
airport-free
Free nodes, automatically renews subscription every 3hours
Stars: 453
Airport-Free is a repository that provides free v2ray and clash nodes for subscription. The nodes are automatically updated every 3 hours. Users can access the v2ray.txt and clash.txt files from the Github repository. The repository includes scripts for v2ray and clash, which can be run to view the output results. It also allows users to submit new nodes through issues on GitHub. The repository aims to provide a convenient and reliable source of nodes for users to access the internet securely and privately.
README:
- Update time(UTC+8):
2026-02-15 23:19:45 - v2ray nodes all in one.(Not recommended)
- v2ray nodes all in one ( you can use this if can not access)
- Since CDN acceleration will cache and cause nodes updates to lag, you can go to Github fetch clash files or v2ray files
| v2ray | v2ray nodes 1 | v2ray nodes 2 | v2ray nodes 3 |
| clash | clash nodes 1 | clash nodes 2 | clash nodes 3 |
| v2ray | v2ray nodes 1 | v2ray nodes 2 | v2ray nodes 3 |
| clash | clash nodes 1 | clash nodes 2 | clash nodes 3 |
- The sources is opened GitHub
- Just save the v2ray py script to node/v2/, go to action, run the workflow, and you can see the output result.
- Just save the clash py script to node/clash/, go to action, run the workflow, and you can see the output result.
- This source code has added a few node sources by default, automatically detecting updates every 3 hours, if there is a new source, you are welcome to go to issues to submit the node source!
- To modify README.md, go to: nodes/README.md
- Due to the possibility that some of the nodes included in multiple websites may be duplicated, deduplication has been done, but there may still be some duplicates!
- Some websites may not be accessible in the future due to the GFW or the site itself, which may result in the inability to renew the subscription!
- All data comes from the Internet, and users are required to identify the authenticity of the content.
- This source code is only for Python learning, and it is forbidden to use it for illegal and criminal acts, otherwise you will bear the consequences!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for airport-free
Similar Open Source Tools
airport-free
