
AIOLists
Stremio Addon with a bunch of features to manage lists from MDBList and Trakt
Stars: 85
AIOLists is a stateless open source list management addon for Stremio that allows users to import and manage lists from various sources in one place. It offers unified search, metadata customization, Trakt integration, MDBList integration, external lists import, list sorting, customization options, watchlist updates, RPDB support, genre filtering, discovery lists, and shareable configurations. The addon aims to enhance the list management experience for Stremio users by providing a comprehensive set of features and functionalities.
README:
AIOLists is a stateless open source list management addon for Stremio. The project originated from this post, since then I have continued development to add features I would personally want in a list management addon, and fixed bugs shared by the users.
- Unified List Management: Import and manage lists from various sources in one place.
- Unified Search: Choose between Cinemeta, Trakt, TMDB or all 3 aggregated search.
- Metadata: Choose between Cinemeta or TMDB metadata, and choose between one of their extensive set of supported languages.
- MDBList & Trakt URL Imports: Directly import lists by pasting URLs from MDBList.com and Trakt.tv no API key or connection needed.
- Trakt Integration: Connect your Trakt account to access personal lists, watchlist, recommendations, trending, and popular content.
- MDBList Integration: Enter your MDBList API Key and import all your personal lists and watchlists into one place.
- External Lists from Addon: From letterboxd to anime lists import manifest.json from any external addon into AIOLists.
- Sorting: If the sorting option exists it's there.
-
List Customization:
- Change type: Instead of movies/series change it to whatever you want, even make it blank.
- Reorder: Drag and drop to arrange lists as you like.
- Rename: Give custom names to any list for better organization.
- Merge/Split: If a list contains both movies and series you can merge it into a single Stremio row so it doesn't take up more space than it needs to.
- Hide/Show from homeview: Hide lists from homeview, while still accessing them through the Discover tab.
- Instant Watchlist Updates: Fetches watchlist content on load.
- RPDB Support: Optional RatingPosterDB (RPDB) integration for enhanced poster images across all your lists (requires your own RPDB API key).
- Configurable Genre Filtering: If you add too many list you might hit the 8kb manifest size limit. By disabling genre filtering the manifest size should half so you can have more lists.
- Discovery Lists: Randomly selected MDBList from a set list of users, a new random list is delivered everytime you refresh the catalog.
- Share Your Setup: Generate a shareable hash of your AIOLists configuration (list order, names, imported addons) to share with others.
Speed up the loading time of lists in StremioMerged and Anime Search- Fix issues:
- Rework genre filtering
- Add sorting option for MDBList added without key
- Support for Streams/TV lists from external addons
- Randomize option for lists without sort options
- Better TMDB list support
- Maybe features:
- Switching Profiles
- Native Trakt persistance
Due to the stateless nature of this addon Trakt keys can't automatically update when they expire. I have added an option to make Trakt persistant through Upstash. You can create a free account on there. Here's a short guide:
- Create an account, using a temp-mail works fine.
- After logging in you will be prompted to Create a database press Create Database.
- Input a Name and the region closest to you.
- Next -> Next -> Create
- Scroll down to REST API section and copy UPSTASH_REDIS_REST_URL and UPSTASH_REDIS_REST_TOKEN and put them into AIOLists.
Your Trakt tokens are now stored in the redis db and will automatically refresh when they expire.
If you find this project useful, the best way to support me is to star this repository on GitHub!
AIOLists supports several environment variables for advanced configuration:
Create a .env file in the root directory with the following variables:
# TMDB Configuration
TMDB_REDIRECT_URI=your_tmdb_redirect_uri_here
TMDB_BEARER_TOKEN=your_tmdb_bearer_token_here- TMDB_REDIRECT_URI: Redirect URI for TMDB OAuth. When set, users will be redirected after authentication.
- TMDB_BEARER_TOKEN: Your TMDB Read Access Token. When set, the bearer token field is hidden in the UI and this token is used automatically.
When both TMDB_BEARER_TOKEN and redirect URIs are configured, the "Connect to TMDB" button will redirect users directly to the authentication pages instead of showing manual steps.
The easiest way to host this project for free is through hugging face.
Steps:
- Create a huggingface account. https://huggingface.co/
- Go to https://huggingface.co/new-space?sdk=docker
- Fill in the Space name and Create Space
- Scroll down to "Create your Dockerfile" and press "create the Dockerfile" at the bottom of the section.
- Paste in
FROM ghcr.io/sebastianmorel/aiolists:latest ENV PORT=7860
- Press "Commit new file to main"
- Go to settings and add your TMDB_REDIRECT_URI (username-projectname.hf.space) and TMDB_BEARER_TOKEN
- Wait for it to finish building and you should have your own instance.
Most modern PaaS providers that support Docker can deploy AIOLists.
-
Railway: Connect your GitHub repository and let Railway build from the
Dockerfile. Set thePORTenvironment variable if needed (Railway usually injects it). -
Render: Create a new "Web Service", connect your repository, and choose Docker as the environment. Render will build and deploy from the
Dockerfile. Set thePORTenvironment variable. -
Fly.io: Use the
flyctlCLI to launch a new app. It can often detect and use yourDockerfile.
Steps:
-
Clone your fork (or the original repository):
git clone https://github.com/YOUR_USERNAME/AIOLists.git # Replace YOUR_USERNAME if you forked cd AIOLists
-
Build the Docker image:
docker build -t aiolists-addon . -
Run the container:
docker run -d -p 7000:7000 -e NODE_ENV=production --restart unless-stopped aiolists-addon
Your addon will be available at
http://YOUR_SERVER_IP:7000. You can then access the configuration panel athttp://YOUR_SERVER_IP:7000/configure.
You can also run the addon directly with Node.js if you prefer not to use Docker.
-
Clone your fork:
git clone https://github.com/YOUR_USERNAME/AIOLists.git cd AIOLists -
Install dependencies:
npm install --production
-
Start the server:
The server will start on port 7000 by default. Access
npm run prod
/configure.




