
DeepFabric
Create large-scale synthetic training data for model distillation and evaluation
Stars: 444

Deepfabric is an SDK and CLI tool that leverages large language models to generate high-quality synthetic datasets. It's designed for researchers and developers building teacher-student distillation pipelines, creating evaluation benchmarks for models and agents, or conducting research requiring diverse training data. The key innovation lies in Deepfabric's graph and tree-based architecture, which uses structured topic nodes as generation seeds. This approach ensures the creation of datasets that are both highly diverse and domain-specific, while minimizing redundancy and duplication across generated samples.
README:


Deepfabric is an SDK and CLI tool that leverages large language models to generate high-quality synthetic datasets. It's designed for researchers and developers building teacher-student distillation pipelines, creating evaluation benchmarks for models and agents, or conducting research requiring diverse training data.
The key innovation lies in Deepfabric's graph and tree-based architecture, which uses structured topic nodes as generation seeds. This approach ensures the creation of datasets that are both highly diverse and domain-specific, while minimizing redundancy and duplication across generated samples.
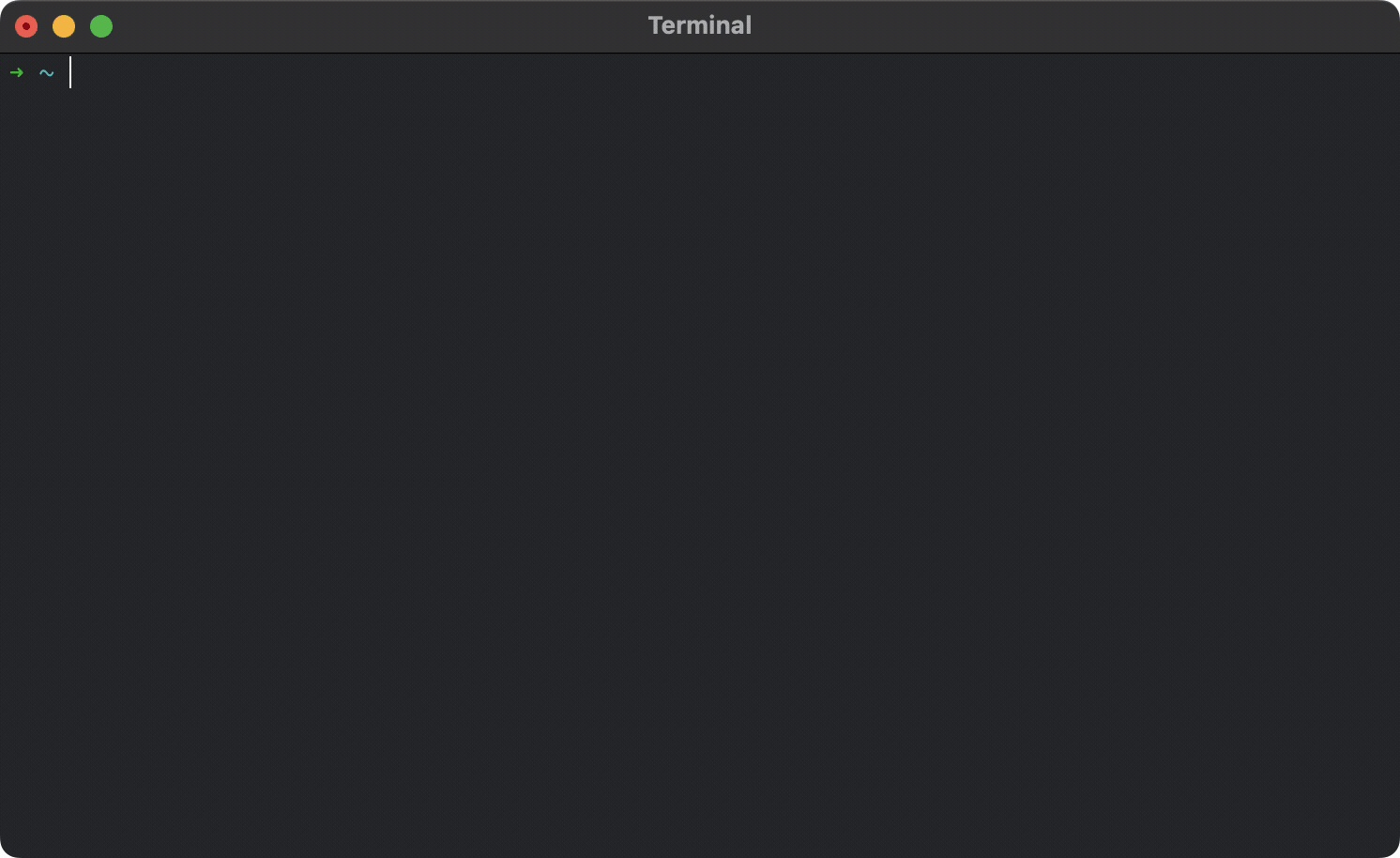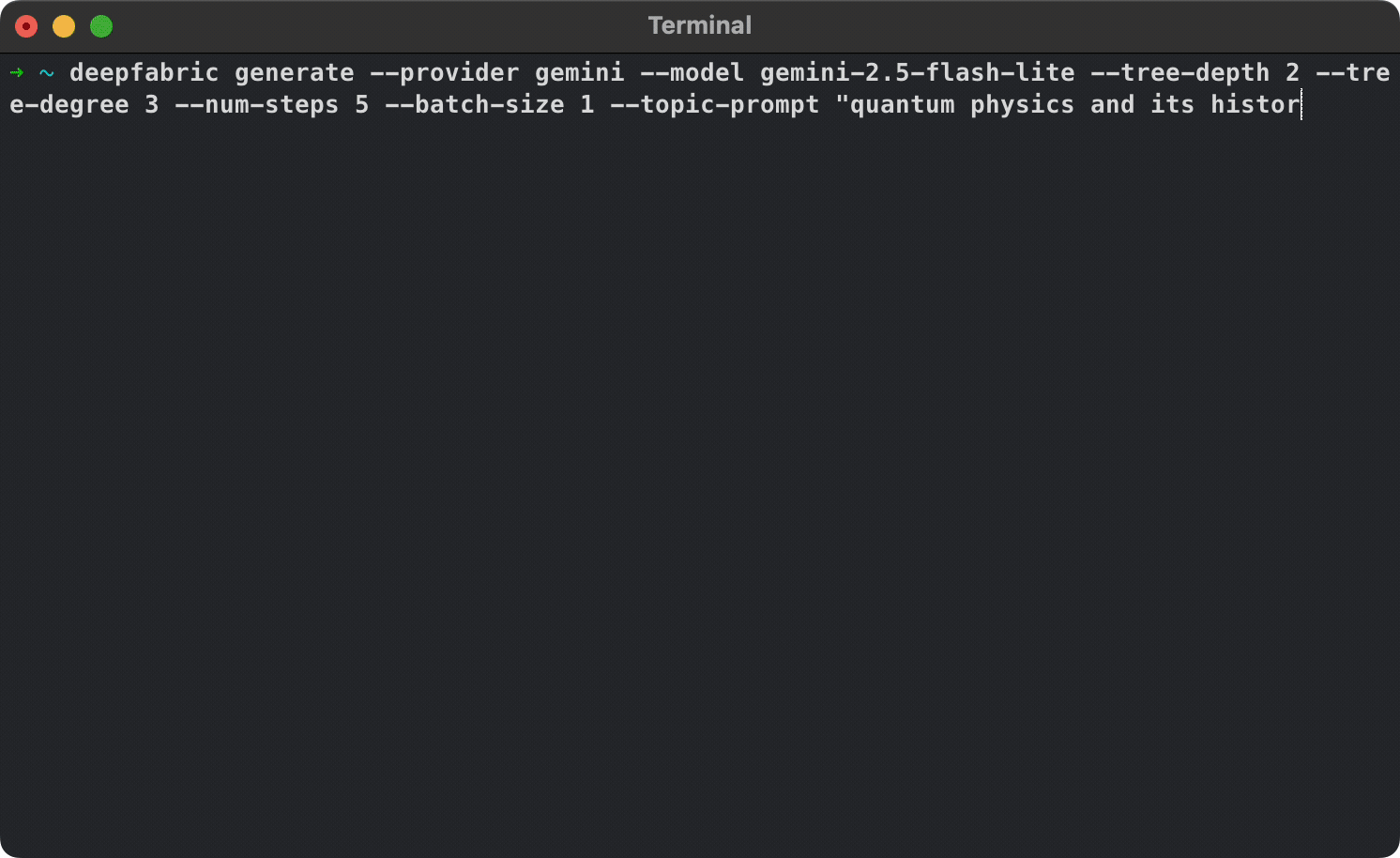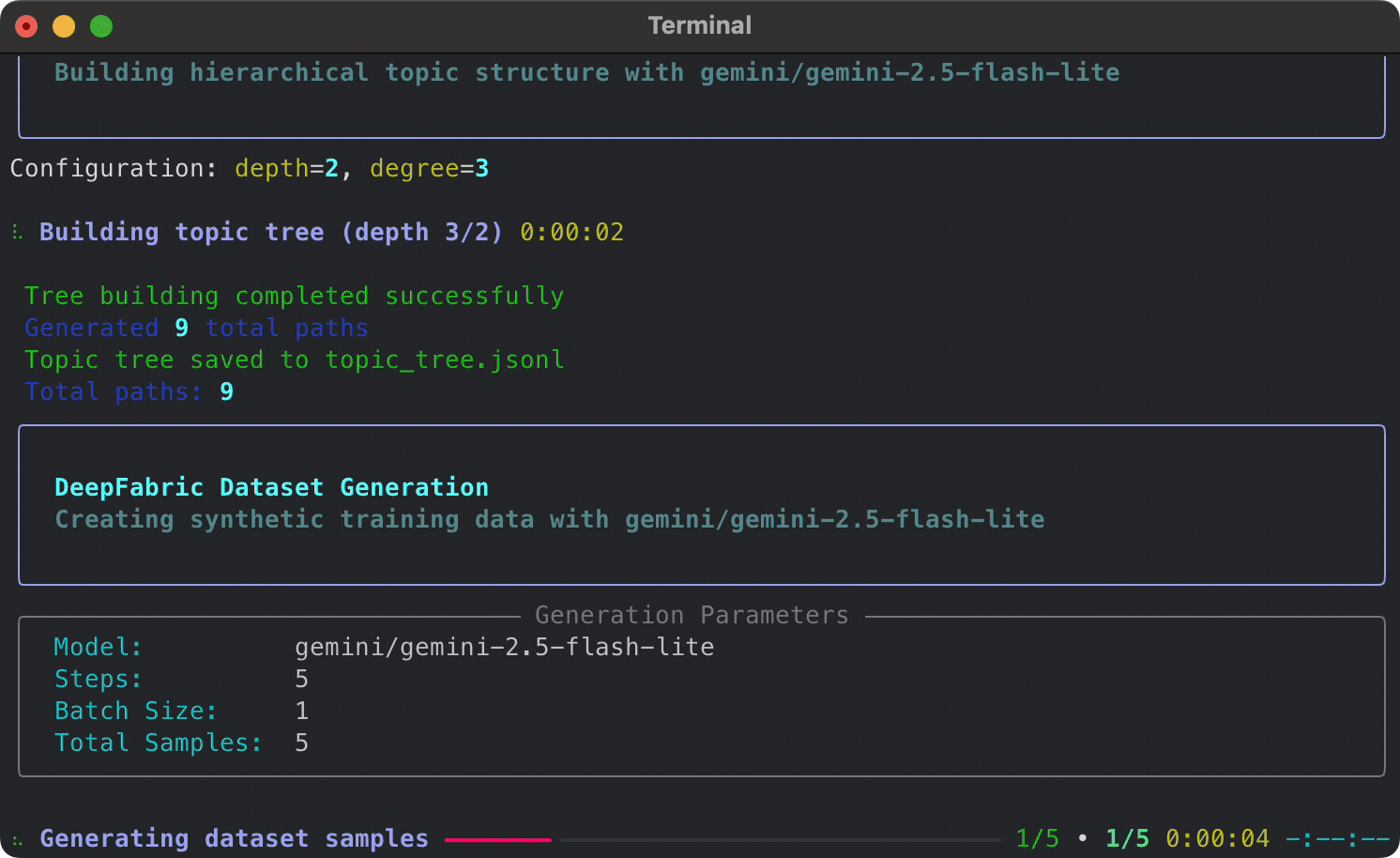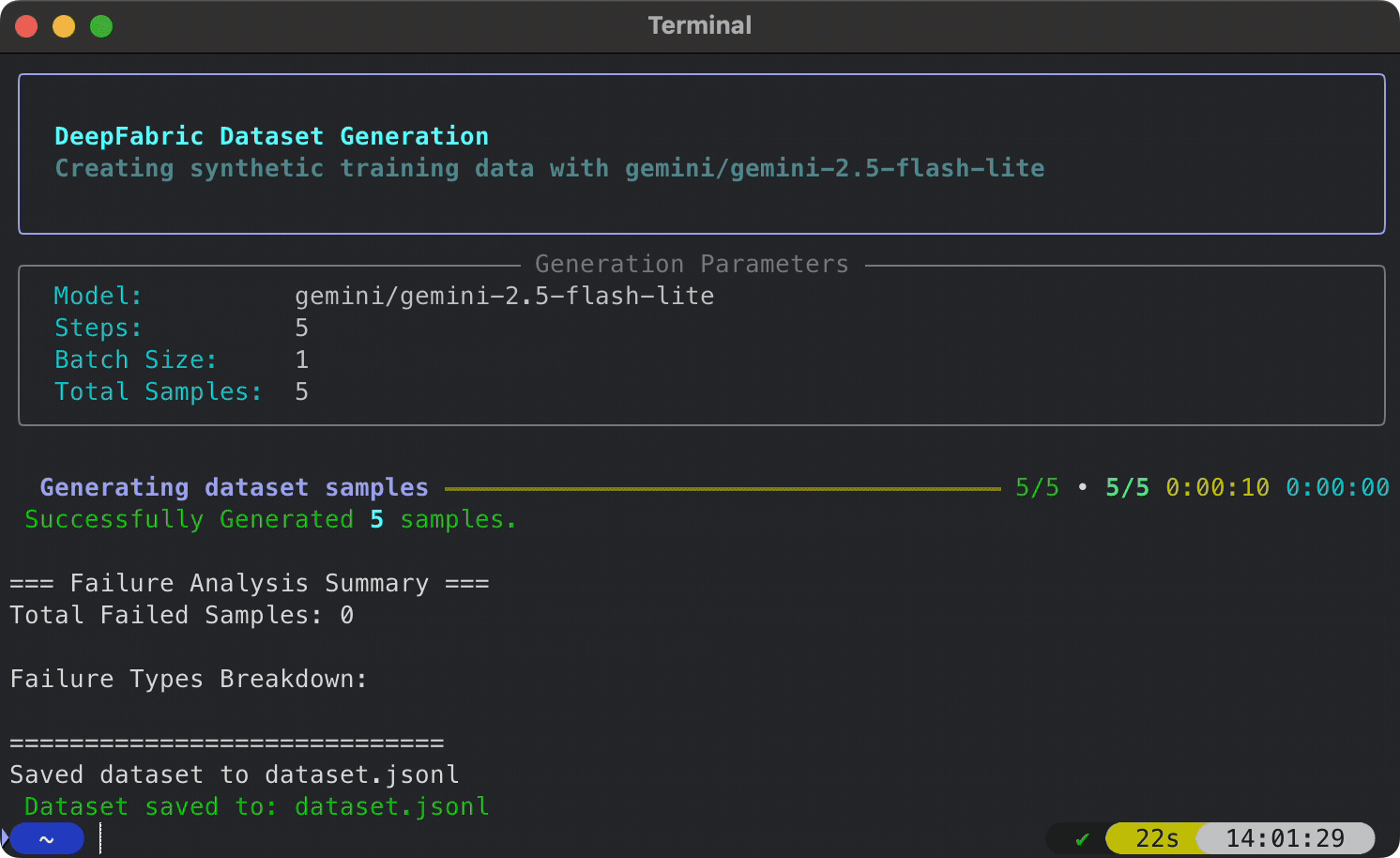
Get up and running in under 60 seconds:
pip install deepfabric# Set your API key (or use Ollama for local generation)
export OPENAI_API_KEY="your-api-key"
# Generate a dataset with a single command
deepfabric generate \
--mode tree \
--provider openai \
--model gpt-4o \
--depth 3 \
--degree 3 \
--num-steps 9 \
--batch-size 1 \
--topic-prompt "This history Quantum physics" \
--generation-system-prompt "You are an expert on academic history, with a specialism in the sciences" \
--dataset-save-as dataset.jsonlDeepfabric will automatically:
