
solon
🔥 Java enterprise application development framework for full scenario: Restrained, Efficient, Open, Ecologicalll!!! 700% higher concurrency 50% memory savings Startup is 10 times faster. Packing 90% smaller; Compatible with java8 ~ java24. (Replaceable spring)
Stars: 2624
Solon is a Java enterprise application development framework that is restrained, efficient, and open. It offers better cost performance for computing resources with 700% higher concurrency and 50% memory savings. It enables faster development productivity with less code and easy startup, 10 times faster than traditional methods. Solon provides a better production and deployment experience by packing applications 90% smaller. It supports a greater range of compatibility with non-Java-EE architecture and compatibility with Java 8 to Java 24, including GraalVM native image support. Solon is built from scratch with flexible interface specifications and an open ecosystem.
README:
Java enterprise application development framework for full scenario: Restrained, Efficient, Open
[OpenAtom foundation, incubation project]



700% higher concurrency 50% memory savings Startup is 10 times faster. Packing 90% smaller; It also supports java8 ~ java24, native runtime.
Built from scratch, with more flexible interface specifications and an open ecosystem
| Feature | Description |
|---|---|
| Better cost performance for computing resources | 700% higher concurrency(techempower), 50% memory savings |
| Faster development productivity | Less code; Easy to get started; 10x faster startup (faster debugging) |
| Better production and deployment experience | Pack 90% smaller |
| Greater range of compatibility | Non-java-ee architecture; It also supports java8 ~ java24, graalvm native image |
| Code repository | Description |
|---|---|
| /opensolon/solon | Solon ,Main code repository |
| /opensolon/solon-examples | Solon ,Official website supporting sample code repository |
| /opensolon/solon-expression | Solon Expression ,Code repository |
| /opensolon/solon-flow | Solon Flow ,Code repository |
| /opensolon/solon-ai | Solon Ai ,Code repository |
| /opensolon/solon-cloud | Solon Cloud ,Code repository |
| /opensolon/solon-admin | Solon Admin ,Code repository |
| /opensolon/solon-jakarta | Solon Jakarta ,Code repository(base java21) |
| /opensolon/solon-integration | Solon Integration ,Code repository |
| /opensolon/solon-gradle-plugin | Solon Gradle ,Plugin code repository |
| /opensolon/solon-idea-plugin | Solon Idea ,Plugin code repository |
| /opensolon/solon-vscode-plugin | Solon VsCode ,Plugin code repository |
- solon

- solon cloud

- Official website address:https://solon.noear.org
- Official website supporting demos:https://gitee.com/opensolon/solon-examples
- Project unit test:__test
- User case:User open source project、User business project

