AI tools for vidio
Related Tools:

DeployMaster
The website is a platform for managing software deployments. It allows users to automate the deployment process, ensuring smooth and efficient delivery of software updates and changes to servers and applications. With features like version control, rollback options, and monitoring capabilities, users can easily track and manage their deployments. The platform simplifies the deployment process, reducing errors and downtime, and improving overall productivity.
ExpiredDomains.com
ExpiredDomains.com is a free online platform that assists users in finding valuable expired and expiring domain names. It aggregates domain data from various top-level domains (TLDs) and presents them in a searchable, filterable format. The platform offers tools and insights to help users make informed decisions when looking for domains with SEO authority, existing traffic, or strong brand potential. With comprehensive listings, exclusive data metrics, a user-friendly interface, and professional trust, ExpiredDomains.com is a preferred choice for SEOs, marketers, and investors worldwide.
quso.ai
quso.ai is an all-in-one Social Media AI Suite that offers a comprehensive set of AI tools for content creation, scheduling, analytics, and video editing. It helps users transform ideas into engaging content across various social platforms, driving growth and engagement. With features like AI Content Creator, AI Clips Generator, AI Video Generator, and more, quso.ai simplifies social media management and boosts efficiency. The platform caters to individuals, small businesses, start-ups, agencies, and various industries, providing a user-friendly interface and powerful AI capabilities.

VisionStory
