
alphadec
AlphaDec, a timezone-agonistic time format for humans, machines, and AI
Stars: 76
Alphadec is a timezone-agnostic, human-readable time format designed for global timestamp synchronization. It encodes any UTC timestamp into a structured string that is lexically sortable, time-series friendly, human-readable, and compact. Alphadec serves as a powerful primitive for AI models to understand the passage of time and offers emergent properties like rhythmic timestamps, chronological ID fragments, and version labels. It is AI-friendly, database-friendly, and collision-free with ISO time formats. Alphadec's canonical format consists of parts representing the UTC year, periods, arcs, bars, beats, and milliseconds offset, allowing for efficient time-range queries and index stability.
README:
A timezone-agnostic, readable time format for humans, machines, and AI.
AlphaDec is a shared global timestamp. If an event is scheduled for N0A0, every participant worldwide knows what that means — without converting timezones or formats.
Example:
-
AlphaDec:
2025_L0V3- UTC: June 5th, 2025, 1:45PM (Approximately)
-
AlphaDec (canonical format):
2025_L0V3_000000- UTC: 2025-06-05T13:45:20.236Z
Current time snapshot (automatically updated; may be around 1 hour behind):
GMT: Monday, Sep 15, 2025, 3:13 PM
| AlphaDec | AlphaDec Arc | Arc Remaining Time |
|---|---|---|
2025_S3N5 |
S3 | 16.2 hrs |
| Mexico City | NYC | Abu Dhabi |
| Mon 9:13 AM | Mon 11:13 AM | Mon 7:13 PM |
| Delhi | Tokyo | Sydney |
| Mon 8:43 PM | Tue 12:13 AM | Tue 1:13 AM |

AlphaDec in action inside an AI chat.
Every ~7.8-minute beat (t) triggers a new memory summary.
Instead of timestamps, the model sees structured time tokens likeN1U0.
It doesn’t just label time — it thinks with it.
AlphaDec encodes any UTC timestamp into a readable string that sorts chronologically. This simple concept unlocks a host of powerful emergent properties.
- Lexically Sortable: Natively time-sortable in any system that can sort strings alphabetically. Perfect for database primary keys.
-
Time-Series Friendly: Truncate the string for efficient time-range queries.
2024_Mfinds everything in that ~14-day period. - Human-Readable & Compact: Understand a timestamp's approximate place in the year at a glance.
- LLM & AI-Native: Its structured, tokenizable, continuous rhythm makes it a powerful primitive for giving AI a sense for how time is passing.
- Collision-free with ISO time: AlphaDec avoids datetime-like formats, so you never confuse an AlphaDec timestamp for a local time (a past Alphadec is the same 'time ago' for everyone).
The canonical AlphaDec string is composed of several parts:
YYYY_PeriodArcBarBeat_MSOffset
- YYYY: The UTC year.
-
Period: The year is divided into 26 periods, represented by letters
AthroughZ. Each period is roughly 14 days long. -
Arc: Each period is divided into 10 arcs, numbered
0through9. Each arc is roughly 33.7 hours long. -
Bar: Each arc is divided into 26 bars,
AthroughZ. Each bar is roughly 77.8 minutes long. -
Beat: Each bar is divided into 10 beats,
0through9. Each beat is roughly 7.8 minutes long. -
MsOffset: The number of milliseconds that have elapsed within the current beat.
- In common years (365 days), the maximum integer ms offset is 466508. In leap years (366 days), the maximum integer ms offset is 467786.
This project is language-agnostic. Below are examples of how to generate an AlphaDec string.
JavaScript Implementation
const clock = {
alphadec: {
_SCALER: 1_000_000,
_toBase26(n) {
if (n < 0 || n > 25) throw new Error("Invalid index for Base26.");
return String.fromCharCode(65 + n);
},
encode(d) {
const y = d.getUTCFullYear();
const SCALER = this._SCALER;
const msSinceYearStart_float = d.getTime() - Date.UTC(y, 0, 1, 0, 0, 0, 0);
const totalScaledMsSinceYearStart = Math.floor(msSinceYearStart_float * SCALER);
const isLeap = ((y % 4 === 0 && y % 100 !== 0) || y % 400 === 0);
const daysInYear = isLeap ? 366 : 365;
const yearTotalMs_float = daysInYear * 86_400_000;
const yearTotalScaledMs = Math.floor(yearTotalMs_float * SCALER);
const periodSizeScaled = Math.floor(yearTotalScaledMs / 26);
const arcSizeScaled = Math.floor(periodSizeScaled / 10);
const barSizeScaled = Math.floor(arcSizeScaled / 26);
const beatSizeScaled = Math.floor(barSizeScaled / 10);
let remainingScaledMs = totalScaledMsSinceYearStart;
const p_idx = Math.floor(remainingScaledMs / periodSizeScaled);
remainingScaledMs -= p_idx * periodSizeScaled;
const a_val = Math.floor(remainingScaledMs / arcSizeScaled);
remainingScaledMs -= a_val * arcSizeScaled;
const b_idx = Math.floor(remainingScaledMs / barSizeScaled);
remainingScaledMs -= b_idx * barSizeScaled;
const t_val = Math.floor(remainingScaledMs / beatSizeScaled);
remainingScaledMs -= t_val * beatSizeScaled;
const msOffsetInBeat = Math.floor(remainingScaledMs / SCALER);
const periodLetter = this._toBase26(p_idx);
const barLetter = this._toBase26(b_idx);
const canonicalMsPart = msOffsetInBeat.toString().padStart(6, "0");
const canonical = `${y}_${periodLetter}${a_val}${barLetter}${t_val}_${canonicalMsPart}`;
return { canonical };
}
}
};PHP Implementation
<?php
/**
* Generates a lexically sortable AlphaDec timestamp from a DateTime object.
