
halbot
Just another `ChatGPT` / `Gemini` / `Mistral (by ollama)` Telegram bob, which is simple design, easy to use, extendable and fun.
Stars: 103
halbot is a Telegram bot that uses ChatGPT, Gemini, Mistral, and other AI engines to provide a variety of services, including text generation, translation, summarization, and question answering. It is easy to use and extend, and it can be integrated into your own projects. halbot is open source and free to use.
README:
![]()
Just another Gemini / ChatGPT / Claude / Mistral (by ollama) Telegram bob, which is simple design, easy to use, extendable and fun.
Live demo, click to watch on YouTube:

Screenshots: 👈 Click here to see screenshots








-
Telegram Bot (
Telegram Bottoken required) -
ChatGPT (
OpenAIAPI key required) -
Gemini (Google
GeminiAPI Key required) -
Claude (
AnthropicAPI Key required) -
Mistral (Install Ollama and enable
Mistral) - Speech-to-Text (
OpenAIorGoogle CloudAPI key required, or your own engine) - Text-to-Speech (
OpenAIorGoogle CloudAPI key required, or your own engine) - Text-to-Image by DALL·E (
OpenAIAPI key required, or your own engine) - OCR/OBJECT_DETECT (
Google CloudAPI key required, or your own engine) - Feeding webpage and YouTube to enhance your prompt
- Custom prompt and 🧠 Awesome ChatGPT Prompts at your fingertips
- Support
privateandpublicmode, with multiple authenticate methods. -
Middlewarestyle workflow, easy to extend. - Built-in support parsing webpages,
YouTubevideos, PDFs, images, Office documents, code files, text files... - Realtime stream-style response, no more waiting.
- Multimodal support for all supported models.
- Automatically selects the optimal model for the task.
- Audio input and output support for supported models, not just TTS.
- Google
Search as a toolsupport for Gemini 2.0. - Markdown rendering
- Reference rendering
- Code block rendering, developers friendly.
- Threaded conversation support.
- ESM from the ground up
Make the halbot json config file and put it in this path ~/.halbot.json.
Basic config demo:
{
"telegramToken": "[[Telegram Bot API Token]]",
"openaiApiKey": "[[OpenAI API Key]]"
}All supported configuration fields:
{
// REQUIRED, string.
"telegramToken": "[[Telegram Bot API Token]]",
// Set some of these fields if you need Google's Gemini, TTS, STT, OCR, OBJECT_DETECT, Embedding features.
// OPTIONAL, string.
"googleApiKey": "[[Google Cloud / Gemini API Key]]",
// OPTIONAL, string, default: "gemini-pro-vision".
"geminiModel": "[[Custom Gemini Model ID]]",
// OPTIONAL, integer, default: 0.
"geminiPriority": "[[Custom Gemini Priority]]",
// Set some of these fields if you need OpenAI's ChatGPT, Whisper, Embedding features.
// OPTIONAL, string.
"openaiApiKey": "[[OpenAI API Key]]",
// OPTIONAL, string.
"openaiEndpoint": "[[Custom OpenAI API endpoint]]",
// OPTIONAL, string, default: "gpt-3.5-turbo".
"chatGptModel": "[[Custom ChatGPT Model ID]]",
// OPTIONAL, integer, default: 1.
"chatGptPriority": "[[Custom ChatGPT Priority]]",
// Set some of these fields if you need to use custom ChatGPT API.
// OPTIONAL, string.
"chatGptApiKey": "[[Custom ChatGPT API Key]]",
// OPTIONAL, string.
"chatGptEndpoint": "[[Custom ChatGPT API endpoint]]",
// Set some of these fields if you need Anthropic's Claude features.
// OPTIONAL, string.
"claudeApiKey": "[[Anthropic API Key]]",
// OPTIONAL, string, default: "claude".
"claudeModel": "[[Custom Claude Model ID]]",
// OPTIONAL, integer, default: 2.
"claudePriority": "[[Custom Claude Priority]]",
// Set some of these fields if you need Mistral features.
// OPTIONAL, boolean.
"mistralEnabled": "[[Enable Mistral hosted by Ollama]]",
// OPTIONAL, string.
"mistralEndpoint": "[[Custom Mistral API endpoint]]",
// OPTIONAL, string, default: "Mistral" (Mistral 7B).
"mistralModel": "[[Custom Mistral Model ID]]",
// OPTIONAL, integer, default: 3.
"mistralPriority": "[[Custom Mistral Priority]]",
// OPTIONAL, undefined || array of string.
// To open the bot to PUBLIC, DO NOT set this field;
// To restrict the bot to PRIVATE, set chat/group/channel ids in this array.
"private": ["[[CHAT_ID]]", "[[GROUP_ID]]", "[[CHANNEL_ID]]", ...],
// OPTIONAL, string.
// Set some of these fields if you want to use a `magic word` to authenticate the bot.
"magicWord": "[[Your Magic Word here]]",
// OPTIONAL, string.
// Use a HOME GROUP to authentication users.
// Anyone in this group can access the bot.
"homeGroup": "[[GROUP_ID]]",
// OPTIONAL, array of enum string.
// Enum: 'private', 'mention', 'group', 'channel'.