MIT
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AIOLists
Similar Open Source Tools
AIOLists
AIOLists is a stateless open source list management addon for Stremio that allows users to import and manage lists from various sources in one place. It offers unified search, metadata customization, Trakt integration, MDBList integration, external lists import, list sorting, customization options, watchlist updates, RPDB support, genre filtering, discovery lists, and shareable configurations. The addon aims to enhance the list management experience for Stremio users by providing a comprehensive set of features and functionalities.

cognita
Cognita is an open-source framework to organize your RAG codebase along with a frontend to play around with different RAG customizations. It provides a simple way to organize your codebase so that it becomes easy to test it locally while also being able to deploy it in a production ready environment. The key issues that arise while productionizing RAG system from a Jupyter Notebook are: 1. **Chunking and Embedding Job** : The chunking and embedding code usually needs to be abstracted out and deployed as a job. Sometimes the job will need to run on a schedule or be trigerred via an event to keep the data updated. 2. **Query Service** : The code that generates the answer from the query needs to be wrapped up in a api server like FastAPI and should be deployed as a service. This service should be able to handle multiple queries at the same time and also autoscale with higher traffic. 3. **LLM / Embedding Model Deployment** : Often times, if we are using open-source models, we load the model in the Jupyter notebook. This will need to be hosted as a separate service in production and model will need to be called as an API. 4. **Vector DB deployment** : Most testing happens on vector DBs in memory or on disk. However, in production, the DBs need to be deployed in a more scalable and reliable way. Cognita makes it really easy to customize and experiment everything about a RAG system and still be able to deploy it in a good way. It also ships with a UI that makes it easier to try out different RAG configurations and see the results in real time. You can use it locally or with/without using any Truefoundry components. However, using Truefoundry components makes it easier to test different models and deploy the system in a scalable way. Cognita allows you to host multiple RAG systems using one app. ### Advantages of using Cognita are: 1. A central reusable repository of parsers, loaders, embedders and retrievers. 2. Ability for non-technical users to play with UI - Upload documents and perform QnA using modules built by the development team. 3. Fully API driven - which allows integration with other systems. > If you use Cognita with Truefoundry AI Gateway, you can get logging, metrics and feedback mechanism for your user queries. ### Features: 1. Support for multiple document retrievers that use `Similarity Search`, `Query Decompostion`, `Document Reranking`, etc 2. Support for SOTA OpenSource embeddings and reranking from `mixedbread-ai` 3. Support for using LLMs using `Ollama` 4. Support for incremental indexing that ingests entire documents in batches (reduces compute burden), keeps track of already indexed documents and prevents re-indexing of those docs.
your-source-to-prompt.html
Your Source to Prompt is a single HTML file tool that allows users to easily select code files and combine them into a single text output. It runs entirely in the browser, ensuring local and secure operation without any external dependencies. The tool offers features like preset management, efficient file selection, context size awareness, hierarchical structure preview, minification, and user-friendly UI with dark mode. It aims to simplify the process of preparing code for Large Language Models (LLMs) by providing a well-structured prompt context.
burpference
Burpference is an open-source extension designed to capture in-scope HTTP requests and responses from Burp's proxy history and send them to a remote LLM API in JSON format. It automates response capture, integrates with APIs, optimizes resource usage, provides color-coded findings visualization, offers comprehensive logging, supports native Burp reporting, and allows flexible configuration. Users can customize system prompts, API keys, and remote hosts, and host models locally to prevent high inference costs. The tool is ideal for offensive web application engagements to surface findings and vulnerabilities.
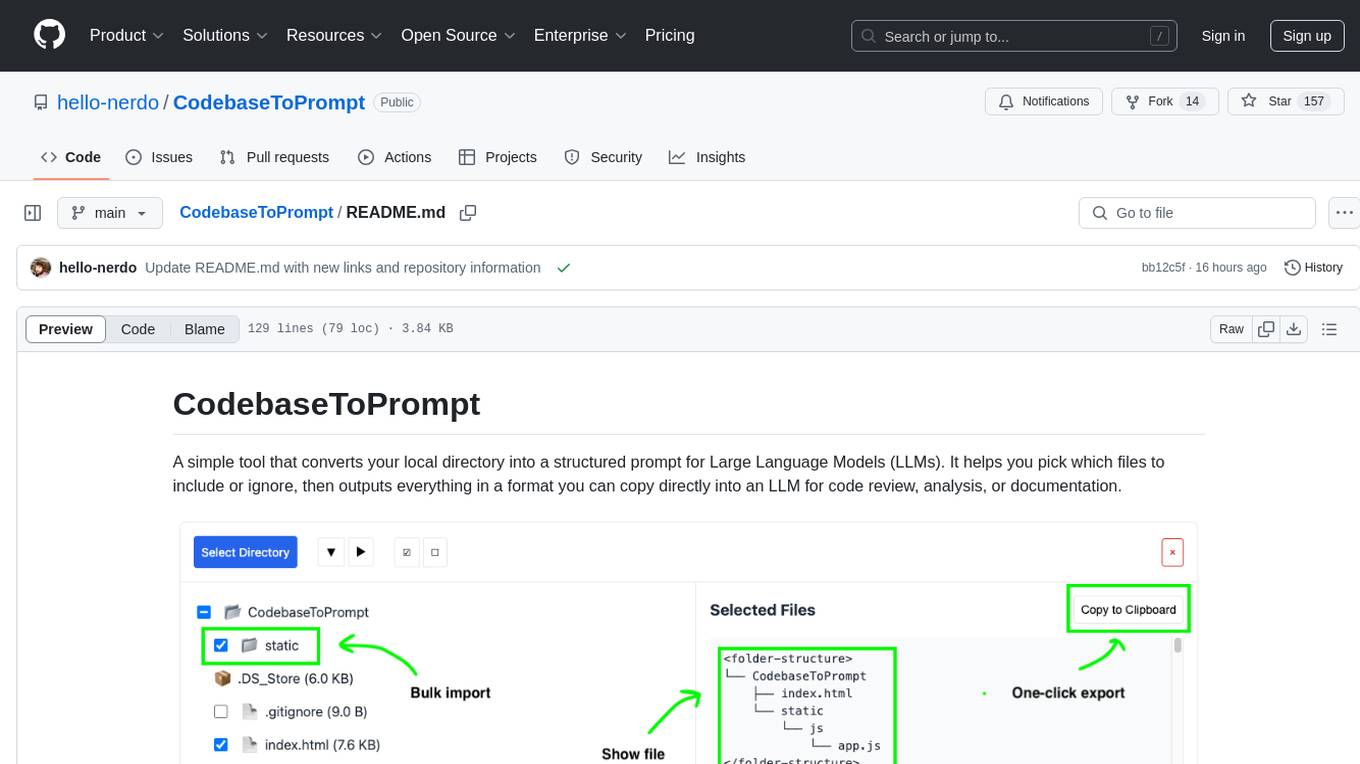
CodebaseToPrompt
CodebaseToPrompt is a tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in an interactive interface. The tool generates a formatted output that can be directly used with LLMs, estimates token count, and supports flexible text selection. Users can deploy the tool using Docker for self-contained usage and can contribute to the project by opening issues or submitting pull requests.

