
behavior3lua
behavior tree for lua
Stars: 106
Behavior3Lua is a Lua framework for behavior trees in game AI. It provides a modified blackboard system where behavior trees are designed like code editors, allowing game designers to configure logic through editing trees. The framework offers various node types for creating complex AI behaviors, freeing game programmers from manual configuration. It includes composite, decorator, and action nodes, along with an API for creating and running behavior trees. The framework supports running states and provides an editor for visual tree editing. It has been successfully used in multiple projects for different game genres, enabling designers to create sophisticated AI and logic systems.
README:
机缘巧合,近几年的工作一直有涉及到游戏AI这块,网上常见的行为树+黑板似乎不太能满足复杂策划需求,也不太可能让策划自己去配置这种行为树。因此,我对行为树的黑板进行了小改造,让行为树更像一个代码编辑器,我们程序提供为数不多的行为节点,让策划通过编辑行为树来实现他们想要的逻辑,这对于游戏程序员来说也算是一种解放吧。
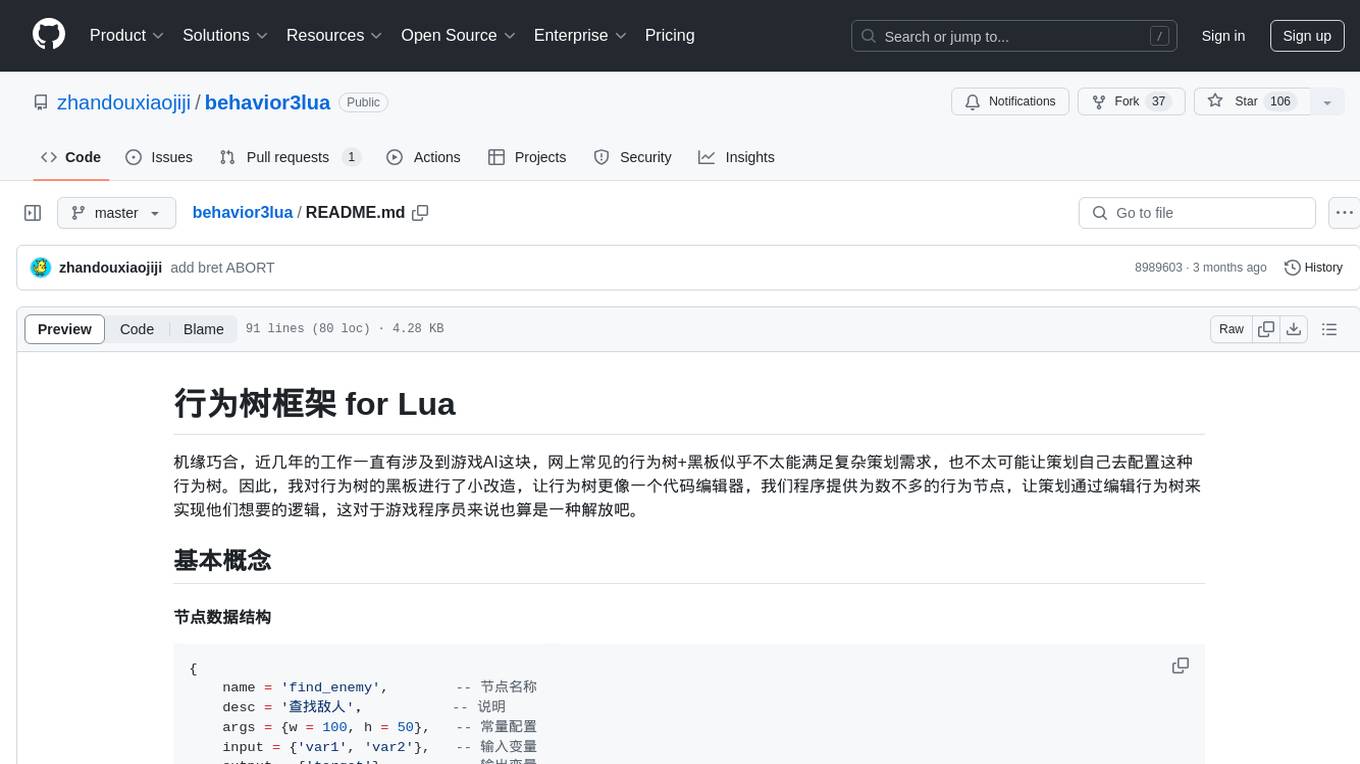
{
name = 'find_enemy', -- 节点名称
desc = '查找敌人', -- 说明
args = {w = 100, h = 50}, -- 常量配置
input = {'var1', 'var2'}, -- 输入变量
output = {'target'}, -- 输出变量
children = {} -- 子节点
}通常是固定值,比如范围,类型之类的
因为节点之间都有相互的影响,比如这个节点可能会用到上一个节点所产生的数据,所以大多数行为树设计者都提供一个数据结构来记录行为树的运行状态,称之为“黑板”。
我偷换了个概念,把节点当成一个function来执行,如上面一个节点定义的input={'var1', 'var2'}意思是在执行节点前从黑板里把var1和var2这两个变量取出来,作为参数传进去,在节点执行完后把结果返回,写到target这个变量上。整个过程就像下面这段伪代码:
function find_enemy(var1, var2)
local w, h = args.w, args.h
// do find enemy in range w, h
...
