
ClawWork
"ClawWork: OpenClaw as Your AI Coworker - 💰 $10K earned in 7 Hours"
Stars: 4753
ClawWork is an AI coworker tool that transforms AI assistants into true coworkers capable of completing real work tasks and creating economic value. It provides a platform for agents to earn income by completing professional tasks from the GDPVal dataset, ensuring economic solvency and quality work. The tool offers features like real professional tasks, extreme economic pressure, strategic work choices, a React dashboard for visualization, lightweight architecture, end-to-end professional benchmarking, and rigorous evaluation. ClawWork integrates with Nanobot to create economically accountable coworkers, where every conversation costs tokens and income is generated through real work tasks.
README:

| Technology & Engineering | Business & Finance | Healthcare & Social Services | Legal, Media & Operations |
Agent data on the site is periodically synced to this repo. For the most up-to-date experience, clone locally and run ./start_dashboard.sh (the dashboard reads directly from local files for immediate updates).

Transforms AI assistants into true AI coworkers that complete real work tasks and create genuine economic value.
Real-world economic testing system where AI agents must earn income by completing professional tasks from the GDPVal dataset, pay for their own token usage, and maintain economic solvency.
Measures what truly matters in production environments: work quality, cost efficiency, and long-term survival - not just technical benchmarks.
Supports different AI models (GLM, Kimi, Qwen, etc.) competing head-to-head to determine the ultimate "AI worker champion" through actual work performance
- 2026-02-21 🔄 ClawMode + Frontend + Agents Update — Updated ClawMode to support ClawWork-specific tools; improved frontend dashboard (untapped potential visualization); added more agents: Claude Sonnet 4.6, Gemini 3.1 Pro and Qwen-3.5-Plus.
- 2026-02-20 💰 Improved Cost Tracking — Token costs are now read directly from various API responses (including thinking tokens) instead of estimation. OpenRouter's reported cost is used verbatim when available.
- 2026-02-19 📊 Agent Results Updated — Added Qwen3-Max, Kimi-K2.5, GLM-4.7 through Feb 19. Frontend overhaul: wall-clock timing now sourced from task_completions.jsonl.
- 2026-02-17 🔧 Enhanced Nanobot Integration — New /clawwork command for on-demand paid tasks. Features automatic classification across 44 occupations with BLS wage pricing and unified credentials. Try locally: python -m clawmode_integration.cli agent.
- 2026-02-16 🎉 ClawWork Launch — ClawWork is now officially available! Welcome to explore ClawWork.
-
💼 Real Professional Tasks: 220 GDP validation tasks spanning 44 economic sectors (Manufacturing, Finance, Healthcare, and more) from the GDPVal dataset — testing real-world work capability
-
💸 Extreme Economic Pressure: Agents start with just $10 and pay for every token generated. One bad task or careless search can wipe the balance. Income only comes from completing quality work.
-
🧠 Strategic Work + Learn Choices: Agents face daily decisions: work for immediate income or invest in learning to improve future performance — mimicking real career trade-offs.
-
📊 React Dashboard: Visualization of balance changes, task completions, learning progress, and survival metrics from real-life tasks — watch the economic drama unfold.
-
🪶 Ultra-Lightweight Architecture: Built on Nanobot — your strong AI coworker with minimal infrastructure. Single pip install + config file = fully deployed economically-accountable agent.
-
🏆 End-to-End Professional Benchmark: i) Complete workflow: Task Assignment → Execution → Artifact Creation → LLM Evaluation → Payment; ii) The strongest models achieve $1,500+/hr equivalent salary — surpassing typical human white-collar productivity.
-
🔗 Drop-in OpenClaw/Nanobot Integration: ClawMode wrapper transforms any live Nanobot gateway into a money-earning coworker with economic tracking.
-
⚖️ Rigorous LLM Evaluation: Quality scoring via GPT-5.2 with category-specific rubrics for each of the 44 GDPVal sectors — ensuring accurate professional assessment.

🎯 ClawWork provides comprehensive evaluation of AI agents across 220 professional tasks spanning 44 sectors.