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for solon
Similar Open Source Tools
solon
Solon is a Java enterprise application development framework that is restrained, efficient, and open. It offers better cost performance for computing resources with 700% higher concurrency and 50% memory savings. It enables faster development productivity with less code and easy startup, 10 times faster than traditional methods. Solon provides a better production and deployment experience by packing applications 90% smaller. It supports a greater range of compatibility with non-Java-EE architecture and compatibility with Java 8 to Java 24, including GraalVM native image support. Solon is built from scratch with flexible interface specifications and an open ecosystem.
llumen
Llumen is a self-hosted interface optimized for modest hardware like Raspberry Pi, old laptops, and minimal VPS. It offers privacy without complexity, providing essential features with minimal resource demands. Users can enjoy sub-second cold starts, real-time token streaming, various chat modes, rich media support, and a universal API for OpenAI-compatible providers. The tool has a small footprint with a binary size of around 17MB and RAM usage under 128MB. Llumen aims to simplify the setup process and offer a user-friendly experience for individuals seeking a privacy-focused solution.
rag-web-ui
RAG Web UI is an intelligent dialogue system based on RAG (Retrieval-Augmented Generation) technology. It helps enterprises and individuals build intelligent Q&A systems based on their own knowledge bases. By combining document retrieval and large language models, it delivers accurate and reliable knowledge-based question-answering services. The system is designed with features like intelligent document management, advanced dialogue engine, and a robust architecture. It supports multiple document formats, async document processing, multi-turn contextual dialogue, and reference citations in conversations. The architecture includes a backend stack with Python FastAPI, MySQL + ChromaDB, MinIO, Langchain, JWT + OAuth2 for authentication, and a frontend stack with Next.js, TypeScript, Tailwind CSS, Shadcn/UI, and Vercel AI SDK for AI integration. Performance optimization includes incremental document processing, streaming responses, vector database performance tuning, and distributed task processing. The project is licensed under the Apache-2.0 License and is intended for learning and sharing RAG knowledge only, not for commercial purposes.
dataforce.studio
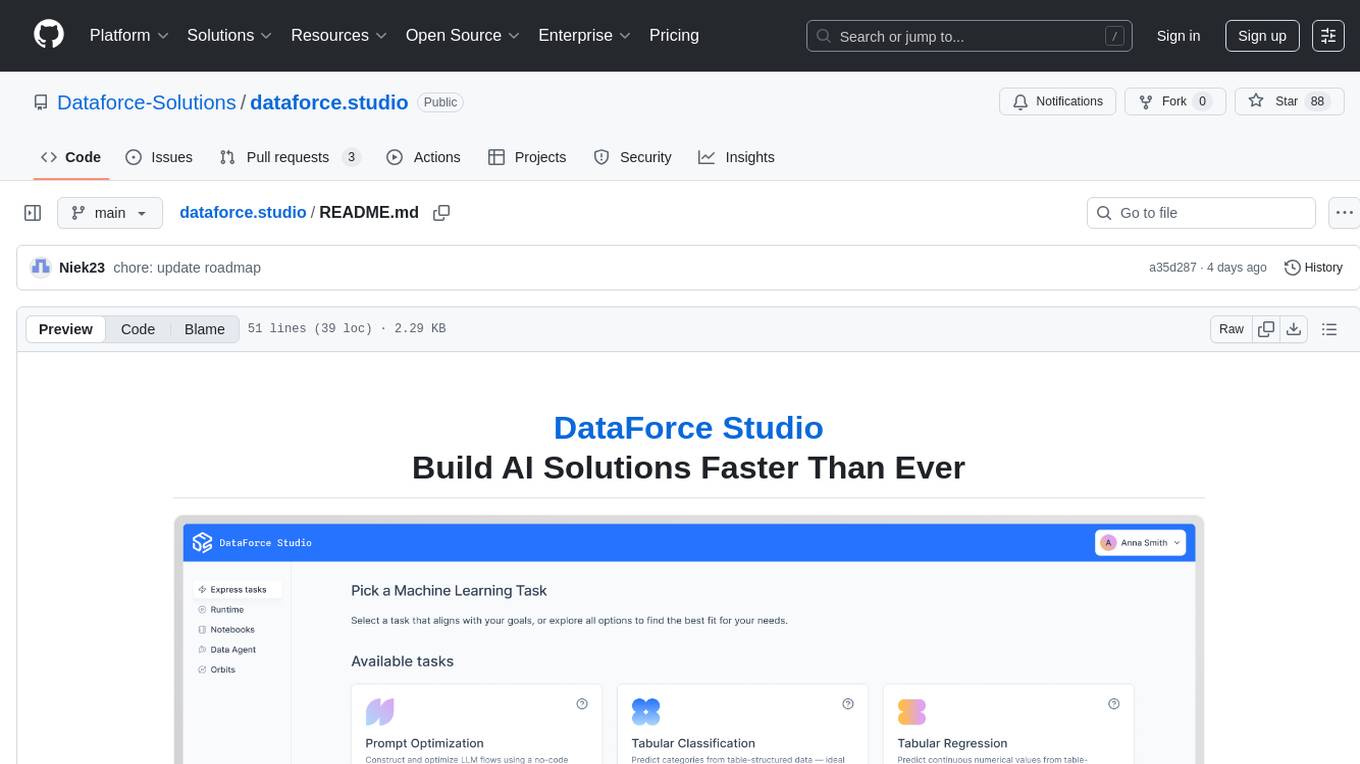
DataForce Studio is an open-source MLOps platform designed to help build, manage, and deploy AI/ML models with ease. It supports the entire model lifecycle, from creation to deployment and monitoring, within a user-friendly interface. The platform is in active early development, aiming to provide features like post-deployment monitoring, model deployment, data science agent, experiment snapshots, model cards, Python SDK, model registry, notebooks, in-browser runtime, and express tasks for prompt optimization and tabular data.

helicone
Helicone is an open-source observability platform designed for Language Learning Models (LLMs). It logs requests to OpenAI in a user-friendly UI, offers caching, rate limits, and retries, tracks costs and latencies, provides a playground for iterating on prompts and chat conversations, supports collaboration, and will soon have APIs for feedback and evaluation. The platform is deployed on Cloudflare and consists of services like Web (NextJs), Worker (Cloudflare Workers), Jawn (Express), Supabase, and ClickHouse. Users can interact with Helicone locally by setting up the required services and environment variables. The platform encourages contributions and provides resources for learning, documentation, and integrations.

