
gemini-2-live-api-demo
Vanilla JS web interface for Gemini 2.0 Flash Experimental Multimodal API with text, audio, camera, screen inputs and audio response and function calling from the LLM
Stars: 186
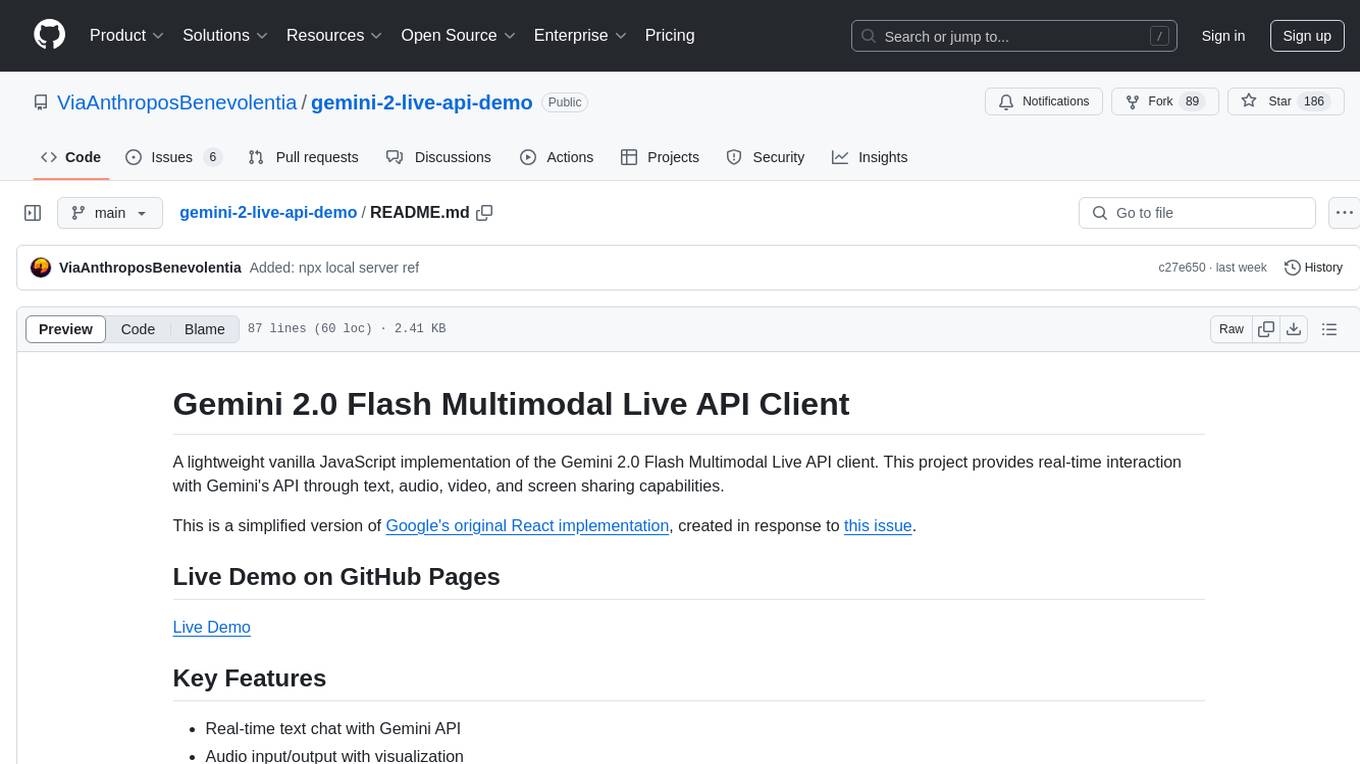
A lightweight vanilla JavaScript implementation of the Gemini 2.0 Flash Multimodal Live API client, providing real-time interaction with Gemini's API through text, audio, video, and screen sharing capabilities. Built with vanilla JavaScript, it offers features like real-time text chat, audio input/output with visualization, motion-detected video streaming, and screen sharing. Users can connect to the API, send text messages, toggle microphone for audio input, enable webcam for video streaming, share screen, and monitor real-time feedback in the logs panel. Custom tools can be added for extending functionality.
