
EuroEval
The robust European language model benchmark.
Stars: 160
EuroEval is a robust European language model benchmark tool, formerly known as ScandEval. It provides a platform to benchmark pretrained models on various tasks across different languages. Users can evaluate models, datasets, and metrics both online and offline. The tool supports benchmarking from the command line, script, and Docker. Additionally, users can reproduce datasets used in the project using provided scripts. EuroEval welcomes contributions and offers guidelines for general contributions and adding new datasets.
README:

(formerly known as ScandEval)


- Dan Saattrup Smart (@saattrupdan, [email protected])
See the documentation for more information.
All datasets used in this project are generated using the scripts located in the src/scripts folder. To reproduce a dataset, run the corresponding script with the following command
uv run src/scripts/<name-of-script>.pyReplace with the specific script you wish to execute, e.g.,
uv run src/scripts/create_allocine.pyA huge thank you to all the contributors who have helped make this project a success!






















We welcome contributions to EuroEval! Whether you're fixing bugs, adding features, or contributing new datasets, your help makes this project better for everyone.
- General contributions: Check out our contribution guidelines for information on how to get started.
- Adding datasets: If you're interested in adding a new dataset to EuroEval, we have a dedicated guide with step-by-step instructions.
- Thanks to Google for sponsoring Gemini credits as part of their Google Cloud for Researchers Program.
- Thanks @Mikeriess for evaluating many of the larger models on the leaderboards.
- Thanks to OpenAI for sponsoring OpenAI credits as part of their Researcher Access Program.
- Thanks to UWV and KU Leuven for sponsoring the Azure OpenAI credits used to evaluate GPT-4-turbo in Dutch.
- Thanks to Miðeind for sponsoring the OpenAI credits used to evaluate GPT-4-turbo in Icelandic and Faroese.
- Thanks to CHC for sponsoring the OpenAI credits used to evaluate GPT-4-turbo in German.
If you want to cite the framework then feel free to use this:
@article{smart2024encoder,
title={Encoder vs Decoder: Comparative Analysis of Encoder and Decoder Language Models on Multilingual NLU Tasks},
author={Smart, Dan Saattrup and Enevoldsen, Kenneth and Schneider-Kamp, Peter},
journal={arXiv preprint arXiv:2406.13469},
year={2024}
}
@inproceedings{smart2023scandeval,
author = {Smart, Dan Saattrup},
booktitle = {Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa)},
month = may,
pages = {185--201},
title = {{ScandEval: A Benchmark for Scandinavian Natural Language Processing}},
year = {2023}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for EuroEval
Similar Open Source Tools
EuroEval
EuroEval is a robust European language model benchmark tool, formerly known as ScandEval. It provides a platform to benchmark pretrained models on various tasks across different languages. Users can evaluate models, datasets, and metrics both online and offline. The tool supports benchmarking from the command line, script, and Docker. Additionally, users can reproduce datasets used in the project using provided scripts. EuroEval welcomes contributions and offers guidelines for general contributions and adding new datasets.
LMCache
LMCache is a serving engine extension designed to reduce time to first token (TTFT) and increase throughput, particularly in long-context scenarios. It stores key-value caches of reusable texts across different locations like GPU, CPU DRAM, and Local Disk, allowing the reuse of any text in any serving engine instance. By combining LMCache with vLLM, significant delay savings and GPU cycle reduction are achieved in various large language model (LLM) use cases, such as multi-round question answering and retrieval-augmented generation (RAG). LMCache provides integration with the latest vLLM version, offering both online serving and offline inference capabilities. It supports sharing key-value caches across multiple vLLM instances and aims to provide stable support for non-prefix key-value caches along with user and developer documentation.

biochatter
Generative AI models have shown tremendous usefulness in increasing accessibility and automation of a wide range of tasks. This repository contains the `biochatter` Python package, a generic backend library for the connection of biomedical applications to conversational AI. It aims to provide a common framework for deploying, testing, and evaluating diverse models and auxiliary technologies in the biomedical domain. BioChatter is part of the BioCypher ecosystem, connecting natively to BioCypher knowledge graphs.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking
MarkFlowy
MarkFlowy is a lightweight and feature-rich Markdown editor with built-in AI capabilities. It supports one-click export of conversations, translation of articles, and obtaining article abstracts. Users can leverage large AI models like DeepSeek and Chatgpt as intelligent assistants. The editor provides high availability with multiple editing modes and custom themes. Available for Linux, macOS, and Windows, MarkFlowy aims to offer an efficient, beautiful, and data-safe Markdown editing experience for users.

