
LLMs-playground
What, Why and How of LLMs.
Stars: 74

LLMs-playground is a repository containing code examples and tutorials for learning and experimenting with Large Language Models (LLMs). It provides a hands-on approach to understanding how LLMs work and how to fine-tune them for specific tasks. The repository covers various LLM architectures, pre-training techniques, and fine-tuning strategies, making it a valuable resource for researchers, students, and practitioners interested in natural language processing and machine learning. By exploring the code and following the tutorials, users can gain practical insights into working with LLMs and apply their knowledge to real-world projects.
README:
| Title | Medium Article | Repository |
|---|---|---|
| Comprehensive Guide to Customize your Llama2 ChatBot using LlamaIndex and Streamlit | 🔗 | 🔗 |
| Mistral-7B-Instruct Based Multi-PDFs ChatBot using LangChain and Streamlit | 🔗 | |
| Llama2-7B Based CSV ChatBot using LangChain | 🔗 | |
| Simple RAG using AWS Bedrock | 🔗 |
| Title | Medium Article | Repository |
|---|---|---|
| Optimizing Retrieval with Additional Context & MetaData using LlamaIndex🦙 | 🔗 | 🔗 |
| Enhancing Retrieval Efficiency through Evaluating Reranker Models using LlamaIndex🦙 | 🔗 | 🔗 |
| Query Augmentation for Next-Level Search using LlamaIndex🦙 | 🔗 | 🔗 |
| Smart Tracking and Debugging of Document Changes using LlamaIndex🦙 | 🔗 | 🔗 |
| Title | Medium Article | Repository |
|---|---|---|
| Elevating Mistral-7B’s Performance through Finetuning using QLoRA | 🔗 | 🔗 |
| T5 Fine Tuning & Evaluation for Text Summarization | 🔗 | |
| Falcon-7B Based Video 🎬 Summarization using Langchain | 🔗 | |
| 🎵 Audio Generation 🎹 using Audio Craft | 🔗 |
| Title | Medium Article | Repository |
|---|---|---|
| Serverless Magic with Lambda, SageMaker DLC, and API Gateway | 🔗 | 🔗 |
| Deploy a Serverless ML Inference using FastAPI, AWS Lambda, and API Gateway | 🔗 | 🔗 |
| Vector Indexing and ANN using FAISS with AWS Serverless Architecture | 🔗 | 🔗 |
| Title | Medium Article | Repository |
|---|---|---|
| Quickstart with LangChain | 🔗 | |
| Summarization Strategies | 🔗 |
Feel free to explore the repository and show your appreciation by giving it a star⭐! Your support means a lot! 😉
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLMs-playground
Similar Open Source Tools
LLMs-playground
LLMs-playground is a repository containing code examples and tutorials for learning and experimenting with Large Language Models (LLMs). It provides a hands-on approach to understanding how LLMs work and how to fine-tune them for specific tasks. The repository covers various LLM architectures, pre-training techniques, and fine-tuning strategies, making it a valuable resource for researchers, students, and practitioners interested in natural language processing and machine learning. By exploring the code and following the tutorials, users can gain practical insights into working with LLMs and apply their knowledge to real-world projects.
ai-workshop-code
The ai-workshop-code repository contains code examples and tutorials for various artificial intelligence concepts and algorithms. It serves as a practical resource for individuals looking to learn and implement AI techniques in their projects. The repository covers a wide range of topics, including machine learning, deep learning, natural language processing, computer vision, and reinforcement learning. By exploring the code and following the tutorials, users can gain hands-on experience with AI technologies and enhance their understanding of how these algorithms work in practice.
awesome-LLM-resources
This repository is a curated list of resources for learning and working with Large Language Models (LLMs). It includes a collection of articles, tutorials, tools, datasets, and research papers related to LLMs such as GPT-3, BERT, and Transformer models. Whether you are a researcher, developer, or enthusiast interested in natural language processing and artificial intelligence, this repository provides valuable resources to help you understand, implement, and experiment with LLMs.
build-your-own-x-machine-learning
