
hoarder
A self-hostable bookmark-everything app (links, notes and images) with AI-based automatic tagging and full text search
Stars: 14654
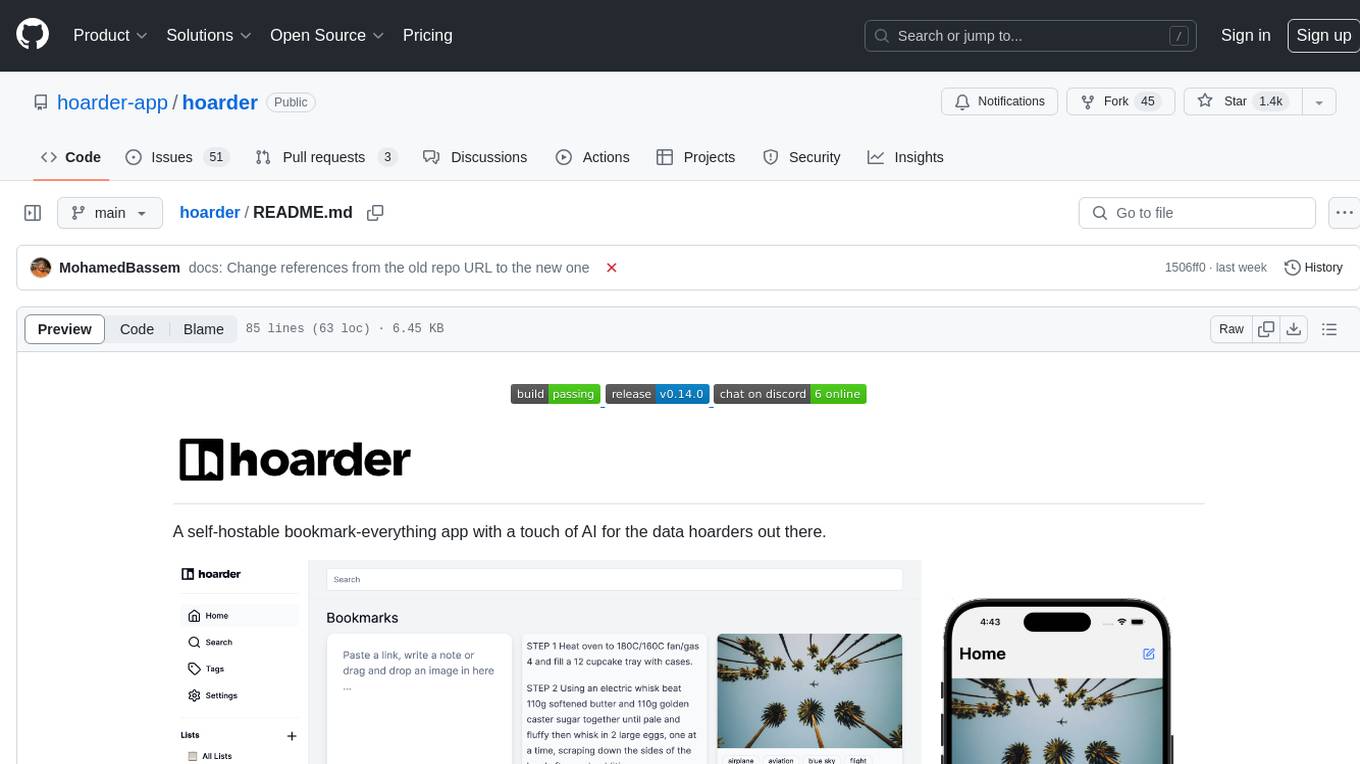
A self-hostable bookmark-everything app with a touch of AI for data hoarders. Features include bookmarking links, taking notes, storing images, automatic fetching for link details, full-text search, AI-based automatic tagging, Chrome and Firefox plugins, iOS and Android apps, dark mode support, and self-hosting. Built to address the need for archiving and previewing links with automatic tagging. Developed by a systems engineer to stay connected with web development and cater to personal use cases.
README:



Karakeep (previously Hoarder) self-hostable bookmark-everything app with a touch of AI for the data hoarders out there.

- 🔗 Bookmark links, take simple notes and store images and pdfs.
- ⬇️ Automatic fetching for link titles, descriptions and images.
