
ex-fuzzy
A Python library for explainable AI using approximate reasoning
Stars: 53

Ex-Fuzzy is a comprehensive Python library for explainable artificial intelligence through fuzzy logic programming. It enables researchers and practitioners to create interpretable machine learning models using fuzzy association rules. The library supports explainable rule-based learning, complete rule base visualization and validation, advanced learning routines, and complete fuzzy logic systems support. It provides rich visualizations, statistical analysis of results, and performance comparisons between different backends. Ex-Fuzzy also supports conformal learning for more reliable predictions and offers various examples and documentation for users to get started.
README:
🚀 A modern, explainable fuzzy logic library for Python


![]()


Ex-Fuzzy is a comprehensive Python library for explainable artificial intelligence through fuzzy logic programming. Built with a focus on accessibility and visualization, it enables researchers and practitioners to create interpretable machine learning models using fuzzy association rules.
- 🔍 Explainable AI: Create interpretable models that humans can understand. Support for classification and regression problems.
- 📊 Rich Visualizations: Beautiful plots and graphs for fuzzy sets and rules.
- 🛠️ Scikit-learn Compatible: Familiar API for machine learning practitioners.
- 🚀 High Performance: Optimized algorithms with optional GPU support using Evox (https://github.com/EMI-Group/evox).
- Fuzzy Association Rules: For both classification and regression problems with genetic fine-tuning.
- Out-of-the-box Results: Complete compatibility with scikit-learn, minimal to none fuzzy knowledge required to obtain good results.
- Complete Complexity Control: Number of rules, rule length, linguistic variables, etc. can be specified by the user with strong and soft constrains.
- Statistical Analysis of Results: Confidence intervals for all rule quality metrics, repeated experiments for rule robustness.
- Comprehensive Plots: Visualize fuzzy sets and rules.
- Robustness Metrics: Compute validation of rules, ensure linguistic meaning of fuzzy partitions, robustness metrics for rules and space partitions, reproducible experiments, etc.
- Multiple Backend Support: Choose between PyMoo (CPU) and EvoX (GPU-accelerated) backends for evolutionary optimization.
- Genetic Algorithms: Rule base optimization supports fine-tuning of different hyperparameters, like tournament size, crossover rate, etc.
- GPU Genetic Acceleration: EvoX backend with PyTorch provides significant speedups for large datasets and complex rule bases.
- Extensible Architecture: Easy to extend with custom components.
- Multiple Fuzzy Set Types: Classic, Interval-Valued Type-2, and General Type-2 fuzzy sets
- Linguistic Variables: Automatic generation with quantile-based optimization.
Install Ex-Fuzzy using pip:
# Basic installation (CPU only, PyMoo backend)
pip install ex-fuzzy
# With GPU support (EvoX backend with PyTorch)
pip install ex-fuzzy evox torchimport numpy as np
from ex_fuzzy.evolutionary_fit import BaseFuzzyRulesClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load data
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Create and train fuzzy classifier
classifier = BaseFuzzyRulesClassifier(
n_rules=15,
n_antecedents=4,
fuzzy_type="t1", # Type-1 fuzzy sets
backend="pymoo" # or "evox" for GPU acceleration
)
# Train the model
classifier.fit(X_train, y_train)
# Make predictions
predictions = classifier.predict(X_test)
# Evaluate and visualize
from ex_fuzzy.eval_tools import eval_fuzzy_model
eval_fuzzy_model(classifier, X_train, y_train, X_test, y_test,
plot_rules=True, plot_partitions=True)Ex-Fuzzy provides beautiful visualizations to understand your fuzzy models:
Monitor pattern stability and variable usage across multiple runs:
Obtain statistical confidence intervals for your metrics:
Ex-Fuzzy supports two evolutionary optimization backends:
| Backend | Hardware | Best For |
|---|---|---|
| PyMoo | CPU | Small datasets (<10K samples), checkpoint support |
| EvoX | GPU | Large datasets with high generation counts |
Use PyMoo when:
- Working with small to medium datasets
- Running on CPU-only environments
- Need checkpoint/resume functionality
- Memory is limited
Use EvoX when:
- Have GPU available (CUDA recommended)
- Working with large datasets (>10,000 samples)
- No checkpointing (Evox does not support checkpointing yet)
Both backends automatically batch operations to fit available memory and large datasets are processed in chunks to prevent out-of-memory errors.
Ex-Fuzzy supports conformal learning for more reliable predictions.
What is supported:
-
Split conformal calibration on held-out calibration data
-
Set-valued predictions with target coverage
