
Awesome-GUI-Agents
A curated collection of resources, tools, and frameworks for developing GUI Agents.
Stars: 303
Awesome-GUI-Agents is a curated list for GUI Agents, focusing on updates, contributing guidelines, modules of GUI Agents, paper lists, datasets, and benchmarks. It provides a comprehensive overview of research papers, models, and projects related to GUI automation, reinforcement learning, and grounding. The repository covers a wide range of topics such as perception, exploration, planning, interaction, memory, online reinforcement learning, GUI navigation benchmarks, and more.
README:
# Awesome-GUI-Agents
A curated list for GUI Agents
Table Content:

🚀 Updates
-
On November 23, 2025, We have summarized and analyzed the AAAI 2026 accepted papers on GUI agents. Check it out.
-
On November 14, 2025, We have summarized and analyzed the ICLR 2026 papers on GUI. Check it out.
-
On November 8, 2025, we are happy that our two papers, GUI-G² and GUI-RC, were accepted by AAAI 2026.
-
October 28, 2025: We have summarized the paper on GUI Agent from ICLR 2026. Please refer to ICLR 2026
-
September 16, 2025: We released our new paper on GUI Automation: UI-S1: Advancing GUI Automation via Semi-online Reinforcement Learning
-
Augest 18, 2025: We open-source our GUI-G2-3B and GUI-G2-7B models. Try it out.
-
Augest 14, 2025: We released our new paper on GUI Grounding: Test-Time Reinforcement Learning for GUI Grounding via Region Consistency
-
August 1, 2025: We will add a weekly section summarizing GUI Agent research papers. Stay tuned!
-
July 22, 2025: We released our new paper on GUI Grounding: GUI-G²: Gaussian Reward Modeling for GUI Grounding. Check it out!
-
April 22, 2025: We're excited to announce that our paper has been published and is now available on arXiv. We welcome your attention and feedback! Check it out. We updated GUI Agents List based on RL (R1 Style).
-
April 2, 2025: We have already uploaded the paper to arXiv, please wait for some time. Meanwhile, we will keep updating this repo.
-
March 24, 2025: We updated the repository and released our comprehensive survey on GUI Agents.
If you'd like to include your paper, or need to update any details such as github repo information or code URLs, please feel free to submit a pull request.
📚 2025-8-25 to 2025-8-29 📚
Weekly Paper List:
- Structuring GUI Elements through Vision Language Models: Towards Action Space Generation
- WEBSIGHT: A Vision-First Architecture for Robust Web Agents
- PerPilot: Personalizing VLM-based Mobile Agents via Memory and Exploration
- UItron: Foundational GUI Agent with Advanced Perception and Planning
📚 2025-8-18 to 2025-8-22 📚
Weekly Paper List:
- CRAFT-GUI: Curriculum-Reinforced Agent For GUI Tasks
- COMPUTERRL: SCALING END-TO-END ONLINE REINFORCEMENT LEARNING FOR COMPUTER USE AGENTS
- Mobile-Agent-v3: Foundamental Agents for GUI Automation
- SWIRL: A STAGED WORKFLOW FOR INTERLEAVED REINFORCEMENT LEARNING IN MOBILE GUI CONTROL
📚 2025-8-11 to 2025-8-15 📚
Weekly Paper List:
- OPENCUA: Open Foundations for Computer-Use Agents
- Test-Time Reinforcement Learning for GUI Grounding via Region Consistency
- WinSpot: A Windows GUI Grounding Benchmark with Multimodal Large Language Models
- InfiGUI-G1: Advancing GUI Grounding with Adaptive Exploration Policy Optimization
- UI-Venus Technical Report: Building High-performance UI Agents with RFT
We have divided GUI Agents into four modules: perception, exploration, planning, and interaction, as shown below:

We have dedicated a separate chapter to datasets and benchmarks for GUI Agents, with all content presented in chronological order.
POINTS-GUI-G: GUI-Grounding Journey
OmegaUse: Building a General-Purpose GUI Agent for Autonomous Task Execution (BaiDu)
MAI-UI Technical Report: Real-World Centric Foundation GUI Agents
Fara-7B: An Efficient Agentic Model for Computer Use
Game-TARS: Pretrained Foundation Models for Scalable Generalist Multimodal Game Agents
UltraCUA: A Foundation Model for Computer Use Agents with Hybrid Action
Surfer 2: The Next Generation of Cross-Platform Computer-Use Agents [bolg]
Holo1.5 - Open Foundation Models for Computer Use Agents [bolg]
AgentS3: THE UNREASONABLE EFFECTIVENESS OF SCALING AGENTS FOR COMPUTER USE
Mano Technical Report
SCALECUA: SCALING OPEN-SOURCE COMPUTER USE AGENTS WITH CROSS-PLATFORM DATA
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
CODA: COORDINATING THE CEREBRUM AND CEREBELLUM FOR A DUAL-BRAIN COMPUTER USE AGENT WITH DECOUPLED REINFORCEMENT LEARNING.