- Generate a hierarchical topic tree (3 levels deep, 3 branches per level)
- Create 9 diverse Q&A pairs across the generated topics
- Save your dataset to
dataset.jsonl
Your dataset is ready for fine-tuning in the standard instruct format:
{
"messages": [
{
"role": "user",
"content": "Can you explain the significance of the double-slit experiment in quantum physics?"
},
{
"role": "assistant",
"content": "The double-slit experiment is fundamental in quantum physics as it demonstrates the dual nature of light and particles, showing both wave-like and particle-like properties. When particles such as photons or electrons pass through two slits, they create an interference pattern characteristic of waves, even if sent one at a time. This result challenged classical physics and contributed significantly to the development of quantum mechanics, highlighting the probabilistic nature of quantum states."
}
]
}
{
"messages": [
{
"role": "user",
"content": "Can you explain Albert Einstein's contribution to quantum theory?"
},
{
"role": "assistant",
"content": "Albert Einstein made significant contributions to quantum theory, particularly through his explanation of the photoelectric effect, for which he won the Nobel Prize in 1921. He proposed that light could be thought of as discrete packets of energy called quanta or photons, which could explain how electrons are emitted from metals when exposed to light. This idea was instrumental in the development of quantum mechanics. He later became famous for his skepticism about quantum mechanics probabilistic interpretation, leading to his quote \"God does not play dice with the universe.\""
}
]
}Generate larger datasets with different models:
# With a depth of 4 and degree of 4^5 = 1,024
deepfabric generate \
--provider ollama \
--model qwen3:8b \
--depth 4 \
--degree 5 \
--num-steps 100 \
--batch-size 5 \
--topic-prompt "Machine Learning Fundamentals"
--generation-system-prompt "You are an expert on Machine Learning and its application in modern technologies" \
--dataset-save-as dataset.jsonlDeepfabric can generate topics using two approaches:
Topic Graphs (Experimental): DAG-based structure allowing cross-connections between topics, ideal for complex domains with interconnected concepts.
Topic Trees: Traditional hierarchical structure where each topic branches into subtopics, perfect for well-organized domains.
Leverage different LLMs for different tasks. Use GPT-4 for complex topic generation, then switch to a local model like Mixtral for bulk data creation:
topic_tree:
provider: "openai"
model: "gpt-4" # High quality for topic structure
data_engine:
provider: "ollama"
model: "mixtral" # Fast and efficient for bulk generationPush your datasets directly to Hugging Face Hub with automatic dataset cards:
deepfabric generate config.yaml --hf-repo username/my-dataset --hf-token $HF_TOKENFor more details, including how to use the SDK, see the docs!
There are also lots of examples to get you going.
Deepfabric development is moving at a fast pace 🏃♂️, for a great way to follow the project and to be instantly notified of new releases, Star the repo.