return target
end上面这个节点执行完,黑板上target这个变量就写上了查找到的目标,而后面的节点就可以使用target这个变量作为input了。
{
name = 'attack',
desc = '攻击敌人',
args = {skill = 101},
input = {'target'},
}- SUCCESS 成功
- FAIL 失败
- RUNNING 正在运行
- ABORT 中断执行
- Parallel 并行执行, 执行所有子节点并反回true
- Sequence 顺序执行,执行所有子节点直到返回false
- Selector 选择执行,执行所有子节点直到返回true
- Not 取反
- AlwaysSuccess
- AlwaysFail
- Wait 等待一段时间后继续执行
- MoveToTarget 移动到目标
- GetHp 获取生命值
- Attack 攻击目标
- new 创建新的行为树对象
- run 执行一次tick
- set_var 设置变量
- get_var 获取变量
做行为树始终绕不开一个问题,就是running状态,如果一套行为树方案没有running状态,那它只能用来做决策树,而不能做持续动作。要想实现running状态,关键是如何用上一次运行的节点恢复起来。行为树的节点调用很像程序的调用栈,其实对复合节点稍做改造即可实现:
- 只要是有任意子节点返回的是RUNNING, 立即返回RUNNING。
- 运行节点前把节点压入栈,如果该节点返回RUNNING,则中断执行,等待下次tick唤醒,如果返回的是SUCCESS或FAIL,则出栈,继续往下执行。

我用阿里的g6图形库开发了一个通用的行为树编辑器,并用electron打包成exe版本,目前还比较简陋,感兴趣的同学可以关注一下 behavior3editor

- 导出节点定义
lua export_node.lua
- 运行测试
lua test.lua
我以前的做法是,把每一tick所有的节点执行结果都发给编辑器然后在编辑器上展示,非常详细,但实际应用却很鸡肋,太多冗余的数据让人眼花缭乱。我目前的做法是在编辑行为树的时候,把需要调试的节点打上标志,当行为树运行到这个节点的时候,打印这个节点相关的日志,比如时间/帧数,执行结果,及所有变量的值。
这套方案我已经在好几个项目中使用过,动作,卡牌,MOBA,MMO类都有,提供三四十种节点,基本上策划可以自己配置出一套很复杂的AI,当然还可以使用在技能系统之类的,需要更直观的逻辑表现的系统。这仅仅是一种思路,各位路过的大神,有啥建议或看法,欢迎Issue或者加群交流(Q群:644761605)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for behavior3lua
Similar Open Source Tools
behavior3lua
Behavior3Lua is a Lua framework for behavior trees in game AI. It provides a modified blackboard system where behavior trees are designed like code editors, allowing game designers to configure logic through editing trees. The framework offers various node types for creating complex AI behaviors, freeing game programmers from manual configuration. It includes composite, decorator, and action nodes, along with an API for creating and running behavior trees. The framework supports running states and provides an editor for visual tree editing. It has been successfully used in multiple projects for different game genres, enabling designers to create sophisticated AI and logic systems.