MiniCPM-V-CookBook
MiniCPM-V & o Cookbook is a comprehensive repository for building multimodal AI applications effortlessly. It provides easy-to-use documentation, supports a wide range of users, and offers versatile deployment scenarios. The repository includes live demonstrations, inference recipes for vision and audio capabilities, fine-tuning recipes, serving recipes, quantization recipes, and a framework support matrix. Users can customize models, deploy them efficiently, and compress models to improve efficiency. The repository also showcases awesome works using MiniCPM-V & o and encourages community contributions.
Awesome-AITools
This repo collects AI-related utilities. ## All Categories * All Categories * ChatGPT and other closed-source LLMs * AI Search engine * Open Source LLMs * GPT/LLMs Applications * LLM training platform * Applications that integrate multiple LLMs * AI Agent * Writing * Programming Development * Translation * AI Conversation or AI Voice Conversation * Image Creation * Speech Recognition * Text To Speech * Voice Processing * AI generated music or sound effects * Speech translation * Video Creation * Video Content Summary * OCR(Optical Character Recognition)
Olares
Olares is an open-source sovereign cloud OS designed for local AI, enabling users to build their own AI assistants, sync data across devices, self-host their workspace, stream media, and more within a sovereign cloud environment. Users can effortlessly run leading AI models, deploy open-source AI apps, access AI apps and models anywhere, and benefit from integrated AI for personalized interactions. Olares offers features like edge AI, personal data repository, self-hosted workspace, private media server, smart home hub, and user-owned decentralized social media. The platform provides enterprise-grade security, secure application ecosystem, unified file system and database, single sign-on, AI capabilities, built-in applications, seamless access, and development tools. Olares is compatible with Linux, Raspberry Pi, Mac, and Windows, and offers a wide range of system-level applications, third-party components and services, and additional libraries and components.
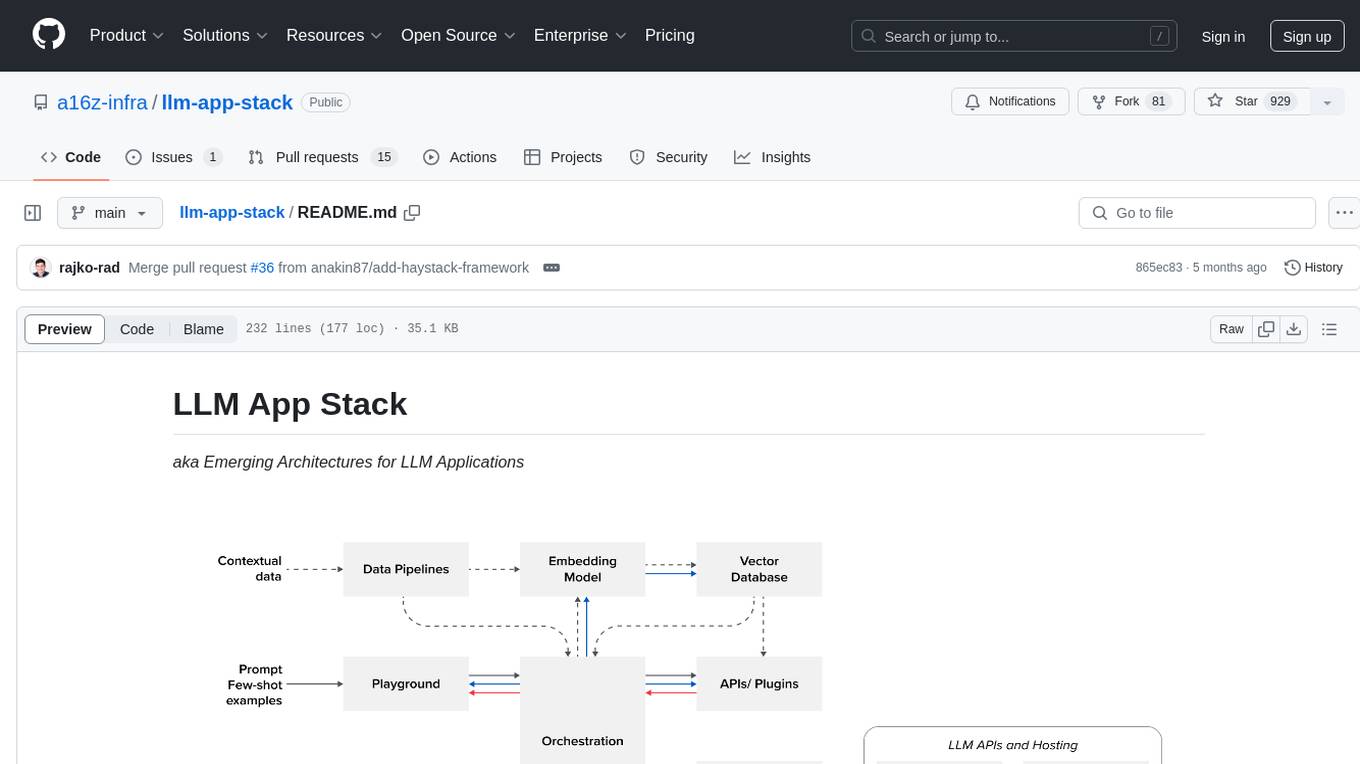
llm-app-stack
LLM App Stack, also known as Emerging Architectures for LLM Applications, is a comprehensive list of available tools, projects, and vendors at each layer of the LLM app stack. It covers various categories such as Data Pipelines, Embedding Models, Vector Databases, Playgrounds, Orchestrators, APIs/Plugins, LLM Caches, Logging/Monitoring/Eval, Validators, LLM APIs (proprietary and open source), App Hosting Platforms, Cloud Providers, and Opinionated Clouds. The repository aims to provide a detailed overview of tools and projects for building, deploying, and maintaining enterprise data solutions, AI models, and applications.
RustySEO
RustySEO is a free, modern SEO/GEO toolkit designed to help users crawl and analyze websites and server logs without crawl limits. It is an all-in-one, cross-platform marketing toolkit for comprehensive SEO & GEO analysis, providing actionable insights into marketing and SEO strategies. The tool offers features such as shallow & deep crawl, technical diagnostics, on-page SEO analysis, dashboards, reporting, topic and keyword generators, AI chatbot, crawl history, image conversion and optimization, and more. RustySEO aims to be a robust, free alternative to costly commercial SEO tools, with integrations like Google PageSpeed Insights, Google Gemini, and more.

