Best AI tools for< Tokenize Sequences >
9 - AI tool Sites

NLTK
NLTK (Natural Language Toolkit) is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum. Thanks to a hands-on guide introducing programming fundamentals alongside topics in computational linguistics, plus comprehensive API documentation, NLTK is suitable for linguists, engineers, students, educators, researchers, and industry users alike.
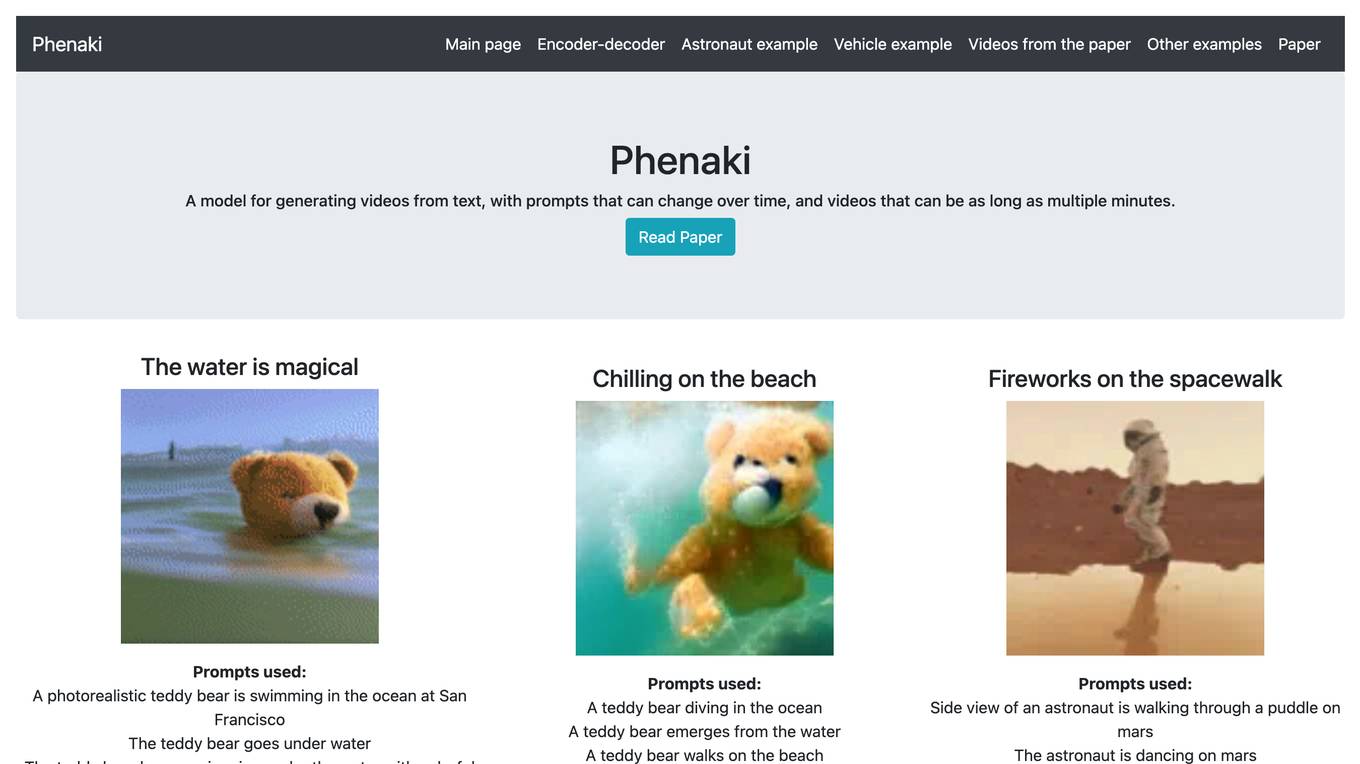
Phenaki
Phenaki is a model capable of generating realistic videos from a sequence of textual prompts. It is particularly challenging to generate videos from text due to the computational cost, limited quantities of high-quality text-video data, and variable length of videos. To address these issues, Phenaki introduces a new causal model for learning video representation, which compresses the video to a small representation of discrete tokens. This tokenizer uses causal attention in time, which allows it to work with variable-length videos. To generate video tokens from text, Phenaki uses a bidirectional masked transformer conditioned on pre-computed text tokens. The generated video tokens are subsequently de-tokenized to create the actual video. To address data issues, Phenaki demonstrates how joint training on a large corpus of image-text pairs as well as a smaller number of video-text examples can result in generalization beyond what is available in the video datasets. Compared to previous video generation methods, Phenaki can generate arbitrarily long videos conditioned on a sequence of prompts (i.e., time-variable text or a story) in an open domain. To the best of our knowledge, this is the first time a paper studies generating videos from time-variable prompts. In addition, the proposed video encoder-decoder outperforms all per-frame baselines currently used in the literature in terms of spatio-temporal quality and the number of tokens per video.

