
backgroundremover
Background Remover lets you Remove Background from images and video using AI with a simple command line interface that is free and open source.
Stars: 6247
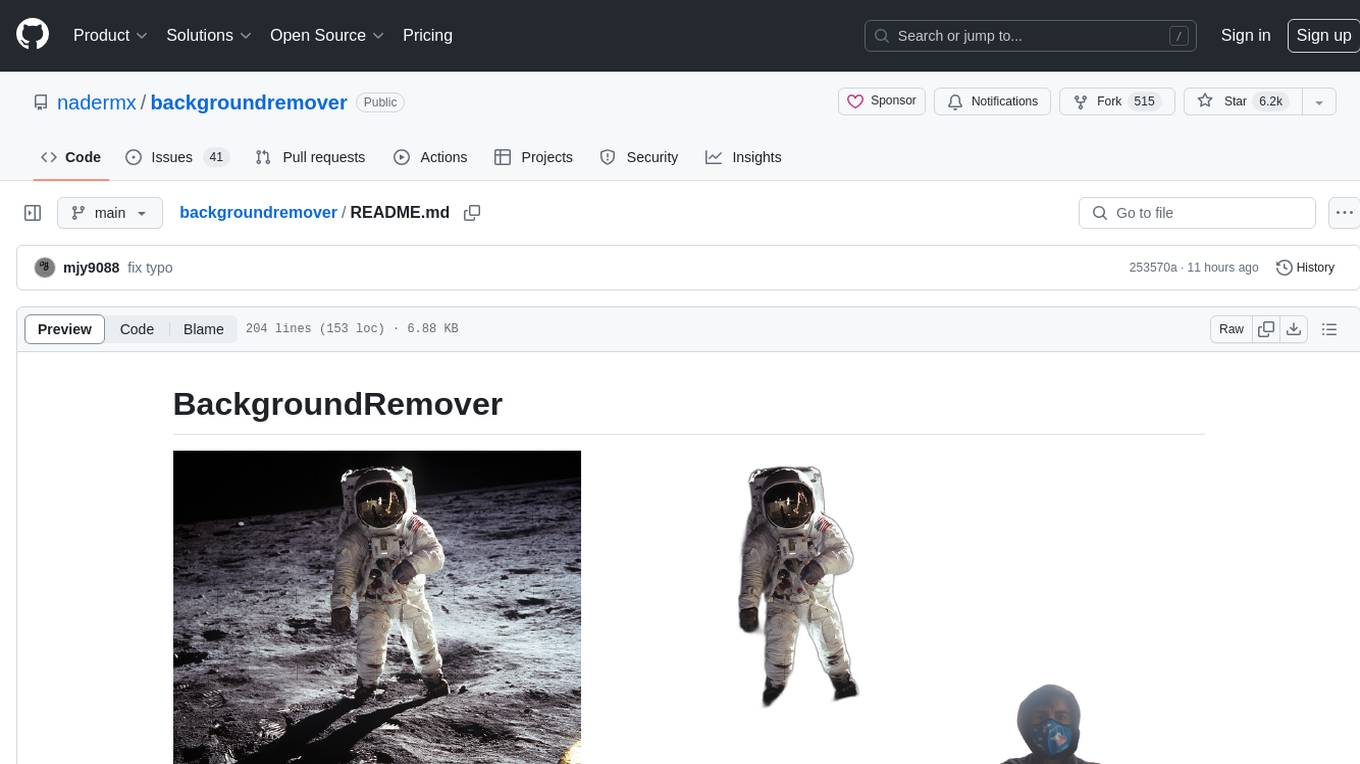
BackgroundRemover is a command line tool to remove background from image and video using AI. It requires python >= 3.6, torch, torchvision, and ffmpeg. The tool can be installed via pip or Docker. It offers various options for image and video background removal, including alpha matting and different models. Users can also use it as a library to remove background from images. The project aims to enhance background removal capabilities, improve documentation, add new features like real-time background removal for videos, and provide the ability to use custom models.
