Best AI tools for< Dataset Preparation >
20 - AI tool Sites
Prophecy
Prophecy is an AI data preparation and analysis tool that leverages AI-driven visual workflows to turn raw data into trusted insights. It is designed for self-serve use by business users and is built to scale on platforms like Databricks, Snowflake, and BigQuery. With Prophecy, users can prompt AI Agents to generate visual workflows, discover and explore datasets, and document their analysis efficiently. The tool aims to enhance productivity by allowing users to interact with AI Agents to streamline data preparation and analytics processes.
Unsloth
Unsloth is an AI tool designed to make finetuning large language models like Llama-3, Mistral, Phi-3, and Gemma 2x faster, use 70% less memory, and with no degradation in accuracy. The tool provides documentation to help users navigate through training their custom models, covering essentials such as installing and updating Unsloth, creating datasets, running, and deploying models. Users can also integrate third-party tools and utilize platforms like Google Colab.
dataset.macgence
dataset.macgence is an AI-powered data analysis tool that helps users extract valuable insights from their datasets. It offers a user-friendly interface for uploading, cleaning, and analyzing data, making it suitable for both beginners and experienced data analysts. With advanced algorithms and visualization capabilities, dataset.macgence enables users to uncover patterns, trends, and correlations in their data, leading to informed decision-making. Whether you're a business professional, researcher, or student, dataset.macgence can streamline your data analysis process and enhance your data-driven strategies.
Deepfake Detection Challenge Dataset
The Deepfake Detection Challenge Dataset is a project initiated by Facebook AI to accelerate the development of new ways to detect deepfake videos. The dataset consists of over 100,000 videos and was created in collaboration with industry leaders and academic experts. It includes two versions: a preview dataset with 5k videos and a full dataset with 124k videos, each featuring facial modification algorithms. The dataset was used in a Kaggle competition to create better models for detecting manipulated media. The top-performing models achieved high accuracy on the public dataset but faced challenges when tested against the black box dataset, highlighting the importance of generalization in deepfake detection. The project aims to encourage the research community to continue advancing in detecting harmful manipulated media.
Kiln
Kiln is an AI tool designed for fine-tuning LLM models, generating synthetic data, and facilitating collaboration on datasets. It offers intuitive desktop apps, zero-code fine-tuning for various models, interactive visual tools for data generation, Git-based version control for datasets, and the ability to generate various prompts from data. Kiln supports a wide range of models and providers, provides an open-source library and API, prioritizes privacy, and allows structured data tasks in JSON format. The tool is free to use and focuses on rapid AI prototyping and dataset collaboration.
Cogitotech
Cogitotech is an AI tool that specializes in data annotation and labeling expertise. The platform offers a comprehensive suite of services tailored to meet training data needs for computer vision models and AI applications. With a decade-long industry exposure, Cogitotech provides high-quality training data for industries like healthcare, financial services, security, and more. The platform helps minimize biases in AI algorithms and ensures accurate and reliable training data solutions for deploying AI in real-life systems.
Datature
Datature is an all-in-one platform for building and deploying computer vision models. It provides tools for data management, annotation, training, and deployment, making it easy to develop and implement computer vision solutions. Datature is used by a variety of industries, including healthcare, retail, manufacturing, and agriculture.
Education Data Center
The Education Data Center (EDC) Version 2.0 is a platform dedicated to providing clear and timely access to education data for researchers and education stakeholders. It offers a State Assessment Data Repository, a leading database of state assessment data in the United States. Users can download data files, utilize a custom-made AI tool to query the data, and access information about the EDC. The platform aims to support evidence-based decision-making to enhance the educational support for the nation's students.
