
amd-shark-ai
AMD-SHARK Inference Modeling and Serving
Stars: 62
The amdshark-ai repository contains the amdshark Modeling and Serving Libraries, which include sub-projects like shortfin for high performance inference, amdsharktank for model recipes and conversion tools, and amdsharktuner for tuning program performance. Developers can find API documentation, programming guides, and support matrix for various models within the repository.
README:

If you're looking to use amdshark check out our User Guide. For developers continue to read on.
![]()
The shortfin sub-project is amdshark's high performance inference library and serving engine.
- API documentation for shortfin is available on readthedocs.
![]()
The amdshark Tank sub-project contains a collection of model recipes and conversion tools to produce inference-optimized programs.
- See the amdshark Tank Programming Guide for information about core concepts, the development model, dataset management, and more.
- See Direct Quantization with amdshark Tank for information about quantization support.
![]()
The amdshark Tuner sub-project assists with tuning program performance by searching for optimal parameter configurations to use during model compilation. Check out the readme for more details.
If you're looking to develop amdshark, check out our Developer Guide.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for amd-shark-ai
Similar Open Source Tools
amd-shark-ai
The amdshark-ai repository contains the amdshark Modeling and Serving Libraries, which include sub-projects like shortfin for high performance inference, amdsharktank for model recipes and conversion tools, and amdsharktuner for tuning program performance. Developers can find API documentation, programming guides, and support matrix for various models within the repository.

ASTRA.ai
ASTRA is an open-source platform designed for developing applications utilizing large language models. It merges the ideas of Backend-as-a-Service and LLM operations, allowing developers to swiftly create production-ready generative AI applications. Additionally, it empowers non-technical users to engage in defining and managing data operations for AI applications. With ASTRA, you can easily create real-time, multi-modal AI applications with low latency, even without any coding knowledge.
LLM-Finetune-Guide
This project provides a comprehensive guide to fine-tuning large language models (LLMs) with efficient methods like LoRA and P-tuning V2. It includes detailed instructions, code examples, and performance benchmarks for various LLMs and fine-tuning techniques. The guide also covers data preparation, evaluation, prediction, and running inference on CPU environments. By leveraging this guide, users can effectively fine-tune LLMs for specific tasks and applications.
lemonade
Lemonade is a tool that helps users run local Large Language Models (LLMs) with high performance by configuring state-of-the-art inference engines for their Neural Processing Units (NPUs) and Graphics Processing Units (GPUs). It is used by startups, research teams, and large companies to run LLMs efficiently. Lemonade provides a high-level Python API for direct integration of LLMs into Python applications and a CLI for mixing and matching LLMs with various features like prompting templates, accuracy testing, performance benchmarking, and memory profiling. The tool supports both GGUF and ONNX models and allows importing custom models from Hugging Face using the Model Manager. Lemonade is designed to be easy to use and switch between different configurations at runtime, making it a versatile tool for running LLMs locally.

GraphGen
GraphGen is a framework for synthetic data generation guided by knowledge graphs. It enhances supervised fine-tuning for large language models (LLMs) by generating synthetic data based on a fine-grained knowledge graph. The tool identifies knowledge gaps in LLMs, prioritizes generating QA pairs targeting high-value knowledge, incorporates multi-hop neighborhood sampling, and employs style-controlled generation to diversify QA data. Users can use LLaMA-Factory and xtuner for fine-tuning LLMs after data generation.

Open-Sora-Plan
Open-Sora-Plan is a project that aims to create a simple and scalable repo to reproduce Sora (OpenAI, but we prefer to call it "ClosedAI"). The project is still in its early stages, but the team is working hard to improve it and make it more accessible to the open-source community. The project is currently focused on training an unconditional model on a landscape dataset, but the team plans to expand the scope of the project in the future to include text2video experiments, training on video2text datasets, and controlling the model with more conditions.

