
automem
AutoMem is a graph-vector memory service that gives AI assistants durable, relational memory:
Stars: 608
AutoMem is a production-grade long-term memory system for AI assistants, achieving 90.53% accuracy on the LoCoMo benchmark. It combines FalkorDB (Graph) and Qdrant (Vectors) storage systems to store, recall, connect, learn, and perform with memories. AutoMem enables AI assistants to remember, connect, and evolve their understanding over time, similar to human long-term memory. It implements techniques from peer-reviewed memory research and offers features like multi-hop bridge discovery, knowledge graphs that evolve, 9-component hybrid scoring, memory consolidation cycles, background intelligence, 11 relationship types, and more. AutoMem is benchmark-proven, research-validated, and production-ready, with features like sub-100ms recall, concurrent writes, automatic retries, health monitoring, dual storage redundancy, and automated backups.
README:

$AUTOMEM: Bags.fm • Jupiter • Photon • DEXScreener
CA: CV485ySXfgFiwLtbh815JRukH4r9ChLhddqsAaZKBAGS (Solana)
AutoMem is a production-grade long-term memory system for AI assistants, achieving 90.53% accuracy on the LoCoMo benchmark (ACL 2024)—outperforming CORE (88.24%).
Deploy in 60 seconds:
railway upYour AI forgets everything between sessions. RAG dumps similar documents. Vector databases match keywords but miss meaning. None of them learn.
AutoMem gives AI assistants the ability to remember, connect, and evolve their understanding over time—just like human long-term memory.
AutoMem combines two complementary storage systems:
- FalkorDB (Graph) - Stores memories as nodes with typed relationships between them
- Qdrant (Vectors) - Enables semantic similarity search via embeddings
This dual architecture lets you ask questions like "why did we choose PostgreSQL?" and get not just the memory, but the reasoning, preferences, and related decisions that informed it.
- 🧠 Store memories with metadata, importance scores, and temporal context
- 🔍 Recall via hybrid search combining semantic, keyword, graph, and temporal signals
- 🔗 Connect memories with 11 typed relationships (RELATES_TO, LEADS_TO, CONTRADICTS, etc.)
- 🎯 Learn through automatic entity extraction, pattern detection, and consolidation
- ⚡ Perform with sub-100ms recall across thousands of memories
AutoMem implements techniques from peer-reviewed memory research:
- HippoRAG 2 (Ohio State, 2025): Graph-vector hybrid for associative memory
- A-MEM (2025): Dynamic memory organization with Zettelkasten-inspired clustering
- MELODI (DeepMind, 2024): Compression via gist representations
- ReadAgent (DeepMind, 2024): Context extension through episodic memory
flowchart TB
subgraph service [AutoMem Service Flask]
API[REST API<br/>Memory Lifecycle]
Enrichment[Background Enrichment<br/>Pipeline]
Consolidation[Consolidation<br/>Engine]
Backups[Automated Backups<br/>Optional]
end
subgraph storage [Dual Storage Layer]
FalkorDB[(FalkorDB<br/>Graph Database)]
Qdrant[(Qdrant<br/>Vector Database)]
end
Client[AI Client] -->|Store/Recall/Associate| API
API --> FalkorDB
API --> Qdrant
Enrichment -->|11 edge types<br/>Pattern nodes| FalkorDB
Enrichment -->|Semantic search<br/>3072-d vectors| Qdrant
Consolidation --> FalkorDB
Consolidation --> Qdrant
Backups -.->|Optional| FalkorDB
Backups -.->|Optional| QdrantFalkorDB (graph) = canonical record, relationships, consolidation Qdrant (vectors) = semantic recall, similarity search Dual storage = Built-in redundancy and disaster recovery
flowchart LR
subgraph trad [Traditional RAG Vector Only]
direction TB
Query1[Query: What database?]
VectorDB1[(Vector DB)]
Result1[✅ PostgreSQL memory<br/>❌ No reasoning<br/>❌ No connections]
Query1 -->|Similarity search| VectorDB1
VectorDB1 --> Result1
end
subgraph automem [AutoMem Graph + Vector]
direction TB
Query2[Query: What database?]
subgraph hybrid [Hybrid Search]
VectorDB2[(Qdrant<br/>Vectors)]
GraphDB2[(FalkorDB<br/>Graph)]
end
Result2[✅ PostgreSQL memory<br/>✅ PREFERS_OVER MongoDB<br/>✅ RELATES_TO team expertise<br/>✅ DERIVED_FROM boring tech]
Query2 --> VectorDB2
Query2 --> GraphDB2
VectorDB2 --> Result2
GraphDB2 --> Result2
endMemory: "Chose PostgreSQL for reliability"
Query: "What database should I use?"