chat-your-doc
Chat Your Doc is an experimental project exploring various applications based on LLM technology. It goes beyond being just a chatbot project, focusing on researching LLM applications using tools like LangChain and LlamaIndex. The project delves into UX, computer vision, and offers a range of examples in the 'Lab Apps' section. It includes links to different apps, descriptions, launch commands, and demos, aiming to showcase the versatility and potential of LLM applications.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.
langfuse-js
langfuse-js is a modular mono repo for the Langfuse JS/TS client libraries. It includes packages for Langfuse API client, tracing, OpenTelemetry export helpers, OpenAI integration, and LangChain integration. The SDK is currently in version 4 and offers universal JavaScript environments support as well as Node.js 20+. The repository provides documentation, reference materials, and development instructions for managing the monorepo with pnpm. It is licensed under MIT.
awesome-llm-webapps
This repository is a curated list of open-source, actively maintained web applications that leverage large language models (LLMs) for various use cases, including chatbots, natural language interfaces, assistants, and question answering systems. The projects are evaluated based on key criteria such as licensing, maintenance status, complexity, and features, to help users select the most suitable starting point for their LLM-based applications. The repository welcomes contributions and encourages users to submit projects that meet the criteria or suggest improvements to the existing list.

awesome-mobile-llm
Awesome Mobile LLMs is a curated list of Large Language Models (LLMs) and related studies focused on mobile and embedded hardware. The repository includes information on various LLM models, deployment frameworks, benchmarking efforts, applications, multimodal LLMs, surveys on efficient LLMs, training LLMs on device, mobile-related use-cases, industry announcements, and related repositories. It aims to be a valuable resource for researchers, engineers, and practitioners interested in mobile LLMs.
For similar tasks
airavata
Apache Airavata is a software framework for executing and managing computational jobs on distributed computing resources. It supports local clusters, supercomputers, national grids, academic and commercial clouds. Airavata utilizes service-oriented computing, distributed messaging, and workflow composition. It includes a server package with an API, client SDKs, and a general-purpose UI implementation called Apache Airavata Django Portal.
CosyVoice
CosyVoice is a tool designed for speech synthesis, offering pretrained models for zero-shot, sft, instruct inference. It provides a web demo for easy usage and supports advanced users with train and inference scripts. The tool can be deployed using grpc for service deployment. Users can download pretrained models and resources for immediate use or train their own models from scratch. CosyVoice is suitable for researchers, developers, linguists, AI engineers, and speech technology enthusiasts.
GenAIComps
GenAIComps is an initiative aimed at building enterprise-grade Generative AI applications using a microservice architecture. It simplifies the scaling and deployment process for production, abstracting away infrastructure complexities. GenAIComps provides a suite of containerized microservices that can be assembled into a mega-service tailored for real-world Enterprise AI applications. The modular approach of microservices allows for independent development, deployment, and scaling of individual components, promoting modularity, flexibility, and scalability. The mega-service orchestrates multiple microservices to deliver comprehensive solutions, encapsulating complex business logic and workflow orchestration. The gateway serves as the interface for users to access the mega-service, providing customized access based on user requirements.

