
llm-d-inference-scheduler
Inference scheduler for llm-d
Stars: 87
This repository contains the Inference Scheduler, which makes optimized routing decisions for inference requests to the llm-d inference framework. It provides an 'Endpoint Picker (EPP)' component to the framework, scheduling incoming inference requests via a Kubernetes Gateway according to scheduler plugins. The EPP extends the Gateway API Inference Extension (GIE) project, adding custom features specific to llm-d, such as P/D Disaggregation. The scheduler architecture, routing logic, and plugin configuration are detailed in the Architecture Documentation. Contributions are welcome, and large changes should be discussed with maintainers first.
README:

This scheduler makes optimized routing decisions for inference requests to the llm-d inference framework.
This provides an "Endpoint Picker (EPP)" component to the llm-d inference framework which schedules incoming inference requests to the platform via a Kubernetes Gateway according to scheduler plugins. For more details on the llm-d inference scheduler architecture, routing logic, and different plugins (filters and scorers), including plugin configuration, see the Architecture Documentation).
The EPP extends the Gateway API Inference Extension (GIE) project, which provides the API resources and machinery for scheduling. We add some custom features that are specific to llm-d here, such as P/D Disaggregation.
A compatible Gateway API implementation is used as the Gateway. The Gateway API implementation must utilize Envoy and support ext-proc, as this is the callback mechanism the EPP relies on to make routing decisions to model serving workloads currently.
Our community meeting is weekly at Wednesday 10AM PDT (Google Meet, Meeting Notes).
We currently utilize the #sig-inference-scheduler channel in llm-d Slack workspace for communications.
For large changes please create an issue first describing the change so the maintainers can do an assessment, and work on the details with you. See DEVELOPMENT.md for details on how to work with the codebase.
Note that in general features should go to the upstream Gateway API Inference Extension (GIE) project first if applicable. The GIE is a major dependency of ours, and where most general purpose inference features live. If you have something that you feel is general purpose or use, it probably should go to the GIE. If you have something that's llm-d specific then it should go here. If you're not sure whether your feature belongs here or in the GIE, feel free to create a discussion or ask on Slack.
Contributions are welcome!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-d-inference-scheduler
Similar Open Source Tools
llm-d-inference-scheduler
This repository contains the Inference Scheduler, which makes optimized routing decisions for inference requests to the llm-d inference framework. It provides an 'Endpoint Picker (EPP)' component to the framework, scheduling incoming inference requests via a Kubernetes Gateway according to scheduler plugins. The EPP extends the Gateway API Inference Extension (GIE) project, adding custom features specific to llm-d, such as P/D Disaggregation. The scheduler architecture, routing logic, and plugin configuration are detailed in the Architecture Documentation. Contributions are welcome, and large changes should be discussed with maintainers first.

llm_client
llm_client is a Rust interface designed for Local Large Language Models (LLMs) that offers automated build support for CPU, CUDA, MacOS, easy model presets, and a novel cascading prompt workflow for controlled generation. It provides a breadth of configuration options and API support for various OpenAI compatible APIs. The tool is primarily focused on deterministic signals from probabilistic LLM vibes, enabling specialized workflows for specific tasks and reproducible outcomes.
ParrotServe
Parrot is a distributed serving system for LLM-based Applications, designed to efficiently serve LLM-based applications by adding Semantic Variable in the OpenAI-style API. It allows for horizontal scalability with multiple Engine instances running LLM models communicating with ServeCore. The system enables AI agents to interact with LLMs via natural language prompts for collaborative tasks.

