AI tools for inference
Related Jobs:
Related Tools:
Cerebras API
The Cerebras API is a high-speed inferencing solution for AI model inference powered by Cerebras Wafer-Scale Engines and CS-3 systems. It offers developers access to two models: Meta’s Llama 3.1 8B and 70B models, which are instruction-tuned and suitable for conversational applications. The API provides low-latency solutions and invites developers to explore new possibilities in AI development.

Wallaroo.AI
Wallaroo.AI is an AI inference platform that offers production-grade AI inference microservices optimized on OpenVINO for cloud and Edge AI application deployments on CPUs and GPUs. It provides hassle-free AI inferencing for any model, any hardware, anywhere, with ultrafast turnkey inference microservices. The platform enables users to deploy, manage, observe, and scale AI models effortlessly, reducing deployment costs and time-to-value significantly.
Cerebras
Cerebras is an AI tool that offers products and services related to AI supercomputers, cloud system processors, and applications for various industries. It provides high-performance computing solutions, including large language models, and caters to sectors such as health, energy, government, scientific computing, and financial services. Cerebras specializes in AI model services, offering state-of-the-art models and training services for tasks like multi-lingual chatbots and DNA sequence prediction. The platform also features the Cerebras Model Zoo, an open-source repository of AI models for developers and researchers.
Cerebras
Cerebras is a leading AI tool and application provider that offers cutting-edge AI supercomputers, model services, and cloud solutions for various industries. The platform specializes in high-performance computing, large language models, and AI model training, catering to sectors such as health, energy, government, and financial services. Cerebras empowers developers and researchers with access to advanced AI models, open-source resources, and innovative hardware and software development kits.
Groq
Groq is a fast AI inference tool that offers GroqCloud™ Platform and GroqRack™ Cluster for developers to build and deploy AI models with ultra-low-latency inference. It provides instant intelligence for openly-available models like Llama 3.1 and is known for its speed and compatibility with other AI providers. Groq powers leading openly-available AI models and has gained recognition in the AI chip industry. The tool has received significant funding and valuation, positioning itself as a strong challenger to established players like Nvidia.
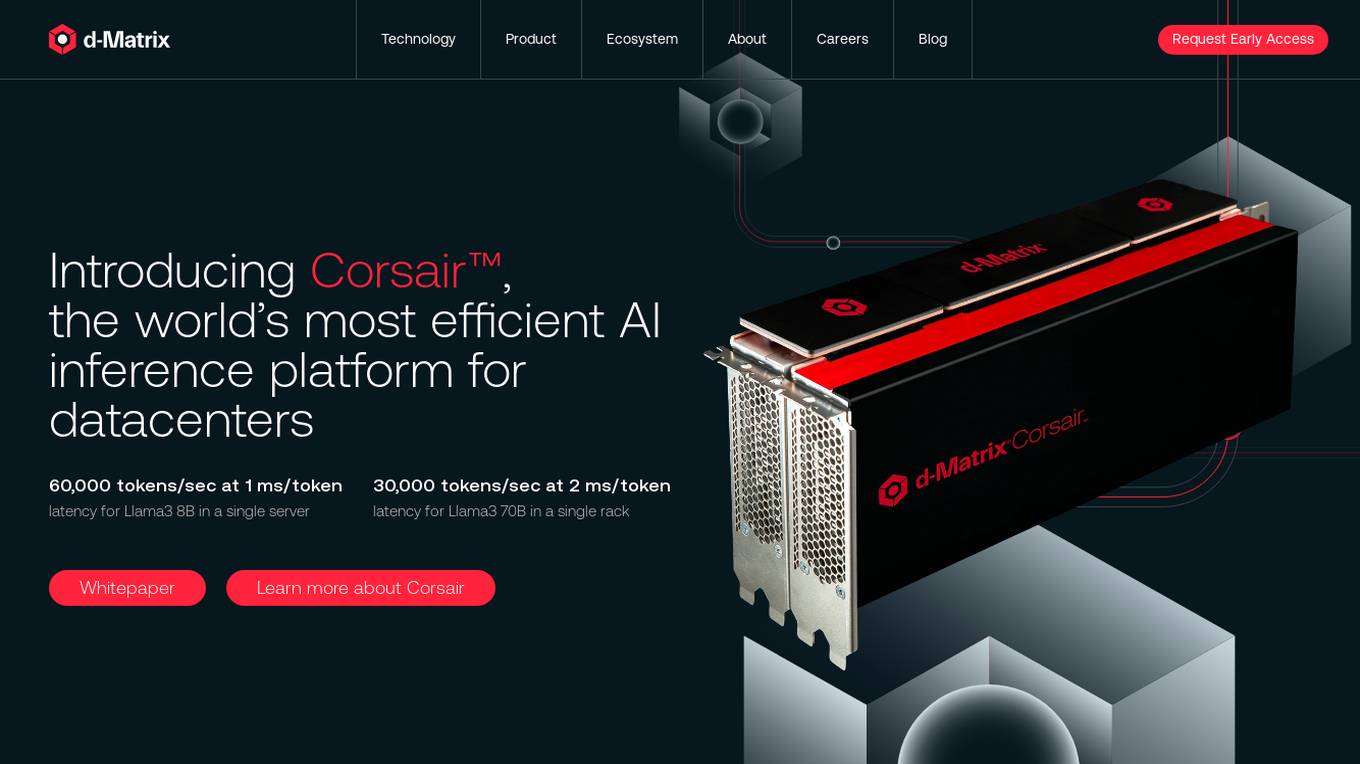
d-Matrix
d-Matrix is an AI tool that offers ultra-low latency batched inference for generative AI technology. It introduces Corsair™, the world's most efficient AI inference platform for datacenters, providing high performance, efficiency, and scalability for large-scale inference tasks. The tool aims to transform the economics of AI inference by delivering fast, sustainable, and scalable AI solutions without compromising on speed or usability.
Modular
Modular is a fast, scalable Gen AI inference platform that offers a comprehensive suite of tools and resources for AI development and deployment. It provides solutions for AI model development, deployment options, AI inference, research, and resources like documentation, models, tutorials, and step-by-step guides. Modular supports GPU and CPU performance, intelligent scaling to any cluster, and offers deployment options for various editions. The platform enables users to build agent workflows, utilize AI retrieval and controlled generation, develop chatbots, engage in code generation, and improve resource utilization through batch processing.
Salad
Salad is a distributed GPU cloud platform that offers fully managed and massively scalable services for AI applications. It provides the lowest priced AI transcription in the market, with features like image generation, voice AI, computer vision, data collection, and batch processing. Salad democratizes cloud computing by leveraging consumer GPUs to deliver cost-effective AI/ML inference at scale. The platform is trusted by hundreds of machine learning and data science teams for its affordability, scalability, and ease of deployment.