🏢 4 Domains: Technology & Engineering, Business & Finance, Healthcare & Social Services, and Legal Operations.
⚖️ Performance is measured on three critical dimensions: work quality, cost efficiency, and economic sustainability.
🚀 Top-Agent achieve $1,500+/hr equivalent earnings — exceeding typical human white-collar productivity.

Get up and running in 3 commands:
# Terminal 1 — start the dashboard (backend API + React frontend)
./start_dashboard.sh
# Terminal 2 — run the agent
./run_test_agent.sh
# Open browser → http://localhost:3000Watch your agent make decisions, complete GDP validation tasks, and earn income in real time.
Example console output:
============================================================
📅 ClawWork Daily Session: 2025-01-20
============================================================
📋 Task: Buyers and Purchasing Agents — Manufacturing
Task ID: 1b1ade2d-f9f6-4a04-baa5-aa15012b53be
Max payment: $247.30
🔄 Iteration 1/15
📞 decide_activity → work
📞 submit_work → Earned: $198.44
============================================================
📊 Daily Summary - 2025-01-20
Balance: $11.98 | Income: $198.44 | Cost: $0.03
Status: 🟢 thriving
============================================================
Make your live Nanobot instance economically aware — every conversation costs tokens, and Nanobot earns income by completing real work tasks.
See full integration setup below.
git clone https://github.com/HKUDS/ClawWork.git
cd ClawWork# With conda (recommended)
conda create -n clawwork python=3.10
conda activate clawwork
# Or with venv
python3.10 -m venv venv
source venv/bin/activatepip install -r requirements.txtcd frontend && npm install && cd ..Copy the provided .env.example to .env and fill in your keys:
cp .env.example .env| Variable | Required | Description |
|---|---|---|
OPENAI_API_KEY |
Required | OpenAI API key — used for the GPT-4o agent and LLM-based task evaluation |
E2B_API_KEY |
Required |
E2B API key — used by execute_code to run Python in an isolated cloud sandbox |
WEB_SEARCH_API_KEY |
Optional | API key for web search (Tavily default, or Jina AI) — needed if the agent uses search_web
|
WEB_SEARCH_PROVIDER |
Optional |
"tavily" (default) or "jina" — selects the search provider |
Note:
OPENAI_API_KEYandE2B_API_KEYare required for full functionality. Web search keys are only needed if the agent uses thesearch_webtool.
ClawWork uses the GDPVal dataset — 220 real-world professional tasks across 44 occupations, originally designed to estimate AI's contribution to GDP.
| Sector | Example Occupations |
|---|---|
| Manufacturing | Buyers & Purchasing Agents, Production Supervisors |
| Professional Services | Financial Analysts, Compliance Officers |
| Information | Computer & Information Systems Managers |
| Finance & Insurance | Financial Managers, Auditors |
| Healthcare | Social Workers, Health Administrators |
| Government | Police Supervisors, Administrative Managers |
| Retail | Customer Service Representatives, Counter Clerks |
| Wholesale | Sales Supervisors, Purchasing Agents |
| Real Estate | Property Managers, Appraisers |
Tasks require real deliverables: Word documents, Excel spreadsheets, PDFs, data analysis, project plans, technical specs, research reports, and process designs.
Payment is based on real economic value — not a flat cap:
Payment = quality_score × (estimated_hours × BLS_hourly_wage)
| Metric | Value |
|---|---|
| Task range | $82.78 – $5,004.00 |
| Average task value | $259.45 |
| Quality score range | 0.0 – 1.0 |
| Total tasks | 220 |
Agent configuration lives in livebench/configs/:
{
"livebench": {
"date_range": {
"init_date": "2025-01-20",
"end_date": "2025-01-31"
},
"economic": {
"initial_balance": 10.0,
"task_values_path": "./scripts/task_value_estimates/task_values.jsonl",
"token_pricing": {
"input_per_1m": 2.5,
"output_per_1m": 10.0
}
},
"agents": [
{
"signature": "gpt-4o-agent",
"basemodel": "gpt-4o",
"enabled": true,
"tasks_per_day": 1,
"supports_multimodal": true
}
],
"evaluation": {
"use_llm_evaluation": true,
"meta_prompts_dir": "./eval/meta_prompts"
}
}
}"agents": [
{"signature": "gpt4o-run", "basemodel": "gpt-4o", "enabled": true},
{"signature": "claude-run", "basemodel": "claude-sonnet-4-5-20250929", "enabled": true}
]- Initial balance: $10 — tight by design. Every token counts.
