
leva
LLM Evaluation Framework for Rails apps to be used with production data.
Stars: 78
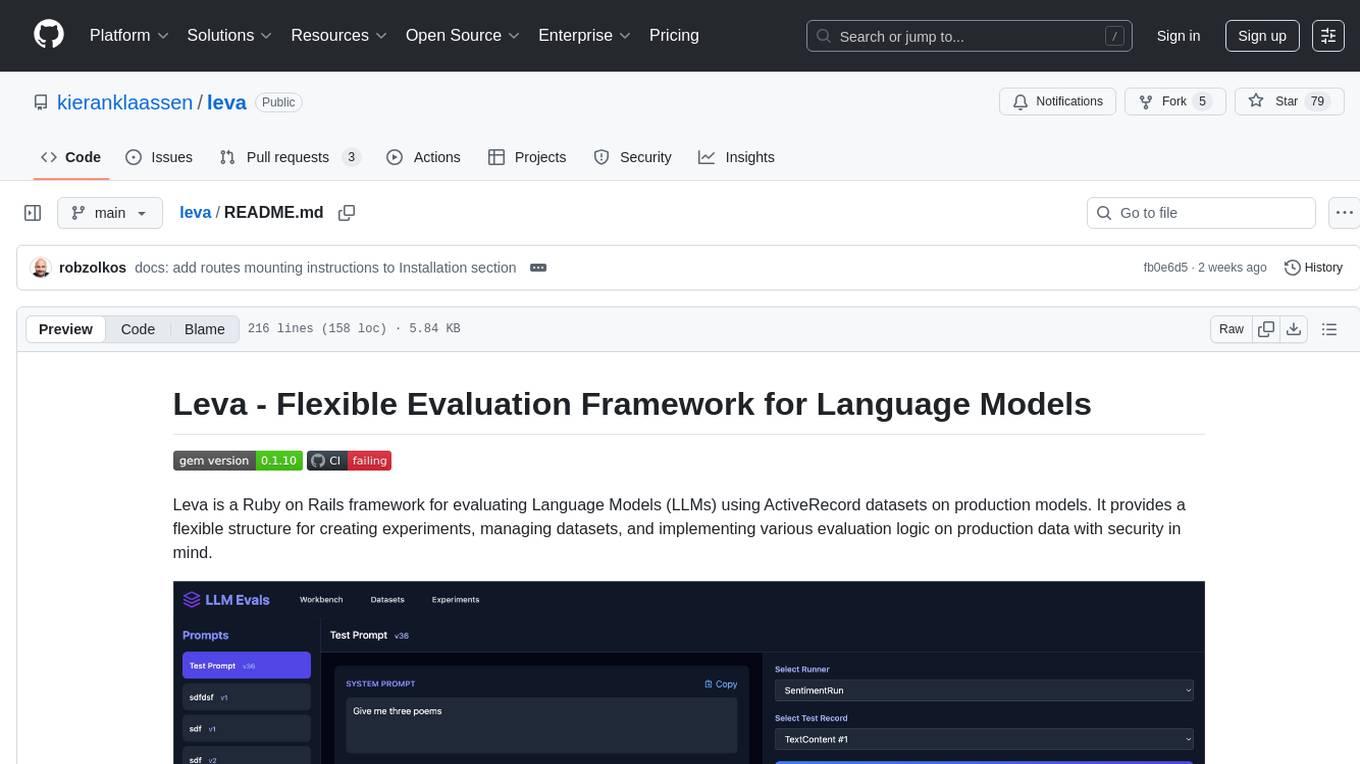
Leva is a Ruby on Rails framework designed for evaluating Language Models (LLMs) using ActiveRecord datasets on production models. It offers a flexible structure for creating experiments, managing datasets, and implementing various evaluation logic on production data with security in mind. Users can set up datasets, implement runs and evals, run experiments with different configurations, use prompts, and analyze results. Leva's components include classes like Leva, Leva::BaseRun, and Leva::BaseEval, as well as models like Leva::Dataset, Leva::DatasetRecord, Leva::Experiment, Leva::RunnerResult, Leva::EvaluationResult, and Leva::Prompt. The tool aims to provide a comprehensive solution for evaluating language models efficiently and securely.