Mystic.ai
Mystic.ai is an AI tool designed to deploy and scale Machine Learning models with ease. It offers a fully managed Kubernetes platform that runs in your own cloud, allowing users to deploy ML models in their own Azure/AWS/GCP account or in a shared GPU cluster. Mystic.ai provides cost optimizations, fast inference, simpler developer experience, and performance optimizations to ensure high-performance AI model serving. With features like pay-as-you-go API, cloud integration with AWS/Azure/GCP, and a beautiful dashboard, Mystic.ai simplifies the deployment and management of ML models for data scientists and AI engineers.

Outspeed
Outspeed is a platform for Realtime Voice and Video AI applications, providing networking and inference infrastructure to build fast, real-time voice and video AI apps. It offers tools for intelligence across industries, including Voice AI, Streaming Avatars, Visual Intelligence, Meeting Copilot, and the ability to build custom multimodal AI solutions. Outspeed is designed by engineers from Google and MIT, offering robust streaming infrastructure, low-latency inference, instant deployment, and enterprise-ready compliance with regulations such as SOC2, GDPR, and HIPAA.

Tensordyne
Tensordyne is a generative AI inference compute tool designed and developed in the US and Germany. It focuses on re-engineering AI math and defining AI inference to run the biggest AI models for thousands of users at a fraction of the rack count, power, and cost. Tensordyne offers custom silicon and systems built on the Zeroth Scaling Law, enabling breakthroughs in AI technology.