README:
A lightweight vanilla JavaScript implementation of the Gemini 2.0 Flash Multimodal Live API client. This project provides real-time interaction with Gemini's API through text, audio, video, and screen sharing capabilities.
This is a simplified version of Google's original React implementation, created in response to this issue.
- Real-time text chat with Gemini API
- Audio input/output with visualization
- Motion-detected video streaming
- Screen sharing capabilities
- Function calling support
- Built with vanilla JavaScript (no dependencies)
- Modern web browser with WebRTC, WebSocket, and Web Audio API support
- Google AI Studio API key
- Python 3.0+ OR
npx http-server(for local development server)
-
Clone the repository
-
Set up your API key:
cp js/config/config.example.js js/config/config.js # Edit js/config/config.js with your API key -
Start the development server:
python -m http.server 8000
or
npx http-server 8000
-
Access the application at
http://localhost:8000
├── js/
│ ├── audio/ # Audio processing and management
│ ├── config/ # Configuration files
│ ├── core/ # Core functionality (WebSocket, worklets)
│ ├── tools/ # Function calling implementations
│ ├── utils/ # Utility functions
│ ├── video/ # Video and screen sharing
│ └── main.js # Application entry point
├── css/ # Styling
└── index.html # Main HTML file
- Click "Connect" to establish API connection
- Use the interface to:
- Send text messages
- Toggle microphone for audio input
- Enable webcam for video streaming
- Share your screen
- Monitor the logs panel for real-time feedback
Custom tools can be added to extend functionality. See js/tools/README.md for implementation details.
Contributions are welcome! Please feel free to submit issues and pull requests.
This project is licensed under the MIT License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for gemini-2-live-api-demo
Similar Open Source Tools
gemini-2-live-api-demo