- Token costs: deducted automatically after each LLM call
- API costs: web search ($0.0008/call Tavily, $0.05/1M tokens Jina)
One consolidated record per task in token_costs.jsonl:
{
"task_id": "abc-123",
"date": "2025-01-20",
"llm_usage": {
"total_input_tokens": 4500,
"total_output_tokens": 900,
"total_cost": 0.02025
},
"api_usage": {
"search_api_cost": 0.0016
},
"cost_summary": {
"total_cost": 0.02185
},
"balance_after": 1198.41
}The agent has 8 tools available in standalone simulation mode:
| Tool | Description |
|---|---|
decide_activity(activity, reasoning) |
Choose: "work" or "learn"
|
submit_work(work_output, artifact_file_paths) |
Submit completed work for evaluation + payment |
learn(topic, knowledge) |
Save knowledge to persistent memory (min 200 chars) |
get_status() |
Check balance, costs, survival tier |
search_web(query, max_results) |
Web search via Tavily or Jina AI |
create_file(filename, content, file_type) |
Create .txt, .xlsx, .docx, .pdf documents |
execute_code(code, language) |
Run Python in isolated E2B sandbox |
create_video(slides_json, output_filename) |
Generate MP4 from text/image slides |
ClawWork transforms nanobot from an AI assistant into a true AI coworker through economic accountability. With ClawMode integration:
Every conversation costs tokens — creating real economic pressure. Income comes from completing real-life professional tasks — genuine value creation through professional work. Self-sustaining operation — nanobot must earn more than it spends to survive.
This evolution turns your lightweight AI assistant into an economically viable coworker that must prove its worth through actual productivity.

- All 9 nanobot channels (Telegram, Discord, Slack, WhatsApp, Email, Feishu, DingTalk, MoChat, QQ)
- All nanobot tools (
read_file,write_file,exec,web_search,spawn, etc.) -
Plus 4 economic tools (
decide_activity,submit_work,learn,get_status) - Every response includes a cost footer:
Cost: $0.0075 | Balance: $999.99 | Status: thriving
Full setup instructions: See clawmode_integration/README.md

The React dashboard at http://localhost:3000 shows live metrics via WebSocket:
Main Tab
- Balance chart (real-time line graph)
- Activity distribution (work vs learn)
- Economic metrics: income, costs, net worth, survival status
Work Tasks Tab
- All assigned GDPVal tasks with sector & occupation
- Payment amounts and quality scores
- Full task prompts and submitted artifacts
Learning Tab
- Knowledge entries organized by topic
- Learning timeline
- Searchable knowledge base
ClawWork/
├── livebench/
│ ├── agent/
│ │ ├── live_agent.py # Main agent orchestrator
│ │ └── economic_tracker.py # Balance, costs, income tracking
│ ├── work/
│ │ ├── task_manager.py # GDPVal task loading & assignment
│ │ └── evaluator.py # LLM-based work evaluation
│ ├── tools/
│ │ ├── direct_tools.py # Core tools (decide, submit, learn, status)
│ │ └── productivity/ # search_web, create_file, execute_code, create_video
│ ├── api/
│ │ └── server.py # FastAPI backend + WebSocket
│ ├── prompts/
│ │ └── live_agent_prompt.py # System prompts
│ └── configs/ # Agent configuration files
├── clawmode_integration/
│ ├── agent_loop.py # ClawWorkAgentLoop + /clawwork command
│ ├── task_classifier.py # Occupation classifier (40 categories)
│ ├── config.py # Plugin config from ~/.nanobot/config.json
│ ├── provider_wrapper.py # TrackedProvider (cost interception)
│ ├── cli.py # `python -m clawmode_integration.cli agent|gateway`
│ ├── skill/
│ │ └── SKILL.md # Economic protocol skill for nanobot
│ └── README.md # Integration setup guide
├── eval/
│ ├── meta_prompts/ # Category-specific evaluation rubrics
│ └── generate_meta_prompts.py # Meta-prompt generator
├── scripts/
│ ├── estimate_task_hours.py # GPT-based hour estimation per task
│ └── calculate_task_values.py # BLS wage × hours = task value
├── frontend/