AIOStreams
AIOStreams is a versatile tool that combines streams from various addons into one platform, offering extensive customization options. Users can change result formats, filter results by various criteria, remove duplicates, prioritize services, sort results, specify size limits, and more. The tool scrapes results from selected addons, applies user configurations, and presents the results in a unified manner. It simplifies the process of finding and accessing desired content from multiple sources, enhancing user experience and efficiency.
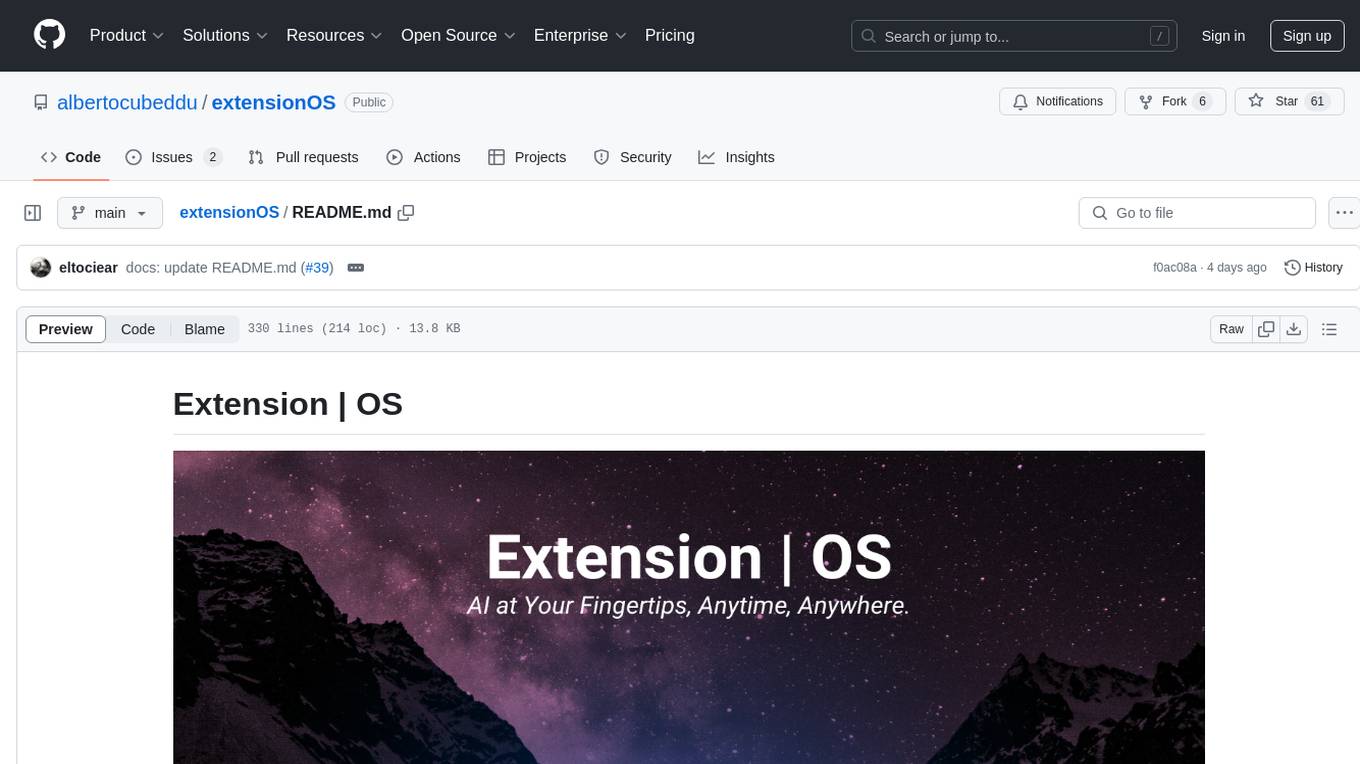
extensionOS
Extension | OS is an open-source browser extension that brings AI directly to users' web browsers, allowing them to access powerful models like LLMs seamlessly. Users can create prompts, fix grammar, and access intelligent assistance without switching tabs. The extension aims to revolutionize online information interaction by integrating AI into everyday browsing experiences. It offers features like Prompt Factory for tailored prompts, seamless LLM model access, secure API key storage, and a Mixture of Agents feature. The extension was developed to empower users to unleash their creativity with custom prompts and enhance their browsing experience with intelligent assistance.

