
Chital
A native macOS app for chatting with local LLMs
Stars: 209
Chital is a native macOS app designed for chatting with Ollama models. It offers low memory usage and fast app launch times, supports multiple chat threads, allows users to switch between different models, provides Markdown support, and automatically summarizes chat thread titles. The app requires macOS 14 Sonoma or above, the installation of Ollama, and at least one downloaded LLM model. Chital is a user-friendly tool that simplifies the process of engaging with Ollama models through chat threads on macOS systems.
README:

A native macOS app for chatting with Ollama models
- Low memory usage and fast app launch times
- Support for multiple chat threads
- Switch between different models
- Markdown support
- Automatic chat thread title summarization
https://github.com/user-attachments/assets/14eddab2-87c3-4dd5-b26a-a58e2f12f76a
- Download Chital
- Move
Chital.appfrom theDownloadsfolder into theApplicationsfolder. - Goto
System Settings->Privacy & Security-> clickOpen Anyway
The following settings can be changed from Chital > Settings:
- Default model
- Ollama base URL
- Context window length
- Chat thread title summarization prompt
-
Command + NNew chat thread -
Option + EnterMultiline input
I built this application mainly for my own personal use. Feel free to fork this codebase to add features. I might not have time to look at the PRs and bug tickets.
MIT
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Chital
Similar Open Source Tools
Chital
Chital is a native macOS app designed for chatting with Ollama models. It offers low memory usage and fast app launch times, supports multiple chat threads, allows users to switch between different models, provides Markdown support, and automatically summarizes chat thread titles. The app requires macOS 14 Sonoma or above, the installation of Ollama, and at least one downloaded LLM model. Chital is a user-friendly tool that simplifies the process of engaging with Ollama models through chat threads on macOS systems.
SecureAI-Tools
SecureAI Tools is a private and secure AI tool that allows users to chat with AI models, chat with documents (PDFs), and run AI models locally. It comes with built-in authentication and user management, making it suitable for family members or coworkers. The tool is self-hosting optimized and provides necessary scripts and docker-compose files for easy setup in under 5 minutes. Users can customize the tool by editing the .env file and enabling GPU support for faster inference. SecureAI Tools also supports remote OpenAI-compatible APIs, with lower hardware requirements for using remote APIs only. The tool's features wishlist includes chat sharing, mobile-friendly UI, and support for more file types and markdown rendering.
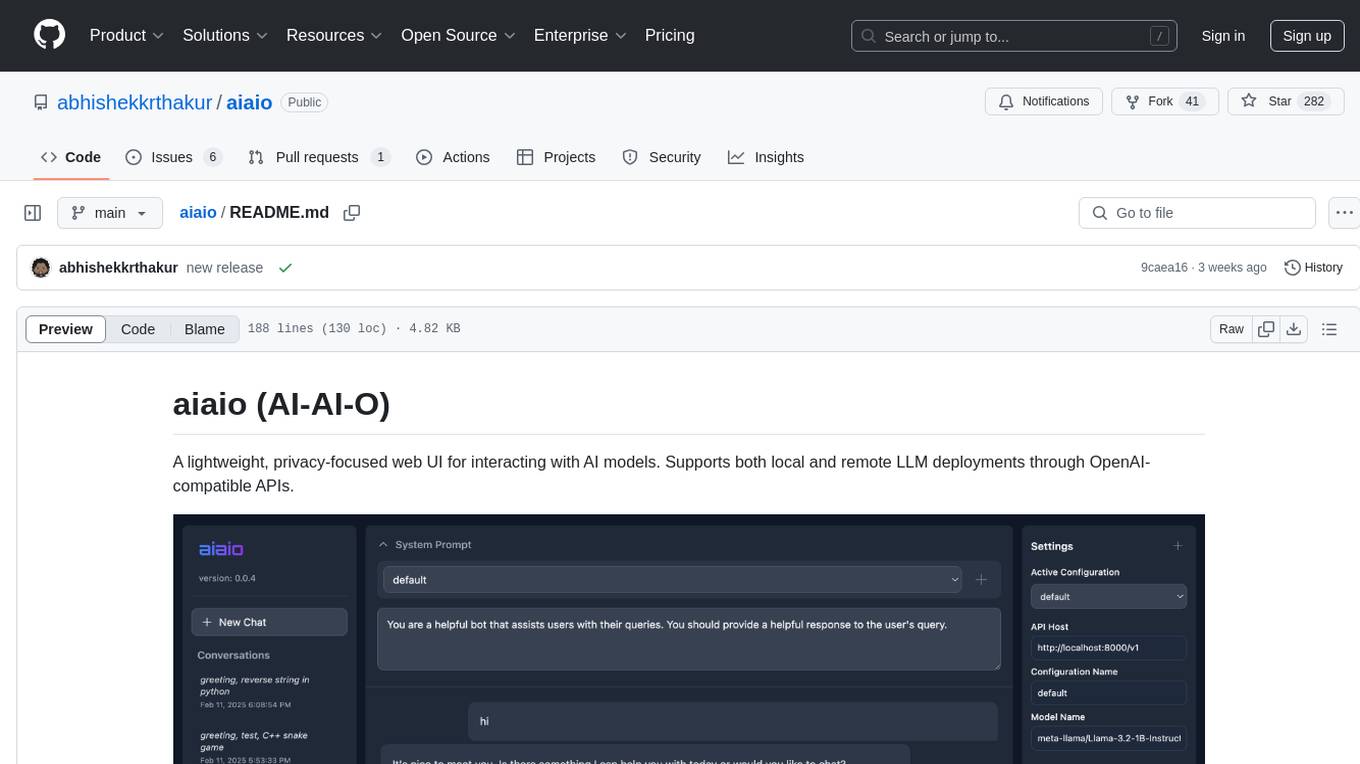
aiaio
aiaio (AI-AI-O) is a lightweight, privacy-focused web UI for interacting with AI models. It supports both local and remote LLM deployments through OpenAI-compatible APIs. The tool provides features such as dark/light mode support, local SQLite database for conversation storage, file upload and processing, configurable model parameters through UI, privacy-focused design, responsive design for mobile/desktop, syntax highlighting for code blocks, real-time conversation updates, automatic conversation summarization, customizable system prompts, WebSocket support for real-time updates, Docker support for deployment, multiple API endpoint support, and multiple system prompt support. Users can configure model parameters and API settings through the UI, handle file uploads, manage conversations, and use keyboard shortcuts for efficient interaction. The tool uses SQLite for storage with tables for conversations, messages, attachments, and settings. Contributions to the project are welcome under the Apache License 2.0.