Introduce Outlines as an LiteLLM replacement, and make use of its structured ouput support
Deepfabric currently outputs to Open AI chat format, we will provide a system where you can easily plug in a post-processing conversion to whatever format is needed. This should allow easy adaption to what ever you need within a training pipeline:
formatters:
- name: "alpaca"
template: "builtin://alpaca.py"
- name: "custom"
template: "file://./my_format.py"
config:
instruction_field: "query"We will be introducing, multi-turn, reasoning, chain-of-thought etc.
Push to Kaggel
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for DeepFabric
Similar Open Source Tools
DeepFabric
Deepfabric is an SDK and CLI tool that leverages large language models to generate high-quality synthetic datasets. It's designed for researchers and developers building teacher-student distillation pipelines, creating evaluation benchmarks for models and agents, or conducting research requiring diverse training data. The key innovation lies in Deepfabric's graph and tree-based architecture, which uses structured topic nodes as generation seeds. This approach ensures the creation of datasets that are both highly diverse and domain-specific, while minimizing redundancy and duplication across generated samples.

marqo
Marqo is more than a vector database, it's an end-to-end vector search engine for both text and images. Vector generation, storage and retrieval are handled out of the box through a single API. No need to bring your own embeddings.

LongBench
LongBench v2 is a benchmark designed to assess the ability of large language models (LLMs) to handle long-context problems requiring deep understanding and reasoning across various real-world multitasks. It consists of 503 challenging multiple-choice questions with contexts ranging from 8k to 2M words, covering six major task categories. The dataset is collected from nearly 100 highly educated individuals with diverse professional backgrounds and is designed to be challenging even for human experts. The evaluation results highlight the importance of enhanced reasoning ability and scaling inference-time compute to tackle the long-context challenges in LongBench v2.
Figma-Context-MCP
Figma-Context-MCP is a plugin for Figma that allows users to easily manage and switch between multiple design contexts within a single Figma file. This tool simplifies the process of working on different design variations or versions by providing a seamless way to organize and switch between them. With Figma-Context-MCP, designers can streamline their workflow and improve collaboration by keeping all design contexts in one place and easily accessible. This plugin enhances productivity and efficiency for Figma users who frequently work on multiple design iterations or versions within a project.
CodeFuse-ModelCache
Codefuse-ModelCache is a semantic cache for large language models (LLMs) that aims to optimize services by introducing a caching mechanism. It helps reduce the cost of inference deployment, improve model performance and efficiency, and provide scalable services for large models. The project caches pre-generated model results to reduce response time for similar requests and enhance user experience. It integrates various embedding frameworks and local storage options, offering functionalities like cache-writing, cache-querying, and cache-clearing through RESTful API. The tool supports multi-tenancy, system commands, and multi-turn dialogue, with features for data isolation, database management, and model loading schemes. Future developments include data isolation based on hyperparameters, enhanced system prompt partitioning storage, and more versatile embedding models and similarity evaluation algorithms.

