Best AI tools for< Llm Debugging >
Infographic
20 - AI tool Sites
Langfuse
Langfuse is an AI tool that offers the Langfuse TypeScript SDK v4 for building and debugging LLM (Large Language Models) applications. It provides features such as tracing, prompt management, evaluation, and metrics to enhance the performance of LLM applications. Langfuse is backed by a team of experts and offers integrations with various platforms and SDKs. The tool aims to simplify the development process of complex LLM applications and improve overall efficiency.
Parea AI
Parea AI is an AI-powered writing assistant that helps you write better, faster, and more efficiently. It can help you with a variety of writing tasks, including generating text, translating languages, and checking grammar and spelling.
Agenta.ai
Agenta.ai is a platform designed to provide prompt management, evaluation, and observability for LLM (Large Language Model) applications. It aims to address the challenges faced by AI development teams in managing prompts, collaborating effectively, and ensuring reliable product outcomes. By centralizing prompts, evaluations, and traces, Agenta.ai helps teams streamline their workflows and follow best practices in LLMOps. The platform offers features such as unified playground for prompt comparison, automated evaluation processes, human evaluation integration, observability tools for debugging AI systems, and collaborative workflows for PMs, experts, and developers.
FriendliAI
FriendliAI is a generative AI infrastructure company that offers efficient, fast, and reliable generative AI inference solutions for production. Their cutting-edge technologies enable groundbreaking performance improvements, cost savings, and lower latency. FriendliAI provides a platform for building and serving compound AI systems, deploying custom models effortlessly, and monitoring and debugging model performance. The application guarantees consistent results regardless of the model used and offers seamless data integration for real-time knowledge enhancement. With a focus on security, scalability, and performance optimization, FriendliAI empowers businesses to scale with ease.
Giskard
Giskard is an AI Red Teaming & LLM Security Platform designed to continuously secure LLM agents by preventing hallucinations and security issues in production. It offers automated testing to catch vulnerabilities before they happen, trusted by enterprise AI leaders to ensure data and reputation protection. The platform provides comprehensive protection against various security attacks and vulnerabilities, offering end-to-end encryption, data residency & isolation, and compliance with GDPR, SOC 2 Type II, and HIPAA. Giskard helps in uncovering AI vulnerabilities, stopping business failures at the source, unifying testing across teams, and saving time with continuous testing to prevent regressions.
Athina AI
Athina AI is a comprehensive platform designed to monitor, debug, analyze, and improve the performance of Large Language Models (LLMs) in production environments. It provides a suite of tools and features that enable users to detect and fix hallucinations, evaluate output quality, analyze usage patterns, and optimize prompt management. Athina AI supports integration with various LLMs and offers a range of evaluation metrics, including context relevancy, harmfulness, summarization accuracy, and custom evaluations. It also provides a self-hosted solution for complete privacy and control, a GraphQL API for programmatic access to logs and evaluations, and support for multiple users and teams. Athina AI's mission is to empower organizations to harness the full potential of LLMs by ensuring their reliability, accuracy, and alignment with business objectives.
LangChain
LangChain is a framework for developing applications powered by large language models (LLMs). It simplifies every stage of the LLM application lifecycle, including development, productionization, and deployment. LangChain consists of open-source libraries such as langchain-core, langchain-community, and partner packages. It also includes LangGraph for building stateful agents and LangSmith for debugging and monitoring LLM applications.

Haystack
Haystack is a production-ready open-source AI framework designed to facilitate building AI applications. It offers a flexible components and pipelines architecture, allowing users to customize and build applications according to their specific requirements. With partnerships with leading LLM providers and AI tools, Haystack provides freedom of choice for users. The framework is built for production, with fully serializable pipelines, logging, monitoring integrations, and deployment guides for full-scale deployments on various platforms. Users can build Haystack apps faster using deepset Studio, a platform for drag-and-drop construction of pipelines, testing, debugging, and sharing prototypes.
Awan LLM
Awan LLM is an AI tool that offers an Unlimited Tokens, Unrestricted, and Cost-Effective LLM Inference API Platform for Power Users and Developers. It allows users to generate unlimited tokens, use LLM models without constraints, and pay per month instead of per token. The platform features an AI Assistant, AI Agents, Roleplay with AI companions, Data Processing, Code Completion, and Applications for profitable AI-powered applications.