spring-ai
The Spring AI project provides a Spring-friendly API and abstractions for developing AI applications. It offers a portable client API for interacting with generative AI models, enabling developers to easily swap out implementations and access various models like OpenAI, Azure OpenAI, and HuggingFace. Spring AI also supports prompt engineering, providing classes and interfaces for creating and parsing prompts, as well as incorporating proprietary data into generative AI without retraining the model. This is achieved through Retrieval Augmented Generation (RAG), which involves extracting, transforming, and loading data into a vector database for use by AI models. Spring AI's VectorStore abstraction allows for seamless transitions between different vector database implementations.
ask-astro
Ask Astro is an open-source reference implementation of Andreessen Horowitz's LLM Application Architecture built by Astronomer. It provides an end-to-end example of a Q&A LLM application used to answer questions about Apache Airflow® and Astronomer. Ask Astro includes Airflow DAGs for data ingestion, an API for business logic, a Slack bot, a public UI, and DAGs for processing user feedback. The tool is divided into data retrieval & embedding, prompt orchestration, and feedback loops.
codebase-context-spec
The Codebase Context Specification (CCS) project aims to standardize embedding contextual information within codebases to enhance understanding for both AI and human developers. It introduces a convention similar to `.env` and `.editorconfig` files but focused on documenting code for both AI and humans. By providing structured contextual metadata, collaborative documentation guidelines, and standardized context files, developers can improve code comprehension, collaboration, and development efficiency. The project includes a linter for validating context files and provides guidelines for using the specification with AI assistants. Tooling recommendations suggest creating memory systems, IDE plugins, AI model integrations, and agents for context creation and utilization. Future directions include integration with existing documentation systems, dynamic context generation, and support for explicit context overriding.
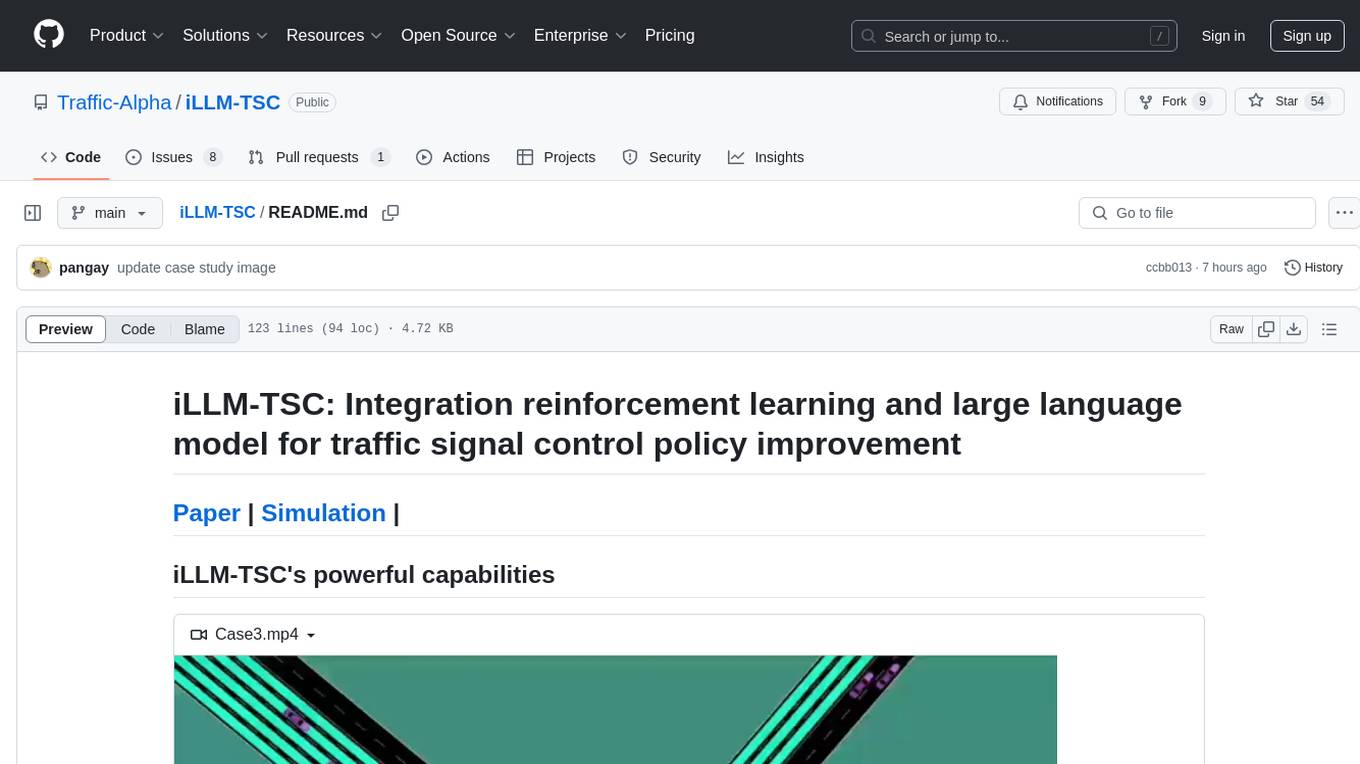
iLLM-TSC
iLLM-TSC is a framework that integrates reinforcement learning and large language models for traffic signal control policy improvement. It refines RL decisions based on real-world contexts and provides reasonable actions when RL agents make erroneous decisions. The framework includes cases where the large language model provides explanations and recommendations for RL agent actions, such as prioritizing emergency vehicles at intersections. Users can install and run the framework locally to train RL models and evaluate the combined RL+LLM approach.