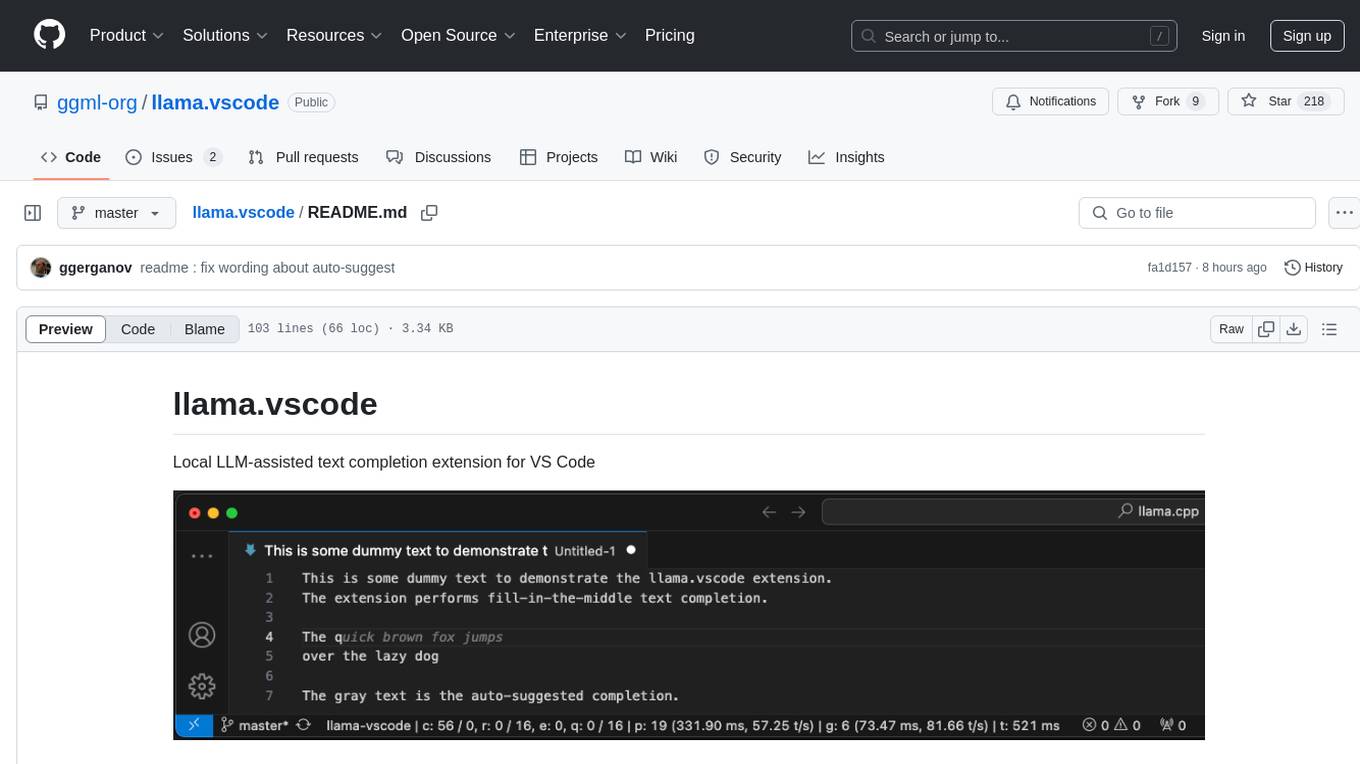
llama.vscode
llama.vscode is a local LLM-assisted text completion extension for Visual Studio Code. It provides auto-suggestions on input, allows accepting suggestions with shortcuts, and offers various features to enhance text completion. The extension is designed to be lightweight and efficient, enabling high-quality completions even on low-end hardware. Users can configure the scope of context around the cursor and control text generation time. It supports very large contexts and displays performance statistics for better user experience.

OmniSteward
OmniSteward is an AI-powered steward system based on large language models that can interact with users through voice or text to help control smart home devices and computer programs. It supports multi-turn dialogue, tool calling for complex tasks, multiple LLM models, voice recognition, smart home control, computer program management, online information retrieval, command line operations, and file management. The system is highly extensible, allowing users to customize and share their own tools.