- 📋 Sort your bookmarks into lists.
- 🔎 Full text search of all the content stored.
- ✨ AI-based (aka chatgpt) automatic tagging. With supports for local models using ollama!
- 🎆 OCR for extracting text from images.
- 🔖 Chrome plugin and Firefox addon for quick bookmarking.
- 📱 An iOS app, and an Android app.
- 📰 Auto hoarding from RSS feeds.
- 🔌 REST API.
- 🌐 Mutli-language support.
- 🖍️ Mark and store highlights from your hoarded content.
- 🗄️ Full page archival (using monolith) to protect against link rot. Auto video archiving using youtube-dl.
- ☑️ Bulk actions support.
- 🔐 SSO support.
- 🌙 Dark mode support.
- 💾 Self-hosting first.
- [Planned] Downloading the content for offline reading in the mobile app.
You can access the demo at https://try.karakeep.app. Login with the following creds:
email: [email protected]
password: demodemo
The demo is seeded with some content, but it's in read-only mode to prevent abuse.
The name Karakeep is inspired by the Arabic word "كراكيب" (karakeeb), a colloquial term commonly used to refer to miscellaneous clutter, odds and ends, or items that may seem disorganized but often hold personal value or hidden usefulness. It evokes the image of a messy drawer or forgotten box, full of stuff you can't quite throw away—because somehow, it matters (or more likely, because you're a hoarder!).
- NextJS for the web app. Using app router.
- Drizzle for the database and its migrations.
- NextAuth for authentication.
- tRPC for client->server communication.
- Puppeteer for crawling the bookmarks.
- OpenAI because AI is so hot right now.
- Meilisearch for the full content search.
I browse reddit, twitter and hackernews a lot from my phone. I frequently find interesting stuff (articles, tools, etc) that I'd like to bookmark and read later when I'm in front of a laptop. Typical read-it-later apps usecase. Initially, I was using Pocket for that. Then I got into self-hosting and I wanted to self-host this usecase. I used memos for those quick notes and I loved it but it was lacking some features that I found important for that usecase such as link previews and automatic tagging (more on that in the next section).
I'm a systems engineer in my day job (and have been for the past 7 years). I didn't want to get too detached from the web development world. I decided to build this app as a way to keep my hand dirty with web development, and at the same time, build something that I care about and use every day.
- memos: I love memos. I have it running on my home server and it's one of my most used self-hosted apps. It doesn't, however, archive or preview the links shared in it. It's just that I dump a lot of links there and I'd have loved if I'd be able to figure which link is that by just looking at my timeline. Also, given the variety of things I dump there, I'd have loved if it does some sort of automatic tagging for what I save there. This is exactly the usecase that I'm trying to tackle with Karakeep.
- mymind: Mymind is the closest alternative to this project and from where I drew a lot of inspirations. It's a commercial product though.
- raindrop: A polished open source bookmark manager that supports links, images and files. It's not self-hostable though.
- Bookmark managers (mostly focused on bookmarking links):
- Pocket: Pocket is what hooked me into the whole idea of read-it-later apps. I used it a lot. However, I recently got into home-labbing and became obsessed with the idea of running my services in my home server. Karakeep is meant to be a self-hosting first app.
- Linkwarden: An open-source self-hostable bookmark manager that I ran for a bit in my homelab. It's focused mostly on links and supports collaborative collections.
- Omnivore: Omnivore is pretty cool open source read-it-later app. Unfortunately, it's heavily dependent on google cloud infra which makes self-hosting it quite hard. They published a blog post on how to run a minimal omnivore but it was lacking a lot of stuff. Self-hosting doesn't really seem to be a high priority for them, and that's something I care about, so I decided to build an alternative.
- Wallabag: Wallabag is a well-established open source read-it-later app written in php and I think it's the common recommendation on reddit for such apps. To be honest, I didn't give it a real shot, and the UI just felt a bit dated for my liking. Honestly, it's probably much more stable and feature complete than this app, but where's the fun in that?
- Shiori: Shiori is meant to be an open source pocket clone written in Go. It ticks all the marks but doesn't have my super sophisticated AI-based tagging. (JK, I only found about it after I decided to build my own app, so here we are 🤷).
Karakeep uses Weblate for managing translations. If you want to help translate Karakeep, you can do so here.
