
harbor
Effortlessly run LLM backends, APIs, frontends, and services with one command.
Stars: 2067
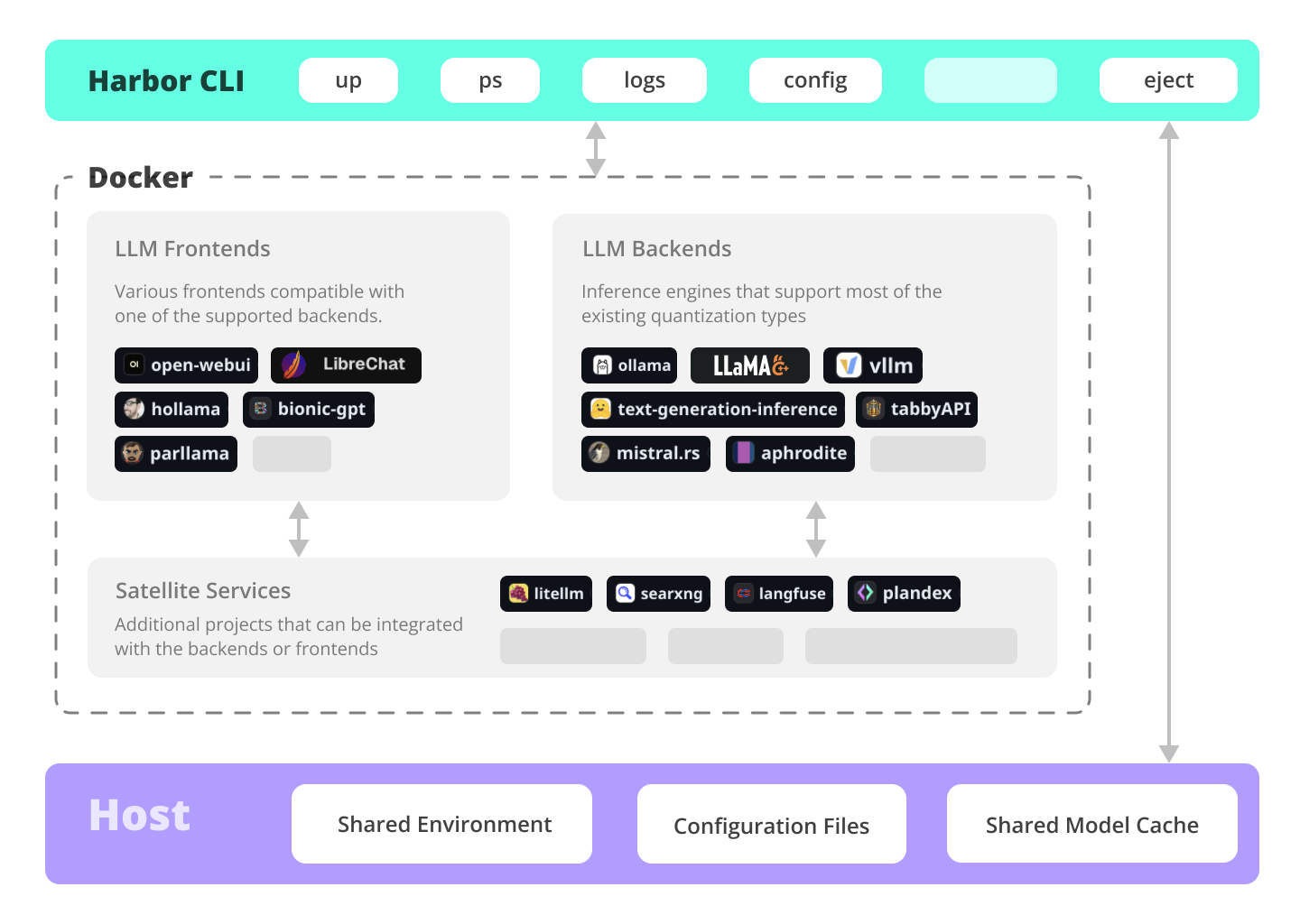
Harbor is a containerized LLM toolkit that simplifies the initial configuration of various LLM-related projects by providing a CLI and pre-configured Docker Compose setup. It serves as a base for managing local LLM stack, offering convenience utilities for tasks like model management, configuration, and service debugging. Users can access service CLIs via Docker without installation, benefit from pre-configured services that work together, share and reuse host cache, and co-locate service configs. Additionally, users can eject from Harbor to run services without it.