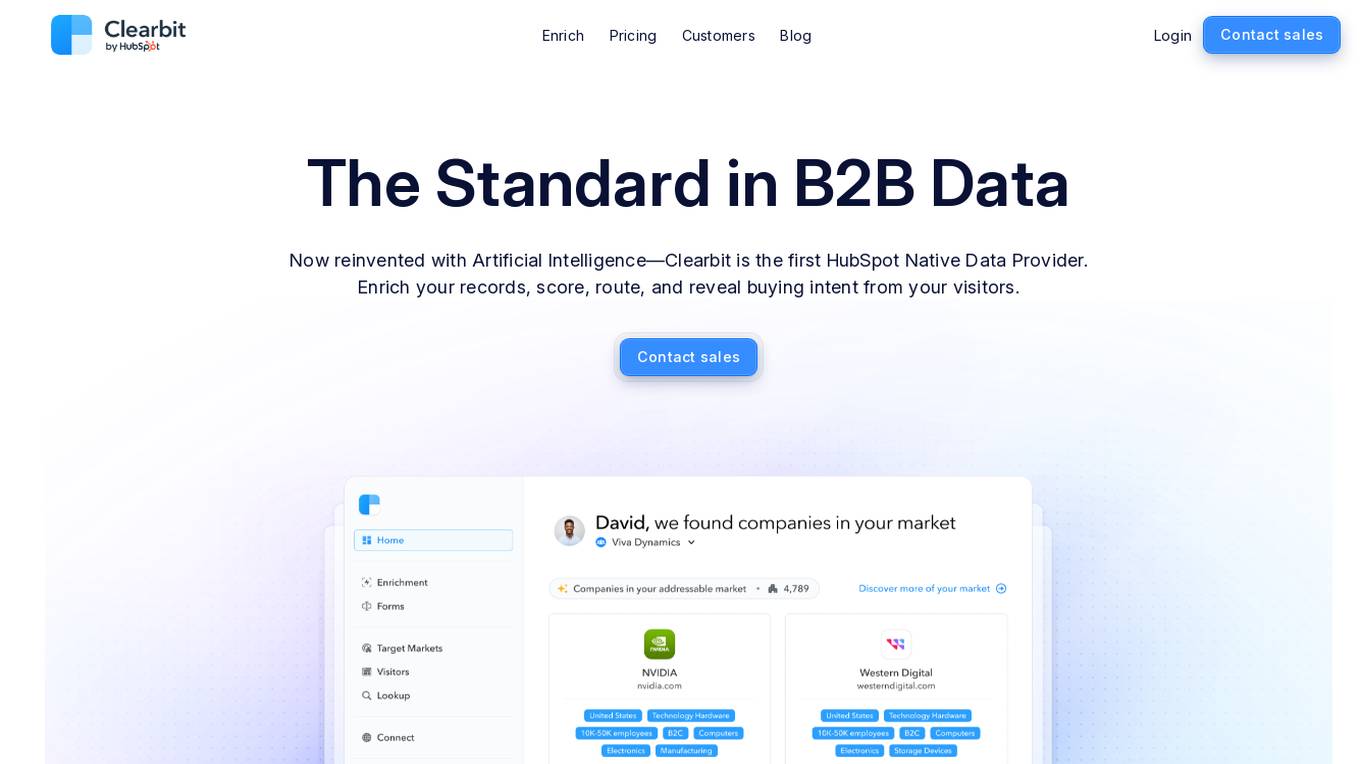
Clearbit
Clearbit is a B2B marketing intelligence platform that provides data enrichment, scoring, routing, and buying intent signals. It is powered by artificial intelligence and is the first HubSpot Native Data Provider. Clearbit's data foundation is built on public data from the web, proprietary data, and the power of LLMs to convert unstructured information into precise and standardized data sets. This data can be used to enrich leads, contacts, and accounts, and to identify hidden buying intent. Clearbit also offers a variety of features to help businesses score and route leads, and to create better converting forms.
Create AI Characters and Chat with AI
This website allows users to create AI characters and chat with them. Users can customize their characters' appearance, personality, and interests. They can also choose from a variety of topics to chat about. The website uses artificial intelligence to generate the characters' responses, which are designed to be realistic and engaging.