README:


BackgroundRemover is a command line tool to remove background from image and video using AI, made by nadermx to power https://BackgroundRemoverAI.com. If you wonder why it was made read this short blog post.
-
python >= 3.6
-
python3.6-dev #or what ever version of python you use
-
torch and torchvision stable version (https://pytorch.org)
-
ffmpeg 4.4+
-
To clarify, you must install both python and whatever dev version of python you installed. IE; python3.10-dev with python3.10 or python3.8-dev with python3.8
Go to https://pytorch.org and scroll down to INSTALL PYTORCH section and follow the instructions.
For example:
PyTorch Build: Stable (1.7.1)
Your OS: Windows
Package: Pip
Language: Python
CUDA: None
To install ffmpeg and python-dev
sudo apt install ffmpeg python3.6-dev
To Install backgroundremover, install it from pypi
pip install --upgrade pip
pip install backgroundremoverPlease note that when you first run the program, it will check to see if you have the u2net models, if you do not, it will pull them from this repo
It is also possible to run this without installing it via pip, just clone the git to local start a virtual env and install requirements and run
python -m backgroundremover.cmd.cli -i "video.mp4" -mk -o "output.mov"and for windows
python.exe -m backgroundremover.cmd.cli -i "video.mp4" -mk -o "output.mov"git clone https://github.com/nadermx/backgroundremover.git
cd backgroundremover
docker build -t bgremover .
alias backgroundremover='docker run -it --rm -v "$(pwd):/tmp" bgremover:latest'Remove the background from a local file image
backgroundremover -i "/path/to/image.jpeg" -o "output.png"Sometimes it is possible to achieve better results by turning on alpha matting. Example:
backgroundremover -i "/path/to/image.jpeg" -a -ae 15 -o "output.png"change the model for different background removal methods between u2netp, u2net, or u2net_human_seg
backgroundremover -i "/path/to/image.jpeg" -m "u2net_human_seg" -o "output.png"backgroundremover -i "/path/to/video.mp4" -tv -o "output.mov"backgroundremover -i "/path/to/video.mp4" -tov "/path/to/videtobeoverlayed.mp4" -o "output.mov"backgroundremover -i "/path/to/video.mp4" -toi "/path/to/videtobeoverlayed.mp4" -o "output.mov"backgroundremover -i "/path/to/video.mp4" -tg -o "output.gif"Make a matte file for premiere
backgroundremover -i "/path/to/video.mp4" -mk -o "output.matte.mp4"Change the framerate of the video (default is set to 30)
backgroundremover -i "/path/to/video.mp4" -fr 30 -tv -o "output.mov"Set total number of frames of the video (default is set to -1, ie the remove background from full video)
backgroundremover -i "/path/to/video.mp4" -fl 150 -tv -o "output.mov"Change the gpu batch size of the video (default is set to 1)
backgroundremover -i "/path/to/video.mp4" -gb 4 -tv -o "output.mov"Change the number of workers working on video (default is set to 1)
backgroundremover -i "/path/to/video.mp4" -wn 4 -tv -o "output.mov"change the model for different background removal methods between u2netp, u2net, or u2net_human_seg and limit the frames to 150
backgroundremover -i "/path/to/video.mp4" -m "u2net_human_seg" -fl 150 -tv -o "output.mov"from backgroundremover.bg import remove
def remove_bg(src_img_path, out_img_path):
model_choices = ["u2net", "u2net_human_seg", "u2netp"]
f = open(src_img_path, "rb")
data = f.read()
img = remove(data, model_name=model_choices[0],
alpha_matting=True,
alpha_matting_foreground_threshold=240,
alpha_matting_background_threshold=10,
alpha_matting_erode_structure_size=10,
alpha_matting_base_size=1000)
f.close()
f = open(out_img_path, "wb")
f.write(img)
f.close()
- convert logic from video to image to utilize more GPU on image removal
- clean up documentation a bit more
- add ability to adjust and give feedback images or videos to datasets
- add ability to realtime background removal for videos, for streaming
- finish flask server api
- add ability to use other models than u2net, ie your own
- other
Accepted
Give a link to our project BackgroundRemoverAI.com or this git, telling people that you like it or use it.