README:
![]()
Leva is a Ruby on Rails framework for evaluating Language Models (LLMs) using ActiveRecord datasets on production models. It provides a flexible structure for creating experiments, managing datasets, and implementing various evaluation logic on production data with security in mind.
Add this line to your application's Gemfile:
gem 'leva'And then execute:
bundle installAdd the migrations to your database:
rails leva:install:migrations
rails db:migrateMount the Leva engine in your application's routes file:
# config/routes.rb
Rails.application.routes.draw do
mount Leva::Engine => "/leva"
# your other routes...
endThe Leva UI will then be available at /leva in your application.
First, create a dataset and add any ActiveRecord records you want to evaluate against. To make your models compatible with Leva, include the Leva::Recordable concern in your model:
class TextContent < ApplicationRecord
include Leva::Recordable
# @return [String] The ground truth label for the record
def ground_truth
expected_label
end
# @return [Hash] A hash of attributes to be displayed in the dataset records index
def index_attributes
{
text: text,
expected_label: expected_label,
created_at: created_at.strftime('%Y-%m-%d %H:%M:%S')
}
end
# @return [Hash] A hash of attributes to be displayed in the dataset record show view
def show_attributes
{
text: text,
expected_label: expected_label,
created_at: created_at.strftime('%Y-%m-%d %H:%M:%S')
}
end
# @return [Hash] A hash of attributes to be displayed in the dataset record show view
def to_llm_context
{
text: text,
expected_label: expected_label,
created_at: created_at.strftime('%Y-%m-%d %H:%M:%S')
}
end
end
dataset = Leva::Dataset.create(name: "Sentiment Analysis Dataset")
dataset.add_record TextContent.create(text: "I love this product!", expected_label: "Positive")
dataset.add_record TextContent.create(text: "Terrible experience", expected_label: "Negative")
dataset.add_record TextContent.create(text: "It's ok", expected_label: "Neutral")Create a run class to handle the execution of your inference logic:
rails generate leva:runner sentimentclass SentimentRun < Leva::BaseRun
def execute(record)
# Your model execution logic here
# This could involve calling an API, running a local model, etc.
# Return the model's output
end
endCreate one or more eval classes to evaluate the model's output:
rails generate leva:eval sentiment_accuracyclass SentimentAccuracyEval < Leva::BaseEval
def evaluate(prediction, record)
score = prediction == record.expected_label ? 1.0 : 0.0
[score, record.expected_label]
end
end
class SentimentF1Eval < Leva::BaseEval
def evaluate(prediction, record)
# Calculate F1 score
# ...
[f1_score, record.f1_score]
end
endYou can run experiments with different runs and evals:
experiment = Leva::Experiment.create!(name: "Sentiment Analysis", dataset: dataset)
run = SentimentRun.new
evals = [SentimentAccuracyEval.new, SentimentF1Eval.new]
Leva.run_evaluation(experiment: experiment, run: run, evals: evals)You can also use prompts with your runs:
prompt = Leva::Prompt.create!(
name: "Sentiment Analysis",
version: 1,
system_prompt: "You are an expert at analyzing text and returning the sentiment.",
user_prompt: "Please analyze the following text and return the sentiment as Positive, Negative, or Neutral.\n\n{{TEXT}}",
metadata: { model: "gpt-4", temperature: 0.5 }
)
experiment = Leva::Experiment.create!(
name: "Sentiment Analysis with LLM",
dataset: dataset,
prompt: prompt
)
run = SentimentRun.new
evals = [SentimentAccuracyEval.new, SentimentF1Eval.new]
Leva.run_evaluation(experiment: experiment, run: run, evals: evals)After the experiments are complete, analyze the results:
experiment.evaluation_results.group_by(&:evaluator_class).each do |evaluator_class, results|
average_score = results.average(&:score)
puts "#{evaluator_class.capitalize} Average Score: #{average_score}"
endEnsure you set up any required API keys or other configurations in your Rails credentials or environment variables.
-
Leva: Handles the process of running experiments. -
Leva::BaseRun: Base class for run implementations. -
Leva::BaseEval: Base class for eval implementations.