README:







Setup your local LLM stack effortlessly.
# Starts fully configured Open WebUI and Ollama
harbor up
# Now, Open WebUI can do Web RAG and TTS/STT
harbor up searxng speachesHarbor is a containerized LLM toolkit that allows you to run LLM backends, frontends and related useful services. It consists of a CLI and a companion App.

-
Installing Harbor
Guides to install Harbor CLI and App -
Harbor User Guide
High-level overview of working with Harbor -
Harbor App
Overview and manual for the Harbor companion application -
Harbor Services
Catalog of services available in Harbor -
Harbor CLI Reference
Read more about Harbor CLI commands and options. Read about supported services and the ways to configure them. -
Join our Discord
Get help, share your experience, and contribute to the project.
Run LLMs and related services locally, with no or minimal configuration, typically in a single command or click.
# All backends are pre-connected to Open WebUI
harbor up ollama
harbor up llamacpp
harbor up vllm
# Set and remember args for llama.cpp
harbor llamacpp args -ngl 32Harbor supports most of the major inference engines as well as a few of the lesser-known ones.
# We sincerely hope you'll never try to run all of them at once
harbor up vllm llamacpp tgi litellm tabbyapi aphrodite sglang ktransformers mistralrs airllmEnjoy the benefits of MCP ecosystem, extend it to your use-cases.
# Manage MCPs with a convenient Web UI
harbor up metamcp
# Connect MCPs to Open WebUI
harbor up metamcp mcpoHarbor includes ComfyUI + Flux + Open WebUI integration.
# Use FLUX in Open WebUI in one command
harbor up comfyuiHarbor includes SearXNG that is pre-connected to a lot of services out of the box: Perplexica, ChatUI, Morphic, Local Deep Research and more.
# SearXNG is pre-connected to Open WebUI
harbor up searxng
# And to many other services
harbor up searxng chatui
harbor up searxng morphic
harbor up searxng perplexica
harbor up searxng ldrHarbor includes multiple services for build LLM-based data and chat workflows: Dify, LitLytics, n8n, Open WebUI Pipelines, FloWise, LangFlow
# Use Dify in Open WebUI
harbor up difySetup voice chats with your LLM in a single command. Open WebUI + Speaches
# Speaches includes OpenAI-compatible SST and TTS
# and connected to Open WebUI out of the box
harbor up speachesYou can access Harbor services from your phone with a QR code. Easily get links for local, LAN or Docker access.
# Print a QR code to open the service on your phone
harbor qr
# Print a link to open the service on your phone
harbor url webuiHarbor includes a built-in tunneling service to expose your Harbor to the internet.
[!WARN] Be careful exposing your computer to the Internet, it's not safe.
# Expose default UI to the internet
harbor tunnel
# Expose a specific service to the internet
# ⚠️ Ensure to configure authentication for the service
harbor tunnel vllm
# Harbor comes with traefik built-in and pre-configured
# for all included services
harbor up traefikHarbor Boost allows you to easily script workflows and interactions with downstream LLMs.
# Use Harbor Boost to script LLM workflows
harbor up boostSave and manage configuration profiles for different scenarios. For example - save llama.cpp args for different models and contexts and switch between them easily.
# Save and use config profiles
harbor profile save llama4
harbor profile use defaultHarbor keeps a local-only history of recent commands. Look up and re-run easily, standalone from the system shell history.
# Lookup recently used harbor commands
harbor historyReady to move to your own setup? Harbor will give you a docker-compose file replicating your setup.