cognee
Cognee is an open-source framework designed for creating self-improving deterministic outputs for Large Language Models (LLMs) using graphs, LLMs, and vector retrieval. It provides a platform for AI engineers to enhance their models and generate more accurate results. Users can leverage Cognee to add new information, utilize LLMs for knowledge creation, and query the system for relevant knowledge. The tool supports various LLM providers and offers flexibility in adding different data types, such as text files or directories. Cognee aims to streamline the process of working with LLMs and improving AI models for better performance and efficiency.
SuperCoder
SuperCoder is an open-source autonomous software development system that leverages advanced AI tools and agents to streamline and automate coding, testing, and deployment tasks, enhancing efficiency and reliability. It supports a variety of languages and frameworks for diverse development needs. Users can set up the environment variables, build and run the Go server, Asynq worker, and Postgres using Docker and Docker Compose. The project is under active development and may still have issues, but users can seek help and support from the Discord community or by creating new issues on GitHub.
esp-ai
ESP-AI provides a complete AI conversation solution for your development board, including IAT+LLM+TTS integration solutions for ESP32 series development boards. It can be injected into projects without affecting existing ones. By providing keys from platforms like iFlytek, Jiling, and local services, you can run the services without worrying about interactions between services or between development boards and services. The project's server-side code is based on Node.js, and the hardware code is based on Arduino IDE.
generative-ai
This repository contains codes related to Generative AI as per YouTube video. It includes various notebooks and files for different days covering topics like map reduce, text to SQL, LLM parameters, tagging, and Kaggle competition. The repository also includes resources like PDF files and databases for different projects related to Generative AI.
Chat2DB
Chat2DB is an AI-driven data development and analysis platform that enables users to communicate with databases using natural language. It supports a wide range of databases, including MySQL, PostgreSQL, Oracle, SQLServer, SQLite, MariaDB, ClickHouse, DM, Presto, DB2, OceanBase, Hive, KingBase, MongoDB, Redis, and Snowflake. Chat2DB provides a user-friendly interface that allows users to query databases, generate reports, and explore data using natural language commands. It also offers a variety of features to help users improve their productivity, such as auto-completion, syntax highlighting, and error checking.
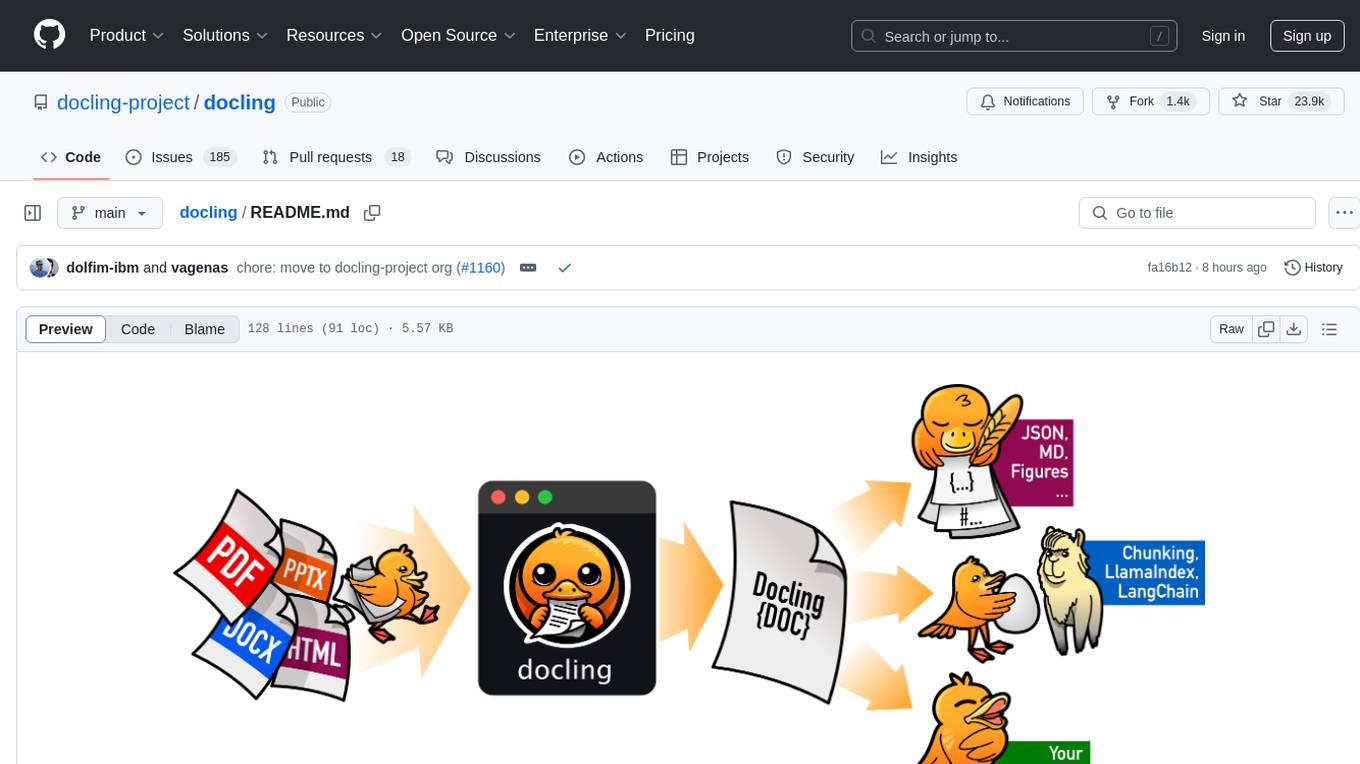
docling
Docling simplifies document processing, parsing diverse formats including advanced PDF understanding, and providing seamless integrations with the general AI ecosystem. It offers features such as parsing multiple document formats, advanced PDF understanding, unified DoclingDocument representation format, various export formats, local execution capabilities, plug-and-play integrations with agentic AI tools, extensive OCR support, and a simple CLI. Coming soon features include metadata extraction, visual language models, chart understanding, and complex chemistry understanding. Docling is installed via pip and works on macOS, Linux, and Windows environments. It provides detailed documentation, examples, integrations with popular frameworks, and support through the discussion section. The codebase is under the MIT license and has been developed by IBM.
lingoose
LinGoose is a modular Go framework designed for building AI/LLM applications. It offers the flexibility to import only the necessary modules, abstracts features for customization, and provides a comprehensive solution for developing AI/LLM applications from scratch. The framework simplifies the process of creating intelligent applications by allowing users to choose preferred implementations or create their own. LinGoose empowers developers to leverage its capabilities to streamline the development of cutting-edge AI and LLM projects.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.
amplication
Amplication is a robust, open-source development platform designed to revolutionize the creation of scalable and secure .NET and Node.js applications. It automates backend applications development, ensuring consistency, predictability, and adherence to the highest standards with code that's built to scale. The user-friendly interface fosters seamless integration of APIs, data models, databases, authentication, and authorization. Built on a flexible, plugin-based architecture, Amplication allows effortless customization of the code and offers a diverse range of integrations. With a strong focus on collaboration, Amplication streamlines team-oriented development, making it an ideal choice for groups of all sizes, from startups to large enterprises. It enables users to concentrate on business logic while handling the heavy lifting of development. Experience the fastest way to develop .NET and Node.js applications with Amplication.
deepchecks
Deepchecks is a holistic open-source solution for AI & ML validation needs, enabling thorough testing of data and models from research to production. It includes components for testing, CI & testing management, and monitoring. Users can install and use Deepchecks for testing and monitoring their AI models, with customizable checks and suites for tabular, NLP, and computer vision data. The tool provides visual reports, pythonic/json output for processing, and a dynamic UI for collaboration and monitoring. Deepchecks is open source, with premium features available under a commercial license for monitoring components.

