
gguf-tools
GGUF implementation in C as a library and a tools CLI program
Stars: 249
GGUF tools is a library designed to manipulate GGUF files commonly used in machine learning projects. The main goal of this library is to provide accessible code that documents GGUF files for the llama.cpp project. The utility implements subcommands to show detailed info about GGUF files, compare two LLMs, inspect tensor weights, and extract models from Mixtral 7B MoE. The library is under active development with well-commented code and a simple API. However, it has limitations in handling quantization formats.
README:
This is a work in progress library to manipulate GGUF files. While the library aims to be useful, one of the main goals is to provide an accessible code base that as a side effect documents the GGUF files used by the awesome llama.cpp project: GGUF files are becoming increasingly more used and central in the local machine learning scene, so to have multiple implementations of parsers and files generators may be useful.
The program gguf-tools uses the library to implement both useful and useless stuff, to show the library usage in the real world. For now the utility implements the following subcommands:
shows detailed info about the GGUF file. This will include all the key-value pairs, including arrays, and detailed tensors informations. Tensor offsets will be relative to the start of the file (so they are actually absolute offsets), not the start of the data section like in the GGUF format.
Example output:
./gguf-tools show models/phi-2.Q8_0.gguf | head -20 :main*: ??
models/phi-2.Q8_0.gguf (ver 3): 20 key-value pairs, 325 tensors
general.architecture: [string] phi2
general.name: [string] Phi2
phi2.context_length: [uint32] 2048
phi2.embedding_length: [uint32] 2560
phi2.feed_forward_length: [uint32] 10240
phi2.block_count: [uint32] 32
phi2.attention.head_count: [uint32] 32
phi2.attention.head_count_kv: [uint32] 32
phi2.attention.layer_norm_epsilon: [float32] 0.000010
phi2.rope.dimension_count: [uint32] 32
general.file_type: [uint32] 7
tokenizer.ggml.add_bos_token: [bool] false
tokenizer.ggml.model: [string] gpt2
tokenizer.ggml.tokens: [array] [!, ", #, $, %, &, ', (, ), *, +, ,, -, ., /, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, :, ;, <, =, >, ... 51170 more items of 51200]
... many more key-value pairs ...
q8_0 tensor token_embd.weight @1806176, 131072000 weights, dims [2560,51200], 139264000 bytes
f32 tensor blk.0.attn_norm.bias @141070176, 2560 weights, dims [2560], 10240 bytes
f32 tensor blk.0.attn_norm.weight @141080416, 2560 weights, dims [2560], 10240 bytes
f32 tensor blk.0.attn_qkv.bias @141090656, 7680 weights, dims [7680], 30720 bytes
q8_0 tensor blk.0.attn_qkv.weight @141121376, 19660800 weights, dims [2560,7680], 20889600 bytes
f32 tensor blk.0.attn_output.bias @162010976, 2560 weights, dims [2560], 10240 bytes
q8_0 tensor blk.0.attn_output.weight @162021216, 6553600 weights, dims [2560,2560], 6963200 bytes
f32 tensor blk.0.ffn_up.bias @168984416, 10240 weights, dims [10240], 40960 bytes
... many more tensors ...
This tool is useful to understand if two LLMs (or other models distributed as GGUF files) are related, for instance if one is the finetune of another, or if both are fine-tuned from the same parent model.
For each matching tensor (same name and parameters count), the command computes the average weights difference (in percentage, so that a random distribution in the interval -N, +N would be on average 100% different than another random distribution in the same interval). This is useful to see if a model is a finetune of another model, how much it was finetuned, which layers were frozen while finetuning and so forth. Note that because of quantization, even tensors that are functionally equivalent may have some small average difference.