VisionStory is an AI-powered video creation platform that allows users to transform images and text into captivating videos with lifelike avatars, natural voiceovers, and dynamic animations. With features like AI video creation, voice cloning, green screen effects, and support for multiple languages, VisionStory empowers content creators, marketers, educators, and YouTubers to produce high-quality video content effortlessly. The platform offers fast rendering, HD video output, and affordable pricing, making it a valuable tool for solo creators and teams alike.
Videograph
Videograph is an AI-powered video streaming platform that offers a range of video APIs for live and on-demand video streaming. It provides advanced video analytics, content distribution analytics, and features like portrait mode conversion, digital asset management, live streaming with low latency, content monetization, and dynamic ad insertion. With seamless organization through Digital Asset Management, Videograph enables users to elevate their content strategy with precision analytics. The platform also offers a user-friendly interface for easy video management and detailed insights on viewership metrics.
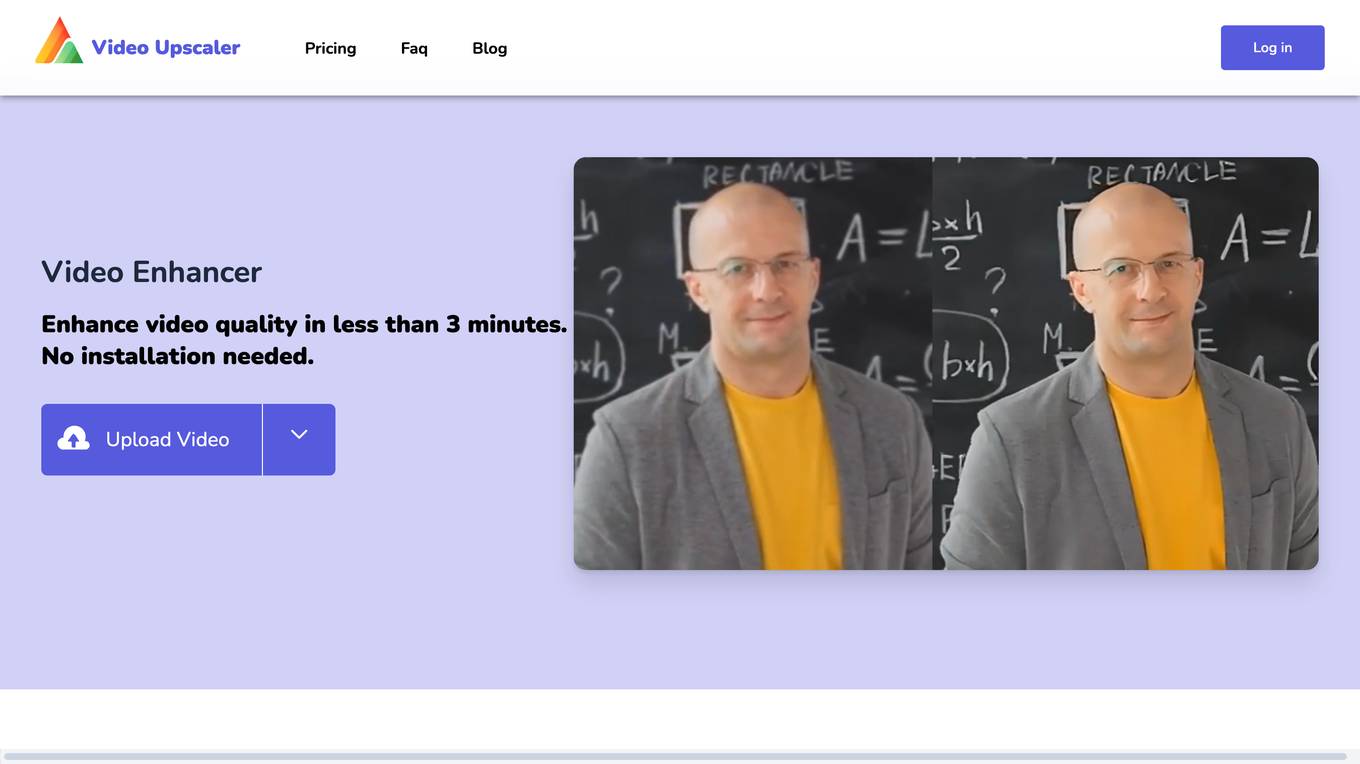
Video Upscaler
Video Upscaler is an online video enhancement platform that utilizes advanced AI algorithms to automatically enhance the quality of videos in just seconds. It offers a simple and effective solution for users to upscale their videos to 4K resolution without any loss of detail or quality. The platform is user-friendly, affordable, and constantly updating its models to provide the highest quality results across various categories.
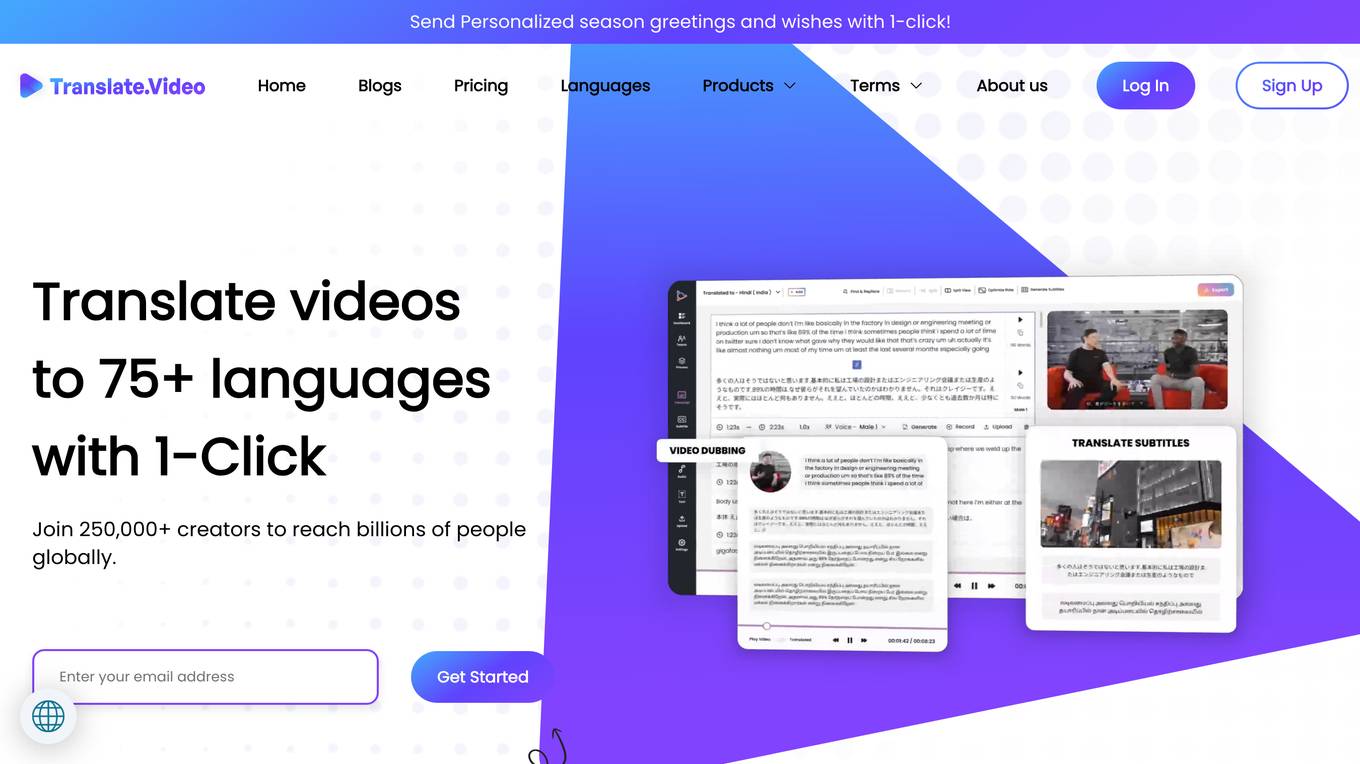
Translate.Video
Translate.Video is an AI multi-speaker video translation tool that offers speaker diarization, voice cloning, text-to-speech, and instant voice cloning features. It allows users to translate videos to over 75 languages with just one click, making content creation and translation efficient and accessible. The tool also provides plugins for popular design software like Photoshop, Illustrator, and Figma, enabling users to accelerate creative translation. Translate.Video is designed to help creators, influencers, and enterprises reach a global audience by simplifying the captioning, subtitling, and dubbing process.