LINQ Me Up
LINQ Me Up is an AI-powered tool designed to boost .Net productivity by generating and converting LINQ code queries. It allows users to effortlessly convert SQL queries to LINQ code, transform LINQ code into SQL queries, and generate tailored LINQ queries for various datasets. The tool supports C# and Visual Basic code, Method and Query syntax, and provides AI-powered analysis for optimized results. LINQ Me Up aims to supercharge productivity by simplifying query conversion processes and enabling users to focus on essential code parts.
Powerdrill
Powerdrill is a platform that provides swift insights from knowledge and data. It offers a range of features such as discovering datasets, creating BI dashboards, accessing various apps, resources, blogs, documentation, and changelogs. The platform is available in English and fosters a community through its affiliate program. Users can sign up for a basic plan to start utilizing the tools and services offered by Powerdrill.
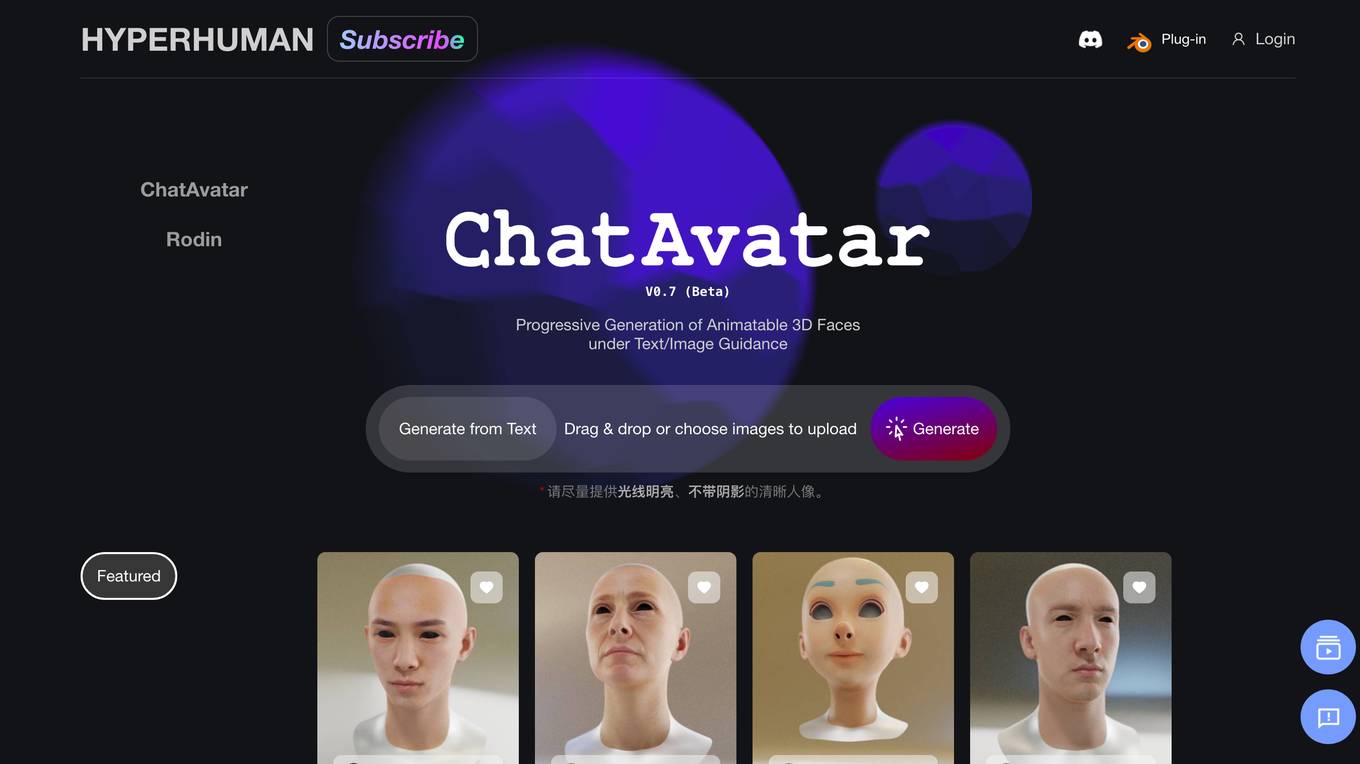
Rodin AI
Rodin AI is a free AI 3D model generator that allows users to instantly create stunning 3D assets, models, and objects powered by AI technology. The platform offers various subscription plans tailored for different user needs, such as business, education, and enterprise. Users can generate 3D designs using AI algorithms and access features like OmniCraft for texture generation, Mesh Editor for model editing, and HDRI Generation for high-quality panoramas. Rodin AI supports multiple languages and provides advanced options for subscribers to enhance their 3D modeling experience.