Tensoic AI
Tensoic AI is an AI tool designed for custom Large Language Models (LLMs) fine-tuning and inference. It offers ultra-fast fine-tuning and inference capabilities for enterprise-grade LLMs, with a focus on use case-specific tasks. The tool is efficient, cost-effective, and easy to use, enabling users to outperform general-purpose LLMs using synthetic data. Tensoic AI generates small, powerful models that can run on consumer-grade hardware, making it ideal for a wide range of applications.
fal
fal is an AI platform that offers cutting-edge AI models and tools for image and video generation, editing, and audio processing. It partners with leading AI companies to bring state-of-the-art technology to its users, enabling them to create stunning visual and audio content with ease. fal is at the forefront of the AI-driven media creation revolution, providing developers and creators with advanced tools to push the boundaries of creativity.
TitanML
TitanML is a platform that provides tools and services for deploying and scaling Generative AI applications. Their flagship product, the Titan Takeoff Inference Server, helps machine learning engineers build, deploy, and run Generative AI models in secure environments. TitanML's platform is designed to make it easy for businesses to adopt and use Generative AI, without having to worry about the underlying infrastructure. With TitanML, businesses can focus on building great products and solving real business problems.
Thirdai
Thirdai.com is an AI-powered platform that offers a range of tools and applications to enhance productivity and decision-making. The platform leverages advanced algorithms and machine learning to provide insights and solutions across various domains such as finance, marketing, and healthcare. Users can access a suite of AI tools to analyze data, automate tasks, and optimize processes. With a user-friendly interface and robust features, Thirdai.com is a valuable resource for individuals and businesses seeking to leverage AI technology for improved outcomes.
Denvr DataWorks AI Cloud
Denvr DataWorks AI Cloud is a cloud-based AI platform that provides end-to-end AI solutions for businesses. It offers a range of features including high-performance GPUs, scalable infrastructure, ultra-efficient workflows, and cost efficiency. Denvr DataWorks is an NVIDIA Elite Partner for Compute, and its platform is used by leading AI companies to develop and deploy innovative AI solutions.
Lambda
Lambda is a superintelligence cloud platform that offers on-demand GPU clusters for multi-node training and fine-tuning, private large-scale GPU clusters, seamless management and scaling of AI workloads, inference endpoints and API, and a privacy-first chat app with open source models. It also provides NVIDIA's latest generation infrastructure for enterprise AI. With Lambda, AI teams can access gigawatt-scale AI factories for training and inference, deploy GPU instances, and leverage the latest NVIDIA GPUs for high-performance computing.
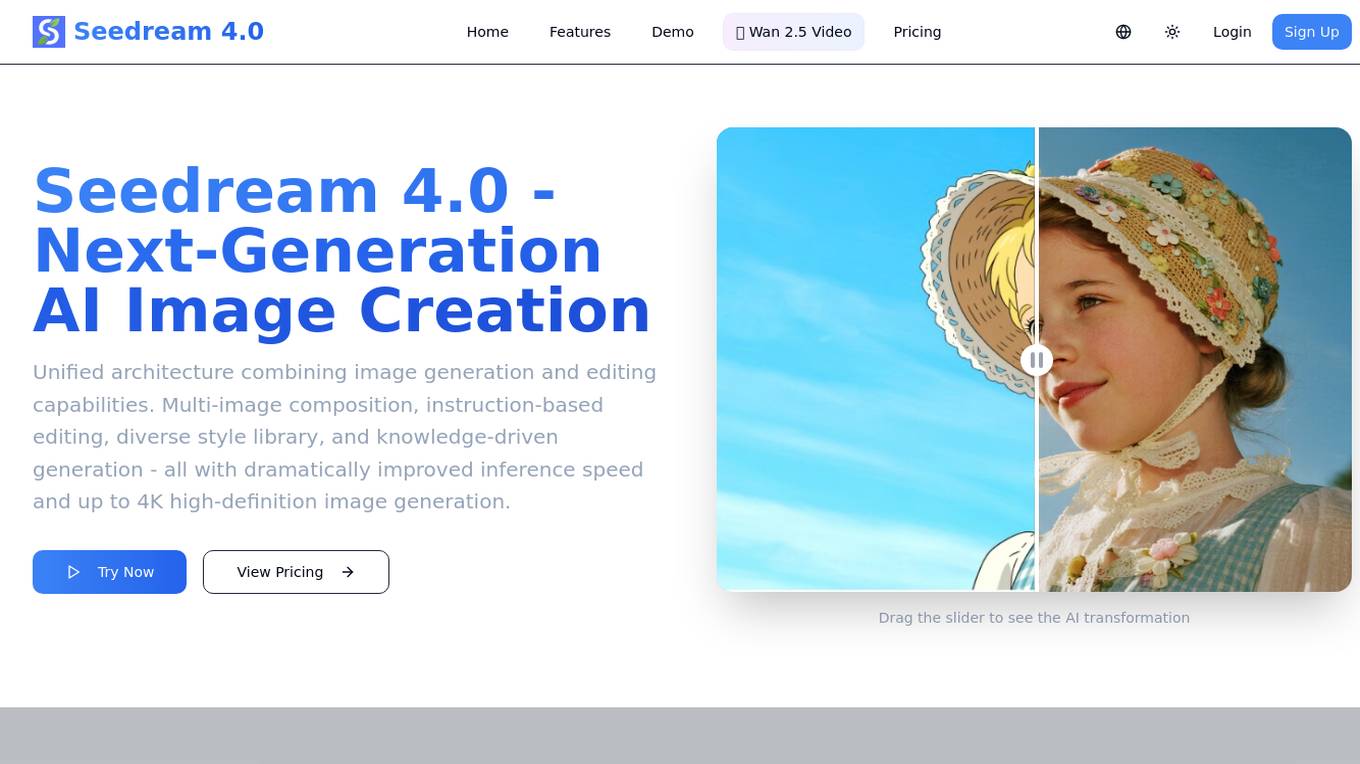
Seedream 4.0
Seedream 4.0 is an AI image generator and editor that offers a unified architecture combining image generation and editing capabilities. It provides features such as multi-image composition, instruction-based editing, diverse style library, and knowledge-driven generation. Users can experience the next generation of AI image creation with dramatically improved inference speed and up to 4K high-definition image generation.
FuriosaAI
FuriosaAI is an AI application that offers Hardware RNGD for LLM and Multimodality, as well as WARBOY for Computer Vision. It provides a comprehensive developer experience through the Furiosa SDK, Model Zoo, and Dev Support. The application focuses on efficient AI inference, high-performance LLM and multimodal deployment capabilities, and sustainable mass adoption of AI. FuriosaAI features the Tensor Contraction Processor architecture, software for streamlined LLM deployment, and a robust ecosystem support. It aims to deliver powerful and efficient deep learning acceleration while ensuring future-proof programmability and efficiency.
ONNX Runtime
ONNX Runtime is a production-grade AI engine designed to accelerate machine learning training and inferencing in various technology stacks. It supports multiple languages and platforms, optimizing performance for CPU, GPU, and NPU hardware. ONNX Runtime powers AI in Microsoft products and is widely used in cloud, edge, web, and mobile applications. It also enables large model training and on-device training, offering state-of-the-art models for tasks like image synthesis and text generation.

Digital Experiment Analyst
Demystifying Experimentation and Causal Inference with 1-Sided Tests Focus

Digest Bot
I provide detailed summaries, critiques, and inferences on articles, papers, transcripts, websites, and more. Just give me text, a URL, or file to digest.
人為的コード性格分析(Code Persona Analyst)
コードを分析し、言語ではなくスタイルに焦点を当て、プログラムを書いた人の性格を推察するツールです。( It is a tool that analyzes code, focuses on style rather than language, and infers the personality of the person who wrote the program. )


InsightIQ - Influencer Marketing
Find influencers across Instagram, TikTok, and YouTube whose audience aligns with your target demographic to effectively engage with your customers.
Andrew Darius' Influencer Genius
I'm a friendly and conversational Social Media Influencer, engaging with a casual tone.
InfluencerAI Creator
AI influencer design expert for virtual personas and social media strategies
Government Relations Advisor
Influences policy decisions through strategic government relationships.