Example output:
./gguf-tools compare mistral-7b-instruct-v0.2.Q8_0.gguf \
solar-10.7b-instruct-v1.0-uncensored.Q8_0.gguf
[token_embd.weight]: avg weights difference: 44.539944%
[blk.0.attn_q.weight]: avg weights difference: 48.717736%
[blk.0.attn_k.weight]: avg weights difference: 56.201885%
[blk.0.attn_v.weight]: avg weights difference: 47.087249%
[blk.0.attn_output.weight]: avg weights difference: 47.663048%
[blk.0.ffn_gate.weight]: avg weights difference: 37.508761%
[blk.0.ffn_up.weight]: avg weights difference: 39.061584%
[blk.0.ffn_down.weight]: avg weights difference: 39.632648%
...
Show all (if count is not specified, otherwise only the first count) weights values of the specified tensor. This is useful for low level stuff, like checking if quantization is working as expected, see the introduced error, model fingerprinting and so forth.
Extracts a 7B model out.gguf from Mixtral 7B MoE using the specified MoE ID for each layer (there are 32 digits in the sequence 652...).
Note that split-mixtral is quite useless as models obtained in this way will not perform any useful work. This is just an experiment and a non trivial task to show how to use the library. Likely it will be removed soon, once I have more interesting and useful examples to show, like models merging.
For now the only documentation is the implementation itself: see the gguf-tools.c for usage information. This may change later, but for now the library is under active development.
The code is well commented, and the API so far is extremely simple to understand and use.
Many quantization formats are missing.
- Official GGUF specification, where the file layout and meta-data is described.
- Quantization formats used in quantized GGUF models.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for gguf-tools
Similar Open Source Tools
gguf-tools
GGUF tools is a library designed to manipulate GGUF files commonly used in machine learning projects. The main goal of this library is to provide accessible code that documents GGUF files for the llama.cpp project. The utility implements subcommands to show detailed info about GGUF files, compare two LLMs, inspect tensor weights, and extract models from Mixtral 7B MoE. The library is under active development with well-commented code and a simple API. However, it has limitations in handling quantization formats.

MiniCheck
MiniCheck is an efficient fact-checking tool designed to verify claims against grounding documents using large language models. It provides a sentence-level fact-checking model that can be used to evaluate the consistency of claims with the provided documents. MiniCheck offers different models, including Bespoke-MiniCheck-7B, which is the state-of-the-art and commercially usable. The tool enables users to fact-check multi-sentence claims by breaking them down into individual sentences for optimal performance. It also supports automatic prefix caching for faster inference when repeatedly fact-checking the same document with different claims.
Gemini