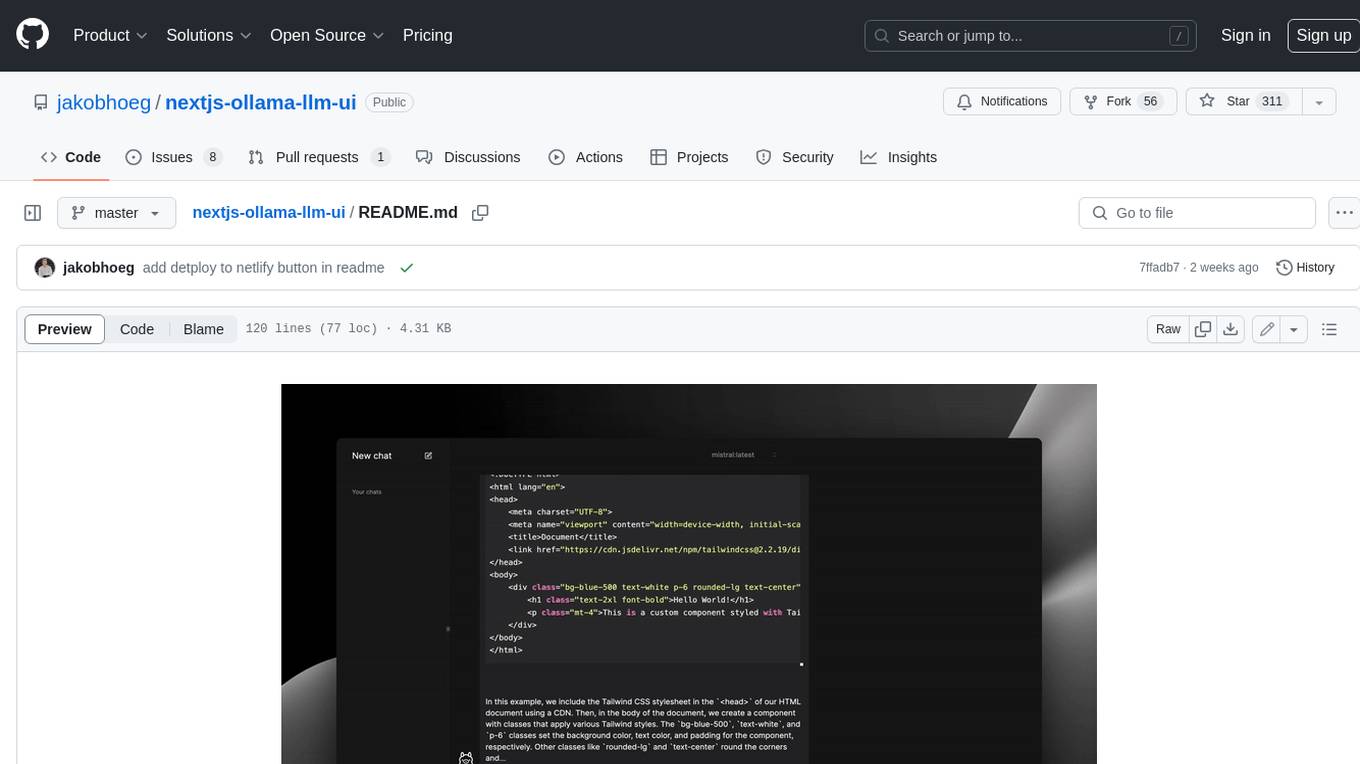
nextjs-ollama-llm-ui
This web interface provides a user-friendly and feature-rich platform for interacting with Ollama Large Language Models (LLMs). It offers a beautiful and intuitive UI inspired by ChatGPT, making it easy for users to get started with LLMs. The interface is fully local, storing chats in local storage for convenience, and fully responsive, allowing users to chat on their phones with the same ease as on a desktop. It features easy setup, code syntax highlighting, and the ability to easily copy codeblocks. Users can also download, pull, and delete models directly from the interface, and switch between models quickly. Chat history is saved and easily accessible, and users can choose between light and dark mode. To use the web interface, users must have Ollama downloaded and running, and Node.js (18+) and npm installed. Installation instructions are provided for running the interface locally. Upcoming features include the ability to send images in prompts, regenerate responses, import and export chats, and add voice input support.
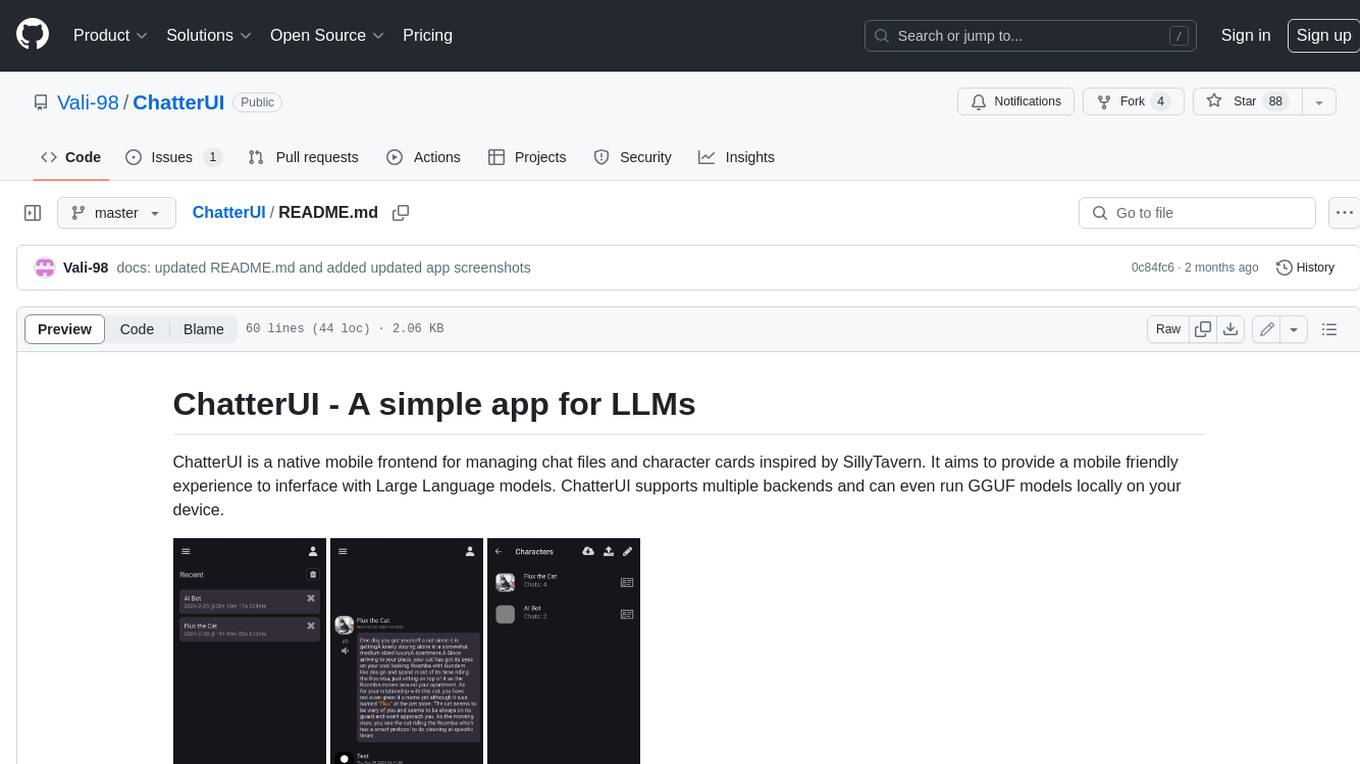
ChatterUI
ChatterUI is a mobile app that allows users to manage chat files and character cards, and to interact with Large Language Models (LLMs). It supports multiple backends, including local, koboldcpp, text-generation-webui, Generic Text Completions, AI Horde, Mancer, Open Router, and OpenAI. ChatterUI provides a mobile-friendly interface for interacting with LLMs, making it easy to use them for a variety of tasks, such as generating text, translating languages, writing code, and answering questions.