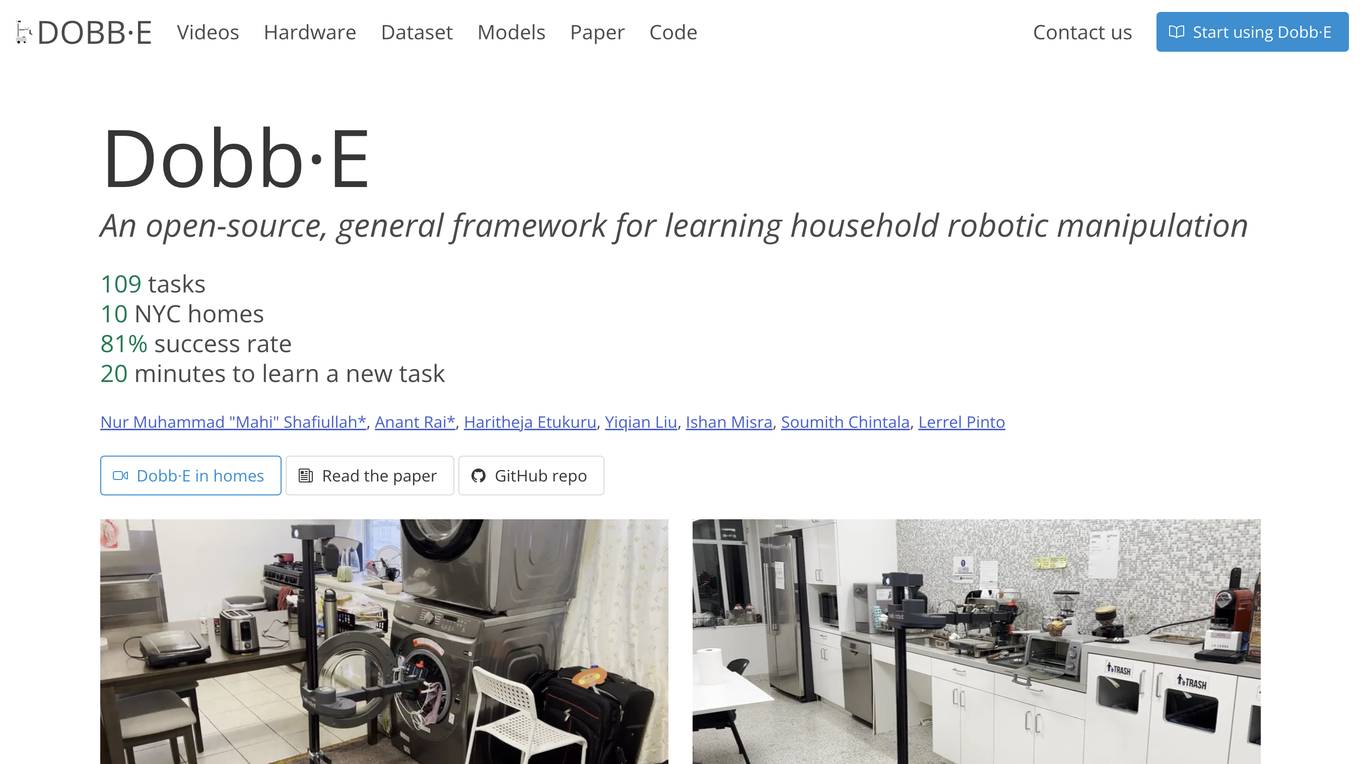
Dobb·E
Dobb·E is an open-source, general framework for learning household robotic manipulation. It aims to create a 'generalist machine' for homes, a domestic assistant that can adapt and learn various tasks cost-effectively. Dobb·E can learn a new task with just five minutes of demonstration, achieving an 81% success rate in 10 NYC homes. The system is designed to accelerate research on home robots and eventually enable robot butlers in every home.