ASTRA.ai
Astra.ai is a multimodal agent powered by TEN, showcasing its capabilities in speech, vision, and reasoning through RAG from local documentation. It provides a platform for developing AI agents with features like RTC transportation, extension store, workflow builder, and local deployment. Users can build and test agents locally using Docker and Node.js, with prerequisites including Agora App ID, Azure's speech-to-text and text-to-speech API keys, and OpenAI API key. The platform offers advanced customization options through config files and API keys setup, enabling users to create and deploy their AI agents for various tasks.
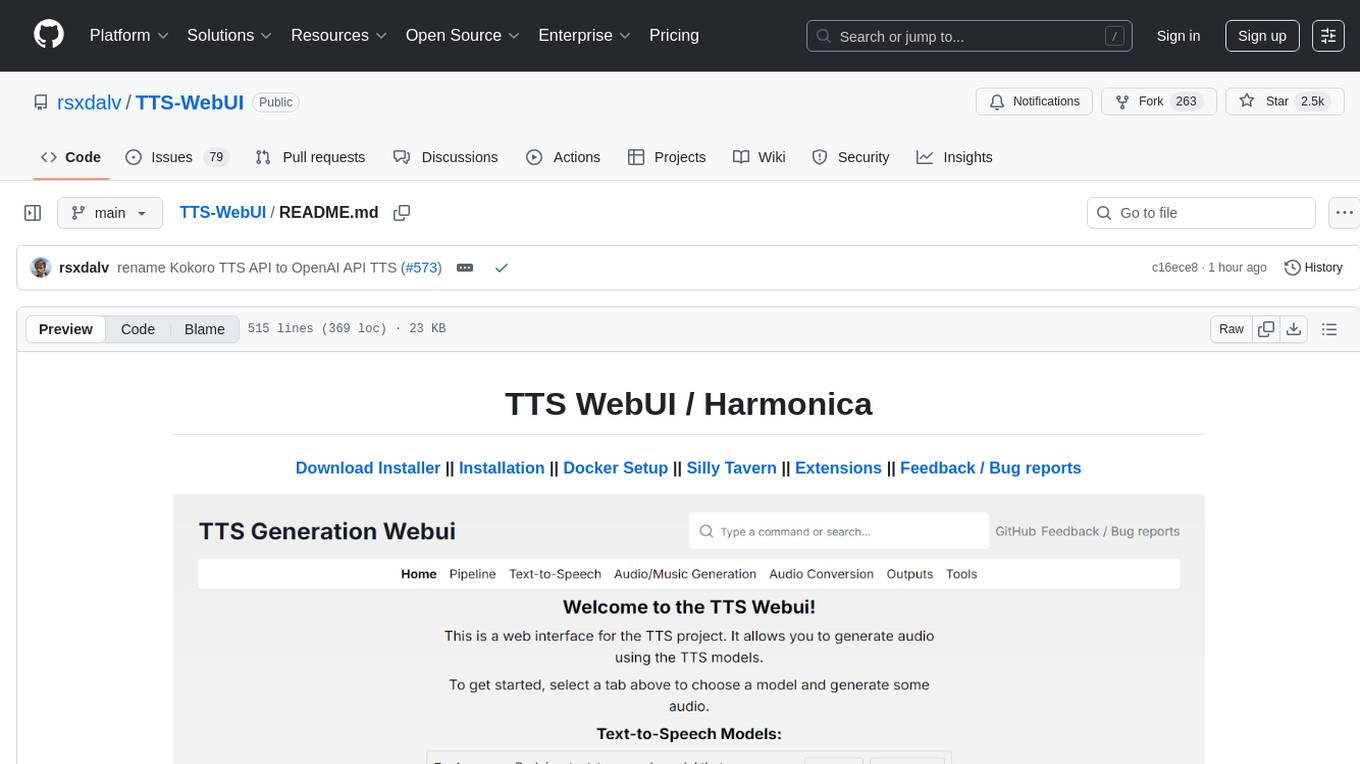
TTS-WebUI
TTS WebUI is a comprehensive tool for text-to-speech synthesis, audio/music generation, and audio conversion. It offers a user-friendly interface for various AI projects related to voice and audio processing. The tool provides a range of models and extensions for different tasks, along with integrations like Silly Tavern and OpenWebUI. With support for Docker setup and compatibility with Linux and Windows, TTS WebUI aims to facilitate creative and responsible use of AI technologies in a user-friendly manner.
local-deep-research
Local Deep Research is a powerful AI-powered research assistant that performs deep, iterative analysis using multiple LLMs and web searches. It can be run locally for privacy or configured to use cloud-based LLMs for enhanced capabilities. The tool offers advanced research capabilities, flexible LLM support, rich output options, privacy-focused operation, enhanced search integration, and academic & scientific integration. It also provides a web interface, command line interface, and supports multiple LLM providers and search engines. Users can configure AI models, search engines, and research parameters for customized research experiences.
aichat
Aichat is an AI-powered CLI chat and copilot tool that seamlessly integrates with over 10 leading AI platforms, providing a powerful combination of chat-based interaction, context-aware conversations, and AI-assisted shell capabilities, all within a customizable and user-friendly environment.
vnc-lm
vnc-lm is a Discord bot designed for messaging with language models. Users can configure model parameters, branch conversations, and edit prompts to enhance responses. The bot supports various providers like OpenAI, Huggingface, and Cloudflare Workers AI. It integrates with ollama and LiteLLM, allowing users to access a wide range of language model APIs through a single interface. Users can manage models, switch between models, split long messages, and create conversation branches. LiteLLM integration enables support for OpenAI-compatible APIs and local LLM services. The bot requires Docker for installation and can be configured through environment variables. Troubleshooting tips are provided for common issues like context window problems, Discord API errors, and LiteLLM issues.