*
* @param DateTime|null $datetime The datetime to encode. Defaults to UTC now.
* @return string The canonical AlphaDec string (e.g., "2024_M5C3_123456").
* @throws Exception If the provided datetime is invalid.
*
* NOTE: This function requires a 64-bit PHP environment due to large integer calculations.
*/
function generate_alphadec(DateTime $datetime = null): string {
// If no datetime is provided, use the current time in UTC.
if ($datetime === null) {
$datetime = new DateTime("now", new DateTimeZone("UTC"));
}
$y = (int)$datetime->format("Y");
// SCALER is used to perform calculations with integer math to avoid float precision issues.
$SCALER = 1000000;
// Calculate the total milliseconds that have passed since the beginning of the year.
$startOfYear = new DateTime("$y-01-01T00:00:00Z");
$msSinceYearStart = ($datetime->format('U.v') - $startOfYear->format('U.v')) * 1000;
// Scale up for integer-based math.
$totalScaledMsSinceYearStart = (int)floor($msSinceYearStart * $SCALER);
// Determine the total number of milliseconds in the current year.
$isLeap = (bool)$datetime->format('L');
$daysInYear = $isLeap ? 366 : 365;
$yearTotalMs = $daysInYear * 86400000;
$yearTotalScaledMs = (int)floor($yearTotalMs * $SCALER);
// Calculate the size of each AlphaDec time unit in scaled milliseconds.
$periodSizeScaled = (int)floor($yearTotalScaledMs / 26); // ~14 days
$arcSizeScaled = (int)floor($periodSizeScaled / 10); // ~33.7 hours
$barSizeScaled = (int)floor($arcSizeScaled / 26); // ~77.8 minutes
$beatSizeScaled = (int)floor($barSizeScaled / 10); // ~7.8 minutes
// Use division and remainder to find the index of each time unit.
$remaining = $totalScaledMsSinceYearStart;
$p_idx = (int)floor($remaining / $periodSizeScaled); $remaining -= $p_idx * $periodSizeScaled;
$a_val = (int)floor($remaining / $arcSizeScaled); $remaining -= $a_val * $arcSizeScaled;
$b_idx = (int)floor($remaining / $barSizeScaled); $remaining -= $b_idx * $barSizeScaled;
$t_val = (int)floor($remaining / $beatSizeScaled); $remaining -= $t_val * $beatSizeScaled;
// The final remainder is the millisecond offset within the current "beat".
$msOffsetInBeat = (int)floor($remaining / $SCALER);
// Convert numeric indices to their character representation (A-Z).
$periodLetter = chr(65 + $p_idx);
$barLetter = chr(65 + $b_idx);
// Format the final milliseconds part to be 6 digits, zero-padded.
$canonicalMsPart = str_pad((string)$msOffsetInBeat, 6, "0", STR_PAD_LEFT);
// Assemble the final canonical string.
return "{$y}_{$periodLetter}{$a_val}{$barLetter}{$t_val}_{$canonicalMsPart}";
}
?>While AlphaDec was designed as a verbally chunked and compressed form of UTC, the mathematical structure leads to many emergent properties. For example:
- AlphaDec timestamps are quite rhythmic: M2L3 ticks over to M2L4, etc.
- Period F, Period M, Period S, and Period Z always bracket equinoxes and solstices, even in leap years when AlphaDec units stretch to accomodate the longer UTC year.
- AlphaDec can be used as readable, chronological ID fragments such as prefixes and suffixes.
- Version labels: Unlike "v1, v10, v2" which breaks alphabetical order, AlphaDec versions (or version prefixes) like
2025_A1B2sort chronologically by default.
- Unit intervals explicitly change one of four characters rather than requiring calculating numeric deltas to realize that time has passed
AlphaDec encodes time hierarchically. Each additional character narrows the scope — from periods to beats to milliseconds — forming a natural prefix tree.