A lightweight vanilla JavaScript implementation of the Gemini 2.0 Flash Multimodal Live API client, providing real-time interaction with Gemini's API through text, audio, video, and screen sharing capabilities. Built with vanilla JavaScript, it offers features like real-time text chat, audio input/output with visualization, motion-detected video streaming, and screen sharing. Users can connect to the API, send text messages, toggle microphone for audio input, enable webcam for video streaming, share screen, and monitor real-time feedback in the logs panel. Custom tools can be added for extending functionality.
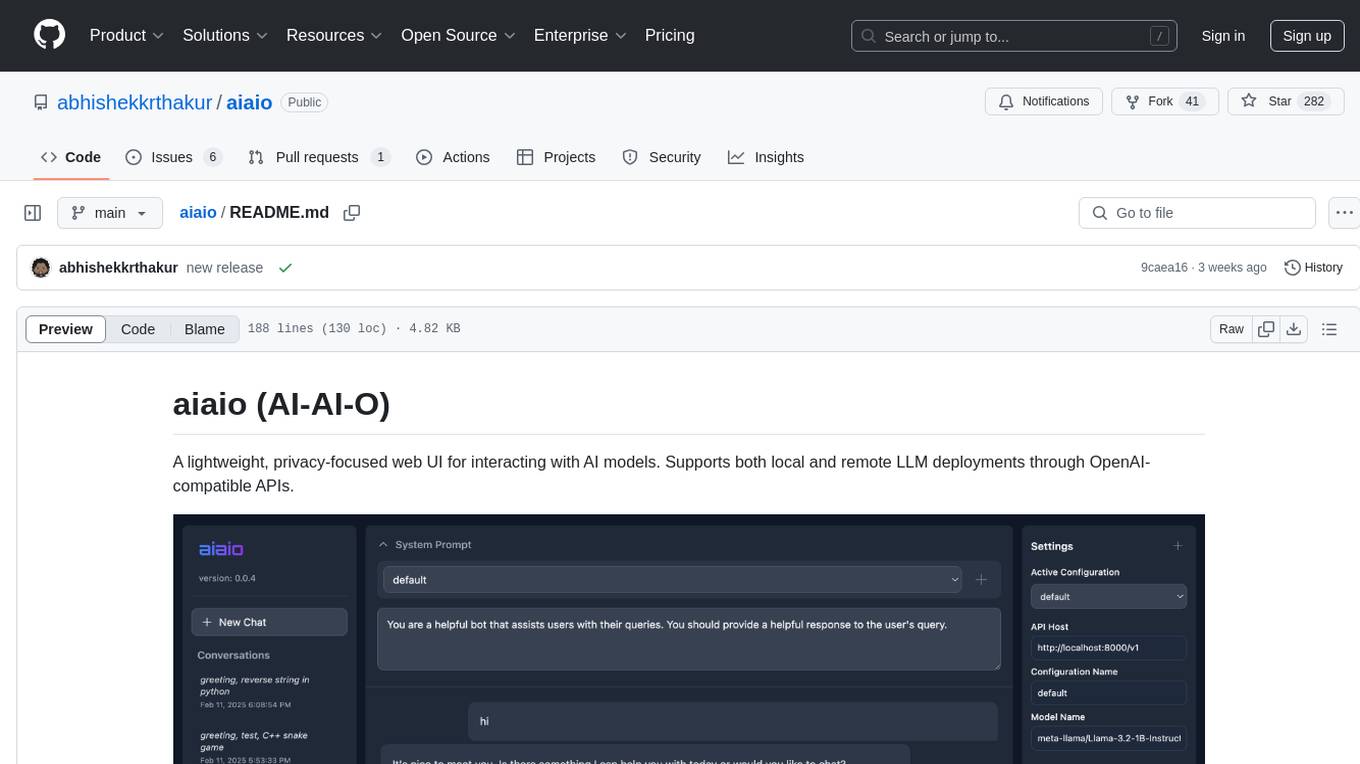
aiaio
aiaio (AI-AI-O) is a lightweight, privacy-focused web UI for interacting with AI models. It supports both local and remote LLM deployments through OpenAI-compatible APIs. The tool provides features such as dark/light mode support, local SQLite database for conversation storage, file upload and processing, configurable model parameters through UI, privacy-focused design, responsive design for mobile/desktop, syntax highlighting for code blocks, real-time conversation updates, automatic conversation summarization, customizable system prompts, WebSocket support for real-time updates, Docker support for deployment, multiple API endpoint support, and multiple system prompt support. Users can configure model parameters and API settings through the UI, handle file uploads, manage conversations, and use keyboard shortcuts for efficient interaction. The tool uses SQLite for storage with tables for conversations, messages, attachments, and settings. Contributions to the project are welcome under the Apache License 2.0.
openagents
OpenAgents is a platform for AI agents using open protocols. The current flagship product (v4) is an agentic chat app live at openagents.com. This repository holds the new cross-platform version (v5), with an initial focus on Coder, a desktop app intended to replace Claude Code with standard chat UI & thread history and first-class MCP integration. The v5 tech stack includes React, React Native, TypeScript for frontend, Cloudflare stack for backend, better-auth for authentication, and Vercel AI SDK. The architecture considerations aim for cross-platform code reuse, open protocol interoperability, long-running agent processes, composability, proportional payment to contributors, and agent wallets for Bitcoin/Lightning & stablecoins via Spark wallet.