agentscope
AgentScope is a multi-agent platform designed to empower developers to build multi-agent applications with large-scale models. It features three high-level capabilities: Easy-to-Use, High Robustness, and Actor-Based Distribution. AgentScope provides a list of `ModelWrapper` to support both local model services and third-party model APIs, including OpenAI API, DashScope API, Gemini API, and ollama. It also enables developers to rapidly deploy local model services using libraries such as ollama (CPU inference), Flask + Transformers, Flask + ModelScope, FastChat, and vllm. AgentScope supports various services, including Web Search, Data Query, Retrieval, Code Execution, File Operation, and Text Processing. Example applications include Conversation, Game, and Distribution. AgentScope is released under Apache License 2.0 and welcomes contributions.

nacos
Nacos is an easy-to-use platform designed for dynamic service discovery and configuration and service management. It helps build cloud native applications and microservices platform easily. Nacos provides functions like service discovery, health check, dynamic configuration management, dynamic DNS service, and service metadata management.
retinify
Retinify is an advanced AI-powered stereo vision library designed for robotics, enabling real-time, high-precision 3D perception by leveraging GPU and NPU acceleration. It is open source under Apache-2.0 license, offers high precision 3D mapping and object recognition, runs computations on GPU for fast performance, accepts stereo images from any rectified camera setup, is cost-efficient using minimal hardware, and has minimal dependencies on CUDA Toolkit, cuDNN, and TensorRT. The tool provides a pipeline for stereo matching and supports various image data types independently of OpenCV.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.
llama-assistant
Llama Assistant is an AI-powered assistant that helps with daily tasks, such as voice recognition, natural language processing, summarizing text, rephrasing sentences, answering questions, and more. It runs offline on your local machine, ensuring privacy by not sending data to external servers. The project is a work in progress with regular feature additions.
For similar tasks
bedrock-book
This repository contains sample code for hands-on exercises related to the book 'Amazon Bedrock 生成AIアプリ開発入門'. It allows readers to easily access and copy the code. The repository also includes directories for each chapter's hands-on code, settings, and a 'requirements.txt' file listing necessary Python libraries. Updates and error fixes will be provided as needed. Users can report issues in the repository's 'Issues' section, and errata will be published on the SB Creative official website.
FocusOnAI_24
The .NET Conf Focus on AI 2024 repository contains content from the event focusing on incorporating AI into .NET applications and services. It includes slides and demos showcasing various AI-powered web apps, AI models, generative AI apps, and more. The repository serves as a resource for developers looking to explore AI integration with .NET technologies.

quarkus-workshop-langchain4j
This repository contains a workshop to learn how to build AI-Infused applications with Quarkus and LangChain4j. It is divided into several steps with instructions available on the workshop website or locally in the docs/README file. Each step's final state is available in the step-XX directory, and the application can be run using './mvnw quarkus:dev' command on http://localhost:8080.
amd-shark-ai
The amdshark-ai repository contains the amdshark Modeling and Serving Libraries, which include sub-projects like shortfin for high performance inference, amdsharktank for model recipes and conversion tools, and amdsharktuner for tuning program performance. Developers can find API documentation, programming guides, and support matrix for various models within the repository.

deeplake
Deep Lake is a Database for AI powered by a storage format optimized for deep-learning applications. Deep Lake can be used for: 1. Storing data and vectors while building LLM applications 2. Managing datasets while training deep learning models Deep Lake simplifies the deployment of enterprise-grade LLM-based products by offering storage for all data types (embeddings, audio, text, videos, images, pdfs, annotations, etc.), querying and vector search, data streaming while training models at scale, data versioning and lineage, and integrations with popular tools such as LangChain, LlamaIndex, Weights & Biases, and many more. Deep Lake works with data of any size, it is serverless, and it enables you to store all of your data in your own cloud and in one place. Deep Lake is used by Intel, Bayer Radiology, Matterport, ZERO Systems, Red Cross, Yale, & Oxford.

python-aiplatform
The Vertex AI SDK for Python is a library that provides a convenient way to use the Vertex AI API. It offers a high-level interface for creating and managing Vertex AI resources, such as datasets, models, and endpoints. The SDK also provides support for training and deploying custom models, as well as using AutoML models. With the Vertex AI SDK for Python, you can quickly and easily build and deploy machine learning models on Vertex AI.

CSGHub
CSGHub is an open source, trustworthy large model asset management platform that can assist users in governing the assets involved in the lifecycle of LLM and LLM applications (datasets, model files, codes, etc). With CSGHub, users can perform operations on LLM assets, including uploading, downloading, storing, verifying, and distributing, through Web interface, Git command line, or natural language Chatbot. Meanwhile, the platform provides microservice submodules and standardized OpenAPIs, which could be easily integrated with users' own systems. CSGHub is committed to bringing users an asset management platform that is natively designed for large models and can be deployed On-Premise for fully offline operation. CSGHub offers functionalities similar to a privatized Huggingface(on-premise Huggingface), managing LLM assets in a manner akin to how OpenStack Glance manages virtual machine images, Harbor manages container images, and Sonatype Nexus manages artifacts.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.