openrl
OpenRL is an open-source general reinforcement learning research framework that supports training for various tasks such as single-agent, multi-agent, offline RL, self-play, and natural language. Developed based on PyTorch, the goal of OpenRL is to provide a simple-to-use, flexible, efficient and sustainable platform for the reinforcement learning research community. It supports a universal interface for all tasks/environments, single-agent and multi-agent tasks, offline RL training with expert dataset, self-play training, reinforcement learning training for natural language tasks, DeepSpeed, Arena for evaluation, importing models and datasets from Hugging Face, user-defined environments, models, and datasets, gymnasium environments, callbacks, visualization tools, unit testing, and code coverage testing. It also supports various algorithms like PPO, DQN, SAC, and environments like Gymnasium, MuJoCo, Atari, and more.
For similar tasks
EuroEval
EuroEval is a robust European language model benchmark tool, formerly known as ScandEval. It provides a platform to benchmark pretrained models on various tasks across different languages. Users can evaluate models, datasets, and metrics both online and offline. The tool supports benchmarking from the command line, script, and Docker. Additionally, users can reproduce datasets used in the project using provided scripts. EuroEval welcomes contributions and offers guidelines for general contributions and adding new datasets.
rageval
Rageval is an evaluation tool for Retrieval-augmented Generation (RAG) methods. It helps evaluate RAG systems by performing tasks such as query rewriting, document ranking, information compression, evidence verification, answer generation, and result validation. The tool provides metrics for answer correctness and answer groundedness, along with benchmark results for ASQA and ALCE datasets. Users can install and use Rageval to assess the performance of RAG models in question-answering tasks.
FedLLM-Bench
FedLLM-Bench is a realistic benchmark for the Federated Learning of Large Language Models community. It includes datasets for federated instruction tuning and preference alignment tasks, exhibiting diversities in language, quality, quantity, instruction, sequence length, embedding, and preference. The repository provides training scripts and code for open-ended evaluation, aiming to facilitate research and development in federated learning of large language models.