-
Leva::Dataset: Represents a collection of data to be evaluated. -
Leva::DatasetRecord: Represents individual records within a dataset. -
Leva::Experiment: Represents a single run of an evaluation on a dataset. -
Leva::RunnerResult: Stores the results of each run execution. -
Leva::EvaluationResult: Stores the results of each evaluation. -
Leva::Prompt: Represents a prompt for an LLM.
Bug reports and pull requests are welcome on GitHub at https://github.com/kieranklaassen/leva.
The gem is available as open source under the terms of the MIT License.
- [x] Parallelize evaluation
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for leva
Similar Open Source Tools
leva
Leva is a Ruby on Rails framework designed for evaluating Language Models (LLMs) using ActiveRecord datasets on production models. It offers a flexible structure for creating experiments, managing datasets, and implementing various evaluation logic on production data with security in mind. Users can set up datasets, implement runs and evals, run experiments with different configurations, use prompts, and analyze results. Leva's components include classes like Leva, Leva::BaseRun, and Leva::BaseEval, as well as models like Leva::Dataset, Leva::DatasetRecord, Leva::Experiment, Leva::RunnerResult, Leva::EvaluationResult, and Leva::Prompt. The tool aims to provide a comprehensive solution for evaluating language models efficiently and securely.
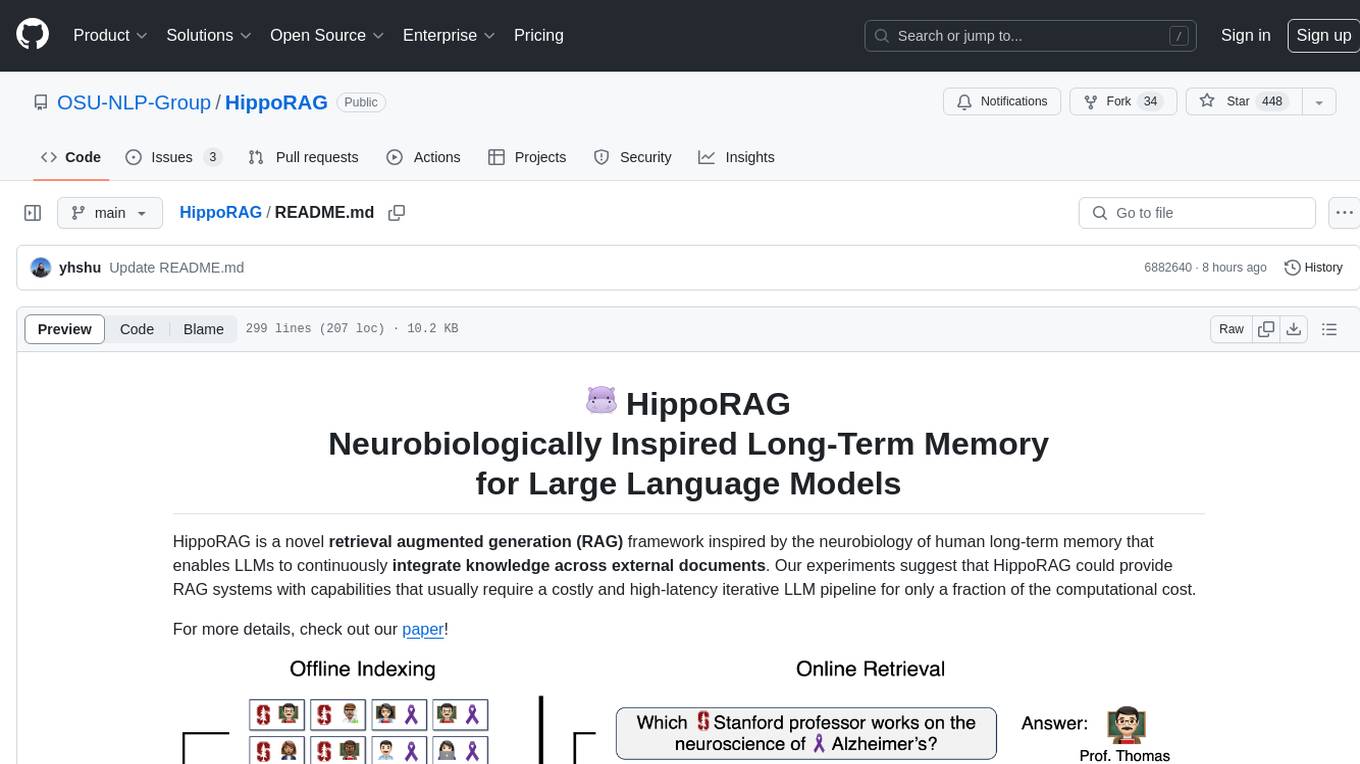
HippoRAG
HippoRAG is a novel retrieval augmented generation (RAG) framework inspired by the neurobiology of human long-term memory that enables Large Language Models (LLMs) to continuously integrate knowledge across external documents. It provides RAG systems with capabilities that usually require a costly and high-latency iterative LLM pipeline for only a fraction of the computational cost. The tool facilitates setting up retrieval corpus, indexing, and retrieval processes for LLMs, offering flexibility in choosing different online LLM APIs or offline LLM deployments through LangChain integration. Users can run retrieval on pre-defined queries or integrate directly with the HippoRAG API. The tool also supports reproducibility of experiments and provides data, baselines, and hyperparameter tuning scripts for research purposes.
