
sidemantic
A universal metrics layer. Compatible with LookML, MetricFlow, Cube via DuckDB, Snowflake, Clickhouse, Bigquery & more!
Stars: 51
Sidemantic is a SQL-first semantic layer tool designed to provide consistent metrics across various databases and semantic model formats. It offers features like automatic joins, multi-format adapters, SQL query interface, pre-aggregations, and more. Users can define models in SQL, YAML, or Python and query via CLI or Python API. The tool supports databases like DuckDB, PostgreSQL, BigQuery, Snowflake, ClickHouse, Databricks, and Spark SQL. Sidemantic is ideal for users looking to streamline their data analysis process and ensure data consistency across different platforms.
README:
SQL-first semantic layer for consistent metrics across your data stack. Compatible with many other semantic model formats.
- Formats: Sidemantic, Cube, MetricFlow (dbt), LookML, Hex, Rill, Superset, Omni, BSL, GoodData LDM, Snowflake Cortex, Malloy, OSI, AtScale SML, ThoughtSpot TML
- Databases: DuckDB, MotherDuck, PostgreSQL, BigQuery, Snowflake, ClickHouse, Databricks, Spark SQL
Documentation | GitHub | Discord | Demo (50+ MB download)

Sidemantic is a very ambitious and young semantic layer project. You may encounter rough patches, especially with the more exotic features like converting between semantic model formats.
Issue reports are much appreciated if you try out Sidemantic and hit a snag 🫡
Install:
uv add sidemanticMalloy support (uv):
uv add "sidemantic[malloy]"Notebook widget (uv):
uv add "sidemantic[widget]" jupyterlab
uv run jupyter labMarimo (uv):
uv add "sidemantic[widget]" marimo
uv run marimo editimport duckdb
from sidemantic.widget import MetricsExplorer
conn = duckdb.connect(":memory:")
conn.execute("create table t as select 1 as value, 'a' as category, date '2024-01-01' as d")
MetricsExplorer(conn.table("t"), time_dimension="d")Define models in SQL, YAML, or Python:
SQL (orders.sql)
MODEL (name orders, table orders, primary_key order_id);
DIMENSION (name status, type categorical);
DIMENSION (name order_date, type time, granularity day);
METRIC (name revenue, agg sum, sql amount);
METRIC (name order_count, agg count);YAML (orders.yml)
models:
- name: orders
table: orders
primary_key: order_id
dimensions:
- name: status
type: categorical
- name: order_date
type: time
granularity: day
metrics:
- name: revenue
agg: sum
sql: amount
- name: order_count
agg: countPython (programmatic)
from sidemantic import Model, Dimension, Metric
orders = Model(
name="orders",
table="orders",
primary_key="order_id",
dimensions=[
Dimension(name="status", type="categorical"),
Dimension(name="order_date", type="time", granularity="day"),
],
metrics=[
Metric(name="revenue", agg="sum", sql="amount"),
Metric(name="order_count", agg="count"),
]
)Query via CLI:
sidemantic query "SELECT revenue, status FROM orders" --db data.duckdbOr Python API:
from sidemantic import SemanticLayer, load_from_directory
layer = SemanticLayer(connection="duckdb:///data.duckdb")
load_from_directory(layer, "models/")
