
SkyRL
SkyRL: A Modular Full-stack RL Library for LLMs
Stars: 886
SkyRL is a full-stack RL library that provides components such as 'skyagent' for training long-horizon, real-world agents, 'skyrl-train' for modular RL training, and 'skyrl-gym' for a variety of tool-use tasks. It offers a library of math, coding, search, and SQL environments implemented in the Gymnasium API, optimized for multi-turn tool use LLMs on long-horizon, real-environment tasks.
README:
News • Links • Getting Started • Citation • Acknowledgement
SkyRL is a full-stack RL library that provides the following components:
-
skyagent: Our agent layer for training long-horizon, real-world agents. Contains code for SkyRL-v0. - (NEW)
skyrl-train: Our modular, performant training framework for RL. - (NEW)
skyrl-gym: Our gynasium of tool-use tasks, including a library of math, coding, search and SQL environments implemented in the Gymnasium API.
For a guide on developing with SkyRL, take at look at our Development Guide docs.
For model training, checkout skyrl-train to start using, modifying, or building on top of the SkyRL training stack. See our quickstart docs to ramp up!
For building environments, checkout skyrl-gym to integrate your task in the simple gymnasium interface.
For agentic pipelines, checkout skyagent for our work on optimizing and scaling pipelines for multi-turn tool use LLMs on long-horizon, real-environment tasks.
- [2025/06/26] 🎉 We released SkyRL-v0.1: A highly-modular, performant RL training framework. [Blog]
- [2025/06/26] 🎉 We released SkyRL-Gym: A library of RL environments for LLMs implemented with the Gymnasium API. [Blog]
- [2025/05/20] 🎉 We released SkyRL-SQL: a multi-turn RL training pipeline for Text-to-SQL, along with SkyRL-SQL-7B — a model trained on just 653 samples that outperforms both GPT-4o and o4-mini!
- [2025/05/06] 🎉 We released SkyRL-v0: our open RL training pipeline for multi-turn tool use LLMs, optimized for long-horizon, real-environment tasks like SWE-Bench!
This work is done at Berkeley Sky Computing Lab in collaboration with Anyscale, with generous compute support from Anyscale, Databricks, NVIDIA, Lambda Labs, and AMD.
We adopt many lessons and code from several great projects such as veRL, OpenRLHF, Search-R1, OpenReasonerZero, and NeMo-RL. We appreciate each of these teams and their contributions to open-source research!
If you find the work in this repository helpful, please consider citing:
@misc{cao2025skyrl,
title = {SkyRL-v0: Train Real-World Long-Horizon Agents via Reinforcement Learning},
author = {Shiyi Cao and Sumanth Hegde and Dacheng Li and Tyler Griggs and Shu Liu and Eric Tang and Jiayi Pan and Xingyao Wang and Akshay Malik and Graham Neubig and Kourosh Hakhamaneshi and Richard Liaw and Philipp Moritz and Matei Zaharia and Joseph E. Gonzalez and Ion Stoica},
year = {2025},
}@misc{liu2025skyrlsql,
title={SkyRL-SQL: Matching GPT-4o and o4-mini on Text2SQL with Multi-Turn RL},
author={Shu Liu and Sumanth Hegde and Shiyi Cao and Alan Zhu and Dacheng Li and Tyler Griggs and Eric Tang and Akshay Malik and Kourosh Hakhamaneshi and Richard Liaw and Philipp Moritz and Matei Zaharia and Joseph E. Gonzalez and Ion Stoica},
year={2025},
}@misc{griggs2025skrylv01,
title={Evolving SkyRL into a Highly-Modular RL Framework},
author={Tyler Griggs and Sumanth Hegde and Eric Tang and Shu Liu and Shiyi Cao and Dacheng Li and Charlie Ruan and Philipp Moritz and Kourosh Hakhamaneshi and Richard Liaw and Akshay Malik and Matei Zaharia and Joseph E. Gonzalez and Ion Stoica},
year={2025},
note={Notion Blog}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for SkyRL
Similar Open Source Tools
SkyRL
SkyRL is a full-stack RL library that provides components such as 'skyagent' for training long-horizon, real-world agents, 'skyrl-train' for modular RL training, and 'skyrl-gym' for a variety of tool-use tasks. It offers a library of math, coding, search, and SQL environments implemented in the Gymnasium API, optimized for multi-turn tool use LLMs on long-horizon, real-environment tasks.