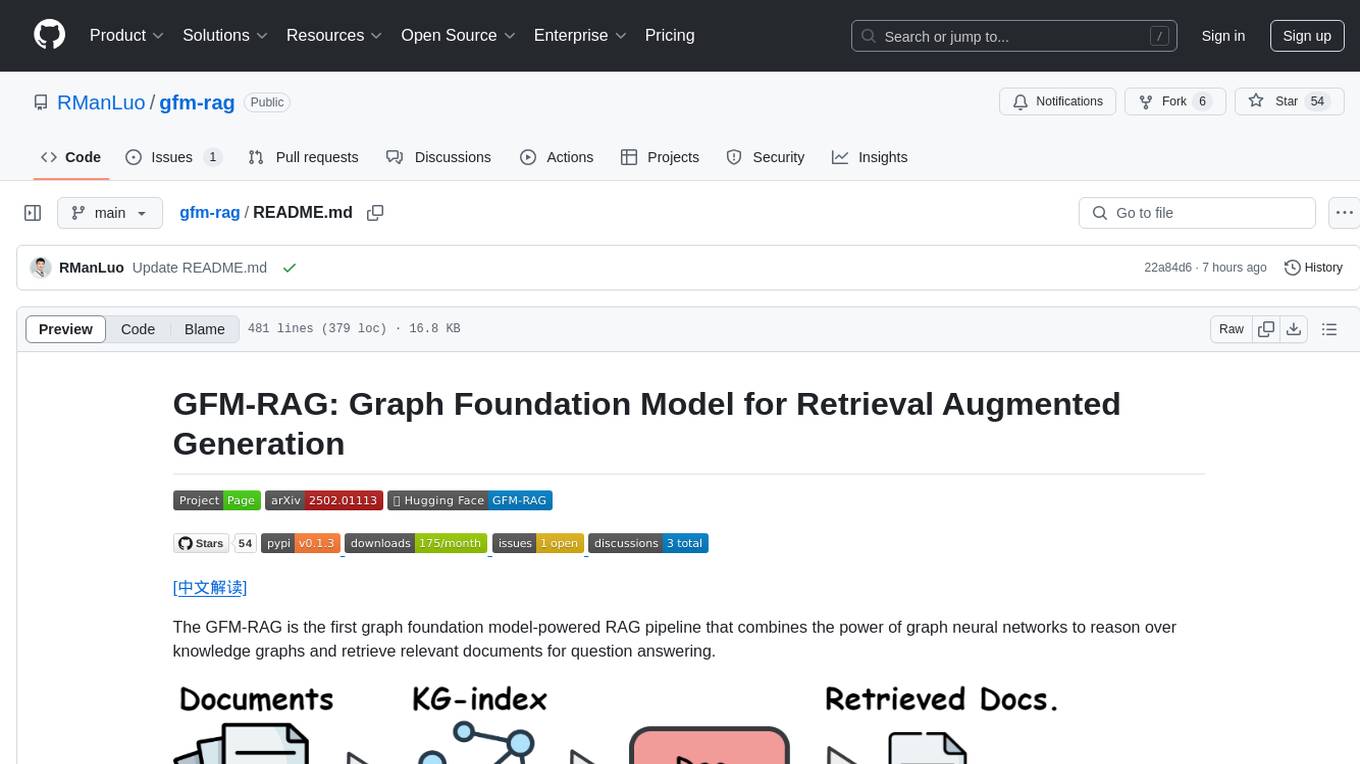
gfm-rag
The GFM-RAG is a graph foundation model-powered pipeline that combines graph neural networks to reason over knowledge graphs and retrieve relevant documents for question answering. It features a knowledge graph index, efficiency in multi-hop reasoning, generalizability to unseen datasets, transferability for fine-tuning, compatibility with agent-based frameworks, and interpretability of reasoning paths. The tool can be used for conducting retrieval and question answering tasks using pre-trained models or fine-tuning on custom datasets.