ZEN Influencer Insurance
I create social media influencer insurance plans with a focus on legal compliance.
Expert in Legal Review of Influencer Agreements
Legal expert in reviewing influencer agreement (Powered by LegalNow, ai.legalnow.xyz)
Content Coach
🚀 Meet Content Coach, your go-to virtual influencer for all things social media! With a flair for crafting eye-catching content, I'm here to elevate your brand's online presence. 🌟 I've got the strategies to engage your audience and boost your brand's awareness. ✨


末日幸存者:社会动态模拟 Doomsday Survivor
上帝视角观察、探索和影响一个末日丧尸灾难后的人类社会。Observe, explore and influence human society after the apocalyptic zombie disaster from a God's perspective. Sponsor:小红书“ ItsJoe就出行 ”
Content Evaluator
Analyzes and rates your writing using insights derived from studying LinkedIn influencers' top performing posts from the last 4 years.
言語匠くん“AI.WordArtisan”
“A Journey of Weaving Language. Elevating Inferential Abilities.”#GPTs ”chat.openai.com”👈みんなであそぼう #ChatGPT

inference
Xorbits Inference (Xinference) is a powerful and versatile library designed to serve language, speech recognition, and multimodal models. With Xorbits Inference, you can effortlessly deploy and serve your or state-of-the-art built-in models using just a single command. Whether you are a researcher, developer, or data scientist, Xorbits Inference empowers you to unleash the full potential of cutting-edge AI models.