result = layer.sql("SELECT revenue, status FROM orders")# Query
sidemantic query "SELECT revenue FROM orders" --db data.duckdb
# Interactive workbench (TUI with SQL editor + charts)
sidemantic workbench models/ --db data.duckdb
# PostgreSQL server (connect Tableau, DBeaver, etc.)
sidemantic serve models/ --port 5433
# Validate definitions
sidemantic validate models/
# Model info
sidemantic info models/
# Pre-aggregation recommendations
sidemantic preagg recommend --db data.duckdb
# Migrate SQL queries to semantic layer
sidemantic migrator --queries legacy/ --generate-models output/Workbench (TUI with SQL editor + charts):
uvx sidemantic workbench --demoPostgreSQL server (connect Tableau, DBeaver, etc.):
uvx sidemantic serve --demo --port 5433Colab notebooks:
SQL + DuckDB
LookML multi-entity
SQL syntax:
uv run https://raw.githubusercontent.com/sidequery/sidemantic/main/examples/sql/sql_syntax_example.pyComprehensive demo:
uv run https://raw.githubusercontent.com/sidequery/sidemantic/main/examples/advanced/comprehensive_demo.pySymmetric aggregates:
uv run https://raw.githubusercontent.com/sidequery/sidemantic/main/examples/features/symmetric_aggregates_example.pySuperset with DuckDB:
git clone https://github.com/sidequery/sidemantic.git && cd sidemantic
uv run examples/superset_demo/run_demo.pyCube Playground:
git clone https://github.com/sidequery/sidemantic.git && cd sidemantic
uv run examples/cube_demo/run_demo.pyRill Developer:
git clone https://github.com/sidequery/sidemantic.git && cd sidemantic
uv run examples/rill_demo/run_demo.pyOSI (complex adtech semantic model):
git clone https://github.com/sidequery/sidemantic.git && cd sidemantic
uv run examples/osi_demo/run_demo.pyOSI widget notebook (percent-cell Python notebook):
git clone https://github.com/sidequery/sidemantic.git && cd sidemantic
uv run examples/osi_demo/osi_widget_notebook.pySee examples/ for more.
- SQL query interface with automatic rewriting
- Automatic joins across models
- Multi-format adapters (Cube, MetricFlow, LookML, Hex, Rill, Superset, Omni, BSL, GoodData LDM, OSI, AtScale SML, ThoughtSpot TML)
- SQLGlot-based SQL generation and transpilation
- Pydantic validation and type safety
- Pre-aggregations with automatic routing
- Predicate pushdown for faster queries
- Segments and metric-level filters
- Jinja2 templating for dynamic SQL
- PostgreSQL wire protocol server for BI tools
Auto-detects: Sidemantic (SQL/YAML), Cube, MetricFlow (dbt), LookML, Hex, Rill, Superset, Omni, BSL, GoodData LDM, OSI, AtScale SML, ThoughtSpot TML
sidemantic query "SELECT revenue FROM orders" --models ./my_modelsfrom sidemantic import SemanticLayer, load_from_directory
layer = SemanticLayer(connection="duckdb:///data.duckdb")
load_from_directory(layer, "my_models/") # Auto-detects formats| Database | Status | Installation |
|---|---|---|
| DuckDB | ✅ | built-in |
| MotherDuck | ✅ | built-in |
| PostgreSQL | ✅ | uv add sidemantic[postgres] |
| BigQuery | ✅ | uv add sidemantic[bigquery] |
| Snowflake | ✅ | uv add sidemantic[snowflake] |
| ClickHouse | ✅ | uv add sidemantic[clickhouse] |
| Databricks | ✅ | uv add sidemantic[databricks] |
| Spark SQL | ✅ | uv add sidemantic[spark] |
uv run pytest -vFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for sidemantic
Similar Open Source Tools
sidemantic
Sidemantic is a SQL-first semantic layer tool designed to provide consistent metrics across various databases and semantic model formats. It offers features like automatic joins, multi-format adapters, SQL query interface, pre-aggregations, and more. Users can define models in SQL, YAML, or Python and query via CLI or Python API. The tool supports databases like DuckDB, PostgreSQL, BigQuery, Snowflake, ClickHouse, Databricks, and Spark SQL. Sidemantic is ideal for users looking to streamline their data analysis process and ensure data consistency across different platforms.
adk-rust
ADK-Rust is a comprehensive and production-ready Rust framework for building AI agents. It features type-safe agent abstractions with async execution and event streaming, multiple agent types including LLM agents, workflow agents, and custom agents, realtime voice agents with bidirectional audio streaming, a tool ecosystem with function tools, Google Search, and MCP integration, production features like session management, artifact storage, memory systems, and REST/A2A APIs, and a developer-friendly experience with interactive CLI, working examples, and comprehensive documentation. The framework follows a clean layered architecture and is production-ready and actively maintained.
augustus
Augustus is a Go-based LLM vulnerability scanner designed for security professionals to test large language models against a wide range of adversarial attacks. It integrates with 28 LLM providers, covers 210+ adversarial attacks including prompt injection, jailbreaks, encoding exploits, and data extraction, and produces actionable vulnerability reports. The tool is built for production security testing with features like concurrent scanning, rate limiting, retry logic, and timeout handling out of the box.