foodai.app
foodai.app is a website domain that may be for sale. It does not currently offer any AI tool or application. The website seems to be focused on the sale of the domain name and provides contact information for inquiries. It is a simple webpage with limited content and no interactive features.
Averroes
Averroes is the #1 AI Automated Visual Inspection Software designed for various industries such as Oil and Gas, Food and Beverage, Pharma, Semiconductor, and Electronics. It offers an end-to-end AI visual inspection platform that allows users to effortlessly train and deploy custom AI models for defect classification, object detection, and segmentation. Averroes provides advanced solutions for quality assurance, including automated defect classification, submicron defect detection, defect segmentation, defect review, and defect monitoring. The platform ensures labeling consistency, offers flexible deployment options, and has shown remarkable improvements in defect detection and productivity for semiconductor OEMs.
How Old Do I Look?
This AI-powered age detection tool analyzes your photo to estimate how old you look. It utilizes advanced artificial intelligence technology to assess facial characteristics such as wrinkles, skin texture, and facial features, comparing them against a vast dataset to provide an approximation of your age. The tool is free to use and ensures privacy by automatically deleting uploaded photos after analysis.
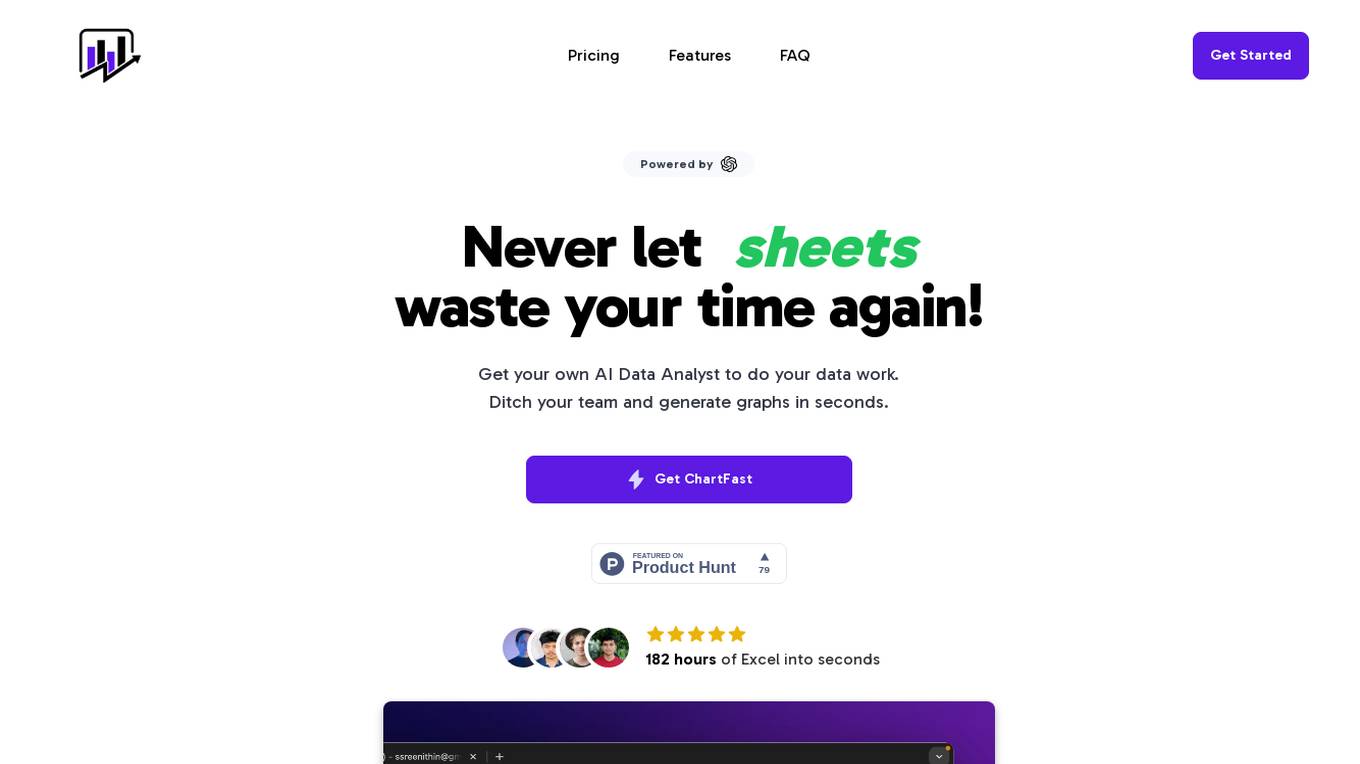
ChartFast
ChartFast is an AI Data Analyzer tool that automates data visualization and analysis tasks, powered by GPT-4 technology. It allows users to generate precise and sleek graphs in seconds, process vast amounts of data, and provide interactive data queries and quick exports. With features like specialized internal libraries for complex graph generation, customizable visualization code, and instant data export, ChartFast aims to streamline data work and enhance data analysis efficiency.