UItron: Foundational GUI Agent with Advanced Perception and Planning
Mobile-Agent-v3: Foundamental Agents for GUI Automation
UI-Venus Technical Report: Building High-performance UI Agents with RFT
OPENCUA: Open Foundations for Computer-Use Agents
MAGICGUI: A FOUNDATIONAL MOBILE GUI AGENT WITH SCALABLE DATA PIPELINE AND REINFORCEMENT FINE-TUNING
Magentic-UI: Towards Human-in-the-loop Agentic Systems
Phi-Ground Tech Report: Advancing Perception in GUI Grounding
MobileGUI-RL: Advancing Mobile GUI Agent through Reinforcement Learning in Online Environment
GTA1: GUI Test-time Scaling Agent
AgentCPM-GUI: Building Mobile-Use Agents with Reinforcement Fine-Tuning
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
1、ShowUI-π: Flow-based Generative Models as GUI Dexterous Hands
1、MobileWorldBench: Towards Semantic World Modeling For Mobile Agents
2、A Generative Visual GUI World Model for App Agents
3、MobileDreamer: Generative Sketch World Model for GUI Agent
4、Generative Visual Code Mobile World Models
2026-02-09: MemGUI-Bench: Benchmarking Memory of Mobile GUI Agents in Dynamic Environments
2025-02-06: UI-Mem: Self-Evolving Experience Memory for Online Reinforcement Learning in Mobile GUI Agents
2025-12-24: EchoTrail-GUI: Building Actionable Memory for GUI Agents via Critic-Guided Self-Exploration
2025-10-28: MGA: Memory-Driven GUI Agent for Observation-Centric Interaction
2025-10-13: AUTO-SCALING CONTINUOUS MEMORY FOR GUI AGENT
MobileRL: Online Agentic Reinforcement Learning for Mobile GUI Agents
EFFICIENT MULTI-TURN RL FOR GUI AGENTS VIA DECOUPLED TRAINING AND ADAPTIVE DATA CURATION
UI-S1: Advancing GUI Automation via Semi-online Reinforcement Learning
MOBILERL: ADVANCING MOBILE USE AGENTS WITH ADAPTIVE ONLINE REINFORCEMENT LEARNING
COMPUTERRL: SCALING END-TO-END ONLINE REINFORCEMENT LEARNING FOR COMPUTER USE AGENTS
Mobile-Agent-v3: Foundamental Agents for GUI Automation
MobileWorldBench: Towards Semantic World Modeling For Mobile Agents
Modular and Multi-Path-Aware Offline Benchmarking for Mobile GUI Agents
FlashAdventure: A Benchmark for GUI Agents Solving Full Story Arcs in Diverse Adventure Games [Game]
MemGUI-Bench: Benchmarking Memory of Mobile GUI Agents in Dynamic Environments
2025-09: MAS-Bench: A Unified Benchmark for Shortcut-Augmented Hybrid Mobile GUI Agents
2025-08: UI-NEXUS: Atomic-to-Compositional Generalization for Mobile Agents with A New Benchmark and Scheduling System
2025-07: MMBENCH-GUI: HIERARCHICAL MULTI-PLATFORM EVALUATION FRAMEWORK FOR GUI AGENTS We will organize these points later:
1、AndroidWorld
2、AndroidControl
3、GUI-Odyssey
4、Amex
5、WebArena
6、WebSRC_v1.0
7、Mind2Web 2
8、... stay tuned
1、ShowUI: One Vision-Language-Action Model for GUI Visual Agent
2、ShowUI-Aloha: Human-Taught GUI Agent
3、ShowUI-π: Flow-based Generative Models as GUI Dexterous Hands
1、AUTO-Explorer: Automated Data Collection for GUI Agent
2、GUI-ReWalk: Massive Data Generation for GUI Agent via Stochastic Exploration and Intent-Aware Reasoning
2025-12 GUI Exploration Lab: Enhancing Screen Navigation in Agents via Multi-Turn Reinforcement Learning [nips 2025]
2025-10: EFFICIENT MULTI-TURN RL FOR GUI AGENTS VIA DECOUPLED TRAINING AND ADAPTIVE DATA CURATION
2025-09: UI-S1: Advancing GUI Automation via Semi-online Reinforcement Learning
2025-05: ARPO: End-to-End Policy Optimization for GUI Agents with Experience Replay
2025-05: WEBAGENT-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning
1、Attention-driven GUI Grounding: Leveraging Pretrained Multimodal Large Language Models without Fine-Tuning [2025AAAI]
2、MEGA-GUI: MULTI-STAGE ENHANCED GROUNDING AGENTS FOR GUI ELEMENTS [2025-11-18]
3、DiMo-GUI: Advancing Test-time Scaling in GUI Grounding via Modality-Aware Visual Reasoning [EMNLP 2025]
4、Visual Test-time Scaling for GUI Agent Grounding [ICCV 2025]
5、Chain-of-Ground: Improving GUI Grounding via Iterative Reasoning and Reference Feedback
6、Improved GUI Grounding via Iterative Narrowing
7、Zoom in, Click out: Unlocking and Evaluating the Potential of Zooming for GUI Grounding
8、MVP: Multiple View Prediction Improves GUI Grounding
9、Trifuse: Enhancing Attention-Based GUI Grounding via Multimodal Fusion
2025-6-02: ZeroGUI: Automating Online GUI Learning at Zero Human Cost
Beyond Clicking: A Step Towards Generalist GUI Grounding via Text Dragging Drag Datasets of CUA
Using GUI Agent for Electronic Design Automation [CAD]
VenusBench-GD: A Comprehensive Multi-Platform GUI Benchmark for Diverse Grounding Tasks
WinSpot: A Windows GUI Grounding Benchmark with Multimodal Large Language Models
UI-Vision: A Desktop-centric GUI Benchmark for Visual Perception and Interaction [2025ICML]
ScreenSpot: SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents
ScreenSpot-V2: OS-ATLAS: Foundation Action Model for Generalist GUI Agents
ScreenSpot-Pro: ScreenSpot-Pro: GUI Grounding for Professional High-Resolution Computer Use
CA-GUI: AgentCPM-GUI: An on-device GUI agent for operating Android apps, enhancing reasoning ability with reinforcement fine-tuning for efficient task execution.