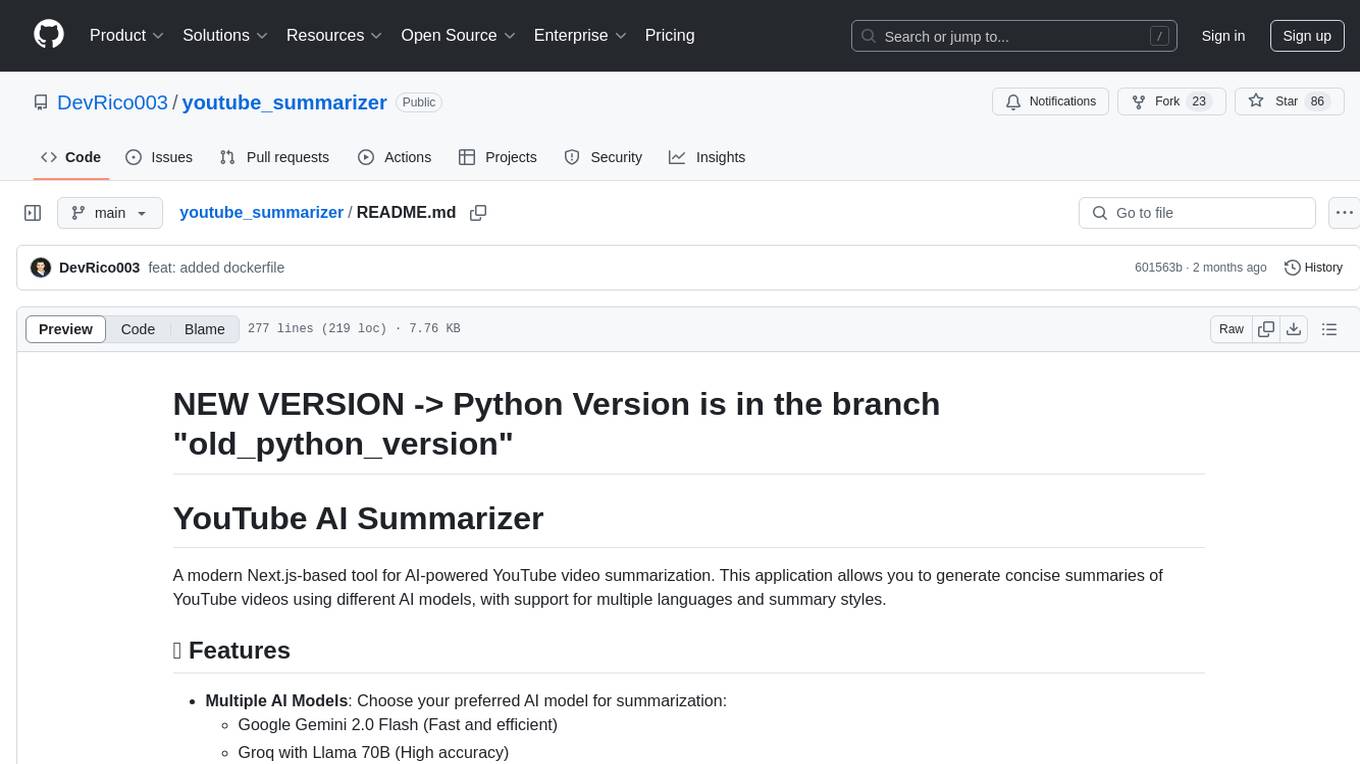
youtube_summarizer
YouTube AI Summarizer is a modern Next.js-based tool for AI-powered YouTube video summarization. It allows users to generate concise summaries of YouTube videos using various AI models, with support for multiple languages and summary styles. The application features flexible API key requirements, multilingual support, flexible summary modes, a smart history system, modern UI/UX design, and more. Users can easily input a YouTube URL, select language, summary type, and AI model, and generate summaries with real-time progress tracking. The tool offers a clean, well-structured summary view, history dashboard, and detailed history view for past summaries. It also provides configuration options for API keys and database setup, along with technical highlights, performance improvements, and a modern tech stack.
