AI tools for video
Related Jobs:
Related Tools:
Videograph
Videograph is an AI-powered video streaming platform that offers a range of video APIs for live and on-demand video streaming. It provides advanced video analytics, content distribution analytics, and features like portrait mode conversion, digital asset management, live streaming with low latency, content monetization, and dynamic ad insertion. With seamless organization through Digital Asset Management, Videograph enables users to elevate their content strategy with precision analytics. The platform also offers a user-friendly interface for easy video management and detailed insights on viewership metrics.
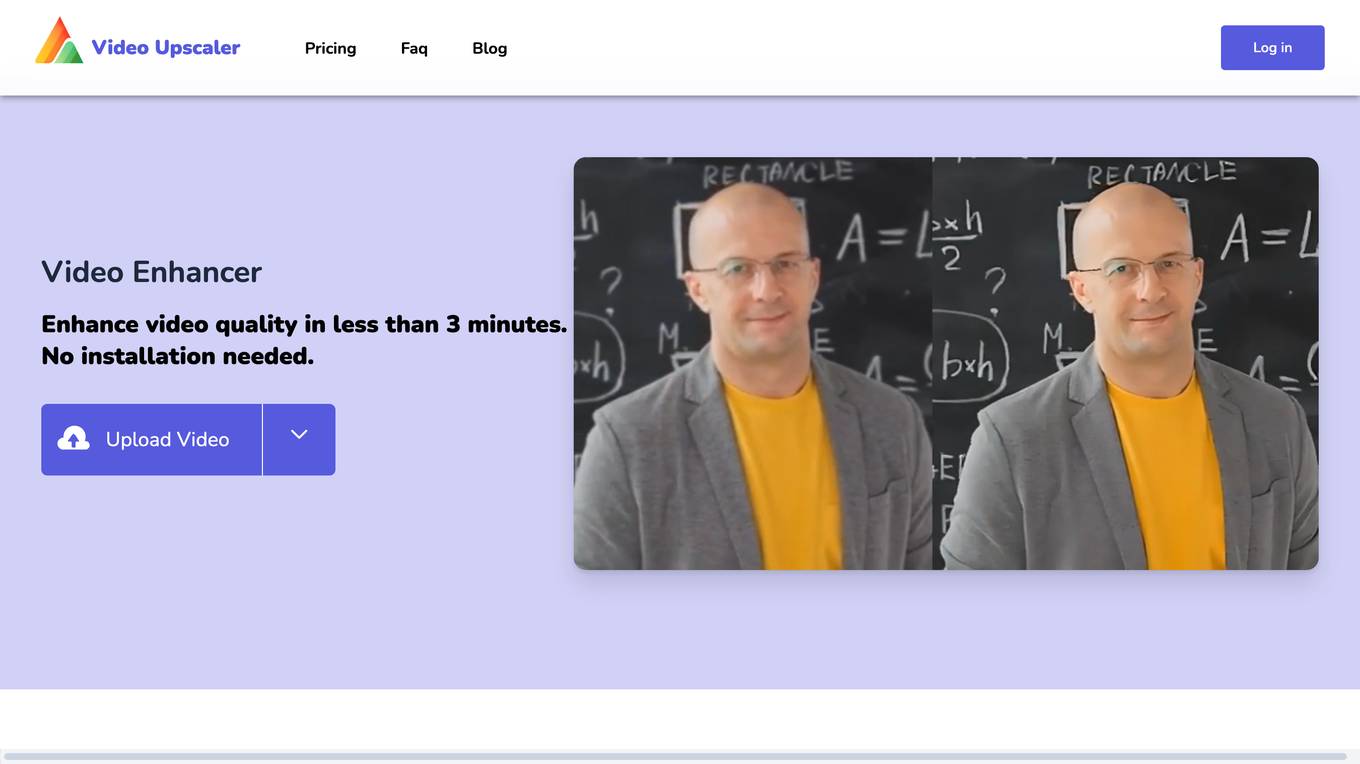
Video Upscaler
Video Upscaler is an online video enhancement platform that utilizes advanced AI algorithms to automatically enhance the quality of videos in just seconds. It offers a simple and effective solution for users to upscale their videos to 4K resolution without any loss of detail or quality. The platform is user-friendly, affordable, and constantly updating its models to provide the highest quality results across various categories.