Result: ✅ Finds the memory
❌ Doesn't know WHY you chose it
❌ Can't connect to related decisions
Memory: "Chose PostgreSQL for reliability"
Graph: PREFERS_OVER MongoDB
RELATES_TO "team expertise" memory
DERIVED_FROM "boring technology" principle
Query: "What database should I use?"
Result: ✅ Finds the memory
✅ Knows your decision factors
✅ Shows related preferences
✅ Explains your reasoning pattern
When you ask a question, AutoMem doesn't just find relevant memories—it finds the connections between them. This is called bridge discovery: following graph relationships to surface memories that link your initial results together.
graph TB
Query[User Query:<br/>Why boring tech for Kafka?]
Seed1[Seed Memory 1:<br/>PostgreSQL migration<br/>for operational simplicity]
Seed2[Seed Memory 2:<br/>Kafka vs RabbitMQ<br/>evaluation]
Bridge[Bridge Memory:<br/>Team prefers boring technology<br/>proven, debuggable systems]
Result[Result:<br/>AI understands architectural<br/>philosophy, not just isolated choices]
Query -->|Initial recall| Seed1
Query -->|Initial recall| Seed2
Seed1 -.->|DERIVED_FROM| Bridge
Seed2 -.->|DERIVED_FROM| Bridge
Bridge --> Result
Seed1 --> Result
Seed2 --> ResultTraditional RAG: Returns "Kafka" memories (misses the connection)
AutoMem bridge discovery:
- Seed 1: "Migrated to PostgreSQL for operational simplicity"
- Seed 2: "Evaluating Kafka vs RabbitMQ for message queue"
- Bridge: "Team prefers boring technology—proven, debuggable systems"
AutoMem finds the bridge that connects both decisions → Result: AI understands your architectural philosophy, not just isolated choices
How to enable:
- Set
expand_relations=truein recall requests (enabled by default) - Control depth with
relation_limitandexpansion_limitparameters - Results are ranked by relation strength, temporal relevance, and importance
# After storing: "Migrated to PostgreSQL for operational simplicity"
AutoMem automatically:
├── Extracts entities (PostgreSQL, operational simplicity)
├── Auto-tags (entity:tool:postgresql, entity:concept:ops-simplicity)
├── Detects pattern ("prefers boring technology")
├── Links temporally (PRECEDED_BY migration planning)
└── Connects semantically (SIMILAR_TO "Redis deployment")
# Next query: "Should we use Kafka?"
AI recalls:
- PostgreSQL decision
- "Boring tech" pattern (reinforced across memories)
- Operational simplicity preference
→ Suggests: "Based on your pattern, consider RabbitMQ instead"
flowchart LR
Query[User Query:<br/>database migration<br/>tags=decision<br/>time=last month]
subgraph scoring [Hybrid Scoring Components]
direction TB
V[Vector 25%<br/>Semantic similarity]
K[Keyword 15%<br/>TF-IDF matching]
R[Relation 25%<br/>Graph strength]
C[Content 25%<br/>Token overlap]
T[Temporal 15%<br/>Time alignment]
Tag[Tag 10%<br/>Tag matching]
I[Importance 5%<br/>User priority]
Conf[Confidence 5%<br/>Memory confidence]
Rec[Recency 10%<br/>Freshness boost]
end
FinalScore[Final Score:<br/>Ranked by meaning,<br/>not just similarity]
Query --> V
Query --> K
Query --> R
Query --> C
Query --> T
Query --> Tag
Query --> I
Query --> Conf
Query --> Rec
V --> FinalScore
K --> FinalScore
R --> FinalScore
C --> FinalScore
T --> FinalScore
Tag --> FinalScore
I --> FinalScore
Conf --> FinalScore
Rec --> FinalScoreGET /recall?query=database%20migration&tags=decision&time_query=last%20month
# AutoMem combines nine signals:
score = vector×0.25 # Semantic similarity
+ keyword×0.15 # TF-IDF text matching
+ relation×0.25 # Graph relationship strength
+ content×0.25 # Direct token overlap
+ temporal×0.15 # Time alignment with query
+ tag×0.10 # Tag matching
+ importance×0.05 # User-assigned priority
+ confidence×0.05 # Memory confidence
+ recency×0.10 # Freshness boost
# Result: Memories ranked by meaning, not just similarity- Store - Rich memories with metadata, importance, timestamps, embeddings
- Recall - Hybrid search (vector + keyword + tags + time windows)
- Update - Modify memories, auto-regenerate embeddings
- Delete - Remove from both graph and vector stores