We made it our own package after merging together parts of others, adding in a few features of our own via posting parts as bounty questions on superuser, etc. As well as asked on hackernews earlier to open source the image part, so decided to add in video, and a bit more.
- https://arxiv.org/pdf/2005.09007.pdf
- https://github.com/NathanUA/U-2-Net
- https://github.com/pymatting/pymatting
- https://github.com/danielgatis/rembg
- https://github.com/ecsplendid/rembg-greenscreen
- https://superuser.com/questions/1647590/have-ffmpeg-merge-a-matte-key-file-over-the-normal-video-file-removing-the-backg
- https://superuser.com/questions/1648680/ffmpeg-alphamerge-two-videos-into-a-gif-with-transparent-background/1649339?noredirect=1#comment2522687_1649339
- https://superuser.com/questions/1649817/ffmpeg-overlay-a-video-after-alphamerging-two-others/1649856#1649856
- Copyright (c) 2021-present Johnathan Nader
- Copyright (c) 2020-present Lucas Nestler
- Copyright (c) 2020-present Dr. Tim Scarfe
- Copyright (c) 2020-present Daniel Gatis
Code Licensed under MIT License Models Licensed under Apache License 2.0
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for backgroundremover
Similar Open Source Tools
backgroundremover
BackgroundRemover is a command line tool to remove background from image and video using AI. It requires python >= 3.6, torch, torchvision, and ffmpeg. The tool can be installed via pip or Docker. It offers various options for image and video background removal, including alpha matting and different models. Users can also use it as a library to remove background from images. The project aims to enhance background removal capabilities, improve documentation, add new features like real-time background removal for videos, and provide the ability to use custom models.

rclip
rclip is a command-line photo search tool powered by the OpenAI's CLIP neural network. It allows users to search for images using text queries, similar image search, and combining multiple queries. The tool extracts features from photos to enable searching and indexing, with options for previewing results in supported terminals or custom viewers. Users can install rclip on Linux, macOS, and Windows using different installation methods. The repository follows the Conventional Commits standard and welcomes contributions from the community.

lexido
Lexido is an innovative assistant for the Linux command line, designed to boost your productivity and efficiency. Powered by Gemini Pro 1.0 and utilizing the free API, Lexido offers smart suggestions for commands based on your prompts and importantly your current environment. Whether you're installing software, managing files, or configuring system settings, Lexido streamlines the process, making it faster and more intuitive.
parllama
PAR LLAMA is a Text UI application for managing and using LLMs, designed with Textual and Rich and PAR AI Core. It runs on major OS's including Windows, Windows WSL, Mac, and Linux. Supports Dark and Light mode, custom themes, and various workflows like Ollama chat, image chat, and OpenAI provider chat. Offers features like custom prompts, themes, environment variables configuration, and remote instance connection. Suitable for managing and using LLMs efficiently.

fabric
Fabric is an open-source framework for augmenting humans using AI. It provides a structured approach to breaking down problems into individual components and applying AI to them one at a time. Fabric includes a collection of pre-defined Patterns (prompts) that can be used for a variety of tasks, such as extracting the most interesting parts of YouTube videos and podcasts, writing essays, summarizing academic papers, creating AI art prompts, and more. Users can also create their own custom Patterns. Fabric is designed to be easy to use, with a command-line interface and a variety of helper apps. It is also extensible, allowing users to integrate it with their own AI applications and infrastructure.