If you're enjoying using Karakeep, drop a ⭐️ on the repo!

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for hoarder
Similar Open Source Tools
hoarder
A self-hostable bookmark-everything app with a touch of AI for data hoarders. Features include bookmarking links, taking notes, storing images, automatic fetching for link details, full-text search, AI-based automatic tagging, Chrome and Firefox plugins, iOS and Android apps, dark mode support, and self-hosting. Built to address the need for archiving and previewing links with automatic tagging. Developed by a systems engineer to stay connected with web development and cater to personal use cases.
hoarder-app
Hoarder is a self-hostable bookmark manager with a focus on privacy and customization. It features automatic link previews, full-text search, AI-based tagging, and a variety of import and export options. Hoarder is designed to be easy to use and extensible, with a plugin system that allows users to add their own features and integrations.
karakeep
Karakeep is a self-hostable bookmark-everything app with a touch of AI for data hoarders. It allows users to bookmark links, take notes, store images and pdfs, and offers features like automatic fetching, full-text search, AI-based tagging, OCR, rule-based engine, Chrome plugin, Firefox addon, iOS and Android apps, auto hoarding from RSS feeds, REST API, multi-language support, and more. The app is under heavy development and aims to provide a self-hosting first solution for managing bookmarks and content.
obsidian-smart-connections
Smart Connections is an AI-powered plugin for Obsidian that helps you discover hidden connections and insights in your notes. With features like Smart View for real-time relevant note suggestions and Smart Chat for chatting with your notes, Smart Connections makes it easier than ever to stay organized and uncover hidden connections between your notes. Its intuitive interface and customizable settings ensure a seamless experience, tailored to your unique needs and preferences.
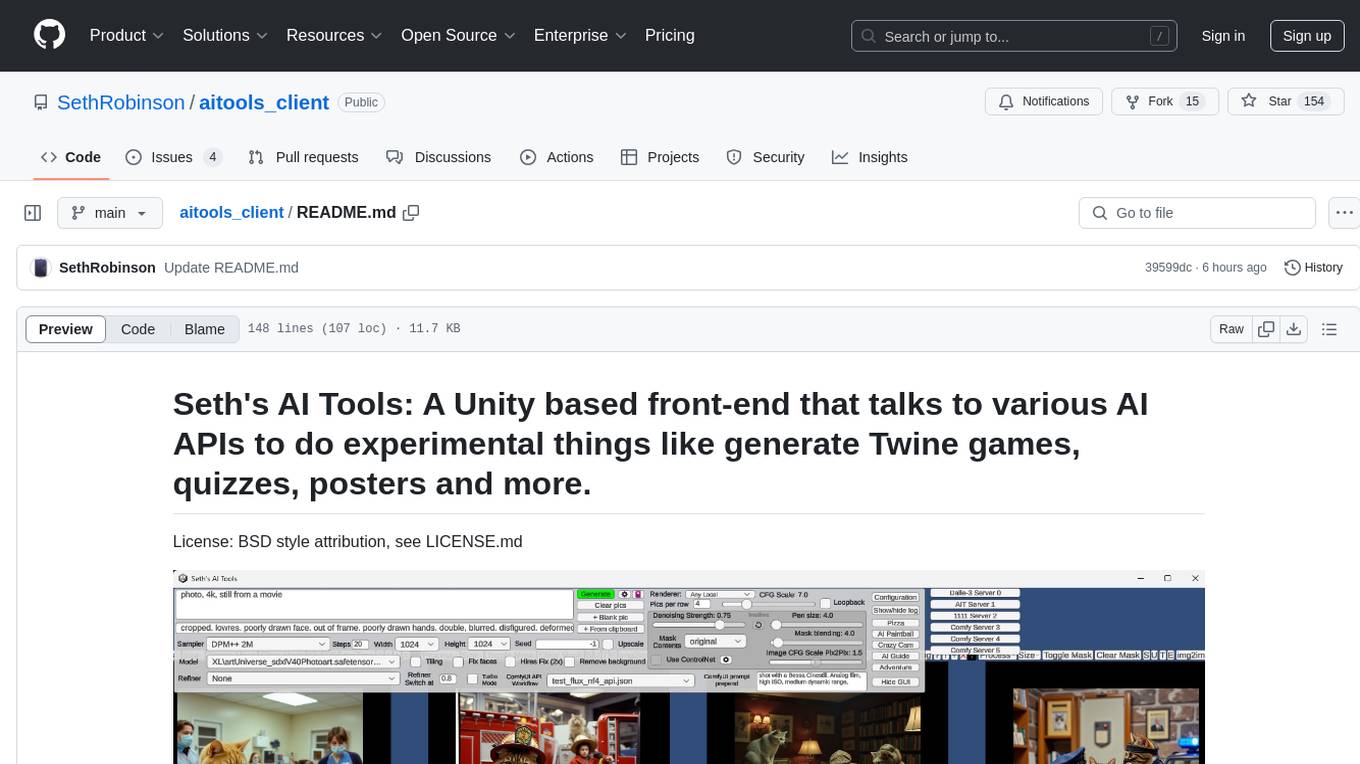
aitools_client
Seth's AI Tools is a Unity-based front-end that interfaces with various AI APIs to perform tasks such as generating Twine games, quizzes, posters, and more. The tool is a native Windows application that supports features like live update integration with image editors, text-to-image conversion, image processing, mask painting, and more. It allows users to connect to multiple servers for fast generation using GPUs and offers a neat workflow for evolving images in real-time. The tool respects user privacy by operating locally and includes built-in games and apps to test AI/SD capabilities. Additionally, it features an AI Guide for creating motivational posters and illustrated stories, as well as an Adventure mode with presets for generating web quizzes and Twine game projects.