This structure enables:
- Time-based partitioning (e.g., logs by 2025_M)
- Fast range queries with simple string matching
- Index stability (no random insert churn like UUIDs)
- Optional semantic suffixes without breaking order
Because Alphadec stamps are strings, you can use them in more contexts than a standard timestamp—and unlike 2025-08-11, the unit sizes on 2025_P8G2 don't jump from 1 day to a full month.
AlphaDec does not prescribe a rigid ID format. Instead, its time-based, sortable nature makes it an excellent component for building meaningful identifiers through composition.
You can use the full canonical string or truncate it to the desired precision. Combine it with prefixes or suffixes like dictionary words, counters, or random characters to suit your specific needs.
This flexibility allows you to create IDs that are both chronologically sortable and contextually rich, without sacrificing readability.
Examples:
-
2025_G0R5_todo.txt(A truncated AlphaDec timestamp followed by a semantic tag) -
2025_R173_154329_01.png(An AlphaDec timestamp followed by a counter) -
sales_Y3.sql(A category prefix followed by a truncated AlphaDec timestamp)
Consider these filenames prefixed with ISO dates:
- 2025-08-07-screenshot.png
- 2025-10-22-crashlog.txt
And now with Alphadec:
- 2025_P5I6-screenshot.png
- 2025_V0A0-crashlog.txt
Both prefixes sort chronologically, but Alphadec achieves far higher resolution with fewer characters: setting aside underscores and hyphens, 8 chars in Alphadec mark an ~8 minute period of time compared to 24 hours in ISO.
More significantly: the Alphadec prefixes are easier to skim past as a label, and less aesthetically harsh-looking. Admittedly this is a subjective point, but it's worthy of consideration.
Time is usually 'metadata': a file property, a database column. Alphadec, by virtue of being a string that can be used in filenames and AI conversations, turns time into document syntax, like a bullet point.
Furthermore, Alphadec includes strong semantics because of the way it combines unit position and compression: it's like a Zip Code for time.
These properties lead to time becoming a more prominent citizen of informational workflows.
A UUID is a collection of random characters like f81d4fae-7dec-11d0-a765-00a0c91e6bf6.
Now consider: what is the point of all this paranoid entropy? Is there any chance that a 7-Eleven receipt and NASA spectrograph will end up in the same S3 bucket?
And even if so:
- How would you tell your objects apart? You'd still need a separate index to organize your jumble of UUIDs.
- Why would Snowflake IDs not suffice? Very few organizations are generating more varied objects at higher velocity than Twitter.
To be fair, if you were a software component identifying yourself to Windows 3.1 in 1992, a 'GUID' made sense. But UUIDs were never meant to be database keys (where they cause index problems) or URLs (where they're ugly).
Now here is a cosmic truth: Time is entropy. Why ignore literal entropy to create a bag of your own?
Alphadec, like Snowflake, KSUIDs, and ULIDs, embrace time as an inherent disambiguiator. However, an Alphadec prefix like 2025_P5U5_326662 is more easily interpretable than the others.
Consumer laptops using Node.js can encode nearly 1 million UTC dates into Alphadec per second, i.e. roughly one timestamp per microsecond. This represents the lower bound of expected performance.
AlphaDec units stretch in leap years to accommodate the extra 24 hours. Since the year is always divided into exactly 26 periods regardless of length, each time unit becomes slightly longer in leap years than in common years.
This creates temporal drift between leap and common years that accumulates throughout the year, reaching maximum separation at the midpoint at Beat N0A0 — exactly 12 hours difference.
For example, July 4th midnight demonstrates how the same calendar moment maps to different AlphaDec coordinates:
-
2025 (common):
N1B7- July 4, 2025 00:00 UTC -
2024 (leap):
N1K9- July 4, 2024 00:00 UTC
Notice the first two characters remain the same (N1) as both dates fall within the same period and arc, but the bar-beat coordinates diverge significantly (K9 vs B7), reflecting the accumulated temporal drift.
Pure Function Design: We accept this temporal drift as a deliberate trade-off to maintain AlphaDec as a pure mathematical function of UTC year duration and milliseconds elapsed since year start, ensuring the encoding remains deterministic.
Gregorian Boundary: AlphaDec acts like a temporal compass bounded by Gregorian years. The drift simply reflects the underlying astronomical reality that July 4th occurs at different orbital positions in 365-day versus 366-day years.
- Not aligned with ISO Date/Time: Alphadec units are rational fractions of the year, and are thus almost never aligned with ISO dates. Do not use Alphadec to fill out tax forms.
- Quantization Loss: Conversion (UTC → Alphadec or Alphadec → UTC) may drift by a few milliseconds. This is for two reasons: Alphadec units are almost never aligned with ISO seconds; additionally, when encoding and decoding, we never round 'up' fractional values and instead truncate to the nearest completed unit of time. (Note that in practice, an accumulated round-trip loss of ~3 ms is usually irrelevant; a default MySQL datetime has second-level precision, i.e. 1000x more coarse than a millisecond.)