vector-inference
This repository provides an easy-to-use solution for running inference servers on Slurm-managed computing clusters using vLLM. All scripts in this repository run natively on the Vector Institute cluster environment. Users can deploy models as Slurm jobs, check server status and performance metrics, and shut down models. The repository also supports launching custom models with specific configurations. Additionally, users can send inference requests and set up an SSH tunnel to run inference from a local device.
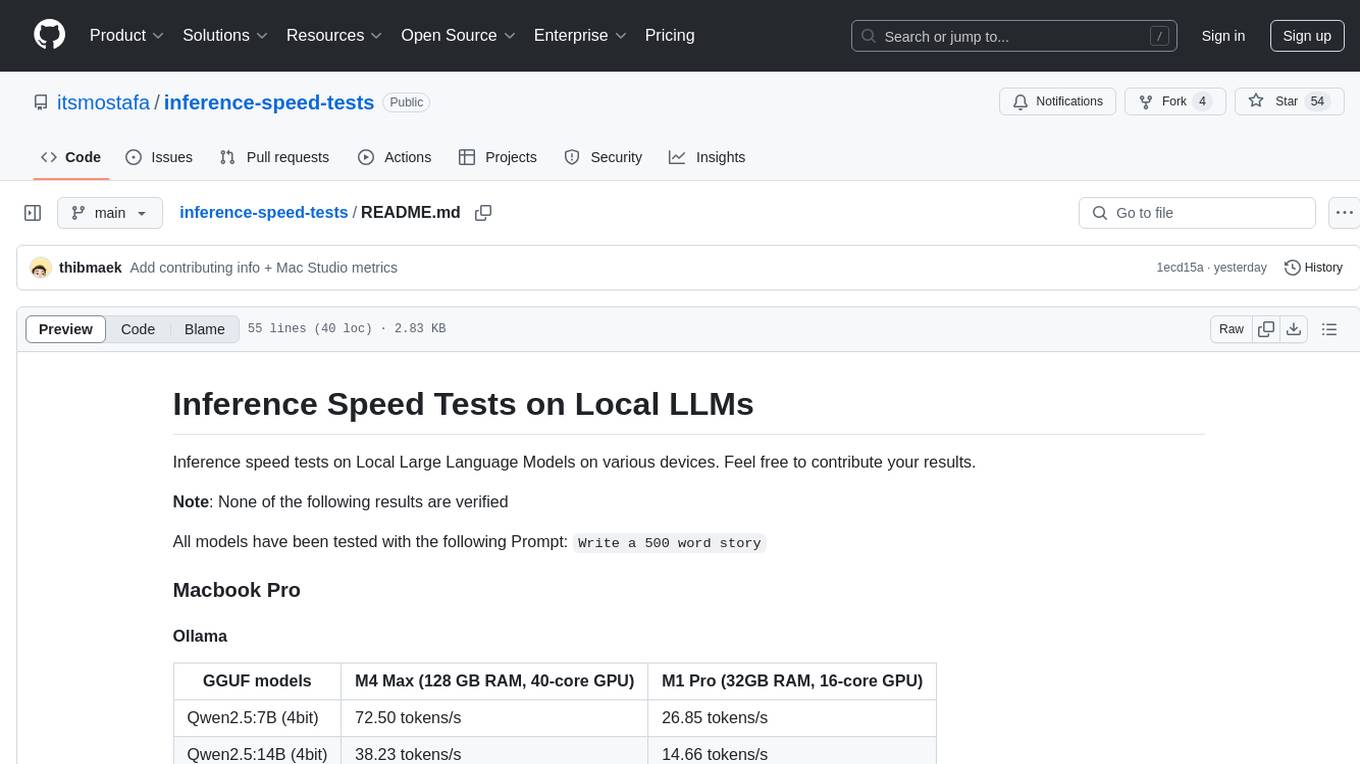
inference-speed-tests
This repository contains inference speed tests on Local Large Language Models on various devices. It provides results for different models tested on Macbook Pro and Mac Studio. Users can contribute their own results by running models with the provided prompt and adding the tokens-per-second output. Note that the results are not verified.
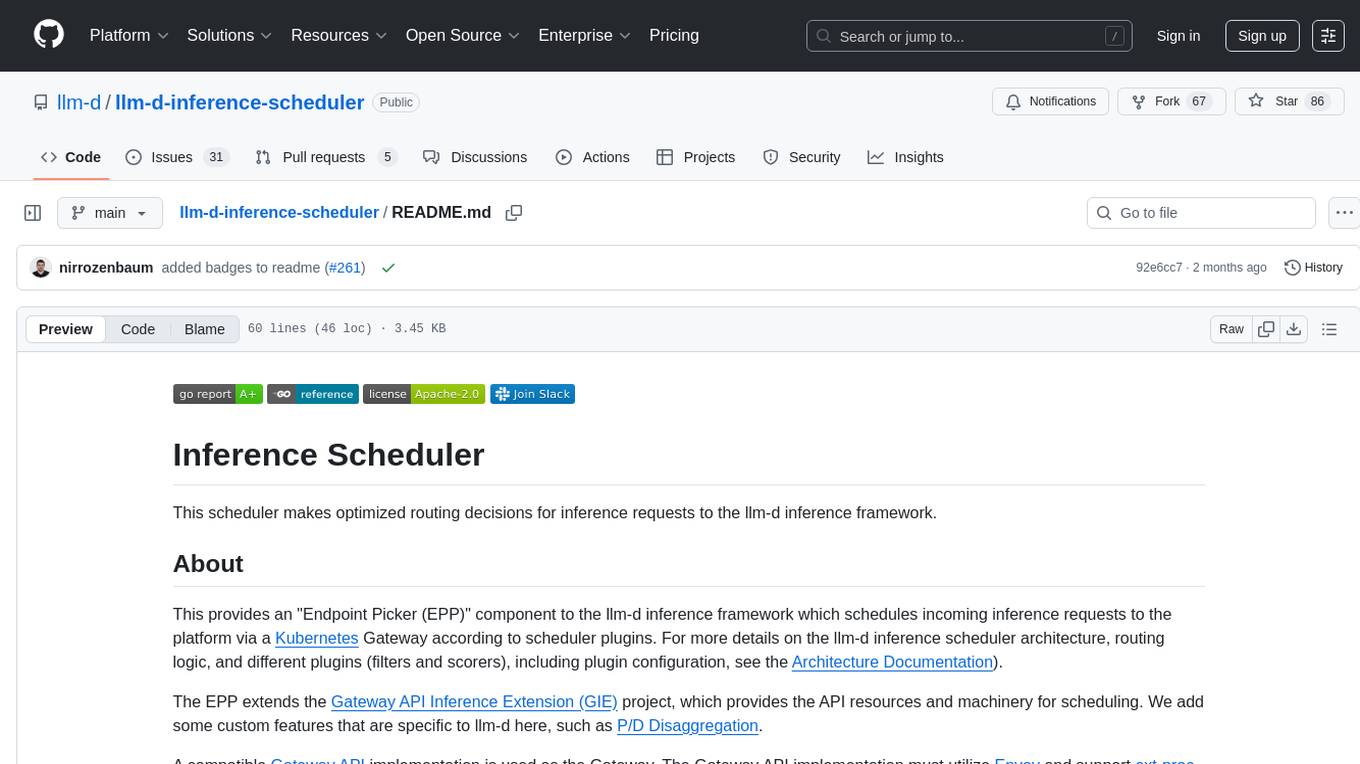
llm-d-inference-scheduler
This repository contains the Inference Scheduler, which makes optimized routing decisions for inference requests to the llm-d inference framework. It provides an 'Endpoint Picker (EPP)' component to the framework, scheduling incoming inference requests via a Kubernetes Gateway according to scheduler plugins. The EPP extends the Gateway API Inference Extension (GIE) project, adding custom features specific to llm-d, such as P/D Disaggregation. The scheduler architecture, routing logic, and plugin configuration are detailed in the Architecture Documentation. Contributions are welcome, and large changes should be discussed with maintainers first.
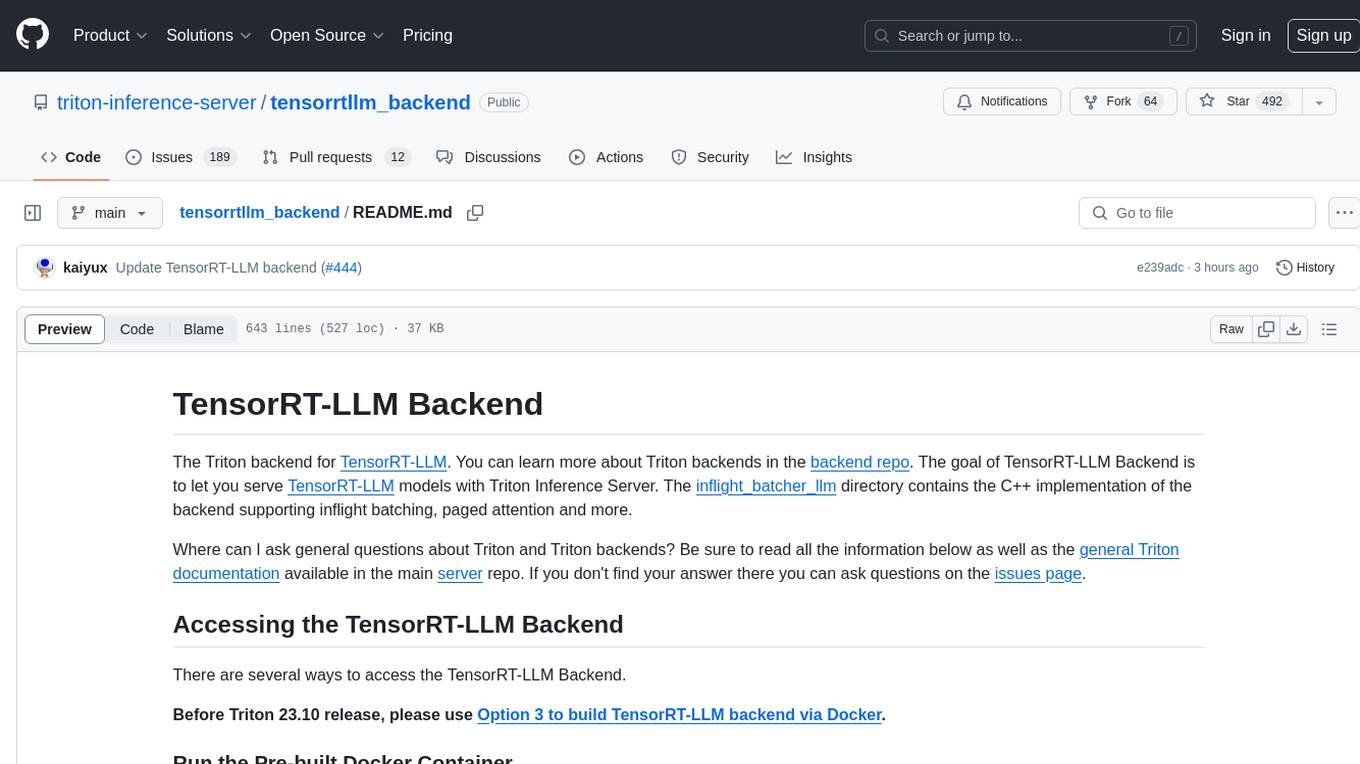
tensorrtllm_backend
The TensorRT-LLM Backend is a Triton backend designed to serve TensorRT-LLM models with Triton Inference Server. It supports features like inflight batching, paged attention, and more. Users can access the backend through pre-built Docker containers or build it using scripts provided in the repository. The backend can be used to create models for tasks like tokenizing, inferencing, de-tokenizing, ensemble modeling, and more. Users can interact with the backend using provided client scripts and query the server for metrics related to request handling, memory usage, KV cache blocks, and more. Testing for the backend can be done following the instructions in the 'ci/README.md' file.