desc: using video to assist gui agent learn
Scalable Video-to-Dataset Generation for Cross-Platform Mobile Agents
ASSISTGUI: Task-Oriented Desktop Graphical User Interface Automation
VideoGUI: A Benchmark for GUI Automation from Instructional Videos
Mobile-Agent-V: A Video-Guided Approach for Effortless and Efficient Operational Knowledge Injection in Mobile Automation
Watch and Learn: Learning to Use Computers from Online Videos
1、Test-Time Reinforcement Learning for GUI Grounding via Region Consistency
2、GTA1: GUI Test-time Scaling Agent
3、DiMo-GUI: Advancing Test-time Scaling in GUI Grounding via Modality-Aware Visual Reasoning [2025 EMNLP]
4、Improved GUI Grounding via Iterative Narrowing
5、Visual Test-time Scaling for GUI Agent Grounding
6、UI-AGILE: Advancing GUI Agents with Effective Reinforcement Learning and Precise Inference-Time Grounding
7、GENERALIST SCANNER MEETS SPECIALIST LOCATOR: A SYNERGISTIC COARSE-TO-FINE FRAMEWORK FOR ROBUST GUI GROUNDING
2026-1-08: FOCUSUI: Efficient UI Grounding via Position-Preserving Visual Token Selection
2025-10-24: Mixing Importance with Diversity: Joint Optimization for KV Cache Compression in Large Vision-Language Model
2025-10-01: GUI-KV: EFFICIENT GUI AGENTS VIA KV CACHE WITH SPATIO-TEMPORAL AWARENESS
2026-1-20: Continual GUI Agents
2026-1-12: From Off-Policy to On-Policy: Enhancing GUI Agents via Bi-level Expert-to-Policy Assimilation
2025-11-27: Training High-Level Schedulers with Execution-Feedback Reinforcement Learning for Long-Horizon GUI Automation
2025-11-17: Co-EPG: A Framework for Co-Evolution of Planning and Grounding in Autonomous GUI Agents
2025-11-12: GROUNDING COMPUTER USE AGENTS ON HUMAN DEMONSTRATIONS (open sourced training data)
2025-11-3: HYPERCLICK: ADVANCING RELIABLE GUI GROUNDING VIA UNCERTAINTY CALIBRATION
2025-11-3: GUI-Rise: Structured Reasoning and History Summarization for GUI Navigation
2025-10-24: UI-INS: ENHANCING GUI GROUNDING WITH MULTIPERSPECTIVE INSTRUCTION-AS-REASONING
2025-10-22: AndroidControl-Curated: Revealing the True Potential of GUI Agents through Benchmark Purification
2025-10-13: GUI-SHIFT: ENHANCING VLM-BASED GUI AGENTS THROUGH SELF-SUPERVISED REINFORCEMENT LEARNING
2025-10-04: GUI-SPOTLIGHT: ADAPTIVE ITERATIVE FOCUS REFINEMENT FOR ENHANCED GUI VISUAL GROUNDING
2025-9-30: Ferret-UI Lite: Lessons from Building Small On-Device GUI Agents
2025-9-30: UI-UG: A Unified MLLM for UI Understanding and Generation
2025-9-28: GUI-SHEPHERD: RELIABLE PROCESS REWARD AND VERIFICATION FOR LONG-SEQUENCE GUI TASKS
2025-9-28: EFFICIENT MULTI-TURN RL FOR GUI AGENTS VIA DECOUPLED TRAINING AND ADAPTIVE DATA CURATION
2025-9-25: LEARNING GUI GROUNDING WITH SPATIAL REASONING FROM VISUAL FEEDBACK
2025-9-23: Orcust: Stepwise-Feedback Reinforcement Learning for GUI Agent
2025-9-22: GUI-ARP: ENHANCING GROUNDING WITH ADAPTIVE REGION PERCEPTION FOR GUI AGENTS
2025-9-22: BTL-UI: Blink-Think-Link Reasoning Model for GUI Agent (2025 NIPS)
2025-9-16: UI-S1: Advancing GUI Automation via Semi-online Reinforcement Learning
2025-9-06: WebExplorer: Explore and Evolve for Training Long-Horizon Web Agents
2025-9-05: Learning Active Perception via Self-Evolving Preference Optimization for GUI Grounding
2025-8-28: SWIRL: A STAGED WORKFLOW FOR INTERLEAVED REINFORCEMENT LEARNING IN MOBILE GUI CONTROL
2025-8-20: CODA: COORDINATING THE CEREBRUM AND CEREBELLUM FOR A DUAL-BRAIN COMPUTER USE AGENT WITH DECOUPLED REINFORCEMENT LEARNING.