probe
Probe is an AI-friendly, fully local, semantic code search tool designed to power the next generation of AI coding assistants. It combines the speed of ripgrep with the code-aware parsing of tree-sitter to deliver precise results with complete code blocks, making it perfect for large codebases and AI-driven development workflows. Probe supports various features like AI-friendly code extraction, fully local operation without external APIs, fast scanning of large codebases, accurate code structure parsing, re-rankers and NLP methods for better search results, multi-language support, interactive AI chat mode, and flexibility to run as a CLI tool, MCP server, or interactive AI chat.
json-io
json-io is a powerful and lightweight Java library that simplifies JSON5, JSON, and TOON serialization and deserialization while handling complex object graphs with ease. It preserves object references, handles polymorphic types, and maintains cyclic relationships in data structures. It offers full JSON5 support, TOON read/write capabilities, and is compatible with JDK 1.8 through JDK 24. The library is built with a focus on correctness over speed, providing extensive configuration options and two modes for data representation. json-io is designed for developers who require advanced serialization features and support for various Java types without external dependencies.
git-mcp-server
A secure and scalable Git MCP server providing AI agents with powerful version control capabilities for local and serverless environments. It offers 28 comprehensive Git operations organized into seven functional categories, resources for contextual information about the Git environment, and structured prompt templates for guiding AI agents through complex workflows. The server features declarative tools, robust error handling, pluggable authentication, abstracted storage, full-stack observability, dependency injection, and edge-ready architecture. It also includes specialized features for Git integration such as cross-runtime compatibility, provider-based architecture, optimized Git execution, working directory management, configurable Git identity, safety features, and commit signing.

dexto
Dexto is a lightweight runtime for creating and running AI agents that turn natural language into real-world actions. It serves as the missing intelligence layer for building AI applications, standalone chatbots, or as the reasoning engine inside larger products. Dexto features a powerful CLI and Web UI for running AI agents, supports multiple interfaces, allows hot-swapping of LLMs from various providers, connects to remote tool servers via the Model Context Protocol, is config-driven with version-controlled YAML, offers production-ready core features, extensibility for custom services, and enables multi-agent collaboration via MCP and A2A.
mcp-devtools
MCP DevTools is a high-performance server written in Go that replaces multiple Node.js and Python-based servers. It provides access to essential developer tools through a unified, modular interface. The server is efficient, with minimal memory footprint and fast response times. It offers a comprehensive tool suite for agentic coding, including 20+ essential developer agent tools. The tool registry allows for easy addition of new tools. The server supports multiple transport modes, including STDIO, HTTP, and SSE. It includes a security framework for multi-layered protection and a plugin system for adding new tools.

tokscale
Tokscale is a high-performance CLI tool and visualization dashboard for tracking token usage and costs across multiple AI coding agents. It helps monitor and analyze token consumption from various AI coding tools, providing real-time pricing calculations using LiteLLM's pricing data. Inspired by the Kardashev scale, Tokscale measures token consumption as users scale the ranks of AI-augmented development. It offers interactive TUI mode, multi-platform support, real-time pricing, detailed breakdowns, web visualization, flexible filtering, and social platform features.