VMind
VMind is an open-source solution for intelligent visualization, providing an intelligent chart component based on LLM by VisActor. It allows users to create chart narrative works with natural language interaction, edit charts through dialogue, and export narratives as videos or GIFs. The tool is easy to use, scalable, supports various chart types, and offers one-click export functionality. Users can customize chart styles, specify themes, and aggregate data using LLM models. VMind aims to enhance efficiency in creating data visualization works through dialogue-based editing and natural language interaction.

xFinder
xFinder is a model specifically designed for key answer extraction from large language models (LLMs). It addresses the challenges of unreliable evaluation methods by optimizing the key answer extraction module. The model achieves high accuracy and robustness compared to existing frameworks, enhancing the reliability of LLM evaluation. It includes a specialized dataset, the Key Answer Finder (KAF) dataset, for effective training and evaluation. xFinder is suitable for researchers and developers working with LLMs to improve answer extraction accuracy.

oasis
OASIS is a scalable, open-source social media simulator that integrates large language models with rule-based agents to realistically mimic the behavior of up to one million users on platforms like Twitter and Reddit. It facilitates the study of complex social phenomena such as information spread, group polarization, and herd behavior, offering a versatile tool for exploring diverse social dynamics and user interactions in digital environments. With features like scalability, dynamic environments, diverse action spaces, and integrated recommendation systems, OASIS provides a comprehensive platform for simulating social media interactions at a large scale.
lorax
LoRAX is a framework that allows users to serve thousands of fine-tuned models on a single GPU, dramatically reducing the cost of serving without compromising on throughput or latency. It features dynamic adapter loading, heterogeneous continuous batching, adapter exchange scheduling, optimized inference, and is ready for production with prebuilt Docker images, Helm charts for Kubernetes, Prometheus metrics, and distributed tracing with Open Telemetry. LoRAX supports a number of Large Language Models as the base model including Llama, Mistral, and Qwen, and any of the linear layers in the model can be adapted via LoRA and loaded in LoRAX.
AutoNode
AutoNode is a self-operating computer system designed to automate web interactions and data extraction processes. It leverages advanced technologies like OCR (Optical Character Recognition), YOLO (You Only Look Once) models for object detection, and a custom site-graph to navigate and interact with web pages programmatically. Users can define objectives, create site-graphs, and utilize AutoNode via API to automate tasks on websites. The tool also supports training custom YOLO models for object detection and OCR for text recognition on web pages. AutoNode can be used for tasks such as extracting product details, automating web interactions, and more.

DemoGPT
DemoGPT is an all-in-one agent library that provides tools, prompts, frameworks, and LLM models for streamlined agent development. It leverages GPT-3.5-turbo to generate LangChain code, creating interactive Streamlit applications. The tool is designed for creating intelligent, interactive, and inclusive solutions in LLM-based application development. It offers model flexibility, iterative development, and a commitment to user engagement. Future enhancements include integrating Gorilla for autonomous API usage and adding a publicly available database for refining the generation process.
neo4j-graphrag-python
The Neo4j GraphRAG package for Python is an official repository that provides features for creating and managing vector indexes in Neo4j databases. It aims to offer developers a reliable package with long-term commitment, maintenance, and fast feature updates. The package supports various Python versions and includes functionalities for creating vector indexes, populating them, and performing similarity searches. It also provides guidelines for installation, examples, and development processes such as installing dependencies, making changes, and running tests.

AutoMathText
AutoMathText is an extensive dataset of around 200 GB of mathematical texts autonomously selected by the language model Qwen-72B. It aims to facilitate research in mathematics and artificial intelligence, serve as an educational tool for learning complex mathematical concepts, and provide a foundation for developing AI models specialized in processing mathematical content.
open-extract
open-extract simplifies the ingestion and processing of unstructured data for those building AI Agents/Agentic Workflows using frameworks such as LangGraph, AG2, and CrewAI. It allows applications to identify and extract relevant data from large documents and websites with a single API call, supporting multi-schema/multi-document extraction without vendor lock-in. The tool includes built-in caching for rapid repeat extractions, providing flexibility in model provider choice.

instructor-js
Instructor is a Typescript library for structured extraction in Typescript, powered by llms, designed for simplicity, transparency, and control. It stands out for its simplicity, transparency, and user-centric design. Whether you're a seasoned developer or just starting out, you'll find Instructor's approach intuitive and steerable.