Gemini is an open-source model designed to handle multiple modalities such as text, audio, images, and videos. It utilizes a transformer architecture with special decoders for text and image generation. The model processes input sequences by transforming them into tokens and then decoding them to generate image outputs. Gemini differs from other models by directly feeding image embeddings into the transformer instead of using a visual transformer encoder. The model also includes a component called Codi for conditional generation. Gemini aims to effectively integrate image, audio, and video embeddings to enhance its performance.
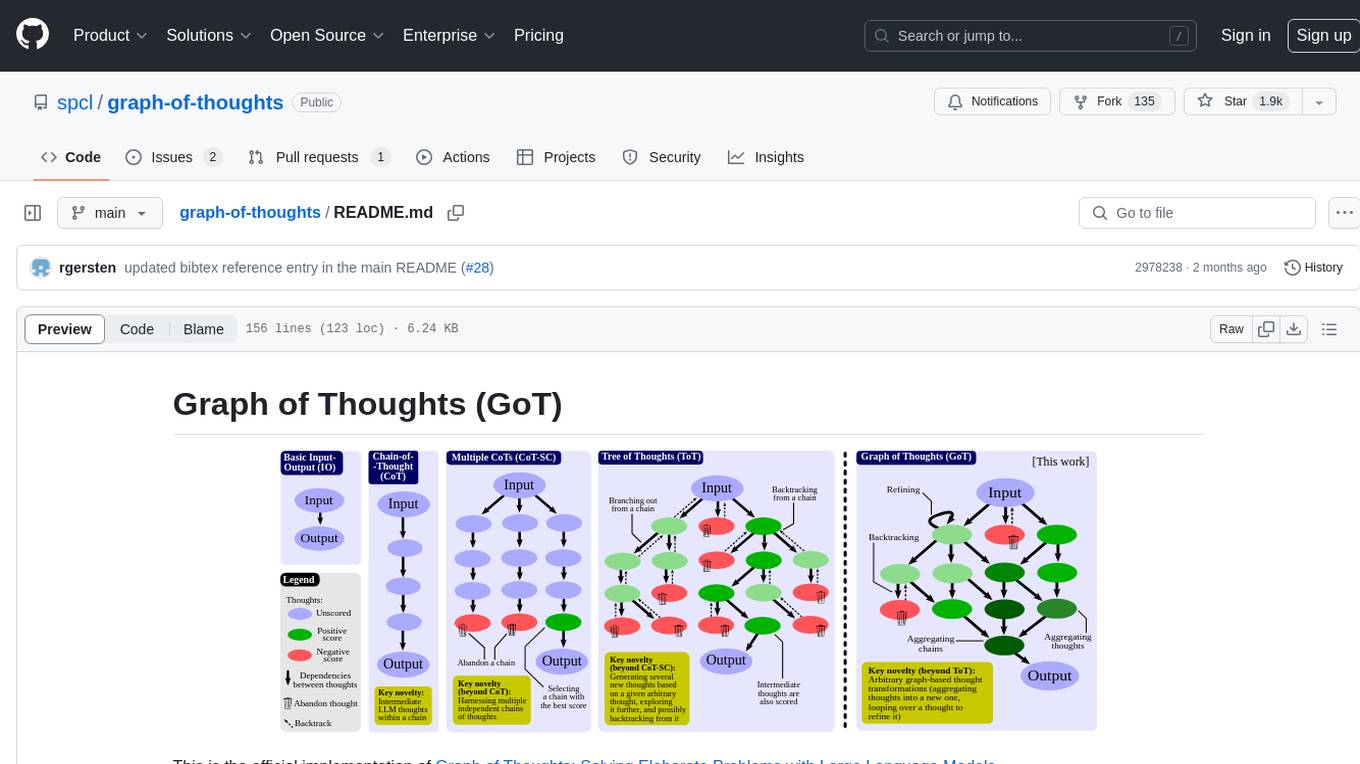
graph-of-thoughts
Graph of Thoughts (GoT) is an official implementation framework designed to solve complex problems by modeling them as a Graph of Operations (GoO) executed with a Large Language Model (LLM) engine. It offers flexibility to implement various approaches like CoT or ToT, allowing users to solve problems using the new GoT approach. The framework includes setup guides, quick start examples, documentation, and examples for users to understand and utilize the tool effectively.
parsee-core
Parsee AI is a high-level open source data extraction and structuring framework specialized for the extraction of data from a financial domain, but can be used for other use-cases as well. It aims to make the structuring of data from unstructured sources like PDFs, HTML files, and images as easy as possible. Parsee can be used locally in Python environments or through a hosted version for cloud-based jobs. It supports the extraction of tables, numbers, and other data elements, with the ability to create custom extraction templates and run jobs using different models.
audioseal
AudioSeal is a method for speech localized watermarking, designed with state-of-the-art robustness and detector speed. It jointly trains a generator to embed a watermark in audio and a detector to detect watermarked fragments in longer audios, even in the presence of editing. The tool achieves top-notch detection performance at the sample level, generates minimal alteration of signal quality, and is robust to various audio editing types. With a fast, single-pass detector, AudioSeal surpasses existing models in speed, making it ideal for large-scale and real-time applications.
DataFrame
DataFrame is a C++ analytical library designed for data analysis similar to libraries in Python and R. It allows you to slice, join, merge, group-by, and perform various statistical, summarization, financial, and ML algorithms on your data. DataFrame also includes a large collection of analytical algorithms in form of visitors, ranging from basic stats to more involved analysis. You can easily add your own algorithms as well. DataFrame employs extensive multithreading in almost all its APIs, making it suitable for analyzing large datasets. Key principles followed in the library include supporting any type without needing new code, avoiding pointer chasing, having all column data in contiguous memory space, minimizing space usage, avoiding data copying, using multi-threading judiciously, and not protecting the user against garbage in, garbage out.