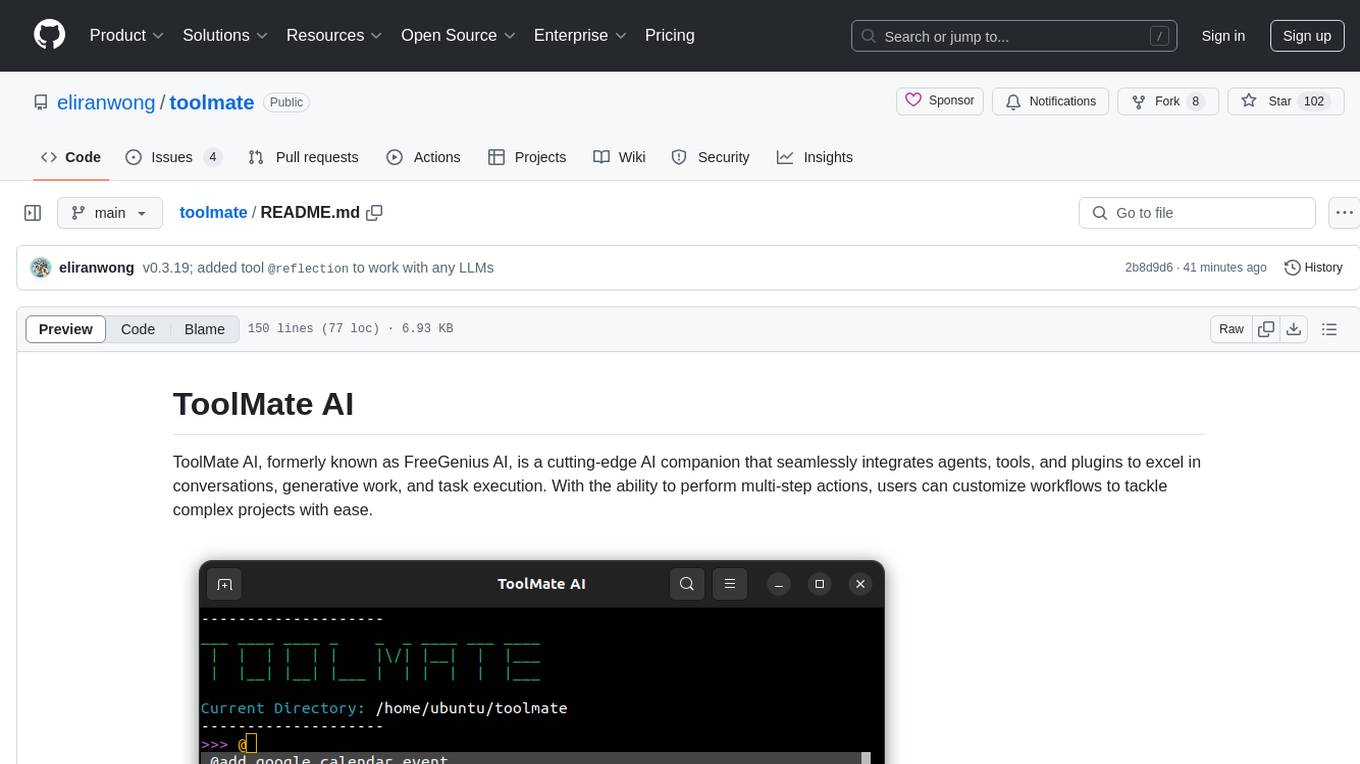
toolmate
ToolMate AI is an advanced AI companion that integrates agents, tools, and plugins to excel in conversations, generative work, and task execution. It supports multi-step actions, allowing users to customize workflows for tackling complex projects with ease. The tool offers a wide range of AI backends and models, including Ollama, Llama.cpp, Groq Cloud API, OpenAI API, and Google Gemini via Vertex AI. Users can easily switch between backends and leverage AI models like wizardlm2 and mixtral. ToolMate AI stands out for its distinctive features such as tool calling for any LLMs, running multiple tools in one go, highly customizable plugins, and integration with popular AI tools. It also supports quick tool calling using '@' notation and enables the execution of computing tasks on demand. With features like multiple tools in one go, customizable plugins, system command and fabric integration, GPU offloading support, real-time data access, and device information retrieval, ToolMate AI offers a comprehensive solution for various tasks and content creation.
CodeNomad
CodeNomad is a fast, multi-instance workspace designed for users who spend extended hours in OpenCode. It provides a premium, low-latency environment with features like managing multiple OpenCode sessions side-by-side, global command palette for keyboard-first control, rich media previews, and browser support via CodeNomad Server. Users can choose between a Desktop App (Electron-based) with global shortcuts and deeper system integration, a Tauri App for lightweight high-performance experience, or run CodeNomad as a local server accessed via web browser. The tool supports multi-instance workspace, long-session native scrolling, command palette for easy navigation, and deep task awareness to monitor background tasks and child sessions without interruptions.
mobile-use
Mobile-use is an open-source AI agent that controls Android or IOS devices using natural language. It understands commands to perform tasks like sending messages and navigating apps. Features include natural language control, UI-aware automation, data scraping, and extensibility. Users can automate their mobile experience by setting up environment variables, customizing LLM configurations, and launching the tool via Docker or manually for development. The tool supports physical Android phones, Android simulators, and iOS simulators. Contributions are welcome, and the project is licensed under MIT.
ChatGPT-desktop
ChatGPT Desktop Application is a multi-platform tool that provides a powerful AI wrapper for generating text. It offers features like text-to-speech, exporting chat history in various formats, automatic application upgrades, system tray hover window, support for slash commands, customization of global shortcuts, and pop-up search. The application is built using Tauri and aims to enhance user experience by simplifying text generation tasks. It is available for Mac, Windows, and Linux, and is designed for personal learning and research purposes.
mu
Mu is a collection of simple tools for everyday use that respect users' time by providing utilities without ads, algorithms, or tracking. It includes features like personalized dashboard, microblogging, AI-powered chat, RSS feeds with AI summaries, ad-free YouTube viewing, private messaging & email, and crypto payments. Users can self-host Mu or use the hosted version at mu.xyz. The tools are designed to be small, focused, and do one thing well, enhancing some features with AI capabilities like auto-tagging topics, summarizing articles, and providing knowledge assistance.