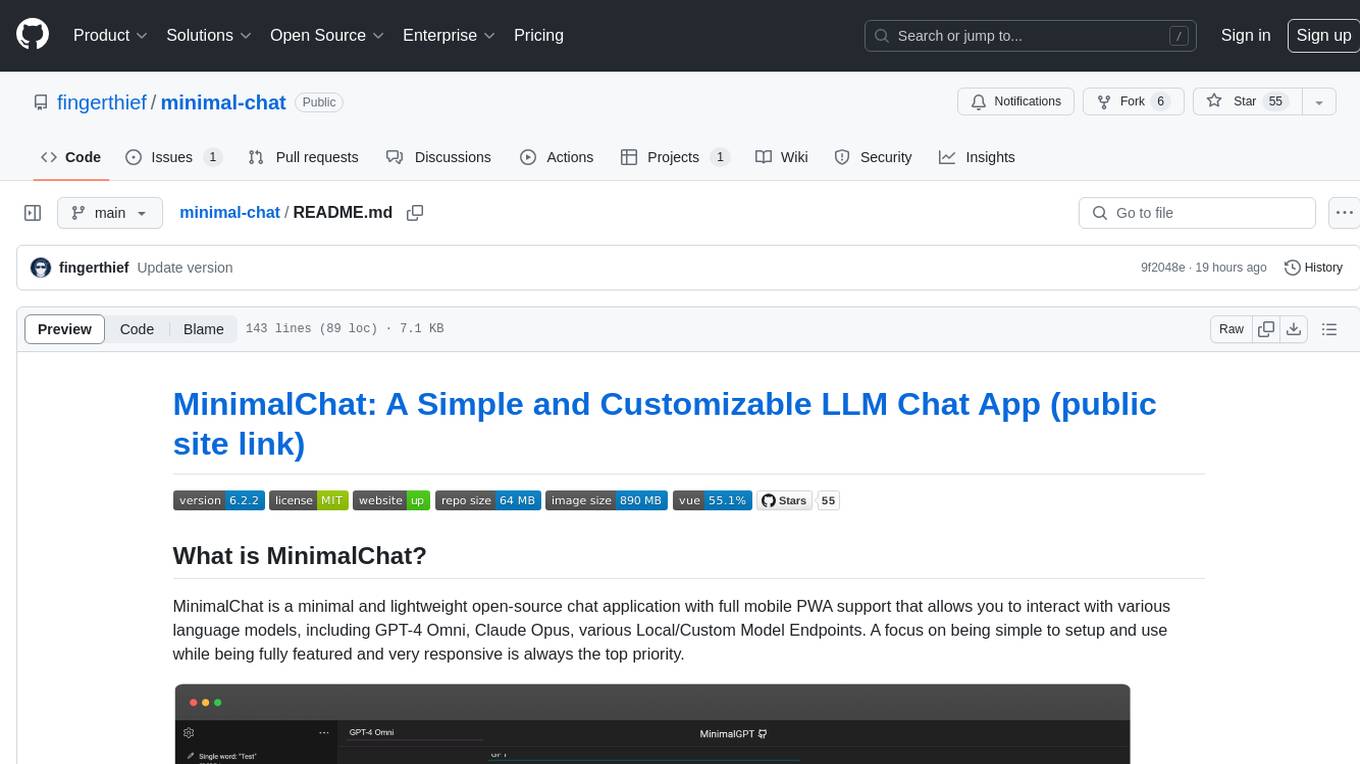
minimal-chat
MinimalChat is a minimal and lightweight open-source chat application with full mobile PWA support that allows users to interact with various language models, including GPT-4 Omni, Claude Opus, and various Local/Custom Model Endpoints. It focuses on simplicity in setup and usage while being fully featured and highly responsive. The application supports features like fully voiced conversational interactions, multiple language models, markdown support, code syntax highlighting, DALL-E 3 integration, conversation importing/exporting, and responsive layout for mobile use.
KeyboardGPT
Keyboard GPT is an LSPosed Module that integrates Generative AI like ChatGPT into your keyboard, allowing for real-time AI responses, custom prompts, and web search capabilities. It works in all apps and supports popular keyboards like Gboard, Swiftkey, Fleksy, and Samsung Keyboard. Users can easily configure API providers, submit prompts, and perform web searches directly from their keyboard. The tool also supports multiple Generative AI APIs such as ChatGPT, Gemini, and Groq. It offers an easy installation process for both rooted and non-rooted devices, making it a versatile and powerful tool for enhancing text input experiences on mobile devices.
reachat
Reachat is a UI library designed for building chat experiences without the need for manual coding of components. Users can customize each component and theme using Tailwind. The library offers features such as console and companion modes, markdown rendering, code highlighting, tables, JSON support, math rendering, YouTube embeds, file uploads, message sources, animations, conversation pagination, keyboard shortcuts, responsive design, and more. Reachat is highly customizable and suitable for creating interactive chat interfaces.