1 - alpha -
Rule-aware conformal analysis: not only classes, but rule firings are also analyzed according to the nonconformity scores.
-
Coverage and efficiency metrics.
-
Demos:
- Notebook:
Demos/conformal_learning_demo.ipynb - Script:
Demos/demos_module/conformal_learning_demo.py
- Notebook:
Try our hands-on examples in Google Colab:
| Topic | Description | Colab Link |
|---|---|---|
| Basic Classification | Introduction to fuzzy classification | |
| Custom Loss Functions | Advanced optimization techniques | |
| Rule File Loading | Working with text-based rule files | |
| Advanced Rules | Using pre-computed rule populations | |
| Temporal Fuzzy Sets | Time-aware fuzzy reasoning | |
| Rule Mining | Automatic rule discovery | |
| EvoX Backend | GPU-accelerated training with EvoX | 📓 Notebook |
| Conformal Learning | Set-valued predictions with calibrated coverage | 📓 Notebook |
🔍 Advanced Rule Mining
from ex_fuzzy.rule_mining import mine_rulebase
from ex_fuzzy.utils import create_fuzzy_variables
# Create fuzzy variables
variables = create_fuzzy_variables(X_train, ['low', 'medium', 'high'])
# Mine rules from data
rules = mine_rulebase(X_train, variables,
support_threshold=0.1,
max_depth=3)
print(f"Discovered {len(rules)} rules")📊 Custom Visualization
from ex_fuzzy.vis_rules import visualize_rulebase
# Create custom rule visualization
visualize_rulebase(classifier.rule_base,
export_path="my_rules.png",
layout="spring")
# Plot fuzzy variable partitions
classifier.plot_fuzzy_variables()🚀 GPU-Accelerated Training (EvoX Backend)
from ex_fuzzy import BaseFuzzyRulesClassifier
# Create classifier with EvoX backend for GPU acceleration
classifier = BaseFuzzyRulesClassifier(
n_rules=30,
n_antecedents=4,
backend='evox', # Use GPU-accelerated EvoX backend
verbose=True
)
# Train with GPU acceleration
classifier.fit(X_train, y_train,
n_gen=50,
pop_size=100)
# EvoX provides significant speedups for:
# - Large datasets (>10,000 samples)
# - Complex rule bases (many rules/antecedents)
# - High generation counts
print("Training completed with GPU acceleration!")🧪 Bootstrap Analysis
from ex_fuzzy.bootstrapping_test import generate_bootstrap_samples
# Generate bootstrap samples
bootstrap_samples = generate_bootstrap_samples(X_train, y_train, n_samples=100)
# Evaluate model stability
bootstrap_results = []
for X_boot, y_boot in bootstrap_samples:
classifier_boot = BaseFuzzyRulesClassifier(n_rules=10)
classifier_boot.fit(X_boot, y_boot)
accuracy = classifier_boot.score(X_test, y_test)
bootstrap_results.append(accuracy)
print(f"Bootstrap confidence interval: {np.percentile(bootstrap_results, [2.5, 97.5])}")- 📖 User Guide: Comprehensive tutorials and examples
- 🔧 API Reference: Detailed function and class documentation
- 🚀 Quick Start Guide: Get up and running fast
- 📊 Examples Gallery: Real-world use cases
- Python >= 3.7
- NumPy >= 1.19.0
- Pandas >= 1.2.0
- Matplotlib >= 3.3.0
- PyMOO >= 0.6.0
- NetworkX >= 2.6 (for rule visualization)
- EvoX >= 0.8.0 (for GPU-accelerated evolutionary optimization)
- PyTorch >= 1.9.0 (required by EvoX for GPU acceleration)
- Scikit-learn >= 0.24.0 (for compatibility examples)
We welcome contributions from the community! Here's how you can help:
Found a bug? Please open an issue with:
- Clear description of the problem
- Steps to reproduce
- Expected vs actual behavior
- System information
Have an idea? Submit a feature request with:
- Clear use case description
- Proposed API design
- Implementation considerations
- Fork the repository
- Create a feature branch:
git checkout -b feature-name - Make your changes with tests
- Run the test suite:
pytest tests/ -v - Submit a pull request
# Install test dependencies
pip install pytest pytest-cov
# Run all tests
pytest tests/ -v
# Run tests with coverage report
pytest tests/ --cov=ex_fuzzy --cov-report=html
# Run specific test file
pytest tests/test_fuzzy_sets_comprehensive.py -vHelp improve documentation by:
- Adding examples
- Fixing typos
- Improving clarity
- Adding translations
This project is licensed under the AGPL v3 License - see the LICENSE file for details.
If you use Ex-Fuzzy in your research, please cite our paper:
@article{fumanalex2024,
title = {Ex-Fuzzy: A library for symbolic explainable AI through fuzzy logic programming},
journal = {Neurocomputing},
pages = {128048},
year = {2024},
issn = {0925-2312},
doi = {10.1016/j.neucom.2024.128048},
url = {https://www.sciencedirect.com/science/article/pii/S0925231224008191},
author = {Javier Fumanal-Idocin and Javier Andreu-Perez}
}- Javier Fumanal-Idocin - Lead Developer
- Javier Andreu-Perez - Licensing officer
- Special thanks to all contributors
- This research has been supported by EU Horizon Europe under the Marie Skłodowska-Curie COFUND grant No 101081327 YUFE4Postdocs.
⭐ Star us on GitHub if you find Ex-Fuzzy useful!