2025-8-20: COMPUTERRL: SCALING END-TO-END ONLINE REINFORCEMENT LEARNING FOR COMPUTER USE AGENTS
2025-8-18: CRAFT-GUI: Curriculum-Reinforced Agent For GUI Tasks
2025-8-11: InfiGUI-G1: Advancing GUI Grounding with Adaptive Exploration Policy Optimization
2025-8-06: SEA: Self-Evolution Agent with Step-wise Reward for Computer Use
2025-8-06: NaviMaster: Learning a Unified Policy for GUI and Embodied Navigation Tasks
2025-8-04: GuirlVG: Incentivize GUI Visual Grounding via Empirical Exploration on Reinforcement Learning
2025-7-22: GUI-G²: Gaussian Reward Modeling for GUI Grounding
2025-7-09: MobileGUI-RL: Advancing Mobile GUI Agent through Reinforcement Learning in Online Environment
2025-7-09: GTA1: GUI Test-time Scaling Agent
2025-6-25: Mobile-R1: Towards Interactive Reinforcement Learning for VLM-Based Mobile Agent via Task-Level Rewards
2025-6-13: LPO: Towards Accurate GUI Agent Interaction via Location Preference Optimization
2025-5-29: Grounded Reinforcement Learning for Visual Reasoning
2025-5-22: WEBAGENT-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning
2025-6-06: Look Before You Leap: A GUI-Critic-R1 Model for Pre-Operative Error Diagnosis in GUI Automation
2025-5-21: GUI-G1: Understanding R1-Zero-Like Training for Visual Grounding in GUI Agents
2025-5-18: Enhancing Visual Grounding for GUI Agents via Self-Evolutionary Reinforcement Learning
2025-4-19: InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reasoners
2025-4-14: GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
2025-3-27: UI-R1: Enhancing Action Prediction of GUI Agents by Reinforcement Learning
2025-10 MLLM as a UI Judge: Benchmarking Multimodal LLMs for Predicting Human Perception of User Interfaces
2025-10 ReInAgent: A Context-Aware GUI Agent Enabling Human-in-the-Loop Mobile Task Navigation
2025-10 IMPROVING GUI GROUNDING WITH EXPLICIT POSITION-TO-COORDINATE MAPPING
2025-10 PAL-UI: PLANNING WITH ACTIVE LOOK-BACK FOR VISION-BASED GUI AGENTS (SFT)
2025-10 AGENT-SCANKIT: UNRAVELING MEMORY AND REASONING OF MULTIMODAL AGENTS VIA SENSITIVITY PERTURBATIONS
2025-9 Log2Plan: An Adaptive GUI Automation Framework Integrated with Task Mining Approach
2025-9 Retrieval-augmented GUI Agents with Generative Guidelines
2025-9 Instruction Agent: Enhancing Agent with Expert Demonstration
2025-9 Learning Active Perception via Self-Evolving Preference Optimization for GUI Grounding
2025-8 SWIRL: A STAGED WORKFLOW FOR INTERLEAVED REINFORCEMENT LEARNING IN MOBILE GUI CONTROL
2025-8 PerPilot: Personalizing VLM-based Mobile Agents via Memory and Exploration
2025-8 WEBSIGHT: A Vision-First Architecture for Robust Web Agents
2025-8 Structuring GUI Elements through Vision Language Models: Towards Action Space Generation
2025-8 You Don’t Know Until You Click: Automated GUI Testing for Production-Ready Software Evaluation
2025-8 Browsing Like Human: A Multimodal Web Agent with Experiential Fast-and-Slow Thinking [2025ACL]
2025-8 Uncertainty-Aware GUI Agent: Adaptive Perception through Component Recommendation and Human-in-the-Loop Refinement
2025-7 ZonUI-3B: A Lightweight Vision–Language Model for Cross-Resolution GUI Grounding
2025-7 Qwen-GUI-3B: A Lightweight Vision–Language Model for Cross-Resolution GUI Grounding
2025-6 Understanding GUI Agent Localization Biases through Logit Sharpness
2025-6 DiMo-GUI: Advancing Test-time Scaling in GUI Grounding via Modality-Aware Visual Reasoning
2025-6 GUI-Actor: Coordinate-Free Visual Grounding for GUI Agents Github Paper
2025-5 Advancing Mobile GUI Agents: A Verifier-Driven Approach to Practical Deployment
2025-5 UI-Genie: A Self-Improving Approach for Iteratively Boosting MLLM-based Mobile GUI Agents
2025-5 SpiritSight Agent: Advanced GUI Agent with One Look (2025CVPR)
| Title & Time | Introduction | Links |
|---|---|---|
| Less is More: Empowering GUI Agent with Context-Aware Simplification (2025-7, 2025ICCV) |  |
Github Paper |
| Mirage-1: Augmenting and Updating GUI Agent with Hierarchical Multimodal Skills (2025-6) |  |
Github Paper |
| GUI-Explorer: Autonomous Exploration and Mining of Transition-aware Knowledge for GUI Agent (2025-5, 2025ACL) |  |
Github Paper |
| MobileA^3gent: Training Mobile GUI Agents Using Decentralized Self-Sourced Data from Diverse Users (2025-5) |  |
Github Paper |
| Advancing Mobile GUI Agents: A Verifier-Driven Approach to Practical Deployment (2025-3) |  |
Github Paper |
| API Agents vs. GUI Agents: Divergence and Convergence (2025-3) |  |
Github Paper |
| AppAgentX: Evolving GUI Agents as Proficient Smartphone Users (2025-3) |  |
Github Paper |
| Think Twice, Click Once: Enhancing GUI Grounding via Fast and Slow Systems (2025-3) |  |
Github Paper |
| UI-TARS: Pioneering Automated GUI Interaction with Native Agents (2025-2) |  |
Github Paper |
| Mobile-Agent-E: Self-Evolving Mobile Assistant for Complex Tasks (2025-1) |  |
Github Paper |
| InfiGUIAgent: A Multimodal Generalist GUI Agent with Native Reasoning and Reflection (2025-1) |  |