- Associate - Create typed relationships between memories
- Filter - Tag-based queries with prefix/exact matching
AutoMem uses neuroscience-inspired consolidation cycles—like human sleep—to keep memories relevant:
| Cycle | Frequency | Purpose |
|---|---|---|
| Decay | Daily | Exponential relevance scoring (age, access, connections, importance) |
| Creative | Weekly | REM-like processing that discovers non-obvious connections |
| Cluster | Monthly | Groups similar memories, generates meta-patterns |
| Forget | Disabled | Archives low-relevance (<0.2), deletes very old (<0.05) when enabled |
How it works:
- Wrong rabbit holes fade naturally (~30-45 days without access)
- Important memories with strong connections stay indefinitely
- Memories archive before deletion (0.05-0.2 relevance range)
- The system learns what matters to you, not what you explicitly tag
Every memory gets automatically enhanced in the background (doesn't block your API calls):
Enrichment Pipeline (runs immediately after storage):
- Entity extraction - Identifies people, projects, tools, concepts (spaCy NLP)
-
Auto-tagging - Generates
entity:<type>:<slug>for structured queries - Summaries - Lightweight gist representations for quick scanning
-
Temporal links - Connects to recent memories with
PRECEDED_BYrelationships -
Semantic neighbors - Finds similar memories via cosine similarity (
SIMILAR_TO) - Pattern detection - Reinforces emerging themes across your memory graph
Consolidation Engine (runs on configurable schedules):
- See Memory Consolidation section above
Build rich knowledge graphs:
| Type | Use Case | Example |
|---|---|---|
RELATES_TO |
General connection | Bug report → Related issue |
LEADS_TO |
Causal relationship | Problem → Solution |
OCCURRED_BEFORE |
Temporal sequence | Planning → Execution |
PREFERS_OVER |
User preferences | PostgreSQL → MongoDB |
EXEMPLIFIES |
Pattern examples | Code review → Best practice |
CONTRADICTS |
Conflicting info | Old approach → New approach |
REINFORCES |
Supporting evidence | Decision → Validation |
INVALIDATED_BY |
Outdated info | Legacy docs → Current docs |
EVOLVED_INTO |
Knowledge evolution | Initial design → Final design |
DERIVED_FROM |
Source tracking | Implementation → Spec |
PART_OF |
Hierarchical structure | Feature → Epic |
Deploy AutoMem to Railway in 60 seconds:

This deploys 3 services automatically:
- memory-service — Core AutoMem API
- falkordb — Graph database with persistent storage
- mcp-sse-server — MCP bridge for ChatGPT, Claude.ai, ElevenLabs
👉 Deployment Guide for detailed Railway setup
Run everything locally:
# Clone and start services
git clone https://github.com/verygoodplugins/automem.git
cd automem
make dev
# API: http://localhost:8001
# FalkorDB: localhost:6379
# Qdrant: localhost:6333Run API without Docker:
python3 -m venv venv
source venv/bin/activate
pip install -r requirements-dev.txt
PORT=8001 python app.pycurl -X POST http://localhost:8001/memory \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"content": "Chose PostgreSQL over MongoDB for ACID compliance",
"type": "Decision",
"confidence": 0.95,
"tags": ["database", "architecture"],
"importance": 0.9,
"metadata": {
"source": "architecture-meeting",
"alternatives": ["MongoDB", "MySQL"],
"deciding_factors": ["ACID", "team_expertise"]
}
}'Available memory types: Decision, Pattern, Preference, Style, Habit, Insight, Context (default)
-
Explicit
typerecommended when you know the classification -
Omit
typeto let enrichment auto-classify from content
# Hybrid search with tags and time
GET /recall?query=database&tags=decision&time_query=last%20month
# Semantic search with vector
GET /recall?embedding=0.12,0.56,...&limit=10
# Tag prefix matching (finds slack:U123:*, slack:channel-ops, etc.)
GET /recall?tags=slack&tag_match=prefix
# Graph expansion with filtering (reduce noise in related memories)
GET /recall?query=auth%20architecture&expand_relations=true&expand_min_importance=0.5&expand_min_strength=0.3