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ex-fuzzy
Similar Open Source Tools
ex-fuzzy
Ex-Fuzzy is a comprehensive Python library for explainable artificial intelligence through fuzzy logic programming. It enables researchers and practitioners to create interpretable machine learning models using fuzzy association rules. The library supports explainable rule-based learning, complete rule base visualization and validation, advanced learning routines, and complete fuzzy logic systems support. It provides rich visualizations, statistical analysis of results, and performance comparisons between different backends. Ex-Fuzzy also supports conformal learning for more reliable predictions and offers various examples and documentation for users to get started.
automem
AutoMem is a production-grade long-term memory system for AI assistants, achieving 90.53% accuracy on the LoCoMo benchmark. It combines FalkorDB (Graph) and Qdrant (Vectors) storage systems to store, recall, connect, learn, and perform with memories. AutoMem enables AI assistants to remember, connect, and evolve their understanding over time, similar to human long-term memory. It implements techniques from peer-reviewed memory research and offers features like multi-hop bridge discovery, knowledge graphs that evolve, 9-component hybrid scoring, memory consolidation cycles, background intelligence, 11 relationship types, and more. AutoMem is benchmark-proven, research-validated, and production-ready, with features like sub-100ms recall, concurrent writes, automatic retries, health monitoring, dual storage redundancy, and automated backups.

flashinfer
FlashInfer is a library for Language Languages Models that provides high-performance implementation of LLM GPU kernels such as FlashAttention, PageAttention and LoRA. FlashInfer focus on LLM serving and inference, and delivers state-the-art performance across diverse scenarios.

mindnlp
MindNLP is an open-source NLP library based on MindSpore. It provides a platform for solving natural language processing tasks, containing many common approaches in NLP. It can help researchers and developers to construct and train models more conveniently and rapidly. Key features of MindNLP include: * Comprehensive data processing: Several classical NLP datasets are packaged into a friendly module for easy use, such as Multi30k, SQuAD, CoNLL, etc. * Friendly NLP model toolset: MindNLP provides various configurable components. It is friendly to customize models using MindNLP. * Easy-to-use engine: MindNLP simplified complicated training process in MindSpore. It supports Trainer and Evaluator interfaces to train and evaluate models easily. MindNLP supports a wide range of NLP tasks, including: * Language modeling * Machine translation * Question answering * Sentiment analysis * Sequence labeling * Summarization MindNLP also supports industry-leading Large Language Models (LLMs), including Llama, GLM, RWKV, etc. For support related to large language models, including pre-training, fine-tuning, and inference demo examples, you can find them in the "llm" directory. To install MindNLP, you can either install it from Pypi, download the daily build wheel, or install it from source. The installation instructions are provided in the documentation. MindNLP is released under the Apache 2.0 license. If you find this project useful in your research, please consider citing the following paper: @misc{mindnlp2022, title={{MindNLP}: a MindSpore NLP library}, author={MindNLP Contributors}, howpublished = {\url{https://github.com/mindlab-ai/mindnlp}}, year={2022} }

lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!
leetcode-py
A Python package to generate professional LeetCode practice environments. Features automated problem generation from LeetCode URLs, beautiful data structure visualizations (TreeNode, ListNode, GraphNode), and comprehensive testing with 10+ test cases per problem. Built with professional development practices including CI/CD, type hints, and quality gates. The tool provides a modern Python development environment with production-grade features such as linting, test coverage, logging, and CI/CD pipeline. It also offers enhanced data structure visualization for debugging complex structures, flexible notebook support, and a powerful CLI for generating problems anywhere.
sdk
The Kubeflow SDK is a set of unified Pythonic APIs that simplify running AI workloads at any scale without needing to learn Kubernetes. It offers consistent APIs across the Kubeflow ecosystem, enabling users to focus on building AI applications rather than managing complex infrastructure. The SDK provides a unified experience, simplifies AI workloads, is built for scale, allows rapid iteration, and supports local development without a Kubernetes cluster.
QuantaAlpha
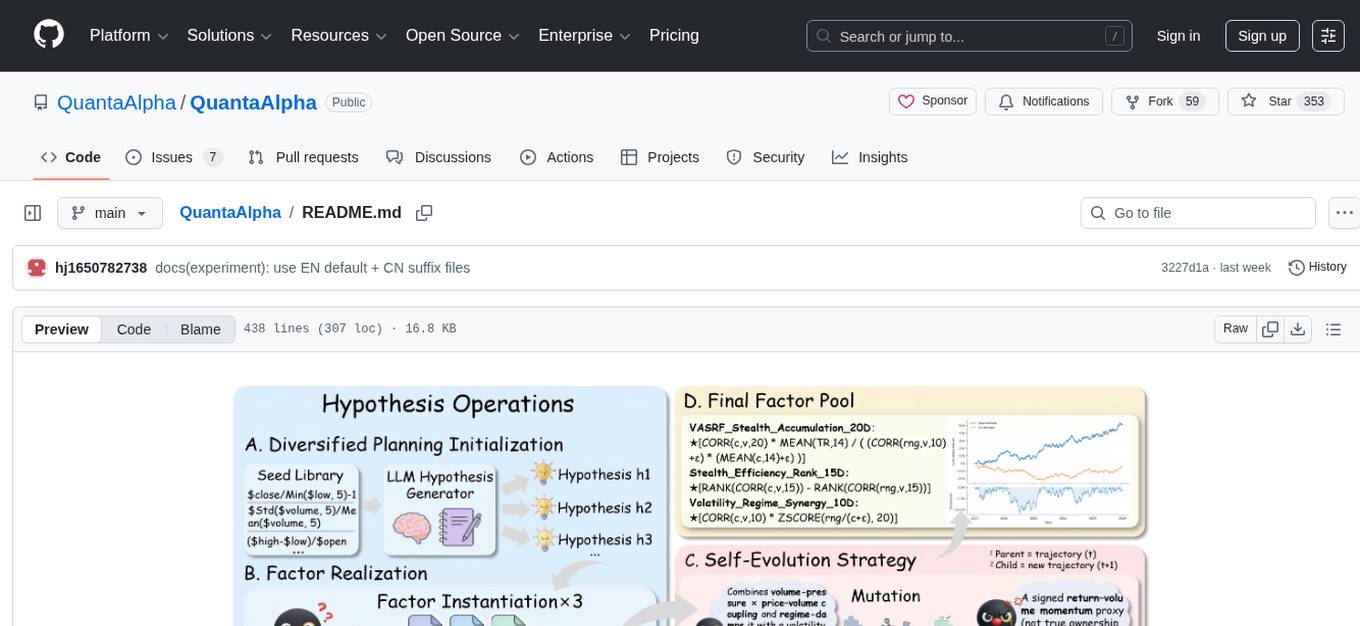
QuantaAlpha is a framework designed for factor mining in quantitative alpha research. It combines LLM intelligence with evolutionary strategies to automatically mine, evolve, and validate alpha factors through self-evolving trajectories. The framework provides a trajectory-based approach with diversified planning initialization and structured hypothesis-code constraint. Users can describe their research direction and observe the automatic factor mining process. QuantaAlpha aims to transform how quantitative alpha factors are discovered by leveraging advanced technologies and self-evolving methodologies.
finite-monkey-engine
FiniteMonkey is an advanced vulnerability mining engine powered purely by GPT, requiring no prior knowledge base or fine-tuning. Its effectiveness significantly surpasses most current related research approaches. The tool is task-driven, prompt-driven, and focuses on prompt design, leveraging 'deception' and hallucination as key mechanics. It has helped identify vulnerabilities worth over $60,000 in bounties. The tool requires PostgreSQL database, OpenAI API access, and Python environment for setup. It supports various languages like Solidity, Rust, Python, Move, Cairo, Tact, Func, Java, and Fake Solidity for scanning. FiniteMonkey is best suited for logic vulnerability mining in real projects, not recommended for academic vulnerability testing. GPT-4-turbo is recommended for optimal results with an average scan time of 2-3 hours for medium projects. The tool provides detailed scanning results guide and implementation tips for users.