Github Paper |
| OS-Genesis: Automating GUI Agent Trajectory Construction via Reverse Task Synthesis (2024-12) |  |
Github Paper |
| PC Agent: While You Sleep, AI Works - A Cognitive Journey into Digital World (2024-12) |  |
Github Paper |
| Aria-UI: Visual Grounding for GUI Instructions (2024-12) |  |
Github Paper |
| Iris: Breaking GUI Complexity with Adaptive Focus and Self-Refining (2024-12) |  |
Github Paper |
| AgentTrek : AGENT TRAJECTORY SYNTHESIS VIA GUIDING REPLAY WITH WEB TUTORIALS (2024-12) |  |
Github Paper |
| AGUVIS: UNIFIED PURE VISION AGENTS FOR AUTONOMOUS GUI INTERACTION (2024-12) |  |
Github Paper |
| Ponder & Press: Advancing Visual GUI Agent towards General Computer Control (2024-12) |  |
Github Paper |
| ShowUI: One Vision-Language-Action Model for GUI Visual Agent (2024-11) |  |
Github Paper |
| The Dawn of GUI Agent: A Preliminary Case Study with Claude 3.5 Computer Use (2024-11) |  |
Github Paper |
| MobA: Multifaceted Memory-Enhanced Adaptive Planning for Efficient Mobile Task Automation (2024-10) (2025 NAACL Demo) |  |
Github Paper |
| OS-ATLAS: A FOUNDATION ACTION MODEL FOR GENERALIST GUI AGENTS (2024-10) |  |
Github Paper |
| AutoGLM: Autonomous Foundation Agents for GUIs (2024-10) |  |
Github Paper |
| FERRET-UI 2: MASTERING UNIVERSAL USER INTERFACE UNDERSTANDING ACROSS PLATFORMS (2024-10) |  |
Github Paper |
| AutoWebGLM: A Large Language Model-based Web Navigating Agent (2024-10) |  |
Github Paper |
| AGENT S: AN OPEN AGENTIC FRAMEWORK THAT USES COMPUTERS LIKE A HUMAN (2024-10) |  |
Github Paper |
| Navigating the Digital World as Humans Do: UNIVERSAL VISUAL GROUNDING FOR GUI AGENTS (2024-10) |  |
Github Paper |
| MOBILEFLOW: A MULTIMODAL LLM FOR MOBILE GUI AGENT (2024-8) |  |
Github Paper |
| AppAgent v2: Advanced Agent for Flexible Mobile Interactions (2024-8) |  |
Github Paper |
| OmniParser for Pure Vision Based GUI Agent (2024-8) |  |
Github Paper |
| OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop (2024-7) |  |
Github Paper |
| Android in the Zoo: Chain-of-Action-Thought for GUI Agents (2024-7) |  |
Github Paper |
| CRADLE: Empowering Foundation Agents Towards General Computer Control (2024-7) |  |
Github Paper |
| VGA: Vision GUI Assistant - Minimizing Hallucinations through Image-Centric Fine-Tuning (2024-6) |  |
Github Paper |
| WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models (2024-6) |  |
Github Paper |
| Mobile-Agent-v2: Mobile Device Operation Assistant with Effective Navigation via Multi-Agent Collaboration (2024-6) |  |
Github Paper |
| SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering (2024-5) |  |
Github Paper |
| UFO : A UI-Focused Agent for Windows OS Interaction (2024-5) |  |
Github Paper |
| MOBILE-AGENT: AUTONOMOUS MULTI-MODAL MOBILE DEVICE AGENT WITH VISUAL PERCEPTION (2024-4) |  |
Github Paper |
| WebArena: A REALISTIC WEB ENVIRONMENT FOR BUILDING AUTONOMOUS AGENTS (2024-4) |  |
Github Paper |
| TRAINING A VISION LANGUAGE MODEL AS SMARTPHONE ASSISTANT (2024-4) |  |
Github Paper |
| GPT-4V(ision) is a Generalist Web Agent, if Grounded (SeeAct)(2024-3) |  |
Github Paper |
| AutoDroid: LLM-powered Task Automation in Android (2024-3) |  |
Github Paper |
| SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents (2024-2) |  |
Github Paper |
| OS-Copilot: Towards Generalist Computer Agents with Self-Improvement (2024-2) |  |
Github Paper |
| Understanding the Weakness of Large Language Model Agents within a Complex Android Environment (2024-2) |  |
Github Paper |
| MOBILEAGENT: ENHANCING MOBILE CONTROL VIA HUMAN-MACHINE INTERACTION AND SOP INTEGRATION (2024-1) |  |
Github Paper |
| ASSISTGUI: Task-Oriented Desktop Graphical User Interface Automation (2024-1) |  |
Github Paper |
| AppAgent: Multimodal Agents as Smartphone Users (2023-12) |  |
Github Paper |
| CogAgent: A Visual Language Model for GUI Agents (2023-12) |  |
Github Paper |
| MIND2WEB: Towards a Generalist Agent for the Web (2023-12) |  |
Github Paper |
| Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V (2023-11) |  |
Github Paper |
| META-GUI: Towards Multi-modal Conversational Agents on Mobile GUI (2022-12) |  |
Github Paper |
| UIBert: Learning Generic Multimodal Representations for UI Understanding (2021-8) |  |
Github Paper |
| Title & Time | Introduction | Links |
|---|---|---|
| UI-E2I-Synth: Advancing GUI Grounding with Large-Scale Instruction Synthesis (2025-04) |  |
Github Paper |
| Ui-vision: A desktop-centric gui benchmark for visual perception and interaction (2025-03) |  |
Github Paper |
| Worldgui: Dynamic testing for comprehensive desktop gui automation (2025-02) |  |
Github Paper |
| Screenspot-pro: Gui grounding for professional high-resolution computer use (2025-01) |  |
Github Paper |
| Webwalker: Benchmarking llms in web traversal (2025-01) |  |
Github Paper |
| A3: Android agent arena for mobile gui agents (2025-01) |  |
Github Paper |
| Gui testing arena: A unified benchmark for advancing autonomous gui testing agent (2024-12) |  |