mikupad
mikupad is a lightweight and efficient language model front-end powered by ReactJS, all packed into a single HTML file. Inspired by the likes of NovelAI, it provides a simple yet powerful interface for generating text with the help of various backends.
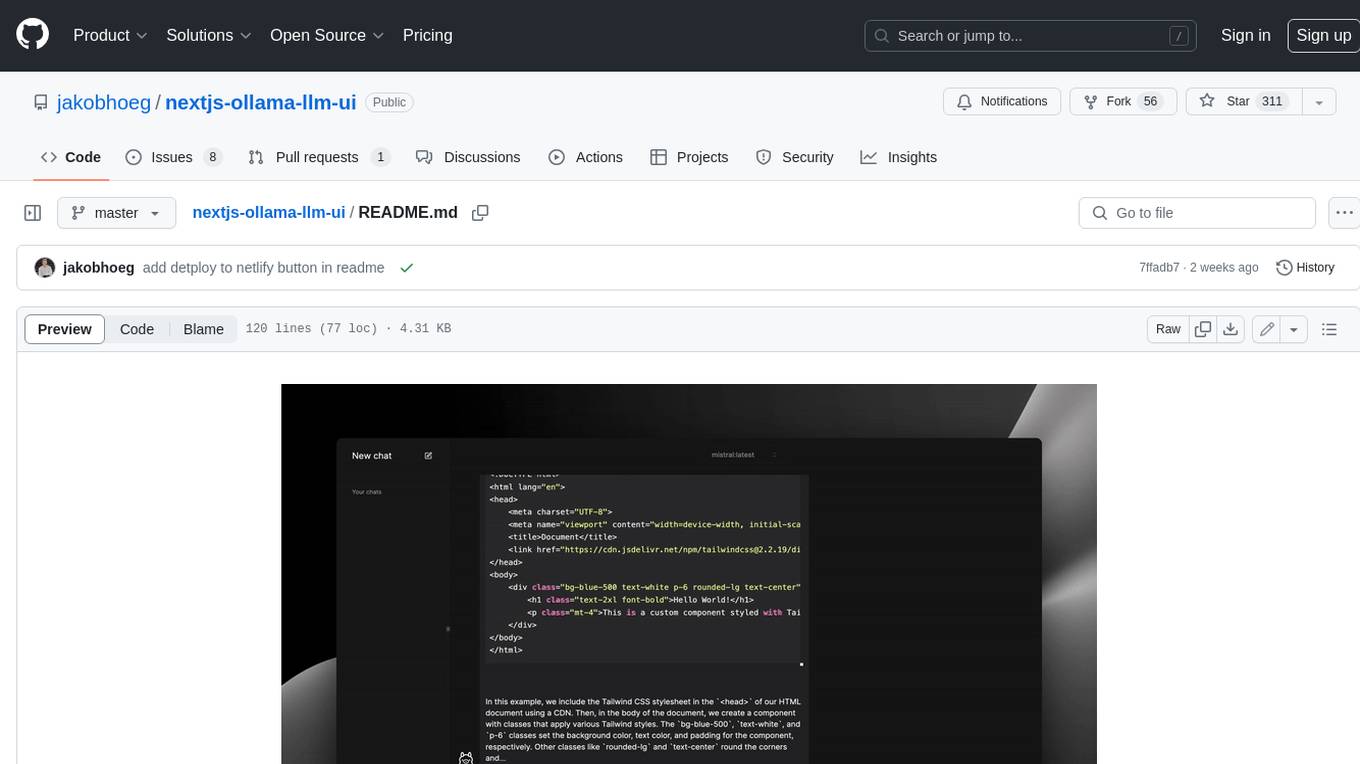
nextjs-ollama-llm-ui
This web interface provides a user-friendly and feature-rich platform for interacting with Ollama Large Language Models (LLMs). It offers a beautiful and intuitive UI inspired by ChatGPT, making it easy for users to get started with LLMs. The interface is fully local, storing chats in local storage for convenience, and fully responsive, allowing users to chat on their phones with the same ease as on a desktop. It features easy setup, code syntax highlighting, and the ability to easily copy codeblocks. Users can also download, pull, and delete models directly from the interface, and switch between models quickly. Chat history is saved and easily accessible, and users can choose between light and dark mode. To use the web interface, users must have Ollama downloaded and