FDAbench
FDABench is a benchmark tool designed for evaluating data agents' reasoning ability over heterogeneous data in analytical scenarios. It offers 2,007 tasks across various data sources, domains, difficulty levels, and task types. The tool provides ready-to-use data agent implementations, a DAG-based evaluation system, and a framework for agent-expert collaboration in dataset generation. Key features include data agent implementations, comprehensive evaluation metrics, multi-database support, different task types, extensible framework for custom agent integration, and cost tracking. Users can set up the environment using Python 3.10+ on Linux, macOS, or Windows. FDABench can be installed with a one-command setup or manually. The tool supports API configuration for LLM access and offers quick start guides for database download, dataset loading, and running examples. It also includes features like dataset generation using the PUDDING framework, custom agent integration, evaluation metrics like accuracy and rubric score, and a directory structure for easy navigation.
ck
ck (seek) is a semantic grep tool that finds code by meaning, not just keywords. It replaces traditional grep by understanding the user's search intent. It allows users to search for code based on concepts like 'error handling' and retrieves relevant code even if the exact keywords are not present. ck offers semantic search, drop-in grep compatibility, hybrid search combining keyword precision with semantic understanding, agent-friendly output in JSONL format, smart file filtering, and various advanced features. It supports multiple search modes, relevance scoring, top-K results, and smart exclusions. Users can index projects for semantic search, choose embedding models, and search specific files or directories. The tool is designed to improve code search efficiency and accuracy for developers and AI agents.

lingo.dev
Replexica AI automates software localization end-to-end, producing authentic translations instantly across 60+ languages. Teams can do localization 100x faster with state-of-the-art quality, reaching more paying customers worldwide. The tool offers a GitHub Action for CI/CD automation and supports various formats like JSON, YAML, CSV, and Markdown. With lightning-fast AI localization, auto-updates, native quality translations, developer-friendly CLI, and scalability for startups and enterprise teams, Replexica is a top choice for efficient and effective software localization.
atlas-mcp-server
ATLAS (Adaptive Task & Logic Automation System) is a high-performance Model Context Protocol server designed for LLMs to manage complex task hierarchies. Built with TypeScript, it features ACID-compliant storage, efficient task tracking, and intelligent template management. ATLAS provides LLM Agents task management through a clean, flexible tool interface. The server implements the Model Context Protocol (MCP) for standardized communication between LLMs and external systems, offering hierarchical task organization, task state management, smart templates, enterprise features, and performance optimization.
OpenMemory
OpenMemory is a cognitive memory engine for AI agents, providing real long-term memory capabilities beyond simple embeddings. It is self-hosted and supports Python + Node SDKs, with integrations for various tools like LangChain, CrewAI, AutoGen, and more. Users can ingest data from sources like GitHub, Notion, Google Drive, and others directly into memory. OpenMemory offers explainable traces for recalled information and supports multi-sector memory, temporal reasoning, decay engine, waypoint graph, and more. It aims to provide a true memory system rather than just a vector database with marketing copy, enabling users to build agents, copilots, journaling systems, and coding assistants that can remember and reason effectively.
flyte-sdk
Flyte 2 SDK is a pure Python tool for type-safe, distributed orchestration of agents, ML pipelines, and more. It allows users to write data pipelines, ML training jobs, and distributed compute in Python without any DSL constraints. With features like async-first parallelism and fine-grained observability, Flyte 2 offers a seamless workflow experience. Users can leverage core concepts like TaskEnvironments for container configuration, pure Python workflows for flexibility, and async parallelism for distributed execution. Advanced features include sub-task observability with tracing and remote task execution. The tool also provides native Jupyter integration for running and monitoring workflows directly from notebooks. Configuration and deployment are made easy with configuration files and commands for deploying and running workflows. Flyte 2 is licensed under the Apache 2.0 License.
localgpt
LocalGPT is a local device focused AI assistant built in Rust, providing persistent memory and autonomous tasks. It runs entirely on your machine, ensuring your memory data stays private. The tool offers a markdown-based knowledge store with full-text and semantic search capabilities, hybrid web search, and multiple interfaces including CLI, web UI, desktop GUI, and Telegram bot. It supports multiple LLM providers, is OpenClaw compatible, and offers defense-in-depth security features such as signed policy files, kernel-enforced sandbox, and prompt injection defenses. Users can configure web search providers, use OAuth subscription plans, and access the tool from Telegram for chat, tool use, and memory support.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs
vscode-dbt-power-user
The vscode-dbt-power-user is an open-source extension that enhances the functionality of Visual Studio Code to seamlessly work with dbt™. It provides features such as auto-complete for dbt™ code, previewing query results, column lineage visualization, generating dbt™ models, documentation generation, deferring model builds, running parent/child models and tests with a click, compiled query preview and explanation, project health check, SQL validation, BigQuery cost estimation, and other features like dbt™ logs viewer. The extension is fully compatible with dev containers, code spaces, and remote extensions, supporting dbt™ versions above 1.0.