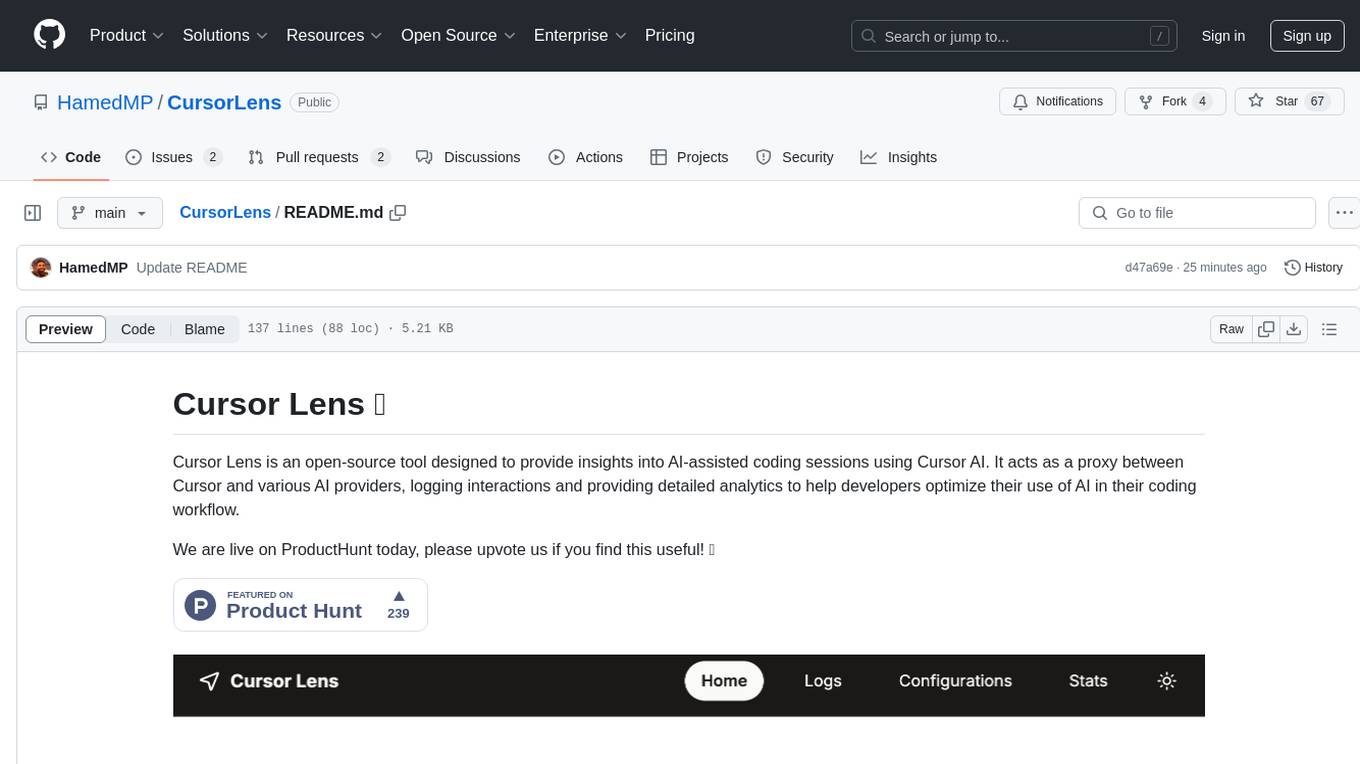
CursorLens
Cursor Lens is an open-source tool that acts as a proxy between Cursor and various AI providers, logging interactions and providing detailed analytics to help developers optimize their use of AI in their coding workflow. It supports multiple AI providers, captures and logs all requests, provides visual analytics on AI usage, allows users to set up and switch between different AI configurations, offers real-time monitoring of AI interactions, tracks token usage, estimates costs based on token usage and model pricing. Built with Next.js, React, PostgreSQL, Prisma ORM, Vercel AI SDK, Tailwind CSS, and shadcn/ui components.
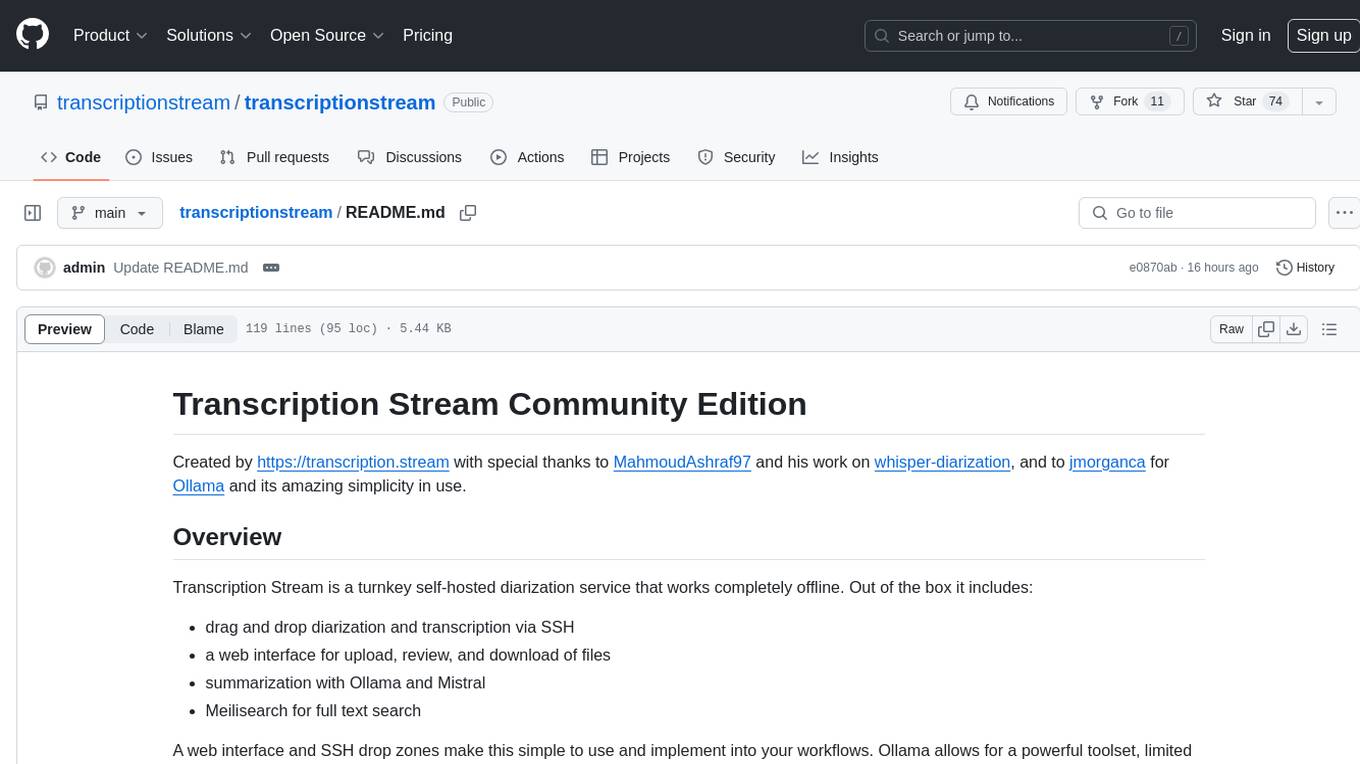
transcriptionstream
Transcription Stream is a self-hosted diarization service that works offline, allowing users to easily transcribe and summarize audio files. It includes a web interface for file management, Ollama for complex operations on transcriptions, and Meilisearch for fast full-text search. Users can upload files via SSH or web interface, with output stored in named folders. The tool requires a NVIDIA GPU and provides various scripts for installation and running. Ports for SSH, HTTP, Ollama, and Meilisearch are specified, along with access details for SSH server and web interface. Customization options and troubleshooting tips are provided in the documentation.