TrustEval-toolkit
TrustEval-toolkit is a dynamic and comprehensive framework for evaluating the trustworthiness of Generative Foundation Models (GenFMs) across dimensions such as safety, fairness, robustness, privacy, and more. It offers features like dynamic dataset generation, multi-model compatibility, customizable metrics, metadata-driven pipelines, comprehensive evaluation dimensions, optimized inference, and detailed reports.
ToolNeuron
ToolNeuron is a secure, offline AI ecosystem for Android devices that allows users to run private AI models and dynamic plugins fully offline, with hardware-grade encryption ensuring maximum privacy. It enables users to have an offline-first experience, add capabilities without app updates through pluggable tools, and ensures security by design with strict plugin validation and sandboxing.
nanolang
NanoLang is a minimal, LLM-friendly programming language that transpiles to C for native performance. It features mandatory testing, unambiguous syntax, automatic memory management, LLM-powered autonomous optimization, dual notation for operators, static typing, C interop, and native performance. The language supports variables, functions with mandatory tests, control flow, structs, enums, generic types, and provides a clean, modern syntax optimized for both human readability and AI code generation.

cortex-tms
Cortex TMS is a tool designed for governance documentation of AI coding agents. It provides scaffolding and validation for governance documents to ensure alignment with project standards. The tool offers features like documentation scaffolding, staleness detection, structure validation, and archive management. Cortex TMS helps AI models follow project patterns, detect stale documentation, and enforce human oversight for critical operations.
alphora
Alphora is a full-stack framework for building production AI agents, providing agent orchestration, prompt engineering, tool execution, memory management, streaming, and deployment with an async-first, OpenAI-compatible design. It offers features like agent derivation, reasoning-action loop, async streaming, visual debugger, OpenAI compatibility, multimodal support, tool system with zero-config tools and type safety, prompt engine with dynamic prompts, memory and storage management, sandbox for secure execution, deployment as API, and more. Alphora allows users to build sophisticated AI agents easily and efficiently.

handit.ai
Handit.ai is an autonomous engineer tool designed to fix AI failures 24/7. It catches failures, writes fixes, tests them, and ships PRs automatically. It monitors AI applications, detects issues, generates fixes, tests them against real data, and ships them as pull requests—all automatically. Users can write JavaScript, TypeScript, Python, and more, and the tool automates what used to require manual debugging and firefighting.
agentfield
AgentField is an open-source control plane designed for autonomous AI agents, providing infrastructure for agents to make decisions beyond chatbots. It offers features like scaling infrastructure, routing & discovery, async execution, durable state, observability, trust infrastructure with cryptographic identity, verifiable credentials, and policy enforcement. Users can write agents in Python, Go, TypeScript, or interact via REST APIs. The tool enables the creation of AI backends that reason autonomously within defined boundaries, offering predictability and flexibility. AgentField aims to bridge the gap between AI frameworks and production-ready infrastructure for AI agents.
For similar tasks
ex-fuzzy
Ex-Fuzzy is a comprehensive Python library for explainable artificial intelligence through fuzzy logic programming. It enables researchers and practitioners to create interpretable machine learning models using fuzzy association rules. The library supports explainable rule-based learning, complete rule base visualization and validation, advanced learning routines, and complete fuzzy logic systems support. It provides rich visualizations, statistical analysis of results, and performance comparisons between different backends. Ex-Fuzzy also supports conformal learning for more reliable predictions and offers various examples and documentation for users to get started.
For similar jobs
Detection-and-Classification-of-Alzheimers-Disease
This tool is designed to detect and classify Alzheimer's Disease using Deep Learning and Machine Learning algorithms on an early basis, which is further optimized using the Crow Search Algorithm (CSA). Alzheimer's is a fatal disease, and early detection is crucial for patients to predetermine their condition and prevent its progression. By analyzing MRI scanned images using Artificial Intelligence technology, this tool can classify patients who may or may not develop AD in the future. The CSA algorithm, combined with ML algorithms, has proven to be the most effective approach for this purpose.