semlib
Semlib is a Python library for building data processing and data analysis pipelines that leverage the power of large language models (LLMs). It provides functional programming primitives like map, reduce, sort, and filter, programmed with natural language descriptions. Semlib handles complexities such as prompting, parsing, concurrency control, caching, and cost tracking. The library breaks down sophisticated data processing tasks into simpler steps to improve quality, feasibility, latency, cost, security, and flexibility of data processing tasks.

llm-reasoners
LLM Reasoners is a library that enables LLMs to conduct complex reasoning, with advanced reasoning algorithms. It approaches multi-step reasoning as planning and searches for the optimal reasoning chain, which achieves the best balance of exploration vs exploitation with the idea of "World Model" and "Reward". Given any reasoning problem, simply define the reward function and an optional world model (explained below), and let LLM reasoners take care of the rest, including Reasoning Algorithms, Visualization, LLM calling, and more!

uncheatable_eval
Uncheatable Eval is a tool designed to assess the language modeling capabilities of LLMs on real-time, newly generated data from the internet. It aims to provide a reliable evaluation method that is immune to data leaks and cannot be gamed. The tool supports the evaluation of Hugging Face AutoModelForCausalLM models and RWKV models by calculating the sum of negative log probabilities on new texts from various sources such as recent papers on arXiv, new projects on GitHub, news articles, and more. Uncheatable Eval ensures that the evaluation data is not included in the training sets of publicly released models, thus offering a fair assessment of the models' performance.
Minic
Minic is a chess engine developed for learning about chess programming and modern C++. It is compatible with CECP and UCI protocols, making it usable in various software. Minic has evolved from a one-file code to a more classic C++ style, incorporating features like evaluation tuning, perft, tests, and more. It has integrated NNUE frameworks from Stockfish and Seer implementations to enhance its strength. Minic is currently ranked among the top engines with an Elo rating around 3400 at CCRL scale.
simple_GRPO
simple_GRPO is a very simple implementation of the GRPO algorithm for reproducing r1-like LLM thinking. It provides a codebase that supports saving GPU memory, understanding RL processes, trying various improvements like multi-answer generation, regrouping, penalty on KL, and parameter tuning. The project focuses on simplicity, performance, and core loss calculation based on Hugging Face's trl. It offers a straightforward setup with minimal dependencies and efficient training on multiple GPUs.

Quantus
Quantus is a toolkit designed for the evaluation of neural network explanations. It offers more than 30 metrics in 6 categories for eXplainable Artificial Intelligence (XAI) evaluation. The toolkit supports different data types (image, time-series, tabular, NLP) and models (PyTorch, TensorFlow). It provides built-in support for explanation methods like captum, tf-explain, and zennit. Quantus is under active development and aims to provide a comprehensive set of quantitative evaluation metrics for XAI methods.
neutone_sdk
The Neutone SDK is a tool designed for researchers to wrap their own audio models and run them in a DAW using the Neutone Plugin. It simplifies the process by allowing models to be built using PyTorch and minimal Python code, eliminating the need for extensive C++ knowledge. The SDK provides support for buffering inputs and outputs, sample rate conversion, and profiling tools for model performance testing. It also offers examples, notebooks, and a submission process for sharing models with the community.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package for time series forecasting with state-of-the-art network architectures. It offers a high-level API for training networks on pandas data frames and utilizes PyTorch Lightning for scalable training on GPUs and CPUs. The package aims to simplify time series forecasting with neural networks by providing a flexible API for professionals and default settings for beginners. It includes a timeseries dataset class, base model class, multiple neural network architectures, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. PyTorch Forecasting is built on pytorch-lightning for easy training on various hardware configurations.