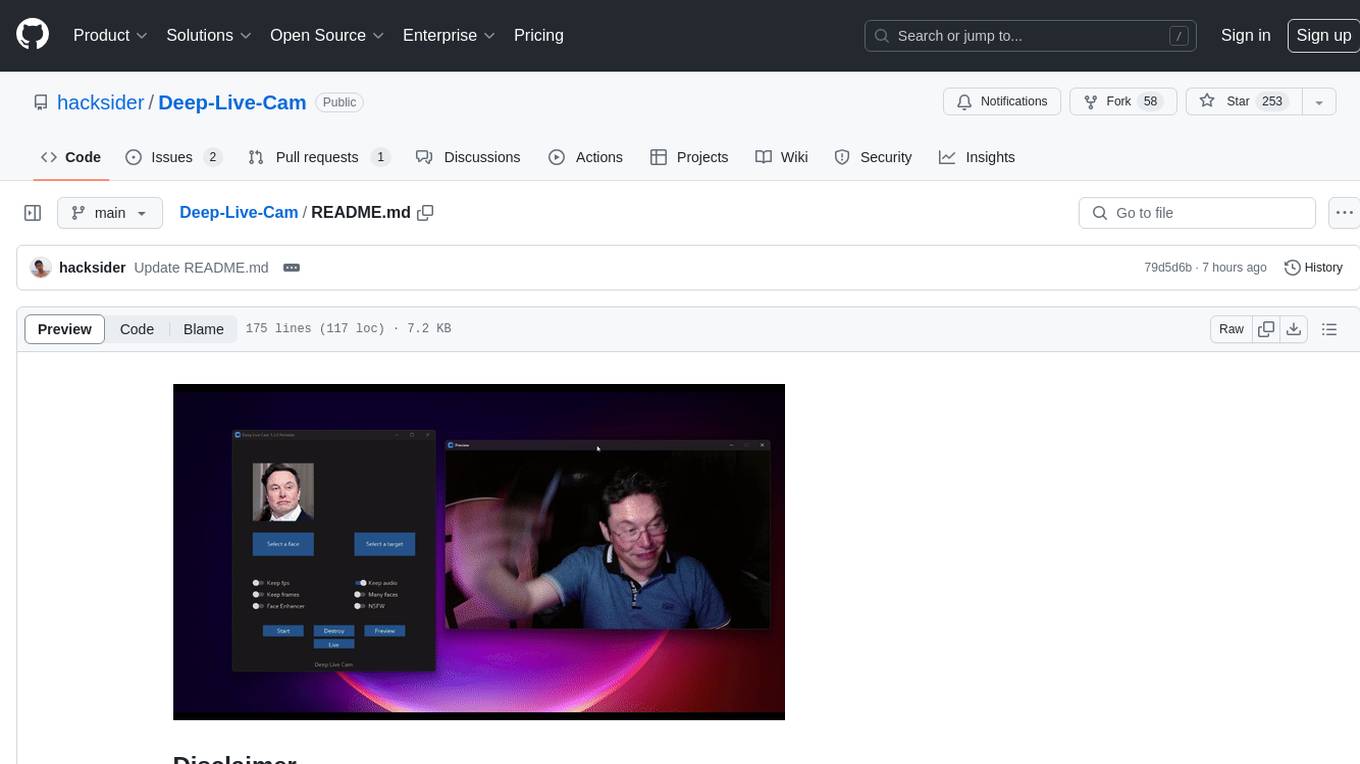
Deep-Live-Cam
Deep-Live-Cam is a software tool designed to assist artists in tasks such as animating custom characters or using characters as models for clothing. The tool includes built-in checks to prevent unethical applications, such as working on inappropriate media. Users are expected to use the tool responsibly and adhere to local laws, especially when using real faces for deepfake content. The tool supports both CPU and GPU acceleration for faster processing and provides a user-friendly GUI for swapping faces in images or videos.

Fabric
Fabric is an open-source framework designed to augment humans using AI by organizing prompts by real-world tasks. It addresses the integration problem of AI by creating and organizing prompts for various tasks. Users can create, collect, and organize AI solutions in a single place for use in their favorite tools. Fabric also serves as a command-line interface for those focused on the terminal. It offers a wide range of features and capabilities, including support for multiple AI providers, internationalization, speech-to-text, AI reasoning, model management, web search, text-to-speech, desktop notifications, and more. The project aims to help humans flourish by leveraging AI technology to solve human problems and enhance creativity.
