
savvy-cli
Create, share, and run runbooks from your terminal.
Stars: 246
Savvy is a CLI tool that simplifies the creation, sharing, and running of runbooks directly from the terminal. It can generate runbooks using AI or commands provided by the user. The tool allows users to easily create runbooks for various tasks, share them, and run them automatically. Savvy also provides features like explaining commands and troubleshooting errors in a user-friendly manner. It supports creating runbooks from shell history, sharing runbooks, and running runbooks seamlessly from the terminal.
README:
Savvy is the easiest way to create, share and run runbooks from your terminal.
Savvy's CLI generates runbooks with AI or from commands you provide.
curl -fsSL https://install.getsavvy.so | shUse savvy ask to generate entire runbooks or a single command using natural language.
Just run savvy ask and provide a prompt.
Any one can use it, there's no need to signup for an account or provide a credit card.
- Ask Savvy to create a runbook for publishing a new go module.

- Ask Savvy to help you with a tricky sequence of shell commands.

Use savvy record or savvy record history to create a runbook using commands you provide.
You don't have to change anything about your shell or aliases, savvy auto expands all aliases to make sure your runbook runs reliably on any machine.
Use savvy record history to go back in time and create a runbooks by selecting just the commands you want.
Savvy will never execute any command you select.

Runbooks are private by default, but you can share them using a public or unlisted link from Savvy's dashboard.
You can also export runbooks to markdown and paste them in your existing docs.
savvy record starts a new shell and all commands in this shell are recorded and sent to an LLM to generate a runbook.

[!NOTE] Creating a runbook with savvy record requires you to signup for a free account.
Use savvy run to search and run runbooks right from your terminal.
Savvy automatically fills in the next command to execute. Just press enter to run it.

Parameterizing runbooks is very easy with Savvy.
Replace hardcoded values with <parameters> from the dashboard for any step. Savvy takes care of the rest.
savvy run automatically detects any <parameters> and prompts users to fill in the value only once per parameter.


Check our docs for more details on runbook parameterization
Not sure what a particular command or flag does? Don't want to research an opaque error message? then savvy explain is for you.
Savvy explain generates a simple and easy to understand explanation for any command or error message before you can say RTFM!
- Use
savvy explainto understand everything that goes into parsing a x509 certificate with openssl

- Dive into an error message and learn troubleshooting next steps.

- How do I Install Savvy?
curl -fsSL https://install.getsavvy.so | sh- How do I uninstall Savvy?
rm -rf ~/.savvy
rm -rf ~/.config/savvy
- How do I upgrade Savvy?
Run savvy upgrade to get the latest version of the CLI.
- How do I login?
Run savvy login to start the login flow.
- What shells does Savvy support?
Savvy supports zsh and bash. Please create an issue if you'd like us to support your favorite shell.
- Does Savvy work on Windows?
Not yet.
- I'm stuck. How do I get help?
If you need assistance or have questions:
- Create an issue on our GitHub repository.
- Join our Discord server
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for savvy-cli
Similar Open Source Tools
savvy-cli
Savvy is a CLI tool that simplifies the creation, sharing, and running of runbooks directly from the terminal. It can generate runbooks using AI or commands provided by the user. The tool allows users to easily create runbooks for various tasks, share them, and run them automatically. Savvy also provides features like explaining commands and troubleshooting errors in a user-friendly manner. It supports creating runbooks from shell history, sharing runbooks, and running runbooks seamlessly from the terminal.

lovelaice
Lovelaice is an AI-powered assistant for your terminal and editor. It can run bash commands, search the Internet, answer general and technical questions, complete text files, chat casually, execute code in various languages, and more. Lovelaice is configurable with API keys and LLM models, and can be used for a wide range of tasks requiring bash commands or coding assistance. It is designed to be versatile, interactive, and helpful for daily tasks and projects.
polis
Polis is an AI powered sentiment gathering platform that offers a more organic approach than surveys and requires less effort than focus groups. It provides a comprehensive wiki, main deployment at https://pol.is, discussions, issue tracking, and project board for users. Polis can be set up using Docker infrastructure and offers various commands for building and running containers. Users can test their instance, update the system, and deploy Polis for production. The tool also provides developer conveniences for code reloading, type checking, and database connections. Additionally, Polis supports end-to-end browser testing using Cypress and offers troubleshooting tips for common Docker and npm issues.

