables, fetch config, and query data. It provides tools for project management, database operations, project configuration, branching (experimental), and development tools. The server is pre-1.0, so expect some breaking changes between versions.
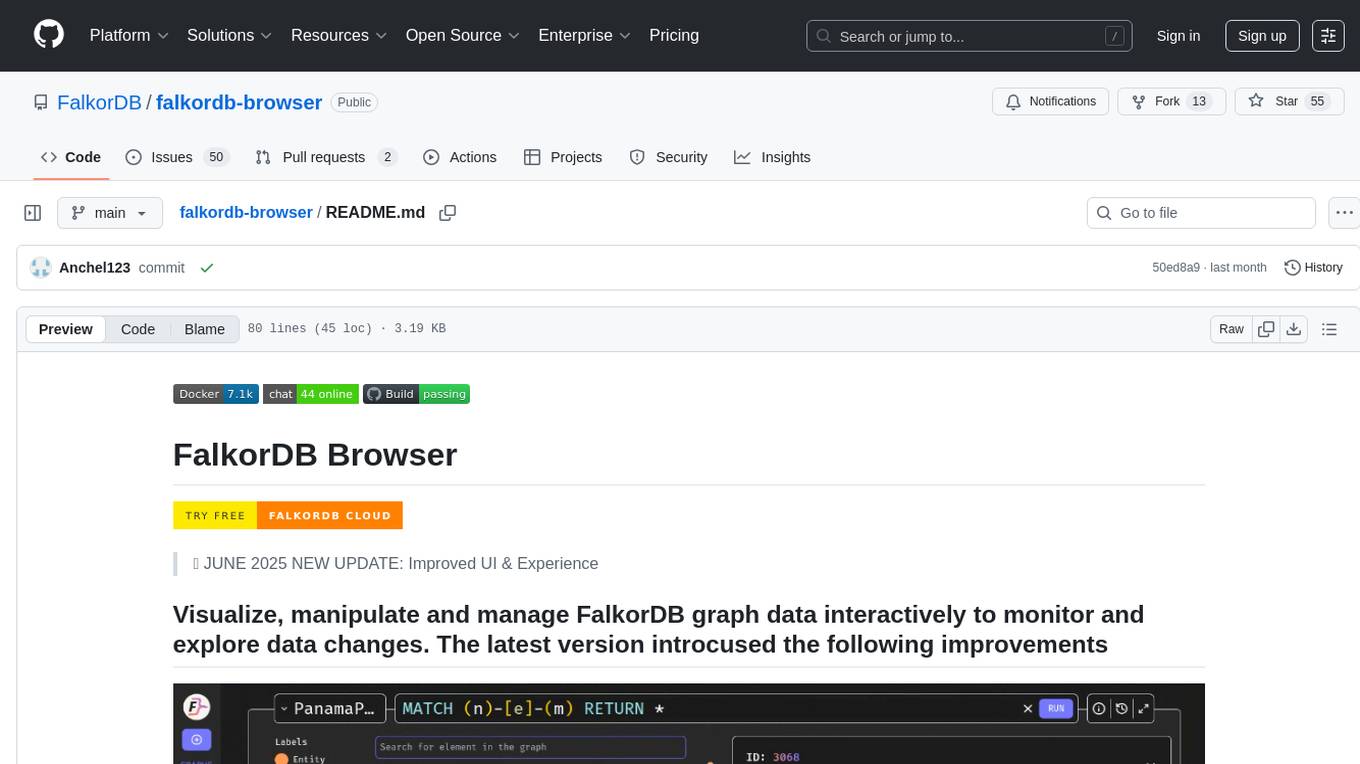
falkordb-browser
FalkorDB Browser is a user-friendly web application for browsing and managing databases. It provides an intuitive interface for users to interact with their databases, allowing them to view, edit, and query data easily. With FalkorDB Browser, users can perform various database operations without the need for complex commands or scripts, making database management more accessible and efficient.

llama_index
LlamaIndex is a data framework for building LLM applications. It provides tools for ingesting, structuring, and querying data, as well as integrating with LLMs and other tools. LlamaIndex is designed to be easy to use for both beginner and advanced users, and it provides a comprehensive set of features for building LLM applications.

kernel-memory
Kernel Memory (KM) is a multi-modal AI Service specialized in the efficient indexing of datasets through custom continuous data hybrid pipelines, with support for Retrieval Augmented Generation (RAG), synthetic memory, prompt engineering, and custom semantic memory processing. KM is available as a Web Service, as a Docker container, a Plugin for ChatGPT/Copilot/Semantic Kernel, and as a .NET library for embedded applications. Utilizing advanced embeddings and LLMs, the system enables Natural Language querying for obtaining answers from the indexed data, complete with citations and links to the original sources. Designed for seamless integration as a Plugin with Semantic Kernel, Microsoft Copilot and ChatGPT, Kernel Memory enhances data-driven features in applications built for most popular AI platforms.

deeplake
Deep Lake is a Database for AI powered by a storage format optimized for deep-learning applications. Deep Lake can be used for: 1. Storing data and vectors while building LLM applications 2. Managing datasets while training deep learning models Deep Lake simplifies the deployment of enterprise-grade LLM-based products by offering storage for all data types (embeddings, audio, text, videos, images, pdfs, annotations, etc.), querying and vector search, data streaming while training models at scale, data versioning and lineage, and integrations with popular tools such as LangChain, LlamaIndex, Weights & Biases, and many more. Deep Lake works with data of any size, it is serverless, and it enables you to store all of your data in your own cloud and in one place. Deep Lake is used by Intel, Bayer Radiology, Matterport, ZERO Systems, Red Cross, Yale, & Oxford.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
db-ally
db-ally is a library for creating natural language interfaces to data sources. It allows developers to outline specific use cases for a large language model (LLM) to handle, detailing the desired data format and the possible operations to fetch this data. db-ally effectively shields the complexity of the underlying data source from the model, presenting only the essential information needed for solving the specific use cases. Instead of generating arbitrary SQL, the model is asked to generate responses in a simplified query language.
DeepBI
DeepBI is an AI-native data analysis platform that leverages the power of large language models to explore, query, visualize, and share data from any data source. Users can use DeepBI to gain data insight and make data-driven decisions.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.