minbpe
This repository contains a minimal, clean code implementation of the Byte Pair Encoding (BPE) algorithm, commonly used in LLM tokenization. The BPE algorithm is "byte-level" because it runs on UTF-8 encoded strings. This algorithm was popularized for LLMs by the GPT-2 paper and the associated GPT-2 code release from OpenAI. Sennrich et al. 2015 is cited as the original reference for the use of BPE in NLP applications. Today, all modern LLMs (e.g. GPT, Llama, Mistral) use this algorithm to train their tokenizers. There are two Tokenizers in this repository, both of which can perform the 3 primary functions of a Tokenizer: 1) train the tokenizer vocabulary and merges on a given text, 2) encode from text to tokens, 3) decode from tokens to text. The files of the repo are as follows: 1. minbpe/base.py: Implements the `Tokenizer` class, which is the base class. It contains the `train`, `encode`, and `decode` stubs, save/load functionality, and there are also a few common utility functions. This class is not meant to be used directly, but rather to be inherited from. 2. minbpe/basic.py: Implements the `BasicTokenizer`, the simplest implementation of the BPE algorithm that runs directly on text. 3. minbpe/regex.py: Implements the `RegexTokenizer` that further splits the input text by a regex pattern, which is a preprocessing stage that splits up the input text by categories (think: letters, numbers, punctuation) before tokenization. This ensures that no merges will happen across category boundaries. This was introduced in the GPT-2 paper and continues to be in use as of GPT-4. This class also handles special tokens, if any. 4. minbpe/gpt4.py: Implements the `GPT4Tokenizer`. This class is a light wrapper around the `RegexTokenizer` (2, above) that exactly reproduces the tokenization of GPT-4 in the tiktoken library. The wrapping handles some details around recovering the exact merges in the tokenizer, and the handling of some unfortunate (and likely historical?) 1-byte token permutations. Finally, the script train.py trains the two major tokenizers on the input text tests/taylorswift.txt (this is the Wikipedia entry for her kek) and saves the vocab to disk for visualization. This script runs in about 25 seconds on my (M1) MacBook. All of the files above are very short and thoroughly commented, and also contain a usage example on the bottom of the file.
For similar tasks
gguf-tools
GGUF tools is a library designed to manipulate GGUF files commonly used in machine learning projects. The main goal of this library is to provide accessible code that documents GGUF files for the llama.cpp project. The utility implements subcommands to show detailed info about GGUF files, compare two LLMs, inspect tensor weights, and extract models from Mixtral 7B MoE. The library is under active development with well-commented code and a simple API. However, it has limitations in handling quantization formats.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!