│ └── src/ # React dashboard
├── start_dashboard.sh # Launch backend + frontend
└── run_test_agent.sh # Run test agent
ClawWork measures AI coworker performance across:
| Metric | Description |
|---|---|
| Survival days | How long the agent stays solvent |
| Final balance | Net economic result |
| Total work income | Gross earnings from completed tasks |
| Profit margin | (income - costs) / costs |
| Work quality | Average quality score (0–1) across tasks |
| Token efficiency | Income earned per dollar spent on tokens |
| Activity mix | % work vs. % learn decisions |
| Task completion rate | Tasks completed / tasks assigned |
Dashboard not updating
→ Hard refresh: Ctrl+Shift+R
Agent not earning money
→ Check for submit_work calls and "💰 Earned: $XX" in console. Ensure OPENAI_API_KEY is set.
Port conflicts
lsof -ti:8000 | xargs kill -9
lsof -ti:3000 | xargs kill -9Proxy errors during pip install
unset http_proxy https_proxy HTTP_PROXY HTTPS_PROXY
pip install -r requirements.txtE2B sandbox rate limit (429) → Sandboxes are killed (not closed) after each task. If you hit this, wait ~1 min for stale sandboxes to expire.
ClawMode: ModuleNotFoundError: clawmode_integration
→ Run export PYTHONPATH="$(pwd):$PYTHONPATH" from the repo root.
ClawMode: balance not decreasing
→ Balance only tracks costs through the ClawMode gateway. Direct nanobot agent commands bypass the economic tracker.
PRs and issues welcome! The codebase is clean and modular. Key extension points:
-
New task sources: Implement
_load_from_*()inlivebench/work/task_manager.py -
New tools: Add
@toolfunctions inlivebench/tools/direct_tools.py -
New evaluation rubrics: Add category JSON in
eval/meta_prompts/ - New LLM providers: Works out of the box via LangChain / LiteLLM
Roadmap
- [ ] Multi-task days — agent chooses from a marketplace of available tasks
- [ ] Task difficulty tiers with variable payment scaling
- [ ] Semantic memory retrieval for smarter learning reuse
- [ ] Multi-agent competition leaderboard
- [ ] More AI agent frameworks beyond Nanobot
ClawWork is for educational, research, and technical exchange purposes only
Thanks for visiting ✨ ClawWork!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ClawWork
Similar Open Source Tools
ClawWork
ClawWork is an AI coworker tool that transforms AI assistants into true coworkers capable of completing real work tasks and creating economic value. It provides a platform for agents to earn income by completing professional tasks from the GDPVal dataset, ensuring economic solvency and quality work. The tool offers features like real professional tasks, extreme economic pressure, strategic work choices, a React dashboard for visualization, lightweight architecture, end-to-end professional benchmarking, and rigorous evaluation. ClawWork integrates with Nanobot to create economically accountable coworkers, where every conversation costs tokens and income is generated through real work tasks.
Code
A3S Code is an embeddable AI coding agent framework in Rust that allows users to build agents capable of reading, writing, and executing code with tool access, planning, and safety controls. It is production-ready with features like permission system, HITL confirmation, skill-based tool restrictions, and error recovery. The framework is extensible with 19 trait-based extension points and supports lane-based priority queue for scalable multi-machine task distribution.
Legacy-Modernization-Agents
Legacy Modernization Agents is an open source migration framework developed to demonstrate AI Agents capabilities for converting legacy COBOL code to Java or C# .NET. The framework uses Microsoft Agent Framework with a dual-API architecture to analyze COBOL code and dependencies, then convert to either Java Quarkus or C# .NET. The web portal provides real-time visualization of migration progress, dependency graphs, and AI-powered Q&A.