ultravox
Ultravox is a fast multimodal Language Model (LLM) that can understand both text and human speech in real-time without the need for a separate Audio Speech Recognition (ASR) stage. By extending Meta's Llama 3 model with a multimodal projector, Ultravox converts audio directly into a high-dimensional space used by Llama 3, enabling quick responses and potential understanding of paralinguistic cues like timing and emotion in human speech. The current version (v0.3) has impressive speed metrics and aims for further enhancements. Ultravox currently converts audio to streaming text and plans to emit speech tokens for direct audio conversion. The tool is open for collaboration to enhance this functionality.
AI-Horde-Worker
AI-Horde-Worker is a repository containing the original reference implementation for a worker that turns your graphics card(s) into a worker for the AI Horde. It allows users to generate or alchemize images for others. The repository provides instructions for setting up the worker on Windows and Linux, updating the worker code, running with multiple GPUs, and stopping the worker. Users can configure the worker using a WebUI to connect to the horde with their username and API key. The repository also includes information on model usage and running the Docker container with specified environment variables.
SolidGPT
SolidGPT is an AI searching assistant for developers that helps with code and workspace semantic search. It provides features such as talking to your codebase, asking questions about your codebase, semantic search and summary in Notion, and getting questions answered from your codebase and Notion without context switching. The tool ensures data safety by not collecting users' data and uses the OpenAI series model API.
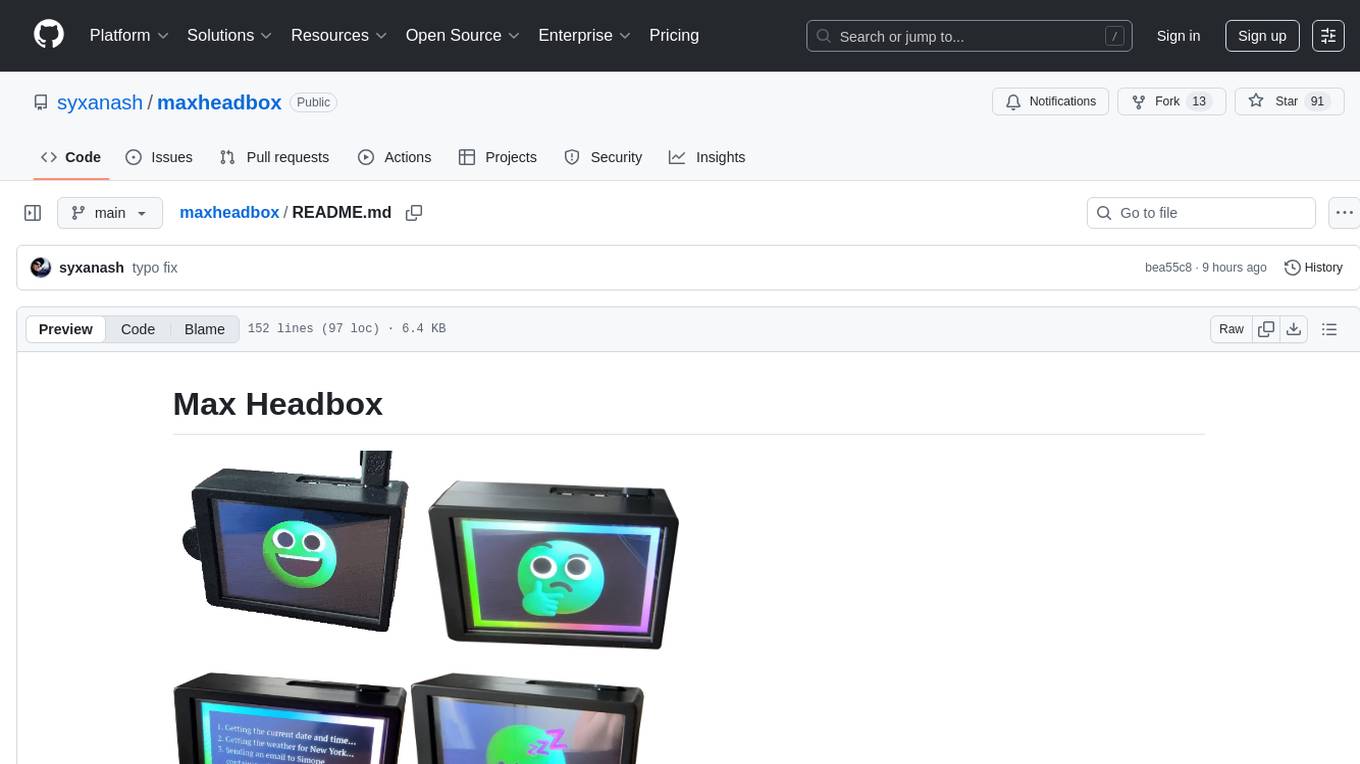
maxheadbox
Max Headbox is an open-source voice-activated LLM Agent designed to run on a Raspberry Pi. It can be configured to execute a variety of tools and perform actions. The project requires specific hardware and software setups, and provides detailed instructions for installation, configuration, and usage. Users can create custom tools by making JavaScript modules and backend API handlers. The project acknowledges the use of various open-source projects and resources in its development.
Discord-AI-Selfbot
Discord-AI-Selfbot is a Python-based Discord selfbot that uses the `discord.py-self` library to automatically respond to messages mentioning its trigger word using Groq API's Llama-3 model. It functions as a normal Discord bot on a real Discord account, enabling interactions in DMs, servers, and group chats without needing to invite a bot. The selfbot comes with features like custom AI instructions, free LLM model usage, mention and reply recognition, message handling, channel-specific responses, and a psychoanalysis command to analyze user messages for insights on personality.
AlwaysReddy
AlwaysReddy is a simple LLM assistant with no UI that you interact with entirely using hotkeys. It can easily read from or write to your clipboard, and voice chat with you via TTS and STT. Here are some of the things you can use AlwaysReddy for: - Explain a new concept to AlwaysReddy and have it save the concept (in roughly your words) into a note. - Ask AlwaysReddy "What is X called?" when you know how to roughly describe something but can't remember what it is called. - Have AlwaysReddy proofread the text in your clipboard before you send it. - Ask AlwaysReddy "From the comments in my clipboard, what do the r/LocalLLaMA users think of X?" - Quickly list what you have done today and get AlwaysReddy to write a journal entry to your clipboard before you shutdown the computer for the day.
openui
OpenUI is a tool designed to simplify the process of building UI components by allowing users to describe UI using their imagination and see it rendered live. It supports converting HTML to React, Svelte, Web Components, etc. The tool is open source and aims to make UI development fun, fast, and flexible. It integrates with various AI services like OpenAI, Groq, Gemini, Anthropic, Cohere, and Mistral, providing users with the flexibility to use different models. OpenUI also supports LiteLLM for connecting to various LLM services and allows users to create custom proxy configs. The tool can be run locally using Docker or Python, and it offers a development environment for quick setup and testing.
WebCraftifyAI
WebCraftifyAI is a software aid that makes it easy to create and build web pages and content. It is designed to be user-friendly and accessible to people of all skill levels. With WebCraftifyAI, you can quickly and easily create professional-looking websites without having to learn complex coding or design skills.
CLI
Bito CLI provides a command line interface to the Bito AI chat functionality, allowing users to interact with the AI through commands. It supports complex automation and workflows, with features like long prompts and slash commands. Users can install Bito CLI on Mac, Linux, and Windows systems using various methods. The tool also offers configuration options for AI model type, access key management, and output language customization. Bito CLI is designed to enhance user experience in querying AI models and automating tasks through the command line interface.