Visionati
Visionati is an AI-powered platform that provides image captioning, descriptions, and analysis for everyone. It offers a comprehensive toolkit for visual analysis, including intelligent tagging, content filtering, and integration with various AI technologies. Visionati helps transform complex visuals into clear, actionable insights for digital marketing, storytelling, and data analysis. Users can easily create an account, access seamless integration, and leverage advanced analysis capabilities through the Visionati API.
Boolvideo
Boolvideo is an AI video generator application that allows users to turn various content such as product URLs, blog URLs, images, and text into high-quality videos with dynamic AI voices and engaging audio-visual elements. It offers a user-friendly interface and a range of features to create captivating videos effortlessly. Users can customize videos with AI co-pilots, choose from professional templates, and make advanced edits with a lightweight editor. Boolvideo caters to a wide range of use cases, including e-commerce, content creation, marketing, design, photography, and more.
video2quiz
video2quiz is an AI tool that allows users to create quizzes in seconds based on any video. The platform emphasizes the importance of human knowledge for skills and professionalism, with a focus on validating learnings through quizzes and tests. Founded in 2023, video2quiz offers consulting services, AI tools, and the K3 LMS to help individuals, teams, and enterprises thrive in the AI era.
Video2Recipe
Video2Recipe is an AI tool that allows users to convert their favorite cooking videos into recipes effortlessly. By simply pasting the video URL or ID, the AI generates step-by-step instructions and ingredient lists. The platform aims to simplify the process of following cooking tutorials and make it more accessible for users to recreate dishes they love.