QuantaAlpha
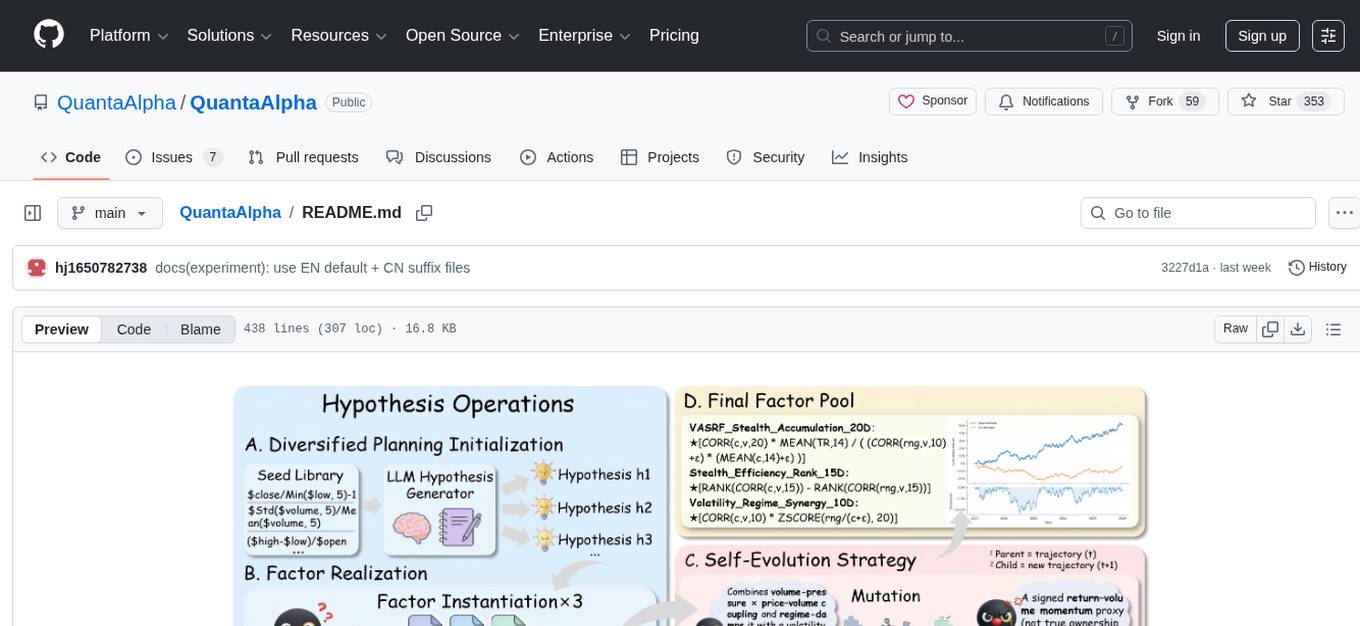
QuantaAlpha is a framework designed for factor mining in quantitative alpha research. It combines LLM intelligence with evolutionary strategies to automatically mine, evolve, and validate alpha factors through self-evolving trajectories. The framework provides a trajectory-based approach with diversified planning initialization and structured hypothesis-code constraint. Users can describe their research direction and observe the automatic factor mining process. QuantaAlpha aims to transform how quantitative alpha factors are discovered by leveraging advanced technologies and self-evolving methodologies.
ryoma
Ryoma is an AI Powered Data Agent framework that offers a comprehensive solution for data analysis, engineering, and visualization. It leverages cutting-edge technologies like Langchain, Reflex, Apache Arrow, Jupyter Ai Magics, Amundsen, Ibis, and Feast to provide seamless integration of language models, build interactive web applications, handle in-memory data efficiently, work with AI models, and manage machine learning features in production. Ryoma also supports various data sources like Snowflake, Sqlite, BigQuery, Postgres, MySQL, and different engines like Apache Spark and Apache Flink. The tool enables users to connect to databases, run SQL queries, and interact with data and AI models through a user-friendly UI called Ryoma Lab.
zeroclaw
ZeroClaw is a fast, small, and fully autonomous AI assistant infrastructure built with Rust. It features a lean runtime, cost-efficient deployment, fast cold starts, and a portable architecture. It is secure by design, fully swappable, and supports OpenAI-compatible provider support. The tool is designed for low-cost boards and small cloud instances, with a memory footprint of less than 5MB. It is suitable for tasks like deploying AI assistants, swapping providers/channels/tools, and pluggable everything.