- Cross-Year Math: Arithmetic operations spanning multiple years are not supported or intended due to the units stretching on leap years.
- Distributed Local Events: AlphaDec is not particularly applicable to global events that synchronize with local time of day. For example, iftar during Ramadan, Christmas midnight mass, or New Year's Eve celebrations are inherently tied to local time. AlphaDec is for marking singular moments, not distributed observances.
AlphaDec is not a replacement for ISO 8601, created_at, or your existing datetime columns.
It’s a representation — a compact, structured, and readable fingerprint of UTC time.
You still store full datetimes in your database.
You still use ISO for APIs, logs, schemas, and interop.
But when you want to name a file, index a memory, prefix a row, or group logs, you can reach for:
AlphaDec: 2025_L0V3_001827
Instead of:
ISO 8601: 2025-06-14T23:37:42.814Z
One is for machines.
One is for humans, filenames, indexes, AI models.
AlphaDec sits beside your datetime — not in place of it.
Here’s how AlphaDec compares to other systems:
- Divides the day into 1000 “.beats” (
@000to@999), anchored to UTC+1. - Intended to be universal, but doesn't encode the date —
@000repeats every day. -
@000in Tokyo might be a different date than in NYC.
✅ Global
❌ Ambiguous
❌ Not hierarchical
❌ Not useful for indexing or filenames
- Used in ham radio to encode spatial positions in a compact grid (e.g.,
FN31pr). - Each character increases precision, and prefixes group cleanly.
✅ Hierarchical
✅ Prefix-sortable
✅ Spatially meaningful
AlphaDec is like Maidenhead — but for time.
You can zoom in or out: Year → Period → Arc → Beat → Offset.
- Canonical format for timestamps (
2025-07-21T13:42:11Z) - Great for storage, transport, and validation.
✅ Precise
✅ Interoperable
❌ Verbose
❌ Not sort-friendly as a string (unless zero-padded)
❌ Not great for filenames or embeddings
These are modern, sortable database IDs designed to replace UUIDs. They combine a high-precision timestamp with machine IDs (Snowflake) or randomness (ULID).
They are excellent for generating unique, chronological primary keys at scale.
- ✅ Sortable
- ✅ High-performance
- ✅ Collision-resistant
- ❌ Not Glanceable: The timestamp portion is a monolithic integer, not broken down into meaningful components. You can't tell if a ULID is from mid-year.
- ❌ Not Hierarchical: They don't have a "time tree" structure. You can't query for a ~14-day "Period" using a simple string prefix. AlphaDec focuses on human/AI legibility and hierarchical querying, whereas ULID/Snowflake focus on machine-level key generation.
Alphadec originated as a way to synchronize events across timezones. Splitting the year into A-Z creates periods with gradations, and further heirarchical division is quite effective in creating smaller 'addresses' in time.
Numeric characters were interwoven to enable verbal chunking and to avoid spelling words.
Any other characteristics of Alphadec were not designed; they emerged from this arithmetic and associated semantics.
Alphadec is well-applicable to time because of the nature of an 'Year':
- Cyclical: The ends of the scale overlap. When 2024 is 100% done we're back to 0% done in 2025
- Relational: Multiple reference points are discussed at the same time, e.g. 'the movie is coming out three periods from now'
Interestingly, the Maidenhead Locator System is quite similar to Alphadec and has both properties: geocodes are cyclical and relational.
Compass bearings have the same properties—and indeed, Alphadec functions as an approximate compass for Earth's orbit around the sun.
- If you visualize Alphadec as a radial clock, A0A0 sits at 0 degrees in the circle, and N0A0 is at 180 degrees. Period A contains the moment when Earth is closest to the Sun (perihelion), while Period N marks the time when Earth is furthest (aphelion).
We can contrast these properties by using altitude as a foil. Why would altitude not benefit from an Alphadec-like quantization? Because altitude is linear: there is a fixed zero and no "wrap-around." Additionally, altitude is absolute: when you are climbing from 5,000 ft to 10,000 ft, the starting point becomes irrelevant.
A color wheel is another helpful contrast: although it is cyclical, points on the wheel are usually discussed independently. Referring to colors in a navigational or hierarchical manner is uncommon.
An ISO time like 4:30pm represents progress in sunrise and sunset. This is useful if you are laboring in a field: when sunlight fades, you are done for the day. However, in most contemporary contexts, the clock is a marker of events decoupled from the sun. "We have three hours to get ready and reach the wedding venue." Alphadec is literally a measure of such 'time elapsed' and 'time remaining'.
The scale of Alphadec units (a ~34 hr arc and ~1hr20 min bar) can be used by a person to plan their day.
