Best AI tools for< Tokenization >
11 - AI tool Sites

Deckee.AI
Deckee.AI is an AI-powered platform that allows users to instantly build blockchain websites and tokens. With Deckee.AI, users can create customized webpages for blogging, consulting, digital creation, and more. Deckee.AI also provides powerful editing tools, domain and SSL, separate hosting options, and the ability to choose the exact layout users want. Additionally, Deckee.AI makes it easy to create professional designs and digital collections, as well as unique digital tokens as a representation of products, events, rewards, and more.
Atriv
Atriv is a comprehensive digital art creation and monetization platform that empowers artists to showcase, sell, and earn from their creations. With a user-friendly interface and advanced tools, Atriv provides a seamless experience for artists to create stunning digital art, connect with collectors, and build a sustainable income stream.

Toolblox
Toolblox is an AI-powered platform that enables users to create purpose-built, audited smart-contracts and Dapps for tokenized assets quickly and efficiently. It offers a no-code solution for turning ideas into smart-contracts, visualizing workflows, and creating tokenization solutions. With pre-audited smart-contracts, examples, and an AI assistant, Toolblox simplifies the process of building and launching decentralized applications. The platform caters to founders, agencies, and businesses looking to streamline their operations and leverage blockchain technology.
Token Counter
Token Counter is an AI tool designed to convert text input into tokens for various AI models. It helps users accurately determine the token count and associated costs when working with AI models. By providing insights into tokenization strategies and cost structures, Token Counter streamlines the process of utilizing advanced technologies.

Tresata
Tresata is an AI tool that offers inventory and cataloging, inferencing and connecting, discoverability and lineage tracking, tokenization, and data enrichment capabilities. It provides SAM (Smart Augmented Intelligence) features and seamless integrations for customers. The platform empowers users to create data products for AI applications by uploading data to the Tresata cloud and accessing it for analysis and insights. Tresata emphasizes the importance of good data for all, with a focus on data-driven decision-making and innovation.