dataline
DataLine is an AI-driven data analysis and visualization tool designed for technical and non-technical users to explore data quickly. It offers privacy-focused data storage on the user's device, supports various data sources, generates charts, executes queries, and facilitates report building. The tool aims to speed up data analysis tasks for businesses and individuals by providing a user-friendly interface and natural language querying capabilities.
claude.vim
Claude.vim is a Vim plugin that integrates Claude, an AI pair programmer, into your Vim workflow. It allows you to chat with Claude about what to build or how to debug problems, and Claude offers opinions, proposes modifications, or even writes code. The plugin provides a chat/instruction-centric interface optimized for human collaboration, with killer features like access to chat history and vimdiff interface. It can refactor code, modify or extend selected pieces of code, execute complex tasks by reading documentation, cloning git repositories, and more. Note that it is early alpha software and expected to rapidly evolve.
ChatGPT-OpenAI-Smart-Speaker
ChatGPT Smart Speaker is a project that enables speech recognition and text-to-speech functionalities using OpenAI and Google Speech Recognition. It provides scripts for running on PC/Mac and Raspberry Pi, allowing users to interact with a smart speaker setup. The project includes detailed instructions for setting up the required hardware and software dependencies, along with customization options for the OpenAI model engine, language settings, and response randomness control. The Raspberry Pi setup involves utilizing the ReSpeaker hardware for voice feedback and light shows. The project aims to offer an advanced smart speaker experience with features like wake word detection and response generation using AI models.
create-tsi
Create TSI is a generative AI RAG toolkit that simplifies the process of creating AI Applications using LlamaIndex with low code. The toolkit leverages LLMs hosted by T-Systems on Open Telekom Cloud to generate bots, write agents, and customize them for specific use cases. It provides a Next.js-powered front-end for a chat interface, a Python FastAPI backend powered by llama-index package, and the ability to ingest and index user-supplied data for answering questions.
For similar tasks
savvy-cli
Savvy is a CLI tool that simplifies the creation, sharing, and running of runbooks directly from the terminal. It can generate runbooks using AI or commands provided by the user. The tool allows users to easily create runbooks for various tasks, share them, and run them automatically. Savvy also provides features like explaining commands and troubleshooting errors in a user-friendly manner. It supports creating runbooks from shell history, sharing runbooks, and running runbooks seamlessly from the terminal.
For similar jobs