# Eject from Harbor into a standalone Docker Compose setup
# Will export related services and variables into a standalone file.
harbor eject searxng llamacpp > docker-compose.harbor.ymlOpen WebUI ⦁︎ ComfyUI ⦁︎ LibreChat ⦁︎ HuggingFace ChatUI ⦁︎ Lobe Chat ⦁︎ Hollama ⦁︎ parllama ⦁︎ BionicGPT ⦁︎ AnythingLLM ⦁︎ Chat Nio ⦁︎ mikupad ⦁︎ oterm
Ollama ⦁︎ llama.cpp ⦁︎ vLLM ⦁︎ TabbyAPI ⦁︎ Aphrodite Engine ⦁︎ mistral.rs ⦁︎ openedai-speech ⦁︎ Speaches ⦁︎ Parler ⦁︎ text-generation-inference ⦁︎ LMDeploy ⦁︎ AirLLM ⦁︎ SGLang ⦁︎ KTransformers ⦁︎ Nexa SDK ⦁︎ KoboldCpp
Harbor Bench ⦁︎ Harbor Boost ⦁︎ SearXNG ⦁︎ Perplexica ⦁︎ Dify ⦁︎ Plandex ⦁︎ LiteLLM ⦁︎ LangFuse ⦁︎ Open Interpreter ⦁ ︎cloudflared ⦁︎ cmdh ⦁︎ fabric ⦁︎ txtai RAG ⦁︎ TextGrad ⦁︎ Aider ⦁︎ aichat ⦁︎ omnichain ⦁︎ lm-evaluation-harness ⦁︎ JupyterLab ⦁︎ ol1 ⦁︎ OpenHands ⦁︎ LitLytics ⦁︎ Repopack ⦁︎ n8n ⦁︎ Bolt.new ⦁︎ Open WebUI Pipelines ⦁︎ Qdrant ⦁︎ K6 ⦁︎ Promptfoo ⦁︎ Webtop ⦁︎ OmniParser ⦁︎ Flowise ⦁︎ Langflow ⦁︎ OptiLLM ⦁︎ Morphic ⦁︎ SQL Chat ⦁︎ gptme ⦁︎ traefik ⦁︎ Latent Scope ⦁︎ RAGLite ⦁︎ llama-swap ⦁︎ LibreTranslate ⦁︎ MetaMCP ⦁︎ mcpo ⦁︎ SuperGateway ⦁︎ Local Deep Research ⦁︎ LocalAI ⦁︎ AgentZero
See services documentation for a brief overview of each.
# Run Harbor with default services:
# Open WebUI and Ollama
harbor up
# Run Harbor with additional services
# Running SearXNG automatically enables Web RAG in Open WebUI
harbor up searxng
# Speaches includes OpenAI-compatible SST and TTS
# and connected to Open WebUI out of the box
harbor up speaches
# Run additional/alternative LLM Inference backends
# Open Webui is automatically connected to them.
harbor up llamacpp tgi litellm vllm tabbyapi aphrodite sglang ktransformers
# Run different Frontends
harbor up librechat chatui bionicgpt hollama
# Get a free quality boost with
# built-in optimizing proxy
harbor up boost
# Use FLUX in Open WebUI in one command
harbor up comfyui
# Use custom models for supported backends
harbor llamacpp model https://huggingface.co/user/repo/model.gguf
# Access service CLIs without installing them
# Caches are shared between services where possible
harbor hf scan-cache
harbor hf download google/gemma-2-2b-it
harbor ollama list
# Shortcut to HF Hub to find the models
harbor hf find gguf gemma-2
# Use HFDownloader and official HF CLI to download models
harbor hf dl -m google/gemma-2-2b-it -c 10 -s ./hf
harbor hf download google/gemma-2-2b-it
# Where possible, cache is shared between the services
harbor tgi model google/gemma-2-2b-it
harbor vllm model google/gemma-2-2b-it
harbor aphrodite model google/gemma-2-2b-it
harbor tabbyapi model google/gemma-2-2b-it-exl2
harbor mistralrs model google/gemma-2-2b-it
harbor opint model google/gemma-2-2b-it
harbor sglang model google/gemma-2-2b-it
# Convenience tools for docker setup
harbor logs llamacpp
harbor exec llamacpp ./scripts/llama-bench --help
harbor shell vllm
# Tell your shell exactly what you think about it
harbor opint
harbor aider
harbor aichat
harbor cmdh
# Use fabric to LLM-ify your linux pipes
cat ./file.md | harbor fabric --pattern extract_extraordinary_claims | grep "LK99"