NLTK
NLTK (Natural Language Toolkit) is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum. Thanks to a hands-on guide introducing programming fundamentals alongside topics in computational linguistics, plus comprehensive API documentation, NLTK is suitable for linguists, engineers, students, educators, researchers, and industry users alike.
Immplify
Immplify is the ultimate platform for immigrants, offering an advanced document management system, on-demand immigration-related services, and a vibrant verified immigrant community. The platform prioritizes security, employing 2-factor authentication, data redaction, AES 256-bit encryption, and tokenization to protect users' confidential information. Immplify simplifies the immigration process by providing features like document digitization, on-the-go scanning, advanced encryption, automatic document organization, travel time tracking, intelligent document tracking, key insights dashboard, instant access to immigration guidance, and secure document sharing. Trusted by immigrants for its efficiency and reliability, Immplify streamlines tasks such as managing travel history, organizing documents, filling out visa forms, and ensuring document security.
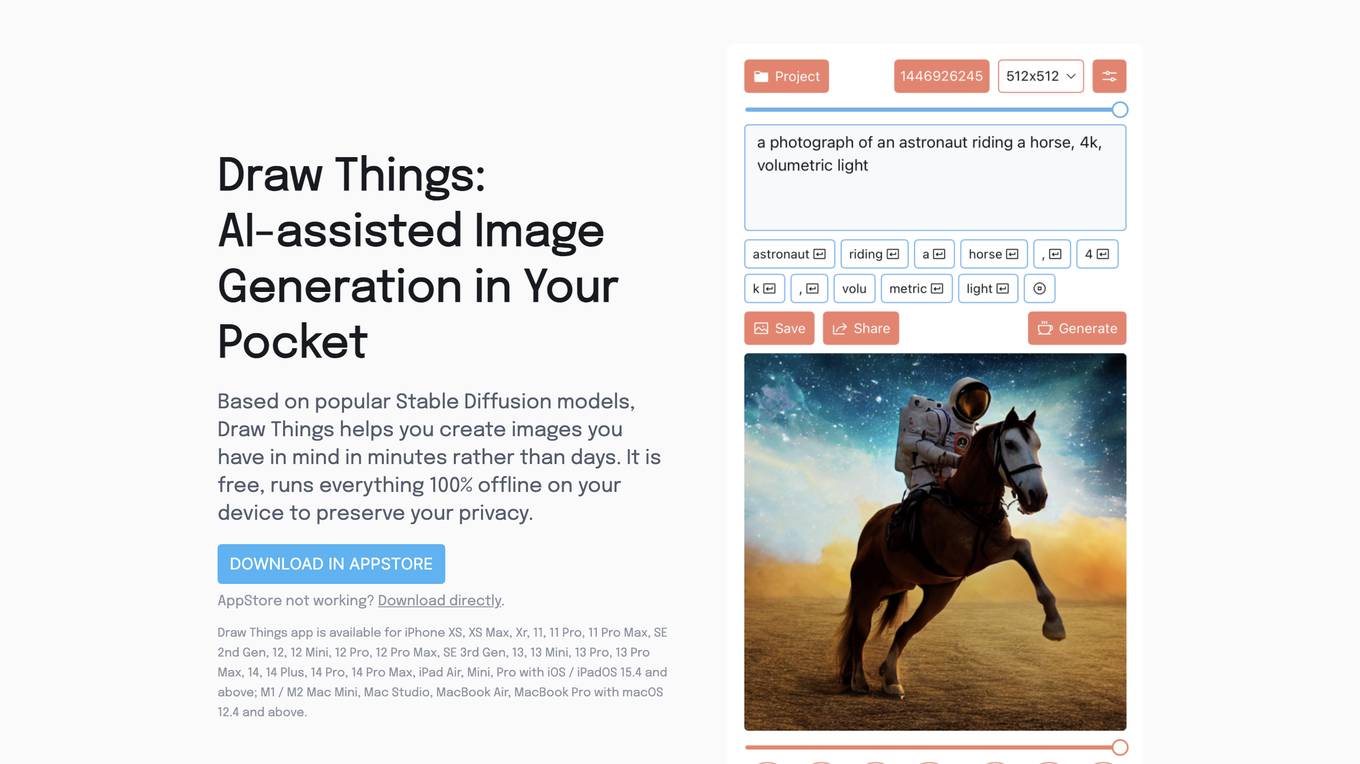
Draw Things
Draw Things is an AI-assisted image generation app that allows users to create images from their imagination in minutes. It is powered by Stable Diffusion models and runs entirely offline on the user's device, ensuring privacy. The app offers a range of features, including inpainting, outpainting, text-to-image generation, text-guided image-to-image generation, and image and prompt editing history. Users can also select images from their camera roll and utilize various Stable Diffusion features such as guidance scale, steps, strength, image sizes, negative prompts, manual seed, and prompt tokenization. Additionally, the app allows users to preview different models and styles, including Generic Stable Diffusion v1.4, Waifu Diffusion v1.3 for Anime, and Stable Diffusion v1.5 Inpainting.
Trust Stamp
Trust Stamp is an AI-powered digital identity solution that focuses on mitigating fraud through biometrics, privacy, and cybersecurity. The platform offers secure authentication and multi-factor authentication using biometric data, along with features like KYC/AML compliance, tokenization, and age estimation. Trust Stamp helps financial institutions, healthcare providers, dating platforms, and other industries prevent identity theft and fraud by providing innovative solutions for account recovery and user security.
Evervault
Evervault is a flexible payments security platform that provides maximum protection with minimum compliance burden. It allows users to easily tokenize cards, optimize margins, comply with PCI standards, avoid gateway lock-in, and set up card issuing programs. Evervault is trusted by global leaders for securing sensitive payment data and offers features like PCI compliance, payments optimization, card issuing, network tokens, key management, and more. The platform enables users to accelerate card product launches, build complex card sharing workflows, optimize payment performance, and run highly sensitive payment operations. Evervault's unique encryption model ensures data security, reduced risk of data breach, improved performance, and maximum resiliency. It offers agile payments infrastructure, customizable UI components, cross-platform support, and effortless scalability, making it a developer-friendly solution for securing payment data.
LLM Token Counter
The LLM Token Counter is a sophisticated tool designed to help users effectively manage token limits for various Language Models (LLMs) like GPT-3.5, GPT-4, Claude-3, Llama-3, and more. It utilizes Transformers.js, a JavaScript implementation of the Hugging Face Transformers library, to calculate token counts client-side. The tool ensures data privacy by not transmitting prompts to external servers.
1 - Open Source AI Tools
llama.rn
React Native binding of llama.cpp, which is an inference of LLaMA model in pure C/C++. This tool allows you to use the LLaMA model in your React Native applications for various tasks such as text completion, tokenization, detokenization, and embedding. It provides a convenient interface to interact with the LLaMA model and supports features like grammar sampling and mocking for testing purposes.
1 - OpenAI Gpts
Web3 Wizard
Web3 expert knowledgeable in Blockchains, DApps, NFTs, Wallets, Tokenization, CBDCs, and more.