Airport-Free is a repository that provides free v2ray and clash nodes for subscription. The nodes are automatically updated every 3 hours. Users can access the v2ray.txt and clash.txt files from the Github repository. The repository includes scripts for v2ray and clash, which can be run to view the output results. It also allows users to submit new nodes through issues on GitHub. The repository aims to provide a convenient and reliable source of nodes for users to access the internet securely and privately.
AIOLists
AIOLists is a stateless open source list management addon for Stremio that allows users to import and manage lists from various sources in one place. It offers unified search, metadata customization, Trakt integration, MDBList integration, external lists import, list sorting, customization options, watchlist updates, RPDB support, genre filtering, discovery lists, and shareable configurations. The addon aims to enhance the list management experience for Stremio users by providing a comprehensive set of features and functionalities.
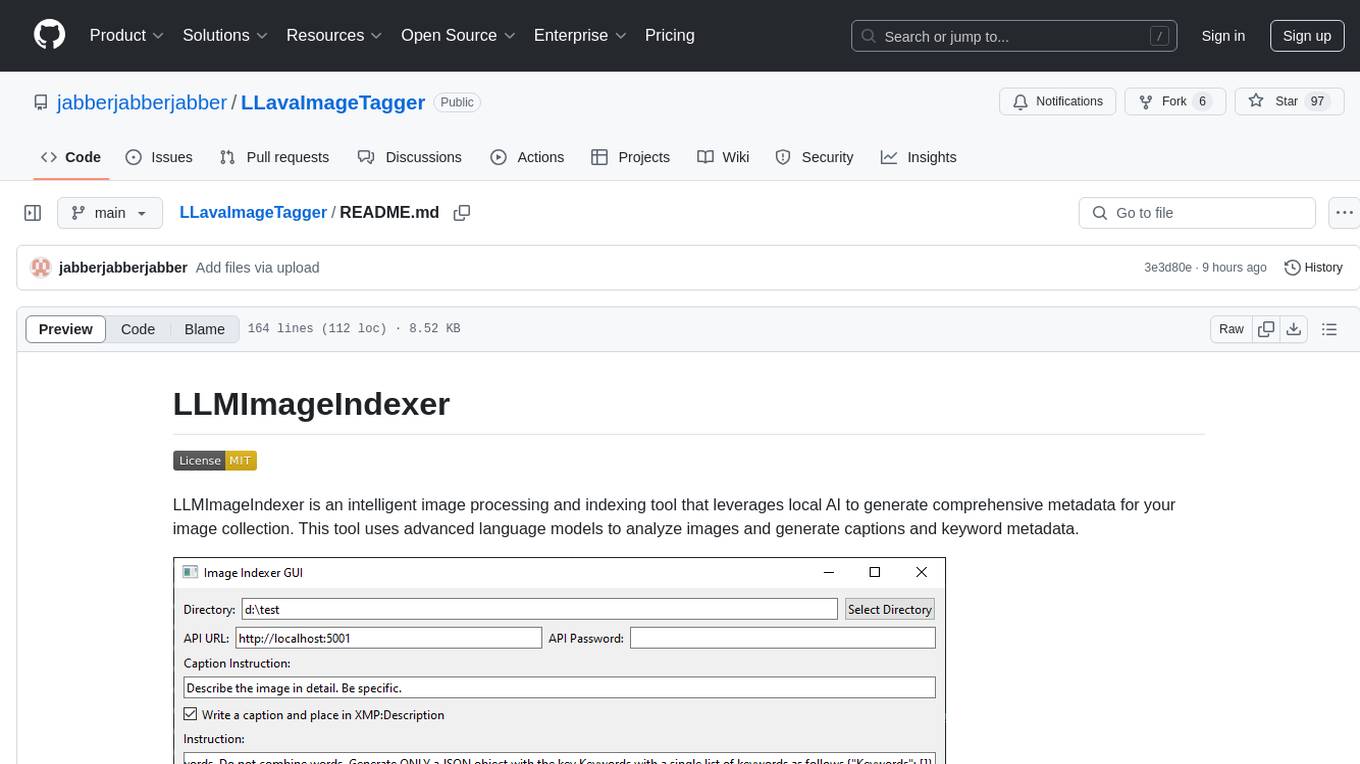
LLavaImageTagger
LLMImageIndexer is an intelligent image processing and indexing tool that leverages local AI to generate comprehensive metadata for your image collection. It uses advanced language models to analyze images and generate captions and keyword metadata. The tool offers features like intelligent image analysis, metadata enhancement, local processing, multi-format support, user-friendly GUI, GPU acceleration, cross-platform support, stop and start capability, and keyword post-processing. It operates directly on image file metadata, allowing users to manage files, add new files, and run the tool multiple times without reprocessing previously keyworded files. Installation instructions are provided for Windows, macOS, and Linux platforms, along with usage guidelines and configuration options.
SunoApi
SunoAPI is an unofficial client for Suno AI, built on Python and Streamlit. It supports functions like generating music and obtaining music information. Users can set up multiple account information to be saved for use. The tool also features built-in maintenance and activation functions for tokens, eliminating concerns about token expiration. It supports multiple languages and allows users to upload pictures for generating songs based on image content analysis.