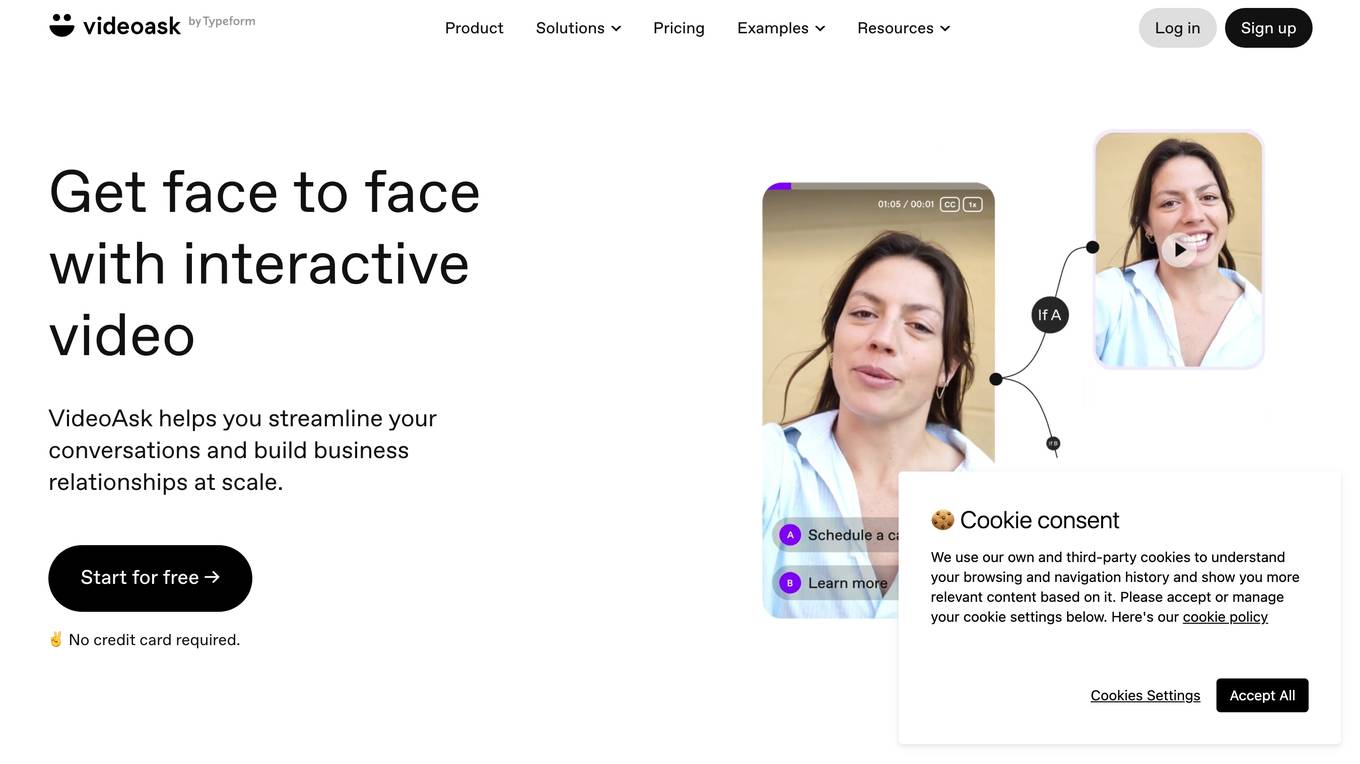
VideoAsk by Typeform
VideoAsk by Typeform is an interactive video platform that helps streamline conversations and build business relationships at scale. It offers features such as asynchronous interviews, easy scheduling, tagging, gathering contact info, capturing leads, research and feedback, training, customer support, and more. Users can create interactive video forms, conduct async interviews, and engage with their audience through AI-powered video chatbots. The platform is user-friendly, code-free, and integrates with over 1,500 applications through Zapier.
Video Silence Remover
Video Silence Remover is a free AI-powered video editing tool that helps users trim silent and quiet parts of their videos quickly and efficiently. The tool operates on the cloud, allowing users to go from a raw video to a first cut edit in minutes. It supports MP4 and other video files, enabling users to create AI-edited and captioned shorts and reels from full-form videos. Video Silence Remover is ideal for content creators, video editors, social media managers, course creators, and anyone looking to enhance video quality with minimal time investment.
Video Summarizer
Video Summarizer is an AI tool designed to generate educational summaries from lengthy videos in multiple languages. It simplifies the process of summarizing video content, making it easier for users to grasp key information efficiently. The tool is user-friendly and efficient, catering to individuals seeking quick and concise video summaries for educational purposes.
VideoSage
VideoSage is an AI-powered platform that allows users to ask questions and gain insights about videos. Empowered by Moonshot Kimi AI, VideoSage provides summaries, insights, timestamps, and accurate information based on video content. Users can engage in conversations with the AI while watching videos, fostering a collaborative environment. The platform aims to enhance the user experience by offering tools to customize and enhance viewing experiences.