lumentis
Lumentis is a tool that allows users to generate beautiful and comprehensive documentation from meeting transcripts and large documents with a single command. It reads transcripts, asks questions to understand themes and audience, generates an outline, and creates detailed pages with visual variety and styles. Users can switch models for different tasks, control the process, and deploy the generated docs to Vercel. The tool is designed to be open, clean, fast, and easy to use, with upcoming features including folders, PDFs, auto-transcription, website scraping, scientific papers handling, summarization, and continuous updates.
chatgpt-universe
ChatGPT is a large language model that can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in a conversational way. It is trained on a massive amount of text data, and it is able to understand and respond to a wide range of natural language prompts. Here are 5 jobs suitable for this tool, in lowercase letters: 1. content writer 2. chatbot assistant 3. language translator 4. creative writer 5. researcher

local-chat
LocalChat is a simple, easy-to-set-up, and open-source local AI chat tool that allows users to interact with generative language models on their own computers without transmitting data to a cloud server. It provides a chat-like interface for users to experience ChatGPT-like behavior locally, ensuring GDPR compliance and data privacy. Users can download LocalChat for macOS, Windows, or Linux to chat with open-weight generative language models.
iris-llm
iris-llm is a personal project aimed at creating an Intelligent Residential Integration System (IRIS) with a voice interface to local language models or GPT. It provides options for chat engines, text-to-speech engines, speech-to-text engines, feedback sounds, and push-to-talk or wake word features. The tool is still in early development and serves as a tutorial for Python coders interested in working with language models.
FreeChat
FreeChat is a native LLM appliance for macOS that runs completely locally. Download it and ask your LLM a question without doing any configuration. A local/llama version of OpenAI's chat without login or tracking. You should be able to install from the Mac App Store and use it immediately.
RTranslator
RTranslator is an almost open-source, free, and offline real-time translation app for Android. It offers Conversation mode for multi-user translations, WalkieTalkie mode for quick conversations, and Text translation mode. It uses Meta's NLLB for translation and OpenAi's Whisper for speech recognition, ensuring privacy. The app is optimized for performance and supports multiple languages. It is ad-free and donation-supported.