Github Paper |
| Harnessing web page uis for text-rich visual understanding (2024-11) |  |
Github Paper |
| On the effects of data scale on computer control agents (2024-11) |  |
Github Paper |
| AndroidLab: training and systematic benchmarking of android autonomous agents(2024-10) |  |
Github Paper |
| Spa-bench: A comprehensive benchmark for smartphone agent evaluation (2024-10) |  |
Github Paper |
| Read anywhere pointed: Layout-aware gui screen reading with tree of-lens grounding (2024-10) |  |
Github Paper |
| Crab: Cross environment agent benchmark for multimodal lan guage model agents (2024-10) |  |
Github Paper |
| Androidworld: A dynamic benchmarking environment for autonomous agents (2024-10) |  |
Github Paper |
| Benchmarking mobile device control agents across diverse configurations (2024-10) |  |
Github Paper |
| Agentstudio: A toolkit for building general virtual agents (2024-10) |  |
Github Paper |
| Weblinx: Real world website navigation with multi-turn dialogue (2024-10) |  |
Github Paper |
| Windows agent arena: Evaluating multi-modal os agents at scale (2024-09) |  |
Github Paper |
| Understanding the weakness of large lan guage model agents within a complex android en vironment (2024-09) |  |
Github Paper |
| Llamatouch: A faithful and scalable testbed for mobile ui automation task evaluation (2024-08) |  |
Github Paper |
| Amex: Android multi annotation expo dataset for mobile gui agents (2024-07) |  |
Github Paper |
| Omniact: A dataset and benchmark for enabling multimodal generalist autonomous agents for desktop and web (2024-07) |  |
HuggingFace Paper |
| Spider2-v: Howfar are multimodal agents from automating data science and engineering workflows? (2024-07) |  |
Github Paper |
| Webcanvas: Benchmarking web agents in online environments (2024-07) |  |
HuggingFace Paper |
| Gui odyssey: A comprehensive dataset for cross-app gui navigation on mobile devices (2024-06) |  |
Github Paper |
| Gui-world: A dataset for gui-oriented multimodal llm-based agents (2024-06) |  |
Github Paper |
| Guicourse: From general vision language models to versatile gui agents (2024-06) |  |
Github Paper |
| Mobileagentbench: An efficient and user-friendly benchmark for mobile llm agents (2024-06) |  |
Github Paper |
| Videogui: A benchmark for gui automation from instructional videos (2024-06) |  |
Github Paper |
| Visualwebarena: Evaluating multimodal agents on realistic visual web tasks (2024-06) |  |
HomePage Paper |
| Mobile-env: an evaluation platform and benchmark for llm-gui interaction (2024-06) |  |
Github Paper |
| Os world: Benchmarking multimodal agents for open ended tasks in real computer environments (2024-05) |  |
Github Paper |
| Visualwebbench: How far have multi modal llms evolved in web page understanding and grounding? (2024-04) |  |
Github Paper |
| Mmina: Benchmarking multihop multimodal internet agents (2024-04) |  |
HomePage Paper |
| Webarena: Arealistic web environment for building autonomous agents (2024-04) |  |
HomePage Paper |
| Webvln: Vision-and-language navigation on websites (2024-03) |  |
Github Paper |
| On the multi-turn instruction fol lowing for conversational web agents (2024-02) |  |
Github Paper |
| Assist gui: Task-oriented desktop graphical user interface automation (2024-01) |  |
Github Paper |
| Mind2web: Towards a generalist agent for the web (2023-12) |  |
Github Paper |
| Androidinthewild: A large-scale dataset for an droid device control (2023-10) |  |
Github Paper |
| Web shop: Towards scalable real-world web interaction with grounded language agents (2023-02) |  |
Github Paper |
| Meta-gui: Towards multi-modal con versational agents on mobile gui (2022-11) |  |
Github Paper |
| A dataset for interactive vision language navigation with unknown command fea sibility (2022-08) |  |
Github Paper |
| Websrc: A dataset for web-based structural reading comprehension (2021-11) |  |
Github Paper |
| Mapping natural language instructions to mobile ui action sequences (2020-06) |  |
Github Paper |
| Reinforcement learning on web interfaces using workflow-guided exploration (2018-02) |  |
Github Paper |
| Rico: A mobile app dataset for building data-driven design applications (2017-10) |  |
HomePage Paper |
| World of bits: An open-domain platform for web based agents (2017-08) |  |
Paper |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Awesome-GUI-Agents
Similar Open Source Tools
Awesome-GUI-Agents
Awesome-GUI-Agents is a curated list for GUI Agents, focusing on updates, contributing guidelines, modules of GUI Agents, paper lists, datasets, and benchmarks. It provides a comprehensive overview of research papers, models, and projects related to GUI automation, reinforcement learning, and grounding. The repository covers a wide range of topics such as perception, exploration, planning, interaction, memory, online reinforcement learning, GUI navigation benchmarks, and more.