Video Tap
Video Tap is an AI-powered tool that transforms videos into various types of content such as social media clips, blog posts, summaries, and more. It helps users repurpose their existing videos efficiently by utilizing AI technology to generate different forms of content, saving time and effort. With features like YouTube Clips Finder, Chapters Generator, Summarizer, Tags Generator, and Transcript Generator, Video Tap offers a comprehensive solution for content creators to enhance their video marketing strategies and reach a wider audience across different platforms.
VideoGen
VideoGen is an AI video generator tool that allows users to create professional videos in seconds. It offers a fast and easy video creation experience by providing features such as one-click video creation, copyright-free assets, text-to-speech narration, and smooth editing capabilities. Trusted by marketers, creators, professionals, and businesses, VideoGen helps in scaling up video production, improving turnaround time, and refining messaging for better results. It is designed for ROI, performance, and scalability, making it a valuable tool for content creators looking to produce high-quality videos efficiently.
vidBoard
vidBoard is an AI-powered video production platform that enables users to create engaging videos with ease. With its intuitive interface and advanced AI capabilities, vidBoard empowers creators and businesses to generate unique and captivating videos for various purposes, including marketing, education, and entertainment.
Videoleap
Videoleap is a powerful and easy-to-use video editor that offers a wide range of features, including AI-powered tools, to help you create stunning videos. With Videoleap, you can remove objects from videos, change video backgrounds, blur videos, add filters and effects, and more. You can also access a library of pre-made templates to get started quickly. Videoleap is available as an online video editor and as an iPhone and Android app.

VideomakerAI
VideomakerAI is an AI-powered video creation platform that allows users to create professional-quality videos in minutes. With VideomakerAI, you can easily create videos for social media, marketing, education, and more. No video editing experience is necessary - VideomakerAI's intuitive interface and powerful AI tools make it easy for anyone to create stunning videos.
NeuralNexus
Leveraging the power of models like VisionaryGeniusAI, GaiaAI, ACALLM, GannAI, and many more, I will generate answers that go beyond standard replies, instead offering a unique blend of insights and perspectives drawn from multiple domains and methodologies.

Visionary Business Coach
A vision-based business coach specializing in plan creation and strategy refinement.
Video Brief Genius
Transform your brand! Provide brand and product info, and we'll craft a unique, visually stunning 30-45 second video brief. Simple, effective, impactful.


Stock Footage Metadata
Expert in video titles and keywords, with strict adherence to best practices.




VIDEO GAME versus VIDEO GAME
A fun game of VIDEO GAME versus VIDEO GAME. Get the conversation and debates going!


Visionary Quotations And Context
Thought-provoking quotes relate to visionary thinking, human-AI collaboration, and Doughnut Economics. Fostering a sustainable and equitable future for all.

Awesome-LLMs-for-Video-Understanding
Awesome-LLMs-for-Video-Understanding is a repository dedicated to exploring Video Understanding with Large Language Models. It provides a comprehensive survey of the field, covering models, pretraining, instruction tuning, and hybrid methods. The repository also includes information on tasks, datasets, and benchmarks related to video understanding. Contributors are encouraged to add new papers, projects, and materials to enhance the repository.
video2blog
video2blog is an open-source project aimed at converting videos into textual notes. The tool follows a process of extracting video information using yt-dlp, downloading the video, downloading subtitles if available, translating subtitles if not in Chinese, generating Chinese subtitles using whisper if no subtitles exist, converting subtitles to articles using gemini, and manually inserting images from the video into the article. The tool provides a solution for creating blog content from video resources, enhancing accessibility and content creation efficiency.