running, and Node.js (18+) and npm installed. Installation instructions are provided for running the interface locally. Upcoming features include the ability to send images in prompts, regenerate responses, import and export chats, and add voice input support.
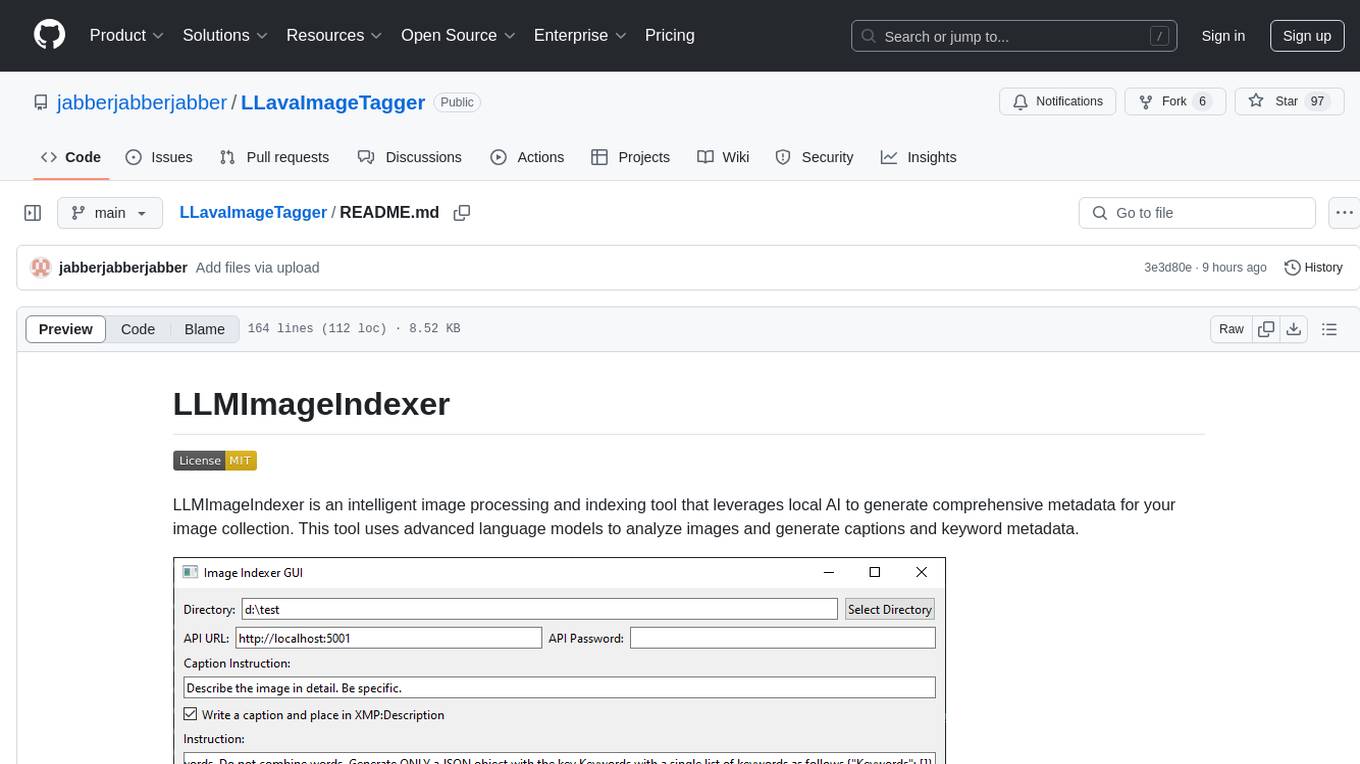
LLavaImageTagger
LLMImageIndexer is an intelligent image processing and indexing tool that leverages local AI to generate comprehensive metadata for your image collection. It uses advanced language models to analyze images and generate captions and keyword metadata. The tool offers features like intelligent image analysis, metadata enhancement, local processing, multi-format support, user-friendly GUI, GPU acceleration, cross-platform support, stop and start capability, and keyword post-processing. It operates directly on image file metadata, allowing users to manage files, add new files, and run the tool multiple times without reprocessing previously keyworded files. Installation instructions are provided for Windows, macOS, and Linux platforms, along with usage guidelines and configuration options.

Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.
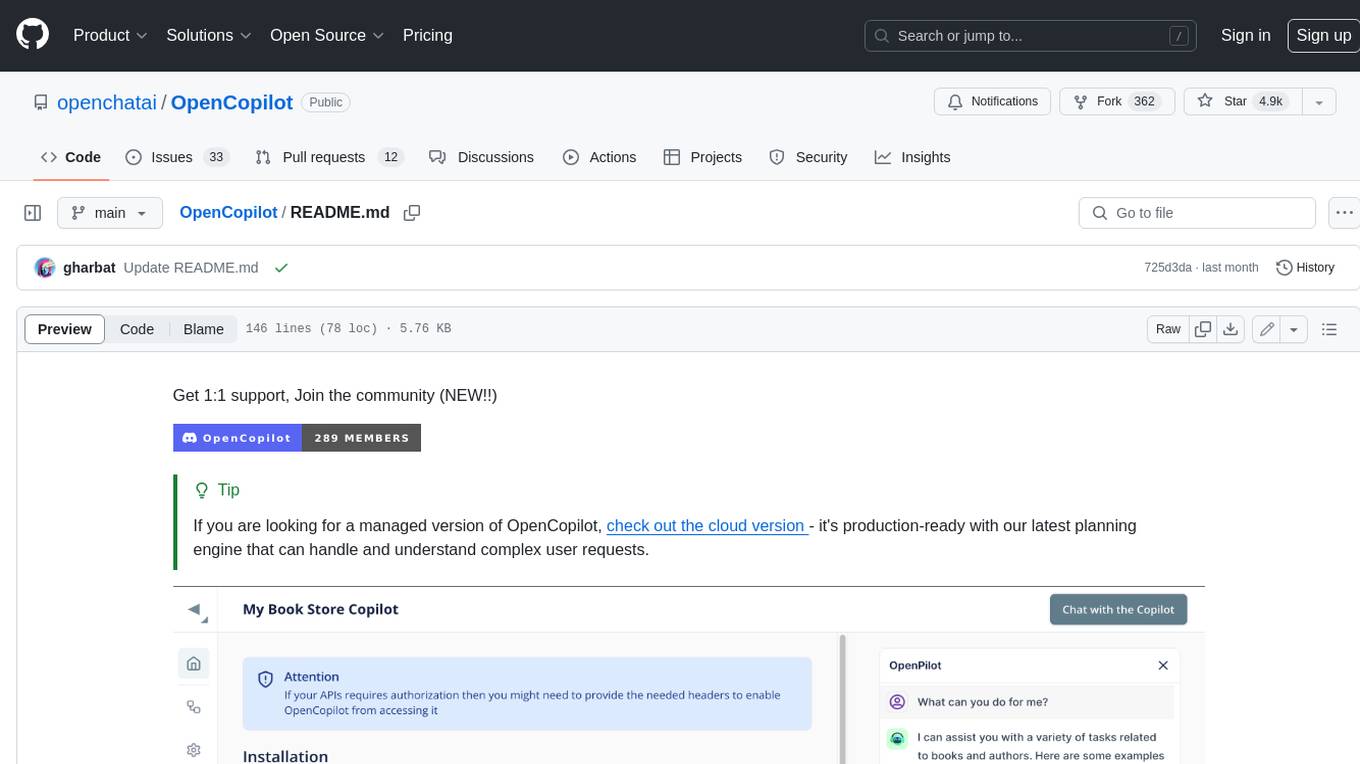
OpenCopilot
OpenCopilot allows you to have your own product's AI copilot. It integrates with your underlying APIs and can execute API calls whenever needed. It uses LLMs to determine if the user's request requires calling an API endpoint. Then, it decides which endpoint to call and passes the appropriate payload based on the given API definition.
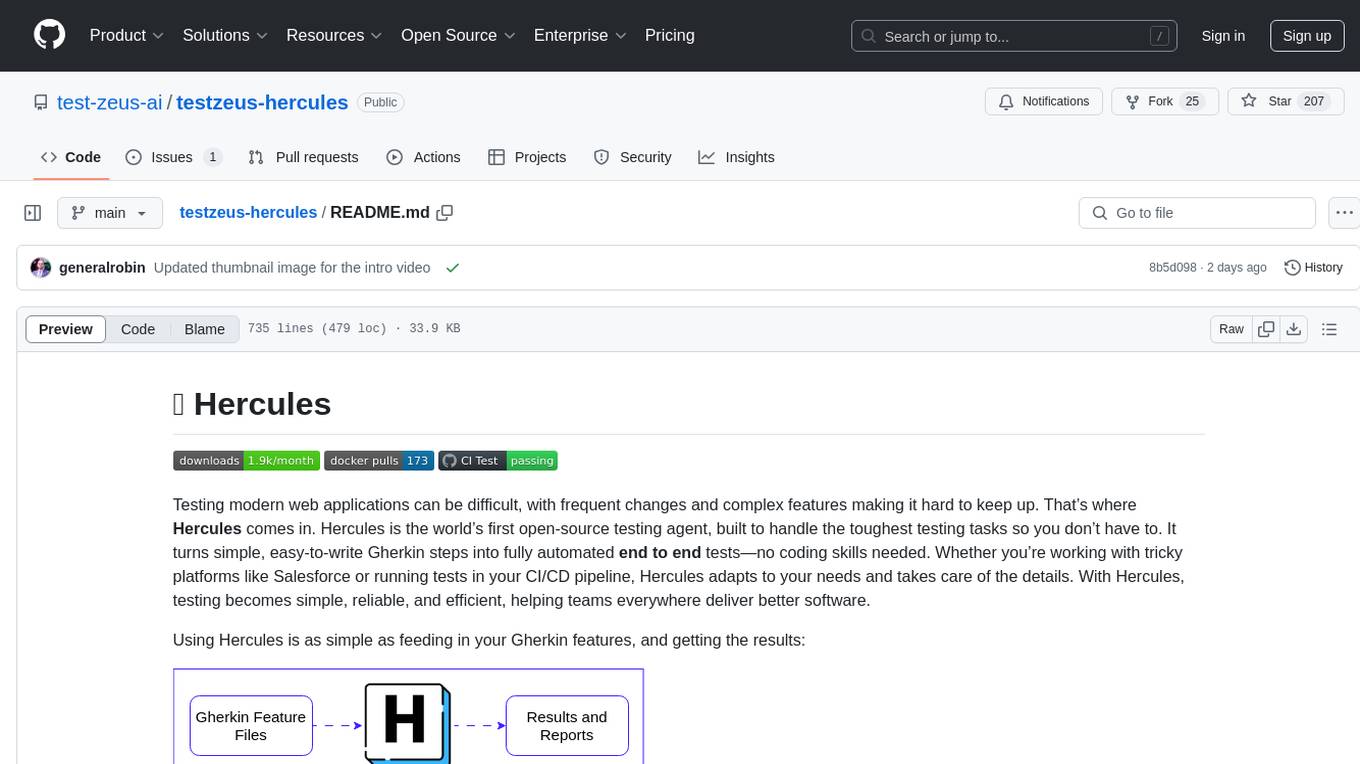
testzeus-hercules
Hercules is the world’s first open-source testing agent designed to handle the toughest testing tasks for modern web applications. It turns simple Gherkin steps into fully automated end-to-end tests, making testing simple, reliable, and efficient. Hercules adapts to various platforms like Salesforce and is suitable for CI/CD pipelines. It aims to democratize and disrupt test automation, making top-tier testing accessible to everyone. The tool is transparent, reliable, and community-driven, empowering teams to deliver better software. Hercules offers multiple ways to get started, including using PyPI package, Docker, or building and running from source code. It supports various AI models, provides detailed installation and usage instructions, and integrates with Nuclei for security testing and WCAG for accessibility testing. The tool is production-ready, open core, and open source, with plans for enhanced LLM support, advanced tooling, improved DOM distillation, community contributions, extensive documentation, and a bounty program.

