
cloudflare-rag
Fullstack "Chat with your PDFs" RAG (Retrieval Augmented Generation) app built fully on Cloudflare
Stars: 93
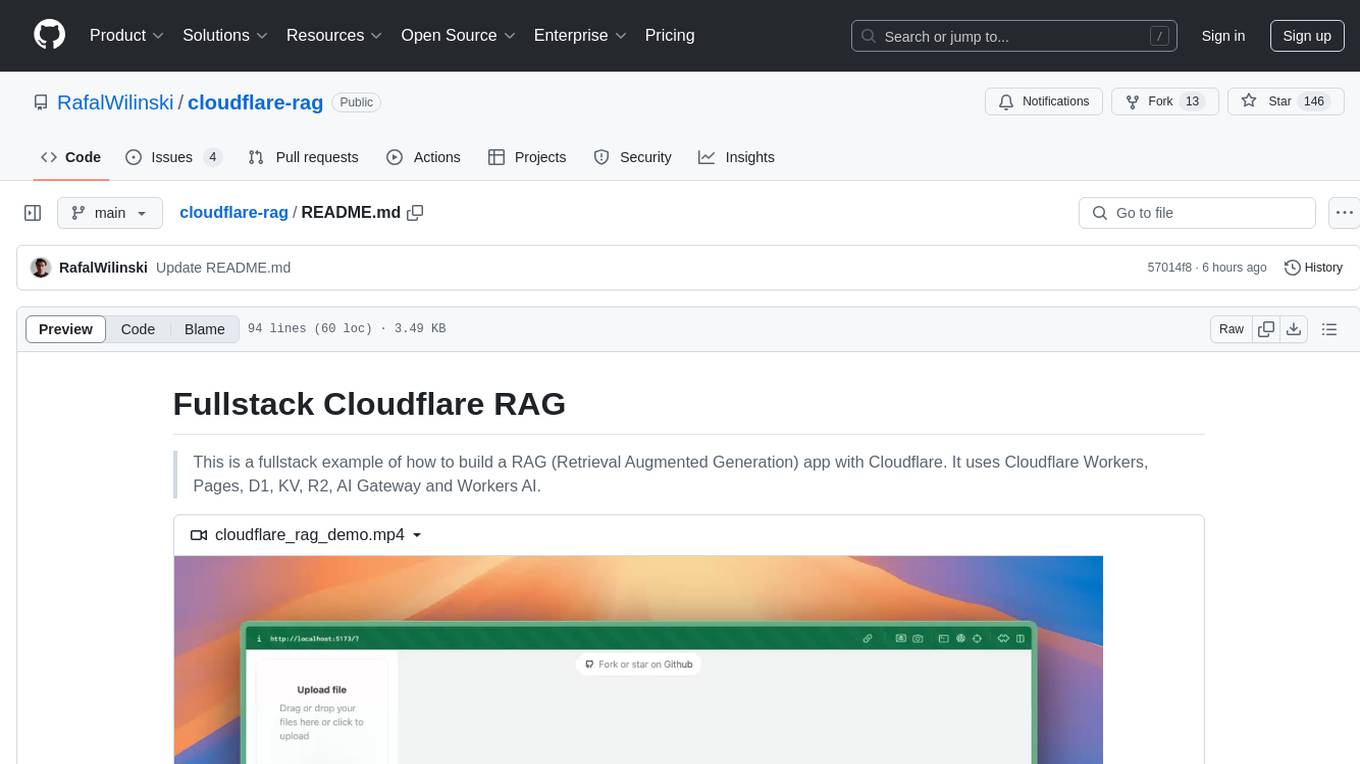
This repository provides a fullstack example of building a Retrieval Augmented Generation (RAG) app with Cloudflare. It utilizes Cloudflare Workers, Pages, D1, KV, R2, AI Gateway, and Workers AI. The app features streaming interactions to the UI, hybrid RAG with Full-Text Search and Vector Search, switchable providers using AI Gateway, per-IP rate limiting with Cloudflare's KV, OCR within Cloudflare Worker, and Smart Placement for workload optimization. The development setup requires Node, pnpm, and wrangler CLI, along with setting up necessary primitives and API keys. Deployment involves setting up secrets and deploying the app to Cloudflare Pages. The project implements a Hybrid Search RAG approach combining Full Text Search against D1 and Hybrid Search with embeddings against Vectorize to enhance context for the LLM.
README:
This is a fullstack example of how to build a RAG (Retrieval Augmented Generation) app with Cloudflare. It uses Cloudflare Workers, Pages, D1, KV, R2, AI Gateway and Workers AI.
https://github.com/user-attachments/assets/cbaa0380-7ad6-448d-ad44-e83772a9cf3f
Features:
- Every interaction is streamed to the UI using Server-Sent Events
- Hybrid RAG using Full-Text Search on D1 and Vector Search on Vectorize
- Switchable between various providers (OpenAI, Groq, Anthropic) using AI Gateway with fallbacks
- Per-IP Rate limiting using Cloudflare's KV
- OCR is running inside Cloudflare Worker using unpdf
- Smart Placement automatically places your workloads in an optimal location that minimizes latency and speeds up your applications
Make sure you have Node, pnpm and wrangler CLI installed.
Install dependencies:
pnpm install # or npm installDeploy necessary primitives:
./setup.shThen, in wrangler.toml, set the d1_databases.database_id to your D1 database id and kv_namespaces.rate_limiter to your rate limiter KV namespace id.
Then, create a .dev.vars file with your API keys:
CLOUDFLARE_ACCOUNT_ID=your-cloudflare-account-id # Required
GROQ_API_KEY=your-groq-api-key # Optional
OPENAI_API_KEY=your-openai-api-key # Optional