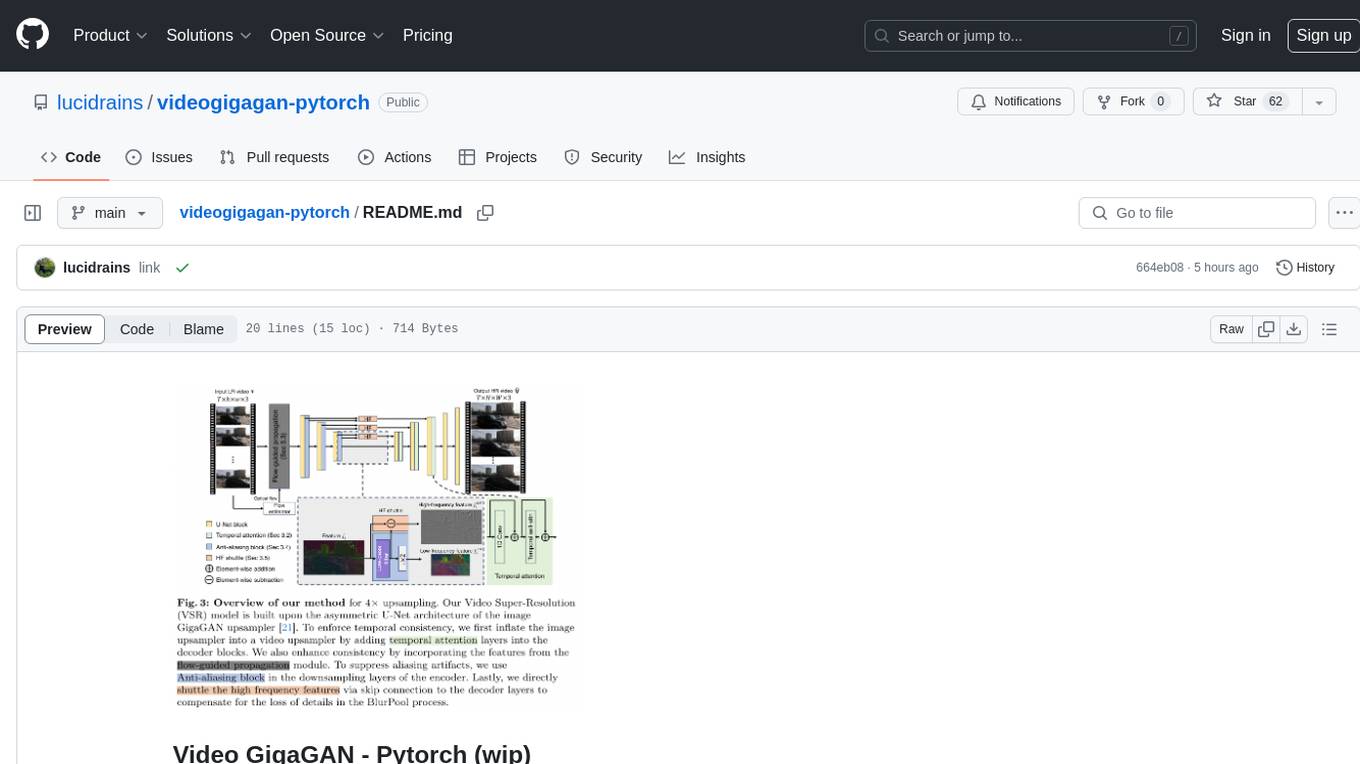
videogigagan-pytorch
Video GigaGAN - Pytorch is an implementation of Video GigaGAN, a state-of-the-art video upsampling technique developed by Adobe AI labs. The project aims to provide a Pytorch implementation for researchers and developers interested in video super-resolution. The codebase allows users to replicate the results of the original research paper and experiment with video upscaling techniques. The repository includes the necessary code and resources to train and test the GigaGAN model on video datasets. Researchers can leverage this implementation to enhance the visual quality of low-resolution videos and explore advancements in video super-resolution technology.
Video-MME
Video-MME is the first-ever comprehensive evaluation benchmark of Multi-modal Large Language Models (MLLMs) in Video Analysis. It assesses the capabilities of MLLMs in processing video data, covering a wide range of visual domains, temporal durations, and data modalities. The dataset comprises 900 videos with 256 hours and 2,700 human-annotated question-answer pairs. It distinguishes itself through features like duration variety, diversity in video types, breadth in data modalities, and quality in annotations.