LLM Clash
LLM Clash is a web-based application that allows users to compare the outputs of different large language models (LLMs) on a given task. Users can input a prompt and select which LLMs they want to compare. The application will then display the outputs of the LLMs side-by-side, allowing users to compare their strengths and weaknesses.
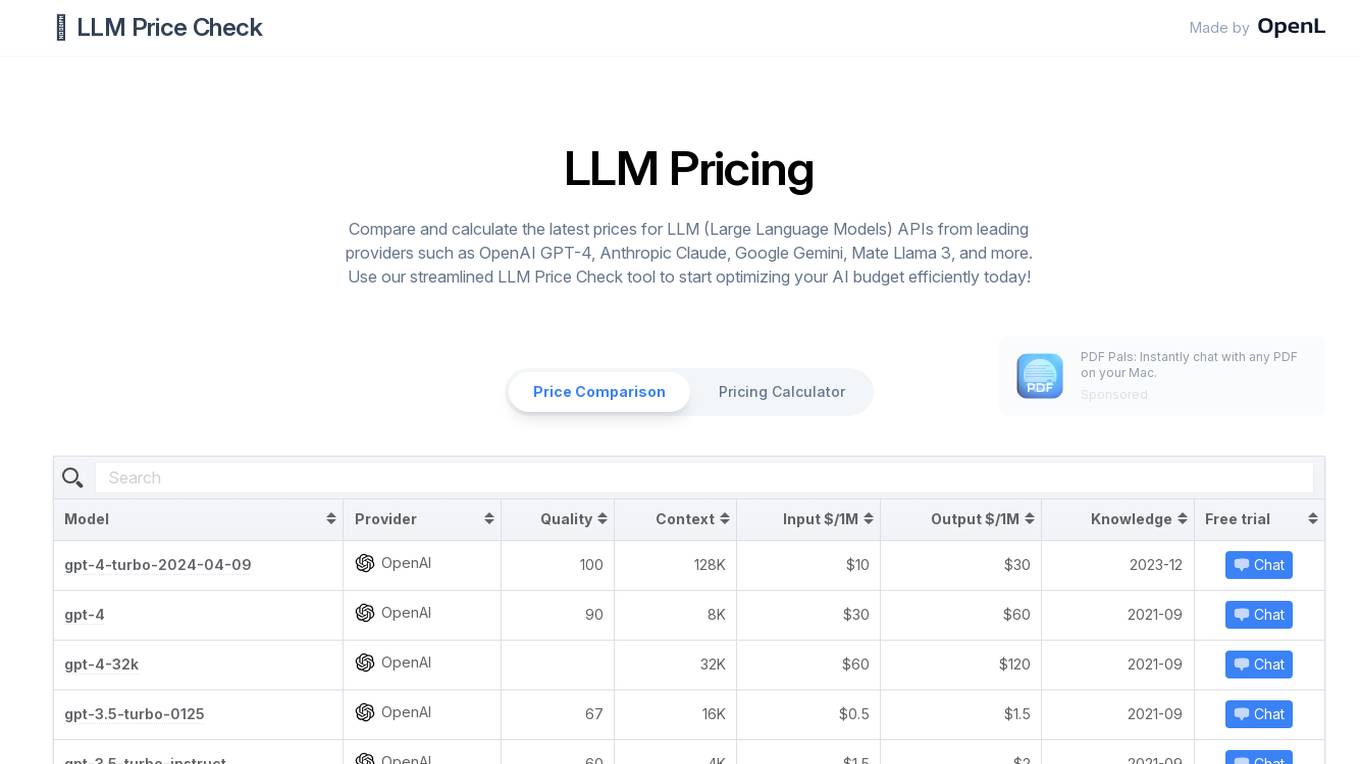
LLM Price Check
LLM Price Check is an AI tool designed to compare and calculate the latest prices for Large Language Models (LLM) APIs from leading providers such as OpenAI, Anthropic, Google, and more. Users can use the streamlined tool to optimize their AI budget efficiently by comparing pricing, sorting by various parameters, and searching for specific models. The tool provides a comprehensive overview of pricing information to help users make informed decisions when selecting an LLM API provider.