SheetCopilot
SheetCopilot is an assistant agent that manipulates spreadsheets by following user commands. It leverages Large Language Models (LLMs) to interact with spreadsheets like a human expert, enabling non-expert users to complete tasks on complex software such as Google Sheets and Excel via a language interface. The tool observes spreadsheet states, polishes generated solutions based on external action documents and error feedback, and aims to improve success rate and efficiency. SheetCopilot offers a dataset with diverse task categories and operations, supporting operations like entry & manipulation, management, formatting, charts, and pivot tables. Users can interact with SheetCopilot in Excel or Google Sheets, executing tasks like calculating revenue, creating pivot tables, and plotting charts. The tool's evaluation includes performance comparisons with leading LLMs and VBA-based methods on specific datasets, showcasing its capabilities in controlling various aspects of a spreadsheet.

wren-engine
Wren Engine is a semantic engine designed to serve as the backbone of the semantic layer for LLMs. It simplifies the user experience by translating complex data structures into a business-friendly format, enabling end-users to interact with data using familiar terminology. The engine powers the semantic layer with advanced capabilities to define and manage modeling definitions, metadata, schema, data relationships, and logic behind calculations and aggregations through an analytics-as-code design approach. By leveraging Wren Engine, organizations can ensure a developer-friendly semantic layer that reflects nuanced data relationships and dynamics, facilitating more informed decision-making and strategic insights.
mslearn-knowledge-mining
The mslearn-knowledge-mining repository contains lab files for Azure AI Knowledge Mining modules. It provides resources for learning and implementing knowledge mining techniques using Azure AI services. The repository is designed to help users explore and understand how to leverage AI for knowledge mining purposes within the Azure ecosystem.

extension-gen-ai
The Looker GenAI Extension provides code examples and resources for building a Looker Extension that integrates with Vertex AI Large Language Models (LLMs). Users can leverage the power of LLMs to enhance data exploration and analysis within Looker. The extension offers generative explore functionality to ask natural language questions about data and generative insights on dashboards to analyze data by asking questions. It leverages components like BQML Remote Models, BQML Remote UDF with Vertex AI, and Custom Fine Tune Model for different integration options. Deployment involves setting up infrastructure with Terraform and deploying the Looker Extension by creating a Looker project, copying extension files, configuring BigQuery connection, connecting to Git, and testing the extension. Users can save example prompts and configure user settings for the extension. Development of the Looker Extension environment includes installing dependencies, starting the development server, and building for production.