VideoLLaMA2
VideoLLaMA 2 is a project focused on advancing spatial-temporal modeling and audio understanding in video-LLMs. It provides tools for multi-choice video QA, open-ended video QA, and video captioning. The project offers model zoo with different configurations for visual encoder and language decoder. It includes training and evaluation guides, as well as inference capabilities for video and image processing. The project also features a demo setup for running a video-based Large Language Model web demonstration.

videodb-python
VideoDB Python SDK allows you to interact with the VideoDB serverless database. Manage videos as intelligent data, not files. It's scalable, cost-efficient & optimized for AI applications and LLM integration. The SDK provides functionalities for uploading videos, viewing videos, streaming specific sections of videos, searching inside a video, searching inside multiple videos in a collection, adding subtitles to a video, generating thumbnails, and more. It also offers features like indexing videos by spoken words, semantic indexing, and future indexing options for scenes, faces, and specific domains like sports. The SDK aims to simplify video management and enhance AI applications with video data.
video-subtitle-remover
Video-subtitle-remover (VSR) is a software based on AI technology that removes hard subtitles from videos. It achieves the following functions: - Lossless resolution: Remove hard subtitles from videos, generate files with subtitles removed - Fill the region of removed subtitles using a powerful AI algorithm model (non-adjacent pixel filling and mosaic removal) - Support custom subtitle positions, only remove subtitles in defined positions (input position) - Support automatic removal of all text in the entire video (no input position required) - Support batch removal of watermark text from multiple images.
videokit
VideoKit is a full-featured user-generated content solution for Unity Engine, enabling video recording, camera streaming, microphone streaming, social sharing, and conversational interfaces. It is cross-platform, with C# source code available for inspection. Users can share media, save to camera roll, pick from camera roll, stream camera preview, record videos, remove background, caption audio, and convert text commands. VideoKit requires Unity 2022.3+ and supports Android, iOS, macOS, Windows, and WebGL platforms.

PromptClip
PromptClip is a tool that allows developers to create video clips using LLM prompts. Users can upload videos from various sources, prompt the video in natural language, use different LLM models, instantly watch the generated clips, finetune the clips, and add music or image overlays. The tool provides a seamless way to extract specific moments from videos based on user queries, making video editing and content creation more efficient and intuitive.
VideoLingo
VideoLingo is an all-in-one video translation and localization dubbing tool designed to generate Netflix-level high-quality subtitles. It aims to eliminate stiff machine translation, multiple lines of subtitles, and can even add high-quality dubbing, allowing knowledge from around the world to be shared across language barriers. Through an intuitive Streamlit web interface, the entire process from video link to embedded high-quality bilingual subtitles and even dubbing can be completed with just two clicks, easily creating Netflix-quality localized videos. Key features and functions include using yt-dlp to download videos from Youtube links, using WhisperX for word-level timeline subtitle recognition, using NLP and GPT for subtitle segmentation based on sentence meaning, summarizing intelligent term knowledge base with GPT for context-aware translation, three-step direct translation, reflection, and free translation to eliminate strange machine translation, checking single-line subtitle length and translation quality according to Netflix standards, using GPT-SoVITS for high-quality aligned dubbing, and integrating package for one-click startup and one-click output in streamlit.
Topaz-Video-AI
Topaz-Video-AI is a software tool designed to enhance video quality and provide various editing features. Users can utilize this tool to improve the visual appeal of their videos by applying filters, adjusting colors, and enhancing details. The software offers a user-friendly interface and a range of customization options to cater to different editing needs. Despite potential triggers from antivirus programs, Topaz-Video-AI is safe to use and has been tested by numerous users. By following the provided instructions, users can easily download, install, and run the software to enhance their video content.

Director
Director is a framework to build video agents that can reason through complex video tasks like search, editing, compilation, generation, etc. It enables users to summarize videos, search for specific moments, create clips instantly, integrate GenAI projects and APIs, add overlays, generate thumbnails, and more. Built on VideoDB's 'video-as-data' infrastructure, Director is perfect for developers, creators, and teams looking to simplify media workflows and unlock new possibilities.