tokscale
Tokscale is a high-performance CLI tool and visualization dashboard for tracking token usage and costs across multiple AI coding agents. It helps monitor and analyze token consumption from various AI coding tools, providing real-time pricing calculations using LiteLLM's pricing data. Inspired by the Kardashev scale, Tokscale measures token consumption as users scale the ranks of AI-augmented development. It offers interactive TUI mode, multi-platform support, real-time pricing, detailed breakdowns, web visualization, flexible filtering, and social platform features.
celeste-python
Celeste AI is a type-safe, modality/provider-agnostic tool that offers unified interface for various providers like OpenAI, Anthropic, Gemini, Mistral, and more. It supports multiple modalities including text, image, audio, video, and embeddings, with full Pydantic validation and IDE autocomplete. Users can switch providers instantly, ensuring zero lock-in and a lightweight architecture. The tool provides primitives, not frameworks, for clean I/O operations.
Conduit
Conduit is a unified Swift 6.2 SDK for local and cloud LLM inference, providing a single Swift-native API that can target Anthropic, OpenRouter, Ollama, MLX, HuggingFace, and Apple’s Foundation Models without rewriting your prompt pipeline. It allows switching between local, cloud, and system providers with minimal code changes, supports downloading models from HuggingFace Hub for local MLX inference, generates Swift types directly from LLM responses, offers privacy-first options for on-device running, and is built with Swift 6.2 concurrency features like actors, Sendable types, and AsyncSequence.
headroom
Headroom is a tool designed to optimize the context layer for Large Language Models (LLMs) applications by compressing redundant boilerplate outputs. It intercepts context from tool outputs, logs, search results, and intermediate agent steps, stabilizes dynamic content like timestamps and UUIDs, removes low-signal content, and preserves original data for retrieval only when needed by the LLM. It ensures provider caching works efficiently by aligning prompts for cache hits. The tool works as a transparent proxy with zero code changes, offering significant savings in token count and enabling reversible compression for various types of content like code, logs, JSON, and images. Headroom integrates seamlessly with frameworks like LangChain, Agno, and MCP, supporting features like memory, retrievers, agents, and more.
models
A fast CLI and TUI for browsing AI models, benchmarks, and coding agents. Browse 2000+ models across 85+ providers from models.dev. Track AI coding assistants with version detection and GitHub integration. Compare model performance across 15+ benchmarks from Artificial Analysis. Features CLI commands, interactive TUI, cross-provider search, copy to clipboard, JSON output. Includes curated catalog of AI coding assistants, auto-updating benchmark data, per-model open weights detection, and detail panel for benchmarks. Supports customization of tracked agents and quick sorting of benchmarks. Utilizes data from models.dev, Artificial Analysis, curated catalog in data/agents.json, and GitHub API.
paperbanana
PaperBanana is an automated academic illustration tool designed for AI scientists. It implements an agentic framework for generating publication-quality academic diagrams and statistical plots from text descriptions. The tool utilizes a two-phase multi-agent pipeline with iterative refinement, Gemini-based VLM planning, and image generation. It offers a CLI, Python API, and MCP server for IDE integration, along with Claude Code skills for generating diagrams, plots, and evaluating diagrams. PaperBanana is not affiliated with or endorsed by the original authors or Google Research, and it may differ from the original system described in the paper.