CodebaseToPrompt
CodebaseToPrompt is a simple tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in a browser-based interface. The tool generates a formatted output that can be directly used with AI tools, provides token count estimates, and supports local storage for saving selections. Users can easily copy the selected files in the desired format for further use.
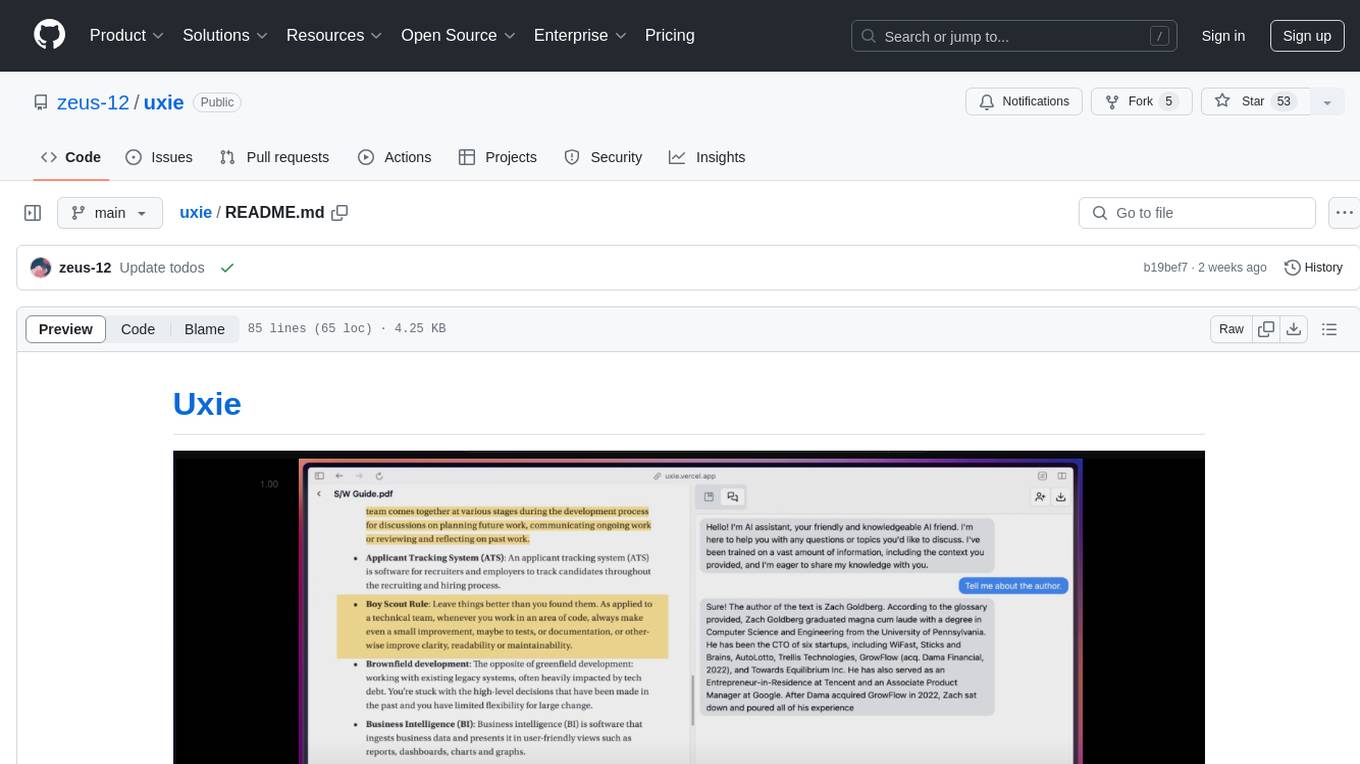
uxie
Uxie is a PDF reader app designed to revolutionize the learning experience. It offers features such as annotation, note-taking, collaboration tools, integration with LLM for enhanced learning, and flashcard generation with LLM feedback. Built using Nextjs, tRPC, Zod, TypeScript, Tailwind CSS, React Query, React Hook Form, Supabase, Prisma, and various other tools. Users can take notes, summarize PDFs, chat and collaborate with others, create custom blocks in the editor, and use AI-powered text autocompletion. The tool allows users to craft simple flashcards, test knowledge, answer questions, and receive instant feedback through AI evaluation.