AirGo
AirGo is a front and rear end separation, multi user, multi protocol proxy service management system, simple and easy to use. It supports vless, vmess, shadowsocks, and hysteria2.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

llm-code-interpreter
The 'llm-code-interpreter' repository is a deprecated plugin that provides a code interpreter on steroids for ChatGPT by E2B. It gives ChatGPT access to a sandboxed cloud environment with capabilities like running any code, accessing Linux OS, installing programs, using filesystem, running processes, and accessing the internet. The plugin exposes commands to run shell commands, read files, and write files, enabling various possibilities such as running different languages, installing programs, starting servers, deploying websites, and more. It is powered by the E2B API and is designed for agents to freely experiment within a sandboxed environment.

pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.

learn-generative-ai
Learn Cloud Applied Generative AI Engineering (GenEng) is a course focusing on the application of generative AI technologies in various industries. The course covers topics such as the economic impact of generative AI, the role of developers in adopting and integrating generative AI technologies, and the future trends in generative AI. Students will learn about tools like OpenAI API, LangChain, and Pinecone, and how to build and deploy Large Language Models (LLMs) for different applications. The course also explores the convergence of generative AI with Web 3.0 and its potential implications for decentralized intelligence.

gcloud-aio
This repository contains shared codebase for two projects: gcloud-aio and gcloud-rest. gcloud-aio is built for Python 3's asyncio, while gcloud-rest is a threadsafe requests-based implementation. It provides clients for Google Cloud services like Auth, BigQuery, Datastore, KMS, PubSub, Storage, and Task Queue. Users can install the library using pip and refer to the documentation for usage details. Developers can contribute to the project by following the contribution guide.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.

aiges
AIGES is a core component of the Athena Serving Framework, designed as a universal encapsulation tool for AI developers to deploy AI algorithm models and engines quickly. By integrating AIGES, you can deploy AI algorithm models and engines rapidly and host them on the Athena Serving Framework, utilizing supporting auxiliary systems for networking, distribution strategies, data processing, etc. The Athena Serving Framework aims to accelerate the cloud service of AI algorithm models and engines, providing multiple guarantees for cloud service stability through cloud-native architecture. You can efficiently and securely deploy, upgrade, scale, operate, and monitor models and engines without focusing on underlying infrastructure and service-related development, governance, and operations.