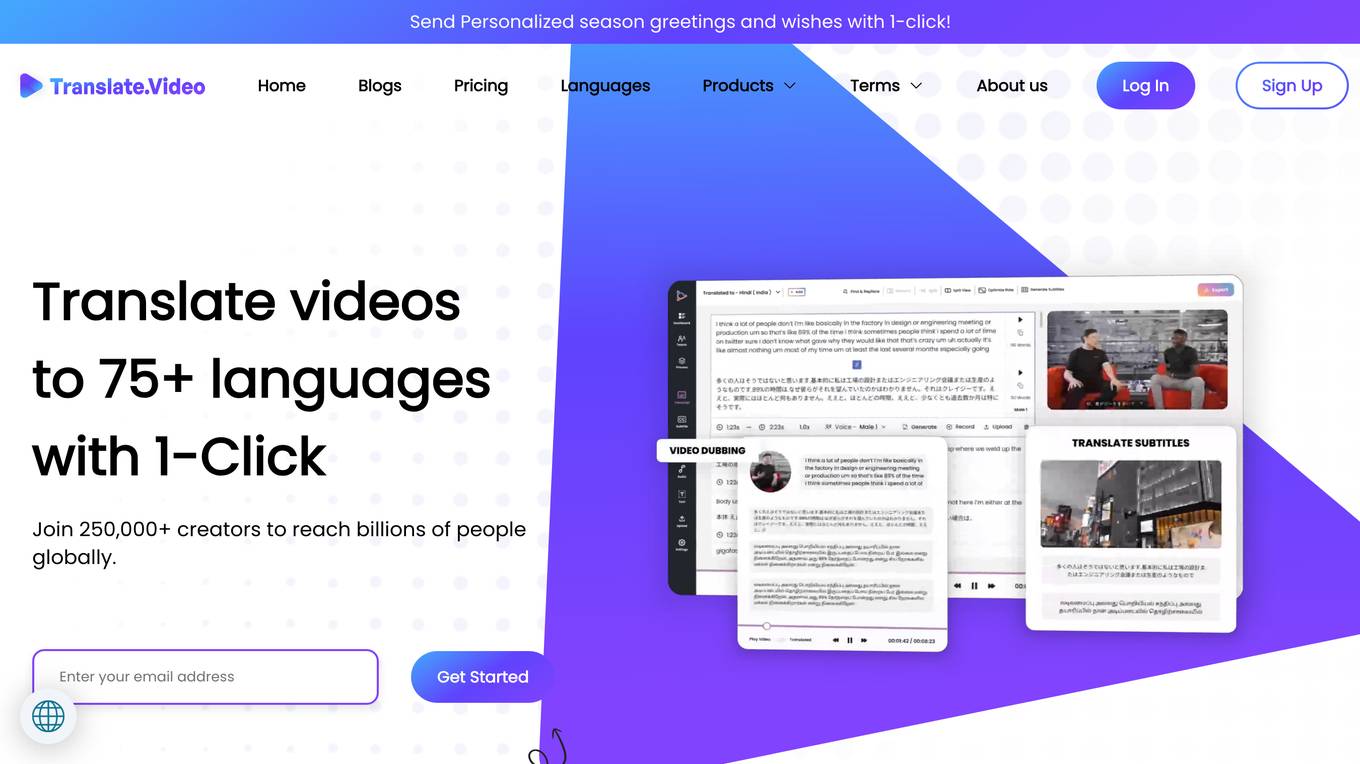
Translate.Video
Translate.Video is an AI multi-speaker video translation tool that offers speaker diarization, voice cloning, text-to-speech, and instant voice cloning features. It allows users to translate videos to over 75 languages with just one click, making content creation and translation efficient and accessible. The tool also provides plugins for popular design software like Photoshop, Illustrator, and Figma, enabling users to accelerate creative translation. Translate.Video is designed to help creators, influencers, and enterprises reach a global audience by simplifying the captioning, subtitling, and dubbing process.
VideoAsk by Typeform
VideoAsk by Typeform is an interactive video platform that helps streamline conversations and build business relationships at scale. It offers features such as asynchronous interviews, easy scheduling, tagging, gathering contact info, capturing leads, research and feedback, training, customer support, and more. Users can create interactive video forms, conduct async interviews, and engage with their audience through AI-powered video chatbots. The platform is user-friendly, code-free, and integrates with over 1,500 applications through Zapier.
Video Silence Remover
Video Silence Remover is a free AI-powered video editing tool that helps users trim silent and quiet parts of their videos quickly and efficiently. The tool operates on the cloud, allowing users to go from a raw video to a first cut edit in minutes. It supports MP4 and other video files, enabling users to create AI-edited and captioned shorts and reels from full-form videos. Video Silence Remover is ideal for content creators, video editors, social media managers, course creators, and anyone looking to enhance video quality with minimal time investment.
Video Summarizer
Video Summarizer is an AI tool designed to generate educational summaries from lengthy videos in multiple languages. It simplifies the process of summarizing video content, making it easier for users to grasp key information efficiently. The tool is user-friendly and efficient, catering to individuals seeking quick and concise video summaries for educational purposes.
VideoSage
VideoSage is an AI-powered platform that allows users to ask questions and gain insights about videos. Empowered by Moonshot Kimi AI, VideoSage provides summaries, insights, timestamps, and accurate information based on video content. Users can engage in conversations with the AI while watching videos, fostering a collaborative environment. The platform aims to enhance the user experience by offering tools to customize and enhance viewing experiences.
Video Tap
Video Tap is an AI-powered tool that transforms videos into various types of content such as social media clips, blog posts, summaries, and more. It helps users repurpose their existing videos efficiently by utilizing AI technology to generate different forms of content, saving time and effort. With features like YouTube Clips Finder, Chapters Generator, Summarizer, Tags Generator, and Transcript Generator, Video Tap offers a comprehensive solution for content creators to enhance their video marketing strategies and reach a wider audience across different platforms.

VideomakerAI
VideomakerAI is an AI-powered video creation platform that allows users to create professional-quality videos in minutes. With VideomakerAI, you can easily create videos for social media, marketing, education, and more. No video editing experience is necessary - VideomakerAI's intuitive interface and powerful AI tools make it easy for anyone to create stunning videos.
