
tetris-ai
A deep reinforcement learning bot that plays tetris
Stars: 256
A bot that plays Tetris using deep reinforcement learning. The agent learns to play by training itself with a neural network and Q Learning algorithm. It explores different 'paths' to achieve higher scores and makes decisions based on predicted scores for possible moves. The game state includes attributes like lines cleared, holes, bumpiness, and total height. The agent is implemented in Python using Keras framework with a deep neural network structure. Training involves a replay queue, random sampling, and optimization techniques. Results show the agent's progress in achieving higher scores over episodes.
README:
A bot that plays Tetris using deep reinforcement learning.
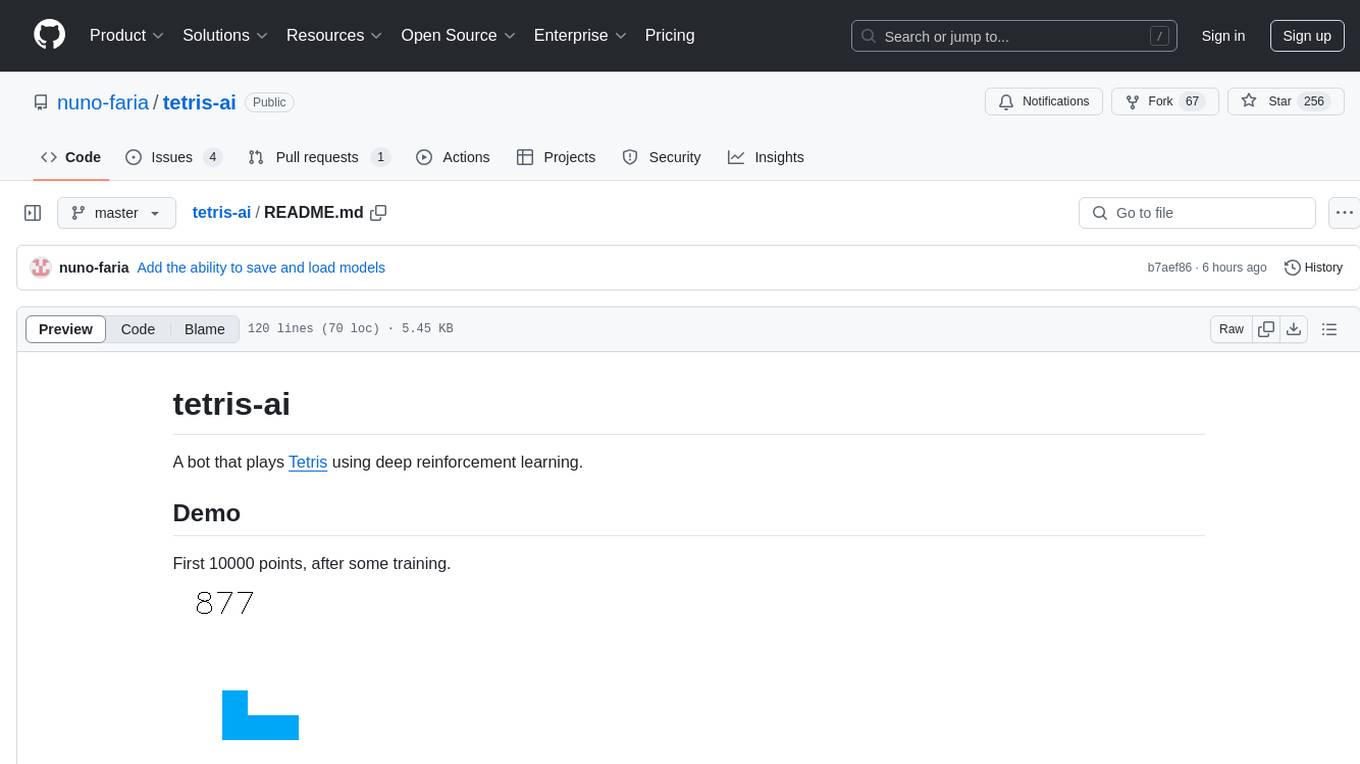
First 10000 points, after some training.