// Defaule: ['private', 'mention'].
// By default, it will only reply to `private` chats and group `mention`s.
// Adding 'group' or 'channel' may cause too much disturbance.
"chatType": ["mention", "private"],
// OPTIONAL, string.
"hello": "[[initial prompt]]",
// OPTIONAL, string.
"info": "[[bot description]]",
// OPTIONAL, string.
"help": "[[help information]]",
// OPTIONAL, object.
// Sessions/conversations storage.
// support PostgreSQL, MariaDB/MySQL and Redis for now.
// If omitted, the bot will use memory storage and sync to this file.
// Example: (Compatibility: https://node-postgres.com/apis/pool)
// PostgreSQL is recommended for vector storage.
"storage": {
"provider": "POSTGRESQL",
"host": "[[DATABASE HOST]]",
"database": "[[DATABASE NAME]]",
"user": "[[DATABASE USER]]",
"password": "[[DATABASE PASSWORD]]",
"vector": true, // REQUIRED
...[[OTHER DATABASE OPTIONS]],
},
// OR: (Compatibility: https://github.com/sidorares/node-mysql2)
"storage": {
"provider": "[["MARIADB" || "MYSQL"]]",
"host": "[[DATABASE HOST]]",
"database": "[[DATABASE NAME]]",
"user": "[[DATABASE USER]]",
"password": "[[DATABASE PASSWORD]]",
"charset": "utf8mb4", // REQUIRED
...[[OTHER DATABASE OPTIONS]],
},
// OR: (Compatibility: https://github.com/luin/ioredis)
"storage": {
"provider": "REDIS",
"host": "[[REDIS HOST]]",
"password": "[[REDIS PASSWORD]]",
...[[OTHER REDIS OPTIONS]],
},
}In peace-of-mind:
$ npx halbotIf you have multible AI engines configed, use '/chatgpt' or '/bing' to switch between them, or you can use '/*' to ask them all at the same time.
Install:
$ npm i halbotCode:
import halbot from 'halbot';
const config = {
// ...[[ALL THE CONFIG FIELDS SUPPORTED ABOVE]]],
// OPTIONAL, function.
// Your own authentication logic.
// return true if the user is authenticated.
// return false if the user is not authenticated.
auth: async (ctx) => {
// ctx is the `telegraf` context object: https://telegraf.js.org/#context-class
// It has been extended: https://github.com/Leask/utilitas/blob/master/lib/bot.mjs
return true;
},
// OPTIONAL, object (key renderd as name) or array (name ignored).
ai: {
[[aiNameA]]: [[aiConfigA]],
[[aiNameB]]: [[aiConfigB]],
// ...
},
// OPTIONAL, object.
// Your own speech-to-text and text-to-speech engine.
speech: {
stt: [[sttApi]],
tts: [[ttsApi]],
},
// OPTIONAL, object.
// Your own computer-vision engine.
vision: {
see: [[ocrAndObjectDetectApi]],
read: [[documentAnnotateApi]],
},
// OPTIONAL, object.
// Your own image-generator engine.
image: {
generate: [[textToImageApi]],
},
// OPTIONAL, string.
// Path to your own middlewares.
// ./skills
// |- skill_a.mjs
// | const action = async (bot) => {
// | bot.use(async (ctx, next) => {
// | ctx.reply('42');
// | await next();
// | });
// | };
// |
// | export const { run, priority, func } = {
// | run: true,
// | priority: 100,
// | func: action,
// | };
skillPath: [[pathToYourMiddlewares]],
// OPTIONAL, object.
// Using customized storage engine.
// `storage` should Should be compatible with the `Map` interface:
// https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Map
storage: {
provider: [[POSTGRESQL || MARIADB || MYSQL || REDIS]],
get: async (key) => { /* Return session object by chatId. */ },
set: async (key, session) => { /* Save session object by chatId. */ },
client: { /* Customized database client / pool. */ },
query: async (topic) => { /* Search history and session by topic. */ },
upsert: async (event) => { /* Save event for history and session. */ },
},
},
// OPTIONAL, function.
// Using customized embedding engine for history and session search.
embedding: async (text) => { /* Return vector embedding of the text. */ },
// OPTIONAL, array of string.
// Supported mime types of your vision-enabled AI models.
// If omitted, bot will use standard OCR and Object Detect to handle images.
supportedMimeTypes: [...[[mimeTypes]]],
// OPTIONAL, object.
// Adding extra commands.
cmds: {
[[commandA]]: [[descriptionA]],
[[commandB]]: [[descriptionB]],
...[[OTHER COMMANDS]],
},
// OPTIONAL, object.
// Adding extra configurations
args: {
[[argA]]: {
type: 'string',
short: [[shortCut]],
default: [[defaultValue]],
desc: [[description]],
},
[[argB]]: {
type: 'binary',
short: [[shortCut]],
default: [[defaultValue]],
desc: [[description]],
},
...[[OTHER ARGS]],
},
};
await halbot(config);-
halbotuses my other project 🧰 utilitas as the basic framework to handle all the dirty work. -
halbotuses 🤖 utilitas.bot as a Telegram bot engine. -
halbotuses 🤖 utilitas.alan to communicate with the AI engines.