mistral-inference
Mistral Inference repository contains minimal code to run 7B, 8x7B, and 8x22B models. It provides model download links, installation instructions, and usage guidelines for running models via CLI or Python. The repository also includes information on guardrailing, model platforms, deployment, and references. Users can interact with models through commands like mistral-demo, mistral-chat, and mistral-common. Mistral AI models support function calling and chat interactions for tasks like testing models, chatting with models, and using Codestral as a coding assistant. The repository offers detailed documentation and links to blogs for further information.
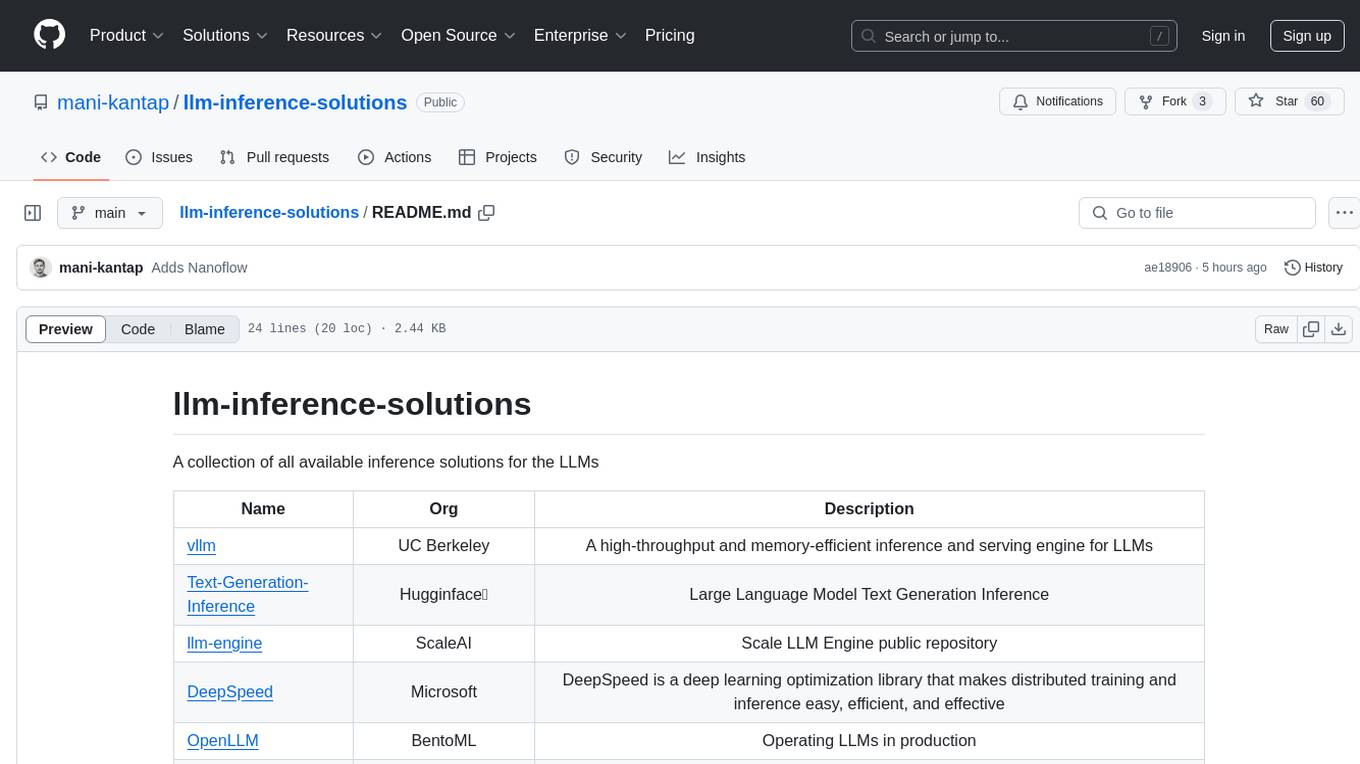
llm-inference-solutions
A collection of available inference solutions for Large Language Models (LLMs) including high-throughput engines, optimization libraries, deployment toolkits, and deep learning frameworks for production environments.
llm-inference-calculator
A web-based calculator to estimate hardware requirements for running Large Language Models (LLMs) in inference mode. This tool helps determine VRAM and system RAM needed for different LLM configurations. It calculates VRAM requirements based on model size, quantization method, context length, and KV cache settings. It provides estimates for required VRAM, minimum system RAM, on-disk model size, and number of GPUs needed. The project uses React, TypeScript, and Vite. Docker support is available with instructions provided. The tool provides approximations for calculations, includes overhead for KV cache, and assumes certain percentages for unified memory and discrete GPU calculations.
Awesome-LLM-Inference
Awesome-LLM-Inference: A curated list of 📙Awesome LLM Inference Papers with Codes, check 📖Contents for more details. This repo is still updated frequently ~ 👨💻 Welcome to star ⭐️ or submit a PR to this repo!