AirGym
AirGym is an open source Python quadrotor simulator based on IsaacGym, providing a high-fidelity dynamics and Deep Reinforcement Learning (DRL) framework for quadrotor robot learning research. It offers a lightweight and customizable platform with strict alignment with PX4 logic, multiple control modes, and Sim-to-Real toolkits. Users can perform tasks such as Hovering, Balloon, Tracking, Avoid, and Planning, with the ability to create customized environments and tasks. The tool also supports training from scratch, visual encoding approaches, playing and testing of trained models, and customization of new tasks and assets.
LLMDebugger
This repository contains the code and dataset for LDB, a novel debugging framework that enables Large Language Models (LLMs) to refine their generated programs by tracking the values of intermediate variables throughout the runtime execution. LDB segments programs into basic blocks, allowing LLMs to concentrate on simpler code units, verify correctness block by block, and pinpoint errors efficiently. The tool provides APIs for debugging and generating code with debugging messages, mimicking how human developers debug programs.

Lumos
Lumos is a Chrome extension powered by a local LLM co-pilot for browsing the web. It allows users to summarize long threads, news articles, and technical documentation. Users can ask questions about reviews and product pages. The tool requires a local Ollama server for LLM inference and embedding database. Lumos supports multimodal models and file attachments for processing text and image content. It also provides options to customize models, hosts, and content parsers. The extension can be easily accessed through keyboard shortcuts and offers tools for automatic invocation based on prompts.

syncode
SynCode is a novel framework for the grammar-guided generation of Large Language Models (LLMs) that ensures syntactically valid output based on a Context-Free Grammar (CFG). It supports various programming languages like Python, Go, SQL, Math, JSON, and more. Users can define custom grammars using EBNF syntax. SynCode offers fast generation, seamless integration with HuggingFace Language Models, and the ability to sample with different decoding strategies.

syncode
SynCode is a novel framework for the grammar-guided generation of Large Language Models (LLMs) that ensures syntactically valid output with respect to defined Context-Free Grammar (CFG) rules. It supports general-purpose programming languages like Python, Go, SQL, JSON, and more, allowing users to define custom grammars using EBNF syntax. The tool compares favorably to other constrained decoders and offers features like fast grammar-guided generation, compatibility with HuggingFace Language Models, and the ability to work with various decoding strategies.
parsera
Parsera is a lightweight Python library designed for scraping websites using LLMs. It offers simplicity and efficiency by minimizing token usage, enhancing speed, and reducing costs. Users can easily set up and run the tool to extract specific elements from web pages, generating JSON output with relevant data. Additionally, Parsera supports integration with various chat models, such as Azure, expanding its functionality and customization options for web scraping tasks.

req_llm
ReqLLM is a Req-based library for LLM interactions, offering a unified interface to AI providers through a plugin-based architecture. It brings composability and middleware advantages to LLM interactions, with features like auto-synced providers/models, typed data structures, ergonomic helpers, streaming capabilities, usage & cost extraction, and a plugin-based provider system. Users can easily generate text, structured data, embeddings, and track usage costs. The tool supports various AI providers like Anthropic, OpenAI, Groq, Google, and xAI, and allows for easy addition of new providers. ReqLLM also provides API key management, detailed documentation, and a roadmap for future enhancements.