The Period unit exhibits alignment with the Earth's orbit.
| Period | Event | Description |
|---|---|---|
| A | Perihelion | Earth's closest approach to the Sun (Early January) |
| F | March Equinox | Spring in the Northern Hemisphere and autumn in the Southern Hemisphere |
| M | June Solstice | Summer in the Northern Hemisphere, winter in the Southern Hemisphere |
| N | Aphelion | Earth's farthest distance from the Sun (Early July) |
| S | September Equinox | Autumn in the Northern Hemisphere and spring in the Southern Hemisphere |
| Z | December Solstice | Winter in the Northern Hemisphere, summer in the Southern Hemisphere |
These 16 AlphaDec coordinates represent exact fractional positions in the year where the encoding aligns perfectly with millisecond boundaries (offset _000000).
The alignments are a result of the mathematical relationship between the total number of seconds in a common year (31,536,000) and the total number of AlphaDec beats (67,600). The Greatest Common Divisor (GCD) of these two numbers is 400.
Any fraction 1/D, where D is a divisor of 400, will create a set of alignment points. This includes fractions like 1/100 (1% intervals), 1/20 (5% intervals), and even 1/400 (0.25% intervals), which yields a total of 400 perfect alignment points throughout the year. These 16 points are a subset.
| % of Year | AlphaDec | 2025 UTC (Common) | 2024 UTC (Leap) |
|---|---|---|---|
| 0% | A0A0_000000 |
Jan 1, 00:00 | Jan 1, 00:00 |
| 6.25% | B6G5_000000 |
Jan 23, 19:30 | Jan 23, 21:00 |
| 12.5% | D2N0_000000 |
Feb 15, 15:00 | Feb 15, 18:00 |
| 18.75% | E8T5_000000 |
Mar 10, 10:30 | Mar 9, 15:00 |
| 25% | G5A0_000000 |
Apr 2, 06:00 | Apr 1, 12:00 |
| 31.25% | I1G5_000000 |
Apr 25, 01:30 | Apr 24, 09:00 |
| 37.5% | J7N0_000000 |
May 17, 21:00 | May 17, 06:00 |
| 43.75% | L3T5_000000 |
Jun 9, 16:30 | Jun 9, 03:00 |
| 50% | N0A0_000000 |
Jul 2, 12:00 | Jul 2, 00:00 |
| 56.25% | O6G5_000000 |
Jul 25, 07:30 | Jul 24, 21:00 |
| 62.5% | Q2N0_000000 |
Aug 17, 03:00 | Aug 16, 18:00 |
| 68.75% | R8T5_000000 |
Sep 8, 22:30 | Sep 8, 15:00 |
| 75% | T5A0_000000 |
Oct 1, 18:00 | Oct 1, 12:00 |
| 81.25% | V1G5_000000 |
Oct 24, 13:30 | Oct 24, 09:00 |
| 87.5% | W7N0_000000 |
Nov 16, 09:00 | Nov 16, 06:00 |
| 93.75% | Y3T5_000000 |
Dec 9, 04:30 | Dec 9, 03:00 |
Note: While these points encode with perfect _000000 offsets, they still decode with the standard -1ms precision loss due to systematic flooring in the decoder. These represent the rare moments where AlphaDec's rational fractions of the year align exactly with integer millisecond values.
| AlphaDec | 2024 ISO (Leap Yr) | 2025 ISO | Drift |
|---|---|---|---|
A0A0 |
2024-01-01T00:00:00.000Z |
2025-01-01T00:00:00.000Z |
0 min |
B0A0 |
2024-01-15T01:50:46.153Z |
2025-01-15T00:55:23.076Z |
+55 min |
C0A0 |
2024-01-29T03:41:32.307Z |
2025-01-29T01:50:46.153Z |
+1h 51m |
D0A0 |
2024-02-12T05:32:18.461Z |
2025-02-12T02:46:09.230Z |
+2h 46m |
E0A0 |
2024-02-26T07:23:04.615Z |
2025-02-26T03:41:32.307Z |
+3h 42m |
F0A0 |
2024-03-11T09:13:50.769Z |
2025-03-12T04:36:55.384Z |
+4h 37m |
G0A0 |
2024-03-25T11:04:36.923Z |
2025-03-26T05:32:18.461Z |
+5h 32m |
H0A0 |
2024-04-08T12:55:23.076Z |
2025-04-09T06:27:41.538Z |
+6h 28m |
I0A0 |
2024-04-22T14:46:09.230Z |
2025-04-23T07:23:04.615Z |
+7h 23m |
J0A0 |
2024-05-06T16:36:55.384Z |
2025-05-07T08:18:27.692Z |
+8h 18m |
K0A0 |
2024-05-20T18:27:41.538Z |
2025-05-21T09:13:50.769Z |
+9h 14m |
L0A0 |
2024-06-03T20:18:27.692Z |
2025-06-04T10:09:13.846Z |
+10h 9m |
M0A0 |
2024-06-17T22:09:13.846Z |
2025-06-18T11:04:36.923Z |
+11h 5m |
N0A0 |
2024-07-01T23:59:59.999Z |
2025-07-02T12:00:00.000Z |
+12h 0m ⭐ |
O0A0 |
2024-07-16T01:50:46.153Z |
2025-07-16T12:55:23.076Z |
+11h 5m |
P0A0 |
2024-07-30T03:41:32.307Z |
2025-07-30T13:50:46.153Z |
+10h 9m |
Q0A0 |
2024-08-13T05:32:18.461Z |
2025-08-13T14:46:09.230Z |
+9h 14m |
R0A0 |
2024-08-27T07:23:04.615Z |
2025-08-27T15:41:32.307Z |
+8h 18m |
S0A0 |
2024-09-10T09:13:50.769Z |
2025-09-10T16:36:55.384Z |
+7h 23m |
T0A0 |
2024-09-24T11:04:36.923Z |
2025-09-24T17:32:18.461Z |
+6h 28m |
U0A0 |
2024-10-08T12:55:23.076Z |
2025-10-08T18:27:41.538Z |
+5h 32m |
V0A0 |