ANTHROPIC_API_KEY=your-anthropic-api-key # OptionalIf you don't have these keys, /api/stream will fallback to Workers AI.
Run the dev server:
npm run devAnd access the app at http://localhost:5173/.
Having the necessary primitives setup, first setup secrets:
npx wrangler secret put CLOUDFLARE_ACCOUNT_ID
npx wrangler secret put GROQ_API_KEY
npx wrangler secret put OPENAI_API_KEY
npx wrangler secret put ANTHROPIC_API_KEYThen, deploy your app to Cloudflare Pages:
npm run deploy
This project uses a combination of classical Full Text Search (sparse) against Cloudflare D1 and Hybrid Search with embeddings against Vectorize (dense) to provide the best of both worlds providing the most applicable context to the LLM.
The way it works is this:
- We take user input and we rewrite it to 5 different queries using an LLM
- We run each of these queries against our both datastores - D1 database using BM25 for full-text search and Vectorize for dense retrieval
- We take the results from both datastores and we merge them together using Reciprocal Rank Fusion which provides us with a single list of results
- We then take the top 10 results from this list and we pass them to the LLM to generate a response
This project is licensed under the terms of the MIT License.
If you need help in building AI applications, please reach out to me on Twitter or via my website. Happy to help!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for cloudflare-rag
Similar Open Source Tools
cloudflare-rag
This repository provides a fullstack example of building a Retrieval Augmented Generation (RAG) app with Cloudflare. It utilizes Cloudflare Workers, Pages, D1, KV, R2, AI Gateway, and Workers AI. The app features streaming interactions to the UI, hybrid RAG with Full-Text Search and Vector Search, switchable providers using AI Gateway, per-IP rate limiting with Cloudflare's KV, OCR within Cloudflare Worker, and Smart Placement for workload optimization. The development setup requires Node, pnpm, and wrangler CLI, along with setting up necessary primitives and API keys. Deployment involves setting up secrets and deploying the app to Cloudflare Pages. The project implements a Hybrid Search RAG approach combining Full Text Search against D1 and Hybrid Search with embeddings against Vectorize to enhance context for the LLM.