instructor
Instructor is a popular Python library for managing structured outputs from large language models (LLMs). It offers a user-friendly API for validation, retries, and streaming responses. With support for various LLM providers and multiple languages, Instructor simplifies working with LLM outputs. The library includes features like response models, retry management, validation, streaming support, and flexible backends. It also provides hooks for logging and monitoring LLM interactions, and supports integration with Anthropic, Cohere, Gemini, Litellm, and Google AI models. Instructor facilitates tasks such as extracting user data from natural language, creating fine-tuned models, managing uploaded files, and monitoring usage of OpenAI models.
claim-ai-phone-bot
AI-powered call center solution with Azure and OpenAI GPT. The bot can answer calls, understand the customer's request, and provide relevant information or assistance. It can also create a todo list of tasks to complete the claim, and send a report after the call. The bot is customizable, and can be used in multiple languages.
call-center-ai
Call Center AI is an AI-powered call center solution that leverages Azure and OpenAI GPT. It is a proof of concept demonstrating the integration of Azure Communication Services, Azure Cognitive Services, and Azure OpenAI to build an automated call center solution. The project showcases features like accessing claims on a public website, customer conversation history, language change during conversation, bot interaction via phone number, multiple voice tones, lexicon understanding, todo list creation, customizable prompts, content filtering, GPT-4 Turbo for customer requests, specific data schema for claims, documentation database access, SMS report sending, conversation resumption, and more. The system architecture includes components like RAG AI Search, SMS gateway, call gateway, moderation, Cosmos DB, event broker, GPT-4 Turbo, Redis cache, translation service, and more. The tool can be deployed remotely using GitHub Actions and locally with prerequisites like Azure environment setup, configuration file creation, and resource hosting. Advanced usage includes custom training data with AI Search, prompt customization, language customization, moderation level customization, claim data schema customization, OpenAI compatible model usage for the LLM, and Twilio integration for SMS.
golf
Golf is a simple command-line tool for calculating the distance between two geographic coordinates. It uses the Haversine formula to accurately determine the distance between two points on the Earth's surface. This tool is useful for developers working on location-based applications or projects that require distance calculations. With Golf, users can easily input latitude and longitude coordinates and get the precise distance in kilometers or miles. The tool is lightweight, easy to use, and can be integrated into various programming workflows.
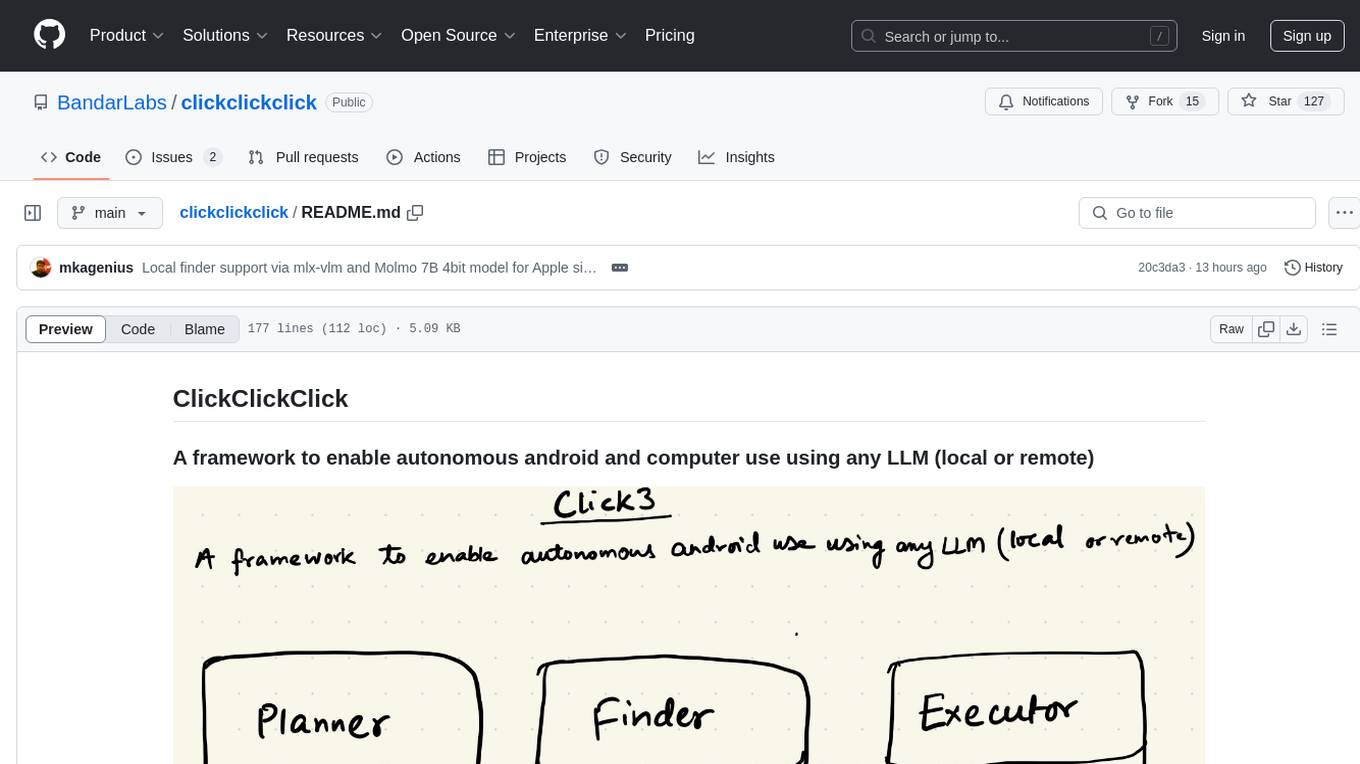
clickclickclick