graphrag
The GraphRAG project is a data pipeline and transformation suite designed to extract meaningful, structured data from unstructured text using LLMs. It enhances LLMs' ability to reason about private data. The repository provides guidance on using knowledge graph memory structures to enhance LLM outputs, with a warning about the potential costs of GraphRAG indexing. It offers contribution guidelines, development resources, and encourages prompt tuning for optimal results. The Responsible AI FAQ addresses GraphRAG's capabilities, intended uses, evaluation metrics, limitations, and operational factors for effective and responsible use.

easydist
EasyDist is an automated parallelization system and infrastructure designed for multiple ecosystems. It offers usability by making parallelizing training or inference code effortless with just a single line of change. It ensures ecological compatibility by serving as a centralized source of truth for SPMD rules at the operator-level for various machine learning frameworks. EasyDist decouples auto-parallel algorithms from specific frameworks and IRs, allowing for the development and benchmarking of different auto-parallel algorithms in a flexible manner. The architecture includes MetaOp, MetaIR, and the ShardCombine Algorithm for SPMD sharding rules without manual annotations.
quick-start-connectors
Cohere's Build-Your-Own-Connector framework allows integration of Cohere's Command LLM via the Chat API endpoint to any datastore/software holding text information with a search endpoint. Enables user queries grounded in proprietary information. Use-cases include question/answering, knowledge working, comms summary, and research. Repository provides code for popular datastores and a template connector. Requires Python 3.11+ and Poetry. Connectors can be built and deployed using Docker. Environment variables set authorization values. Pre-commits for linting. Connectors tailored to integrate with Cohere's Chat API for creating chatbots. Connectors return documents as JSON objects for Cohere's API to generate answers with citations.

pathway
Pathway is a Python data processing framework for analytics and AI pipelines over data streams. It's the ideal solution for real-time processing use cases like streaming ETL or RAG pipelines for unstructured data. Pathway comes with an **easy-to-use Python API** , allowing you to seamlessly integrate your favorite Python ML libraries. Pathway code is versatile and robust: **you can use it in both development and production environments, handling both batch and streaming data effectively**. The same code can be used for local development, CI/CD tests, running batch jobs, handling stream replays, and processing data streams. Pathway is powered by a **scalable Rust engine** based on Differential Dataflow and performs incremental computation. Your Pathway code, despite being written in Python, is run by the Rust engine, enabling multithreading, multiprocessing, and distributed computations. All the pipeline is kept in memory and can be easily deployed with **Docker and Kubernetes**. You can install Pathway with pip: `pip install -U pathway` For any questions, you will find the community and team behind the project on Discord.
GhostOS
GhostOS is an AI Agent framework designed to replace JSON Schema with a Turing-complete code interaction interface (Moss Protocol). It aims to create intelligent entities capable of continuous learning and growth through code generation and project management. The framework supports various capabilities such as turning Python files into web agents, real-time voice conversation, body movements control, and emotion expression. GhostOS is still in early experimental development and focuses on out-of-the-box capabilities for AI agents.

WilmerAI
WilmerAI is a middleware system designed to process prompts before sending them to Large Language Models (LLMs). It categorizes prompts, routes them to appropriate workflows, and generates manageable prompts for local models. It acts as an intermediary between the user interface and LLM APIs, supporting multiple backend LLMs simultaneously. WilmerAI provides API endpoints compatible with OpenAI API, supports prompt templates, and offers flexible connections to various LLM APIs. The project is under heavy development and may contain bugs or incomplete code.

airbroke
Airbroke is an open-source error catcher tool designed for modern web applications. It provides a PostgreSQL-based backend with an Airbrake-compatible HTTP collector endpoint and a React-based frontend for error management. The tool focuses on simplicity, maintaining a small database footprint even under heavy data ingestion. Users can ask AI about issues, replay HTTP exceptions, and save/manage bookmarks for important occurrences. Airbroke supports multiple OAuth providers for secure user authentication and offers occurrence charts for better insights into error occurrences. The tool can be deployed in various ways, including building from source, using Docker images, deploying on Vercel, Render.com, Kubernetes with Helm, or Docker Compose. It requires Node.js, PostgreSQL, and specific system resources for deployment.
agents-at-scale-ark
ARK is an agentic runtime for Kubernetes that codifies patterns and practices developed across client projects. It provides a foundation for platform-agnostic operations and standardized deployment approaches. The project is in early access, evolving based on team feedback, and aims to share technical approach with the community for feedback and input in the field of agentic AI systems and Kubernetes orchestration.