dataline
DataLine is an AI-driven data analysis and visualization tool designed for technical and non-technical users to explore data quickly. It offers privacy-focused data storage on the user's device, supports various data sources, generates charts, executes queries, and facilitates report building. The tool aims to speed up data analysis tasks for businesses and individuals by providing a user-friendly interface and natural language querying capabilities.
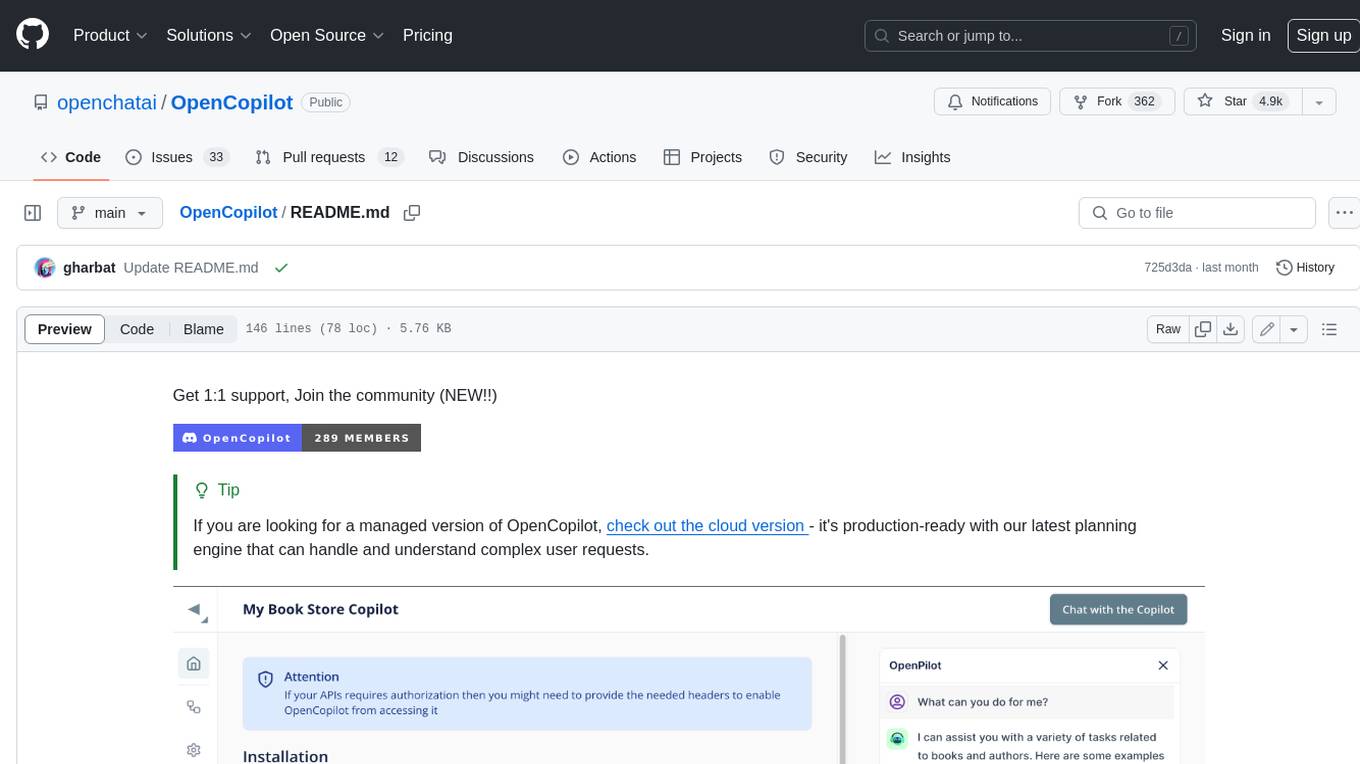
OpenCopilot
OpenCopilot allows you to have your own product's AI copilot. It integrates with your underlying APIs and can execute API calls whenever needed. It uses LLMs to determine if the user's request requires calling an API endpoint. Then, it decides which endpoint to call and passes the appropriate payload based on the given API definition.
SeaGOAT
SeaGOAT is a local search tool that leverages vector embeddings to enable you to search your codebase semantically. It is designed to work on Linux, macOS, and Windows and can process files in various formats, including text, Markdown, Python, C, C++, TypeScript, JavaScript, HTML, Go, Java, PHP, and Ruby. SeaGOAT uses a vector database called ChromaDB and a local vector embedding engine to provide fast and accurate search results. It also supports regular expression/keyword-based matches. SeaGOAT is open-source and licensed under an open-source license, and users are welcome to examine the source code, raise concerns, or create pull requests to fix problems.
extensionOS
Extension | OS is an open-source browser extension that brings AI directly to users' web browsers, allowing them to access powerful models like LLMs seamlessly. Users can create prompts, fix grammar, and access intelligent assistance without switching tabs. The extension aims to revolutionize online information interaction by integrating AI into everyday browsing experiences. It offers features like Prompt Factory for tailored prompts, seamless LLM model access, secure API key storage, and a Mixture of Agents feature. The extension was developed to empower users to unleash their creativity with custom prompts and enhance their browsing experience with intelligent assistance.
bittensor
Bittensor is an internet-scale neural network that incentivizes computers to provide access to machine learning models in a decentralized and censorship-resistant manner. It operates through a token-based mechanism where miners host, train, and procure machine learning systems to fulfill verification problems defined by validators. The network rewards miners and validators for their contributions, ensuring continuous improvement in knowledge output. Bittensor allows anyone to participate, extract value, and govern the network without centralized control. It supports tasks such as generating text, audio, images, and extracting numerical representations.
CyberScraper-2077
CyberScraper 2077 is an advanced web scraping tool powered by AI, designed to extract data from websites with precision and style. It offers a user-friendly interface, supports multiple data export formats, operates in stealth mode to avoid detection, and promises lightning-fast scraping. The tool respects ethical scraping practices, including robots.txt and site policies. With upcoming features like proxy support and page navigation, CyberScraper 2077 is a futuristic solution for data extraction in the digital realm.