acte
Acte is a framework designed to build GUI-like tools for AI Agents. It aims to address the issues of cognitive load and freedom degrees when interacting with multiple APIs in complex scenarios. By providing a graphical user interface (GUI) for Agents, Acte helps reduce cognitive load and constraints interaction, similar to how humans interact with computers through GUIs. The tool offers APIs for starting new sessions, executing actions, and displaying screens, accessible via HTTP requests or the SessionManager class.
llm.nvim
llm.nvim is a plugin for Neovim that enables code completion using LLM models. It supports 'ghost-text' code completion similar to Copilot and allows users to choose their model for code generation via HTTP requests. The plugin interfaces with multiple backends like Hugging Face, Ollama, Open AI, and TGI, providing flexibility in model selection and configuration. Users can customize the behavior of suggestions, tokenization, and model parameters to enhance their coding experience. llm.nvim also includes commands for toggling auto-suggestions and manually requesting suggestions, making it a versatile tool for developers using Neovim.
connectonion
ConnectOnion is a simple, elegant open-source framework for production-ready AI agents. It provides a platform for creating and using AI agents with a focus on simplicity and efficiency. The framework allows users to easily add tools, debug agents, make them production-ready, and enable multi-agent capabilities. ConnectOnion offers a simple API, is production-ready with battle-tested models, and is open-source under the MIT license. It features a plugin system for adding reflection and reasoning capabilities, interactive debugging for easy troubleshooting, and no boilerplate code for seamless scaling from prototypes to production systems.
ai
The Vercel AI SDK is a library for building AI-powered streaming text and chat UIs. It provides React, Svelte, Vue, and Solid helpers for streaming text responses and building chat and completion UIs. The SDK also includes a React Server Components API for streaming Generative UI and first-class support for various AI providers such as OpenAI, Anthropic, Mistral, Perplexity, AWS Bedrock, Azure, Google Gemini, Hugging Face, Fireworks, Cohere, LangChain, Replicate, Ollama, and more. Additionally, it offers Node.js, Serverless, and Edge Runtime support, as well as lifecycle callbacks for saving completed streaming responses to a database in the same request.
z-ai-sdk-python
Z.ai Open Platform Python SDK is the official Python SDK for Z.ai's large model open interface, providing developers with easy access to Z.ai's open APIs. The SDK offers core features like chat completions, embeddings, video generation, audio processing, assistant API, and advanced tools. It supports various functionalities such as speech transcription, text-to-video generation, image understanding, and structured conversation handling. Developers can customize client behavior, configure API keys, and handle errors efficiently. The SDK is designed to simplify AI interactions and enhance AI capabilities for developers.
polyfire-js
Polyfire is an all-in-one managed backend for AI apps that allows users to build AI apps directly from the frontend, eliminating the need for a separate backend. It simplifies the process by providing most backend services in just a few lines of code. With Polyfire, users can easily create chatbots, transcribe audio files to text, generate simple text, create a long-term memory, and generate images with Dall-E. The tool also offers starter guides and tutorials to help users get started quickly and efficiently.
OpenMemory
OpenMemory is a cognitive memory engine for AI agents, providing real long-term memory capabilities beyond simple embeddings. It is self-hosted and supports Python + Node SDKs, with integrations for various tools like LangChain, CrewAI, AutoGen, and more. Users can ingest data from sources like GitHub, Notion, Google Drive, and others directly into memory. OpenMemory offers explainable traces for recalled information and supports multi-sector memory, temporal reasoning, decay engine, waypoint graph, and more. It aims to provide a true memory system rather than just a vector database with marketing copy, enabling users to build agents, copilots, journaling systems, and coding assistants that can remember and reason effectively.
flyte-sdk
Flyte 2 SDK is a pure Python tool for type-safe, distributed orchestration of agents, ML pipelines, and more. It allows users to write data pipelines, ML training jobs, and distributed compute in Python without any DSL constraints. With features like async-first parallelism and fine-grained observability, Flyte 2 offers a seamless workflow experience. Users can leverage core concepts like TaskEnvironments for container configuration, pure Python workflows for flexibility, and async parallelism for distributed execution. Advanced features include sub-task observability with tracing and remote task execution. The tool also provides native Jupyter integration for running and monitoring workflows directly from notebooks. Configuration and deployment are made easy with configuration files and commands for deploying and running workflows. Flyte 2 is licensed under the Apache 2.0 License.
