
Complete-LLM-Finetuning
None
Stars: 54
Complete-LLM-Finetuning is a tool designed for fine-tuning large language models for various natural language processing tasks. It provides a comprehensive guide and resources for users to effectively fine-tune language models for specific applications. The tool aims to simplify the process of adapting pre-trained language models to new tasks by offering step-by-step instructions and best practices. Users can leverage the tool to enhance the performance of language models on specific datasets and tasks, enabling them to achieve better results in natural language processing projects.
README:
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Complete-LLM-Finetuning
Similar Open Source Tools
Complete-LLM-Finetuning
Complete-LLM-Finetuning is a tool designed for fine-tuning large language models for various natural language processing tasks. It provides a comprehensive guide and resources for users to effectively fine-tune language models for specific applications. The tool aims to simplify the process of adapting pre-trained language models to new tasks by offering step-by-step instructions and best practices. Users can leverage the tool to enhance the performance of language models on specific datasets and tasks, enabling them to achieve better results in natural language processing projects.

LLMs-playground
LLMs-playground is a repository containing code examples and tutorials for learning and experimenting with Large Language Models (LLMs). It provides a hands-on approach to understanding how LLMs work and how to fine-tune them for specific tasks. The repository covers various LLM architectures, pre-training techniques, and fine-tuning strategies, making it a valuable resource for researchers, students, and practitioners interested in natural language processing and machine learning. By exploring the code and following the tutorials, users can gain practical insights into working with LLMs and apply their knowledge to real-world projects.

DelhiLM
DelhiLM is a natural language processing tool for building and training language models. It provides a user-friendly interface for text processing tasks such as tokenization, lemmatization, and language model training. With DelhiLM, users can easily preprocess text data and train custom language models for various NLP applications. The tool supports different languages and allows for fine-tuning pre-trained models to suit specific needs. DelhiLM is designed to be flexible, efficient, and easy to use for both beginners and experienced NLP practitioners.

PaddleNLP
PaddleNLP is an easy-to-use and high-performance NLP library. It aggregates high-quality pre-trained models in the industry and provides out-of-the-box development experience, covering a model library for multiple NLP scenarios with industry practice examples to meet developers' flexible customization needs.
FastGPT
FastGPT is a knowledge base Q&A system based on the LLM large language model, providing out-of-the-box data processing, model calling and other capabilities. At the same time, you can use Flow to visually arrange workflows to achieve complex Q&A scenarios!

