
auto-md
Convert Files / Folders / GitHub Repos Into AI / LLM-ready Files
Stars: 141
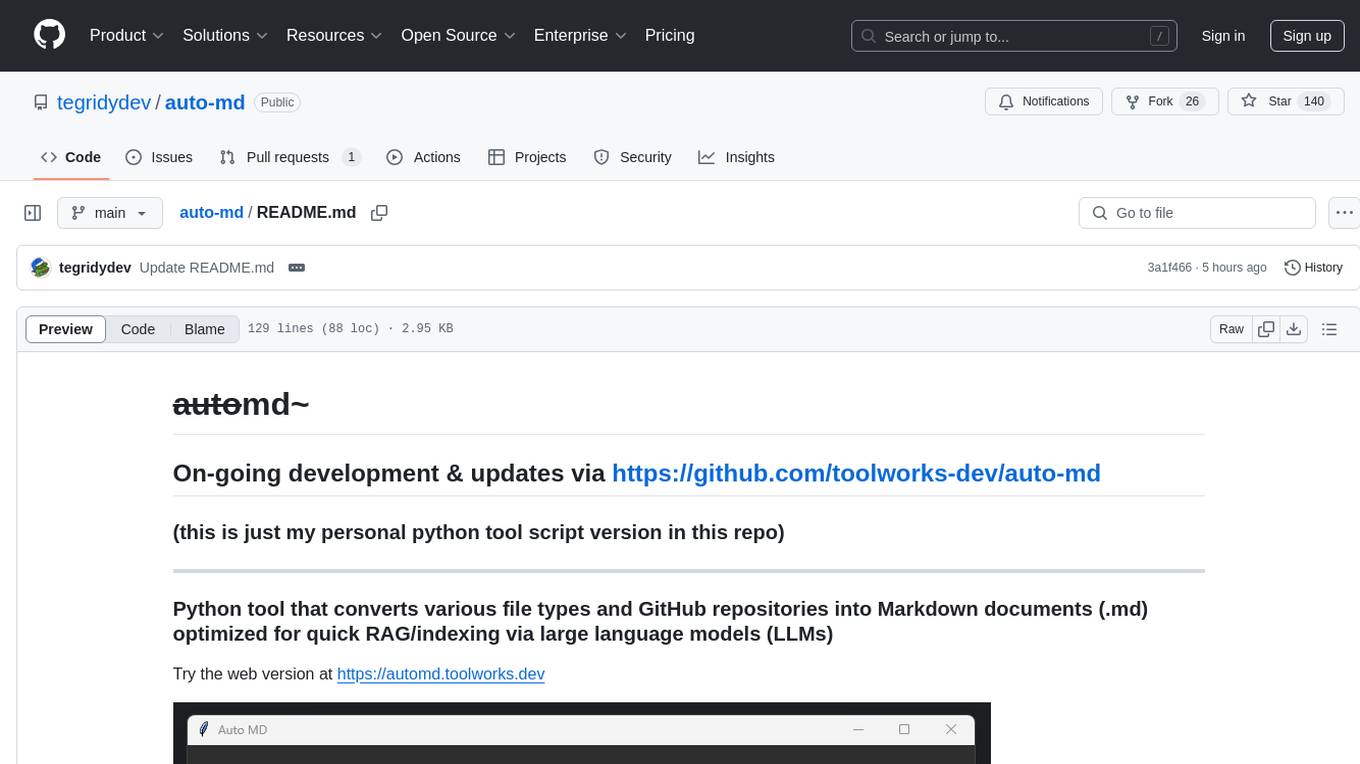
Auto-MD is a Python tool that converts various file types and GitHub repositories into Markdown documents optimized for quick indexing via large language models. It supports multiple file types, processes zip files/folders/individual files and GitHub repositories, generates single or multiple Markdown files, and creates a table of contents and metadata for each processed file.
README:
On-going development & updates via https://github.com/toolworks-dev/auto-md
Python tool that converts various file types and GitHub repositories into Markdown documents (.md) optimized for quick RAG/indexing via large language models (LLMs)
Try the web version at https://automd.toolworks.dev