# Multi-hop entity expansion (e.g., "What is Sarah's sister's job?")
GET /recall?query=What%20is%20Sarah%27s%20sister%27s%20job&expand_entities=truecurl -X POST http://localhost:8001/associate \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"memory1_id": "uuid-postgres-decision",
"memory2_id": "uuid-mongodb-evaluation",
"type": "PREFERS_OVER",
"strength": 0.9
}'AutoMem works with any AI platform via:
Local MCP Bridge (Claude Desktop, Cursor, Claude Code):
# Install official MCP bridge
npm install -g @verygoodplugins/mcp-automem
# Configure for local AI tools
npx @verygoodplugins/mcp-automem setupRemote MCP (Cloud AI Platforms):
Connect AutoMem to cloud AI platforms via HTTPS. Works with:
- ChatGPT (requires developer mode)
- Claude.ai web interface
- Claude mobile app
- ElevenLabs Agents
See Remote MCP documentation for setup instructions.
👉 Resources:
- NPM bridge (local):
@verygoodplugins/mcp-automem - Remote MCP setup: docs/MCP_SSE.md
Any language, any framework:
import requests
response = requests.post(
"https://your-automem.railway.app/memory",
headers={"Authorization": f"Bearer {token}"},
json={"content": "Memory content", "importance": 0.8}
)Traditional RAG retrieves similar documents. AutoMem understands relationships:
RAG: "Here are 5 documents about PostgreSQL" AutoMem: "You chose PostgreSQL over MongoDB because you prefer boring technology for operational simplicity. This pattern also influenced your Redis and RabbitMQ decisions."
- ✅ Typed relationships - Not just "similar", but "causes", "contradicts", "evolved from"
- ✅ Temporal awareness - Knows what preceded, what invalidated, what emerged
- ✅ Pattern learning - Discovers your preferences and decision-making style
- ✅ Consolidation - Memories strengthen or fade based on use—like human memory
Vector databases match embeddings. AutoMem builds knowledge graphs:
- ✅ Multi-hop reasoning - Bridge discovery connects memories across conversation threads
- ✅ 11 relationship types - Structured semantics vs. cosine similarity alone
- ✅ Background intelligence - Auto-enrichment, pattern detection, decay cycles
- ✅ 9-component scoring - Combines semantic, lexical, graph, temporal, and importance signals
AutoMem saves you months of iteration:
- ✅ Benchmark-proven - 90.53% on LoCoMo (ACL 2024)
- ✅ Research-validated - Implements HippoRAG 2, A-MEM, MELODI, ReadAgent principles
- ✅ Production-ready - Auth, admin tools, health monitoring, automated backups
- ✅ Battle-tested - Enrichment pipeline, consolidation engine, retry logic, dual storage
- ✅ Open source - MIT license, deploy anywhere, no vendor lock-in
90.53% overall accuracy across 1,986 questions:
| Category | AutoMem | Notes |
|---|---|---|
| Complex Reasoning | 100% | Perfect score on multi-step reasoning |
| Open Domain | 95.84% | General knowledge recall |
| Temporal Understanding | 85.05% | Time-aware queries |
| Single-hop Recall | 79.79% | Basic fact retrieval |
| Multi-hop Reasoning | 50.00% | Connecting disparate memories (+12.5pp) |
Comparison with other systems:
| System | Score |
|---|---|
| AutoMem | 90.53% |
| CORE | 88.24% |
Run the benchmark yourself: make test-locomo
- ⚡ Sub-100ms recall - Even with 100k+ memories
- 🔄 Concurrent writes - Background enrichment doesn't block API
- 🛡️ Graceful degradation - Works without Qdrant (graph-only mode)
- ♻️ Automatic retries - Failed enrichments queue for reprocessing
- 💚 Health monitoring -
/healthand/enrichment/statusendpoints - 💾 Dual storage redundancy - Data persists in both FalkorDB and Qdrant
- 📦 Automated backups - Optional backup service for disaster recovery
-
AUTOMEM_API_TOKEN- Authentication for all endpoints (except/health) -
FALKORDB_HOST/FALKORDB_PORT- Graph database connection
-
QDRANT_URL/QDRANT_API_KEY- Enable semantic search (setup guide) -
EMBEDDING_PROVIDER- Choosevoyage,openai,local,ollama, orplaceholderbackends -
VOYAGE_API_KEY/VOYAGE_MODEL- Voyage embeddings (if usingvoyage) -
OPENAI_API_KEY- OpenAI embeddings (if usingopenai) -
OPENAI_BASE_URL- Custom endpoint for OpenAI-compatible providers (OpenRouter, LiteLLM, vLLM, etc.) -
OLLAMA_BASE_URL/OLLAMA_MODEL- Ollama embeddings (if usingollama) -
ADMIN_API_TOKEN- Required for/admin/reembedand enrichment controls - Consolidation tuning:
CONSOLIDATION_*_INTERVAL_SECONDS - Enrichment tuning:
ENRICHMENT_*(similarity threshold, retry limits, etc.)