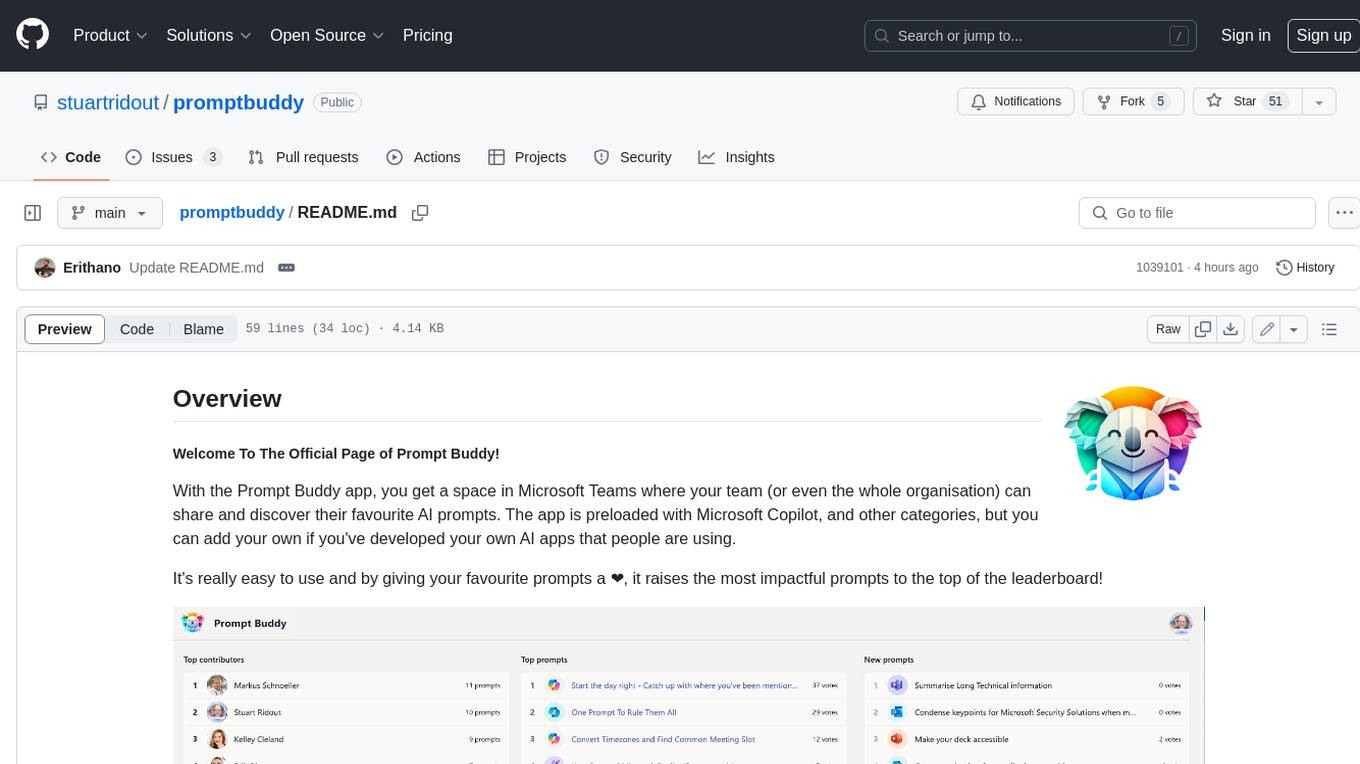
promptbuddy
Prompt Buddy is a Microsoft Teams app that provides a central location for teams to share and discover their favorite AI prompts. It comes preloaded with Microsoft Copilot and other categories, but users can also add their own custom prompts. The app is easy to use and allows users to upvote their favorite prompts, which raises them to the top of the leaderboard. Prompt Buddy also supports dark mode and offers a mobile layout for use on phones. It is built on the Power Platform and can be customized and extended by the installer.