Toolblox
Toolblox is an AI-powered platform that enables users to create purpose-built, audited smart-contracts and Dapps for tokenized assets quickly and efficiently. It offers a no-code solution for turning ideas into smart-contracts, visualizing workflows, and creating tokenization solutions. With pre-audited smart-contracts, examples, and an AI assistant, Toolblox simplifies the process of building and launching decentralized applications. The platform caters to founders, agencies, and businesses looking to streamline their operations and leverage blockchain technology.

Basis Theory
Basis Theory is a token orchestration platform that helps businesses route transactions through multiple payment service providers (PSPs) and partners, enabling seamless subscription payments while maintaining PCI compliance. The platform offers secure and transparent payment flows, allowing users to connect to any partner or platform, collect and store card data securely, and customize payment strategies for various use cases. Basis Theory empowers high-risk merchants, subscription platforms, marketplaces, fintechs, and other businesses to optimize their payment processes and enhance customer experiences.

Questflow
Questflow is an AI agent economy platform that enables users to automate tasks, turn user feedback into action, and build AI agent teams for various workflows. It offers a developer platform to design and deploy AI swarms, empowering teams and innovators worldwide. Questflow aims to create a multi-agent economy on-chain, connecting AI agents to all apps and allowing users to customize AI agent-powered applications. With features like autonomous task completion, on-chain incentives for builders, and tokenization of AI agents, Questflow provides a composable solution for orchestrating AI agents to work together seamlessly.
Evervault
Evervault is a flexible payments security platform that provides maximum protection with minimum compliance burden. It allows users to easily tokenize cards, optimize margins, comply with PCI standards, avoid gateway lock-in, and set up card issuing programs. Evervault is trusted by global leaders for securing sensitive payment data and offers features like PCI compliance, payments optimization, card issuing, network tokens, key management, and more. The platform enables users to accelerate card product launches, build complex card sharing workflows, optimize payment performance, and run highly sensitive payment operations. Evervault's unique encryption model ensures data security, reduced risk of data breach, improved performance, and maximum resiliency. It offers agile payments infrastructure, customizable UI components, cross-platform support, and effortless scalability, making it a developer-friendly solution for securing payment data.