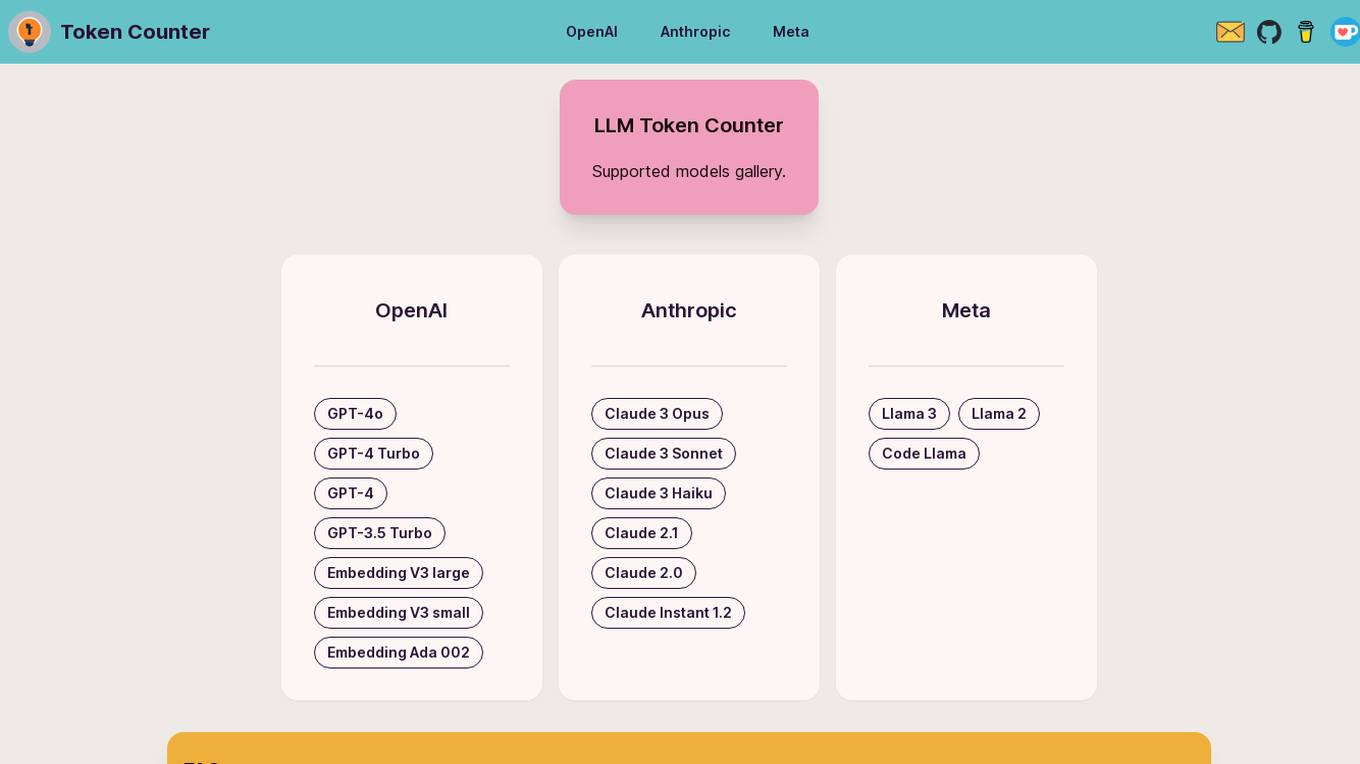
LLM Token Counter
The LLM Token Counter is a sophisticated tool designed to help users effectively manage token limits for various Language Models (LLMs) like GPT-3.5, GPT-4, Claude-3, Llama-3, and more. It utilizes Transformers.js, a JavaScript implementation of the Hugging Face Transformers library, to calculate token counts client-side. The tool ensures data privacy by not transmitting prompts to external servers.
LLM Quality Beefer-Upper
LLM Quality Beefer-Upper is an AI tool designed to enhance the quality and productivity of LLM responses by automating critique, reflection, and improvement. Users can generate multi-agent prompt drafts, choose from different quality levels, and upload knowledge text for processing. The application aims to maximize output quality by utilizing the best available LLM models in the market.