# Open services from the CLI
harbor open webui
harbor open llamacpp
# Print yourself a QR to quickly open the
# service on your phone
harbor qr
# Feeling adventurous? Expose your Harbor
# to the internet
harbor tunnel
# Config management
harbor config list
harbor config set webui.host.port 8080
# Create and manage config profiles
harbor profile save l370b
harbor profile use default
# Lookup recently used harbor commands
harbor history
# Eject from Harbor into a standalone Docker Compose setup
# Will export related services and variables into a standalone file.
harbor eject searxng llamacpp > docker-compose.harbor.yml
# Run a built-in LLM benchmark with
# your own tasks
harbor bench run
# Gimmick/Fun Area
# Argument scrambling, below commands are all the same as above
# Harbor doesn't care if it's "vllm model" or "model vllm", it'll
# figure it out.
harbor model vllm
harbor vllm model
harbor config get webui.name
harbor get config webui_name
harbor tabbyapi shell
harbor shell tabbyapi
# 50% gimmick, 50% useful
# Ask harbor about itself
harbor how to ping ollama container from the webui?https://github.com/user-attachments/assets/a5cd2ef1-3208-400a-8866-7abd85808503
In the demo, Harbor App is used to launch a default stack with Ollama and Open WebUI services. Later, SearXNG is also started, and WebUI can connect to it for the Web RAG right out of the box. After that, Harbor Boost is also started and connected to the WebUI automatically to induce more creative outputs. As a final step, Harbor config is adjusted in the App for the klmbr module in the Harbor Boost, which makes the output unparsable for the LLM (yet still undetstandable for humans).
- If you're comfortable with Docker and Linux administration - you likely don't need Harbor to manage your local LLM environment. However, while growing it - you're also likely to eventually arrive to a similar solution. I know this for a fact, since that's exactly how Harbor came to be.
- Harbor is not designed as a deployment solution, but rather as a helper for the local LLM development environment. It's a good starting point for experimenting with LLMs and related services.
- Workflow/setup centralisation - you can be sure where to find a specific config or service, logs, data and configuration files.
- Convenience factor - single CLI with a lot of services and features, accessible from anywhere on your host.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for harbor
Similar Open Source Tools
harbor
Harbor is a containerized LLM toolkit that simplifies the initial configuration of various LLM-related projects by providing a CLI and pre-configured Docker Compose setup. It serves as a base for managing local LLM stack, offering convenience utilities for tasks like model management, configuration, and service debugging. Users can access service CLIs via Docker without installation, benefit from pre-configured services that work together, share and reuse host cache, and co-locate service configs. Additionally, users can eject from Harbor to run services without it.
batteries-included
Batteries Included is an all-in-one platform for building and running modern applications, simplifying cloud infrastructure complexity. It offers production-ready capabilities through an intuitive interface, focusing on automation, security, and enterprise-grade features. The platform includes databases like PostgreSQL and Redis, AI/ML capabilities with Jupyter notebooks, web services deployment, security features like SSL/TLS management, and monitoring tools like Grafana dashboards. Batteries Included is designed to streamline infrastructure setup and management, allowing users to concentrate on application development without dealing with complex configurations.
FreedomGPT
Freedom GPT is a desktop application that allows users to run alpaca models on their local machine. It is built using Electron and React. The application is open source and available on GitHub. Users can contribute to the project by following the instructions in the repository. The application can be run using the following command: yarn start. The application can also be dockerized using the following command: docker run -d -p 8889:8889 freedomgpt/freedomgpt. The application utilizes several open-source packages and libraries, including llama.cpp, LLAMA, and Chatbot UI. The developers of these packages and their contributors deserve gratitude for making their work available to the public under open source licenses.

trieve
Trieve is an advanced relevance API for hybrid search, recommendations, and RAG. It offers a range of features including self-hosting, semantic dense vector search, typo tolerant full-text/neural search, sub-sentence highlighting, recommendations, convenient RAG API routes, the ability to bring your own models, hybrid search with cross-encoder re-ranking, recency biasing, tunable popularity-based ranking, filtering, duplicate detection, and grouping. Trieve is designed to be flexible and customizable, allowing users to tailor it to their specific needs. It is also easy to use, with a simple API and well-documented features.
shinkai-node
Shinkai Node is a tool that enables users to create AI agents without coding. Users can define tasks, schedule actions, and let Shinkai generate custom code. The tool also provides native crypto support. It has a companion repo called Shinkai Apps for the frontend. The tool offers easy local compilation and OpenAPI support for generating schemas and Swagger UI. Users can run tests and dockerized tests for the tool. It also provides guidance on releasing a new version.