- 📦 Installation Guide - Railway, Docker, development setup
- 🔍 Qdrant Setup Guide - Step-by-step vector database configuration
- 🌉 Remote MCP - Connect cloud AI platforms (ChatGPT, Claude.ai, ElevenLabs) to AutoMem
- 💾 Monitoring & Backups - Health monitoring and automated backups
- 🔧 API Reference - All endpoints with examples
- 🧪 Testing Guide - Unit, integration, live server, and LoCoMo benchmark tests
- 📊 LoCoMo Benchmark - Validate against ACL 2024 long-term memory benchmark
- 🔄 Migration Guide - Move from MCP SQLite
- 🌐 automem.ai - Official website and guides
- 🌐 automem.ai - Official website
- 💬 Discord - Community chat
- 🐦 X Community - Follow updates
- 📺 YouTube - Tutorials and demos
- 🐙 GitHub - Source code
- 📦 NPM MCP Bridge - MCP integration
- 🐛 Issues - Bug reports and feature requests
AutoMem's architecture is based on peer-reviewed research in memory systems and graph theory:
HippoRAG 2 (Ohio State, June 2025)
Finding: Graph-vector hybrid achieves 7% better associative memory than pure vector RAG, approaching human long-term memory performance.
AutoMem implementation: Dual FalkorDB (graph) + Qdrant (vector) architecture with 11 typed relationship edges.
A-MEM (July 2025)
Finding: Dynamic memory organization with Zettelkasten principles enables emergent knowledge structures.
AutoMem implementation: Pattern detection, clustering cycles, and automatic entity linking that builds knowledge graphs from conversation.
MELODI (DeepMind, 2024)
Finding: 8x memory compression without quality loss through gist representations and selective preservation.
AutoMem implementation: Summary generation, importance scoring, and consolidation cycles that strengthen relevant memories while fading noise.
ReadAgent (DeepMind, 2024)
Finding: 20x context extension via episodic memory and temporal organization.
AutoMem implementation: Temporal relationship types (PRECEDED_BY, OCCURRED_BEFORE) and time-aware scoring that preserves conversation flow.
We welcome contributions! Please:
- Fork the repository
- Create a feature branch
- Add tests for your changes
- Submit a pull request
See TESTING.md for running the test suite.
MIT - Because AI memory should be free.
railway upOpen source. Research-validated. Production-ready.
MIT License. Deploy anywhere. No vendor lock-in.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for automem
Similar Open Source Tools
automem
AutoMem is a production-grade long-term memory system for AI assistants, achieving 90.53% accuracy on the LoCoMo benchmark. It combines FalkorDB (Graph) and Qdrant (Vectors) storage systems to store, recall, connect, learn, and perform with memories. AutoMem enables AI assistants to remember, connect, and evolve their understanding over time, similar to human long-term memory. It implements techniques from peer-reviewed memory research and offers features like multi-hop bridge discovery, knowledge graphs that evolve, 9-component hybrid scoring, memory consolidation cycles, background intelligence, 11 relationship types, and more. AutoMem is benchmark-proven, research-validated, and production-ready, with features like sub-100ms recall, concurrent writes, automatic retries, health monitoring, dual storage redundancy, and automated backups.
OpenMemory
OpenMemory is a cognitive memory engine for AI agents, providing real long-term memory capabilities beyond simple embeddings. It is self-hosted and supports Python + Node SDKs, with integrations for various tools like LangChain, CrewAI, AutoGen, and more. Users can ingest data from sources like GitHub, Notion, Google Drive, and others directly into memory. OpenMemory offers explainable traces for recalled information and supports multi-sector memory, temporal reasoning, decay engine, waypoint graph, and more. It aims to provide a true memory system rather than just a vector database with marketing copy, enabling users to build agents, copilots, journaling systems, and coding assistants that can remember and reason effectively.
alphora
Alphora is a full-stack framework for building production AI agents, providing agent orchestration, prompt engineering, tool execution, memory management, streaming, and deployment with an async-first, OpenAI-compatible design. It offers features like agent derivation, reasoning-action loop, async streaming, visual debugger, OpenAI compatibility, multimodal support, tool system with zero-config tools and type safety, prompt engine with dynamic prompts, memory and storage management, sandbox for secure execution, deployment as API, and more. Alphora allows users to build sophisticated AI agents easily and efficiently.