2024-10-22T14:46:09.230Z |
2025-10-22T19:23:04.615Z |
+4h 37m |
W0A0 |
2024-11-05T16:36:55.384Z |
2025-11-05T20:18:27.692Z |
+3h 42m |
X0A0 |
2024-11-19T18:27:41.538Z |
2025-11-19T21:13:50.769Z |
+2h 46m |
Y0A0 |
2024-12-03T20:18:27.692Z |
2025-12-03T22:09:13.846Z |
+1h 51m |
Z0A0 |
2024-12-17T22:09:13.846Z |
2025-12-17T23:04:36.923Z |
+55 min |
Designed by Firas Durri • https://twitter.com/firasd • https://www.linkedin.com/in/firasd
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for alphadec
Similar Open Source Tools
alphadec
Alphadec is a timezone-agnostic, human-readable time format designed for global timestamp synchronization. It encodes any UTC timestamp into a structured string that is lexically sortable, time-series friendly, human-readable, and compact. Alphadec serves as a powerful primitive for AI models to understand the passage of time and offers emergent properties like rhythmic timestamps, chronological ID fragments, and version labels. It is AI-friendly, database-friendly, and collision-free with ISO time formats. Alphadec's canonical format consists of parts representing the UTC year, periods, arcs, bars, beats, and milliseconds offset, allowing for efficient time-range queries and index stability.

sycamore
Sycamore is a conversational search and analytics platform for complex unstructured data, such as documents, presentations, transcripts, embedded tables, and internal knowledge repositories. It retrieves and synthesizes high-quality answers through bringing AI to data preparation, indexing, and retrieval. Sycamore makes it easy to prepare unstructured data for search and analytics, providing a toolkit for data cleaning, information extraction, enrichment, summarization, and generation of vector embeddings that encapsulate the semantics of data. Sycamore uses your choice of generative AI models to make these operations simple and effective, and it enables quick experimentation and iteration. Additionally, Sycamore uses OpenSearch for indexing, enabling hybrid (vector + keyword) search, retrieval-augmented generation (RAG) pipelining, filtering, analytical functions, conversational memory, and other features to improve information retrieval.
suql
SUQL (Structured and Unstructured Query Language) is a tool that augments SQL with free text primitives for building chatbots that can interact with relational data sources containing both structured and unstructured information. It seamlessly integrates retrieval models, large language models (LLMs), and traditional SQL to provide a clean interface for hybrid data access. SUQL supports optimizations to minimize expensive LLM calls, scalability to large databases with PostgreSQL, and general SQL operations like JOINs and GROUP BYs.

Main
This repository contains material related to the new book _Synthetic Data and Generative AI_ by the author, including code for NoGAN, DeepResampling, and NoGAN_Hellinger. NoGAN is a tabular data synthesizer that outperforms GenAI methods in terms of speed and results, utilizing state-of-the-art quality metrics. DeepResampling is a fast NoGAN based on resampling and Bayesian Models with hyperparameter auto-tuning. NoGAN_Hellinger combines NoGAN and DeepResampling with the Hellinger model evaluation metric.
rag-chatbot
The RAG ChatBot project combines Lama.cpp, Chroma, and Streamlit to build a Conversation-aware Chatbot and a Retrieval-augmented generation (RAG) ChatBot. The RAG Chatbot works by taking a collection of Markdown files as input and provides answers based on the context provided by those files. It utilizes a Memory Builder component to load Markdown pages, divide them into sections, calculate embeddings, and save them in an embedding database. The chatbot retrieves relevant sections from the database, rewrites questions for optimal retrieval, and generates answers using a local language model. It also remembers previous interactions for more accurate responses. Various strategies are implemented to deal with context overflows, including creating and refining context, hierarchical summarization, and async hierarchical summarization.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).