SecureAI-Tools
SecureAI Tools is a private and secure AI tool that allows users to chat with AI models, chat with documents (PDFs), and run AI models locally. It comes with built-in authentication and user management, making it suitable for family members or coworkers. The tool is self-hosting optimized and provides necessary scripts and docker-compose files for easy setup in under 5 minutes. Users can customize the tool by editing the .env file and enabling GPU support for faster inference. SecureAI Tools also supports remote OpenAI-compatible APIs, with lower hardware requirements for using remote APIs only. The tool's features wishlist includes chat sharing, mobile-friendly UI, and support for more file types and markdown rendering.
ollama4j-web-ui
Ollama4j Web UI is a Java-based web interface built using Spring Boot and Vaadin framework for Ollama users with Java and Spring background. It allows users to interact with various models running on Ollama servers, providing a fully functional web UI experience. The project offers multiple ways to run the application, including via Docker, Docker Compose, or as a standalone JAR. Users can configure the environment variables and access the web UI through a browser. The project also includes features for error handling on the UI and settings pane for customizing default parameters.
air-light
Air-light is a minimalist WordPress starter theme designed to be an ultra minimal starting point for a WordPress project. It is built to be very straightforward, backwards compatible, front-end developer friendly and modular by its structure. Air-light is free of weird "app-like" folder structures or odd syntaxes that nobody else uses. It loves WordPress as it was and as it is.

datalore-localgen-cli
Datalore is a terminal tool for generating structured datasets from local files like PDFs, Word docs, images, and text. It extracts content, uses semantic search to understand context, applies instructions through a generated schema, and outputs clean, structured data. Perfect for converting raw or unstructured local documents into ready-to-use datasets for training, analysis, or experimentation, all without manual formatting.
llamafile-docker
This repository, llamafile-docker, automates the process of checking for new releases of Mozilla-Ocho/llamafile, building a Docker image with the latest version, and pushing it to Docker Hub. Users can download a pre-trained model in gguf format and use the Docker image to interact with the model via a server or CLI version. Contributions are welcome under the Apache 2.0 license.
nosia
Nosia is a platform that allows users to run an AI model on their own data. It is designed to be easy to install and use. Users can follow the provided guides for quickstart, API usage, upgrading, starting, stopping, and troubleshooting. The platform supports custom installations with options for remote Ollama instances, custom completion models, and custom embeddings models. Advanced installation instructions are also available for macOS with a Debian or Ubuntu VM setup. Users can access the platform at 'https://nosia.localhost' and troubleshoot any issues by checking logs and job statuses.

AppFlowy-Cloud
AppFlowy Cloud is a secure user authentication, file storage, and real-time WebSocket communication tool written in Rust. It is part of the AppFlowy ecosystem, providing an efficient and collaborative user experience. The tool offers deployment guides, development setup with Rust and Docker, debugging tips for components like PostgreSQL, Redis, Minio, and Portainer, and guidelines for contributing to the project.
open-cuak
Open CUAK (Computer Use Agent) is a platform for managing automation agents at scale, designed to run and manage thousands of automation agents with reliability. It allows for abundant productivity by ensuring scalability and profitability. The project aims to usher in a new era of work with equally distributed productivity, making it open-sourced for real businesses and real people. The core features include running operator-like automation workflows locally, vision-based automation, turning any browser into an operator-companion, utilizing a dedicated remote browser, and more.
skynet
Skynet is an API server for AI services that wraps several apps and models. It consists of specialized modules that can be enabled or disabled as needed. Users can utilize Skynet for tasks such as summaries and action items with vllm or Ollama, live transcriptions with Faster Whisper via websockets, and RAG Assistant. The tool requires Poetry and Redis for operation. Skynet provides a quickstart guide for both Summaries/Assistant and Live Transcriptions, along with instructions for testing docker changes and running demos. Detailed documentation on configuration, running, building, and monitoring Skynet is available in the docs. Developers can contribute to Skynet by installing the pre-commit hook for linting. Skynet is distributed under the Apache 2.0 License.
gpt-engineer
GPT-Engineer is a tool that allows you to specify a software in natural language, sit back and watch as an AI writes and executes the code, and ask the AI to implement improvements.