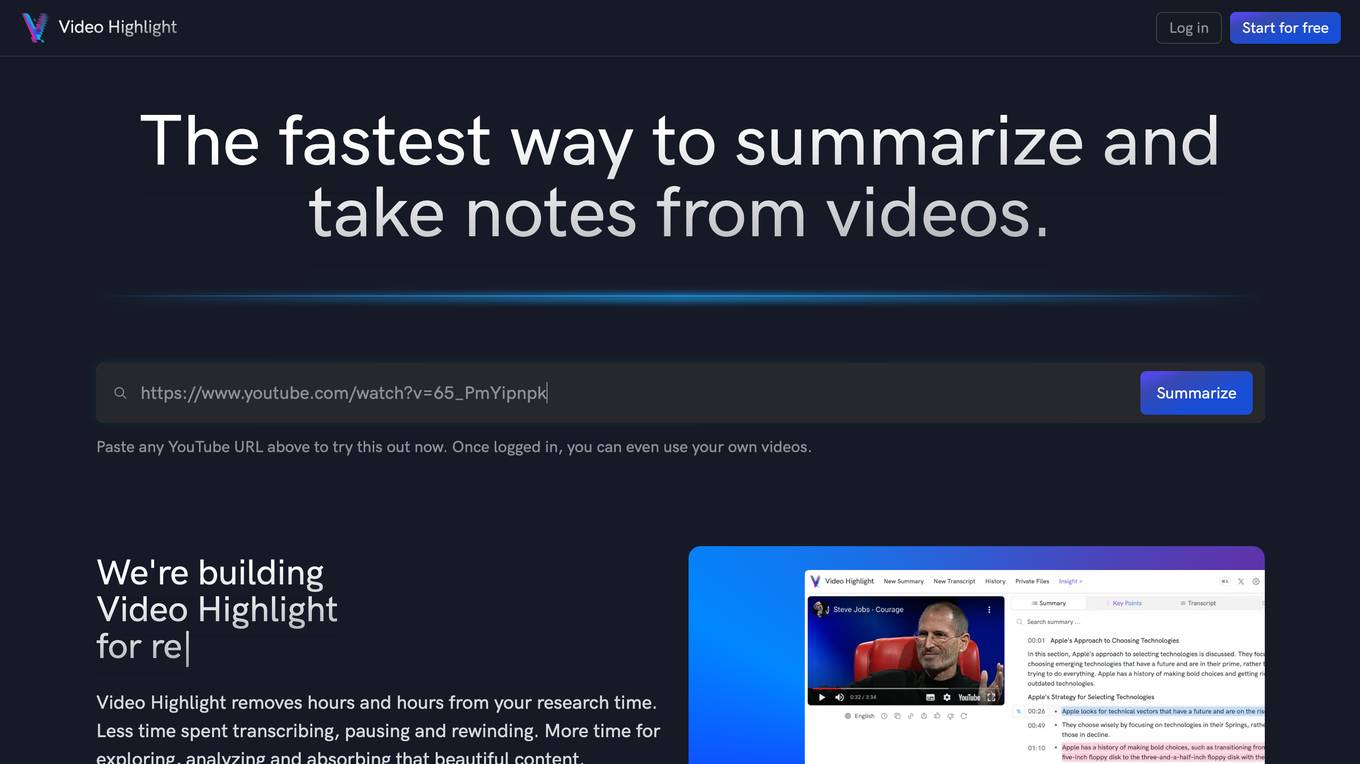
Video Highlight
Video Highlight is an AI-powered tool that helps you summarize and take notes from videos. It uses the latest AI technology to generate timestamped summaries and transcripts, highlight key moments, and engage in interactive chats. With Video Highlight, you can save hours of research time and focus on exploring, analyzing, and absorbing content.

OneTake AI
OneTake AI is an autonomous video editor that uses artificial intelligence to edit videos with a single click. It can transcribe speech, add titles and transitions, and even translate videos into multiple languages. OneTake AI is designed to help businesses and individuals create professional-quality videos quickly and easily.
Wisecut
Wisecut is an automatic video editor that uses AI and voice recognition to edit videos automatically. With Wisecut, you can easily turn your long-form talking videos into short, impactful clips with music, subtitles, and auto reframe. These short clips are perfect for platforms like YouTube Shorts, TikTok, Instagram Reels, and Social Ads.
Wave.video
Wave.video is an online video editor and hosting platform that allows users to create, edit, and host videos. It offers a wide range of features, including a live streaming studio, video recorder, stock library, and video hosting. Wave.video is easy to use and affordable, making it a great option for businesses and individuals who need to create high-quality videos.