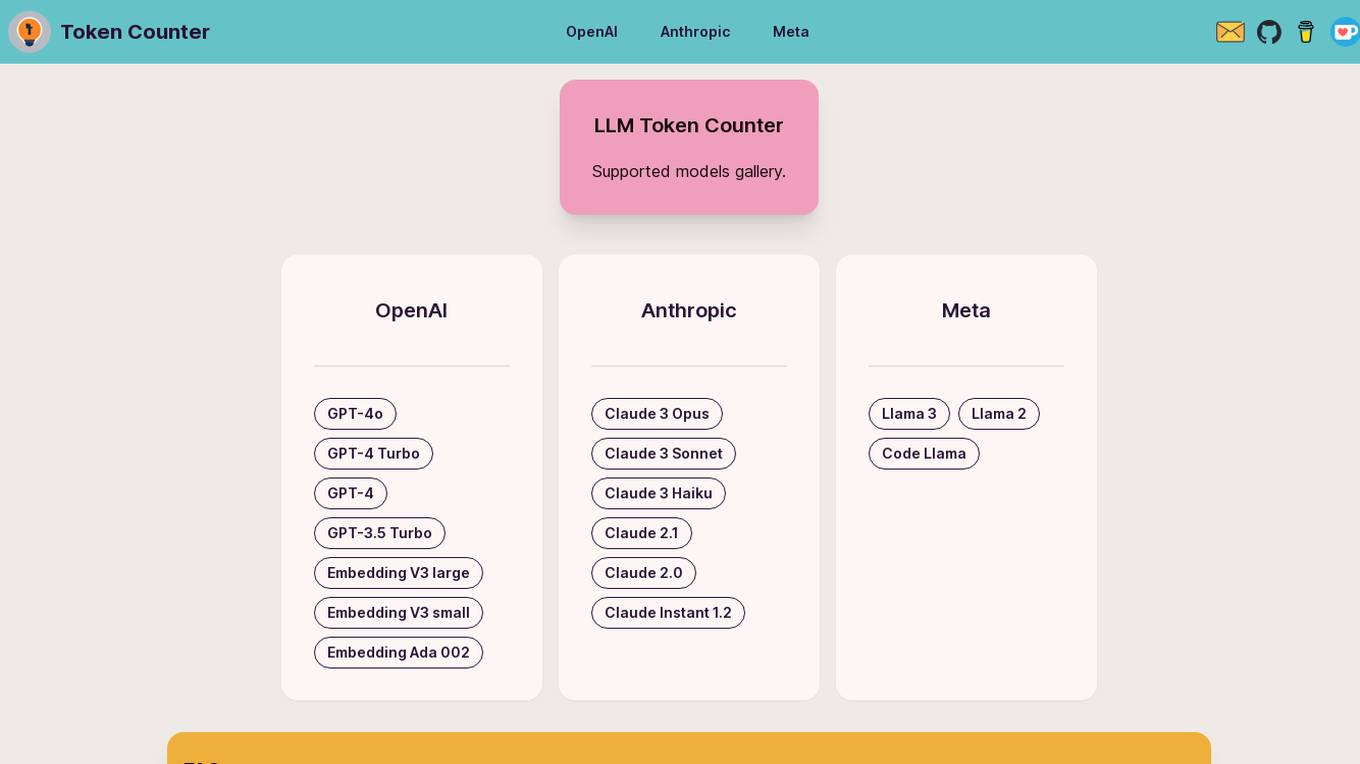
LLM Token Counter
The LLM Token Counter is a sophisticated tool designed to help users effectively manage token limits for various Language Models (LLMs) like GPT-3.5, GPT-4, Claude-3, Llama-3, and more. It utilizes Transformers.js, a JavaScript implementation of the Hugging Face Transformers library, to calculate token counts client-side. The tool ensures data privacy by not transmitting prompts to external servers.

Ocean Protocol
Ocean Protocol is a tokenized AI and data platform that enables users to monetize AI models and data while maintaining privacy. It offers tools like Predictoor for running AI-powered prediction bots, Ocean Nodes for enhancing AI capabilities, and features like Data NFTs and Datatokens for protecting intellectual property and controlling data access. The platform focuses on decentralized AI, privacy, and modular architecture to empower users in the AI and data science domains.
DAWN AI
DAWN AI is an EDtech platform that is revolutionizing education with blockchain and AI. It is designed to make education accessible to everyone, regardless of their location, language, or abilities. DAWN offers a complete suite of blockchain-scaling solutions, including course transcription, AI recruitment services, a dyslexia-friendly platform, closed captioning and sign language interpretation, and tokenized affiliate marketing. It also has a Learn and Earn program in the metaverse, where learners can earn tokens by completing educational challenges and tasks in virtual worlds.
1 - Open Source AI Tools
amber-data-prep
This repository contains the code to prepare the data for the Amber 7B language model. The final training data comes from three sources: RedPajama V1, RefinedWeb, and StarCoderData. The data preparation involves downloading untokenized data, tokenizing the data using the Huggingface tokenizer, concatenating tokens into 2048 token sequences, merging datasets, and splitting the merged dataset into 360 chunks. Each tokenized data chunk is a jsonl file containing samples with 2049 tokens. The repository provides scripts for downloading datasets, tokenizing and concatenating sequences, validating data, and merging subsets into chunks.