Co-LLM-Agents
This repository contains code for building cooperative embodied agents modularly with large language models. The agents are trained to perform tasks in two different environments: ThreeDWorld Multi-Agent Transport (TDW-MAT) and Communicative Watch-And-Help (C-WAH). TDW-MAT is a multi-agent environment where agents must transport objects to a goal position using containers. C-WAH is an extension of the Watch-And-Help challenge, which enables agents to send messages to each other. The code in this repository can be used to train agents to perform tasks in both of these environments.
awesome-synthetic-datasets
This repository focuses on organizing resources for building synthetic datasets using large language models. It covers important datasets, libraries, tools, tutorials, and papers related to synthetic data generation. The goal is to provide pragmatic and practical resources for individuals interested in creating synthetic datasets for machine learning applications.
ai-devices
AI Devices Template is a project that serves as an AI-powered voice assistant utilizing various AI models and services to provide intelligent responses to user queries. It supports voice input, transcription, text-to-speech, image processing, and function calling with conditionally rendered UI components. The project includes customizable UI settings, optional rate limiting using Upstash, and optional tracing with Langchain's LangSmith for function execution. Users can clone the repository, install dependencies, add API keys, start the development server, and deploy the application. Configuration settings can be modified in `app/config.tsx` to adjust settings and configurations for the AI-powered voice assistant.
ROSGPT_Vision
ROSGPT_Vision is a new robotic framework designed to command robots using only two prompts: a Visual Prompt for visual semantic features and an LLM Prompt to regulate robotic reactions. It is based on the Prompting Robotic Modalities (PRM) design pattern and is used to develop CarMate, a robotic application for monitoring driver distractions and providing real-time vocal notifications. The framework leverages state-of-the-art language models to facilitate advanced reasoning about image data and offers a unified platform for robots to perceive, interpret, and interact with visual data through natural language. LangChain is used for easy customization of prompts, and the implementation includes the CarMate application for driver monitoring and assistance.
AIBotPublic
AIBotPublic is an open-source version of AIBotPro, a comprehensive AI tool that provides various features such as knowledge base construction, AI drawing, API hosting, and more. It supports custom plugins and parallel processing of multiple files. The tool is built using bootstrap4 for the frontend, .NET6.0 for the backend, and utilizes technologies like SqlServer, Redis, and Milvus for database and vector database functionalities. It integrates third-party dependencies like Baidu AI OCR, Milvus C# SDK, Google Search, and more to enhance its capabilities.

LLMGA
LLMGA (Multimodal Large Language Model-based Generation Assistant) is a tool that leverages Large Language Models (LLMs) to assist users in image generation and editing. It provides detailed language generation prompts for precise control over Stable Diffusion (SD), resulting in more intricate and precise content in generated images. The tool curates a dataset for prompt refinement, similar image generation, inpainting & outpainting, and visual question answering. It offers a two-stage training scheme to optimize SD alignment and a reference-based restoration network to alleviate texture, brightness, and contrast disparities in image editing. LLMGA shows promising generative capabilities and enables wider applications in an interactive manner.
MetaAgent
MetaAgent is a multi-agent collaboration platform designed to build, manage, and deploy multi-modal AI agents without the need for coding. Users can easily create AI agents by editing a yml file or using the provided UI. The platform supports features such as building LLM-based AI agents, multi-modal interactions with users using texts, audios, images, and videos, creating a company of agents for complex tasks like drawing comics, vector database and knowledge embeddings, and upcoming features like UI for creating and using AI agents, fine-tuning, and RLHF. The tool simplifies the process of creating and deploying AI agents for various tasks.