- Supports multiple file types (see table below)
- Processes zip files/folders/individual files and GitHub repositories
- Generates a single Markdown file or multiple files
- Creates a table of contents and metadata for each file processed
| Category | Extensions |
|---|---|
| Text | .txt, .text, .log |
| Markdown | .md, .markdown, .mdown, .mkdn, .mkd, .mdwn, .mdtxt, .mdtext |
| Web | .html, .htm, .xhtml, .shtml, .css, .scss, .sass, .less |
| Programming | .py, .pyw, .js, .jsx, .ts, .tsx, .java, .c, .cpp, .cs, .go, .rb, .php, .swift, .kt |
| Data | .json, .jsonl, .yaml, .yml, .xml, .csv, .tsv |
| Config | .ini, .cfg, .conf, .config, .toml, .editorconfig |
| Shell | .sh, .bash, .zsh, .fish, .bat, .cmd, .ps1 |
| Other | .rst, .tex, .sql, .r, .lua, .pl, .scala, .clj, .ex, .hs, .ml, .rs, .vim |
-
Install Python 3.7 or newer
-
Download this project (or clone repo like normal):
- Click the green "Code" button above
- Choose "Download ZIP"
- Extract the ZIP file
-
Open a terminal/command prompt and navigate to the extracted folder:
cd path/to/Auto-MD -
Install required packages:
pip install -r requirements.txt -
Run the application:
python main.py -
Use the GUI to:
- Select input files/folders
- Choose output location
- Set processing options
- Click "Start Processing"
Let's say you have the following files in a folder called "my_project":
- README.md
- script.py
- data.json
- styles.css
After processing with Auto MD, you would get a single Markdown file (output.md) that looks like the example below
This single .md file contains all the content from your input files, with a table of contents at the top for easy navigation and referencing / indexing via LLM models
# Auto MD Output
## Table of Contents
- [README](#readme)
- [script](#script)
- [data](#data)
- [styles](#styles)
---
# README
## Metadata
- **Generated on:** 2024-06-30 16:30:15
- **Source:** my_project
(Content of README.md)
---
# script
## Metadata
- **Generated on:** 2024-06-30 16:30:16
- **Source:** my_project
(Content of script.py)
---
# data
## Metadata
- **Generated on:** 2024-06-30 16:30:17
- **Source:** my_project
(Content of data.json)
---
# styles
## Metadata
- **Generated on:** 2024-06-30 16:30:18
- **Source:** my_project
(Content of styles.css)For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for auto-md
Similar Open Source Tools
auto-md
Auto-MD is a Python tool that converts various file types and GitHub repositories into Markdown documents optimized for quick indexing via large language models. It supports multiple file types, processes zip files/folders/individual files and GitHub repositories, generates single or multiple Markdown files, and creates a table of contents and metadata for each processed file.
honey
Bee is an ORM framework that provides easy and high-efficiency database operations, allowing developers to focus on business logic development. It supports various databases and features like automatic filtering, partial field queries, pagination, and JSON format results. Bee also offers advanced functionalities like sharding, transactions, complex queries, and MongoDB ORM. The tool is designed for rapid application development in Java, offering faster development for Java Web and Spring Cloud microservices. The Enterprise Edition provides additional features like financial computing support, automatic value insertion, desensitization, dictionary value conversion, multi-tenancy, and more.
docling
Docling is a tool that bundles PDF document conversion to JSON and Markdown in an easy, self-contained package. It can convert any PDF document to JSON or Markdown format, understand detailed page layout, reading order, recover table structures, extract metadata such as title, authors, references, and language, and optionally apply OCR for scanned PDFs. The tool is designed to be stable, lightning fast, and suitable for macOS and Linux environments.
pyspur
PySpur is a graph-based editor designed for LLM (Large Language Models) workflows. It offers modular building blocks, node-level debugging, and performance evaluation. The tool is easy to hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies. Users can quickly set up PySpur by cloning the repository, creating a .env file, starting docker services, and accessing the portal. PySpur can also work with local models served using Ollama, with steps provided for configuration. The roadmap includes features like canvas, async/batch execution, support for Ollama, new nodes, pipeline optimization, templates, code compilation, multimodal support, and more.