QodeAssist
QodeAssist is an AI-powered coding assistant plugin for Qt Creator, offering intelligent code completion and suggestions for C++ and QML. It leverages large language models like Ollama to enhance coding productivity with context-aware AI assistance directly in the Qt development environment. The plugin supports multiple LLM providers, extensive model-specific templates, and easy configuration for enhanced coding experience.
For similar tasks
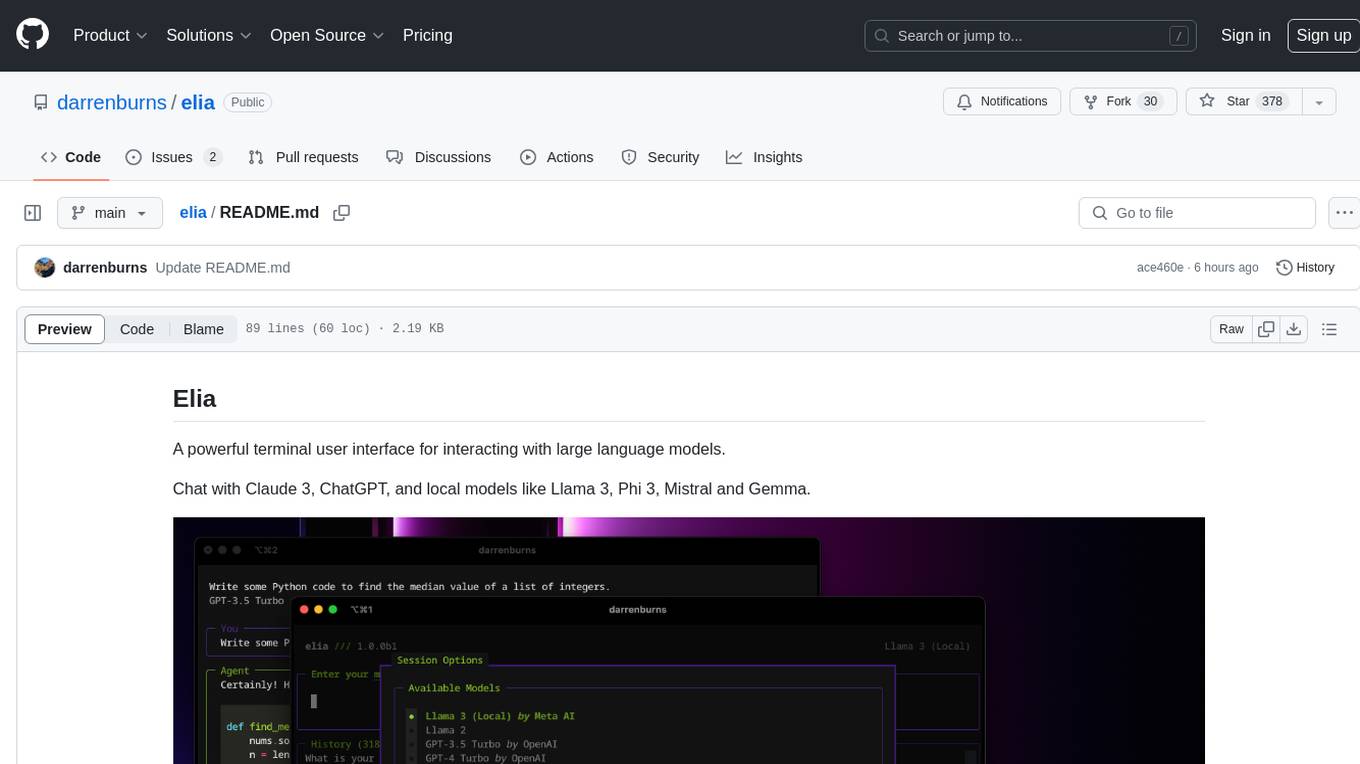
elia
Elia is a powerful terminal user interface designed for interacting with large language models. It allows users to chat with models like Claude 3, ChatGPT, Llama 3, Phi 3, Mistral, and Gemma. Conversations are stored locally in a SQLite database, ensuring privacy. Users can run local models through 'ollama' without data leaving their machine. Elia offers easy installation with pipx and supports various environment variables for different models. It provides a quick start to launch chats and manage local models. Configuration options are available to customize default models, system prompts, and add new models. Users can import conversations from ChatGPT and wipe the database when needed. Elia aims to enhance user experience in interacting with language models through a user-friendly interface.

mistral-inference
Mistral Inference repository contains minimal code to run 7B, 8x7B, and 8x22B models. It provides model download links, installation instructions, and usage guidelines for running models via CLI or Python. The repository also includes information on guardrailing, model platforms, deployment, and references. Users can interact with models through commands like mistral-demo, mistral-chat, and mistral-common. Mistral AI models support function calling and chat interactions for tasks like testing models, chatting with models, and using Codestral as a coding assistant. The repository offers detailed documentation and links to blogs for further information.