FastGPT
FastGPT is a knowledge base Q&A system based on the LLM large language model, providing out-of-the-box data processing, model calling and other capabilities. At the same time, you can use Flow to visually arrange workflows to achieve complex Q&A scenarios!
Sarvadnya
Sarvadnya is a repository focused on interfacing custom data using Large Language Models (LLMs) through Proof-of-Concepts (PoCs) like Retrieval Augmented Generation (RAG) and Fine-Tuning. It aims to enable domain adaptation for LLMs to answer on user-specific corpora. The repository also covers topics such as Indic-languages models, 3D World Simulations, Knowledge Graphs Generation, Signal Processing, Drones, UAV Image Processing, and Floor Plan Segmentation. It provides insights into building chatbots of various modalities, preparing videos, and creating content for different platforms like Medium, LinkedIn, and YouTube. The tech stacks involved range from enterprise solutions like Google Doc AI and Microsoft Azure Language AI Services to open-source tools like Langchain and HuggingFace.

NeMo-Guardrails
NeMo Guardrails is an open-source toolkit for easily adding _programmable guardrails_ to LLM-based conversational applications. Guardrails (or "rails" for short) are specific ways of controlling the output of a large language model, such as not talking about politics, responding in a particular way to specific user requests, following a predefined dialog path, using a particular language style, extracting structured data, and more.
yek
Yek is a fast Rust-based tool designed to read text-based files in a repository or directory, chunk them, and serialize them for Large Language Models (LLM) consumption. It utilizes .gitignore rules to skip unwanted files, Git history to infer important files, and additional ignore patterns. Yek splits content into chunks based on token count or byte size, supports processing multiple directories, and can stream content when output is piped. It is configurable via a 'yek.toml' file and prioritizes important files at the end of the output.
RWKV_APP
RWKV App is an experimental application that enables users to run Large Language Models (LLMs) offline on their edge devices. It offers a privacy-first, on-device LLM experience for everyday devices. Users can engage in multi-turn conversations, text-to-speech, visual understanding, and more, all without requiring an internet connection. The app supports switching between different models, running locally without internet, and exploring various AI tasks such as chat, speech generation, and visual understanding. It is built using Flutter and Dart FFI for cross-platform compatibility and efficient communication with the C++ inference engine. The roadmap includes integrating features into the RWKV Chat app, supporting more model weights, hardware, operating systems, and devices.
sglang
SGLang is a structured generation language designed for large language models (LLMs). It makes your interaction with LLMs faster and more controllable by co-designing the frontend language and the runtime system. The core features of SGLang include: - **A Flexible Front-End Language**: This allows for easy programming of LLM applications with multiple chained generation calls, advanced prompting techniques, control flow, multiple modalities, parallelism, and external interaction. - **A High-Performance Runtime with RadixAttention**: This feature significantly accelerates the execution of complex LLM programs by automatic KV cache reuse across multiple calls. It also supports other common techniques like continuous batching and tensor parallelism.
FastFlowLM
FastFlowLM is a Python library for efficient and scalable language model inference. It provides a high-performance implementation of language model scoring using n-gram language models. The library is designed to handle large-scale text data and can be easily integrated into natural language processing pipelines for tasks such as text generation, speech recognition, and machine translation. FastFlowLM is optimized for speed and memory efficiency, making it suitable for both research and production environments.
NovelForge
NovelForge is an AI-assisted writing tool with the potential for creating long-form content of millions of words. It offers a solution that combines world-building, structured content generation, and consistency maintenance. The tool is built around four core concepts: modular 'cards', customizable 'dynamic output models', flexible 'context injection', and consistency assurance through a 'knowledge graph'. It provides a highly structured and configurable writing environment, inspired by the Snowflake Method, allowing users to create and organize their content in a tree-like structure. NovelForge is highly customizable and extensible, allowing users to tailor their writing workflow to their specific needs.

llms-tools
The 'llms-tools' repository is a comprehensive collection of AI tools, open-source projects, and research related to Large Language Models (LLMs) and Chatbots. It covers a wide range of topics such as AI in various domains, open-source models, chats & assistants, visual language models, evaluation tools, libraries, devices, income models, text-to-image, computer vision, audio & speech, code & math, games, robotics, typography, bio & med, military, climate, finance, and presentation. The repository provides valuable resources for researchers, developers, and enthusiasts interested in exploring the capabilities of LLMs and related technologies.
llms-from-scratch-rs
This project provides Rust code that follows the text 'Build An LLM From Scratch' by Sebastian Raschka. It translates PyTorch code into Rust using the Candle crate, aiming to build a GPT-style LLM. Users can clone the repo, run examples/exercises, and access the same datasets as in the book. The project includes chapters on understanding large language models, working with text data, coding attention mechanisms, implementing a GPT model, pretraining unlabeled data, fine-tuning for classification, and fine-tuning to follow instructions.