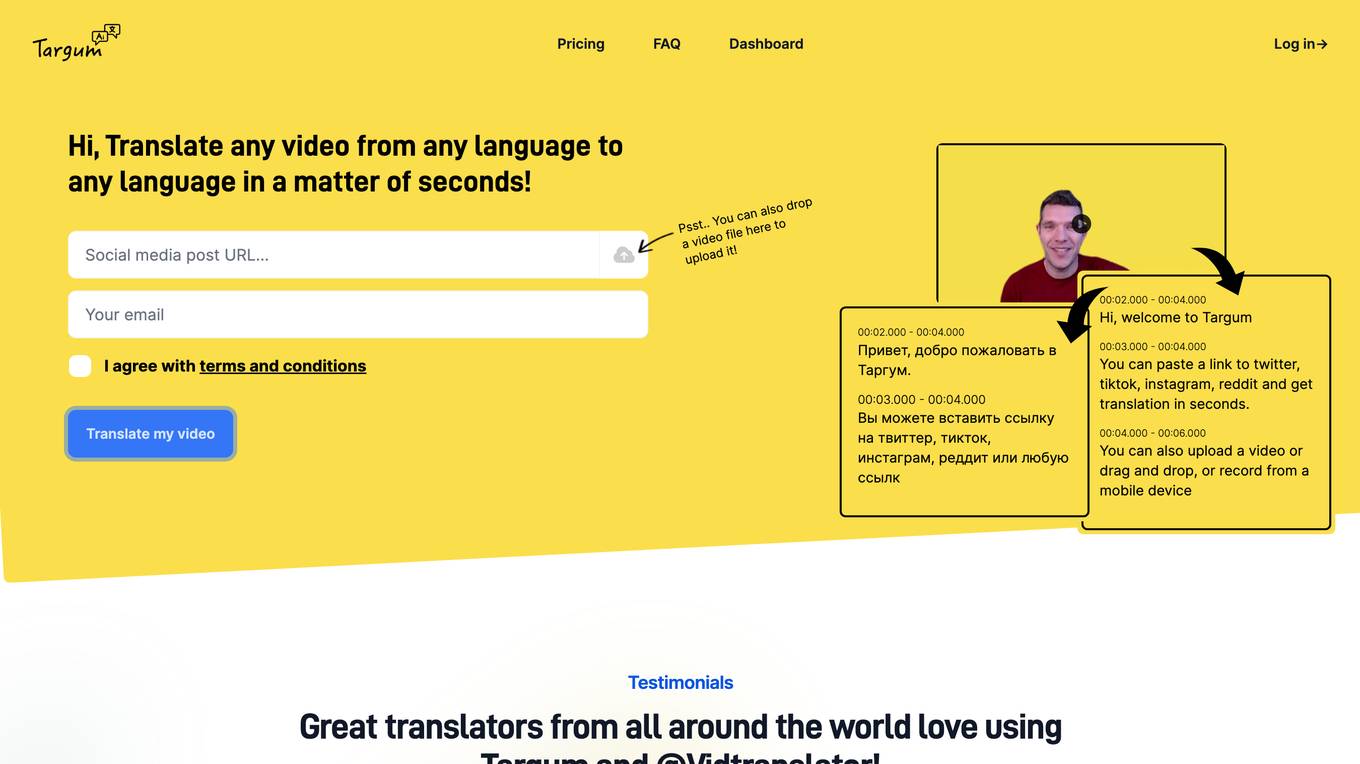
Targum
Targum is a super fast AI-based video translation service that allows users to translate any video from any language to any language in a matter of seconds. Users can paste a link to a video from Twitter, TikTok, Instagram, or Reddit, or they can upload a video file or drag and drop it onto the Targum website. Targum also allows users to record a video from a mobile device. Once a video has been uploaded, Targum will automatically translate it to the user's desired language. Targum is a valuable tool for anyone who needs to translate videos for personal or professional use.
SORA AI Video Generator
SORA AI Video Generator is a powerful online tool that allows you to create stunning videos from text. With SORA AI, you can easily convert your written content into engaging and informative videos, perfect for marketing, education, and more. SORA AI's advanced artificial intelligence technology analyzes your text and automatically generates a video that is tailored to your specific needs. You can customize your videos with a variety of features, including text-to-speech narration, background music, and images. SORA AI also offers a wide range of templates to help you get started quickly and easily.
OpenAI Sora
OpenAI Sora is a text-to-video model that can generate realistic and imaginative video scenes from text instructions. It's designed to simulate the physical world in motion, generating videos up to a minute long while maintaining visual quality and adhering to the user's prompt.

SoraHub
SoraHub is a platform that showcases videos and prompts generated by OpenAI's Sora model. Users can explore the latest Sora-generated content, subscribe to a newsletter for updates, and submit their own prompts for the model to generate. The platform also provides a list of frequently asked questions and answers about the application.