serena
Serena is a powerful coding agent that integrates with existing LLMs to provide essential semantic code retrieval and editing tools. It is free to use and does not require API keys or subscriptions. Serena can be used for coding tasks such as analyzing, planning, and editing code directly on your codebase. It supports various programming languages and offers semantic code analysis capabilities through language servers. Serena can be integrated with different LLMs using the model context protocol (MCP) or Agno framework. The tool provides a range of functionalities for code retrieval, editing, and execution, making it a versatile coding assistant for developers.
For similar tasks
HookPHP
HookPHP is an open-source project that provides a PHP extension for hooking into various aspects of PHP applications. It allows developers to easily extend and customize the behavior of their PHP applications by providing hooks at key points in the execution flow. With HookPHP, developers can efficiently add custom functionality, modify existing behavior, and enhance the overall performance of their PHP applications. The project is licensed under the MIT license, making it accessible for developers to use and contribute to.
llm-d-inference-scheduler
This repository contains the Inference Scheduler, which makes optimized routing decisions for inference requests to the llm-d inference framework. It provides an 'Endpoint Picker (EPP)' component to the framework, scheduling incoming inference requests via a Kubernetes Gateway according to scheduler plugins. The EPP extends the Gateway API Inference Extension (GIE) project, adding custom features specific to llm-d, such as P/D Disaggregation. The scheduler architecture, routing logic, and plugin configuration are detailed in the Architecture Documentation. Contributions are welcome, and large changes should be discussed with maintainers first.
parallax
Parallax is a fully decentralized inference engine developed by Gradient. It allows users to build their own AI cluster for model inference across distributed nodes with varying configurations and physical locations. Core features include hosting local LLM on personal devices, cross-platform support, pipeline parallel model sharding, paged KV cache management, continuous batching for Mac, dynamic request scheduling, and routing for high performance. The backend architecture includes P2P communication powered by Lattica, GPU backend powered by SGLang and vLLM, and MAC backend powered by MLX LM.
For similar jobs

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

kong
Kong, or Kong API Gateway, is a cloud-native, platform-agnostic, scalable API Gateway distinguished for its high performance and extensibility via plugins. It also provides advanced AI capabilities with multi-LLM support. By providing functionality for proxying, routing, load balancing, health checking, authentication (and more), Kong serves as the central layer for orchestrating microservices or conventional API traffic with ease. Kong runs natively on Kubernetes thanks to its official Kubernetes Ingress Controller.

AI-in-a-Box
AI-in-a-Box is a curated collection of solution accelerators that can help engineers establish their AI/ML environments and solutions rapidly and with minimal friction, while maintaining the highest standards of quality and efficiency. It provides essential guidance on the responsible use of AI and LLM technologies, specific security guidance for Generative AI (GenAI) applications, and best practices for scaling OpenAI applications within Azure. The available accelerators include: Azure ML Operationalization in-a-box, Edge AI in-a-box, Doc Intelligence in-a-box, Image and Video Analysis in-a-box, Cognitive Services Landing Zone in-a-box, Semantic Kernel Bot in-a-box, NLP to SQL in-a-box, Assistants API in-a-box, and Assistants API Bot in-a-box.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).
generative-ai-cdk-constructs
The AWS Generative AI Constructs Library is an open-source extension of the AWS Cloud Development Kit (AWS CDK) that provides multi-service, well-architected patterns for quickly defining solutions in code to create predictable and repeatable infrastructure, called constructs. The goal of AWS Generative AI CDK Constructs is to help developers build generative AI solutions using pattern-based definitions for their architecture. The patterns defined in AWS Generative AI CDK Constructs are high level, multi-service abstractions of AWS CDK constructs that have default configurations based on well-architected best practices. The library is organized into logical modules using object-oriented techniques to create each architectural pattern model.

model_server
OpenVINO™ Model Server (OVMS) is a high-performance system for serving models. Implemented in C++ for scalability and optimized for deployment on Intel architectures, the model server uses the same architecture and API as TensorFlow Serving and KServe while applying OpenVINO for inference execution. Inference service is provided via gRPC or REST API, making deploying new algorithms and AI experiments easy.
dify-helm
Deploy langgenius/dify, an LLM based chat bot app on kubernetes with helm chart.