Groq2API
Groq2API is a REST API wrapper around the Groq2 model, a large language model trained by Google. The API allows you to send text prompts to the model and receive generated text responses. The API is easy to use and can be integrated into a variety of applications.

LLMVoX
LLMVoX is a lightweight 30M-parameter, LLM-agnostic, autoregressive streaming Text-to-Speech (TTS) system designed to convert text outputs from Large Language Models into high-fidelity streaming speech with low latency. It achieves significantly lower Word Error Rate compared to speech-enabled LLMs while operating at comparable latency and speech quality. Key features include being lightweight & fast with only 30M parameters, LLM-agnostic for easy integration with existing models, multi-queue streaming for continuous speech generation, and multilingual support for easy adaptation to new languages.
daytona
Daytona is a secure and elastic infrastructure tool designed for running AI-generated code. It offers lightning-fast infrastructure with sub-90ms sandbox creation, separated and isolated runtime for executing AI code with zero risk, massive parallelization for concurrent AI workflows, programmatic control through various APIs, unlimited sandbox persistence, and OCI/Docker compatibility. Users can create sandboxes using Python or TypeScript SDKs, run code securely inside the sandbox, and clean up the sandbox after execution. Daytona is open source under the GNU Affero General Public License and welcomes contributions from developers.
flutter_gen_ai_chat_ui
A modern, high-performance Flutter chat UI kit for building beautiful messaging interfaces. Features streaming text animations, markdown support, file attachments, and extensive customization options. Perfect for AI assistants, customer support, team chat, social messaging, and any conversational application. Production Ready, Cross-Platform, High Performance, Fully Customizable. Core features include dark/light mode, word-by-word streaming with animations, enhanced markdown support, speech-to-text integration, responsive layout, RTL language support, high performance message handling, improved pagination support. AI-specific features include customizable welcome message, example questions component, persistent example questions, AI typing indicators, streaming markdown rendering. New AI Actions System with function calling support, generative UI, human-in-the-loop confirmation dialogs, real-time status updates, type-safe parameters, event streaming, error handling. UI components include customizable message bubbles, custom bubble builder, multiple input field styles, loading indicators, smart scroll management, enhanced theme customization, better code block styling.
ck
ck (seek) is a semantic grep tool that finds code by meaning, not just keywords. It replaces traditional grep by understanding the user's search intent. It allows users to search for code based on concepts like 'error handling' and retrieves relevant code even if the exact keywords are not present. ck offers semantic search, drop-in grep compatibility, hybrid search combining keyword precision with semantic understanding, agent-friendly output in JSONL format, smart file filtering, and various advanced features. It supports multiple search modes, relevance scoring, top-K results, and smart exclusions. Users can index projects for semantic search, choose embedding models, and search specific files or directories. The tool is designed to improve code search efficiency and accuracy for developers and AI agents.
ai-counsel
AI Counsel is a true deliberative consensus MCP server where AI models engage in actual debate, refine positions across multiple rounds, and converge with voting and confidence levels. It features two modes (quick and conference), mixed adapters (CLI tools and HTTP services), auto-convergence, structured voting, semantic grouping, model-controlled stopping, evidence-based deliberation, local model support, data privacy, context injection, semantic search, fault tolerance, and full transcripts. Users can run local and cloud models to deliberate on various questions, ground decisions in reality by querying code and files, and query past decisions for analysis. The tool is designed for critical technical decisions requiring multi-model deliberation and consensus building.
aio-scrapy
Aio-scrapy is an asyncio-based web crawling and web scraping framework inspired by Scrapy. It supports distributed crawling/scraping, implements compatibility with scrapyd, and provides options for using redis queue and rabbitmq queue. The framework is designed for fast extraction of structured data from websites. Aio-scrapy requires Python 3.9+ and is compatible with Linux, Windows, macOS, and BSD systems.
For similar tasks
behavior3lua
Behavior3Lua is a Lua framework for behavior trees in game AI. It provides a modified blackboard system where behavior trees are designed like code editors, allowing game designers to configure logic through editing trees. The framework offers various node types for creating complex AI behaviors, freeing game programmers from manual configuration. It includes composite, decorator, and action nodes, along with an API for creating and running behavior trees. The framework supports running states and provides an editor for visual tree editing. It has been successfully used in multiple projects for different game genres, enabling designers to create sophisticated AI and logic systems.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.