agentfield
AgentField is an open-source control plane designed for autonomous AI agents, providing infrastructure for agents to make decisions beyond chatbots. It offers features like scaling infrastructure, routing & discovery, async execution, durable state, observability, trust infrastructure with cryptographic identity, verifiable credentials, and policy enforcement. Users can write agents in Python, Go, TypeScript, or interact via REST APIs. The tool enables the creation of AI backends that reason autonomously within defined boundaries, offering predictability and flexibility. AgentField aims to bridge the gap between AI frameworks and production-ready infrastructure for AI agents.
logicstamp-context
LogicStamp Context is a static analyzer that extracts deterministic component contracts from TypeScript codebases, providing structured architectural context for AI coding assistants. It helps AI assistants understand architecture by extracting props, hooks, and dependencies without implementation noise. The tool works with React, Next.js, Vue, Express, and NestJS, and is compatible with various AI assistants like Claude, Cursor, and MCP agents. It offers features like watch mode for real-time updates, breaking change detection, and dependency graph creation. LogicStamp Context is a security-first tool that protects sensitive data, runs locally, and is non-opinionated about architectural decisions.

MassGen
MassGen is a cutting-edge multi-agent system that leverages the power of collaborative AI to solve complex tasks. It assigns a task to multiple AI agents who work in parallel, observe each other's progress, and refine their approaches to converge on the best solution to deliver a comprehensive and high-quality result. The system operates through an architecture designed for seamless multi-agent collaboration, with key features including cross-model/agent synergy, parallel processing, intelligence sharing, consensus building, and live visualization. Users can install the system, configure API settings, and run MassGen for various tasks such as question answering, creative writing, research, development & coding tasks, and web automation & browser tasks. The roadmap includes plans for advanced agent collaboration, expanded model, tool & agent integration, improved performance & scalability, enhanced developer experience, and a web interface.
AgentNeo
AgentNeo is an advanced, open-source Agentic AI Application Observability, Monitoring, and Evaluation Framework designed to provide deep insights into AI agents, Large Language Model (LLM) calls, and tool interactions. It offers robust logging, visualization, and evaluation capabilities to help debug and optimize AI applications with ease. With features like tracing LLM calls, monitoring agents and tools, tracking interactions, detailed metrics collection, flexible data storage, simple instrumentation, interactive dashboard, project management, execution graph visualization, and evaluation tools, AgentNeo empowers users to build efficient, cost-effective, and high-quality AI-driven solutions.
empirica
Empirica is an epistemic self-awareness framework for AI agents to understand their knowledge boundaries. It introduces epistemic vectors to measure knowledge state and uncertainty, enabling honest communication. The tool emerged from 600+ real working sessions across various AI systems, providing cognitive infrastructure for distinguishing between confident knowledge and guessing. Empirica's 13 foundational vectors cover engagement, domain knowledge depth, execution capability, information access, understanding clarity, coherence, signal-to-noise ratio, information richness, working state, progress rate, task completion level, work significance, and explicit doubt tracking. It is applicable across industries like software development, research, healthcare, legal, education, and finance, aiding in tasks such as code review, hypothesis testing, diagnostic confidence, case analysis, learning assessment, and risk assessment.
trpc-agent-go
A powerful Go framework for building intelligent agent systems with large language models (LLMs), hierarchical planners, memory, telemetry, and a rich tool ecosystem. tRPC-Agent-Go enables the creation of autonomous or semi-autonomous agents that reason, call tools, collaborate with sub-agents, and maintain long-term state. The framework provides detailed documentation, examples, and tools for accelerating the development of AI applications.

indexify
Indexify is an open-source engine for building fast data pipelines for unstructured data (video, audio, images, and documents) using reusable extractors for embedding, transformation, and feature extraction. LLM Applications can query transformed content friendly to LLMs by semantic search and SQL queries. Indexify keeps vector databases and structured databases (PostgreSQL) updated by automatically invoking the pipelines as new data is ingested into the system from external data sources. **Why use Indexify** * Makes Unstructured Data **Queryable** with **SQL** and **Semantic Search** * **Real-Time** Extraction Engine to keep indexes **automatically** updated as new data is ingested. * Create **Extraction Graph** to describe **data transformation** and extraction of **embedding** and **structured extraction**. * **Incremental Extraction** and **Selective Deletion** when content is deleted or updated. * **Extractor SDK** allows adding new extraction capabilities, and many readily available extractors for **PDF**, **Image**, and **Video** indexing and extraction. * Works with **any LLM Framework** including **Langchain**, **DSPy**, etc. * Runs on your laptop during **prototyping** and also scales to **1000s of machines** on the cloud. * Works with many **Blob Stores**, **Vector Stores**, and **Structured Databases** * We have even **Open Sourced Automation** to deploy to Kubernetes in production.