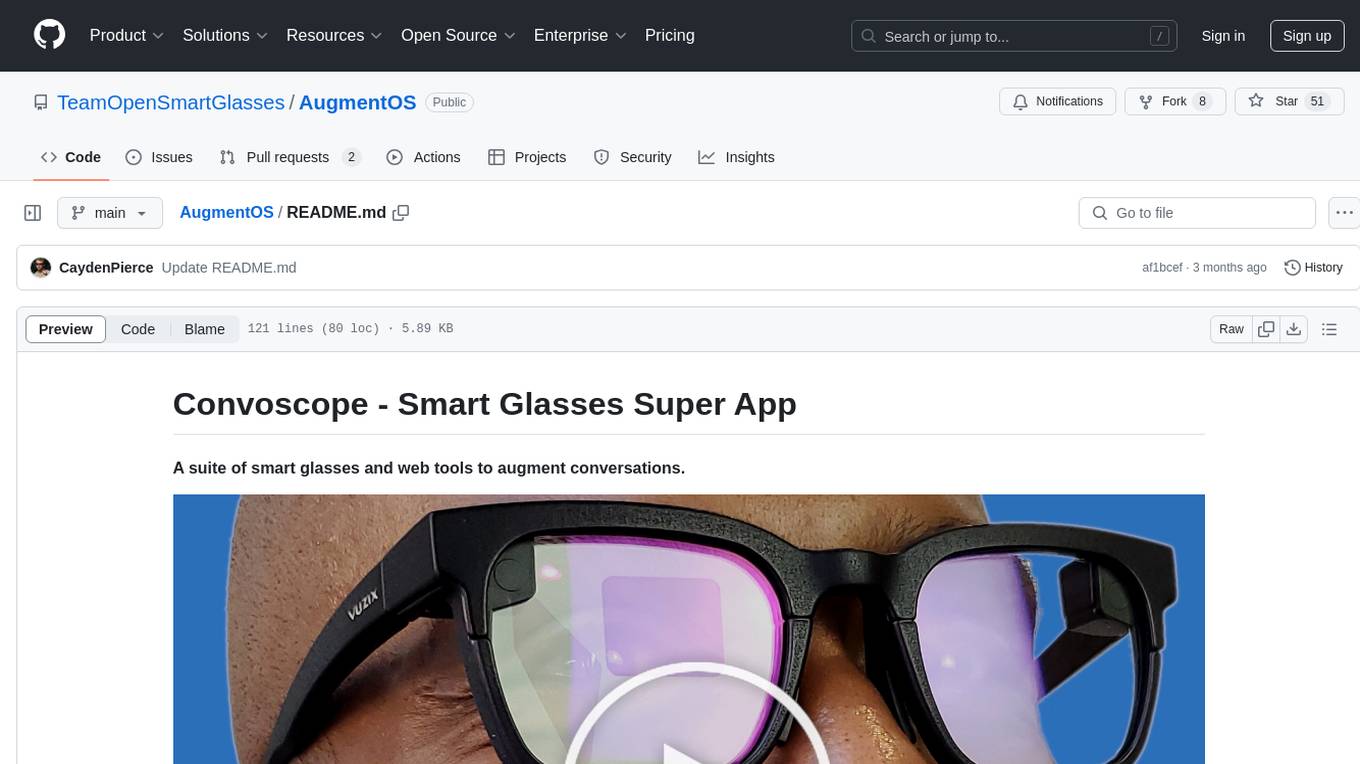
AugmentOS
Convoscope is a suite of smart glasses and web tools designed to augment conversations by providing live proactive agents that answer questions, offer definitions, insights, and alternative viewpoints. It includes features like 'Mira' AI Assistant, Convoscope Proactive AI Agents, Language Learning app, Screen Mirror functionality, and upcoming features such as Live Captions, ADHD Glasses, and Live Language Translation. The tool supports various smart glasses models and Android 12+ phones, offering a unique experience for real-life conversations, meetings, and video calls.
talk-to-chatgpt
Talk-To-ChatGPT is a Google Chrome and Microsoft Edge extension that enables users to interact with the ChatGPT AI using voice commands for speech recognition and text-to-speech responses. The tool enhances the conversational experience by allowing users to speak to the AI and receive spoken responses, making interactions more natural and engaging. It also supports ElevenLabs API integration for creating custom voices for text-to-speech. The extension provides settings for voice, language, and more, and can be installed from the Chrome and Edge web stores or manually. While the project has been discontinued due to upcoming desktop apps from OpenAI, it has been used to assist individuals with disabilities and the elderly in interacting with ChatGPT.
AugmentOS
AugmentOS is an open source operating system for smart glasses that allows users to access various apps and AI agents. It enables developers to easily build and run apps on smart glasses, run multiple apps simultaneously, and interact with AI assistants, translation services, live captions, and more. The platform also supports language learning, ADHD tools, and live language translation. AugmentOS is designed to enhance the user experience of smart glasses by providing a seamless and proactive interaction with AI-first wearables apps.