ClickClickClick is a framework designed to enable autonomous Android and computer use using various LLM models, both locally and remotely. It supports tasks such as drafting emails, opening browsers, and starting games, with current support for local models via Ollama, Gemini, and GPT 4o. The tool is highly experimental and evolving, with the best results achieved using specific model combinations. Users need prerequisites like `adb` installation and USB debugging enabled on Android phones. The tool can be installed via cloning the repository, setting up a virtual environment, and installing dependencies. It can be used as a CLI tool or script, allowing users to configure planner and finder models for different tasks. Additionally, it can be used as an API to execute tasks based on provided prompts, platform, and models.
gemini-srt-translator
Gemini SRT Translator is a tool that utilizes Google Generative AI to provide accurate and efficient translations for subtitle files. Users can customize translation settings, such as model name and batch size, and list available models from the Gemini API. The tool requires a free API key from Google AI Studio for setup and offers features like translating subtitles to a specified target language and resuming partial translations. Users can further customize translation settings with optional parameters like gemini_api_key2, output_file, start_line, model_name, batch_size, and more.
For similar tasks

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.

edsl
The Expected Parrot Domain-Specific Language (EDSL) package enables users to conduct computational social science and market research with AI. It facilitates designing surveys and experiments, simulating responses using large language models, and performing data labeling and other research tasks. EDSL includes built-in methods for analyzing, visualizing, and sharing research results. It is compatible with Python 3.9 - 3.11 and requires API keys for LLMs stored in a `.env` file.

fast-stable-diffusion
Fast-stable-diffusion is a project that offers notebooks for RunPod, Paperspace, and Colab Pro adaptations with AUTOMATIC1111 Webui and Dreambooth. It provides tools for running and implementing Dreambooth, a stable diffusion project. The project includes implementations by XavierXiao and is sponsored by Runpod, Paperspace, and Colab Pro.

RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.

LLM-LieDetector
This repository contains code for reproducing experiments on lie detection in black-box LLMs by asking unrelated questions. It includes Q/A datasets, prompts, and fine-tuning datasets for generating lies with language models. The lie detectors rely on asking binary 'elicitation questions' to diagnose whether the model has lied. The code covers generating lies from language models, training and testing lie detectors, and generalization experiments. It requires access to GPUs and OpenAI API calls for running experiments with open-source models. Results are stored in the repository for reproducibility.