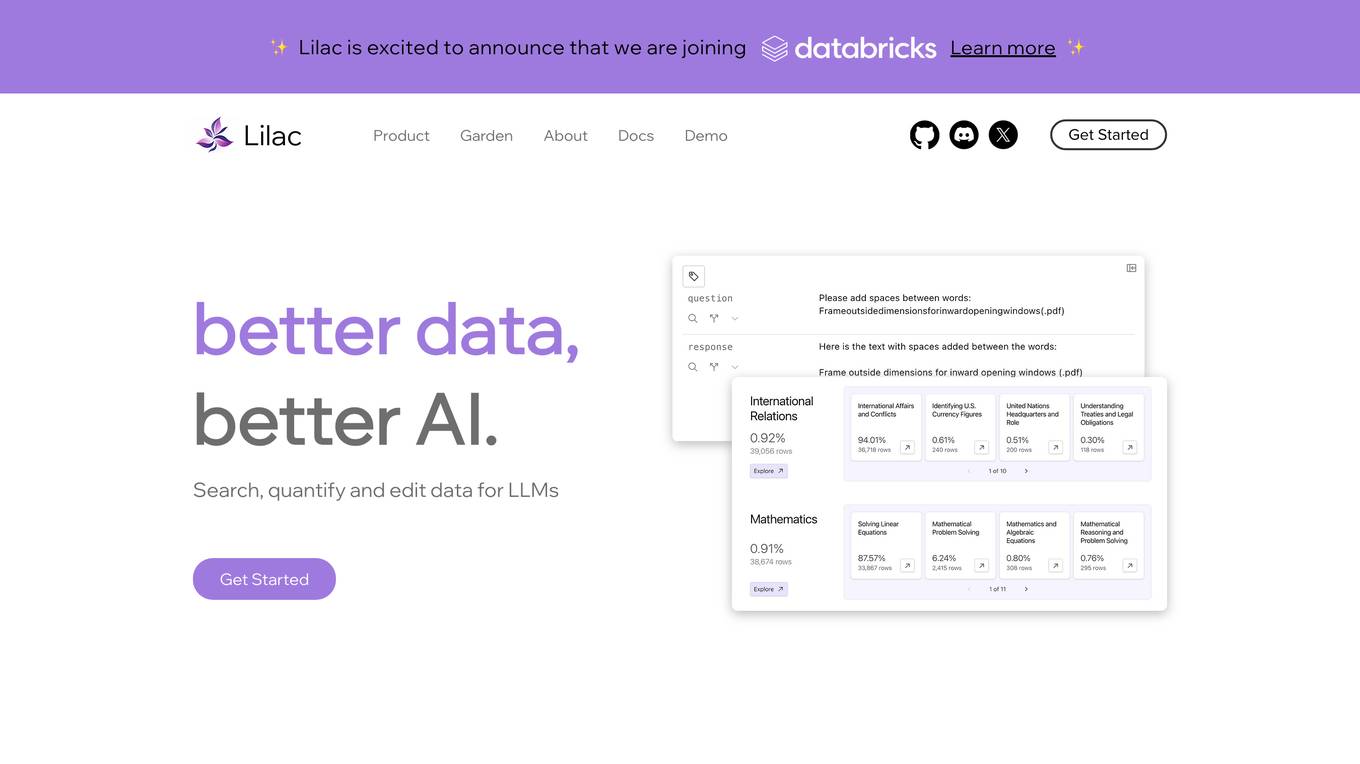
Lilac
Lilac is an AI tool designed to enhance data quality and exploration for AI applications. It offers features such as data search, quantification, editing, clustering, semantic search, field comparison, and fuzzy-concept search. Lilac enables users to accelerate dataset computations and transformations, making it a valuable asset for data scientists and AI practitioners. The tool is trusted by Alignment Lab and is recommended for working with LLM datasets.

Claude
Claude is a large multi-modal model, trained by Google. It is similar to GPT-3, but it is trained on a larger dataset and with more advanced techniques. Claude is capable of generating human-like text, translating languages, answering questions, and writing different kinds of creative content.
1 - Open Source AI Tools

CuMo
CuMo is a project focused on scaling multimodal Large Language Models (LLMs) with Co-Upcycled Mixture-of-Experts. It introduces CuMo, which incorporates Co-upcycled Top-K sparsely-gated Mixture-of-experts blocks into the vision encoder and the MLP connector, enhancing the capabilities of multimodal LLMs. The project adopts a three-stage training approach with auxiliary losses to stabilize the training process and maintain a balanced loading of experts. CuMo achieves comparable performance to other state-of-the-art multimodal LLMs on various Visual Question Answering (VQA) and visual-instruction-following benchmarks.
15 - OpenAI Gpts
Dr. Classify
Just upload a numerical dataset for classification task, will apply data analysis and machine learning steps to make a best model possible.