skypilot
SkyPilot is a framework for running LLMs, AI, and batch jobs on any cloud, offering maximum cost savings, highest GPU availability, and managed execution. SkyPilot abstracts away cloud infra burdens: - Launch jobs & clusters on any cloud - Easy scale-out: queue and run many jobs, automatically managed - Easy access to object stores (S3, GCS, R2) SkyPilot maximizes GPU availability for your jobs: * Provision in all zones/regions/clouds you have access to (the _Sky_), with automatic failover SkyPilot cuts your cloud costs: * Managed Spot: 3-6x cost savings using spot VMs, with auto-recovery from preemptions * Optimizer: 2x cost savings by auto-picking the cheapest VM/zone/region/cloud * Autostop: hands-free cleanup of idle clusters SkyPilot supports your existing GPU, TPU, and CPU workloads, with no code changes.
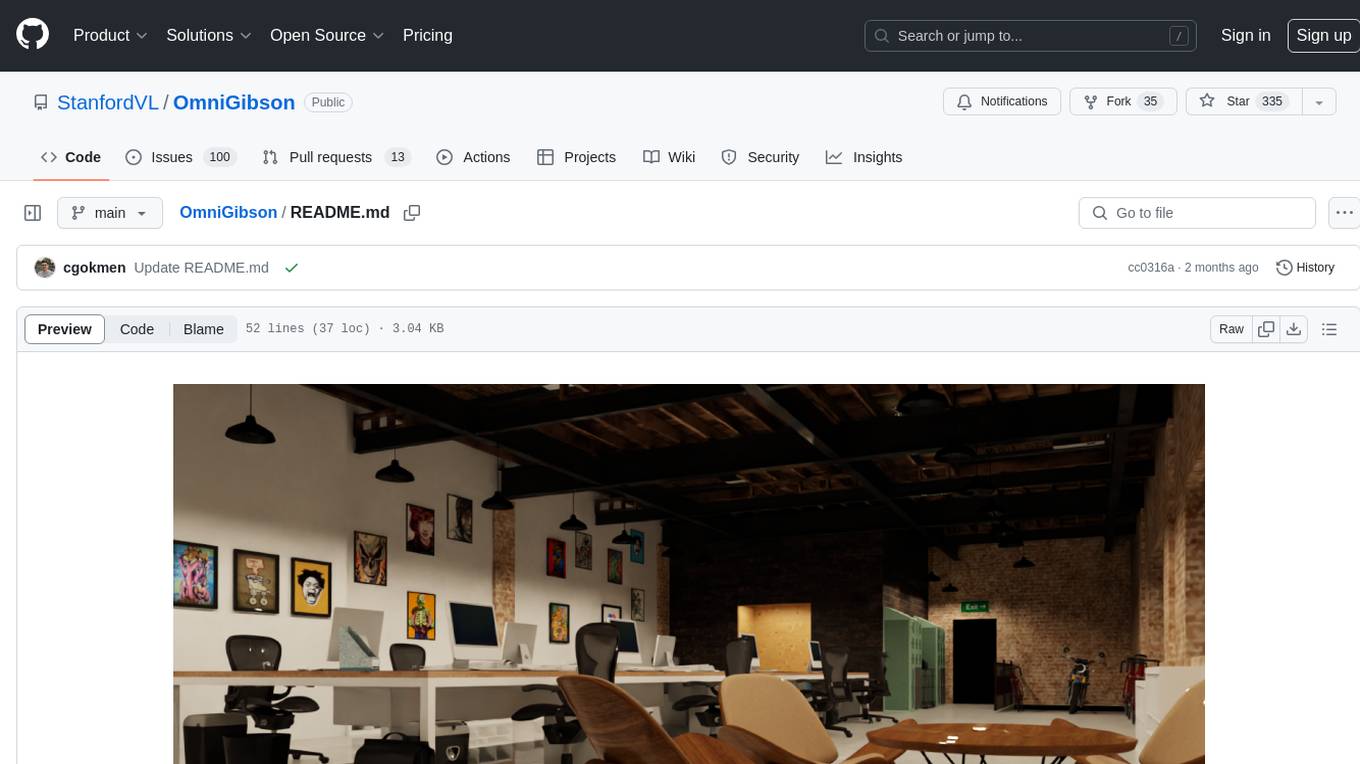
OmniGibson
OmniGibson is a platform for accelerating Embodied AI research built upon NVIDIA's Omniverse platform. It features photorealistic visuals, physical realism, fluid and soft body support, large-scale high-quality scenes and objects, dynamic kinematic and semantic object states, mobile manipulator robots with modular controllers, and an OpenAI Gym interface. The platform provides a comprehensive environment for researchers to conduct experiments and simulations in the field of Embodied AI.
MemOS
MemOS is an operating system for Large Language Models (LLMs) that enhances them with long-term memory capabilities. It allows LLMs to store, retrieve, and manage information, enabling more context-aware, consistent, and personalized interactions. MemOS provides Memory-Augmented Generation (MAG) with a unified API for memory operations, a Modular Memory Architecture (MemCube) for easy integration and management of different memory types, and multiple memory types including Textual Memory, Activation Memory, and Parametric Memory. It is extensible, allowing users to customize memory modules, data sources, and LLM integrations. MemOS demonstrates significant improvements over baseline memory solutions in multiple reasoning tasks, with a notable improvement in temporal reasoning accuracy compared to the OpenAI baseline.