This repository provides a step-by-step guide for building your own machine learning models from scratch. It covers various machine learning algorithms and techniques, including linear regression, logistic regression, decision trees, and neural networks. The code examples are written in Python and include detailed explanations to help beginners understand the concepts behind machine learning. By following the tutorials in this repository, you can gain a deeper understanding of how machine learning works and develop your own models for different applications.
LLM-Workshop
This repository contains a collection of resources for learning about and using Large Language Models (LLMs). The resources include tutorials, code examples, and links to additional resources. LLMs are a type of artificial intelligence that can understand and generate human-like text. They have a wide range of potential applications, including natural language processing, machine translation, and chatbot development.
intro-llm.github.io
Large Language Models (LLM) are language models built by deep neural networks containing hundreds of billions of weights, trained on a large amount of unlabeled text using self-supervised learning methods. Since 2018, companies and research institutions including Google, OpenAI, Meta, Baidu, and Huawei have released various models such as BERT, GPT, etc., which have performed well in almost all natural language processing tasks. Starting in 2021, large models have shown explosive growth, especially after the release of ChatGPT in November 2022, attracting worldwide attention. Users can interact with systems using natural language to achieve various tasks from understanding to generation, including question answering, classification, summarization, translation, and chat. Large language models demonstrate powerful knowledge of the world and understanding of language. This repository introduces the basic theory of large language models including language models, distributed model training, and reinforcement learning, and uses the Deepspeed-Chat framework as an example to introduce the implementation of large language models and ChatGPT-like systems.
cs-self-learning
This repository serves as an archive for computer science learning notes, codes, and materials. It covers a wide range of topics including basic knowledge, AI, backend & big data, tools, and other related areas. The content is organized into sections and subsections for easy navigation and reference. Users can find learning resources, programming practices, and tutorials on various subjects such as languages, data structures & algorithms, AI, frameworks, databases, development tools, and more. The repository aims to support self-learning and skill development in the field of computer science.
Mastering-NLP-from-Foundations-to-LLMs
This code repository is for the book 'Mastering NLP from Foundations to LLMs', which provides an in-depth introduction to Natural Language Processing (NLP) techniques. It covers mathematical foundations of machine learning, advanced NLP applications such as large language models (LLMs) and AI applications, as well as practical skills for working on real-world NLP business problems. The book includes Python code samples and expert insights into current and future trends in NLP.
rag-in-action
rag-in-action is a GitHub repository that provides a practical course structure for developing a RAG system based on DeepSeek. The repository likely contains resources, code samples, and tutorials to guide users through the process of building and implementing a RAG system using DeepSeek technology. Users interested in learning about RAG systems and their development may find this repository helpful in gaining hands-on experience and practical knowledge in this area.
Generative-AI-Indepth-Basic-to-Advance
Generative AI Indepth Basic to Advance is a repository focused on providing tutorials and resources related to generative artificial intelligence. The repository covers a wide range of topics from basic concepts to advanced techniques in the field of generative AI. Users can find detailed explanations, code examples, and practical demonstrations to help them understand and implement generative AI algorithms. The goal of this repository is to help beginners get started with generative AI and to provide valuable insights for more experienced practitioners.