azure-search-openai-javascript
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access the ChatGPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval.

azure-search-openai-demo
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access a GPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval. The repo includes sample data so it's ready to try end to end. In this sample application we use a fictitious company called Contoso Electronics, and the experience allows its employees to ask questions about the benefits, internal policies, as well as job descriptions and roles.
vertex-ai-creative-studio
GenMedia Creative Studio is an application showcasing the capabilities of Google Cloud Vertex AI generative AI creative APIs. It includes features like Gemini for prompt rewriting and multimodal evaluation of generated images. The app is built with Mesop, a Python-based UI framework, enabling rapid development of web and internal apps. The Experimental folder contains stand-alone applications and upcoming features demonstrating cutting-edge generative AI capabilities, such as image generation, prompting techniques, and audio/video tools.
LLM_AppDev-HandsOn
This repository showcases how to build a simple LLM-based chatbot for answering questions based on documents using retrieval augmented generation (RAG) technique. It also provides guidance on deploying the chatbot using Podman or on the OpenShift Container Platform. The workshop associated with this repository introduces participants to LLMs & RAG concepts and demonstrates how to customize the chatbot for specific purposes. The software stack relies on open-source tools like streamlit, LlamaIndex, and local open LLMs via Ollama, making it accessible for GPU-constrained environments.
dream-team
Build your dream team with Autogen is a repository that leverages Microsoft Autogen 0.4, Azure OpenAI, and Streamlit to create an end-to-end multi-agent application. It provides an advanced multi-agent framework based on Magentic One, with features such as a friendly UI, single-line deployment, secure code execution, managed identities, and observability & debugging tools. Users can deploy Azure resources and the app with simple commands, work locally with virtual environments, install dependencies, update configurations, and run the application. The repository also offers resources for learning more about building applications with Autogen.
hashbrown
Hashbrown is a lightweight and efficient hashing library for Python, designed to provide easy-to-use cryptographic hashing functions for secure data storage and transmission. It supports a variety of hashing algorithms, including MD5, SHA-1, SHA-256, and SHA-512, allowing users to generate hash values for strings, files, and other data types. With Hashbrown, developers can quickly implement data integrity checks, password hashing, digital signatures, and other security features in their Python applications.

conversational-agent-langchain
This repository contains a Rest-Backend for a Conversational Agent that allows embedding documents, semantic search, QA based on documents, and document processing with Large Language Models. It uses Aleph Alpha and OpenAI Large Language Models to generate responses to user queries, includes a vector database, and provides a REST API built with FastAPI. The project also features semantic search, secret management for API keys, installation instructions, and development guidelines for both backend and frontend components.

raggenie
RAGGENIE is a low-code RAG builder tool designed to simplify the creation of conversational AI applications. It offers out-of-the-box plugins for connecting to various data sources and building conversational AI on top of them, including integration with pre-built agents for actions. The tool is open-source under the MIT license, with a current focus on making it easy to build RAG applications and future plans for maintenance, monitoring, and transitioning applications from pilots to production.
aws-bedrock-with-rag-and-react
This solution provides a low-code ReactJS application to prototype and vet business use cases for GenAI using Retrieval Augmented Generation (RAG). It includes a backend Flask application that uses LangChain to provide PDF data as embeddings to a text-gen model via Amazon Bedrock and a vector database with FAISS or Kendra Index. The solution utilizes Amazon Bedrock as the only cost-generating AWS service.

serverless-pdf-chat
The serverless-pdf-chat repository contains a sample application that allows users to ask natural language questions of any PDF document they upload. It leverages serverless services like Amazon Bedrock, AWS Lambda, and Amazon DynamoDB to provide text generation and analysis capabilities. The application architecture involves uploading a PDF document to an S3 bucket, extracting metadata, converting text to vectors, and using a LangChain to search for information related to user prompts. The application is not intended for production use and serves as a demonstration and educational tool.
azure-ai-foundry-baseline
This repository serves as a reference implementation for running a chat application and an AI orchestration layer using Azure AI Foundry Agent service and OpenAI foundation models. It covers common generative AI chat application characteristics such as creating agents, querying data stores, chat memory database, orchestration logic, and calling language models. The implementation also includes production requirements like network isolation, Azure AI Foundry Agent Service dependencies, availability zone reliability, and limiting egress network traffic with Azure Firewall.