hass-ollama-conversation
The Ollama Conversation integration adds a conversation agent powered by Ollama in Home Assistant. This agent can be used in automations to query information provided by Home Assistant about your house, including areas, devices, and their states. Users can install the integration via HACS and configure settings such as API timeout, model selection, context size, maximum tokens, and other parameters to fine-tune the responses generated by the AI language model. Contributions to the project are welcome, and discussions can be held on the Home Assistant Community platform.

rclip
rclip is a command-line photo search tool powered by the OpenAI's CLIP neural network. It allows users to search for images using text queries, similar image search, and combining multiple queries. The tool extracts features from photos to enable searching and indexing, with options for previewing results in supported terminals or custom viewers. Users can install rclip on Linux, macOS, and Windows using different installation methods. The repository follows the Conventional Commits standard and welcomes contributions from the community.

honcho
Honcho is a platform for creating personalized AI agents and LLM powered applications for end users. The repository is a monorepo containing the server/API for managing database interactions and storing application state, along with a Python SDK. It utilizes FastAPI for user context management and Poetry for dependency management. The API can be run using Docker or manually by setting environment variables. The client SDK can be installed using pip or Poetry. The project is open source and welcomes contributions, following a fork and PR workflow. Honcho is licensed under the AGPL-3.0 License.
core
OpenSumi is a framework designed to help users quickly build AI Native IDE products. It provides a set of tools and templates for creating Cloud IDEs, Desktop IDEs based on Electron, CodeBlitz web IDE Framework, Lite Web IDE on the Browser, and Mini-App liked IDE. The framework also offers documentation for users to refer to and a detailed guide on contributing to the project. OpenSumi encourages contributions from the community and provides a platform for users to report bugs, contribute code, or improve documentation. The project is licensed under the MIT license and contains third-party code under other open source licenses.
yolo-ios-app
The Ultralytics YOLO iOS App GitHub repository offers an advanced object detection tool leveraging YOLOv8 models for iOS devices. Users can transform their devices into intelligent detection tools to explore the world in a new and exciting way. The app provides real-time detection capabilities with multiple AI models to choose from, ranging from 'nano' to 'x-large'. Contributors are welcome to participate in this open-source project, and licensing options include AGPL-3.0 for open-source use and an Enterprise License for commercial integration. Users can easily set up the app by following the provided steps, including cloning the repository, adding YOLOv8 models, and running the app on their iOS devices.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.