bigcodebench
BigCodeBench is an easy-to-use benchmark for code generation with practical and challenging programming tasks. It aims to evaluate the true programming capabilities of large language models (LLMs) in a more realistic setting. The benchmark is designed for HumanEval-like function-level code generation tasks, but with much more complex instructions and diverse function calls. BigCodeBench focuses on the evaluation of LLM4Code with diverse function calls and complex instructions, providing precise evaluation & ranking and pre-generated samples to accelerate code intelligence research. It inherits the design of the EvalPlus framework but differs in terms of execution environment and test evaluation.
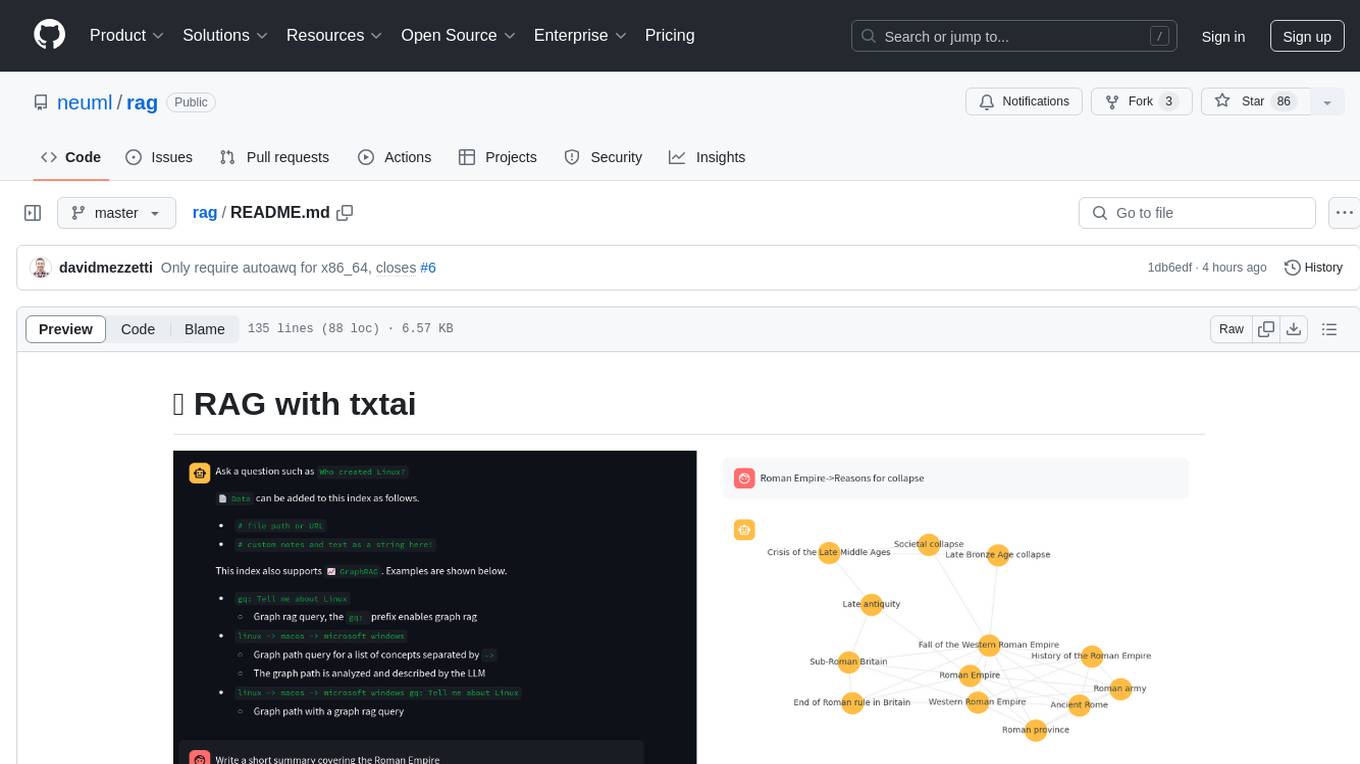
rag
RAG with txtai is a Retrieval Augmented Generation (RAG) Streamlit application that helps generate factually correct content by limiting the context in which a Large Language Model (LLM) can generate answers. It supports two categories of RAG: Vector RAG, where context is supplied via a vector search query, and Graph RAG, where context is supplied via a graph path traversal query. The application allows users to run queries, add data to the index, and configure various parameters to control its behavior.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.