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for halbot
Similar Open Source Tools
halbot
halbot is a Telegram bot that uses ChatGPT, Gemini, Mistral, and other AI engines to provide a variety of services, including text generation, translation, summarization, and question answering. It is easy to use and extend, and it can be integrated into your own projects. halbot is open source and free to use.
x
Ant Design X is a tool for crafting AI-driven interfaces effortlessly. It is built on the best practices of enterprise-level AI products, offering flexible and diverse atomic components for various AI dialogue scenarios. The tool provides out-of-the-box model integration with inference services compatible with OpenAI standards. It also enables efficient management of conversation data flows, supports rich template options, complete TypeScript support, and advanced theme customization. Ant Design X is designed to enhance development efficiency and deliver exceptional AI interaction experiences.
chrome-ai
Chrome AI is a Vercel AI provider for Chrome's built-in model (Gemini Nano). It allows users to create language models using Chrome's AI capabilities. The tool is under development and may contain errors and frequent changes. Users can install the ChromeAI provider module and use it to generate text, stream text, and generate objects. To enable AI in Chrome, users need to have Chrome version 127 or greater and turn on specific flags. The tool is designed for developers and researchers interested in experimenting with Chrome's built-in AI features.
python-utcp
The Universal Tool Calling Protocol (UTCP) is a secure and scalable standard for defining and interacting with tools across various communication protocols. UTCP emphasizes scalability, extensibility, interoperability, and ease of use. It offers a modular core with a plugin-based architecture, making it extensible, testable, and easy to package. The repository contains the complete UTCP Python implementation with core components and protocol-specific plugins for HTTP, CLI, Model Context Protocol, file-based tools, and more.
island-ai
island-ai is a TypeScript toolkit tailored for developers engaging with structured outputs from Large Language Models. It offers streamlined processes for handling, parsing, streaming, and leveraging AI-generated data across various applications. The toolkit includes packages like zod-stream for interfacing with LLM streams, stream-hooks for integrating streaming JSON data into React applications, and schema-stream for JSON streaming parsing based on Zod schemas. Additionally, related packages like @instructor-ai/instructor-js focus on data validation and retry mechanisms, enhancing the reliability of data processing workflows.