bedrock-claude-chatbot
Bedrock Claude ChatBot is a Streamlit application that provides a conversational interface for users to interact with various Large Language Models (LLMs) on Amazon Bedrock. Users can ask questions, upload documents, and receive responses from the AI assistant. The app features conversational UI, document upload, caching, chat history storage, session management, model selection, cost tracking, logging, and advanced data analytics tool integration. It can be customized using a config file and is extensible for implementing specialized tools using Docker containers and AWS Lambda. The app requires access to Amazon Bedrock Anthropic Claude Model, S3 bucket, Amazon DynamoDB, Amazon Textract, and optionally Amazon Elastic Container Registry and Amazon Athena for advanced analytics features.
For similar tasks
AIOLists
AIOLists is a stateless open source list management addon for Stremio that allows users to import and manage lists from various sources in one place. It offers unified search, metadata customization, Trakt integration, MDBList integration, external lists import, list sorting, customization options, watchlist updates, RPDB support, genre filtering, discovery lists, and shareable configurations. The addon aims to enhance the list management experience for Stremio users by providing a comprehensive set of features and functionalities.
For similar jobs

book
Podwise is an AI knowledge management app designed specifically for podcast listeners. With the Podwise platform, you only need to follow your favorite podcasts, such as "Hardcore Hackers". When a program is released, Podwise will use AI to transcribe, extract, summarize, and analyze the podcast content, helping you to break down the hard-core podcast knowledge. At the same time, it is connected to platforms such as Notion, Obsidian, Logseq, and Readwise, embedded in your knowledge management workflow, and integrated with content from other channels including news, newsletters, and blogs, helping you to improve your second brain 🧠.

extractor
Extractor is an AI-powered data extraction library for Laravel that leverages OpenAI's capabilities to effortlessly extract structured data from various sources, including images, PDFs, and emails. It features a convenient wrapper around OpenAI Chat and Completion endpoints, supports multiple input formats, includes a flexible Field Extractor for arbitrary data extraction, and integrates with Textract for OCR functionality. Extractor utilizes JSON Mode from the latest GPT-3.5 and GPT-4 models, providing accurate and efficient data extraction.

Scrapegraph-ai
ScrapeGraphAI is a Python library that uses Large Language Models (LLMs) and direct graph logic to create web scraping pipelines for websites, documents, and XML files. It allows users to extract specific information from web pages by providing a prompt describing the desired data. ScrapeGraphAI supports various LLMs, including Ollama, OpenAI, Gemini, and Docker, enabling users to choose the most suitable model for their needs. The library provides a user-friendly interface through its `SmartScraper` class, which simplifies the process of building and executing scraping pipelines. ScrapeGraphAI is open-source and available on GitHub, with extensive documentation and examples to guide users. It is particularly useful for researchers and data scientists who need to extract structured data from web pages for analysis and exploration.

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.

auto-news
Auto-News is an automatic news aggregator tool that utilizes Large Language Models (LLM) to pull information from various sources such as Tweets, RSS feeds, YouTube videos, web articles, Reddit, and journal notes. The tool aims to help users efficiently read and filter content based on personal interests, providing a unified reading experience and organizing information effectively. It features feed aggregation with summarization, transcript generation for videos and articles, noise reduction, task organization, and deep dive topic exploration. The tool supports multiple LLM backends, offers weekly top-k aggregations, and can be deployed on Linux/MacOS using docker-compose or Kubernetes.

SemanticFinder
SemanticFinder is a frontend-only live semantic search tool that calculates embeddings and cosine similarity client-side using transformers.js and SOTA embedding models from Huggingface. It allows users to search through large texts like books with pre-indexed examples, customize search parameters, and offers data privacy by keeping input text in the browser. The tool can be used for basic search tasks, analyzing texts for recurring themes, and has potential integrations with various applications like wikis, chat apps, and personal history search. It also provides options for building browser extensions and future ideas for further enhancements and integrations.

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.

Agently-Daily-News-Collector
Agently Daily News Collector is an open-source project showcasing a workflow powered by the Agent ly AI application development framework. It allows users to generate news collections on various topics by inputting the field topic. The AI agents automatically perform the necessary tasks to generate a high-quality news collection saved in a markdown file. Users can edit settings in the YAML file, install Python and required packages, input their topic idea, and wait for the news collection to be generated. The process involves tasks like outlining, searching, summarizing, and preparing column data. The project dependencies include Agently AI Development Framework, duckduckgo-search, BeautifulSoup4, and PyYAM.