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.
starter-monorepo
Starter Monorepo is a template repository for setting up a monorepo structure in your project. It provides a basic setup with configurations for managing multiple packages within a single repository. This template includes tools for package management, versioning, testing, and deployment. By using this template, you can streamline your development process, improve code sharing, and simplify dependency management across your project. Whether you are working on a small project or a large-scale application, Starter Monorepo can help you organize your codebase efficiently and enhance collaboration among team members.
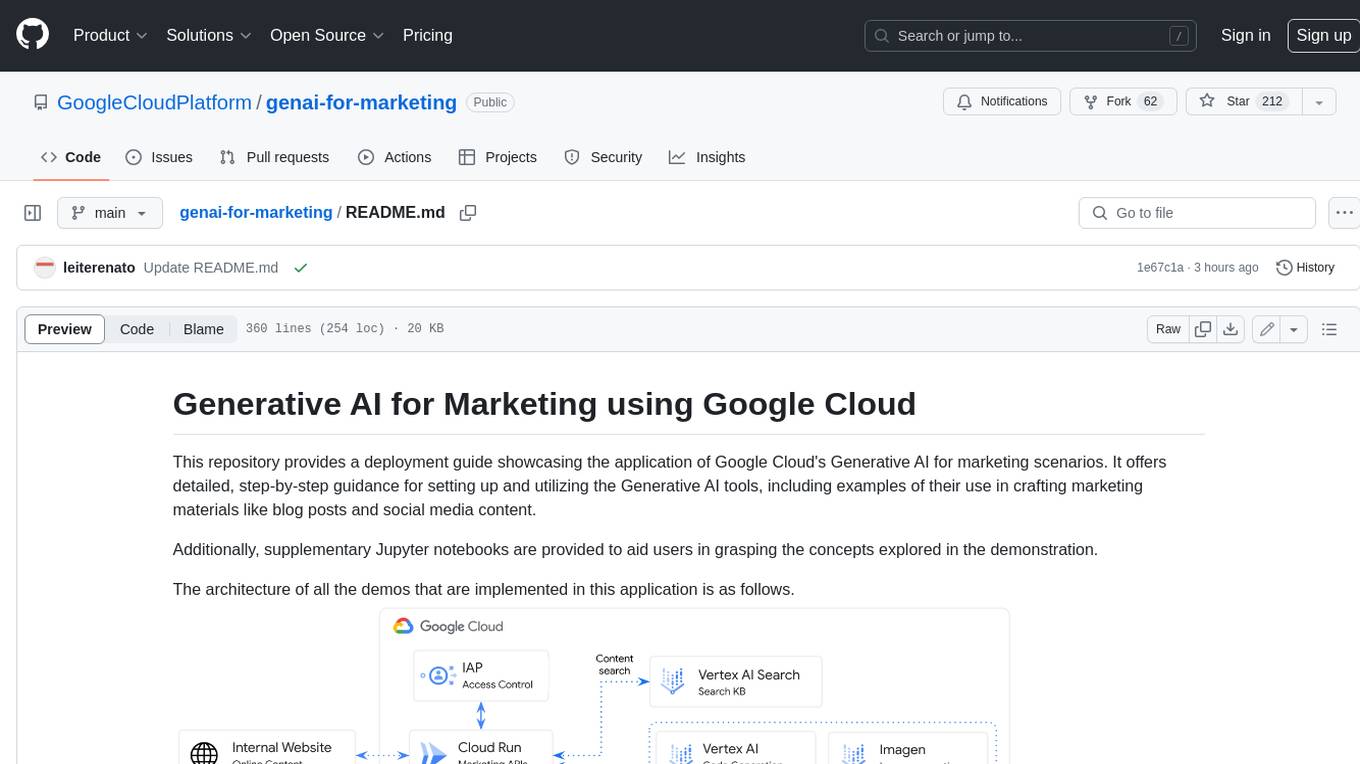
genai-for-marketing
This repository provides a deployment guide for utilizing Google Cloud's Generative AI tools in marketing scenarios. It includes step-by-step instructions, examples of crafting marketing materials, and supplementary Jupyter notebooks. The demos cover marketing insights, audience analysis, trendspotting, content search, content generation, and workspace integration. Users can access and visualize marketing data, analyze trends, improve search experience, and generate compelling content. The repository structure includes backend APIs, frontend code, sample notebooks, templates, and installation scripts.
aws-ai-stack
AWS AI Stack is a full-stack boilerplate project designed for building serverless AI applications on AWS. It provides a trusted AWS foundation for AI apps with access to powerful LLM models via Bedrock. The architecture is serverless, ensuring cost-efficiency by only paying for usage. The project includes features like AI Chat & Streaming Responses, Multiple AI Models & Data Privacy, Custom Domain Names, API & Event-Driven architecture, Built-In Authentication, Multi-Environment support, and CI/CD with Github Actions. Users can easily create AI Chat bots, authentication services, business logic, and async workers using AWS Lambda, API Gateway, DynamoDB, and EventBridge.
For similar tasks

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.