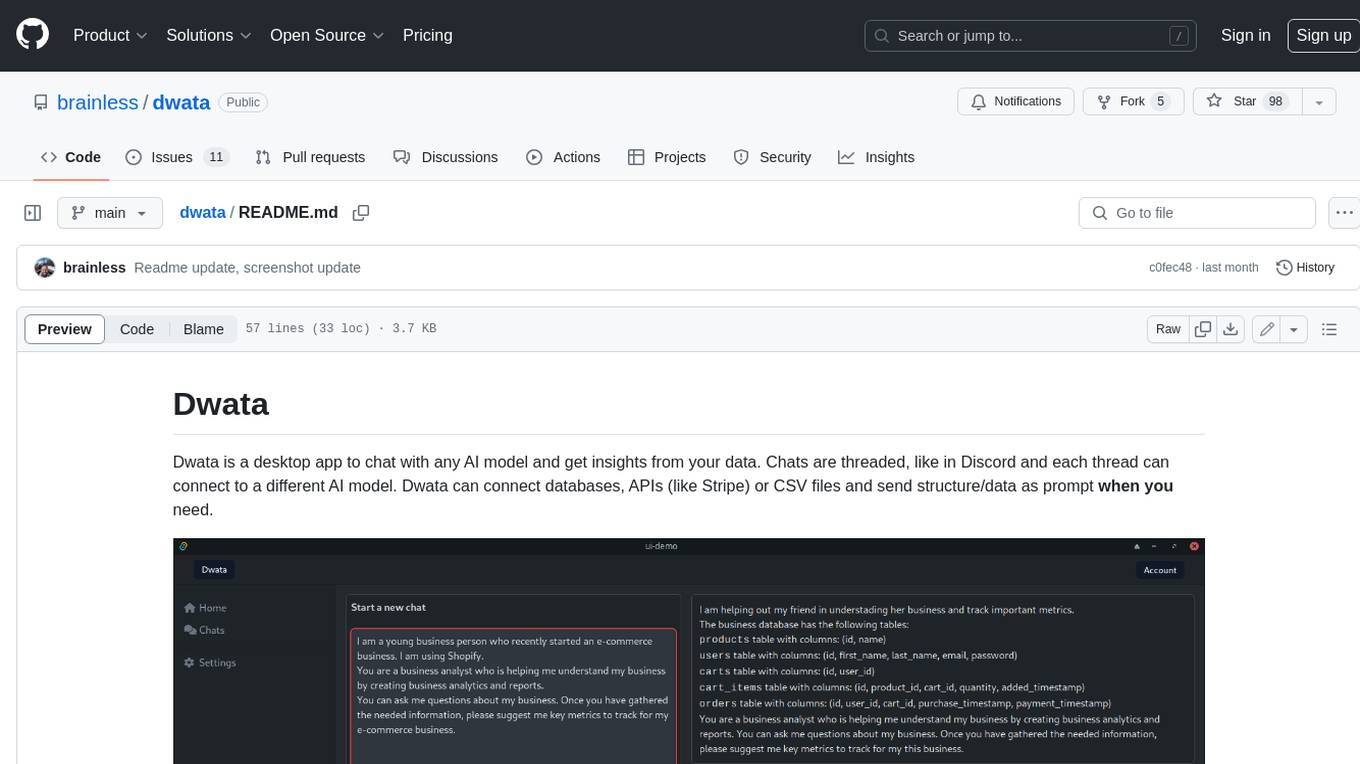
dwata
Dwata is a desktop application that allows users to chat with any AI model and gain insights from their data. Chats are organized into threads, similar to Discord, with each thread connecting to a different AI model. Dwata can connect to databases, APIs (such as Stripe), or CSV files and send structured data as prompts when needed. The AI's response will often include SQL or Python code, which can be used to extract the desired insights. Dwata can validate AI-generated SQL to ensure that the tables and columns referenced are correct and can execute queries against the database from within the application. Python code (typically using Pandas) can also be executed from within Dwata, although this feature is still in development. Dwata supports a range of AI models, including OpenAI's GPT-4, GPT-4 Turbo, and GPT-3.5 Turbo; Groq's LLaMA2-70b and Mixtral-8x7b; Phind's Phind-34B and Phind-70B; Anthropic's Claude; and Ollama's Llama 2, Mistral, and Phi-2 Gemma. Dwata can compare chats from different models, allowing users to see the responses of multiple models to the same prompts. Dwata can connect to various data sources, including databases (PostgreSQL, MySQL, MongoDB), SaaS products (Stripe, Shopify), CSV files/folders, and email (IMAP). The desktop application does not collect any private or business data without the user's explicit consent.

ollama-grid-search
A Rust based tool to evaluate LLM models, prompts and model params. It automates the process of selecting the best model parameters, given an LLM model and a prompt, iterating over the possible combinations and letting the user visually inspect the results. The tool assumes the user has Ollama installed and serving endpoints, either in `localhost` or in a remote server. Key features include: * Automatically fetches models from local or remote Ollama servers * Iterates over different models and params to generate inferences * A/B test prompts on different models simultaneously * Allows multiple iterations for each combination of parameters * Makes synchronous inference calls to avoid spamming servers * Optionally outputs inference parameters and response metadata (inference time, tokens and tokens/s) * Refetching of individual inference calls * Model selection can be filtered by name * List experiments which can be downloaded in JSON format * Configurable inference timeout * Custom default parameters and system prompts can be defined in settings
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.
PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.