text-embeddings-inference
Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for popular models like FlagEmbedding, Ember, GTE, and E5. It implements features such as no model graph compilation step, Metal support for local execution on Macs, small docker images with fast boot times, token-based dynamic batching, optimized transformers code for inference using Flash Attention, Candle, and cuBLASLt, Safetensors weight loading, and production-ready features like distributed tracing with Open Telemetry and Prometheus metrics.

FlexFlow
FlexFlow Serve is an open-source compiler and distributed system for **low latency**, **high performance** LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.

bark.cpp
Bark.cpp is a C/C++ implementation of the Bark model, a real-time, multilingual text-to-speech generation model. It supports AVX, AVX2, and AVX512 for x86 architectures, and is compatible with both CPU and GPU backends. Bark.cpp also supports mixed F16/F32 precision and 4-bit, 5-bit, and 8-bit integer quantization. It can be used to generate realistic-sounding audio from text prompts.
effort
Effort is an example implementation of the bucketMul algorithm, which allows for real-time adjustment of the number of calculations performed during inference of an LLM model. At 50% effort, it performs as fast as regular matrix multiplications on Apple Silicon chips; at 25% effort, it is twice as fast while still retaining most of the quality. Additionally, users have the option to skip loading the least important weights.
cortex
Nitro is a high-efficiency C++ inference engine for edge computing, powering Jan. It is lightweight and embeddable, ideal for product integration. The binary of nitro after zipped is only ~3mb in size with none to minimal dependencies (if you use a GPU need CUDA for example) make it desirable for any edge/server deployment.

NanoLLM
NanoLLM is a tool designed for optimized local inference for Large Language Models (LLMs) using HuggingFace-like APIs. It supports quantization, vision/language models, multimodal agents, speech, vector DB, and RAG. The tool aims to provide efficient and effective processing for LLMs on local devices, enhancing performance and usability for various AI applications.

stable-diffusion.cpp
The stable-diffusion.cpp repository provides an implementation for inferring stable diffusion in pure C/C++. It offers features such as support for different versions of stable diffusion, lightweight and dependency-free implementation, various quantization support, memory-efficient CPU inference, GPU acceleration, and more. Users can download the built executable program or build it manually. The repository also includes instructions for downloading weights, building from scratch, using different acceleration methods, running the tool, converting weights, and utilizing various features like Flash Attention, ESRGAN upscaling, PhotoMaker support, and more. Additionally, it mentions future TODOs and provides information on memory requirements, bindings, UIs, contributors, and references.