osaurus
Osaurus is a native, Apple Silicon-only local LLM server built on Apple's MLX for maximum performance on M‑series chips. It is a SwiftUI app + SwiftNIO server with OpenAI‑compatible and Ollama‑compatible endpoints. The tool supports native MLX text generation, model management, streaming and non‑streaming chat completions, OpenAI‑compatible function calling, real-time system resource monitoring, and path normalization for API compatibility. Osaurus is designed for macOS 15.5+ and Apple Silicon (M1 or newer) with Xcode 16.4+ required for building from source.
PAI
PAI is an open-source personal AI infrastructure designed to orchestrate personal and professional lives. It provides a scaffolding framework with real-world examples for life management, professional tasks, and personal goals. The core mission is to augment humans with AI capabilities to thrive in a world full of AI. PAI features UFC Context Architecture for persistent memory, specialized digital assistants for various tasks, an integrated tool ecosystem with MCP Servers, voice system, browser automation, and API integrations. The philosophy of PAI focuses on augmenting human capability rather than replacing it. The tool is MIT licensed and encourages contributions from the open-source community.

handit.ai
Handit.ai is an autonomous engineer tool designed to fix AI failures 24/7. It catches failures, writes fixes, tests them, and ships PRs automatically. It monitors AI applications, detects issues, generates fixes, tests them against real data, and ships them as pull requests—all automatically. Users can write JavaScript, TypeScript, Python, and more, and the tool automates what used to require manual debugging and firefighting.

layra
LAYRA is the world's first visual-native AI automation engine that sees documents like a human, preserves layout and graphical elements, and executes arbitrarily complex workflows with full Python control. It empowers users to build next-generation intelligent systems with no limits or compromises. Built for Enterprise-Grade deployment, LAYRA features a modern frontend, high-performance backend, decoupled service architecture, visual-native multimodal document understanding, and a powerful workflow engine.

tensorzero
TensorZero is an open-source platform that helps LLM applications graduate from API wrappers into defensible AI products. It enables a data & learning flywheel for LLMs by unifying inference, observability, optimization, and experimentation. The platform includes a high-performance model gateway, structured schema-based inference, observability, experimentation, and data warehouse for analytics. TensorZero Recipes optimize prompts and models, and the platform supports experimentation features and GitOps orchestration for deployment.
For similar tasks
automem
AutoMem is a production-grade long-term memory system for AI assistants, achieving 90.53% accuracy on the LoCoMo benchmark. It combines FalkorDB (Graph) and Qdrant (Vectors) storage systems to store, recall, connect, learn, and perform with memories. AutoMem enables AI assistants to remember, connect, and evolve their understanding over time, similar to human long-term memory. It implements techniques from peer-reviewed memory research and offers features like multi-hop bridge discovery, knowledge graphs that evolve, 9-component hybrid scoring, memory consolidation cycles, background intelligence, 11 relationship types, and more. AutoMem is benchmark-proven, research-validated, and production-ready, with features like sub-100ms recall, concurrent writes, automatic retries, health monitoring, dual storage redundancy, and automated backups.