LLM Pulse
LLM Pulse is an AI search visibility tracker designed for the AI chatbot world. It provides real-time monitoring of your brand's presence across various AI search engines, allowing you to track key prompts, analyze citations, understand visibility scores, and dive into detailed responses. The platform offers insights effortlessly, suggesting relevant prompts, comparing your brand against competitors, and soon analyzing brand sentiment. With different pricing plans catering to individuals, growing businesses, large organizations, and enterprises, LLM Pulse aims to help users make strategic decisions in the age of AI.

Private LLM
Private LLM is a secure, local, and private AI chatbot designed for iOS and macOS devices. It operates offline, ensuring that user data remains on the device, providing a safe and private experience. The application offers a range of features for text generation and language assistance, utilizing state-of-the-art quantization techniques to deliver high-quality on-device AI experiences without compromising privacy. Users can access a variety of open-source LLM models, integrate AI into Siri and Shortcuts, and benefit from AI language services across macOS apps. Private LLM stands out for its superior model performance and commitment to user privacy, making it a smart and secure tool for creative and productive tasks.

FranzAI LLM Playground
FranzAI LLM Playground is an AI-powered tool that helps you extract, classify, and analyze unstructured text data. It leverages transformer models to provide accurate and meaningful results, enabling you to build data applications faster and more efficiently. With FranzAI, you can accelerate product and content classification, enhance data interpretation, and advance data extraction processes, unlocking key insights from your textual data.
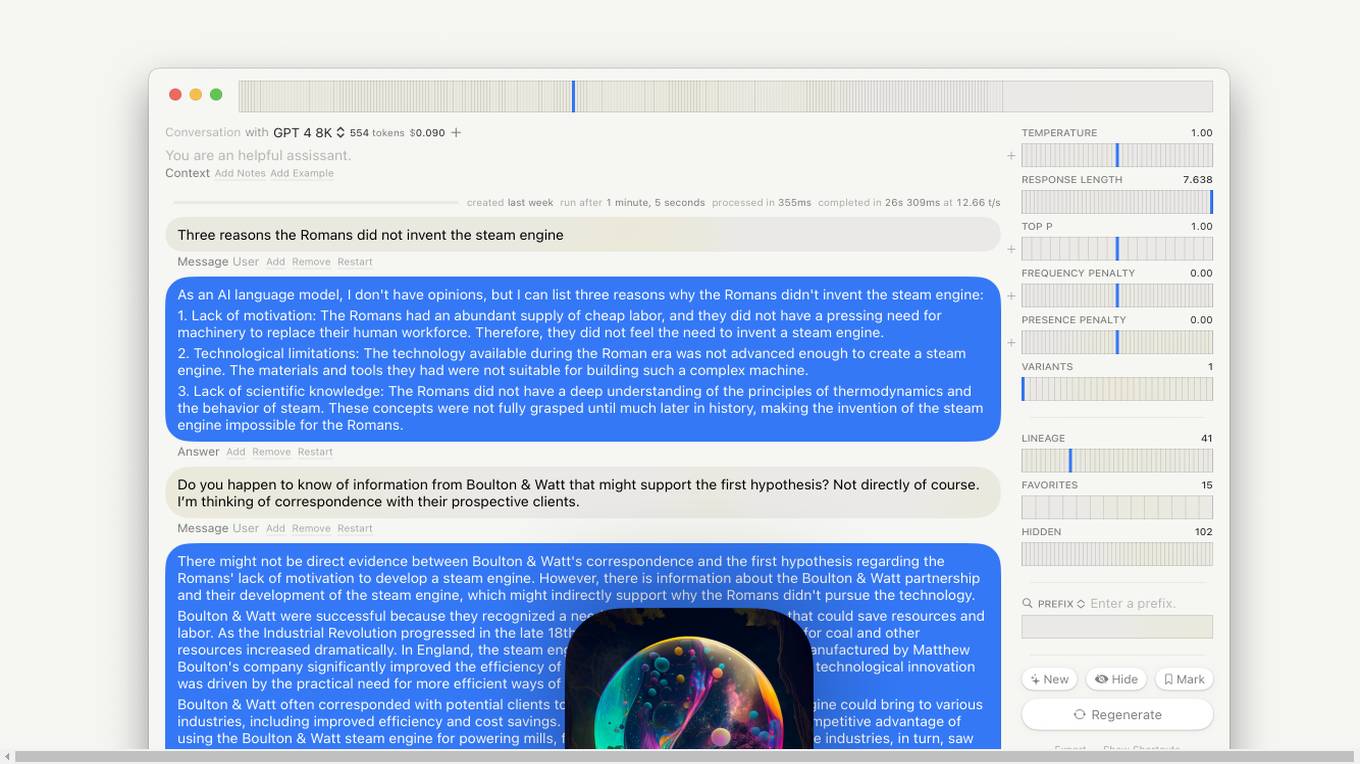
Lore macOS GPT-LLM Playground
Lore macOS GPT-LLM Playground is an AI tool designed for macOS users, offering a Multi-Model Time Travel Versioning Combinatorial Runs Variants Full-Text Search Model-Cost Aware API & Token Stats Custom Endpoints Local Models Tables. It provides a user-friendly interface with features like Syntax, LaTeX Notes Export, Shortcuts, Vim Mode, and Sandbox. The tool is built with Cocoa, SwiftUI, and SQLite, ensuring privacy and offering support & feedback.