chat-vue
Full-featured AI Chatbot Vue application with authentication, chat history, multiple pages, collapsible sidebar, keyboard shortcuts, light & dark mode, command palette and more. Built using Nuxt UI components and integrated with AI SDK v5 for a complete chat experience. Features include streaming AI messages, multiple model support, authentication via GitHub OAuth, chat history persistence, markdown rendering, and easy deployment to Vercel with zero configuration.
codewalk
CodeWalk is a native cross-platform client for OpenCode server mode, built with Flutter. It provides an AI chat interface for coding interactions, multi-server profile management, session lifecycle management, worktree management, speech-to-text input, and more. The project follows Clean Architecture with Flutter, Dart, Provider for state management, Dio for HTTP client, SharedPreferences for local storage, GetIt for dependency injection, and Material Design 3 for design system.
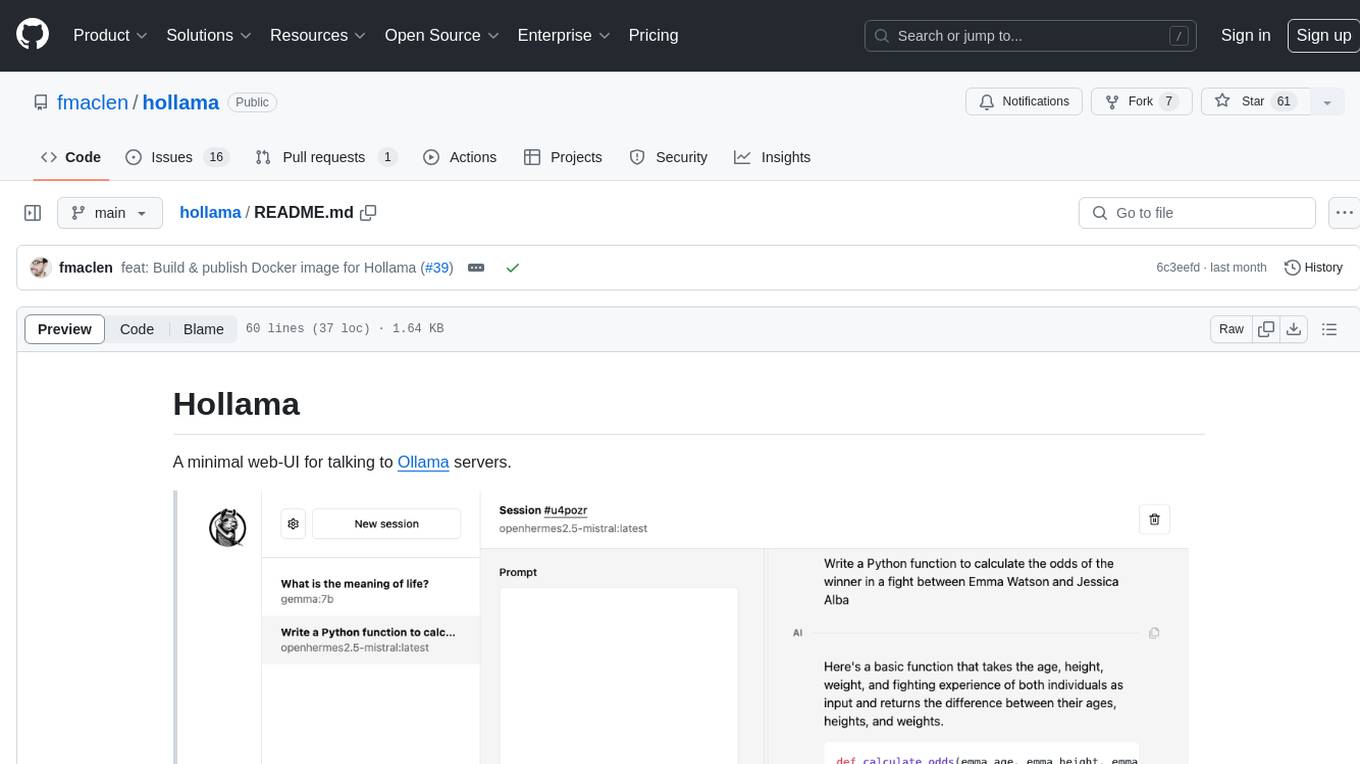
hollama
Hollama is a minimal web-UI tool designed for interacting with Ollama servers. It features large prompt fields, streams completions, ability to copy completions as raw text, Markdown parsing with syntax highlighting, and saves sessions/context in the browser's localStorage. Users can access the latest version of Hollama at https://hollama.fernando.is without sign up, and data is stored locally on the browser. The tool can also be run as a Docker image by executing a specific command. Developers can connect to an Ollama server by updating the ORIGIN settings. Hollama facilitates easy development by providing instructions to set up the environment, install dependencies, and start a development server. Building a production version of the app is straightforward with a single command, and deployment may require installing an adapter for the target environment.