Efficient-Multimodal-LLMs-Survey
Efficient Multimodal Large Language Models: A Survey provides a comprehensive review of efficient and lightweight Multimodal Large Language Models (MLLMs), focusing on model size reduction and cost efficiency for edge computing scenarios. The survey covers the timeline of efficient MLLMs, research on efficient structures and strategies, and applications. It discusses current limitations and future directions in efficient MLLM research.
Efficient-Multimodal-LLMs-Survey
Efficient Multimodal Large Language Models: A Survey provides a comprehensive review of efficient and lightweight Multimodal Large Language Models (MLLMs), focusing on model size reduction and cost efficiency for edge computing scenarios. The survey covers the timeline of efficient MLLMs, research on efficient structures and strategies, and their applications, while also discussing current limitations and future directions.
vlmrun-cookbook
VLM Run Cookbook is a repository containing practical examples and tutorials for extracting structured data from images, videos, and documents using Vision Language Models (VLMs). It offers comprehensive Colab notebooks demonstrating real-world applications of VLM Run, with complete code and documentation for easy adaptation. The examples cover various domains such as financial documents and TV news analysis.
rag-web-ui
RAG Web UI is an intelligent dialogue system based on RAG (Retrieval-Augmented Generation) technology. It helps enterprises and individuals build intelligent Q&A systems based on their own knowledge bases. By combining document retrieval and large language models, it delivers accurate and reliable knowledge-based question-answering services. The system is designed with features like intelligent document management, advanced dialogue engine, and a robust architecture. It supports multiple document formats, async document processing, multi-turn contextual dialogue, and reference citations in conversations. The architecture includes a backend stack with Python FastAPI, MySQL + ChromaDB, MinIO, Langchain, JWT + OAuth2 for authentication, and a frontend stack with Next.js, TypeScript, Tailwind CSS, Shadcn/UI, and Vercel AI SDK for AI integration. Performance optimization includes incremental document processing, streaming responses, vector database performance tuning, and distributed task processing. The project is licensed under the Apache-2.0 License and is intended for learning and sharing RAG knowledge only, not for commercial purposes.

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

chat-your-doc
Chat Your Doc is an experimental project exploring various applications based on LLM technology. It goes beyond being just a chatbot project, focusing on researching LLM applications using tools like LangChain and LlamaIndex. The project delves into UX, computer vision, and offers a range of examples in the 'Lab Apps' section. It includes links to different apps, descriptions, launch commands, and demos, aiming to showcase the versatility and potential of LLM applications.
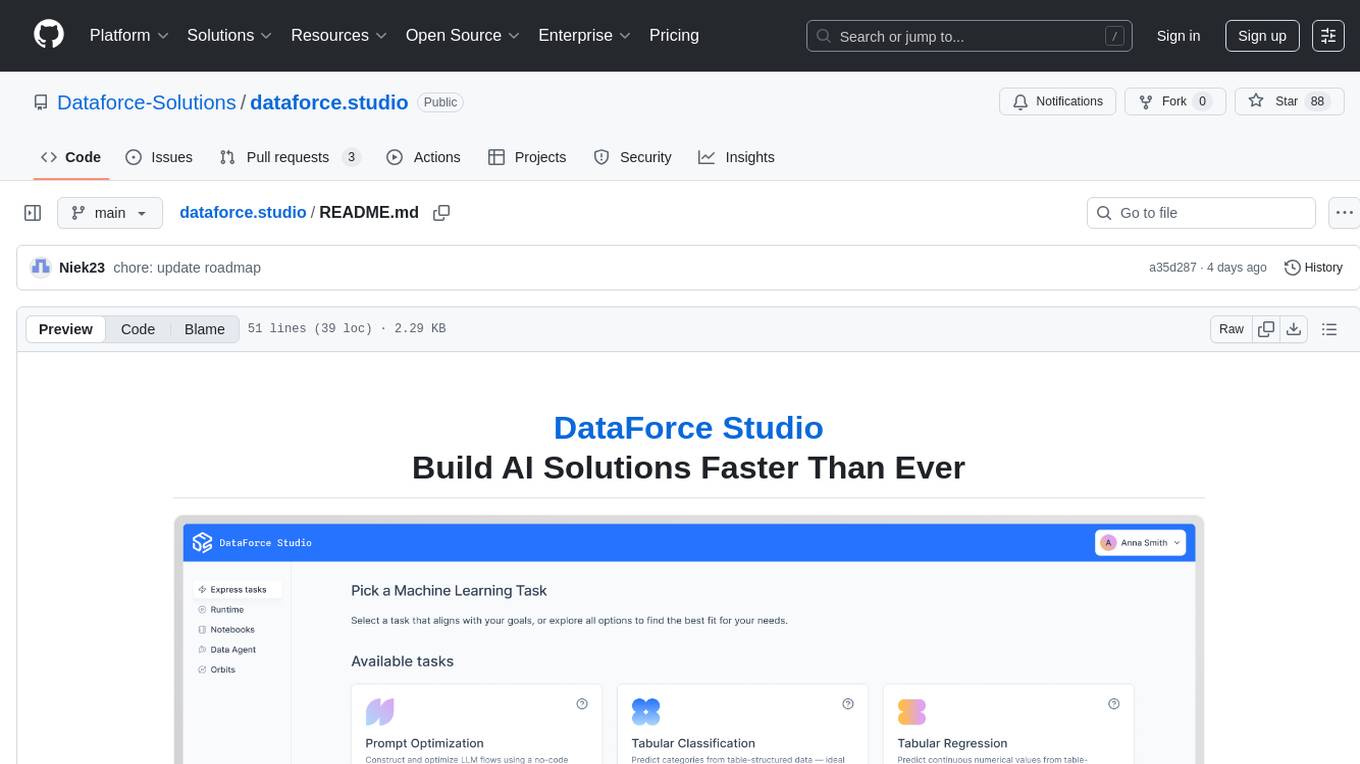
dataforce.studio
DataForce Studio is an open-source MLOps platform designed to help build, manage, and deploy AI/ML models with ease. It supports the entire model lifecycle, from creation to deployment and monitoring, within a user-friendly interface. The platform is in active early development, aiming to provide features like post-deployment monitoring, model deployment, data science agent, experiment snapshots, model cards, Python SDK, model registry, notebooks, in-browser runtime, and express tasks for prompt optimization and tabular data.

HuatuoGPT-II
HuatuoGPT2 is an innovative domain-adapted medical large language model that excels in medical knowledge and dialogue proficiency. It showcases state-of-the-art performance in various medical benchmarks, surpassing GPT-4 in expert evaluations and fresh medical licensing exams. The open-source release includes HuatuoGPT2 models in 7B, 13B, and 34B versions, training code for one-stage adaptation, partial pre-training and fine-tuning instructions, and evaluation methods for medical response capabilities and professional pharmacist exams. The tool aims to enhance LLM capabilities in the Chinese medical field through open-source principles.