- Tensorflow/Jax/PyTorch
- Tensorboard
- Keras
- Opencv-python
- Numpy
- Pillow
- Tqdm
The original tests were evaluated using Keras with Tensorflow as the backend. However, new tests (keras==3.5.0) using Jax (jax[cuda12]) as the backend appear to result in faster training/predict operations (e.g., KERAS_BACKEND="jax" python3 run.py).
- Train/execute:
# hyper parameters can be changed in the run.py script
python3 run.py- View logs with
tensorboard:
tensorboard --logdir ./logs- Play a game with an existing model (
sample.kerasis a previously trained model that achieved more than 800k points, using 3 Relu layers with 32 neurons each):
python3 run_model.py sample.kerasAt first, the agent will play random moves, saving the states and the given reward in a limited queue (replay memory). At the end of each episode (game), the agent will train itself (using a neural network) with a random sample of the replay memory. As more and more games are played, the agent becomes smarter, achieving higher and higher scores.
Since in reinforcement learning once an agent discovers a good 'path' it will stick with it, it was also considered an exploration variable (that decreases over time), so that the agent picks sometimes a random action instead of the one it considers the best. This way, it can discover new 'paths' to achieve higher scores.
The training is based on the Q Learning algorithm. Instead of using just the current state and reward obtained to train the network, it is used Q Learning (that considers the transition from the current state to the future one) to find out what is the best possible score of all the given states considering the future rewards, i.e., the algorithm is not greedy. This allows for the agent to take some moves that might not give an immediate reward, so it can get a bigger one later on (e.g. waiting to clear multiple lines instead of a single one).
The neural network will be updated with the given data (considering a play with reward reward that moves from state to next_state, the latter having an expected value of Q_next_state, found using the prediction from the neural network):
if not terminal state (last round): Q_state = reward + discount × Q_next_state else: Q_state = reward
Most of the deep Q Learning strategies used output a vector of values for a certain state. Each position of the vector maps to some action (ex: left, right, ...), and the position with the higher value is selected.
However, the strategy implemented was slightly different. For some round of Tetris, the states for all the possible moves will be collected. Each state will be inserted in the neural network, to predict the score obtained. The action whose state outputs the biggest value will be played.
It was considered several attributes to train the network. Since there were many, after several tests, a conclusion was reached that only the first four present were necessary to train:
- Number of lines cleared
- Number of holes
- Bumpiness (sum of the difference between heights of adjacent pairs of columns)
- Total Height
- Max height
- Min height
- Max bumpiness
- Next piece
- Current piece
Each block placed yields 1 point. When clearing lines, the given score is $number_lines_cleared^2 \times board_width$. Losing a game subtracts 1 point.
The code was implemented using Python. For the neural network, it was used the framework Keras.
The agent is formed by a deep neural network, with variable number of layers, neurons per layer, activation functions, loss function, optimizer, etc. It was chosen a neural network with 2 hidden layers (32 neurons each); the activations ReLu for the inner layers and the Linear for the last one; Mean Squared Error as the loss function; Adam as the optimizer; Epsilon (exploration) starting at 1 and ending at 0, when the number of episodes reaches 75%; Discount at 0.95 (significance given to the future rewards, instead of the immediate ones).
For the training, the replay queue had size 20000, with a random sample of 512 selected for training each episode, using 1 epoch.
For 2000 episodes, with epsilon ending at 1500, the agent kept going for too long around episode 1460, so it had to be terminated. Here is a chart with the maximum score every 50 episodes, until episode 1450:

Note: Decreasing the epsilon_end_episode could make the agent achieve better results in a smaller number of episodes.
- PythonProgramming - https://pythonprogramming.net/q-learning-reinforcement-learning-python-tutorial/
- Keon - https://keon.io/deep-q-learning/
- Towards Data Science - https://towardsdatascience.com/self-learning-ai-agents-part-ii-deep-q-learning-b5ac60c3f47
- Code My Road - https://codemyroad.wordpress.com/2013/04/14/tetris-ai-the-near-perfect-player/ (uses evolutionary strategies)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for tetris-ai
Similar Open Source Tools
tetris-ai
A bot that plays Tetris using deep reinforcement learning. The agent learns to play by training itself with a neural network and Q Learning algorithm. It explores different 'paths' to achieve higher scores and makes decisions based on predicted scores for possible moves. The game state includes attributes like lines cleared, holes, bumpiness, and total height. The agent is implemented in Python using Keras framework with a deep neural network structure. Training involves a replay queue, random sampling, and optimization techniques. Results show the agent's progress in achieving higher scores over episodes.
SciMLBenchmarks.jl
SciMLBenchmarks.jl holds webpages, pdfs, and notebooks showing the benchmarks for the SciML Scientific Machine Learning Software ecosystem, including: * Benchmarks of equation solver implementations * Speed and robustness comparisons of methods for parameter estimation / inverse problems * Training universal differential equations (and subsets like neural ODEs) * Training of physics-informed neural networks (PINNs) * Surrogate comparisons, including radial basis functions, neural operators (DeepONets, Fourier Neural Operators), and more The SciML Bench suite is made to be a comprehensive open source benchmark from the ground up, covering the methods of computational science and scientific computing all the way to AI for science.

llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.
ChatAFL
ChatAFL is a protocol fuzzer guided by large language models (LLMs) that extracts machine-readable grammar for protocol mutation, increases message diversity, and breaks coverage plateaus. It integrates with ProfuzzBench for stateful fuzzing of network protocols, providing smooth integration. The artifact includes modified versions of AFLNet and ProfuzzBench, source code for ChatAFL with proposed strategies, and scripts for setup, execution, analysis, and cleanup. Users can analyze data, construct plots, examine LLM-generated grammars, enriched seeds, and state-stall responses, and reproduce results with downsized experiments. Customization options include modifying fuzzers, tuning parameters, adding new subjects, troubleshooting, and working on GPT-4. Limitations include interaction with OpenAI's Large Language Models and a hard limit of 150,000 tokens per minute.
audioseal
AudioSeal is a method for speech localized watermarking, designed with state-of-the-art robustness and detector speed. It jointly trains a generator to embed a watermark in audio and a detector to detect watermarked fragments in longer audios, even in the presence of editing. The tool achieves top-notch detection performance at the sample level, generates minimal alteration of signal quality, and is robust to various audio editing types. With a fast, single-pass detector, AudioSeal surpasses existing models in speed, making it ideal for large-scale and real-time applications.

uncheatable_eval
Uncheatable Eval is a tool designed to assess the language modeling capabilities of LLMs on real-time, newly generated data from the internet. It aims to provide a reliable evaluation method that is immune to data leaks and cannot be gamed. The tool supports the evaluation of Hugging Face AutoModelForCausalLM models and RWKV models by calculating the sum of negative log probabilities on new texts from various sources such as recent papers on arXiv, new projects on GitHub, news articles, and more. Uncheatable Eval ensures that the evaluation data is not included in the training sets of publicly released models, thus offering a fair assessment of the models' performance.

CoLLM
CoLLM is a novel method that integrates collaborative information into Large Language Models (LLMs) for recommendation. It converts recommendation data into language prompts, encodes them with both textual and collaborative information, and uses a two-step tuning method to train the model. The method incorporates user/item ID fields in prompts and employs a conventional collaborative model to generate user/item representations. CoLLM is built upon MiniGPT-4 and utilizes pretrained Vicuna weights for training.

MegatronApp
MegatronApp is a toolchain built around the Megatron-LM training framework, offering performance tuning, slow-node detection, and training-process visualization. It includes modules like MegaScan for anomaly detection, MegaFBD for forward-backward decoupling, MegaDPP for dynamic pipeline planning, and MegaScope for visualization. The tool aims to enhance large-scale distributed training by providing valuable capabilities and insights.
Graph-CoT
This repository contains the source code and datasets for Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs accepted to ACL 2024. It proposes a framework called Graph Chain-of-thought (Graph-CoT) to enable Language Models to traverse graphs step-by-step for reasoning, interaction, and execution. The motivation is to alleviate hallucination issues in Language Models by augmenting them with structured knowledge sources represented as graphs.
gptauthor
GPT Author is a command-line tool designed to help users write long form, multi-chapter stories by providing a story prompt and generating a synopsis and subsequent chapters using ChatGPT. Users can review and make changes to the generated content before finalizing the story output in Markdown and HTML formats. The tool aims to unleash storytelling genius by combining human input with AI-generated content, offering a seamless writing experience for creating engaging narratives.
llm-adaptive-attacks
This repository contains code and results for jailbreaking leading safety-aligned LLMs with simple adaptive attacks. We show that even the most recent safety-aligned LLMs are not robust to simple adaptive jailbreaking attacks. We demonstrate how to successfully leverage access to logprobs for jailbreaking: we initially design an adversarial prompt template (sometimes adapted to the target LLM), and then we apply random search on a suffix to maximize the target logprob (e.g., of the token ``Sure''), potentially with multiple restarts. In this way, we achieve nearly 100% attack success rate---according to GPT-4 as a judge---on GPT-3.5/4, Llama-2-Chat-7B/13B/70B, Gemma-7B, and R2D2 from HarmBench that was adversarially trained against the GCG attack. We also show how to jailbreak all Claude models---that do not expose logprobs---via either a transfer or prefilling attack with 100% success rate. In addition, we show how to use random search on a restricted set of tokens for finding trojan strings in poisoned models---a task that shares many similarities with jailbreaking---which is the algorithm that brought us the first place in the SaTML'24 Trojan Detection Competition. The common theme behind these attacks is that adaptivity is crucial: different models are vulnerable to different prompting templates (e.g., R2D2 is very sensitive to in-context learning prompts), some models have unique vulnerabilities based on their APIs (e.g., prefilling for Claude), and in some settings it is crucial to restrict the token search space based on prior knowledge (e.g., for trojan detection).

blades
Blades is a multimodal AI Agent framework in Go, supporting custom models, tools, memory, middleware, and more. It is well-suited for multi-turn conversations, chain reasoning, and structured output. The framework provides core components like Agent, Prompt, Chain, ModelProvider, Tool, Memory, and Middleware, enabling developers to build intelligent applications with flexible configuration and high extensibility. Blades leverages the characteristics of Go to achieve high decoupling and efficiency, making it easy to integrate different language model services and external tools. The project is in its early stages, inviting Go developers and AI enthusiasts to contribute and explore the possibilities of building AI applications in Go.