macai
Macai is a native macOS client for interacting with modern AI tools, such as ChatGPT and Ollama. It features organized chats with custom system messages, system-defined light/dark themes, backup and restore functionality, customizable context size, support for any model with a compatible API, formatted code blocks and tables, multiple chat tabs, CoreData data storage, streamed responses, and automatic chat name generation. Macai is in active development, with contributions welcome.

cossistant
Cossistant is an open source chat support widget tailored for the React ecosystem. It offers headless components for building customizable chat interfaces, real-time messaging with WebSocket technology, and tools for managing customer conversations. The tool is API-first, self-hosted, developer-friendly with TypeScript support, and provides complete integration flexibility. It uses technologies like Next.js, TailwindCSS, and WebSockets, and supports databases like PlanetScale for production and DBgin for local development. Cossistant is ideal for developers seeking a versatile chat solution that can be easily integrated into their applications.
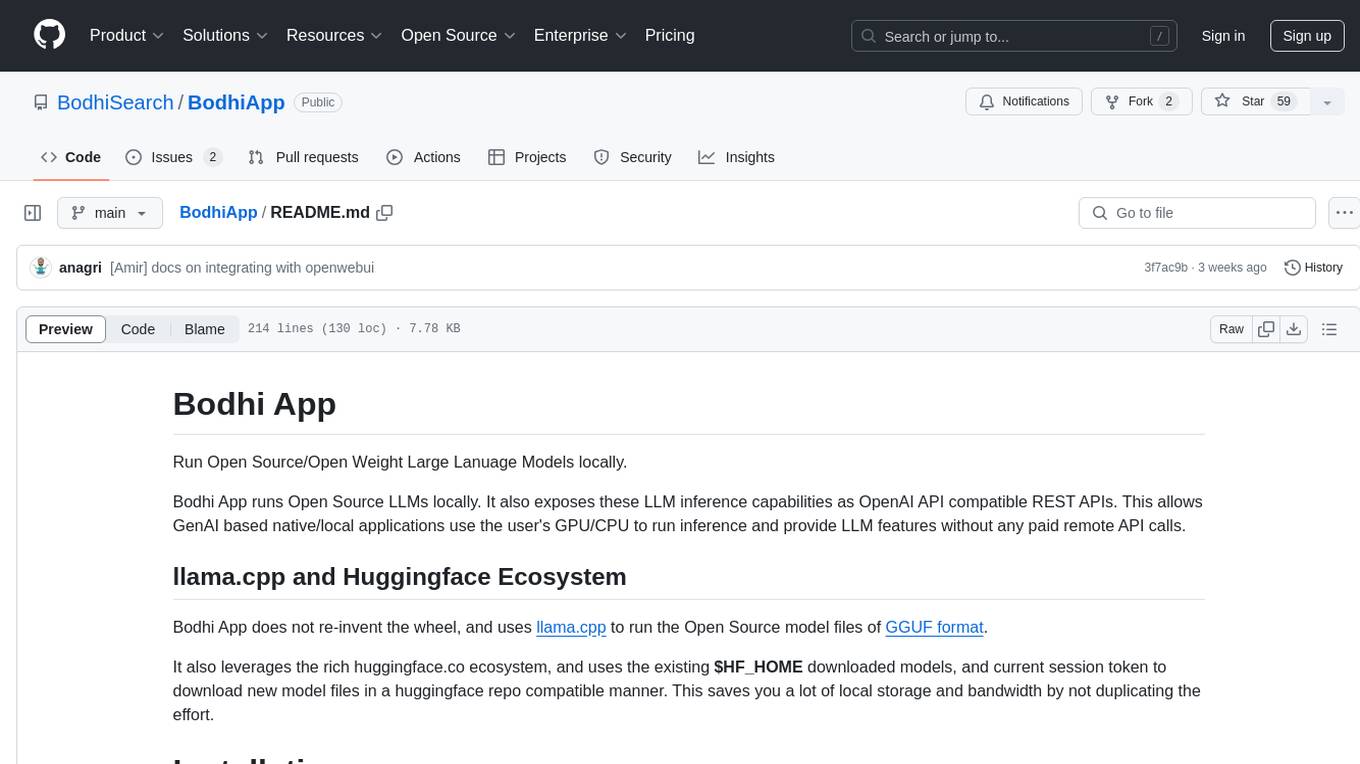
BodhiApp
Bodhi App runs Open Source Large Language Models locally, exposing LLM inference capabilities as OpenAI API compatible REST APIs. It leverages llama.cpp for GGUF format models and huggingface.co ecosystem for model downloads. Users can run fine-tuned models for chat completions, create custom aliases, and convert Huggingface models to GGUF format. The CLI offers commands for environment configuration, model management, pulling files, serving API, and more.
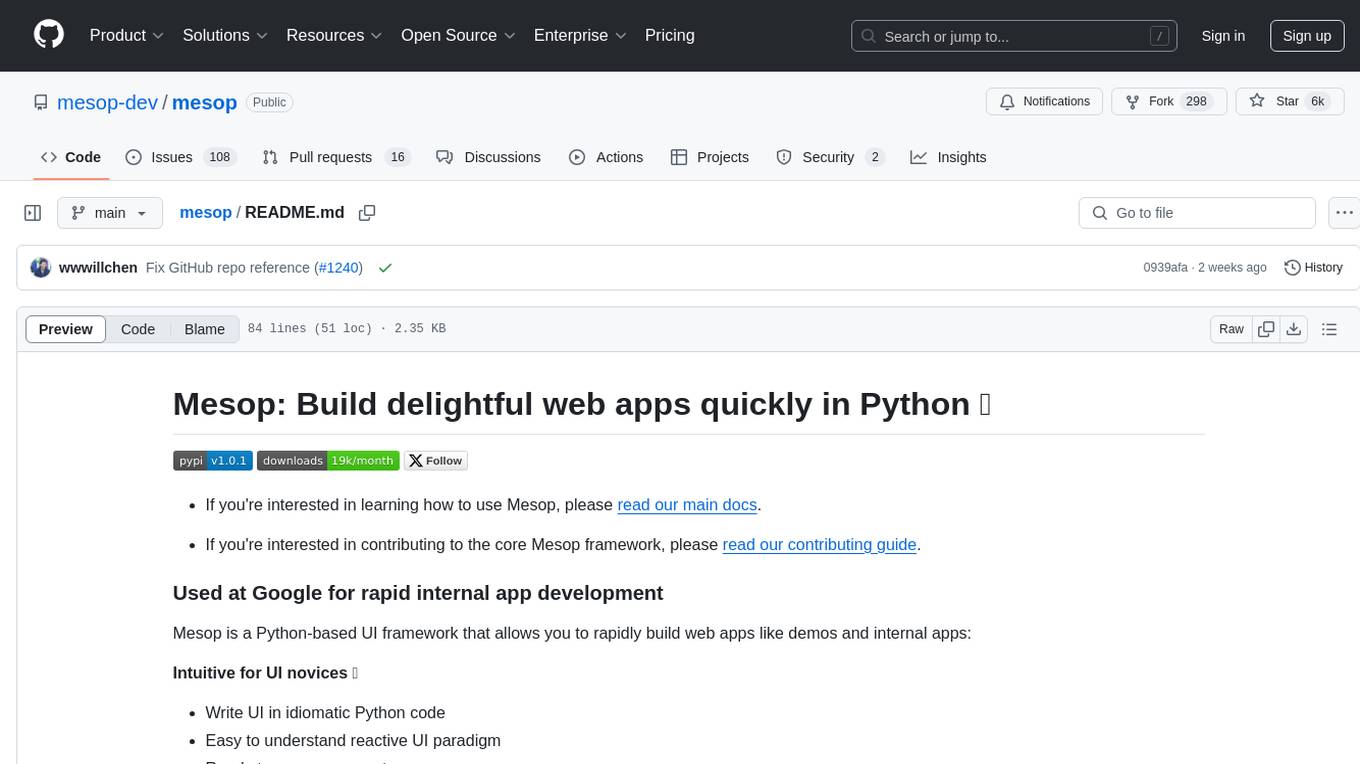
mesop