firecrawl
Firecrawl is an API service that empowers AI applications with clean data from any website. It features advanced scraping, crawling, and data extraction capabilities. The repository is still in development, integrating custom modules into the mono repo. Users can run it locally but it's not fully ready for self-hosted deployment yet. Firecrawl offers powerful capabilities like scraping, crawling, mapping, searching, and extracting structured data from single pages, multiple pages, or entire websites with AI. It supports various formats, actions, and batch scraping. The tool is designed to handle proxies, anti-bot mechanisms, dynamic content, media parsing, change tracking, and more. Firecrawl is available as an open-source project under the AGPL-3.0 license, with additional features offered in the cloud version.
functionary
Functionary is a language model that interprets and executes functions/plugins. It determines when to execute functions, whether in parallel or serially, and understands their outputs. Function definitions are given as JSON Schema Objects, similar to OpenAI GPT function calls. It offers documentation and examples on functionary.meetkai.com. The newest model, meetkai/functionary-medium-v3.1, is ranked 2nd in the Berkeley Function-Calling Leaderboard. Functionary supports models with different context lengths and capabilities for function calling and code interpretation. It also provides grammar sampling for accurate function and parameter names. Users can deploy Functionary models serverlessly using Modal.com.

LocalAGI
LocalAGI is a powerful, self-hostable AI Agent platform that allows you to design AI automations without writing code. It provides a complete drop-in replacement for OpenAI's Responses APIs with advanced agentic capabilities. With LocalAGI, you can create customizable AI assistants, automations, chat bots, and agents that run 100% locally, without the need for cloud services or API keys. The platform offers features like no-code agents, web-based interface, advanced agent teaming, connectors for various platforms, comprehensive REST API, short & long-term memory capabilities, planning & reasoning, periodic tasks scheduling, memory management, multimodal support, extensible custom actions, fully customizable models, observability, and more.

Bindu
Bindu is an operating layer for AI agents that provides identity, communication, and payment capabilities. It delivers a production-ready service with a convenient API to connect, authenticate, and orchestrate agents across distributed systems using open protocols: A2A, AP2, and X402. Built with a distributed architecture, Bindu makes it fast to develop and easy to integrate with any AI framework. Transform any agent framework into a fully interoperable service for communication, collaboration, and commerce in the Internet of Agents.