lemonai
LemonAI is a versatile machine learning library designed to simplify the process of building and deploying AI models. It provides a wide range of tools and algorithms for data preprocessing, model training, and evaluation. With LemonAI, users can easily experiment with different machine learning techniques and optimize their models for various tasks. The library is well-documented and beginner-friendly, making it suitable for both novice and experienced data scientists. LemonAI aims to streamline the development of AI applications and empower users to create innovative solutions using state-of-the-art machine learning methods.

PaddleNLP
PaddleNLP is an easy-to-use and high-performance NLP library. It aggregates high-quality pre-trained models in the industry and provides out-of-the-box development experience, covering a model library for multiple NLP scenarios with industry practice examples to meet developers' flexible customization needs.

ai
This repository contains a collection of AI algorithms and models for various machine learning tasks. It provides implementations of popular algorithms such as neural networks, decision trees, and support vector machines. The code is well-documented and easy to understand, making it suitable for both beginners and experienced developers. The repository also includes example datasets and tutorials to help users get started with building and training AI models. Whether you are a student learning about AI or a professional working on machine learning projects, this repository can be a valuable resource for your development journey.

God-Level-AI
A drill of scientific methods, processes, algorithms, and systems to build stories & models. An in-depth learning resource for humans. This repository is designed for individuals aiming to excel in the field of Data and AI, providing video sessions and text content for learning. It caters to those in leadership positions, professionals, and students, emphasizing the need for dedicated effort to achieve excellence in the tech field. The content covers various topics with a focus on practical application.
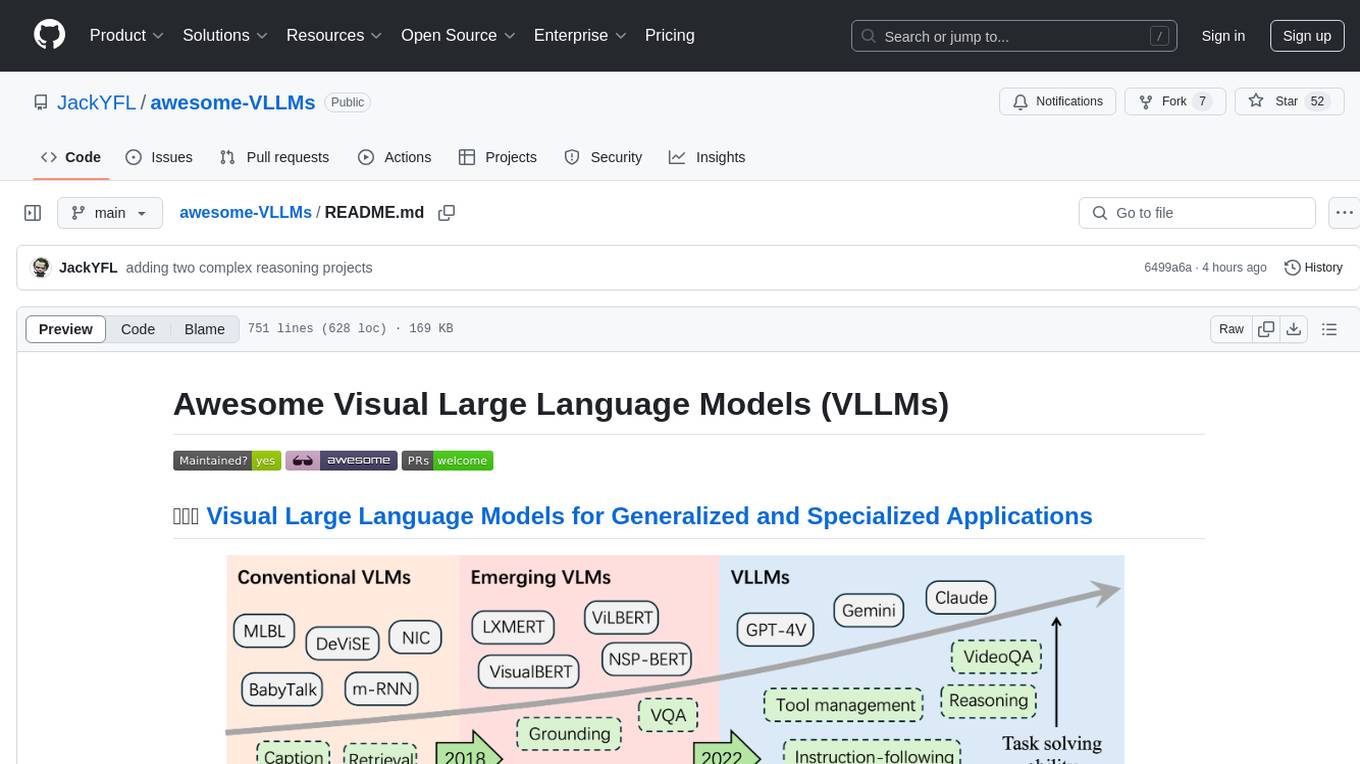
awesome-VLLMs
This repository contains a collection of pre-trained Very Large Language Models (VLLMs) that can be used for various natural language processing tasks. The models are fine-tuned on large text corpora and can be easily integrated into existing NLP pipelines for tasks such as text generation, sentiment analysis, and language translation. The repository also provides code examples and tutorials to help users get started with using these powerful language models in their projects.

oreilly-hands-on-gpt-llm
This repository contains code for the O'Reilly Live Online Training for Deploying GPT & LLMs. Learn how to use GPT-4, ChatGPT, OpenAI embeddings, and other large language models to build applications for experimenting and production. Gain practical experience in building applications like text generation, summarization, question answering, and more. Explore alternative generative models such as Cohere and GPT-J. Understand prompt engineering, context stuffing, and few-shot learning to maximize the potential of GPT-like models. Focus on deploying models in production with best practices and debugging techniques. By the end of the training, you will have the skills to start building applications with GPT and other large language models.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.
LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.