FlashRank
FlashRank is an ultra-lite and super-fast Python library designed to add re-ranking capabilities to existing search and retrieval pipelines. It is based on state-of-the-art Language Models (LLMs) and cross-encoders, offering support for pairwise/pointwise rerankers and listwise LLM-based rerankers. The library boasts the tiniest reranking model in the world (~4MB) and runs on CPU without the need for Torch or Transformers. FlashRank is cost-conscious, with a focus on low cost per invocation and smaller package size for efficient serverless deployments. It supports various models like ms-marco-TinyBERT, ms-marco-MiniLM, rank-T5-flan, ms-marco-MultiBERT, and more, with plans for future model additions. The tool is ideal for enhancing search precision and speed in scenarios where lightweight models with competitive performance are preferred.
For similar tasks
DeepFabric
Deepfabric is an SDK and CLI tool that leverages large language models to generate high-quality synthetic datasets. It's designed for researchers and developers building teacher-student distillation pipelines, creating evaluation benchmarks for models and agents, or conducting research requiring diverse training data. The key innovation lies in Deepfabric's graph and tree-based architecture, which uses structured topic nodes as generation seeds. This approach ensures the creation of datasets that are both highly diverse and domain-specific, while minimizing redundancy and duplication across generated samples.

mindsdb
MindsDB is a platform for customizing AI from enterprise data. You can create, serve, and fine-tune models in real-time from your database, vector store, and application data. MindsDB "enhances" SQL syntax with AI capabilities to make it accessible for developers worldwide. With MindsDB’s nearly 200 integrations, any developer can create AI customized for their purpose, faster and more securely. Their AI systems will constantly improve themselves — using companies’ own data, in real-time.

training-operator
Kubeflow Training Operator is a Kubernetes-native project for fine-tuning and scalable distributed training of machine learning (ML) models created with various ML frameworks such as PyTorch, Tensorflow, XGBoost, MPI, Paddle and others. Training Operator allows you to use Kubernetes workloads to effectively train your large models via Kubernetes Custom Resources APIs or using Training Operator Python SDK. > Note: Before v1.2 release, Kubeflow Training Operator only supports TFJob on Kubernetes. * For a complete reference of the custom resource definitions, please refer to the API Definition. * TensorFlow API Definition * PyTorch API Definition * Apache MXNet API Definition * XGBoost API Definition * MPI API Definition * PaddlePaddle API Definition * For details of all-in-one operator design, please refer to the All-in-one Kubeflow Training Operator * For details on its observability, please refer to the monitoring design doc.

helix
HelixML is a private GenAI platform that allows users to deploy the best of open AI in their own data center or VPC while retaining complete data security and control. It includes support for fine-tuning models with drag-and-drop functionality. HelixML brings the best of open source AI to businesses in an ergonomic and scalable way, optimizing the tradeoff between GPU memory and latency.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.

petals
Petals is a tool that allows users to run large language models at home in a BitTorrent-style manner. It enables fine-tuning and inference up to 10x faster than offloading. Users can generate text with distributed models like Llama 2, Falcon, and BLOOM, and fine-tune them for specific tasks directly from their desktop computer or Google Colab. Petals is a community-run system that relies on people sharing their GPUs to increase its capacity and offer a distributed network for hosting model layers.

LLaVA-pp
This repository, LLaVA++, extends the visual capabilities of the LLaVA 1.5 model by incorporating the latest LLMs, Phi-3 Mini Instruct 3.8B, and LLaMA-3 Instruct 8B. It provides various models for instruction-following LMMS and academic-task-oriented datasets, along with training scripts for Phi-3-V and LLaMA-3-V. The repository also includes installation instructions and acknowledgments to related open-source contributions.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.