kernel-memory
Kernel Memory (KM) is a multi-modal AI Service specialized in the efficient indexing of datasets through custom continuous data hybrid pipelines, with support for Retrieval Augmented Generation (RAG), synthetic memory, prompt engineering, and custom semantic memory processing. KM is available as a Web Service, as a Docker container, a Plugin for ChatGPT/Copilot/Semantic Kernel, and as a .NET library for embedded applications. Utilizing advanced embeddings and LLMs, the system enables Natural Language querying for obtaining answers from the indexed data, complete with citations and links to the original sources. Designed for seamless integration as a Plugin with Semantic Kernel, Microsoft Copilot and ChatGPT, Kernel Memory enhances data-driven features in applications built for most popular AI platforms.
nexus
Nexus is a virtual filesystem server designed for AI agents, offering a unified path-based API that integrates files, databases, APIs, and SaaS tools. It provides built-in permissions, memory management, semantic search, and skills lifecycle management. The Nexus Control Panel allows humans to curate files, memories, permissions, and integrations for agents, ensuring oversight and control while agents focus on execution. The repository includes the open-source server, SDK, CLI, and examples, catering to the needs of AI-native filesystems for cognitive agents.
aichat
Aichat is an AI-powered CLI chat and copilot tool that seamlessly integrates with over 10 leading AI platforms, providing a powerful combination of chat-based interaction, context-aware conversations, and AI-assisted shell capabilities, all within a customizable and user-friendly environment.
ClaudeBar
ClaudeBar is a macOS menu bar application that monitors AI coding assistant usage quotas. It allows users to keep track of their usage of Claude, Codex, Gemini, GitHub Copilot, Antigravity, and Z.ai at a glance. The application offers multi-provider support, real-time quota tracking, multiple themes, visual status indicators, system notifications, auto-refresh feature, and keyboard shortcuts for quick access. Users can customize monitoring by toggling individual providers on/off and receive alerts when quota status changes. The tool requires macOS 15+, Swift 6.2+, and CLI tools installed for the providers to be monitored.
canvas-editor
Canvas Editor is a web-based tool that allows users to create and edit images and graphics directly in the browser. It provides a user-friendly interface with features such as drawing tools, shapes, text editing, and image manipulation. Users can easily customize their designs and export them in various formats. The tool is suitable for graphic designers, web developers, artists, educators, and hobbyists who need a simple yet powerful tool for creating visual content.

screenpipe
Screenpipe is an open source application that turns your computer into a personal AI, capturing screen and audio to create a searchable memory of your activities. It allows you to remember everything, search with AI, and keep your data 100% local. The tool is designed for knowledge workers, developers, researchers, people with ADHD, remote workers, and anyone looking for a private, local-first alternative to cloud-based AI memory tools.
NeuroSandboxWebUI
A simple and convenient interface for using various neural network models. Users can interact with LLM using text, voice, and image input to generate images, videos, 3D objects, music, and audio. The tool supports a wide range of models for different tasks such as image generation, video generation, audio file separation, voice conversion, and more. Users can also view files from the outputs directory in a gallery, download models, change application settings, and check system sensors. The goal of the project is to create an easy-to-use application for utilizing neural network models.

OSA
OSA (Open-Source-Advisor) is a tool designed to improve the quality of scientific open source projects by automating the generation of README files, documentation, CI/CD scripts, and providing advice and recommendations for repositories. It supports various LLMs accessible via API, local servers, or osa_bot hosted on ITMO servers. OSA is currently under development with features like README file generation, documentation generation, automatic implementation of changes, LLM integration, and GitHub Action Workflow generation. It requires Python 3.10 or higher and tokens for GitHub/GitLab/Gitverse and LLM API key. Users can install OSA using PyPi or build from source, and run it using CLI commands or Docker containers.

EvoAgentX
EvoAgentX is an open-source framework for building, evaluating, and evolving LLM-based agents or agentic workflows in an automated, modular, and goal-driven manner. It enables developers and researchers to move beyond static prompt chaining or manual workflow orchestration by introducing a self-evolving agent ecosystem. The framework includes features such as agent workflow autoconstruction, built-in evaluation, self-evolution engine, plug-and-play compatibility, comprehensive built-in tools, memory module support, and human-in-the-loop interactions.
pixeltable
Pixeltable is a Python library designed for ML Engineers and Data Scientists to focus on exploration, modeling, and app development without the need to handle data plumbing. It provides a declarative interface for working with text, images, embeddings, and video, enabling users to store, transform, index, and iterate on data within a single table interface. Pixeltable is persistent, acting as a database unlike in-memory Python libraries such as Pandas. It offers features like data storage and versioning, combined data and model lineage, indexing, orchestration of multimodal workloads, incremental updates, and automatic production-ready code generation. The tool emphasizes transparency, reproducibility, cost-saving through incremental data changes, and seamless integration with existing Python code and libraries.