For similar tasks
alphadec
Alphadec is a timezone-agnostic, human-readable time format designed for global timestamp synchronization. It encodes any UTC timestamp into a structured string that is lexically sortable, time-series friendly, human-readable, and compact. Alphadec serves as a powerful primitive for AI models to understand the passage of time and offers emergent properties like rhythmic timestamps, chronological ID fragments, and version labels. It is AI-friendly, database-friendly, and collision-free with ISO time formats. Alphadec's canonical format consists of parts representing the UTC year, periods, arcs, bars, beats, and milliseconds offset, allowing for efficient time-range queries and index stability.
memsearch
Memsearch is a tool that allows users to give their AI agents persistent memory in a few lines of code. It enables users to write memories as markdown and search them semantically. Inspired by OpenClaw's markdown-first memory architecture, Memsearch is pluggable into any agent framework. The tool offers features like smart deduplication, live sync, and a ready-made Claude Code plugin for building agent memory.
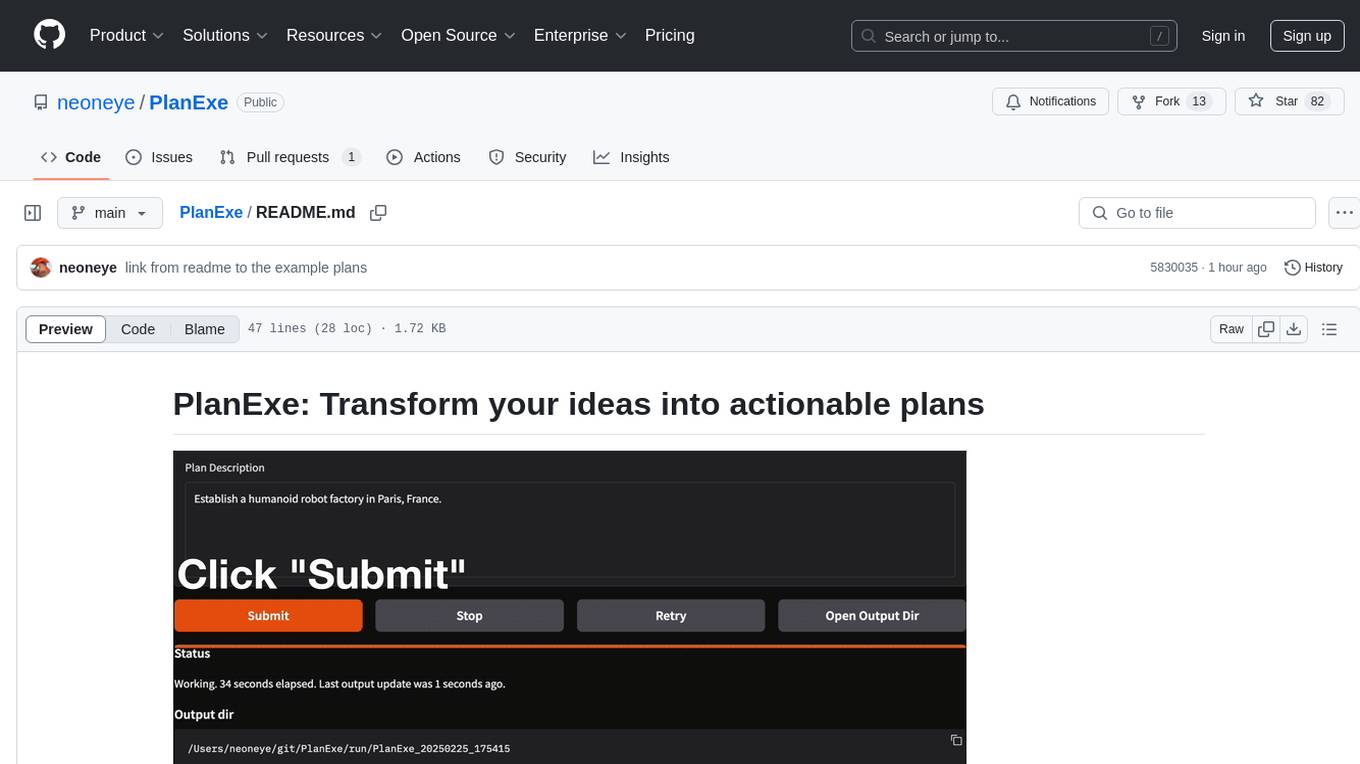
PlanExe
PlanExe is a planning AI tool that helps users generate detailed plans based on vague descriptions. It offers a Gradio-based web interface for easy input and output. Users can choose between running models in the cloud or locally on a high-end computer. The tool aims to provide a straightforward path to planning various tasks efficiently.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.