AI-in-a-Box
AI-in-a-Box is a curated collection of solution accelerators that can help engineers establish their AI/ML environments and solutions rapidly and with minimal friction, while maintaining the highest standards of quality and efficiency. It provides essential guidance on the responsible use of AI and LLM technologies, specific security guidance for Generative AI (GenAI) applications, and best practices for scaling OpenAI applications within Azure. The available accelerators include: Azure ML Operationalization in-a-box, Edge AI in-a-box, Doc Intelligence in-a-box, Image and Video Analysis in-a-box, Cognitive Services Landing Zone in-a-box, Semantic Kernel Bot in-a-box, NLP to SQL in-a-box, Assistants API in-a-box, and Assistants API Bot in-a-box.

spring-ai
The Spring AI project provides a Spring-friendly API and abstractions for developing AI applications. It offers a portable client API for interacting with generative AI models, enabling developers to easily swap out implementations and access various models like OpenAI, Azure OpenAI, and HuggingFace. Spring AI also supports prompt engineering, providing classes and interfaces for creating and parsing prompts, as well as incorporating proprietary data into generative AI without retraining the model. This is achieved through Retrieval Augmented Generation (RAG), which involves extracting, transforming, and loading data into a vector database for use by AI models. Spring AI's VectorStore abstraction allows for seamless transitions between different vector database implementations.
ragstack-ai
RAGStack is an out-of-the-box solution simplifying Retrieval Augmented Generation (RAG) in GenAI apps. RAGStack includes the best open-source for implementing RAG, giving developers a comprehensive Gen AI Stack leveraging LangChain, CassIO, and more. RAGStack leverages the LangChain ecosystem and is fully compatible with LangSmith for monitoring your AI deployments.
breadboard
Breadboard is a library for prototyping generative AI applications. It is inspired by the hardware maker community and their boundless creativity. Breadboard makes it easy to wire prototypes and share, remix, reuse, and compose them. The library emphasizes ease and flexibility of wiring, as well as modularity and composability.
cloudflare-ai-web
Cloudflare-ai-web is a lightweight and easy-to-use tool that allows you to quickly deploy a multi-modal AI platform using Cloudflare Workers AI. It supports serverless deployment, password protection, and local storage of chat logs. With a size of only ~638 kB gzip, it is a great option for building AI-powered applications without the need for a dedicated server.
app-builder
AppBuilder SDK is a one-stop development tool for AI native applications, providing basic cloud resources, AI capability engine, Qianfan large model, and related capability components to improve the development efficiency of AI native applications.
cookbook
This repository contains community-driven practical examples of building AI applications and solving various tasks with AI using open-source tools and models. Everyone is welcome to contribute, and we value everybody's contribution! There are several ways you can contribute to the Open-Source AI Cookbook: Submit an idea for a desired example/guide via GitHub Issues. Contribute a new notebook with a practical example. Improve existing examples by fixing issues/typos. Before contributing, check currently open issues and pull requests to avoid working on something that someone else is already working on.
For similar jobs