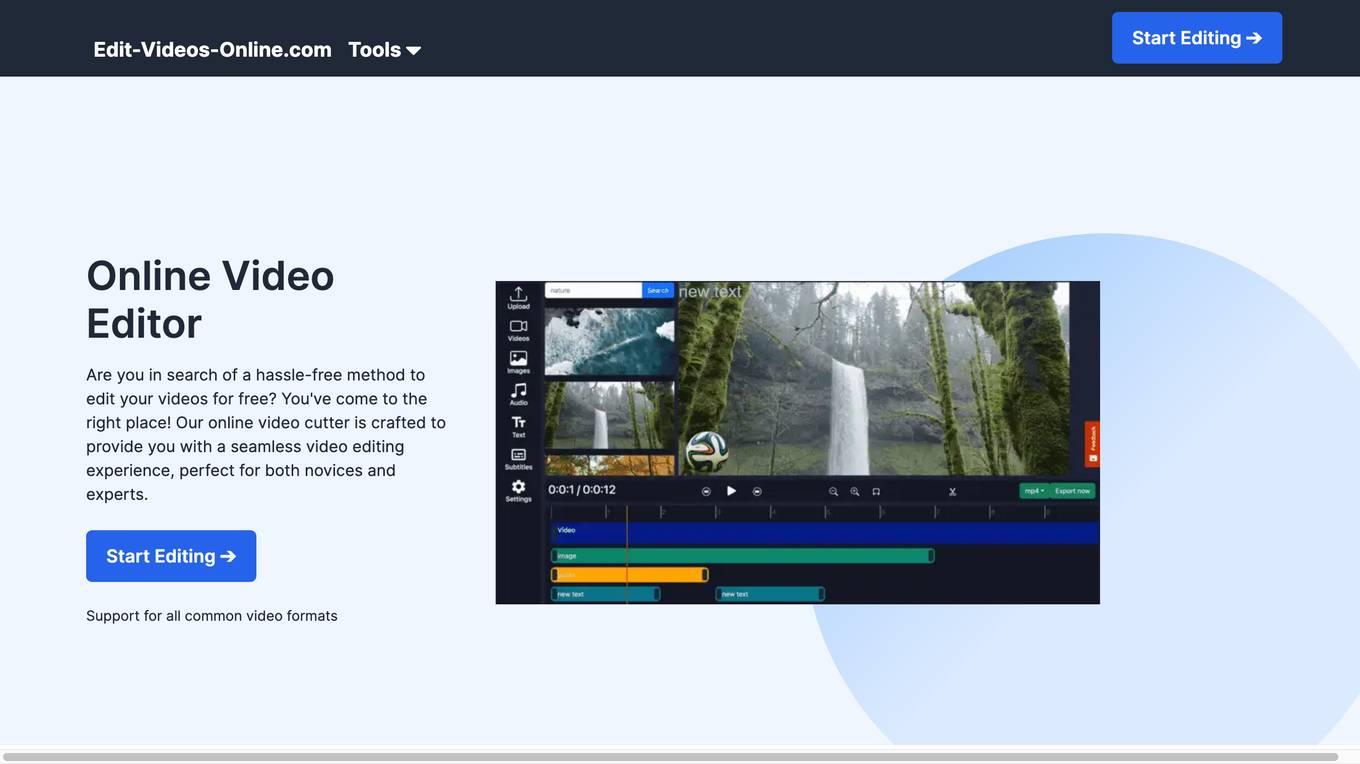
Edit-Videos-Online.com
Edit-Videos-Online.com is a free online video editor that allows users to edit and create videos without the need for registration or software installation. It supports a wide range of popular video formats and offers a variety of features such as video trimming, background removal, automatic caption generation, text and image addition, and audio editing. The editor is easy to use and provides a seamless video editing experience for both novices and experts.
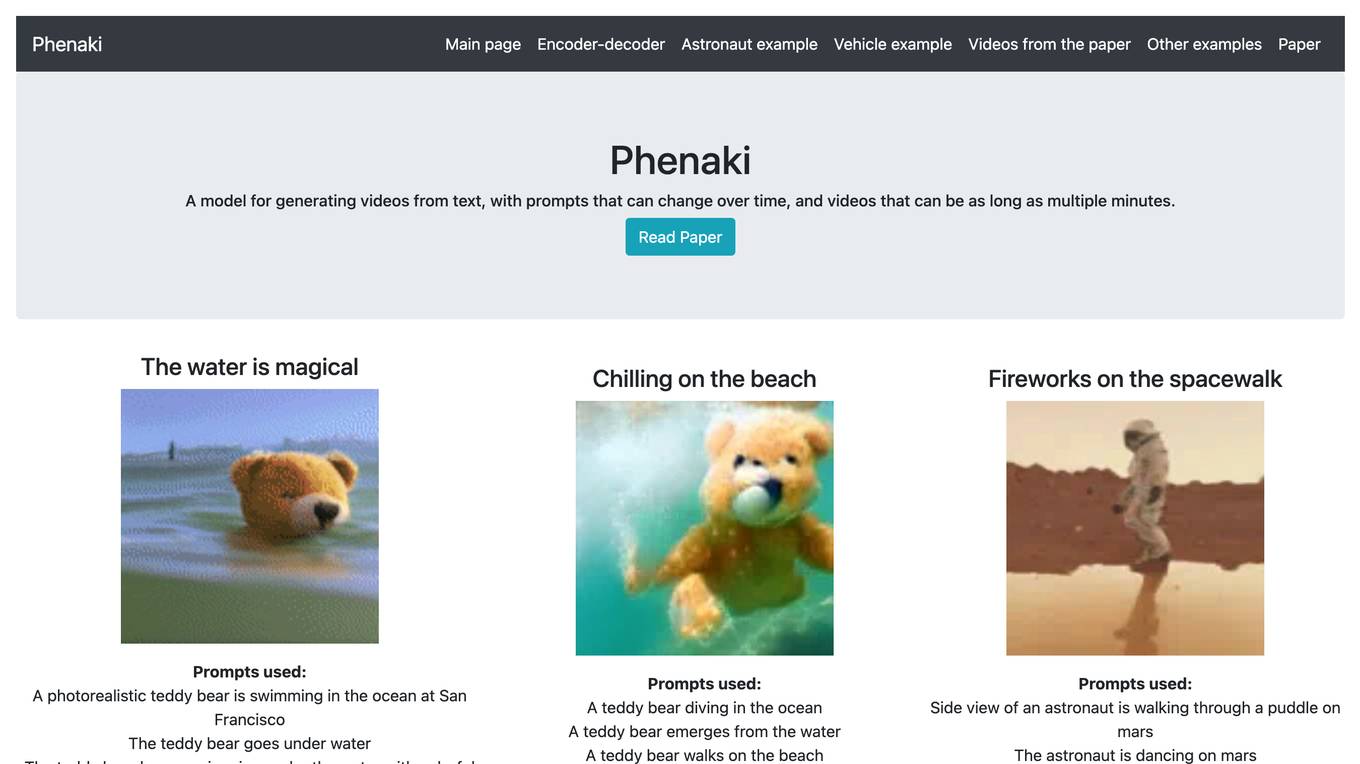
Phenaki
Phenaki is a model capable of generating realistic videos from a sequence of textual prompts. It is particularly challenging to generate videos from text due to the computational cost, limited quantities of high-quality text-video data, and variable length of videos. To address these issues, Phenaki introduces a new causal model for learning video representation, which compresses the video to a small representation of discrete tokens. This tokenizer uses causal attention in time, which allows it to work with variable-length videos. To generate video tokens from text, Phenaki uses a bidirectional masked transformer conditioned on pre-computed text tokens. The generated video tokens are subsequently de-tokenized to create the actual video. To address data issues, Phenaki demonstrates how joint training on a large corpus of image-text pairs as well as a smaller number of video-text examples can result in generalization beyond what is available in the video datasets. Compared to previous video generation methods, Phenaki can generate arbitrarily long videos conditioned on a sequence of prompts (i.e., time-variable text or a story) in an open domain. To the best of our knowledge, this is the first time a paper studies generating videos from time-variable prompts. In addition, the proposed video encoder-decoder outperforms all per-frame baselines currently used in the literature in terms of spatio-temporal quality and the number of tokens per video.