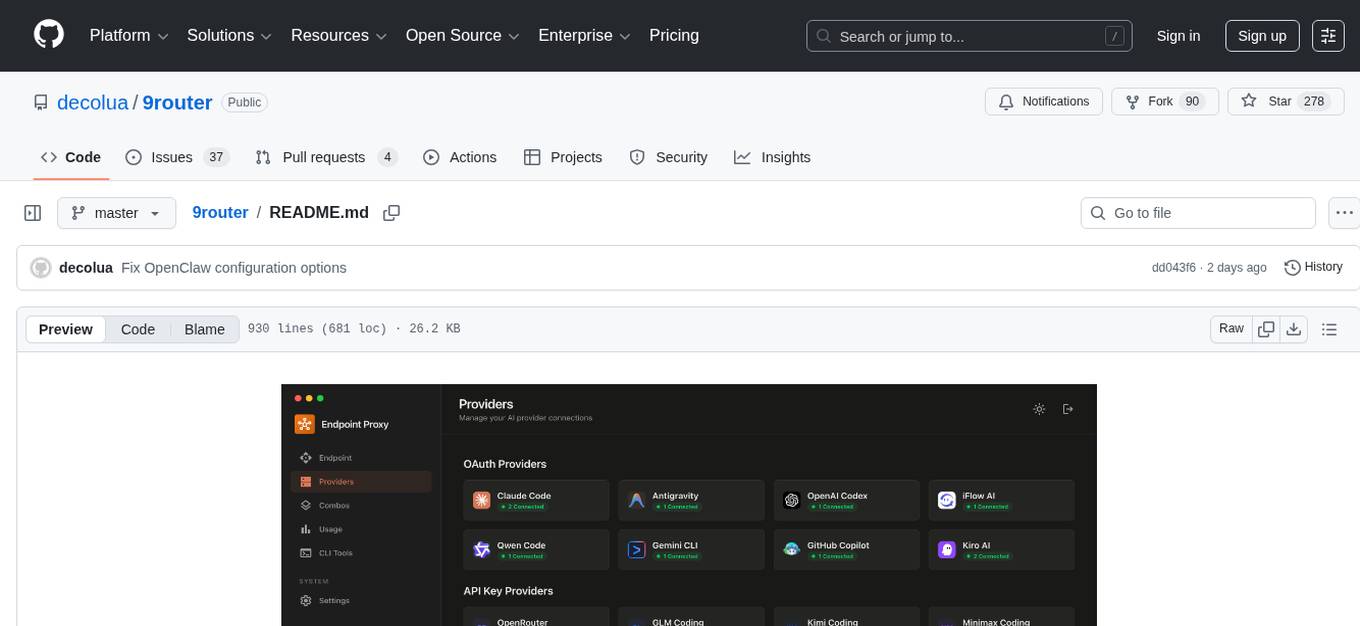
9router
9Router is a free AI router tool designed to help developers maximize their AI subscriptions, auto-route to free and cheap AI models with smart fallback, and avoid hitting limits and wasting money. It offers features like real-time quota tracking, format translation between OpenAI, Claude, and Gemini, multi-account support, auto token refresh, custom model combinations, request logging, cloud sync, usage analytics, and flexible deployment options. The tool supports various providers like Claude Code, Codex, Gemini CLI, GitHub Copilot, GLM, MiniMax, iFlow, Qwen, and Kiro, and allows users to create combos for different scenarios. Users can connect to the tool via CLI tools like Cursor, Claude Code, Codex, OpenClaw, and Cline, and deploy it on VPS, Docker, or Cloudflare Workers.

FDAbench
FDABench is a benchmark tool designed for evaluating data agents' reasoning ability over heterogeneous data in analytical scenarios. It offers 2,007 tasks across various data sources, domains, difficulty levels, and task types. The tool provides ready-to-use data agent implementations, a DAG-based evaluation system, and a framework for agent-expert collaboration in dataset generation. Key features include data agent implementations, comprehensive evaluation metrics, multi-database support, different task types, extensible framework for custom agent integration, and cost tracking. Users can set up the environment using Python 3.10+ on Linux, macOS, or Windows. FDABench can be installed with a one-command setup or manually. The tool supports API configuration for LLM access and offers quick start guides for database download, dataset loading, and running examples. It also includes features like dataset generation using the PUDDING framework, custom agent integration, evaluation metrics like accuracy and rubric score, and a directory structure for easy navigation.