GPTSwarm
GPTSwarm is a graph-based framework for LLM-based agents that enables the creation of LLM-based agents from graphs and facilitates the customized and automatic self-organization of agent swarms with self-improvement capabilities. The library includes components for domain-specific operations, graph-related functions, LLM backend selection, memory management, and optimization algorithms to enhance agent performance and swarm efficiency. Users can quickly run predefined swarms or utilize tools like the file analyzer. GPTSwarm supports local LM inference via LM Studio, allowing users to run with a local LLM model. The framework has been accepted by ICML2024 and offers advanced features for experimentation and customization.

SLAM-LLM
SLAM-LLM is a deep learning toolkit for training custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports various tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). Users can easily extend to new models and tasks, utilize mixed precision training for faster training with less GPU memory, and perform multi-GPU training with data and model parallelism. Configuration is flexible based on Hydra and dataclass, allowing different configuration methods.

promptfoo
Promptfoo is a tool for testing and evaluating LLM output quality. With promptfoo, you can build reliable prompts, models, and RAGs with benchmarks specific to your use-case, speed up evaluations with caching, concurrency, and live reloading, score outputs automatically by defining metrics, use as a CLI, library, or in CI/CD, and use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API.
BMAD-METHOD
BMAD-METHOD™ is a universal AI agent framework that revolutionizes Agile AI-Driven Development. It offers specialized AI expertise across various domains, including software development, entertainment, creative writing, business strategy, and personal wellness. The framework introduces two key innovations: Agentic Planning, where dedicated agents collaborate to create detailed specifications, and Context-Engineered Development, which ensures complete understanding and guidance for developers. BMAD-METHOD™ simplifies the development process by eliminating planning inconsistency and context loss, providing a seamless workflow for creating AI agents and expanding functionality through expansion packs.
DriveLM
DriveLM is a multimodal AI model that enables autonomous driving by combining computer vision and natural language processing. It is designed to understand and respond to complex driving scenarios using visual and textual information. DriveLM can perform various tasks related to driving, such as object detection, lane keeping, and decision-making. It is trained on a massive dataset of images and text, which allows it to learn the relationships between visual cues and driving actions. DriveLM is a powerful tool that can help to improve the safety and efficiency of autonomous vehicles.

cherry-studio
Cherry Studio is a desktop client that supports multiple LLM providers on Windows, Mac, and Linux. It offers diverse LLM provider support, AI assistants & conversations, document & data processing, practical tools integration, and enhanced user experience. The tool includes features like support for major LLM cloud services, AI web service integration, local model support, pre-configured AI assistants, document processing for text, images, and more, global search functionality, topic management system, AI-powered translation, and cross-platform support with ready-to-use features and themes for a better user experience.
rllm
rLLM (relationLLM) is a Pytorch library for Relational Table Learning (RTL) with LLMs. It breaks down state-of-the-art GNNs, LLMs, and TNNs as standardized modules and facilitates novel model building in a 'combine, align, and co-train' way using these modules. The library is LLM-friendly, processes various graphs as multiple tables linked by foreign keys, introduces new relational table datasets, and is supported by students and teachers from Shanghai Jiao Tong University and Tsinghua University.
meridian
Meridian is a tool that provides personalized daily intelligence briefings by scraping news from hundreds of sources, analyzing stories with AI, and delivering concise briefs. It offers key global events, context, implications analysis, and open-source transparency. Built for the curious who seek in-depth news beyond headlines without spending too much time. The tool uses multi-stage LLM processing for article and cluster analysis, smart clustering techniques to group related articles, and a web interface powered by Nuxt 3. The workflow involves scraping RSS feeds, processing articles with Gemini for relevance, clustering articles, and generating a final brief. The project leverages AI models like Gemini, multilingual embeddings, UMAP, and HDBSCAN for analysis. The tech stack includes Turborepo, Cloudflare services, TypeScript, PostgreSQL, and Nuxt 3 with Vue 3 and Tailwind for the frontend.
kornia
Kornia is a differentiable computer vision library for PyTorch. It consists of a set of routines and differentiable modules to solve generic computer vision problems. At its core, the package uses PyTorch as its main backend both for efficiency and to take advantage of the reverse-mode auto-differentiation to define and compute the gradient of complex functions.
lancedb
LanceDB is an open-source database for vector-search built with persistent storage, which greatly simplifies retrieval, filtering, and management of embeddings. The key features of LanceDB include: Production-scale vector search with no servers to manage. Store, query, and filter vectors, metadata, and multi-modal data (text, images, videos, point clouds, and more). Support for vector similarity search, full-text search, and SQL. Native Python and Javascript/Typescript support. Zero-copy, automatic versioning, manage versions of your data without needing extra infrastructure. GPU support in building vector index(*). Ecosystem integrations with LangChain 🦜️🔗, LlamaIndex 🦙, Apache-Arrow, Pandas, Polars, DuckDB, and more on the way. LanceDB's core is written in Rust 🦀 and is built using Lance, an open-source columnar format designed for performant ML workloads.
gen-ai-experiments
Gen-AI-Experiments is a structured collection of Jupyter notebooks and AI experiments designed to guide users through various AI tools, frameworks, and models. It offers valuable resources for both beginners and experienced practitioners, covering topics such as AI agents, model testing, RAG systems, real-world applications, and open-source tools. The repository includes folders with curated libraries, AI agents, experiments, LLM testing, open-source libraries, RAG experiments, and educhain experiments, each focusing on different aspects of AI development and application.