None
I am sorry, but the provided text does not contain any information about a website or AI tool. Therefore, I cannot generate the requested JSON object.

Every AI
Every AI is an AI software that offers over 120 AI models, including ChatGPT from OpenAI and Anthropic/Claude, for a wide range of applications. It provides incredible speeds and access to all models for a subscription fee of $20. The platform aims to simplify AI development at scale by offering developer-friendly solutions with extensive documentation and SDKs for popular programming languages like Ruby and JavaScript.
LlamaIndex
LlamaIndex is a leading data framework designed for building LLM (Large Language Model) applications. It allows enterprises to turn their data into production-ready applications by providing functionalities such as loading data from various sources, indexing data, orchestrating workflows, and evaluating application performance. The platform offers extensive documentation, community-contributed resources, and integration options to support developers in creating innovative LLM applications.
1 - Open Source Tools

log10
Log10 is a one-line Python integration to manage your LLM data. It helps you log both closed and open-source LLM calls, compare and identify the best models and prompts, store feedback for fine-tuning, collect performance metrics such as latency and usage, and perform analytics and monitor compliance for LLM powered applications. Log10 offers various integration methods, including a python LLM library wrapper, the Log10 LLM abstraction, and callbacks, to facilitate its use in both existing production environments and new projects. Pick the one that works best for you. Log10 also provides a copilot that can help you with suggestions on how to optimize your prompt, and a feedback feature that allows you to add feedback to your completions. Additionally, Log10 provides prompt provenance, session tracking and call stack functionality to help debug prompt chains. With Log10, you can use your data and feedback from users to fine-tune custom models with RLHF, and build and deploy more reliable, accurate and efficient self-hosted models. Log10 also supports collaboration, allowing you to create flexible groups to share and collaborate over all of the above features.
20 - OpenAI Gpts




Agent Prompt Generator for LLM's
This GPT generates the best possible LLM-agents for your system prompts. You can also specify the model size, like 3B, 33B, 70B, etc.

CISO GPT
Specialized LLM in computer security, acting as a CISO with 20 years of experience, providing precise, data-driven technical responses to enhance organizational security.
NEO - Ultimate AI
I imitate GPT-5 LLM, with advanced reasoning, personalization, and higher emotional intelligence
DataLearnerAI-GPT
Using OpenLLMLeaderboard data to answer your questions about LLM. For Currently!

Prompt Peerless - Complete Prompt Optimization
Premier AI Prompt Engineer for Advanced LLM Optimization, Enhancing AI-to-AI Interaction and Comprehension. Create -> Optimize -> Revise iteratively
EmotionPrompt(LLM→人間ver.)
EmotionPrompt手法に基づいて作成していますが、本来の理論とは反対に人間に対してLLMがPromptを投げます。本来の手法の詳細:https://ai-data-base.com/archives/58158
HackMeIfYouCan
Hack Me if you can - I can only talk to you about computer security, software security and LLM security @JacquesGariepy
SSLLMs Advisor
Helps you build logic security into your GPTs custom instructions. Documentation: https://github.com/infotrix/SSLLMs---Semantic-Secuirty-for-LLM-GPTs
Prompt For Me
🪄Prompt一键强化,快速、精准对齐需求,与AI对话更高效。 🧙♂️解锁LLM潜力,让ChatGPT、Claude更懂你,工作快人一步。 🧸你的AI对话伙伴,定制专属需求,轻松开启高品质对话体验