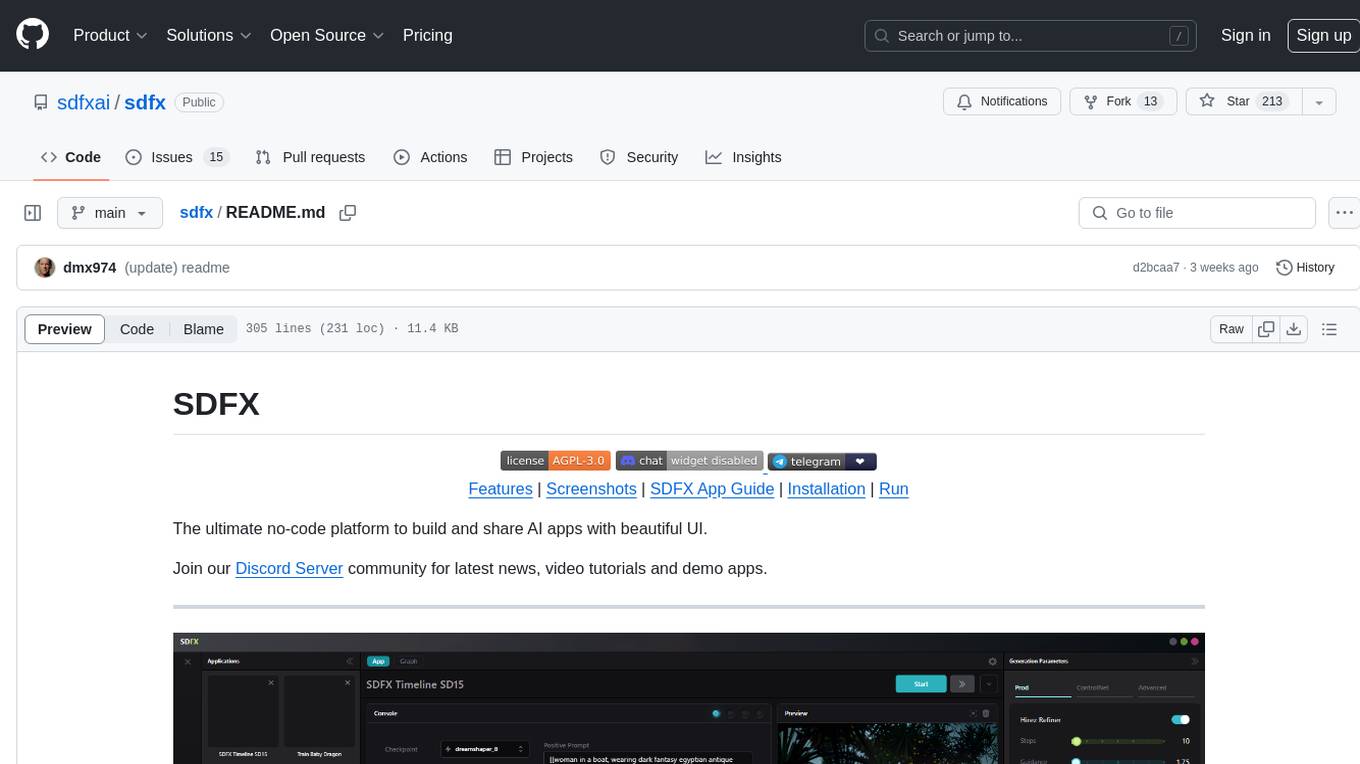
sdfx
SDFX is the ultimate no-code platform for building and sharing AI apps with beautiful UI. It enables the creation of user-friendly interfaces for complex workflows by combining Comfy workflow with a UI. The tool is designed to merge the benefits of form-based UI and graph-node based UI, allowing users to create intricate graphs with a high-level UI overlay. SDFX is fully compatible with ComfyUI, abstracting the need for installing ComfyUI. It offers features like animated graph navigation, node bookmarks, UI debugger, custom nodes manager, app and template export, image and mask editor, and more. The tool compiles as a native app or web app, making it easy to maintain and add new features.

ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.
air-light
Air-light is a minimalist WordPress starter theme designed to be an ultra minimal starting point for a WordPress project. It is built to be very straightforward, backwards compatible, front-end developer friendly and modular by its structure. Air-light is free of weird "app-like" folder structures or odd syntaxes that nobody else uses. It loves WordPress as it was and as it is.
OpenAI-sublime-text
The OpenAI Completion plugin for Sublime Text provides first-class code assistant support within the editor. It utilizes LLM models to manipulate code, engage in chat mode, and perform various tasks. The plugin supports OpenAI, llama.cpp, and ollama models, allowing users to customize their AI assistant experience. It offers separated chat histories and assistant settings for different projects, enabling context-specific interactions. Additionally, the plugin supports Markdown syntax with code language syntax highlighting, server-side streaming for faster response times, and proxy support for secure connections. Users can configure the plugin's settings to set their OpenAI API key, adjust assistant modes, and manage chat history. Overall, the OpenAI Completion plugin enhances the Sublime Text editor with powerful AI capabilities, streamlining coding workflows and fostering collaboration with AI assistants.
wcgw
wcgw is a shell and coding agent designed for Claude and Chatgpt. It provides full shell access with no restrictions, desktop control on Claude for screen capture and control, interactive command handling, large file editing, and REPL support. Users can use wcgw to create, execute, and iterate on tasks, such as solving problems with Python, finding code instances, setting up projects, creating web apps, editing large files, and running server commands. Additionally, wcgw supports computer use on Docker containers for desktop control. The tool can be extended with a VS Code extension for pasting context on Claude app and integrates with Chatgpt for custom GPT interactions.
computer-use-mcp
The computer-use-mcp repository is a model context protocol server that allows Claude to control your computer. It is similar to computer use but is easy to set up and use locally. Users should be cautious as the server gives the model complete control of the computer, similar to giving a hyperactive toddler access. The tool communicates with the computer using nut.js and follows Anthropic's official computer use guide with a focus on keyboard shortcuts.
Upscaler
Holloway's Upscaler is a consolidation of various compiled open-source AI image/video upscaling products for a CLI-friendly image and video upscaling program. It provides low-cost AI upscaling software that can run locally on a laptop, programmable for albums and videos, reliable for large video files, and works without GUI overheads. The repository supports hardware testing on various systems and provides important notes on GPU compatibility, video types, and image decoding bugs. Dependencies include ffmpeg and ffprobe for video processing. The user manual covers installation, setup pathing, calling for help, upscaling images and videos, and contributing back to the project. Benchmarks are provided for performance evaluation on different hardware setups.
UltraSinger
UltraSinger is a tool under development that automatically creates UltraStar.txt, midi, and notes from music. It pitches UltraStar files, adds text and tapping, creates separate UltraStar karaoke files, re-pitches current UltraStar files, and calculates in-game score. It uses multiple AI models to extract text from voice and determine pitch. Users should mention UltraSinger in UltraStar.txt files and only use it on Creative Commons licensed songs.
aimeos-typo3
Aimeos is a professional, full-featured, and high-performance e-commerce extension for TYPO3. It can be installed in an existing TYPO3 website within 5 minutes and can be adapted, extended, overwritten, and customized to meet specific needs.
For similar tasks
backgroundremover
BackgroundRemover is a command line tool to remove background from image and video using AI. It requires python >= 3.6, torch, torchvision, and ffmpeg. The tool can be installed via pip or Docker. It offers various options for image and video background removal, including alpha matting and different models. Users can also use it as a library to remove background from images. The project aims to enhance background removal capabilities, improve documentation, add new features like real-time background removal for videos, and provide the ability to use custom models.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.