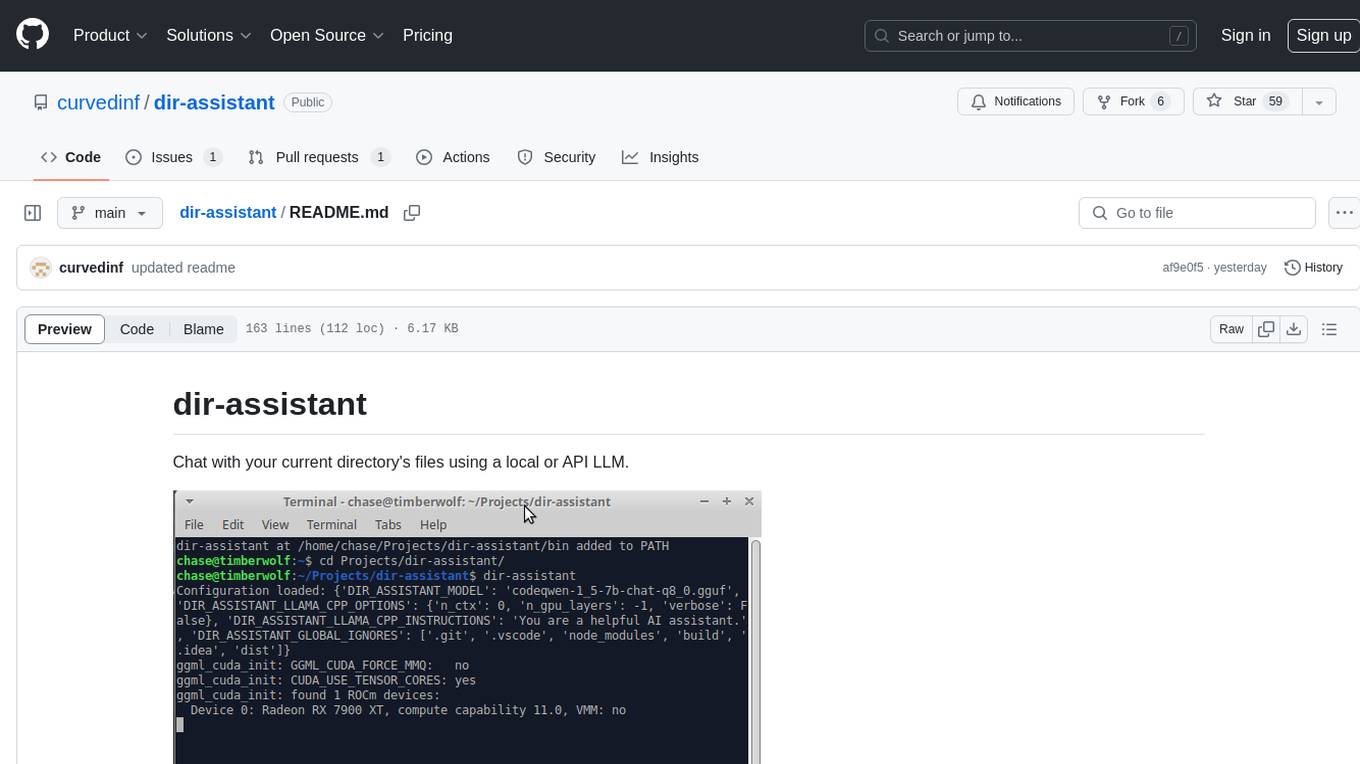
dir-assistant
Dir-assistant is a tool that allows users to interact with their current directory's files using local or API Language Models (LLMs). It supports various platforms and provides API support for major LLM APIs. Users can configure and customize their local LLMs and API LLMs using the tool. Dir-assistant also supports model downloads and configurations for efficient usage. It is designed to enhance file interaction and retrieval using advanced language models.
For similar tasks
harbor
Harbor is a containerized LLM toolkit that simplifies the initial configuration of various LLM-related projects by providing a CLI and pre-configured Docker Compose setup. It serves as a base for managing local LLM stack, offering convenience utilities for tasks like model management, configuration, and service debugging. Users can access service CLIs via Docker without installation, benefit from pre-configured services that work together, share and reuse host cache, and co-locate service configs. Additionally, users can eject from Harbor to run services without it.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.