Groma
Groma is a grounded multimodal assistant that excels in region understanding and visual grounding. It can process user-defined region inputs and generate contextually grounded long-form responses. The tool presents a unique paradigm for multimodal large language models, focusing on visual tokenization for localization. Groma achieves state-of-the-art performance in referring expression comprehension benchmarks. The tool provides pretrained model weights and instructions for data preparation, training, inference, and evaluation. Users can customize training by starting from intermediate checkpoints. Groma is designed to handle tasks related to detection pretraining, alignment pretraining, instruction finetuning, instruction following, and more.

ColossalAI
Colossal-AI is a deep learning system for large-scale parallel training. It provides a unified interface to scale sequential code of model training to distributed environments. Colossal-AI supports parallel training methods such as data, pipeline, tensor, and sequence parallelism and is integrated with heterogeneous training and zero redundancy optimizer.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.

hcaptcha-challenger
hCaptcha Challenger is a tool designed to gracefully face hCaptcha challenges using a multimodal large language model. It does not rely on Tampermonkey scripts or third-party anti-captcha services, instead implementing interfaces for 'AI vs AI' scenarios. The tool supports various challenge types such as image labeling, drag and drop, and advanced tasks like self-supervised challenges and Agentic Workflow. Users can access documentation in multiple languages and leverage resources for tasks like model training, dataset annotation, and model upgrading. The tool aims to enhance user experience in handling hCaptcha challenges with innovative AI capabilities.

UniCoT
Uni-CoT is a unified reasoning framework that extends Chain-of-Thought (CoT) principles to the multimodal domain, enabling Multimodal Large Language Models (MLLMs) to perform interpretable, step-by-step reasoning across both text and vision. It decomposes complex multimodal tasks into structured, manageable steps that can be executed sequentially or in parallel, allowing for more scalable and systematic reasoning.
pr-agent
PR-Agent is a tool that helps to efficiently review and handle pull requests by providing AI feedbacks and suggestions. It supports various commands such as generating PR descriptions, providing code suggestions, answering questions about the PR, and updating the CHANGELOG.md file. PR-Agent can be used via CLI, GitHub Action, GitHub App, Docker, and supports multiple git providers and models. It emphasizes real-life practical usage, with each tool having a single GPT-4 call for quick and affordable responses. The PR Compression strategy enables effective handling of both short and long PRs, while the JSON prompting strategy allows for modular and customizable tools. PR-Agent Pro, the hosted version by CodiumAI, provides additional benefits such as full management, improved privacy, priority support, and extra features.
For similar tasks
Awesome-GUI-Agents
Awesome-GUI-Agents is a curated list for GUI Agents, focusing on updates, contributing guidelines, modules of GUI Agents, paper lists, datasets, and benchmarks. It provides a comprehensive overview of research papers, models, and projects related to GUI automation, reinforcement learning, and grounding. The repository covers a wide range of topics such as perception, exploration, planning, interaction, memory, online reinforcement learning, GUI navigation benchmarks, and more.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.