VideoCaptioner
VideoCaptioner is a video subtitle processing assistant based on a large language model (LLM), supporting speech recognition, subtitle segmentation, optimization, translation, and full-process handling. It is user-friendly and does not require high configuration, supporting both network calls and local offline (GPU-enabled) speech recognition. It utilizes a large language model for intelligent subtitle segmentation, correction, and translation, providing stunning subtitles for videos. The tool offers features such as accurate subtitle generation without GPU, intelligent segmentation and sentence splitting based on LLM, AI subtitle optimization and translation, batch video subtitle synthesis, intuitive subtitle editing interface with real-time preview and quick editing, and low model token consumption with built-in basic LLM model for easy use.
ai-video-search-engine
AI Video Search Engine (AVSE) is a video search engine powered by the latest tools in AI. It allows users to search for specific answers within millions of videos by indexing video content. The tool extracts video transcription, elements like thumbnail and description, and generates vector embeddings using AI models. Users can search for relevant results based on questions, view timestamped transcripts, and get video summaries. AVSE requires a paid Supabase & Fly.io account for hosting and can handle millions of videos with the current setup.
video-starter-kit
A powerful starting kit for building AI-powered video applications. This toolkit simplifies the complexities of working with AI video models in the browser. It offers browser-native video processing, AI model integration, advanced media capabilities, and developer utilities. The tech stack includes fal.ai for AI model infrastructure, Next.js for React framework, Remotion for video processing, IndexedDB for browser-based storage, Vercel for deployment platform, and UploadThing for file upload. The kit provides features like seamless video handling, multi-clip composition, audio track integration, voiceover support, metadata encoding, and ready-to-use UI components.
Video-Super-Resolution-Library
Intel® Library for Video Super Resolution (Intel® Library for VSR) is a project that offers a variety of algorithms, including machine learning and deep learning implementations, to convert low-resolution videos to high resolution. It enhances the RAISR algorithm to provide better visual quality and real-time performance for upscaling on Intel® Xeon® platforms and Intel® GPUs. The project is developed in C++ and utilizes Intel® AVX-512 on Intel® Xeon® Scalable Processor family and OpenCL support on Intel® GPUs. It includes an FFmpeg plugin inside a Docker container for ease of testing and deployment.
VideoChat
VideoChat is a real-time voice interaction digital human tool that supports end-to-end voice solutions (GLM-4-Voice - THG) and cascade solutions (ASR-LLM-TTS-THG). Users can customize appearance and voice, support voice cloning, and achieve low first-packet delay of 3s. The tool offers various modules such as ASR, LLM, MLLM, TTS, and THG for different functionalities. It requires specific hardware and software configurations for local deployment, and provides options for weight downloads and customization of digital human appearance and voice. The tool also addresses known issues related to resource availability, video streaming optimization, and model loading.
Video-ChatGPT
Video-ChatGPT is a video conversation model that aims to generate meaningful conversations about videos by combining large language models with a pretrained visual encoder adapted for spatiotemporal video representation. It introduces high-quality video-instruction pairs, a quantitative evaluation framework for video conversation models, and a unique multimodal capability for video understanding and language generation. The tool is designed to excel in tasks related to video reasoning, creativity, spatial and temporal understanding, and action recognition.

AIO-Video-Downloader
AIO Video Downloader is an open-source Android application built on the robust yt-dlp backend with the help of youtubedl-android. It aims to be the most powerful download manager available, offering a clean and efficient interface while unlocking advanced downloading capabilities with minimal setup. With support for 1000+ sites and virtually any downloadable content across the web, AIO delivers a seamless yet powerful experience that balances speed, flexibility, and simplicity.
Text-To-Video-AI
Text-To-Video-AI is a tool that utilizes AI to generate videos from text. Users can easily create videos by providing text input, making content creation more efficient and accessible. The tool simplifies the video creation process by automating the conversion of text into engaging video content. With Text-To-Video-AI, users can quickly produce high-quality videos without the need for advanced video editing skills. The tool aims to empower content creators, marketers, educators, and individuals looking to enhance their video production capabilities.