VideoDubber
VideoDubber is an AI-powered video translation and voice cloning tool that allows users to translate videos into over 150 languages with just one click. It also offers features such as voice cloning, text-to-speech, and subtitling. VideoDubber is designed to help businesses and content creators reach a global audience by making their videos accessible to viewers who speak different languages.
Video Brief Genius
Transform your brand! Provide brand and product info, and we'll craft a unique, visually stunning 30-45 second video brief. Simple, effective, impactful.

Stock Footage Metadata
Expert in video titles and keywords, with strict adherence to best practices.


VIDEO GAME versus VIDEO GAME
A fun game of VIDEO GAME versus VIDEO GAME. Get the conversation and debates going!

Universal Videos Online Player
Assists in finding online videos with a focus on free options, using a friendly, casual communication style.
JenzGPT - Creative Consulting
Kreative Videostrategien, die funktionieren. Persönlich auf deine Marke abgestimmt. Im Jens Neumann Stil.


CreceTube Experto
Asistente multilingüe para la creación de contenido de video, con apoyo y consejos creativos en múltiples idiomas.

Awesome-LLMs-for-Video-Understanding
Awesome-LLMs-for-Video-Understanding is a repository dedicated to exploring Video Understanding with Large Language Models. It provides a comprehensive survey of the field, covering models, pretraining, instruction tuning, and hybrid methods. The repository also includes information on tasks, datasets, and benchmarks related to video understanding. Contributors are encouraged to add new papers, projects, and materials to enhance the repository.
video2blog
video2blog is an open-source project aimed at converting videos into textual notes. The tool follows a process of extracting video information using yt-dlp, downloading the video, downloading subtitles if available, translating subtitles if not in Chinese, generating Chinese subtitles using whisper if no subtitles exist, converting subtitles to articles using gemini, and manually inserting images from the video into the article. The tool provides a solution for creating blog content from video resources, enhancing accessibility and content creation efficiency.
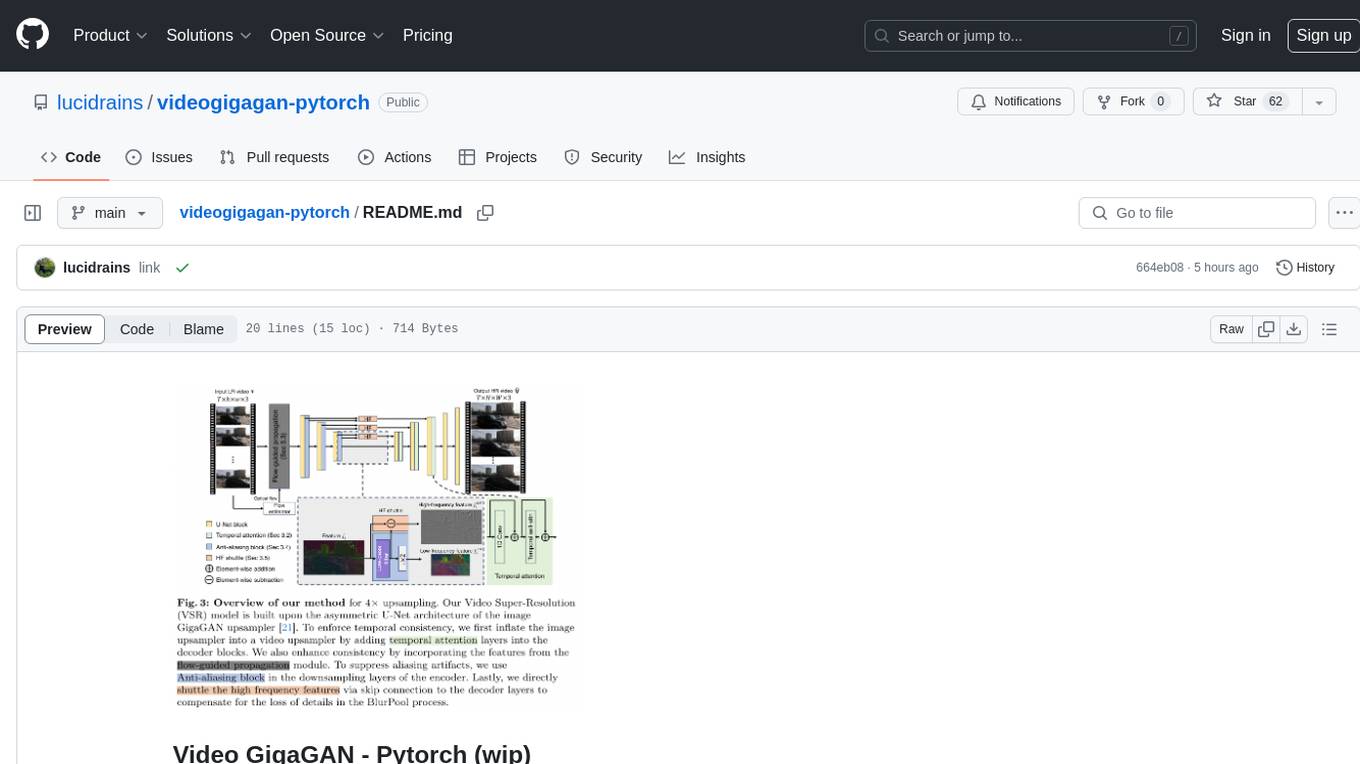
videogigagan-pytorch
Video GigaGAN - Pytorch is an implementation of Video GigaGAN, a state-of-the-art video upsampling technique developed by Adobe AI labs. The project aims to provide a Pytorch implementation for researchers and developers interested in video super-resolution. The codebase allows users to replicate the results of the original research paper and experiment with video upscaling techniques. The repository includes the necessary code and resources to train and test the GigaGAN model on video datasets. Researchers can leverage this implementation to enhance the visual quality of low-resolution videos and explore advancements in video super-resolution technology.
Video-MME
Video-MME is the first-ever comprehensive evaluation benchmark of Multi-modal Large Language Models (MLLMs) in Video Analysis. It assesses the capabilities of MLLMs in processing video data, covering a wide range of visual domains, temporal durations, and data modalities. The dataset comprises 900 videos with 256 hours and 2,700 human-annotated question-answer pairs. It distinguishes itself through features like duration variety, diversity in video types, breadth in data modalities, and quality in annotations.

videodb-python