lemonai
LemonAI is a versatile machine learning library designed to simplify the process of building and deploying AI models. It provides a wide range of tools and algorithms for data preprocessing, model training, and evaluation. With LemonAI, users can easily experiment with different machine learning techniques and optimize their models for various tasks. The library is well-documented and beginner-friendly, making it suitable for both novice and experienced data scientists. LemonAI aims to streamline the development of AI applications and empower users to create innovative solutions using state-of-the-art machine learning methods.
LLM-Project
LLM-Project is a machine learning model for sentiment analysis. It is designed to analyze text data and classify it into positive, negative, or neutral sentiments. The model uses natural language processing techniques to extract features from the text and train a classifier to make predictions. LLM-Project is suitable for researchers, developers, and data scientists who are working on sentiment analysis tasks. It provides a pre-trained model that can be easily integrated into existing projects or used for experimentation and research purposes. The codebase is well-documented and easy to understand, making it accessible to users with varying levels of expertise in machine learning and natural language processing.
build-your-own-x-machine-learning
This repository provides a step-by-step guide for building your own machine learning models from scratch. It covers various machine learning algorithms and techniques, including linear regression, logistic regression, decision trees, and neural networks. The code examples are written in Python and include detailed explanations to help beginners understand the concepts behind machine learning. By following the tutorials in this repository, you can gain a deeper understanding of how machine learning works and develop your own models for different applications.
FastFlowLM
FastFlowLM is a Python library for efficient and scalable language model inference. It provides a high-performance implementation of language model scoring using n-gram language models. The library is designed to handle large-scale text data and can be easily integrated into natural language processing pipelines for tasks such as text generation, speech recognition, and machine translation. FastFlowLM is optimized for speed and memory efficiency, making it suitable for both research and production environments.
eval-assist
EvalAssist is an LLM-as-a-Judge framework built on top of the Unitxt open source evaluation library for large language models. It provides users with a convenient way of iteratively testing and refining LLM-as-a-judge criteria, supporting both direct (rubric-based) and pairwise assessment paradigms. EvalAssist is model-agnostic, supporting a rich set of off-the-shelf judge models that can be extended. Users can auto-generate a Notebook with Unitxt code to run bulk evaluations and save their own test cases. The tool is designed for evaluating text data using language models.
oreilly-llm-rl-alignment
This repository contains Jupyter notebooks for the courses 'Aligning Large Language Models' and 'Reinforcement Learning with Large Language Models' by Sinan Ozdemir. It covers effective best practices and industry case studies in using Large Language Models (LLMs). The courses provide in-depth exploration of alignment techniques, evaluation methods, ethical considerations, and reinforcement learning concepts with practical applications. Participants will gain theoretical insights and hands-on experience in working with LLMs, including fine-tuning models and understanding advanced concepts like RLHF, RLAIF, and Constitutional AI.
ai-workshop-code
The ai-workshop-code repository contains code examples and tutorials for various artificial intelligence concepts and algorithms. It serves as a practical resource for individuals looking to learn and implement AI techniques in their projects. The repository covers a wide range of topics, including machine learning, deep learning, natural language processing, computer vision, and reinforcement learning. By exploring the code and following the tutorials, users can gain hands-on experience with AI technologies and enhance their understanding of how these algorithms work in practice.
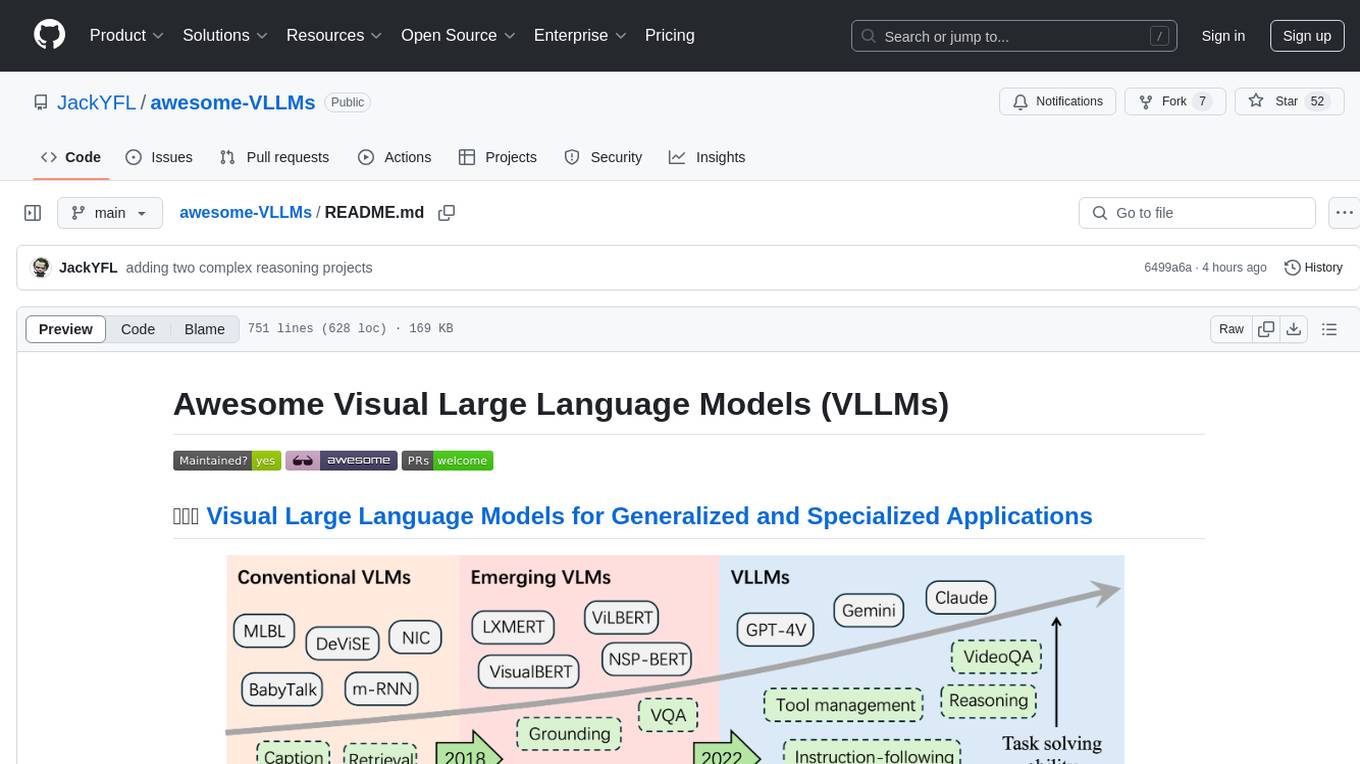
awesome-VLLMs
This repository contains a collection of pre-trained Very Large Language Models (VLLMs) that can be used for various natural language processing tasks. The models are fine-tuned on large text corpora and can be easily integrated into existing NLP pipelines for tasks such as text generation, sentiment analysis, and language translation. The repository also provides code examples and tutorials to help users get started with using these powerful language models in their projects.

awesome-generative-ai-guide
This repository serves as a comprehensive hub for updates on generative AI research, interview materials, notebooks, and more. It includes monthly best GenAI papers list, interview resources, free courses, and code repositories/notebooks for developing generative AI applications. The repository is regularly updated with the latest additions to keep users informed and engaged in the field of generative AI.
openssa
OpenSSA is an open-source framework for creating efficient, domain-specific AI agents. It enables the development of Small Specialist Agents (SSAs) that solve complex problems in specific domains. SSAs tackle multi-step problems that require planning and reasoning beyond traditional language models. They apply OODA for deliberative reasoning (OODAR) and iterative, hierarchical task planning (HTP). This "System-2 Intelligence" breaks down complex tasks into manageable steps. SSAs make informed decisions based on domain-specific knowledge. With OpenSSA, users can create agents that process, generate, and reason about information, making them more effective and efficient in solving real-world challenges.

RecAI
RecAI is a project that explores the integration of Large Language Models (LLMs) into recommender systems, addressing the challenges of interactivity, explainability, and controllability. It aims to bridge the gap between general-purpose LLMs and domain-specific recommender systems, providing a holistic perspective on the practical requirements of LLM4Rec. The project investigates various techniques, including Recommender AI agents, selective knowledge injection, fine-tuning language models, evaluation, and LLMs as model explainers, to create more sophisticated, interactive, and user-centric recommender systems.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.