AI-Writing-Assistant
DeepWrite AI is an AI writing assistant tool created with the help of ChatGPT3. It is designed to generate perfect blog posts with utmost clarity. The tool is currently at version 1.0 with plans for further improvements. It is an open-source project, welcoming contributions. An extension has been developed for using the tool directly in Notepad, currently supported only on Calmly Writer. The tool requires installation and setup, utilizing technologies like React, Next, TailwindCSS, Node, and Express. For support, users can message the creator on Instagram. The creator, Sabir Khan, is an undergraduate student of Computer Science from Mumbai, known for frequently creating innovative projects.
For similar tasks
hoarder
A self-hostable bookmark-everything app with a touch of AI for data hoarders. Features include bookmarking links, taking notes, storing images, automatic fetching for link details, full-text search, AI-based automatic tagging, Chrome and Firefox plugins, iOS and Android apps, dark mode support, and self-hosting. Built to address the need for archiving and previewing links with automatic tagging. Developed by a systems engineer to stay connected with web development and cater to personal use cases.
TabMark-Bookmark-New-Tab
TabMark is a browser extension that transforms bookmarks into a new tab page, allowing you to easily access and organize your saved bookmarks. It features intelligent AI search for quick answers and supports Chrome and Edge browsers. With TabMark, you can set bookmarks as new tab pages, access rich bookmark context menus, use sidebar bookmarks, utilize floating ball functionality, perform AI intelligent searches, compare search results, customize new tab pages, and access browser shortcuts. The extension enhances browsing efficiency and organization.
karakeep
Karakeep is a self-hostable bookmark-everything app with a touch of AI for data hoarders. It allows users to bookmark links, take notes, store images and pdfs, and offers features like automatic fetching, full-text search, AI-based tagging, OCR, rule-based engine, Chrome plugin, Firefox addon, iOS and Android apps, auto hoarding from RSS feeds, REST API, multi-language support, and more. The app is under heavy development and aims to provide a self-hosting first solution for managing bookmarks and content.
mindpocket
MindPocket is a fully open-source, free, multi-platform, one-click deployable personal bookmark system with AI Agent integration. It organizes bookmarks with AI-powered RAG content summarization and automatic tag generation, making it easy to find and manage saved content. The project is built using VIBE CODING principles and offers features like zero cost deployment, one-click deploy setup, multi-platform support, AI enhancement for smart tagging and summarization, and full open-source accessibility for user data ownership. The tool is designed to provide a seamless bookmarking experience across web, mobile, and browser extension platforms.
reor
Reor is an AI-powered desktop note-taking app that automatically links related notes, answers questions on your notes, and provides semantic search. Everything is stored locally and you can edit your notes with an Obsidian-like markdown editor. The hypothesis of the project is that AI tools for thought should run models locally by default. Reor stands on the shoulders of the giants Ollama, Transformers.js & LanceDB to enable both LLMs and embedding models to run locally. Connecting to OpenAI or OpenAI-compatible APIs like Oobabooga is also supported.
blinko
Blinko is an innovative open-source project designed for individuals who want to quickly capture and organize their fleeting thoughts. It allows users to seamlessly jot down ideas the moment they strike, ensuring that no spark of creativity is lost. With advanced AI-powered note retrieval, data ownership, efficient and fast capturing, lightweight architecture, and open collaboration, Blinko offers a comprehensive solution for managing and accessing notes.
QOwnNotes
QOwnNotes is an open source notepad with Markdown support and todo list manager for GNU/Linux, macOS, and Windows. It allows you to write down thoughts, edit, and search for them later from mobile devices. Notes are stored as plain text markdown files and synced with Nextcloud's/ownCloud's file sync functionality. QOwnNotes offers features like multiple note folders, restoration of older versions and trashed notes, sub-string searching, customizable keyboard shortcuts, markdown highlighting, spellchecking, tabbing support, scripting support, encryption of notes, dark mode theme support, and more. It supports hierarchical note tagging, note subfolders, sharing notes on Nextcloud/ownCloud server, portable mode, Vim mode, distraction-free mode, full-screen mode, typewriter mode, Evernote and Joplin import, and is available in over 60 languages.
blinko
Blinko is an innovative open-source project designed for individuals who want to quickly capture and organize their fleeting thoughts. It allows users to seamlessly jot down ideas, ensuring no spark of creativity is lost. With AI-enhanced note retrieval, data ownership, efficient and fast note-taking, lightweight architecture, and open collaboration, Blinko offers a robust platform for managing and accessing notes effortlessly.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.