Mesop is a Python-based UI framework designed for rapid web app development, particularly for demos and internal apps. It allows users to write UI in Python code, offers reactive UI paradigm, ready-to-use components, hot reload feature, rich IDE support, and the ability to build custom UIs without writing Javascript/CSS/HTML. Mesop is intuitive for UI novices, provides frictionless developer workflows, and is flexible for creating delightful demos. It is used at Google for rapid internal app development.
Chital
Chital is a native macOS app designed for chatting with Ollama models. It offers low memory usage and fast app launch times, supports multiple chat threads, allows users to switch between different models, provides Markdown support, and automatically summarizes chat thread titles. The app requires macOS 14 Sonoma or above, the installation of Ollama, and at least one downloaded LLM model. Chital is a user-friendly tool that simplifies the process of engaging with Ollama models through chat threads on macOS systems.
midscene
Midscene.js is an AI-powered automation SDK that allows users to control web pages, perform assertions, and extract data in JSON format using natural language. It offers features such as natural language interaction, understanding UI and providing responses in JSON, intuitive assertion based on AI understanding, compatibility with public multimodal LLMs like GPT-4o, visualization tool for easy debugging, and a brand new experience in automation development.
video-starter-kit
A powerful starting kit for building AI-powered video applications. This toolkit simplifies the complexities of working with AI video models in the browser. It offers browser-native video processing, AI model integration, advanced media capabilities, and developer utilities. The tech stack includes fal.ai for AI model infrastructure, Next.js for React framework, Remotion for video processing, IndexedDB for browser-based storage, Vercel for deployment platform, and UploadThing for file upload. The kit provides features like seamless video handling, multi-clip composition, audio track integration, voiceover support, metadata encoding, and ready-to-use UI components.