dash-infer
DashInfer is a C++ runtime tool designed to deliver production-level implementations highly optimized for various hardware architectures, including x86 and ARMv9. It supports Continuous Batching and NUMA-Aware capabilities for CPU, and can fully utilize modern server-grade CPUs to host large language models (LLMs) up to 14B in size. With lightweight architecture, high precision, support for mainstream open-source LLMs, post-training quantization, optimized computation kernels, NUMA-aware design, and multi-language API interfaces, DashInfer provides a versatile solution for efficient inference tasks. It supports x86 CPUs with AVX2 instruction set and ARMv9 CPUs with SVE instruction set, along with various data types like FP32, BF16, and InstantQuant. DashInfer also offers single-NUMA and multi-NUMA architectures for model inference, with detailed performance tests and inference accuracy evaluations available. The tool is supported on mainstream Linux server operating systems and provides documentation and examples for easy integration and usage.
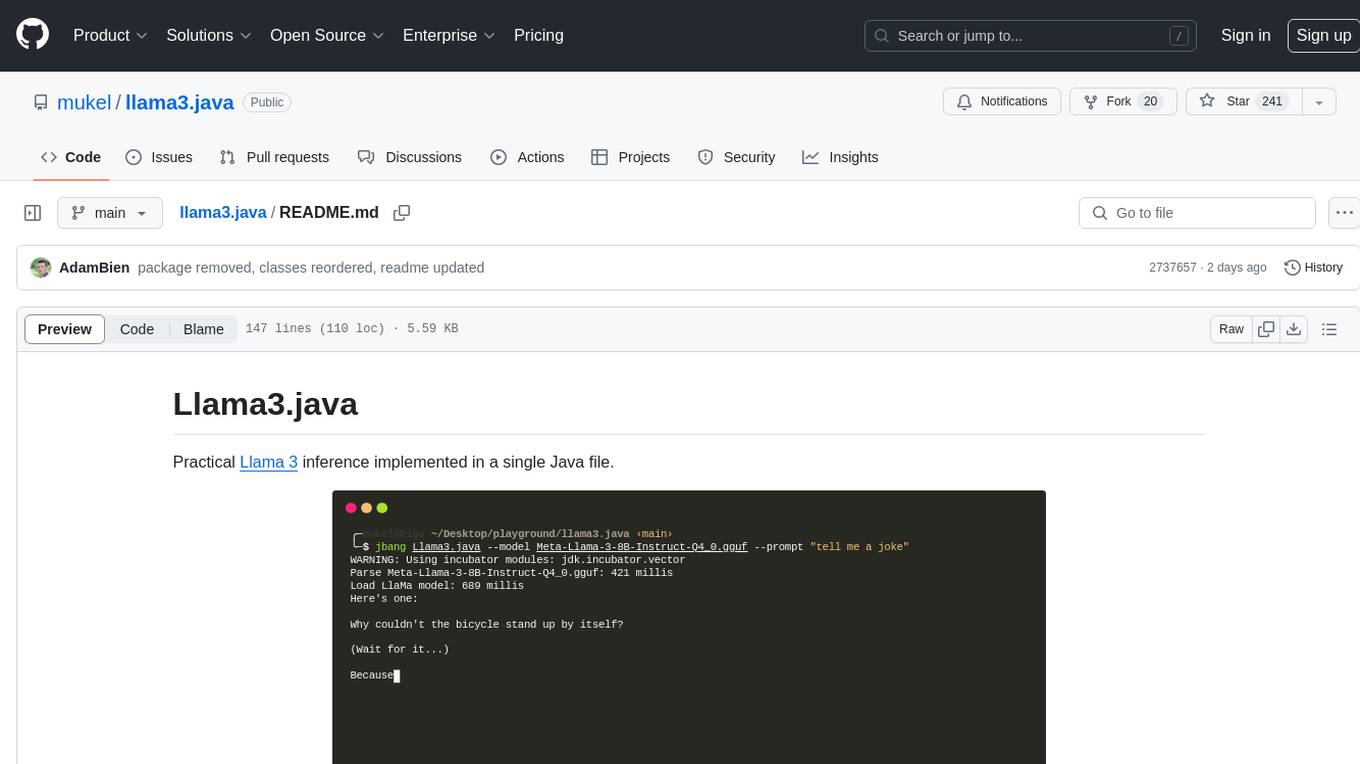
llama3.java
Llama3.java is a practical Llama 3 inference tool implemented in a single Java file. It serves as the successor of llama2.java and is designed for testing and tuning compiler optimizations and features on the JVM, especially for the Graal compiler. The tool features a GGUF format parser, Llama 3 tokenizer, Grouped-Query Attention inference, support for Q8_0 and Q4_0 quantizations, fast matrix-vector multiplication routines using Java's Vector API, and a simple CLI with 'chat' and 'instruct' modes. Users can download quantized .gguf files from huggingface.co for model usage and can also manually quantize to pure 'Q4_0'. The tool requires Java 21+ and supports running from source or building a JAR file for execution. Performance benchmarks show varying tokens/s rates for different models and implementations on different hardware setups.

Jlama
Jlama is a modern Java inference engine designed for large language models. It supports various model types such as Gemma, Llama, Mistral, GPT-2, BERT, and more. The tool implements features like Flash Attention, Mixture of Experts, and supports different model quantization formats. Built with Java 21 and utilizing the new Vector API for faster inference, Jlama allows users to add LLM inference directly to their Java applications. The tool includes a CLI for running models, a simple UI for chatting with LLMs, and examples for different model types.