Awesome-LLM-RAG-Application
Awesome-LLM-RAG-Application is a repository that provides resources and information about applications based on Large Language Models (LLM) with Retrieval-Augmented Generation (RAG) pattern. It includes a survey paper, GitHub repo, and guides on advanced RAG techniques. The repository covers various aspects of RAG, including academic papers, evaluation benchmarks, downstream tasks, tools, and technologies. It also explores different frameworks, preprocessing tools, routing mechanisms, evaluation frameworks, embeddings, security guardrails, prompting tools, SQL enhancements, LLM deployment, observability tools, and more. The repository aims to offer comprehensive knowledge on RAG for readers interested in exploring and implementing LLM-based systems and products.
ChatGPT-On-CS
ChatGPT-On-CS is an intelligent chatbot tool based on large models, supporting various platforms like WeChat, Taobao, Bilibili, Douyin, Weibo, and more. It can handle text, voice, and image inputs, access external resources through plugins, and customize enterprise AI applications based on proprietary knowledge bases. Users can set custom replies, utilize ChatGPT interface for intelligent responses, send images and binary files, and create personalized chatbots using knowledge base files. The tool also features platform-specific plugin systems for accessing external resources and supports enterprise AI applications customization.

call-gpt
Call GPT is a voice application that utilizes Deepgram for Speech to Text, elevenlabs for Text to Speech, and OpenAI for GPT prompt completion. It allows users to chat with ChatGPT on the phone, providing better transcription, understanding, and speaking capabilities than traditional IVR systems. The app returns responses with low latency, allows user interruptions, maintains chat history, and enables GPT to call external tools. It coordinates data flow between Deepgram, OpenAI, ElevenLabs, and Twilio Media Streams, enhancing voice interactions.

awesome-LLM-resourses
A comprehensive repository of resources for Chinese large language models (LLMs), including data processing tools, fine-tuning frameworks, inference libraries, evaluation platforms, RAG engines, agent frameworks, books, courses, tutorials, and tips. The repository covers a wide range of tools and resources for working with LLMs, from data labeling and processing to model fine-tuning, inference, evaluation, and application development. It also includes resources for learning about LLMs through books, courses, and tutorials, as well as insights and strategies from building with LLMs.
tappas
Hailo TAPPAS is a set of full application examples that implement pipeline elements and pre-trained AI tasks. It demonstrates Hailo's system integration scenarios on predefined systems, aiming to accelerate time to market, simplify integration with Hailo's runtime SW stack, and provide a starting point for customers to fine-tune their applications. The tool supports both Hailo-15 and Hailo-8, offering various example applications optimized for different common hosts. TAPPAS includes pipelines for single network, two network, and multi-stream processing, as well as high-resolution processing via tiling. It also provides example use case pipelines like License Plate Recognition and Multi-Person Multi-Camera Tracking. The tool is regularly updated with new features, bug fixes, and platform support.
cloudflare-rag
This repository provides a fullstack example of building a Retrieval Augmented Generation (RAG) app with Cloudflare. It utilizes Cloudflare Workers, Pages, D1, KV, R2, AI Gateway, and Workers AI. The app features streaming interactions to the UI, hybrid RAG with Full-Text Search and Vector Search, switchable providers using AI Gateway, per-IP rate limiting with Cloudflare's KV, OCR within Cloudflare Worker, and Smart Placement for workload optimization. The development setup requires Node, pnpm, and wrangler CLI, along with setting up necessary primitives and API keys. Deployment involves setting up secrets and deploying the app to Cloudflare Pages. The project implements a Hybrid Search RAG approach combining Full Text Search against D1 and Hybrid Search with embeddings against Vectorize to enhance context for the LLM.
pixeltable
Pixeltable is a Python library designed for ML Engineers and Data Scientists to focus on exploration, modeling, and app development without the need to handle data plumbing. It provides a declarative interface for working with text, images, embeddings, and video, enabling users to store, transform, index, and iterate on data within a single table interface. Pixeltable is persistent, acting as a database unlike in-memory Python libraries such as Pandas. It offers features like data storage and versioning, combined data and model lineage, indexing, orchestration of multimodal workloads, incremental updates, and automatic production-ready code generation. The tool emphasizes transparency, reproducibility, cost-saving through incremental data changes, and seamless integration with existing Python code and libraries.
wave-apps
Wave Apps is a directory of sample applications built on H2O Wave, allowing users to build AI apps faster. The apps cover various use cases such as explainable hotel ratings, human-in-the-loop credit risk assessment, mitigating churn risk, online shopping recommendations, and sales forecasting EDA. Users can download, modify, and integrate these sample apps into their own projects to learn about app development and AI model deployment.