For similar tasks
gemini-2-live-api-demo
A lightweight vanilla JavaScript implementation of the Gemini 2.0 Flash Multimodal Live API client, providing real-time interaction with Gemini's API through text, audio, video, and screen sharing capabilities. Built with vanilla JavaScript, it offers features like real-time text chat, audio input/output with visualization, motion-detected video streaming, and screen sharing. Users can connect to the API, send text messages, toggle microphone for audio input, enable webcam for video streaming, share screen, and monitor real-time feedback in the logs panel. Custom tools can be added for extending functionality.
dinopal
DinoPal is an AI voice assistant residing in the Mac menu bar, offering real-time voice and video chat, screen sharing, online search, and multilingual support. It provides various AI assistants with unique strengths and characteristics to meet different conversational needs. Users can easily install DinoPal and access different communication modes, with a call time limit of 30 minutes. User feedback can be shared in the Discord community. DinoPal is powered by Google Gemini & Pipecat.

JiwuChat
JiwuChat is a lightweight multi-platform chat application built on Tauri2 and Nuxt3, with various real-time messaging features, AI group chat bots (such as 'iFlytek Spark', 'KimiAI' etc.), WebRTC audio-video calling, screen sharing, and AI shopping functions. It supports seamless cross-device communication, covering text, images, files, and voice messages, also supporting group chats and customizable settings. It provides light/dark mode for efficient social networking.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.