VideoDB Python SDK allows you to interact with the VideoDB serverless database. Manage videos as intelligent data, not files. It's scalable, cost-efficient & optimized for AI applications and LLM integration. The SDK provides functionalities for uploading videos, viewing videos, streaming specific sections of videos, searching inside a video, searching inside multiple videos in a collection, adding subtitles to a video, generating thumbnails, and more. It also offers features like indexing videos by spoken words, semantic indexing, and future indexing options for scenes, faces, and specific domains like sports. The SDK aims to simplify video management and enhance AI applications with video data.
video-subtitle-remover
Video-subtitle-remover (VSR) is a software based on AI technology that removes hard subtitles from videos. It achieves the following functions: - Lossless resolution: Remove hard subtitles from videos, generate files with subtitles removed - Fill the region of removed subtitles using a powerful AI algorithm model (non-adjacent pixel filling and mosaic removal) - Support custom subtitle positions, only remove subtitles in defined positions (input position) - Support automatic removal of all text in the entire video (no input position required) - Support batch removal of watermark text from multiple images.

PromptClip
PromptClip is a tool that allows developers to create video clips using LLM prompts. Users can upload videos from various sources, prompt the video in natural language, use different LLM models, instantly watch the generated clips, finetune the clips, and add music or image overlays. The tool provides a seamless way to extract specific moments from videos based on user queries, making video editing and content creation more efficient and intuitive.
VideoLingo
VideoLingo is an all-in-one video translation and localization dubbing tool designed to generate Netflix-level high-quality subtitles. It aims to eliminate stiff machine translation, multiple lines of subtitles, and can even add high-quality dubbing, allowing knowledge from around the world to be shared across language barriers. Through an intuitive Streamlit web interface, the entire process from video link to embedded high-quality bilingual subtitles and even dubbing can be completed with just two clicks, easily creating Netflix-quality localized videos. Key features and functions include using yt-dlp to download videos from Youtube links, using WhisperX for word-level timeline subtitle recognition, using NLP and GPT for subtitle segmentation based on sentence meaning, summarizing intelligent term knowledge base with GPT for context-aware translation, three-step direct translation, reflection, and free translation to eliminate strange machine translation, checking single-line subtitle length and translation quality according to Netflix standards, using GPT-SoVITS for high-quality aligned dubbing, and integrating package for one-click startup and one-click output in streamlit.
Topaz-Video-AI
Topaz-Video-AI is a software tool designed to enhance video quality and provide various editing features. Users can utilize this tool to improve the visual appeal of their videos by applying filters, adjusting colors, and enhancing details. The software offers a user-friendly interface and a range of customization options to cater to different editing needs. Despite potential triggers from antivirus programs, Topaz-Video-AI is safe to use and has been tested by numerous users. By following the provided instructions, users can easily download, install, and run the software to enhance their video content.