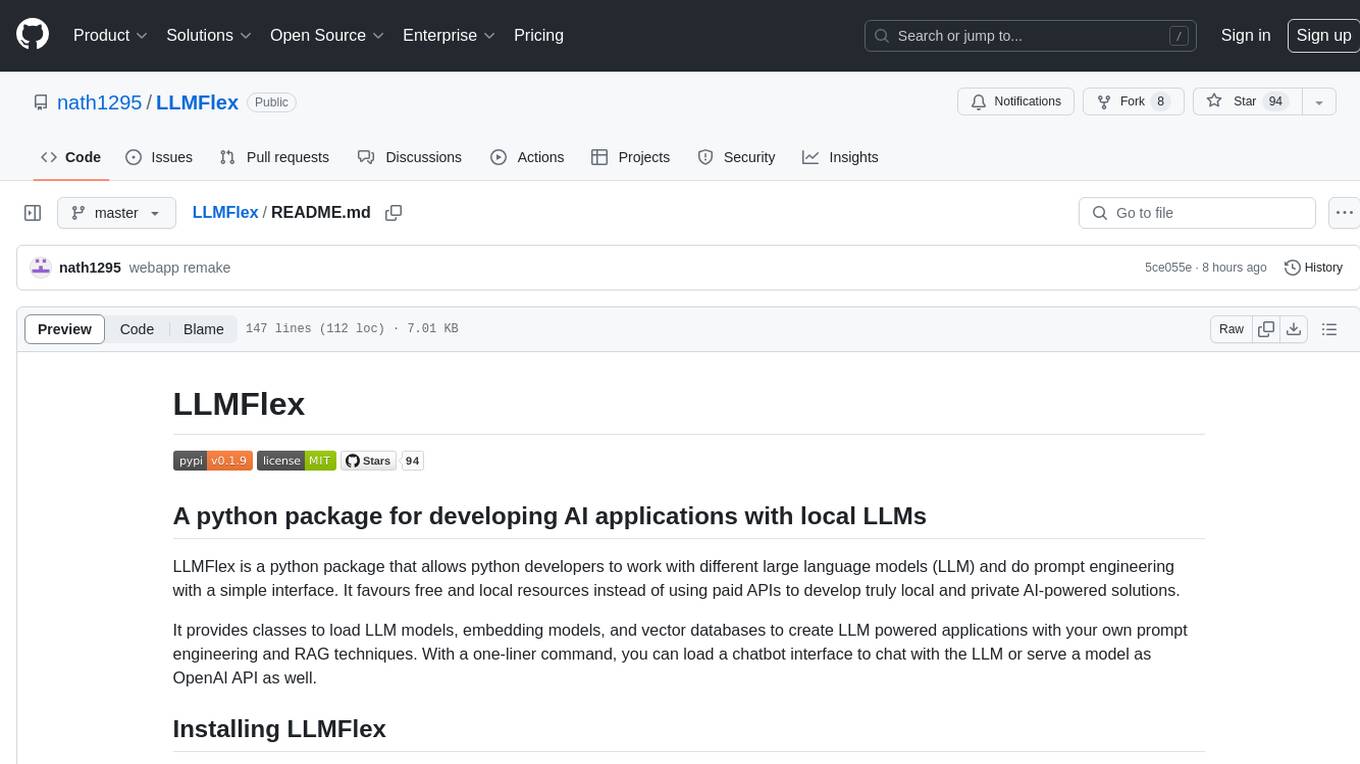
LLMFlex
LLMFlex is a python package designed for developing AI applications with local Large Language Models (LLMs). It provides classes to load LLM models, embedding models, and vector databases to create AI-powered solutions with prompt engineering and RAG techniques. The package supports multiple LLMs with different generation configurations, embedding toolkits, vector databases, chat memories, prompt templates, custom tools, and a chatbot frontend interface. Users can easily create LLMs, load embeddings toolkit, use tools, chat with models in a Streamlit web app, and serve an OpenAI API with a GGUF model. LLMFlex aims to offer a simple interface for developers to work with LLMs and build private AI solutions using local resources.
minimal-chat
MinimalChat is a minimal and lightweight open-source chat application with full mobile PWA support that allows users to interact with various language models, including GPT-4 Omni, Claude Opus, and various Local/Custom Model Endpoints. It focuses on simplicity in setup and usage while being fully featured and highly responsive. The application supports features like fully voiced conversational interactions, multiple language models, markdown support, code syntax highlighting, DALL-E 3 integration, conversation importing/exporting, and responsive layout for mobile use.
chat-with-mlx
Chat with MLX is an all-in-one Chat Playground using Apple MLX on Apple Silicon Macs. It provides privacy-enhanced AI for secure conversations with various models, easy integration of HuggingFace and MLX Compatible Open-Source Models, and comes with default models like Llama-3, Phi-3, Yi, Qwen, Mistral, Codestral, Mixtral, StableLM. The tool is designed for developers and researchers working with machine learning models on Apple Silicon.

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.
ell
ell is a command-line interface for Language Model Models (LLMs) written in Bash. It allows users to interact with LLMs from the terminal, supports piping, context bringing, and chatting with LLMs. Users can also call functions and use templates. The tool requires bash, jq for JSON parsing, curl for HTTPS requests, and perl for PCRE. Configuration involves setting variables for different LLM models and APIs. Usage examples include asking questions, specifying models, recording input/output, running in interactive mode, and using templates. The tool is lightweight, easy to install, and pipe-friendly, making it suitable for interacting with LLMs in a terminal environment.
Ollama-SwiftUI
Ollama-SwiftUI is a user-friendly interface for Ollama.ai created in Swift. It allows seamless chatting with local Large Language Models on Mac. Users can change models mid-conversation, restart conversations, send system prompts, and use multimodal models with image + text. The app supports managing models, including downloading, deleting, and duplicating them. It offers light and dark mode, multiple conversation tabs, and a localized interface in English and Arabic.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.