minbpe
This repository contains a minimal, clean code implementation of the Byte Pair Encoding (BPE) algorithm, commonly used in LLM tokenization. The BPE algorithm is "byte-level" because it runs on UTF-8 encoded strings. This algorithm was popularized for LLMs by the GPT-2 paper and the associated GPT-2 code release from OpenAI. Sennrich et al. 2015 is cited as the original reference for the use of BPE in NLP applications. Today, all modern LLMs (e.g. GPT, Llama, Mistral) use this algorithm to train their tokenizers. There are two Tokenizers in this repository, both of which can perform the 3 primary functions of a Tokenizer: 1) train the tokenizer vocabulary and merges on a given text, 2) encode from text to tokens, 3) decode from tokens to text. The files of the repo are as follows: 1. minbpe/base.py: Implements the `Tokenizer` class, which is the base class. It contains the `train`, `encode`, and `decode` stubs, save/load functionality, and there are also a few common utility functions. This class is not meant to be used directly, but rather to be inherited from. 2. minbpe/basic.py: Implements the `BasicTokenizer`, the simplest implementation of the BPE algorithm that runs directly on text. 3. minbpe/regex.py: Implements the `RegexTokenizer` that further splits the input text by a regex pattern, which is a preprocessing stage that splits up the input text by categories (think: letters, numbers, punctuation) before tokenization. This ensures that no merges will happen across category boundaries. This was introduced in the GPT-2 paper and continues to be in use as of GPT-4. This class also handles special tokens, if any. 4. minbpe/gpt4.py: Implements the `GPT4Tokenizer`. This class is a light wrapper around the `RegexTokenizer` (2, above) that exactly reproduces the tokenization of GPT-4 in the tiktoken library. The wrapping handles some details around recovering the exact merges in the tokenizer, and the handling of some unfortunate (and likely historical?) 1-byte token permutations. Finally, the script train.py trains the two major tokenizers on the input text tests/taylorswift.txt (this is the Wikipedia entry for her kek) and saves the vocab to disk for visualization. This script runs in about 25 seconds on my (M1) MacBook. All of the files above are very short and thoroughly commented, and also contain a usage example on the bottom of the file.

aligner
Aligner is a model-agnostic alignment tool designed to efficiently correct responses from large language models. It redistributes initial answers to align with human intentions, improving performance across various LLMs. The tool can be applied with minimal training, enhancing upstream models and reducing hallucination. Aligner's 'copy and correct' method preserves the base structure while enhancing responses. It achieves significant performance improvements in helpfulness, harmlessness, and honesty dimensions, with notable success in boosting Win Rates on evaluation leaderboards.
blurt
Blurt is a Gnome shell extension that enables accurate speech-to-text input in Linux. It is based on the command line utility NoteWhispers and supports Gnome shell version 48. Users can transcribe speech using a local whisper.cpp installation or a whisper.cpp server. The extension allows for easy setup, start/stop of speech-to-text input with key bindings or icon click, and provides visual indicators during operation. It offers convenience by enabling speech input into any window that allows text input, with the transcribed text sent to the clipboard for easy pasting.

LLMeBench
LLMeBench is a flexible framework designed for accelerating benchmarking of Large Language Models (LLMs) in the field of Natural Language Processing (NLP). It supports evaluation of various NLP tasks using model providers like OpenAI, HuggingFace Inference API, and Petals. The framework is customizable for different NLP tasks, LLM models, and datasets across multiple languages. It features extensive caching capabilities, supports zero- and few-shot learning paradigms, and allows on-the-fly dataset download and caching. LLMeBench is open-source and continuously expanding to support new models accessible through APIs.
For similar tasks
tetris-ai
A bot that plays Tetris using deep reinforcement learning. The agent learns to play by training itself with a neural network and Q Learning algorithm. It explores different 'paths' to achieve higher scores and makes decisions based on predicted scores for possible moves. The game state includes attributes like lines cleared, holes, bumpiness, and total height. The agent is implemented in Python using Keras framework with a deep neural network structure. Training involves a replay queue, random sampling, and optimization techniques. Results show the agent's progress in achieving higher scores over episodes.
TFTMuZeroAgent
TFTMuZeroAgent is an implementation of a purely artificial intelligence algorithm to play Teamfight Tactics, an auto chess game made by Riot. It uses a simulation of TFT Set 4 and the MuZero reinforcement learning algorithm. The project provides a multi-agent petting zoo environment where players, pool, and game round classes are designed for AI project. The implementation excludes graphics and sounds but covers all aspects of the game from set 4. The codebase is open for contributions and improvements, allowing for additional models to be added to the environment.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.