openlrc
Open-Lyrics is a Python library that transcribes voice files using faster-whisper and translates/polishes the resulting text into `.lrc` files in the desired language using LLM, e.g. OpenAI-GPT, Anthropic-Claude. It offers well preprocessed audio to reduce hallucination and context-aware translation to improve translation quality. Users can install the library from PyPI or GitHub and follow the installation steps to set up the environment. The tool supports GUI usage and provides Python code examples for transcription and translation tasks. It also includes features like utilizing context and glossary for translation enhancement, pricing information for different models, and a list of todo tasks for future improvements.
orch
orch is a library for building language model powered applications and agents for the Rust programming language. It can be used for tasks such as text generation, streaming text generation, structured data generation, and embedding generation. The library provides functionalities for executing various language model tasks and can be integrated into different applications and contexts. It offers flexibility for developers to create language model-powered features and applications in Rust.
langchain-rust
LangChain Rust is a library for building applications with Large Language Models (LLMs) through composability. It provides a set of tools and components that can be used to create conversational agents, document loaders, and other applications that leverage LLMs. LangChain Rust supports a variety of LLMs, including OpenAI, Azure OpenAI, Ollama, and Anthropic Claude. It also supports a variety of embeddings, vector stores, and document loaders. LangChain Rust is designed to be easy to use and extensible, making it a great choice for developers who want to build applications with LLMs.
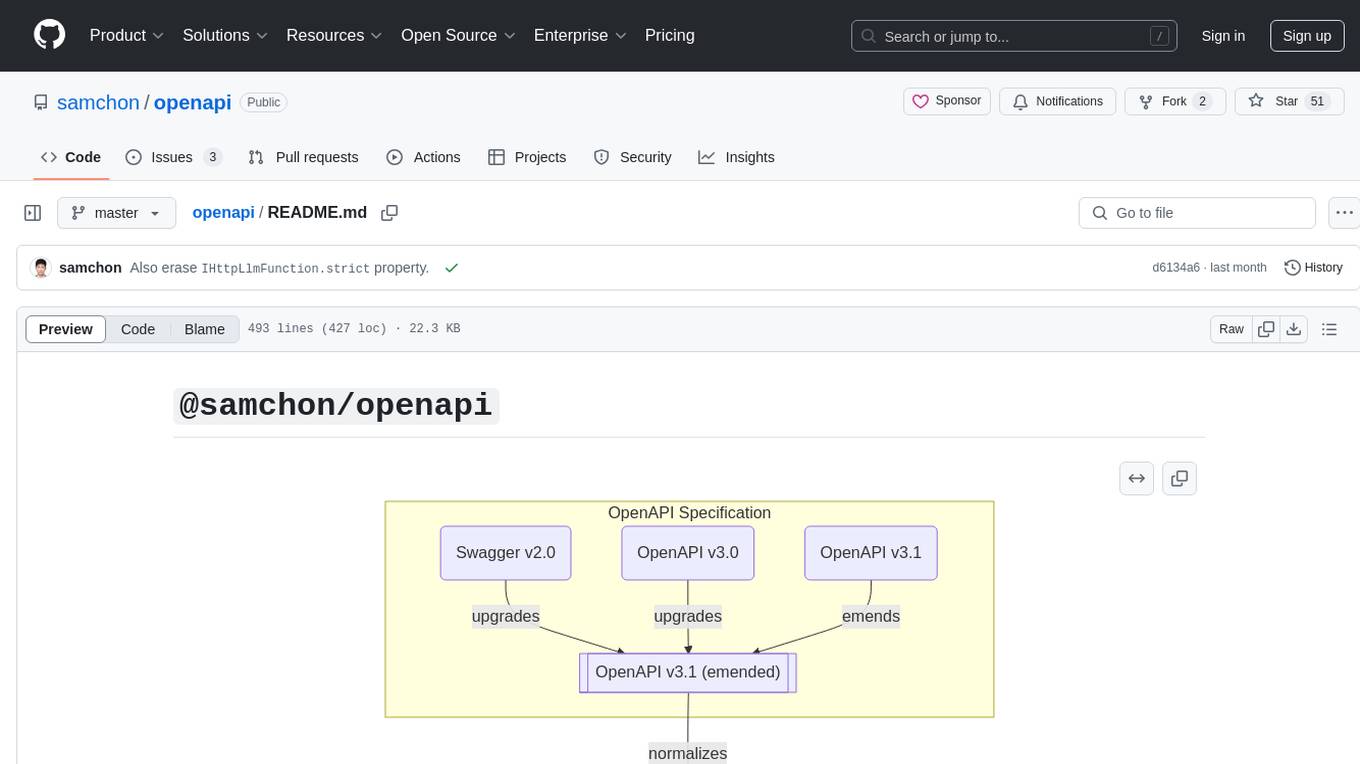
openapi
The `@samchon/openapi` repository is a collection of OpenAPI types and converters for various versions of OpenAPI specifications. It includes an 'emended' OpenAPI v3.1 specification that enhances clarity by removing ambiguous and duplicated expressions. The repository also provides an application composer for LLM (Large Language Model) function calling from OpenAPI documents, allowing users to easily perform LLM function calls based on the Swagger document. Conversions to different versions of OpenAPI documents are also supported, all based on the emended OpenAPI v3.1 specification. Users can validate their OpenAPI documents using the `typia` library with `@samchon/openapi` types, ensuring compliance with standard specifications.
ogpt.nvim
OGPT.nvim is a Neovim plugin that enables users to interact with various language models (LLMs) such as Ollama, OpenAI, TextGenUI, and more. Users can engage in interactive question-and-answer sessions, have persona-based conversations, and execute customizable actions like grammar correction, translation, keyword generation, docstring creation, test addition, code optimization, summarization, bug fixing, code explanation, and code readability analysis. The plugin allows users to define custom actions using a JSON file or plugin configurations.

lagent
Lagent is a lightweight open-source framework that allows users to efficiently build large language model(LLM)-based agents. It also provides some typical tools to augment LLM. The overview of our framework is shown below:

lingo.dev
Replexica AI automates software localization end-to-end, producing authentic translations instantly across 60+ languages. Teams can do localization 100x faster with state-of-the-art quality, reaching more paying customers worldwide. The tool offers a GitHub Action for CI/CD automation and supports various formats like JSON, YAML, CSV, and Markdown. With lightning-fast AI localization, auto-updates, native quality translations, developer-friendly CLI, and scalability for startups and enterprise teams, Replexica is a top choice for efficient and effective software localization.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.
LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.