![VitalsGPT [V0.0.2.2] Screenshot](/screenshots_gpts/g-cL1rJdm11.jpg)
VitalsGPT [V0.0.2.2]
Simple CustomGPT built on Vitals Inquiry Case in Malta, aimed to help journalists and citizens navigate the inquiry's large dataset in a neutral, informative fashion. Always cross-reference replies to actual data. Do not rely solely on this LLM for verification of facts.
Power BI Wizard
Your Power BI assistant for dataset creation, DAX, report review, design, and more... [Updated version].
Chronic Disease Indicators Expert
This chatbot answers questions about the CDC’s Chronic Disease Indicators dataset
Psychology Insight Analyzer
Psychology data analysis expert that guides users through structured, step-by-step exploration of a CSV data set. The analysis is based on research questions.
Personality AI Creator
I will create a quality data set for a personality AI, just dive into each module by saying the name of it and do so for all the modules. If you find it useful, share it to your friends

Dutch SaaS Top 100 Growth in Employees
Analyze and interpret datasets on Dutch SaaS companies' employee growth. Created by [E-commercemanagers.com](https://e-commercemanagers.com).

DataQualityGuardian
A GPT-powered assistant specializing in data validation and quality checks for various datasets.
Eurostat Explorer
Explore & interpret the Eurostat database. Type in requests for statistics, also ask to visualize it. Works best wish specific datasets. It's meant for professionals familiar with the Eurostat database looking for a faster way to explore it.


ResourceFinder
Assists in identifying and utilizing APIs and files effectively to enhance user-designed GPTs.

HuggingFace Helper
A witty yet succinct guide for HuggingFace, offering technical assistance on using the platform - based on their Learning Hub