logto
Logto is a modern, open-source authentication infrastructure designed for SaaS and AI applications. It simplifies OIDC and OAuth 2.1 implementation, enabling secure, production-ready authentication with features like multi-tenancy, enterprise SSO, and RBAC. Logto offers pre-built sign-in flows, customizable UIs, and SDKs for various frameworks, supporting protocols like OIDC, OAuth 2.1, and SAML. It is suitable for teams scaling SaaS, AI, and agent-based platforms without authentication complexities.
For similar tasks
SkyRL
SkyRL is a full-stack RL library that provides components such as 'skyagent' for training long-horizon, real-world agents, 'skyrl-train' for modular RL training, and 'skyrl-gym' for a variety of tool-use tasks. It offers a library of math, coding, search, and SQL environments implemented in the Gymnasium API, optimized for multi-turn tool use LLMs on long-horizon, real-environment tasks.

openvino.genai
The GenAI repository contains pipelines that implement image and text generation tasks. The implementation uses OpenVINO capabilities to optimize the pipelines. Each sample covers a family of models and suggests certain modifications to adapt the code to specific needs. It includes the following pipelines: 1. Benchmarking script for large language models 2. Text generation C++ samples that support most popular models like LLaMA 2 3. Stable Diffuison (with LoRA) C++ image generation pipeline 4. Latent Consistency Model (with LoRA) C++ image generation pipeline
safeguards-shield
Safeguards Shield is a security and alignment toolkit designed to detect unwanted inputs and LLM outputs. It provides tools to optimize RAG pipelines for accuracy and ensure trustworthy AI needs are met. The SDK aims to make LLMs accurate and secure, unlocking value faster by unifying a set of tools.

LightRAG
LightRAG is a PyTorch library designed for building and optimizing Retriever-Agent-Generator (RAG) pipelines. It follows principles of simplicity, quality, and optimization, offering developers maximum customizability with minimal abstraction. The library includes components for model interaction, output parsing, and structured data generation. LightRAG facilitates tasks like providing explanations and examples for concepts through a question-answering pipeline.
RAGHub
RAGHub is a community-driven project focused on cataloging new and emerging frameworks, projects, and resources in the Retrieval-Augmented Generation (RAG) ecosystem. It aims to help users stay ahead of changes in the field by providing a platform for the latest innovations in RAG. The repository includes information on RAG frameworks, evaluation frameworks, optimization frameworks, citation frameworks, engines, search reranker frameworks, projects, resources, and real-world use cases across industries and professions.
AI4U
AI4U is a tool that provides a framework for modeling virtual reality and game environments. It offers an alternative approach to modeling Non-Player Characters (NPCs) in Godot Game Engine. AI4U defines an agent living in an environment and interacting with it through sensors and actuators. Sensors provide data to the agent's brain, while actuators send actions from the agent to the environment. The brain processes the sensor data and makes decisions (selects an action by time). AI4U can also be used in other situations, such as modeling environments for artificial intelligence experiments.

Co-LLM-Agents
This repository contains code for building cooperative embodied agents modularly with large language models. The agents are trained to perform tasks in two different environments: ThreeDWorld Multi-Agent Transport (TDW-MAT) and Communicative Watch-And-Help (C-WAH). TDW-MAT is a multi-agent environment where agents must transport objects to a goal position using containers. C-WAH is an extension of the Watch-And-Help challenge, which enables agents to send messages to each other. The code in this repository can be used to train agents to perform tasks in both of these environments.
godot_rl_agents
Godot RL Agents is an open-source package that facilitates the integration of Machine Learning algorithms with games created in the Godot Engine. It provides interfaces for popular RL frameworks, support for memory-based agents, 2D and 3D games, AI sensors, and is licensed under MIT. Users can train agents in the Godot editor, create custom environments, export trained agents in ONNX format, and utilize advanced features like different RL training frameworks.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.