cognita
Cognita is an open-source framework to organize your RAG codebase along with a frontend to play around with different RAG customizations. It provides a simple way to organize your codebase so that it becomes easy to test it locally while also being able to deploy it in a production ready environment. The key issues that arise while productionizing RAG system from a Jupyter Notebook are: 1. **Chunking and Embedding Job** : The chunking and embedding code usually needs to be abstracted out and deployed as a job. Sometimes the job will need to run on a schedule or be trigerred via an event to keep the data updated. 2. **Query Service** : The code that generates the answer from the query needs to be wrapped up in a api server like FastAPI and should be deployed as a service. This service should be able to handle multiple queries at the same time and also autoscale with higher traffic. 3. **LLM / Embedding Model Deployment** : Often times, if we are using open-source models, we load the model in the Jupyter notebook. This will need to be hosted as a separate service in production and model will need to be called as an API. 4. **Vector DB deployment** : Most testing happens on vector DBs in memory or on disk. However, in production, the DBs need to be deployed in a more scalable and reliable way. Cognita makes it really easy to customize and experiment everything about a RAG system and still be able to deploy it in a good way. It also ships with a UI that makes it easier to try out different RAG configurations and see the results in real time. You can use it locally or with/without using any Truefoundry components. However, using Truefoundry components makes it easier to test different models and deploy the system in a scalable way. Cognita allows you to host multiple RAG systems using one app. ### Advantages of using Cognita are: 1. A central reusable repository of parsers, loaders, embedders and retrievers. 2. Ability for non-technical users to play with UI - Upload documents and perform QnA using modules built by the development team. 3. Fully API driven - which allows integration with other systems. > If you use Cognita with Truefoundry AI Gateway, you can get logging, metrics and feedback mechanism for your user queries. ### Features: 1. Support for multiple document retrievers that use `Similarity Search`, `Query Decompostion`, `Document Reranking`, etc 2. Support for SOTA OpenSource embeddings and reranking from `mixedbread-ai` 3. Support for using LLMs using `Ollama` 4. Support for incremental indexing that ingests entire documents in batches (reduces compute burden), keeps track of already indexed documents and prevents re-indexing of those docs.
uwazi
Uwazi is a flexible database application designed for capturing and organizing collections of information, with a focus on document management. It is developed and supported by HURIDOCS, benefiting human rights organizations globally. The tool requires NodeJs, ElasticSearch, ICU Analysis Plugin, MongoDB, Yarn, and pdftotext for installation. It offers production and development installation guides, including Docker setup. Uwazi supports hot reloading, unit and integration testing with JEST, and end-to-end testing with Nightmare or Puppeteer. The system requirements include RAM, CPU, and disk space recommendations for on-premises and development usage.

Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.

airbyte_serverless
AirbyteServerless is a lightweight tool designed to simplify the management of Airbyte connectors. It offers a serverless mode for running connectors, allowing users to easily move data from any source to their data warehouse. Unlike the full Airbyte-Open-Source-Platform, AirbyteServerless focuses solely on the Extract-Load process without a UI, database, or transform layer. It provides a CLI tool, 'abs', for managing connectors, creating connections, running jobs, selecting specific data streams, handling secrets securely, and scheduling remote runs. The tool is scalable, allowing independent deployment of multiple connectors. It aims to streamline the connector management process and provide a more agile alternative to the comprehensive Airbyte platform.

LARS
LARS is an application that enables users to run Large Language Models (LLMs) locally on their devices, upload their own documents, and engage in conversations where the LLM grounds its responses with the uploaded content. The application focuses on Retrieval Augmented Generation (RAG) to increase accuracy and reduce AI-generated inaccuracies. LARS provides advanced citations, supports various file formats, allows follow-up questions, provides full chat history, and offers customization options for LLM settings. Users can force enable or disable RAG, change system prompts, and tweak advanced LLM settings. The application also supports GPU-accelerated inferencing, multiple embedding models, and text extraction methods. LARS is open-source and aims to be the ultimate RAG-centric LLM application.
merlinn
Merlinn is an open-source AI-powered on-call engineer that automatically jumps into incidents & alerts, providing useful insights and RCA in real time. It integrates with popular observability tools, lives inside Slack, offers an intuitive UX, and prioritizes security. Users can self-host Merlinn, use it for free, and benefit from automatic RCA, Slack integration, integrations with various tools, intuitive UX, and security features.
For similar tasks
airport-free
Airport-Free is a repository that provides free v2ray and clash nodes for subscription. The nodes are automatically updated every 3 hours. Users can access the v2ray.txt and clash.txt files from the Github repository. The repository includes scripts for v2ray and clash, which can be run to view the output results. It also allows users to submit new nodes through issues on GitHub. The repository aims to provide a convenient and reliable source of nodes for users to access the internet securely and privately.
Wave-executor
Wave Executor is an innovative Windows executor developed by SPDM Team and CodeX engineers, featuring cutting-edge technologies like AI, built-in script hub, HDWID spoofing, and enhanced scripting capabilities. It offers a 100% stealth mode Byfron bypass, advanced features like decompiler and save instance functionality, and a commercial edition with ad-free experience and direct download link. Wave Premium provides multi-instance, multi-inject, and 100% UNC support, making it a cost-effective option for executing scripts in popular Roblox games.

kestra
Kestra is an open-source event-driven orchestration platform that simplifies building scheduled and event-driven workflows. It offers Infrastructure as Code best practices for data, process, and microservice orchestration, allowing users to create reliable workflows using YAML configuration. Key features include everything as code with Git integration, event-driven and scheduled workflows, rich plugin ecosystem for data extraction and script running, intuitive UI with syntax highlighting, scalability for millions of workflows, version control friendly, and various features for structure and resilience. Kestra ensures declarative orchestration logic management even when workflows are modified via UI, API calls, or other methods.
For similar jobs

AirGo
AirGo is a front and rear end separation, multi user, multi protocol proxy service management system, simple and easy to use. It supports vless, vmess, shadowsocks, and hysteria2.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

llm-code-interpreter
The 'llm-code-interpreter' repository is a deprecated plugin that provides a code interpreter on steroids for ChatGPT by E2B. It gives ChatGPT access to a sandboxed cloud environment with capabilities like running any code, accessing Linux OS, installing programs, using filesystem, running processes, and accessing the internet. The plugin exposes commands to run shell commands, read files, and write files, enabling various possibilities such as running different languages, installing programs, starting servers, deploying websites, and more. It is powered by the E2B API and is designed for agents to freely experiment within a sandboxed environment.

pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.

learn-generative-ai
Learn Cloud Applied Generative AI Engineering (GenEng) is a course focusing on the application of generative AI technologies in various industries. The course covers topics such as the economic impact of generative AI, the role of developers in adopting and integrating generative AI technologies, and the future trends in generative AI. Students will learn about tools like OpenAI API, LangChain, and Pinecone, and how to build and deploy Large Language Models (LLMs) for different applications. The course also explores the convergence of generative AI with Web 3.0 and its potential implications for decentralized intelligence.

gcloud-aio
This repository contains shared codebase for two projects: gcloud-aio and gcloud-rest. gcloud-aio is built for Python 3's asyncio, while gcloud-rest is a threadsafe requests-based implementation. It provides clients for Google Cloud services like Auth, BigQuery, Datastore, KMS, PubSub, Storage, and Task Queue. Users can install the library using pip and refer to the documentation for usage details. Developers can contribute to the project by following the contribution guide.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.

aiges
AIGES is a core component of the Athena Serving Framework, designed as a universal encapsulation tool for AI developers to deploy AI algorithm models and engines quickly. By integrating AIGES, you can deploy AI algorithm models and engines rapidly and host them on the Athena Serving Framework, utilizing supporting auxiliary systems for networking, distribution strategies, data processing, etc. The Athena Serving Framework aims to accelerate the cloud service of AI algorithm models and engines, providing multiple guarantees for cloud service stability through cloud-native architecture. You can efficiently and securely deploy, upgrade, scale, operate, and monitor models and engines without focusing on underlying infrastructure and service-related development, governance, and operations.