R2R
R2R (RAG to Riches) is a fast and efficient framework for serving high-quality Retrieval-Augmented Generation (RAG) to end users. The framework is designed with customizable pipelines and a feature-rich FastAPI implementation, enabling developers to quickly deploy and scale RAG-based applications. R2R was conceived to bridge the gap between local LLM experimentation and scalable production solutions. **R2R is to LangChain/LlamaIndex what NextJS is to React**. A JavaScript client for R2R deployments can be found here. ### Key Features * **🚀 Deploy** : Instantly launch production-ready RAG pipelines with streaming capabilities. * **🧩 Customize** : Tailor your pipeline with intuitive configuration files. * **🔌 Extend** : Enhance your pipeline with custom code integrations. * **⚖️ Autoscale** : Scale your pipeline effortlessly in the cloud using SciPhi. * **🤖 OSS** : Benefit from a framework developed by the open-source community, designed to simplify RAG deployment.
conduit
Conduit is an open-source, cross-platform mobile application for Open-WebUI, providing a native mobile experience for interacting with your self-hosted AI infrastructure. It supports real-time chat, model selection, conversation management, markdown rendering, theme support, voice input, file uploads, multi-modal support, secure storage, folder management, and tools invocation. Conduit offers multiple authentication flows and follows a clean architecture pattern with Riverpod for state management, Dio for HTTP networking, WebSocket for real-time streaming, and Flutter Secure Storage for credential management.
For similar tasks

MegaParse
MegaParse is a powerful and versatile parser designed to handle various types of documents such as text, PDFs, Powerpoint presentations, and Word documents with no information loss. It is fast, efficient, and open source, supporting a wide range of file formats. MegaParse ensures compatibility with tables, table of contents, headers, footers, and images, making it a comprehensive solution for document parsing.
auto-md
Auto-MD is a Python tool that converts various file types and GitHub repositories into Markdown documents optimized for quick indexing via large language models. It supports multiple file types, processes zip files/folders/individual files and GitHub repositories, generates single or multiple Markdown files, and creates a table of contents and metadata for each processed file.
chunkr
Chunkr is an open-source document intelligence API that provides a production-ready service for document layout analysis, OCR, and semantic chunking. It allows users to convert PDFs, PPTs, Word docs, and images into RAG/LLM-ready chunks. The API offers features such as layout analysis, OCR with bounding boxes, structured HTML and markdown output, and VLM processing controls. Users can interact with Chunkr through a Python SDK, enabling them to upload documents, process them, and export results in various formats. The tool also supports self-hosted deployment options using Docker Compose or Kubernetes, with configurations for different AI models like OpenAI, Google AI Studio, and OpenRouter. Chunkr is dual-licensed under the GNU Affero General Public License v3.0 (AGPL-3.0) and a commercial license, providing flexibility for different usage scenarios.
markdowner
Markdowner is a fast tool designed to convert any website into LLM-ready markdown data. It aims to improve the quality of responses in the AI app Supermemory by structuring and predicting data in markdown format. The tool offers features such as website conversion, LLM filtering, detailed markdown mode, auto crawler, text and JSON responses, and easy self-hosting. Markdowner utilizes Cloudflare's Browser rendering and Durable objects for browser instance creation and markdown conversion. Users can self-host the project with the Workers paid plan, following simple steps. Support the project by starring the repository.
turing
Viglet Turing ES is an open source solution with Semantic Navigation and Chat bot features. It indexes all content in Solr as a search engine.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

mikupad
mikupad is a lightweight and efficient language model front-end powered by ReactJS, all packed into a single HTML file. Inspired by the likes of NovelAI, it provides a simple yet powerful interface for generating text with the help of various backends.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

firecrawl
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown. It crawls all accessible subpages and provides clean markdown for each, without requiring a sitemap. The API is easy to use and can be self-hosted. It also integrates with Langchain and Llama Index. The Python SDK makes it easy to crawl and scrape websites in Python code.