VideoTuna
VideoTuna is a codebase for text-to-video applications that integrates multiple AI video generation models for text-to-video, image-to-video, and text-to-image generation. It provides comprehensive pipelines in video generation, including pre-training, continuous training, post-training, and fine-tuning. The models in VideoTuna include U-Net and DiT architectures for visual generation tasks, with upcoming releases of a new 3D video VAE and a controllable facial video generation model.

Director
Director is a framework to build video agents that can reason through complex video tasks like search, editing, compilation, generation, etc. It enables users to summarize videos, search for specific moments, create clips instantly, integrate GenAI projects and APIs, add overlays, generate thumbnails, and more. Built on VideoDB's 'video-as-data' infrastructure, Director is perfect for developers, creators, and teams looking to simplify media workflows and unlock new possibilities.
VideoCaptioner
VideoCaptioner is a video subtitle processing assistant based on a large language model (LLM), supporting speech recognition, subtitle segmentation, optimization, translation, and full-process handling. It is user-friendly and does not require high configuration, supporting both network calls and local offline (GPU-enabled) speech recognition. It utilizes a large language model for intelligent subtitle segmentation, correction, and translation, providing stunning subtitles for videos. The tool offers features such as accurate subtitle generation without GPU, intelligent segmentation and sentence splitting based on LLM, AI subtitle optimization and translation, batch video subtitle synthesis, intuitive subtitle editing interface with real-time preview and quick editing, and low model token consumption with built-in basic LLM model for easy use.
videos
The 'videos' repository contains resources related to self-media videos on platforms like Bilibili, YouTube, Xiaohongshu, and Douyin. It includes tutorials, deployment guides, and tools for various web frameworks, AI development platforms, and cloud services. The repository offers video tutorials on topics such as AI development, cloud computing, programming tools, and AI-powered applications. Users can find information on deploying AI models, utilizing AI APIs, setting up cloud servers, and enhancing video editing capabilities using AI technology.

VideoRefer
VideoRefer Suite is a tool designed to enhance the fine-grained spatial-temporal understanding capabilities of Video Large Language Models (Video LLMs). It consists of three primary components: Model (VideoRefer) for perceiving, reasoning, and retrieval for user-defined regions at any specified timestamps, Dataset (VideoRefer-700K) for high-quality object-level video instruction data, and Benchmark (VideoRefer-Bench) to evaluate object-level video understanding capabilities. The tool can understand any object within a video.
ai-video-search-engine
AI Video Search Engine (AVSE) is a video search engine powered by the latest tools in AI. It allows users to search for specific answers within millions of videos by indexing video content. The tool extracts video transcription, elements like thumbnail and description, and generates vector embeddings using AI models. Users can search for relevant results based on questions, view timestamped transcripts, and get video summaries. AVSE requires a paid Supabase & Fly.io account for hosting and can handle millions of videos with the current setup.
video-starter-kit
A powerful starting kit for building AI-powered video applications. This toolkit simplifies the complexities of working with AI video models in the browser. It offers browser-native video processing, AI model integration, advanced media capabilities, and developer utilities. The tech stack includes fal.ai for AI model infrastructure, Next.js for React framework, Remotion for video processing, IndexedDB for browser-based storage, Vercel for deployment platform, and UploadThing for file upload. The kit provides features like seamless video handling, multi-clip composition, audio track integration, voiceover support, metadata encoding, and ready-to-use UI components.
VideoTree
VideoTree is an official implementation for a query-adaptive and hierarchical framework for understanding long videos with LLMs. It dynamically extracts query-related information from input videos and builds a tree-based video representation for LLM reasoning. The tool requires Python 3.8 or above and leverages models like LaViLa and EVA-CLIP-8B for feature extraction. It also provides scripts for tasks like Adaptive Breath Expansion, Relevance-based Depth Expansion, and LLM Reasoning. The codebase is being updated to incorporate scripts/captions for NeXT-QA and IntentQA in the future.
Video-Super-Resolution-Library
Intel® Library for Video Super Resolution (Intel® Library for VSR) is a project that offers a variety of algorithms, including machine learning and deep learning implementations, to convert low-resolution videos to high resolution. It enhances the RAISR algorithm to provide better visual quality and real-time performance for upscaling on Intel® Xeon® platforms and Intel® GPUs. The project is developed in C++ and utilizes Intel® AVX-512 on Intel® Xeon® Scalable Processor family and OpenCL support on Intel® GPUs. It includes an FFmpeg plugin inside a Docker container for ease of testing and deployment.
Video-ChatGPT
Video-ChatGPT is a video conversation model that aims to generate meaningful conversations about videos by combining large language models with a pretrained visual encoder adapted for spatiotemporal video representation. It introduces high-quality video-instruction pairs, a quantitative evaluation framework for video conversation models, and a unique multimodal capability for video understanding and language generation. The tool is designed to excel in tasks related to video reasoning, creativity, spatial and temporal understanding, and action recognition.

AIO-Video-Downloader
AIO Video Downloader is an open-source Android application built on the robust yt-dlp backend with the help of youtubedl-android. It aims to be the most powerful download manager available, offering a clean and efficient interface while unlocking advanced downloading capabilities with minimal setup. With support for 1000+ sites and virtually any downloadable content across the web, AIO delivers a seamless yet powerful experience that balances speed, flexibility, and simplicity.