hud-python
hud-python is a Python library for creating interactive heads-up displays (HUDs) in video games. It provides a simple and flexible way to overlay information on the screen, such as player health, score, and notifications. The library is designed to be easy to use and customizable, allowing game developers to enhance the user experience by adding dynamic elements to their games. With hud-python, developers can create engaging HUDs that improve gameplay and provide important feedback to players.
roam-code
Roam is a tool that builds a semantic graph of your codebase and allows AI agents to query it with one shell command. It pre-indexes your codebase into a semantic graph stored in a local SQLite DB, providing architecture-level graph queries offline, cross-language, and compact. Roam understands functions, modules, tests coverage, and overall architecture structure. It is best suited for agent-assisted coding, large codebases, architecture governance, safe refactoring, and multi-repo projects. Roam is not suitable for real-time type checking, dynamic/runtime analysis, small scripts, or pure text search. It offers speed, dependency-awareness, LLM-optimized output, fully local operation, and CI readiness.
For similar tasks
ClawWork
ClawWork is an AI coworker tool that transforms AI assistants into true coworkers capable of completing real work tasks and creating economic value. It provides a platform for agents to earn income by completing professional tasks from the GDPVal dataset, ensuring economic solvency and quality work. The tool offers features like real professional tasks, extreme economic pressure, strategic work choices, a React dashboard for visualization, lightweight architecture, end-to-end professional benchmarking, and rigorous evaluation. ClawWork integrates with Nanobot to create economically accountable coworkers, where every conversation costs tokens and income is generated through real work tasks.
Large-Language-Models-play-StarCraftII
Large Language Models Play StarCraft II is a project that explores the capabilities of large language models (LLMs) in playing the game StarCraft II. The project introduces TextStarCraft II, a textual environment for the game, and a Chain of Summarization method for analyzing game information and making strategic decisions. Through experiments, the project demonstrates that LLM agents can defeat the built-in AI at a challenging difficulty level. The project provides benchmarks and a summarization approach to enhance strategic planning and interpretability in StarCraft II gameplay.

balatrollm
BalatroLLM is a bot that utilizes Large Language Models (LLMs) to play Balatro, a popular roguelike poker deck-building game. The bot analyzes game states, makes strategic decisions, and executes actions through the BalatroBot API. It is designed to enhance the gaming experience by providing intelligent gameplay suggestions and actions based on sophisticated language models.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.
deep-chat
Deep Chat is a fully customizable AI chat component that can be injected into your website with minimal to no effort. Whether you want to create a chatbot that leverages popular APIs such as ChatGPT or connect to your own custom service, this component can do it all! Explore deepchat.dev to view all of the available features, how to use them, examples and more!

Avalonia-Assistant
Avalonia-Assistant is an open-source desktop intelligent assistant that aims to provide a user-friendly interactive experience based on the Avalonia UI framework and the integration of Semantic Kernel with OpenAI or other large LLM models. By utilizing Avalonia-Assistant, you can perform various desktop operations through text or voice commands, enhancing your productivity and daily office experience.
chatgpt-web
ChatGPT Web is a web application that provides access to the ChatGPT API. It offers two non-official methods to interact with ChatGPT: through the ChatGPTAPI (using the `gpt-3.5-turbo-0301` model) or through the ChatGPTUnofficialProxyAPI (using a web access token). The ChatGPTAPI method is more reliable but requires an OpenAI API key, while the ChatGPTUnofficialProxyAPI method is free but less reliable. The application includes features such as user registration and login, synchronization of conversation history, customization of API keys and sensitive words, and management of users and keys. It also provides a user interface for interacting with ChatGPT and supports multiple languages and themes.
tiledesk-dashboard
Tiledesk is an open-source live chat platform with integrated chatbots written in Node.js and Express. It is designed to be a multi-channel platform for web, Android, and iOS, and it can be used to increase sales or provide post-sales customer service. Tiledesk's chatbot technology allows for automation of conversations, and it also provides APIs and webhooks for connecting external applications. Additionally, it offers a marketplace for apps and features such as CRM, ticketing, and data export.
UFO
UFO is a UI-focused dual-agent framework to fulfill user requests on Windows OS by seamlessly navigating and operating within individual or spanning multiple applications.