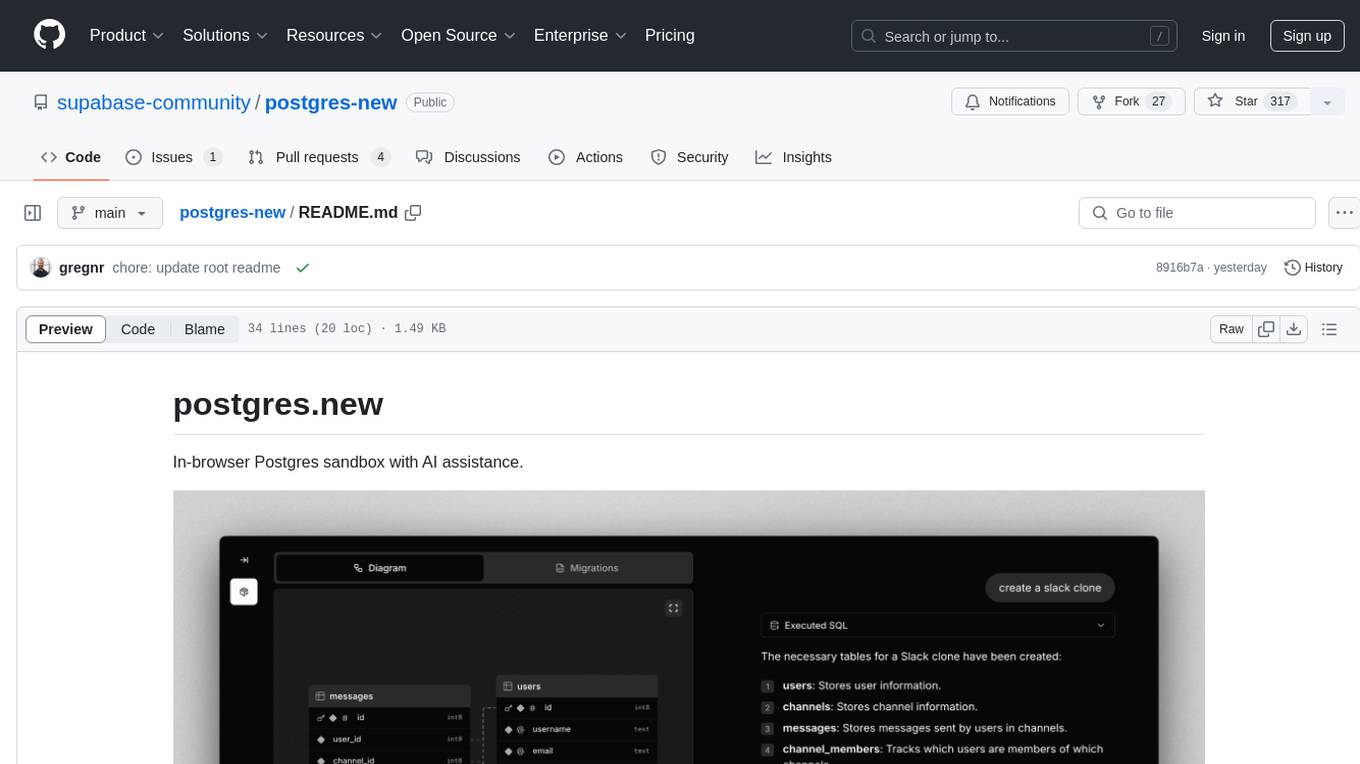
postgres-new
Postgres.new is an in-browser Postgres sandbox with AI assistance that allows users to spin up unlimited Postgres databases directly in the browser. Each database comes with a large language model (LLM) enabling features like drag-and-drop CSV import, report generation, chart creation, and database diagram building. The tool utilizes PGlite, a WASM version of Postgres, to run databases in the browser and store data in IndexedDB for persistence. The monorepo includes a frontend built with Next.js and a backend serving S3-backed PGlite databases over the PG wire protocol using pg-gateway.

text-to-sql-bedrock-workshop
This repository focuses on utilizing generative AI to bridge the gap between natural language questions and SQL queries, aiming to improve data consumption in enterprise data warehouses. It addresses challenges in SQL query generation, such as foreign key relationships and table joins, and highlights the importance of accuracy metrics like Execution Accuracy (EX) and Exact Set Match Accuracy (EM). The workshop content covers advanced prompt engineering, Retrieval Augmented Generation (RAG), fine-tuning models, and security measures against prompt and SQL injections.
airflow-provider-great-expectations
The 'airflow-provider-great-expectations' repository contains a set of Airflow operators for Great Expectations, a Python library used for testing and validating data. The operators enable users to run Great Expectations validations and checks within Apache Airflow workflows. The package requires Airflow 2.1.0+ and Great Expectations >=v0.13.9. It provides functionalities to work with Great Expectations V3 Batch Request API, Checkpoints, and allows passing kwargs to Checkpoints at runtime. The repository includes modules for a base operator and examples of DAGs with sample tasks demonstrating the operator's functionality.