fit-framework
FIT Framework is a Java enterprise AI development framework that provides a multi-language function engine (FIT), a flow orchestration engine (WaterFlow), and a Java ecosystem alternative solution (FEL). It runs in native/Spring dual mode, supports plug-and-play and intelligent deployment, seamlessly unifying large models and business systems. FIT Core offers language-agnostic computation base with plugin hot-swapping and intelligent deployment. WaterFlow Engine breaks the dimensional barrier of BPM and reactive programming, enabling graphical orchestration and declarative API-driven logic composition. FEL revolutionizes LangChain for the Java ecosystem, encapsulating large models, knowledge bases, and toolchains to integrate AI capabilities into Java technology stack seamlessly. The framework emphasizes engineering practices with intelligent conventions to reduce boilerplate code and offers flexibility for deep customization in complex scenarios.
specmatic
Eliminate API integration headaches with Specmatic's no-code AI-powered API development suite. Teams ship APIs 10x faster by transforming specifications into executable contracts instantly—no coding required, no integration surprises. In a complex, interdependent ecosystem, where each service is evolving rapidly, we want to make the dependencies between them explicit in the form of executable contracts. Contract Driven Development leverages API specifications like OpenAPI, AsyncAPI, GraphQL SDL files, gRPC Proto files, etc. as executable contracts allowing teams to get instantaneous feedback while making changes to avoid accidental breakage. With this ability, we can now independently deploy, at will, any service at any time without having to depend on expensive and fragile integration tests.
solon
Solon is a Java enterprise application development framework that is restrained, efficient, and open. It offers better cost performance for computing resources with 700% higher concurrency and 50% memory savings. It enables faster development productivity with less code and easy startup, 10 times faster than traditional methods. Solon provides a better production and deployment experience by packing applications 90% smaller. It supports a greater range of compatibility with non-Java-EE architecture and compatibility with Java 8 to Java 24, including GraalVM native image support. Solon is built from scratch with flexible interface specifications and an open ecosystem.
OpenAGI
OpenAGI is an AI agent creation package designed for researchers and developers to create intelligent agents using advanced machine learning techniques. The package provides tools and resources for building and training AI models, enabling users to develop sophisticated AI applications. With a focus on collaboration and community engagement, OpenAGI aims to facilitate the integration of AI technologies into various domains, fostering innovation and knowledge sharing among experts and enthusiasts.

xef
xef.ai is a one-stop library designed to bring the power of modern AI to applications and services. It offers integration with Large Language Models (LLM), image generation, and other AI services. The library is packaged in two layers: core libraries for basic AI services integration and integrations with other libraries. xef.ai aims to simplify the transition to modern AI for developers by providing an idiomatic interface, currently supporting Kotlin. Inspired by LangChain and Hugging Face, xef.ai may transmit source code and user input data to third-party services, so users should review privacy policies and take precautions. Libraries are available in Maven Central under the `com.xebia` group, with `xef-core` as the core library. Developers can add these libraries to their projects and explore examples to understand usage.
For similar jobs

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

nvidia_gpu_exporter
Nvidia GPU exporter for prometheus, using `nvidia-smi` binary to gather metrics.

tracecat
Tracecat is an open-source automation platform for security teams. It's designed to be simple but powerful, with a focus on AI features and a practitioner-obsessed UI/UX. Tracecat can be used to automate a variety of tasks, including phishing email investigation, evidence collection, and remediation plan generation.

openinference
OpenInference is a set of conventions and plugins that complement OpenTelemetry to enable tracing of AI applications. It provides a way to capture and analyze the performance and behavior of AI models, including their interactions with other components of the application. OpenInference is designed to be language-agnostic and can be used with any OpenTelemetry-compatible backend. It includes a set of instrumentations for popular machine learning SDKs and frameworks, making it easy to add tracing to your AI applications.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

kong
Kong, or Kong API Gateway, is a cloud-native, platform-agnostic, scalable API Gateway distinguished for its high performance and extensibility via plugins. It also provides advanced AI capabilities with multi-LLM support. By providing functionality for proxying, routing, load balancing, health checking, authentication (and more), Kong serves as the central layer for orchestrating microservices or conventional API traffic with ease. Kong runs natively on Kubernetes thanks to its official Kubernetes Ingress Controller.