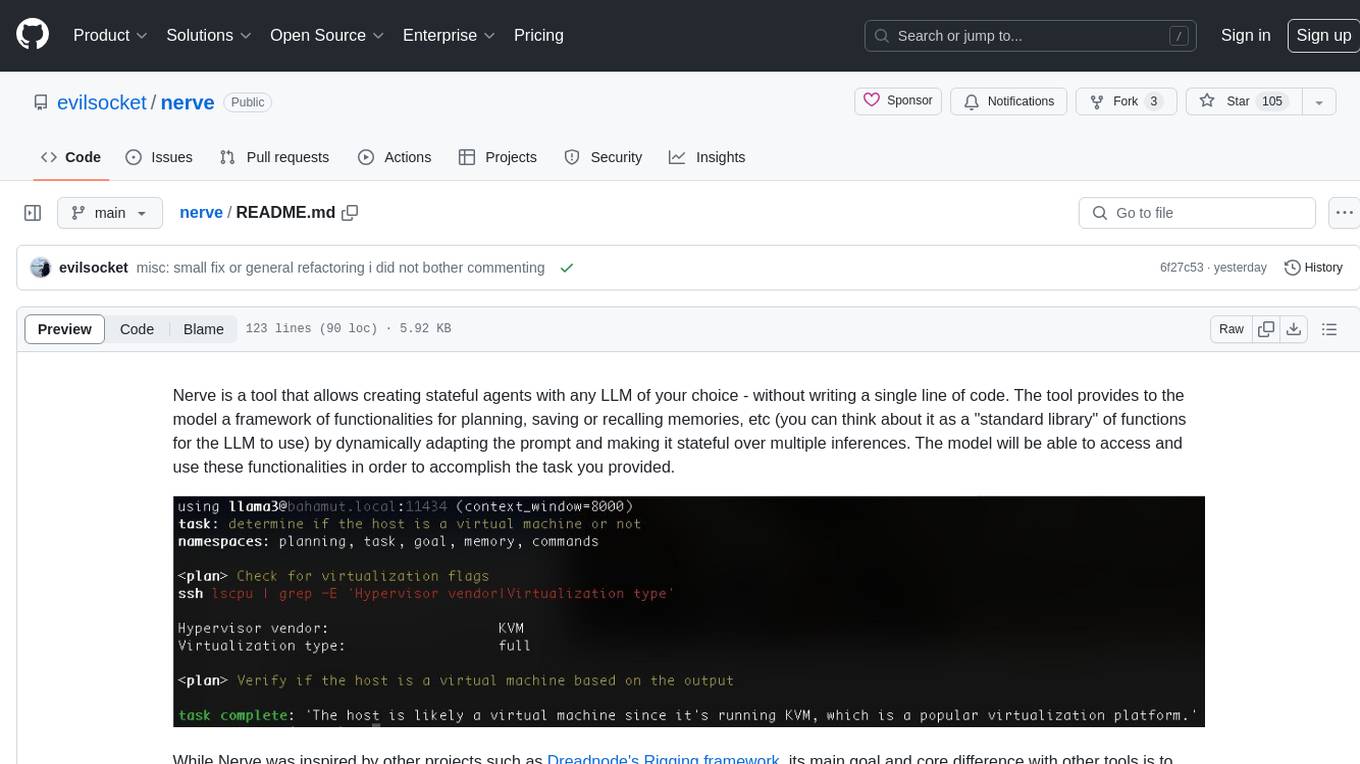
nerve
Nerve is a tool that allows creating stateful agents with any LLM of your choice without writing code. It provides a framework of functionalities for planning, saving, or recalling memories by dynamically adapting the prompt. Nerve is experimental and subject to changes. It is valuable for learning and experimenting but not recommended for production environments. The tool aims to instrument smart agents without code, inspired by projects like Dreadnode's Rigging framework.
shodh-memory
Shodh-Memory is a cognitive memory system designed for AI agents to persist memory across sessions, learn from experience, and run entirely offline. It features Hebbian learning, activation decay, and semantic consolidation, packed into a single ~17MB binary. Users can deploy it on cloud, edge devices, or air-gapped systems to enhance the memory capabilities of AI agents.
claude-memory
Claude Memory is a Chrome extension that enhances interactions with Claude by storing and retrieving important information from conversations, making interactions personalized and context-aware. It allows users to easily manage and organize stored information, with seamless integration with the Claude AI interface.
chrome-extension
Mem0 Chrome Extension lets you own your memory and preferences across any Gen AI apps like ChatGPT, Claude, Perplexity, etc and get personalized, relevant responses. It allows users to store memories from conversations, retrieve relevant memories during chats, manage and organize stored information, and seamlessly integrate with the Claude AI interface. The extension requires an API key and user ID for connecting to the Mem0 API, and it stores this information locally in the browser. Users can troubleshoot common issues, and contributions to improve the extension are welcome under the MIT License.
EverMemOS
EverMemOS is an AI memory system that enables AI to not only remember past events but also understand the meaning behind memories and use them to guide decisions. It achieves 93% reasoning accuracy on the LoCoMo benchmark by providing long-term memory capabilities for conversational AI agents through structured extraction, intelligent retrieval, and progressive profile building. The tool is production-ready with support for Milvus vector DB, Elasticsearch, MongoDB, and Redis, and offers easy integration via a simple REST API. Users can store and retrieve memories using Python code and benefit from features like multi-modal memory storage, smart retrieval mechanisms, and advanced techniques for memory management.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.